【论文阅读】Deep Adversarial Multi-view Clustering Network

摘要
多视图聚类通过挖掘多个视图之间的共同聚类结构,近年来受到了越来越多的关注。现有的大多数多视图聚类算法使用浅层、线性嵌入函数来学习多视图数据的公共结构。然而,这些方法无法充分利用多视图数据的非线性特性,而这种特性对于揭示复杂的聚类结构非常重要。本文提出了一种新颖的多视图聚类方法——深度对抗多视图聚类(Deep Adversarial Multi-view Clustering, DAMC)网络,用于学习嵌入在多视图数据中的内在结构。具体而言,我们的模型采用深度自编码器来学习由多个视图共享的潜在表示,同时利用对抗训练进一步捕获数据分布并解耦潜在空间。在多个真实数据集上的实验结果表明,该方法优于当前最先进的方法。
引言
1 引言
聚类分析是机器学习、模式识别、计算机视觉和数据挖掘等多个领域中的一项基础任务。在这一主题上,研究人员投入了大量精力,其中多视图聚类(multi-view clustering, MVC)[Yang and Wang, 2018] 受到了特别的关注。多视图数据能够为聚类任务提供互补信息,这在许多真实应用中是可以获取的。例如,一张图像可以由多种描述符来表征,如 SIFT [Lowe, 2004]、方向梯度直方图(HOG)[Dalal and Triggs, 2005]、GIST [Oliva and Torralba, 2001] 和局部二值模式(LBP)[Ojala et al., 2002]。由于这些特征从不同角度描述了对象的属性,因此它们被视为多视图数据。近年来,多视图聚类方法 [Zhao et al., 2017; Luo et al., 2018] 得到了快速发展,其核心在于挖掘多视图之间共享的互补信息。在此基础上,过去几十年中,已经有许多先进的多视图聚类算法被提出。
例如,[Liu et al., 2013b] 从非负矩阵分解的角度解决了这一问题,通过在多个视图间进行非负矩阵分解来寻找公共潜在因子;一致性与特定性多视图子空间聚类(CSMSC)[Luo et al., 2018] 则利用一个公共一致性表示和一组特定性表示来刻画多视图数据的自表达特性,更好地适配了真实的多视图数据集。虽然传统的多视图聚类算法已取得了较好效果,但它们主要使用浅层、线性嵌入函数来揭示数据的内在结构,无法有效建模复杂数据的非线性特性。
近年来,深度聚类方法被提出,用于利用深度神经网络建模数据样本之间的关系,从而获得聚类结果。在单视图聚类方法中,DSC [Ji et al., 2017] 以堆叠自编码器为基础模型,利用自表达特性在潜在空间中学习数据的相似度;DAC [Chang et al., 2017] 将聚类问题转化为二值对分类框架,推动相似的图像对归入同一簇;DEC [Xie et al., 2016] 通过最小化预测簇标签分布与预定义分布之间的 KL 散度设计了一种新的聚类目标函数。另一方面,一些最新研究尝试将深度学习引入多视图聚类问题。例如,[Andrew et al., 2013] 提出了典型相关分析(CCA)的深度神经网络扩展——深度 CCA,用于多视图聚类;[Abavisani and Patel, 2018] 则使用卷积神经网络进行无监督多模态子空间聚类。然而,利用深度神经网络在多视图间学习低维潜在空间的研究仍然较少。
在本文中,我们提出了一种新颖的深度对抗多视图聚类(Deep Adversarial Multi-view Clustering, DAMC)网络,用于学习嵌入在多视图数据中的内在结构(见图1)。我们的模型通过共享权重的多视图自编码器网络,从原始特征有效映射到公共低维嵌入空间。与传统算法相比,该方法能够揭示多视图数据的非线性特性,这对于处理复杂和高维数据至关重要。此外,我们采用对抗训练 [Goodfellow et al., 2014] 作为正则化器来引导编码器训练,从而捕获每个单视图的数据分布,并进一步解耦公共潜在空间。在图像和文本数据集上的实验结果表明,该方法优于其他多视图聚类方法。
我们的主要贡献如下:
提出一种新颖的 DAMC 网络:不同于现有的多视图聚类方法,所提方法能够充分建模任意视图之间的多层非线性相关性。
针对每个视图设计判别器网络:能够进一步捕获数据分布并解耦潜在空间。
设计聚类损失约束公共表示:通过最小化预测标签分布与预定义分布之间的相对熵,实现公共表示的优化。
方法
网络架构
给定一个包含 VV 个视图的数据集 χ={X1,…,Xv,…,XV},其中 Xv∈Rdv×n表示来自第 vv 个视图的 n 个样本(每个样本维度为 dv),我们构建了一个 DAMC 网络,该网络由以下部分组成:
一个全连接的多视图去噪编码器 EE;
一个全连接的多视图去噪生成器 GG;
VV 个全连接判别器;
以及位于编码器顶部的深度嵌入聚类层。
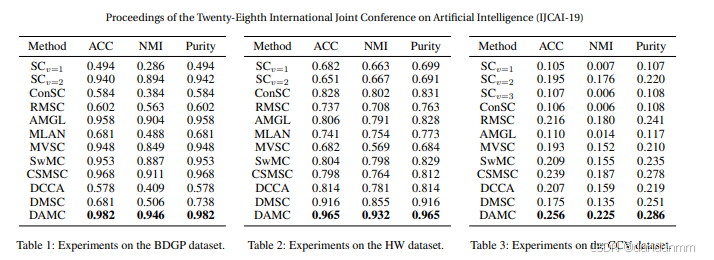
图 1 展示了在 VV 视图场景下的 DAMC 网络结构。
1. 多视图去噪编码器 E
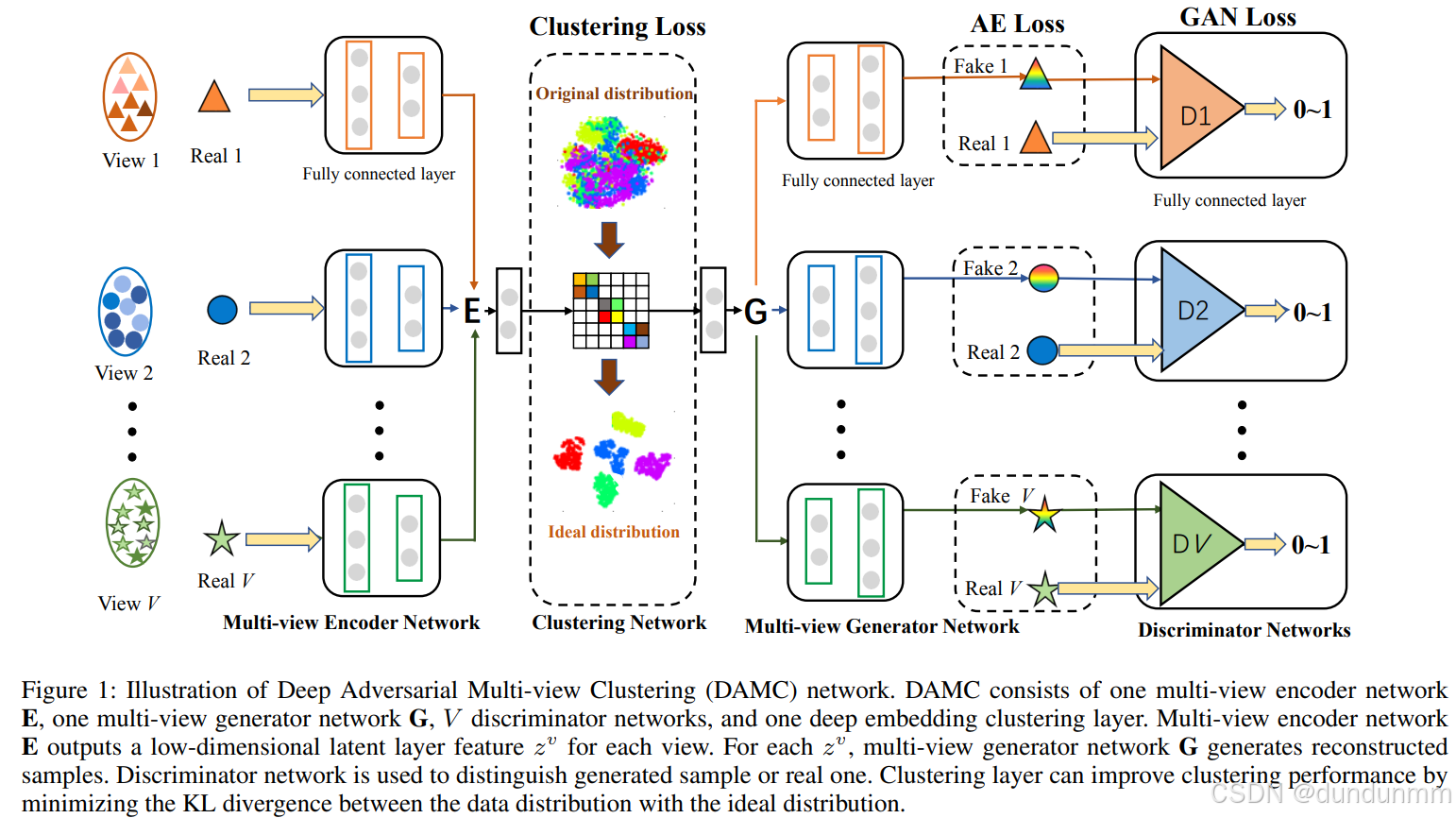
在多视图去噪编码器网络中,每个视图包含 M 层独立全连接网络 和 N 层共享参数的全连接网络。独立层用于处理各视图不同的特征维度。对于第 v 个视图,给定 Xv={x1(v),x2(v),…,xn(v)},多视图去噪编码器 E 旨在学习该视图的潜在表示 Zv={z1(v),z2(v),…,zn(v)},即将 dv 维的输入数据 xi(v)映射到低维表示 zi(v):
![]()
其中 fv表示由参数 ΘE 定义的第 v 个视图的编码网络。
2. 多视图去噪生成器 G
多视图去噪生成器的结构与编码器相反,由 N 层共享参数的全连接网络 和 M 层每个视图独立的全连接网络 组成,可根据各视图的潜在表示生成相应的重构样本:
{Y1,Y2,…,Yv,…,YV}=G(Zv)
其中 Yv 表示第 v个视图的重构样本矩阵。
3. 判别器网络 Dv
判别器网络由 V个全连接判别器组成,每个判别器 Dv包含 3 层全连接层,用于区分生成样本 yi(v)和真实样本 xi(v)。GAN 损失定义为:
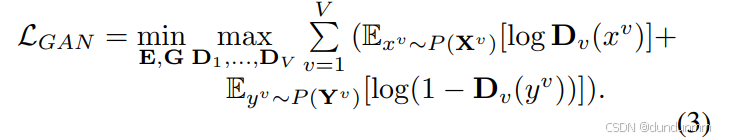
训练过程中,编码器和生成器生成与真实数据相似的假样本,各判别器学习区分真假样本,二者进行对抗直至收敛。由于 GAN 本身并不能在样本级别保证输出的可控性,这对聚类任务是不利的,因此我们将 GAN 损失与 AE(自编码器)损失结合,以提升重构数据的可靠性。
聚类损失(Clustering Loss)
AE 损失和 GAN 损失鼓励生成器生成与真实样本更相似的样本,从而使嵌入表示尽可能保留原始特征信息。但它们无法保证编码后的低维空间具备良好的聚类结构。为了获得有利于聚类划分的表示空间,我们在 DAMC 网络中引入基于 KL 散度的聚类损失。
首先,针对每个视图学习潜在表示:
Z1=f1(X1;θE), Z2=f2(X2;θE),…,ZV=fV(XV;θE)
然后得到公共潜在表示:
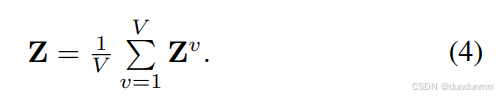
给定初始簇中心 {μj}j=1k,根据 [Xie et al., 2016],采用 Student’s t 分布作为核函数来计算公共潜在表示点 zi 与簇中心 μj 的相似度:
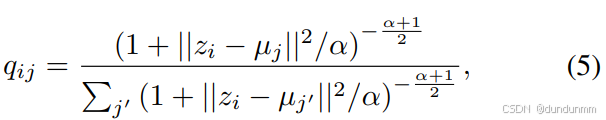
其中 α为自由度(实验中取 α=1),qij 表示样本 i 属于簇 j 的概率(软分配)。
为了优化聚类结构,我们引入辅助目标分布 pij,并通过最小化 qij与 pij 之间的 KL 散度来训练模型:
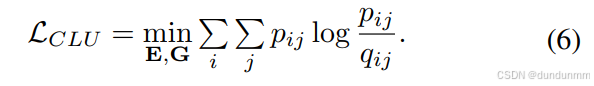
其中,pij 通过提升高置信度样本的权重获得:
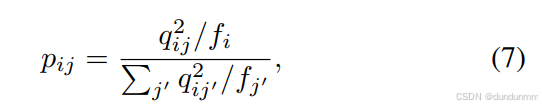
这样可以使同类数据在表示空间中更加集中,从而获得更有效的公共表示。
训练流程
步骤 1:训练多视图去噪编码器 E 和生成器 G,最小化 AE 损失。输入 {x1,x2,…,xV} 得到潜在特征 {z1,z2,…,zV},再输入生成器得到重构样本,更新 E 和 G。然后在公共表示 Z 上运行 k-means 获取初始簇中心 {μj}。
步骤 2:联合训练 E、G 和判别器 D1,…,DV,优化 AE 损失与 GAN 损失之和。将生成样本与真实样本送入各判别器,交替更新生成网络与判别器。
步骤 3:在步骤 2 的基础上,加入嵌入聚类层训练整个网络。每次迭代更新聚类中心,最终在获得的公共表示上使用谱聚类得到最终聚类结果。
实验