论文阅读:AAAI 2024 ExpeL: LLM Agents Are Experiential Learners
https://www.doubao.com/chat/15518976100960770
https://ojs.aaai.org/index.php/AAAI/article/view/29936
Advances and Challenges in Foundation Agents–Memory调研
论文翻译
ExpeL: 大型语言模型代理是经验学习者
摘要
最近,利用大型语言模型(LLMs)中蕴含的丰富世界知识来解决决策任务的研究兴趣激增。虽然针对特定决策任务定制大型语言模型的需求日益增长,但为特定任务微调这些模型不仅耗费资源,还可能降低模型的泛化能力。此外,像GPT-4和Claude这样的最先进语言模型主要通过API调用访问,其参数权重仍为专有信息,不向公众开放。这种情况凸显了对新方法的迫切需求,即无需参数更新就能从代理经验中学习。为解决这些问题,我们提出了经验学习(ExpeL)代理。该代理能自主收集经验,并从一系列训练任务中用自然语言提取知识。在推理阶段,代理会回忆提取的见解和过去的经验,以做出明智的决策。我们的实证结果凸显了ExpeL代理强大的学习效能,表明其性能随着经验的积累而持续提升。我们还通过定性观察和额外实验,进一步探索了ExpeL代理的新兴能力和迁移学习潜力。
1 引言
汤姆·米切尔(Tom Mitchell)曾说:如果一个计算机程序在某类任务T上的性能(由性能指标P衡量)随着经验E的增加而提高,那么就可以说该程序从经验E中学习。
长期以来,机器学习研究一直被自主代理及其能力所吸引。近年来,将大型语言模型融入这些代理(Wang等人,2023a;Xi等人,2023)已经揭示了广泛的应用,甚至超出了学术界的范围(Yang等人,2023a;Significant-Gravitas,2023)。大型语言模型的一个显著优势在于其拥有的世界知识,这使得它们在各种场景中本质上具有通用性(Zhao等人,2023b)。
一方面,先前的研究通过大量环境交互(Yao等人,2023c)或大量人类标记数据集(Nakano等人,2021;Shaw等人,2023)来微调大型语言模型。这类方法计算成本高,并且需要访问大型语言模型的参数权重。此外,微调大型语言模型会限制其功能,并可能损害其泛化能力(Du等人,2022)。另一方面,提示方法只需几个上下文示例,就能增强大型语言模型的顺序决策规划能力(Hao等人,2023;Lin等人,2023b;Sun等人,2023)。然而,由于当前的大型语言模型受限于上下文窗口大小(Tworkowski等人,2023),这些代理无法记住它们所见过的内容,因此除了少数演示之外,无法进行学习。那么,我们如何在这些范式之间取得平衡呢?
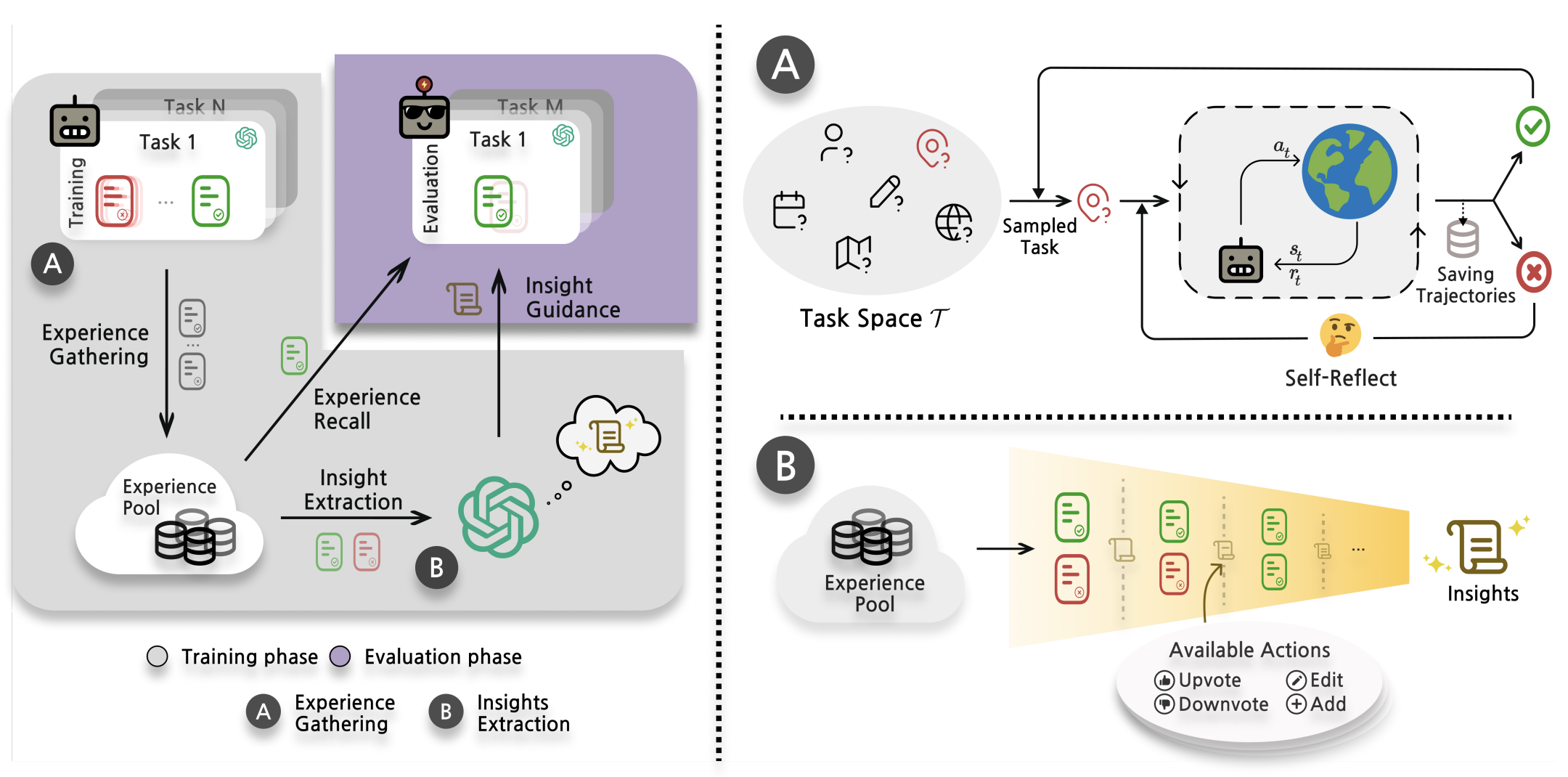
我们提出经验学习(ExpeL)代理作为解决方案。我们的代理通过试错从一系列训练任务中自主收集经验。从这些经验中,它提炼出自然语言见解,并在测试时将自己的成功经验作为上下文示例。我们代理的学习过程类似于学生为考试学习,然后一次性参加考试,这反映了许多现实世界的情况。与Refexion(Shinn等人,2023)等自我改进方法不同,我们的方法强调在多个任务中保留经验对提高代理性能的重要性。此外,ExpeL无需参数更新即可学习,这使其与GPT-4或Claude等强大的闭源模型兼容。最后,经验收集步骤不需要大量数据或人类标签。
我们在三个截然不同的领域对ExpeL进行了评估,其性能始终优于强大的基线模型。此外,我们展示了一个迁移学习场景,即从源任务中积累知识的代理对目标任务表现出积极的前向迁移。最后,我们强调了ExpeL代理获得的一些意想不到的新兴能力。
总之,我们的主要贡献如下:(1)我们提出了ExpeL,这是一种新型的大型语言模型代理,能够在无需梯度更新的情况下自主从经验中学习;(2)我们在一系列不同的任务上对ExpeL进行了评估,以展示其学习能力以及在现有规划方法基础上的改进;(3)我们为我们的大型语言模型代理展示了一种新颖的迁移学习设置,并证明了从源任务到目标任务的前向迁移能力。最后,我们相信,随着规划算法和基础模型的不断改进,ExpeL范式将从它们的性能提升中获得显著收益。