【机器学习深度学习】微调训练数据质量
目录
前言
一、为什么数据质量评估很重要
二、数据质量评估的核心维度
三、数据质量的可量化维度(必须要测的指标)
四、多答案、多类型数据的取舍与优化
场景 A:一个问题有多个相似回答
场景 B:多个类型数据,每个类型内有不同问题和回答
五、可视化案例与实用指标
① 样本类型占比
② 问题相似度热力图
③ 回答多样性散点图
六、实践建议与结论
前言
在大模型的微调过程中,数据质量往往决定了模型的上限。
无论是 ChatGPT 的指令微调(Instruction Tuning),还是垂直领域的定制化训练,数据质量评估都是确保模型产出稳定、高质量输出的核心步骤。
本文将从以下几个方面探讨数据质量评估的思路与方法,并给出可视化建议,帮助你更好地理解和优化微调数据:
为什么数据质量评估很重要
数据质量评估的核心维度
多答案、多类型数据的取舍与优化
可视化案例与实用指标
实践建议与结论
一、为什么数据质量评估很重要
很多人在微调时更关注模型结构和参数配置,但忽略了数据的多样性、一致性和覆盖度。
结果是:
训练集存在重复样本,导致模型过拟合某种回答风格
问题和答案风格不一致,模型学习到的知识片段化
某些类型数据比例过高,模型在不平衡领域表现糟糕
💡 一句话总结:数据质量差,微调模型会“带病上岗”。
二、数据质量评估的核心维度
我们可以将微调数据质量拆解为 覆盖度、准确性、一致性、平衡性、多样性 五个维度:
| 维度 | 说明 | 常用指标 |
|---|---|---|
| 覆盖度 | 数据是否覆盖任务的核心场景 | 类型数量、关键词覆盖率 |
| 准确性 | 问题-回答是否事实正确、逻辑严谨 | 人工标注准确率 |
| 一致性 | 同类问题回答风格是否统一 | BLEU/ROUGE 相似度、风格检测 |
| 平衡性 | 各类型数据是否均衡 | 样本比例统计 |
| 多样性 | 是否避免千篇一律的表达 | Embedding 去重率、回答变体比例 |
为什么该花力气做数据质量?
任务对齐:数据描述的场景和模型使用场景高度一致。
准确性 & 可靠性:答案真实、逻辑通顺、无常识性错误。
一致性 & 风格可控:同一类任务输出风格统一、用词规范。
覆盖度 & 平衡:覆盖常见核心情形,同时避免单类过采样导致偏见。
多样性但低冗余:既要多样化表现,又要去掉低价值重复项。
安全合规:无有害、敏感或违法内容;满足隐私/合规需求。
三、数据质量的可量化维度(必须要测的指标)
-
覆盖度:类型数、每类样本数量、关键意图覆盖率(按标签或关键词统计)。
-
准确率(自动/人工):Human-in-the-loop 标注准确率(目标 > 95% 对于高风险域),自动事实校验通过率(如果可行)。
-
一致性:同题/同意图下回答风格一致性,计算方法:BLEU/ROUGE/embedding-similarity 的类内方差或 Cohen’s κ(多标签)。目标 κ > 0.6(可接受),> 0.75 很好。
-
冗余/重复率:重复样本占比(exact hash去重后),近重复比(基于embedding余弦 > 0.90)。目标:exact dup < 1–2%,近重复视场景控制在 5–15%。
-
多样性:Distinct-1/2(不同 n-gram 占比)、词汇覆盖率、嵌入空间覆盖面积(聚类数)。
-
噪声率:标签/答案错误的样本比例(人工抽样估计),高质量集目标噪声 < 3–5%。
-
可读性 / 质量分:语法/逻辑分(自动语言检查)或 LM-based quality score(用教师模型对答案打分,低于阈值的人工审查)。
-
类别平衡度:每类样本占比与目标分布的 KL 散度或最大/最小比例比值(例如任何类都不低于总体的 1% 或绝对样本数不低于 N)。
-
安全性检测通过率:毒性/敏感/隐私泄露检测器通过率(目标 100%)。
四、多答案、多类型数据的取舍与优化
你提到的两个典型场景:
场景 A:一个问题有多个相似回答
-
优点:提升模型生成的多样性,避免固定输出
-
风险:如果回答差异过小,可能增加训练冗余
-
优化建议:
-
确保每个回答不仅换措辞,还能补充信息或体现不同思路
-
对相似度过高的回答进行合并(可用嵌入余弦相似度过滤)
-
场景 B:多个类型数据,每个类型内有不同问题和回答
-
优点:提升模型的任务覆盖度,防止偏科
-
风险:比例失衡会导致某类任务表现下降
-
优化建议:
-
用类型占比直方图分析比例,必要时欠采样/过采样
-
每类问题要覆盖易、中、难不同层次
-
📌 取舍建议
-
如果目标是对话多样性 → 场景 A 更优,但需去冗余
-
如果目标是任务覆盖全面 → 场景 B 更优,但需平衡比例
-
最佳做法:结合两者,在类型均衡的前提下引入多样化回答
五、可视化案例与实用指标
在评估数据质量时,可视化工具能帮助快速发现问题。
① 样本类型占比
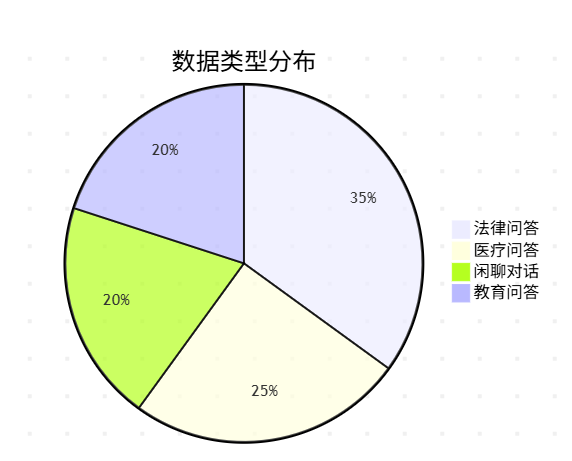
👉 一眼看出比例是否失衡
② 问题相似度热力图
利用文本嵌入(如 text-embedding-ada-002)计算问题之间的相似度:
颜色越深 → 问题越相似 → 冗余度高
可用 Seaborn 绘制热力图来直观发现重复问题簇。
③ 回答多样性散点图
-
横轴:回答相似度
-
纵轴:回答长度
-
目的:发现既短又重复的回答(低价值样本)
六、实践建议与结论
-
先清洗再扩充:去除错误样本和重复样本,再做多样化增强
-
保持比例平衡:尤其在多类型任务中
-
人工抽检不可少:指标+可视化+人工三结合
-
持续迭代:微调不是一次性任务,数据优化是长期工程
🎯 最终结论:
数据质量评估不仅是“选好数据”,更是“优化数据结构”。
多答案和多类型数据没有绝对好坏,取决于你的训练目标,但必须有量化指标和可视化手段来确保质量可控。