MM-2025 | 浙大vivo需求驱动的具身导航!CogDDN:具有基于决策优化和双过程思维的认知驱动导航方法

- 作者:Yuehao Huang1^{1}1, Liang Liu2^{2}2, Shuangming Lei1^{1}1, Yukai Ma1^{1}1, Hao Su1^{1}1, Jianbiao Mei1^{1}1, Pengxiang Zhao1^{1}1, Yaqing Gu1^{1}1, Yong Liu1^{1}1, Jiajun Lv1^{1}1
- 单位:1^{1}1浙江大学,2^{2}2vivo人工智能实验室
- 论文标题:CogDDN: A Cognitive Demand-Driven Navigation with Decision Optimization and Dual-Process Thinking
- 论文链接:https://arxiv.org/pdf/2507.11334
- 项目主页:https://yuehaohuang.github.io/CogDDN/
- 代码链接:https://github.com/yuehaohuang/CogDDN
主要贡献
- 提出基于视觉语言模型的需求驱动导航框架CogDDN,能够模拟人类的认知机制和学习过程。
- 引入了双过程决策模块,该模块无需人工干预,通过自监督机制让经验直觉过程(Heuristic Process)继承理性分析过程(Analytic Process)的能力。
- 利用分析过程和知识积累机制丰富可转移的知识库,实现持续学习,并有效地泛化到新的导航环境中。
- 在AI2Thor模拟器上使用ProcThor数据集进行的大量实验表明,CogDDN的性能优于仅使用单视图相机的方法,导航准确性和适应性显著提高。
研究背景
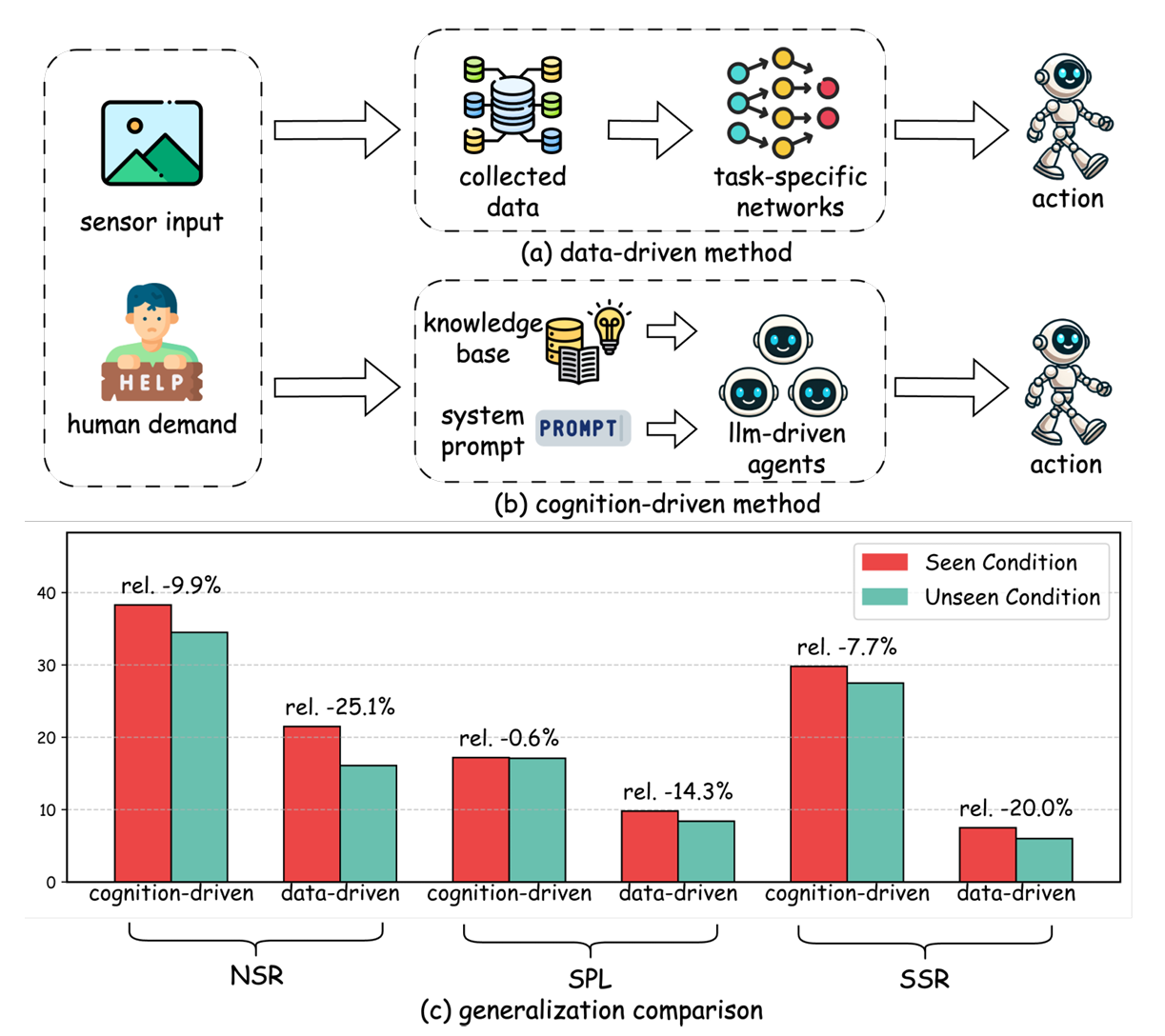
- 移动机器人在未知和非结构化环境中导航和交互的需求日益增加,需求驱动导航(DDN)使机器人能够根据隐含的人类意图识别和定位物体,即使目标物体的位置未知。
- 传统的数据驱动DDN方法依赖于预先收集的数据进行模型训练和决策,限制了它们在未见场景中的泛化能力。
- 近年来,大型语言模型(LLM)和视觉-语言模型(VLM)在多模态推理任务中展现出强大的推理能力和广泛的世界知识,适合用于导航任务。因此,研究开始转向采用这些模型作为认知先验,以实现更接近人类的导航策略。
方法
任务定义
CogDDN 的任务是让机器人在给定环境中根据人类的需求和视觉输入定位相关物体。这可以形式化为部分可观测马尔可夫决策过程(POMDP),定义为:
M=(S,O,A,E) \mathcal{M} = (\mathcal{S}, \mathcal{O}, \mathcal{A}, \mathcal{E}) M=(S,O,A,E)
- 状态空间 S\mathcal{S}S:表示机器人当前的状态。
- 观测空间 O\mathcal{O}O:包括人类需求和图像。
- 动作空间 A\mathcal{A}A:例如前进、左转、右转、抬头、低头等。
- 执行函数 E\mathcal{E}E:定义动作的执行。
任务的目标是让机器人在距离目标物体 1.5 米范围内完成任务。
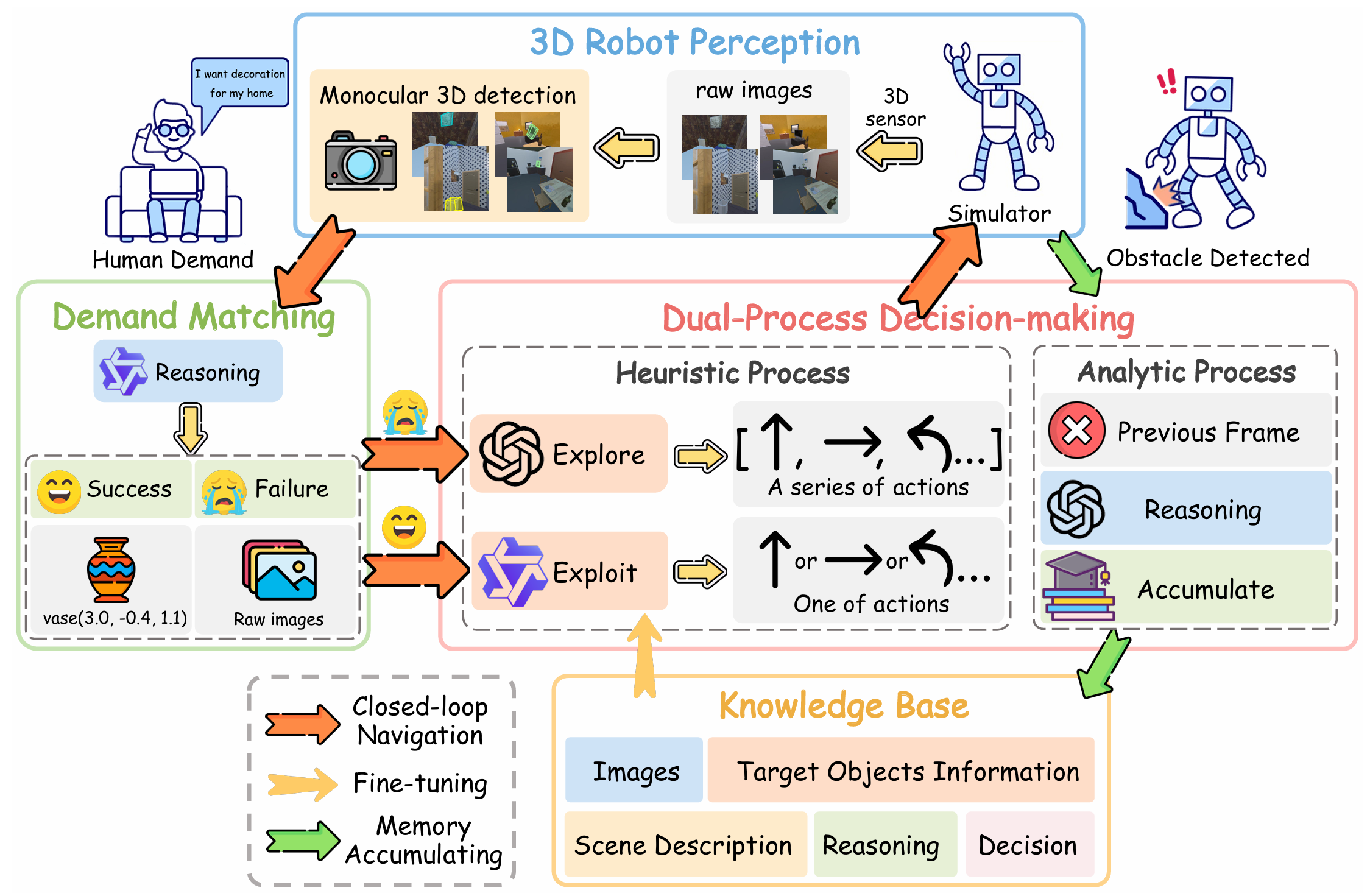
需求匹配
需求匹配模块的核心是利用大型语言模型(LLM)将人类需求与环境中的物体进行语义对齐。具体来说,该模块实现了一个目标对象生成函数:
F:O→P,T \mathcal{F}: \mathcal{O} \to \mathcal{P}, \mathcal{T} F:O→P,T
- 输入:观测空间 O\mathcal{O}O(包括人类需求和图像)。
- 输出:需求属性 P\mathcal{P}P 和目标对象 T\mathcal{T}T。
该模块通过监督微调(SFT)训练 LLM,使其能够更好地将需求与目标对象对齐,避免在没有精确匹配时强行推荐不合适的对象。例如,当用户需求是“我需要一个放花的东西”时,模型不会推荐“杯子”,而是更合适的“花瓶”。
知识库
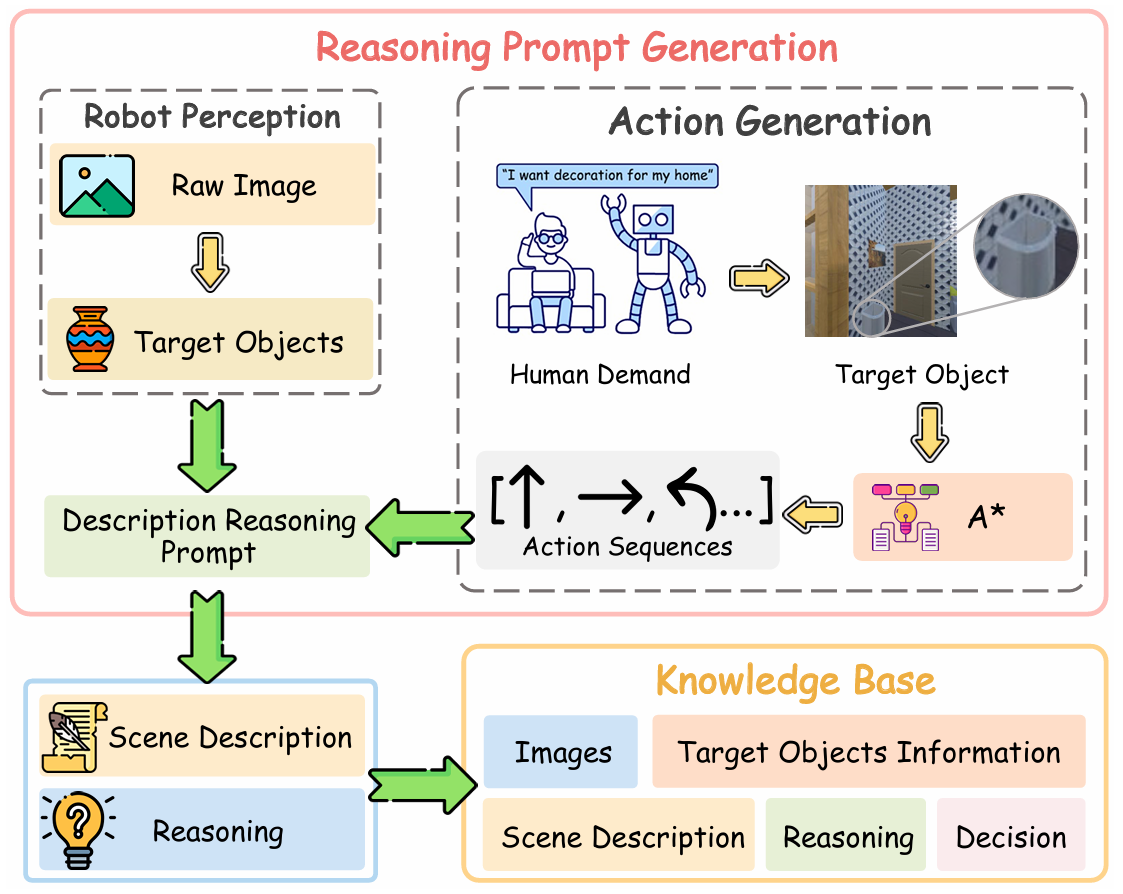
知识库用于存储机器人在导航过程中积累的经验,以支持启发式过程的决策。知识库中的每个条目包含以下内容:
- 场景描述:基于当前视角图像的环境描述,突出可通行区域和可能影响移动的任务相关物体。
- 推理:利用 VLM 的空间感知和常识推理能力,根据目标位置和场景描述生成推理内容。
- 决策:根据推理结果生成最优决策。
知识库的构建过程如下:
- 使用 A* 算法生成从起点到目标物体的最优路径。
- 在执行路径上的每一步时,使用 VLM 生成场景描述和推理。
- 将场景描述、推理和决策存储为经验条目。
这些经验条目用于训练启发式过程,使其能够更好地遵循指令并适应新的导航任务。
启发式过程
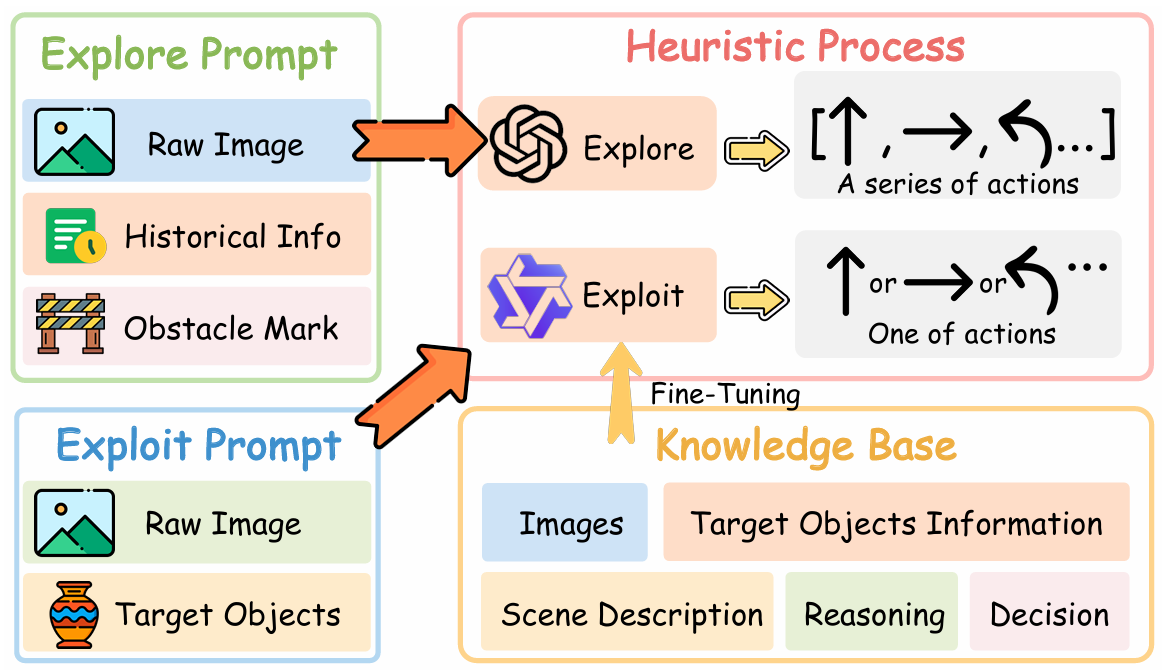
启发式过程模块模拟人类在熟悉环境中的快速、直观决策过程,包含两个子模块:探索(Explore)和利用(Exploit)。
-
探索模块(Explore):
- 当需求匹配模块未能在当前场景中识别出合适的目标对象时激活。
- 生成一系列探索动作,基于当前视角图像、历史动作和障碍物标记。
- 利用 VLM 生成场景描述和推理,指导探索过程。
- 通过避免重复动作和障碍物,优化探索效率。
-
利用模块(Exploit):
- 当需求匹配模块识别出目标对象时激活。
- 利用经过知识库微调的 VLM,生成精确的单步动作以接近目标对象。
- 通过思维链(CoT)推理,确保决策的准确性和高效性。
启发式过程的决策函数定义为:
D,R,S={Explore(I,S′,X)if len(Om)=0Exploit(I,Om)else \mathbf{D}, \mathbf{R}, \mathbf{S} = \begin{cases} \text{Explore}(I, S', X) & \text{if } \text{len}(O_m) = 0 \\ \text{Exploit}(I, O_m) & \text{else} \end{cases} D,R,S={Explore(I,S′,X)Exploit(I,Om)if len(Om)=0else
分析过程
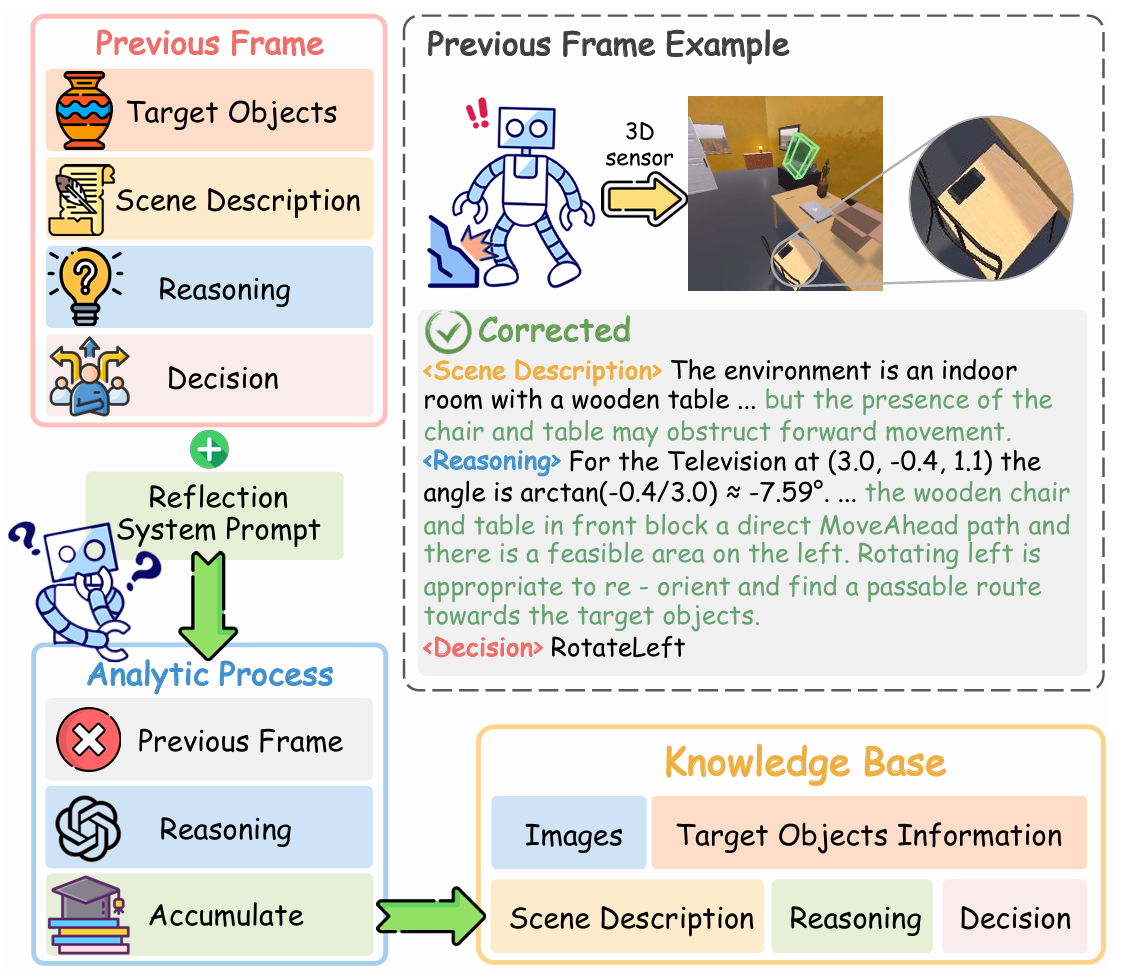
分析过程模块模拟人类在遇到障碍时的深度分析和反思能力。当启发式过程遇到障碍时,分析过程会介入,具体步骤如下:
- 从知识库中获取之前帧的信息,包括目标位置、场景描述、推理和决策。
- 利用 VLM 的世界知识,分析障碍产生的原因。
- 生成纠正后的推理和决策。
- 将纠正后的经验存储到知识库中,以支持未来的决策。
分析过程的决策函数定义为:
Dn,Rn,Sn=GPT(Pr,H,I) \mathbf{D}_n, \mathbf{R}_n, \mathbf{S}_n = \text{GPT}(P_r, H, I) Dn,Rn,Sn=GPT(Pr,H,I)
其中,PrP_rPr 是反思提示,HHH 是障碍信息,III 是当前图像。
实验
数据准备
- 实验环境:使用AI2Thor模拟器和ProcThor数据集进行实验。评估了600个场景(分别来自ProcThor的训练集、验证集和测试集各200个)。这些环境中包含109种不同的目标对象类别,每种对象都能满足需求指令。
- 指令数据:使用DDN提供的1692条训练指令、241条验证指令和485条测试指令。
- 3D机器人感知模块数据:从AI2Thor模拟器中收集了55K帧数据,其中70%用于训练,10%用于验证,20%用于测试。
- 需求匹配模块数据:通过将指令和相关对象输入到LLM中生成共享属性,构建了指令-属性数据集。共收集了7.2K条训练数据、1.4K条验证数据和2.1K条测试数据。
- 启发式过程模块数据:从AI2Thor模拟器中生成了约72K条轨迹数据,其中80%用于训练,20%用于验证。
实现细节
- 3D机器人感知模块:使用UniMODE模型进行3D目标检测。
- 分析过程模块:使用GPT-4进行理性逻辑思考。
- 启发式过程模块和需求匹配模块:使用Qwen2-VL-7B模型,并通过LoRA配置优化性能。
- 训练资源:所有实验在4×RTX6000 GPU上进行训练。
闭环导航评估
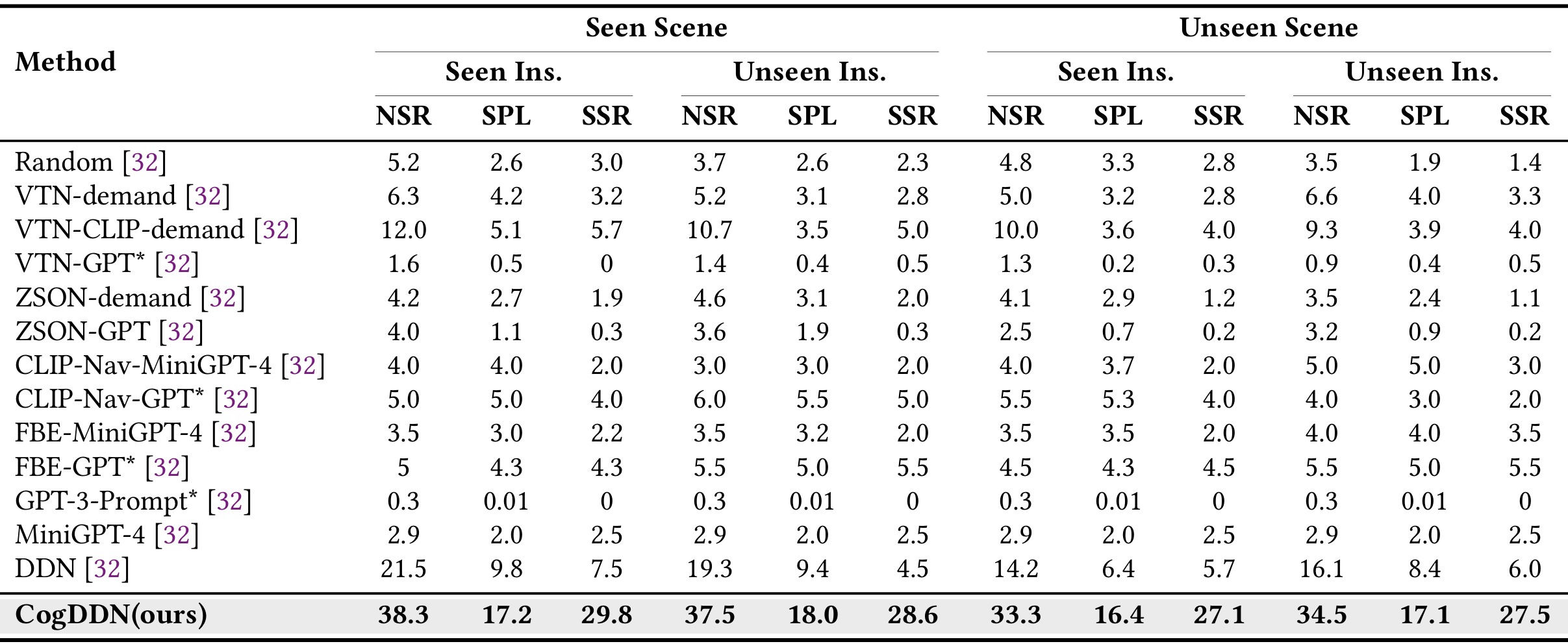
- 评估指标:使用导航成功率(NSR)、按路径长度加权的导航成功率(SPL)和选择成功率(SSR)三个指标来评估CogDDN的性能。
- 实验结果:
- 与单目相机方法对比:CogDDN在所有单目相机方法中表现最佳,与单目相机方法相比,性能提升了15%。
- 与SOTA方法对比:CogDDN在未见场景和未见指令上的性能与InstructNav相当,尽管InstructNav使用了深度图作为额外的输入,而CogDDN仅使用RGB图像。

消融研究
- 实验设置:
- Exploit模块:将Exploit模块替换为未经导航任务微调的GPT-4模型,分别在生成单步动作和完整动作序列的情况下进行评估。
- CoT推理:在启发式和分析过程中移除CoT推理,直接生成决策。
- 反思机制:通过多次迭代(每轮500个epoch),将反思机制生成的经验添加到知识库中,并对VLM进行微调。
- 实验结果:
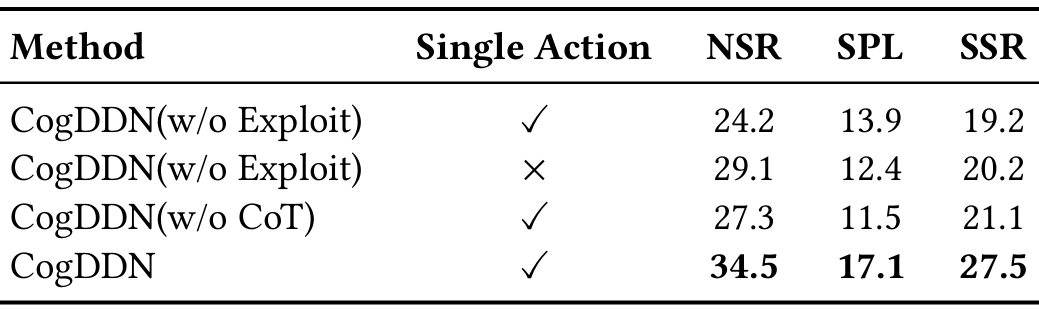
- Exploit模块:在未见场景和未见指令下,移除Exploit模块后,NSR从34.5%下降到24.2%(单步动作)和29.1%(完整动作序列),SPL从17.1%下降到13.9%(单步动作)和12.4%(完整动作序列),SSR从27.5%下降到19.2%(单步动作)和20.2%(完整动作序列)。
- CoT推理:移除CoT推理后,NSR从34.5%下降到27.3%,SPL从17.1%下降到11.5%,SSR从27.5%下降到21.1%。
- 反思机制:经过四轮迭代后,SSR和NSR有小幅提升,而SPL显著提升,表明反思机制通过学习经验,使系统能够更好地预测障碍并采取主动措施。
结论与未来工作
- CogDDN通过模拟人类注意力机制,选择性地关注满足用户需求的关键对象,并通过双过程决策模块和思维链(CoT)推理增强了决策过程。此外,知识库的积累使算法能够持续自我改进。
- CogDDN在闭环性能方面取得了显著的成果,同时所需的训练数据有限。然而,当前系统存在一些局限性,例如在探索模块中仅包含短期记忆,缺乏长期记忆来识别之前探索过的区域;使用GPT-4作为探索阶段的决策模块计算成本较高,不适合实际部署;并且在知识库中添加新经验时,需要对启发式过程进行监督微调,导致效率低下。
- 未来的工作将致力于设计一个包含长期记忆和端到端的新系统,以进一步提升CogDDN的性能和实用性。
