机器学习-增加样本、精确率与召回率
增加样本:
当模型出现较大误差时,有一种改进方法就是增加样本数据,我们可以通过对模型的高偏差与高方差分析来确定增加样本是否有效,而如何增加样本,则可以通过模型的误差分析来考虑。
误差分析是对模型判断的错误部分/错误部分的子集进行分析,找出这些错误之间的共同特征、属性等,从而针对性地增加样本。例如:在垃圾邮件的分类中,如果绝大多数划分错误的样本是某一特定类型的邮件,那么针对性的增加这一类型的样本则很大程度上可以帮助我们的模型降低误差,而如果我们只是一味的增加所有类型的样本,同样的新增样本数量实际上得到的效果远不如前者。
除了这种方法之外,还有两种增加样本的方法,分别是数据增强与数据合成。数据增强是指通过现有的样本来创造新的样本,在这个过程中需要保证创造的需与原始训练集样本相似,否则对于模型的改善并没有作用。对于图像样本而言,常用的数据增强方法有:旋转、缩放、调整对比度、镜像与扭曲等;而对于语音样本,通常是对原始语音数据加上噪音。

数据合成则是通过算法、仿真等方法人为地从0开始合成创造数据,一般可以有效的补充原始数据的不足,同样的也需要保证与原始训练集样本相似。
不过,即使有很多增加样本的有效手段,但是实际中也可能会存在很多小样本问题,无法通过其他方法来增加足够的样本以帮助模型更好的训练,这时候可以考虑迁移学习。
迁移学习:
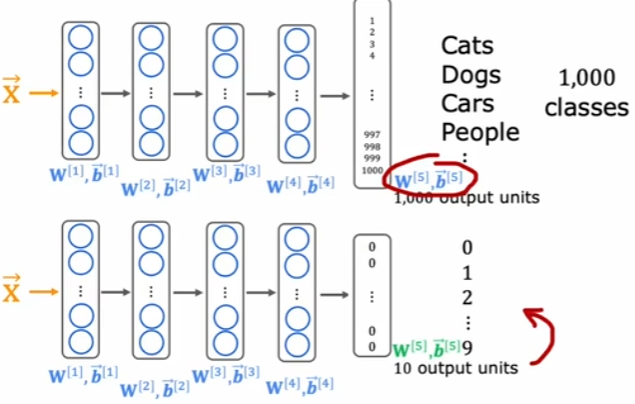
迁移学习是指通过其他相似任务中与本任务完全不同的样本,首先进行有监督预训练,获得初始的模型,包括模型的架构以及各层的参数,然后再根据本任务对这个模型进行微调。微调有两种形式:
- 只替换输出层,保留其他层的所有内容;
- 只保留网络架构,而根据自身训练集样本重新训练所有参数。
迁移学习能够起作用的原因是:在模型的浅层网络,往往学习的都是简单、通用的特征,如边、角点等,再逐步过渡到曲线等其他形状,而在模型的深层网络,才是根据自身样本特征来捕捉高级语义特征,因此有监督预训练可以有效地让模型学习如何从样本中提取通用特征。
即使是全部重新训练所有参数,也优于直接利用自身样本训练。因为此时的预训练模型是可以满足目标要求的,也就代表着此时的模型已经处于一个较好的状态,而不是直接训练时的随机初始化,因此有助于更快收敛;并且小样本时很有可能出现过拟合问题,如果有一个类似任务的预训练模型,之前通过大规模的学习到的通用特征可以有效地避免过拟合。
一般在自身样本数量不是很小时,通常会采用第二种微调形式,此时模型可以更好地适应目标领域的特异性。
精确率与召回率:
在实际的任务中,有时候会出现数据倾斜的问题,例如在二分类问题中,实际数据中只有极少一部分数据属于y=1类,假设y=1的实际占比只有0.5%,那么此时即使把模型直接设置为输出y=0,也就意味着对于实际y=1的类全部判断错误,模型的准确率也高达99.5%,但这个模型显然不是一个合理有效的模型,因此引入了精确率与召回率的概念。
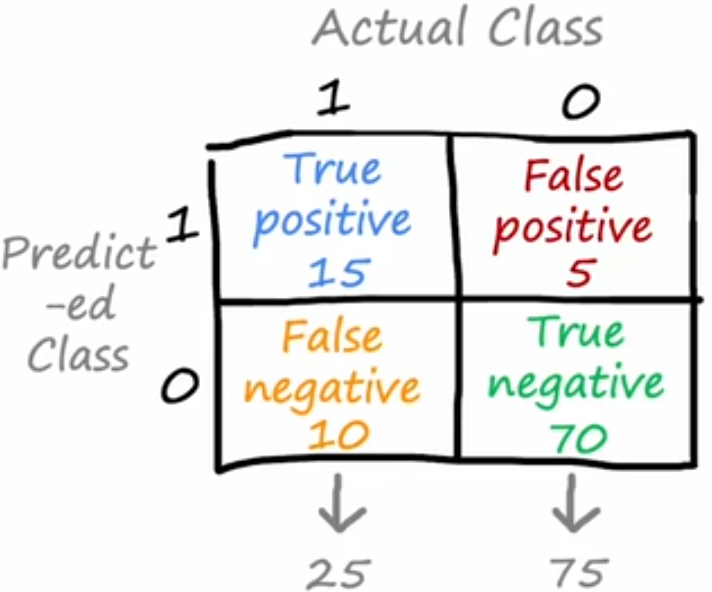
上图称为混淆矩阵,纵列代表实际样本为1/0,横行代表模型预测样本为1/0。
对于模型预测为1,实际也为1的,称为真正例,对应左上;
对于模型预测为1,实际为0的,称为假正例,对应右上;
对于模型预测为0,实际也为0的,称为真负例,对应右下;
对于模型预测为0,实际为1的,称为假负例,对应左下。
精确率:
精确率代表模型预测为1且实际也为1的样本,即真正例,在所有预测为1的样本中的占比,也就意味着,所有模型预测为1的样本中,有多少与实际情况相符,即:
召回率:
召回率代表模型预测为1且实际也为1的样本,即真正例,在所有实际为1的样本中的占比,也就意味着,在实际情况为1时,有多少模型能够正确预测为1,即:
在实际运用中,我们需要在精确率与召回率之间进行权衡。以逻辑回归为例,如果我们希望只有具有很大把握时才认为y=1,对应的阈值设置就会是一个>0.5的数,如0.7;而如果我们希望尽可能地不要漏过任何一个有可能是y=1的样本,对应的阈值设置就会是一个<0.5的数,如0.3。显然在上面两种情况时,前者的精确率会提高但召回率下降,而后者反之。
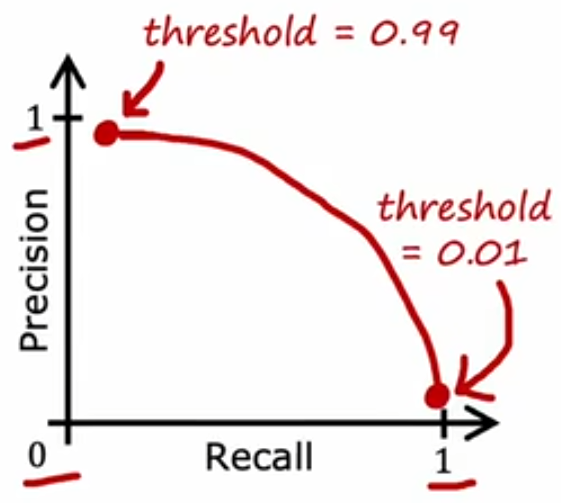
两者的权衡可以结合实际情况进行考虑,此外还引入了一个F1分数用于综合考虑二者。因为如果只是单纯的求二者均值,这个结果显然是不合理的,根据前述很有可能出现精确率/召回率很高,而另一者很低的情况,此时求出来的平均值可能会高于其他模型。但实际上这种精确率/召回率中有一者很低的模型根本没有实际意义,比如在数据倾斜情况时提到的直接将模型设置为y=0。因此F1分数更多的是去关注两者中的较低者: