VLMEvalKit使用记录
背景:最近在做MLLM(其实主要是VLM)的预训练,需要用一些主流的benchmark测试一下性能,就看到了这个工具
codebase:https://github.com/open-compass/VLMEvalKit
简介:OpenCompass开源的一个评测工具包,专门用于VLM的评测。OpenCompass的含金量不多阐述了,上海ai lab(想到了openmmlab的一些mmdetection这种时代的眼泪 哎)
使用:
1.配置环境:
创建一个conda环境然后基础三步
git clone https://github.com/open-compass/VLMEvalKit.git
cd VLMEvalKit
pip install -e .这里以最新的qwen2.5-vl-7b-instruct模型为例,选MMBench_DEV_EN这个评测集
python run.py --data MMBench_DEV_EN --model Qwen2.5-VL-7B-Instruct --verbose会自动下载MMBench_DEV_EN这个数据集
[2025-08-05 19:27:00] ERROR - misc.py: load_env - 215: Did not detect the .env file at /VLMEvalKit/.env, failed to load.
[2025-08-05 19:28:04] ERROR - misc.py: load_env - 215: Did not detect the .env file at /VLMEvalKit/.env, failed to load.
[2025-08-05 19:28:04] WARNING - RUN - run.py: main - 217: --reuse is not set, will not reuse previous (before one day) temporary files
MMBench_DEV_EN.tsv: 20%|█████████████▏ | 7.45M/37.2M [00:11<00:46, 640kB/s]
[2025-08-05 19:28:16] WARNING - file.py: download_file - 220: <class 'urllib.error.ContentTooShortError'>: <urlopen error retrieval incomplete: got only 7454261 out of 37156625 bytes>
[2025-08-05 19:28:16] ERROR - RUN - run.py: main - 481: Model Qwen2.5-VL-7B-Instruct x Dataset MMBench_DEV_EN combination failed: Failed to download https://opencompass.openxlab.space/utils/benchmarks/MMBench/MMBench_DEV_EN.tsv, skipping this combination.网断了一次哈哈(展示容错)
重新再提交命令,好处是知道她check的路径了
python run.py --data MMBench_DEV_EN --model Qwen2.5-VL-7B-Instruct --verbose
[2025-08-05 19:35:42] WARNING - RUN - run.py: main - 217: --reuse is not set, will not reuse previous (before one day) temporary files
/VLMEvalKit/vlmeval/dataset/image_base.py:99: UserWarning: The tsv file is in /home/xxx/LMUData, but the md5 does not match, will re-download那么我只要根据第一次log里的url进行数据集下载,放在第二个log里的路径/home/xxx/LMUData
就可以直接load了,不用在线下载文件了(适合那种网不稳定的,比如我,每次下载都会断)
数据集搞定后,正常要load模型了,模型理论上也会在线下载
preprocessor_config.json: 100%|███████████████████████████████████████████████████████████████| 350/350 [00:00<00:00, 3.41MB/s]
The image processor of type `Qwen2VLImageProcessor` is now loaded as a fast processor by default, even if the model checkpoint was saved with a slow processor. This is a breaking change and may produce slightly different outputs. To continue using the slow processor, instantiate this class with `use_fast=False`. Note that this behavior will be extended to all models in a future release.
tokenizer_config.json: 5.70kB [00:00, 34.1MB/s]
vocab.json: 2.78MB [00:01, 1.60MB/s]
merges.txt: 1.67MB [00:00, 2.47MB/s]
tokenizer.json: 7.03MB [00:01, 4.68MB/s]
You have video processor config saved in `preprocessor.json` file which is deprecated. Video processor configs should be saved in their own `video_preprocessor.json` file. You can rename the file or load and save the processor back which renames it automatically. Loading from `preprocessor.json` will be removed in v5.0.
chat_template.json: 1.05kB [00:00, 1.67MB/s]
config.json: 1.37kB [00:00, 10.7MB/s]
model.safetensors.index.json: 57.6kB [00:00, 203MB/s]
Fetching 5 files: 0%| | 0/5 [00:00<?, ?it/s]
model-00002-of-00005.safetensors: 0%| | 0.00/3.86G [00:00<?, ?B/s]
model-00001-of-00005.safetensors: 0%| | 0.00/3.90G [00:00<?, ?B/s]
model-00005-of-00005.safetensors: 0%| | 0.00/1.09G [00:00<?, ?B/s]
model-00003-of-00005.safetensors: 0%| | 0.00/3.86G [00:00<?, ?B/s]
model-00004-of-00005.safetensors: 0%| | 0.00/3.86G [00:00<?, ?B/s]在这里我还是因为网络原因,提前下载好了权重,放在某个路径中,我不想在线下载,怎么做呢?打开VLMEvalKit/vlmeval/config.py
找到
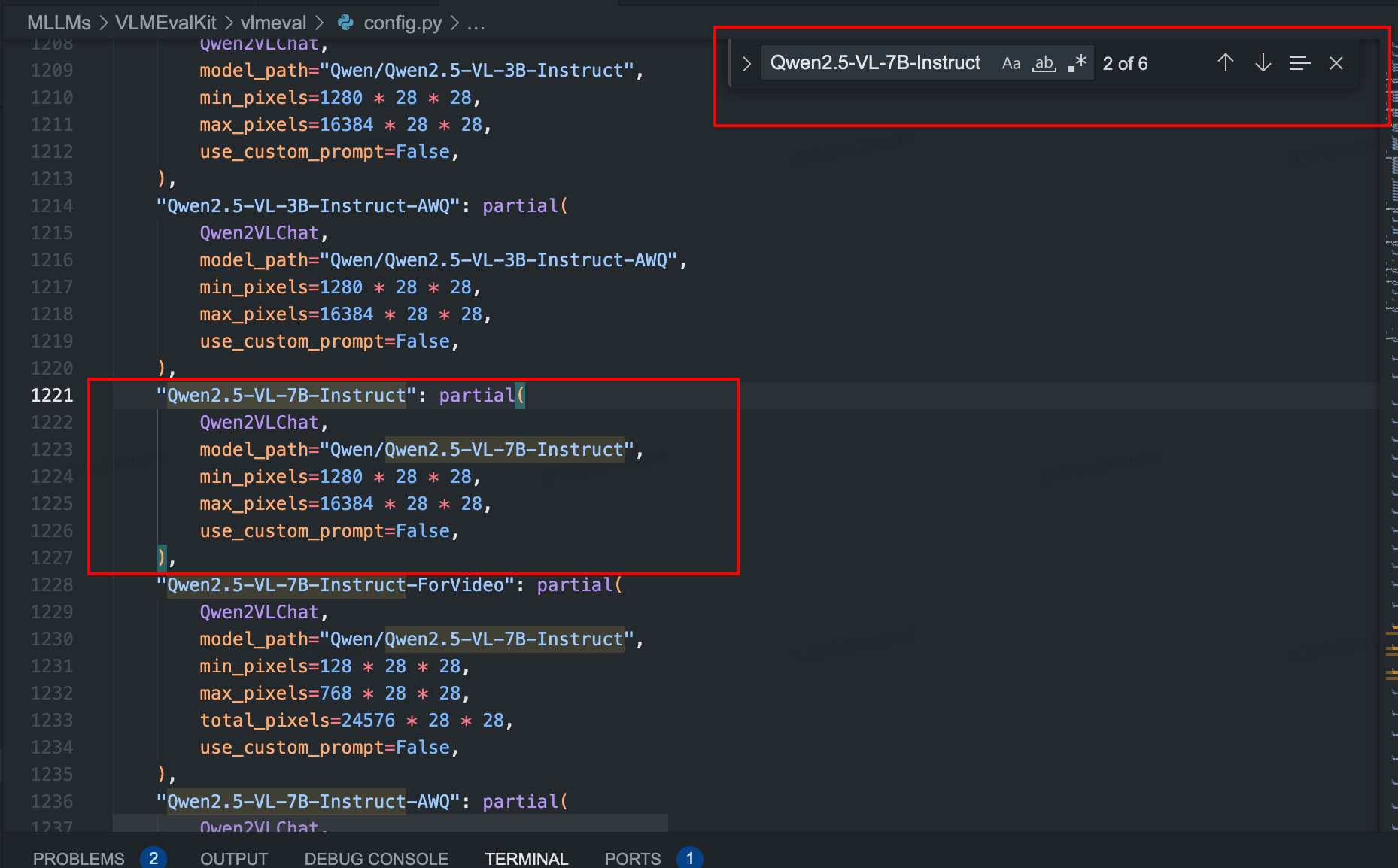
把里面的model_path改成本地的绝对路径,然后再重新执行命令,报了flash-attn not install的错(估计是qwen2.5vl需要的,不在requirement.txt里)
#1.
#2. flash-attn
pip install flash-attn --no-build-isolationflash-attn挺难装的,需要编译,有一些错误,遇到一堆问题后最终还是完成了,主要就确保gcc、glicb版本,然后装对应的cuda版本的torch,然后装对应的flash-attn轮子,编译有问题就一个个解决,耐心点。
然后再执行
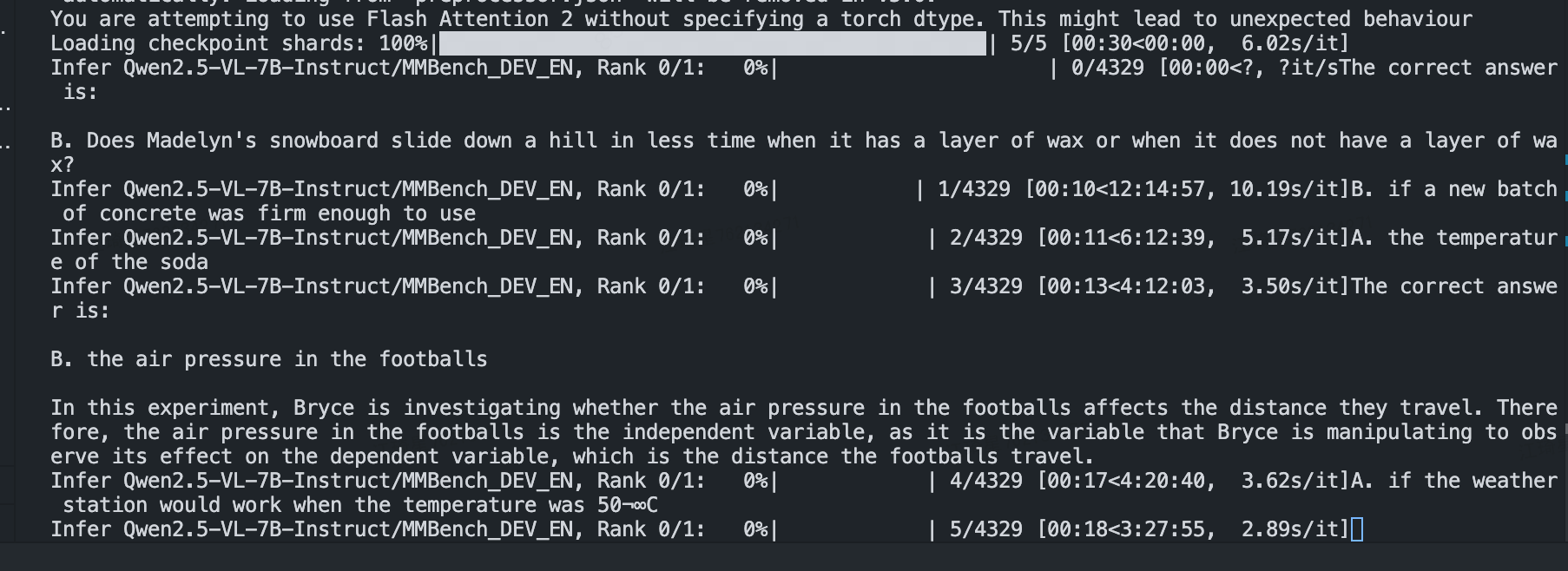
python run.py --data MMBench_DEV_EN --model Qwen2.5-VL-7B-Instruct --verbose
发现推理起来了,ok!等推理完测评再继续更新。
2.参数解释
首先是两个最重要的--data和--model,指定评测集和模型

--model还好,可以从代码里搜到,但是评测集--data有点麻烦,得找到对应版本的仓库的README.md。原本我打算从vlmeval/dataset/__init__.py找对应数据集的name,
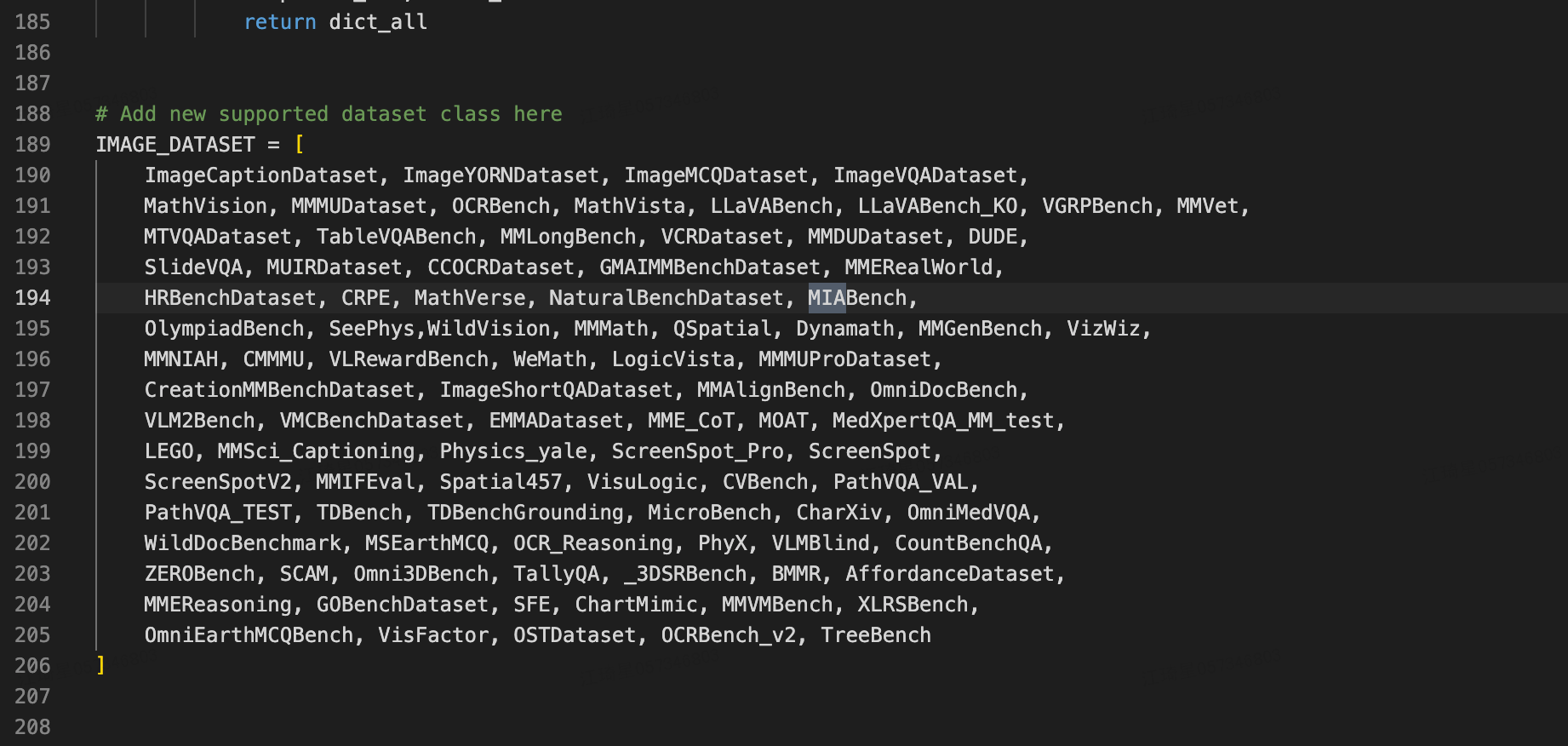
比如MIA_Bench猜测对应的就是MIABench这个name,但是输入命令行--data MIABench后发现 不对(实际上是MIA-Bench)
所以其实还是要从Docs 去看
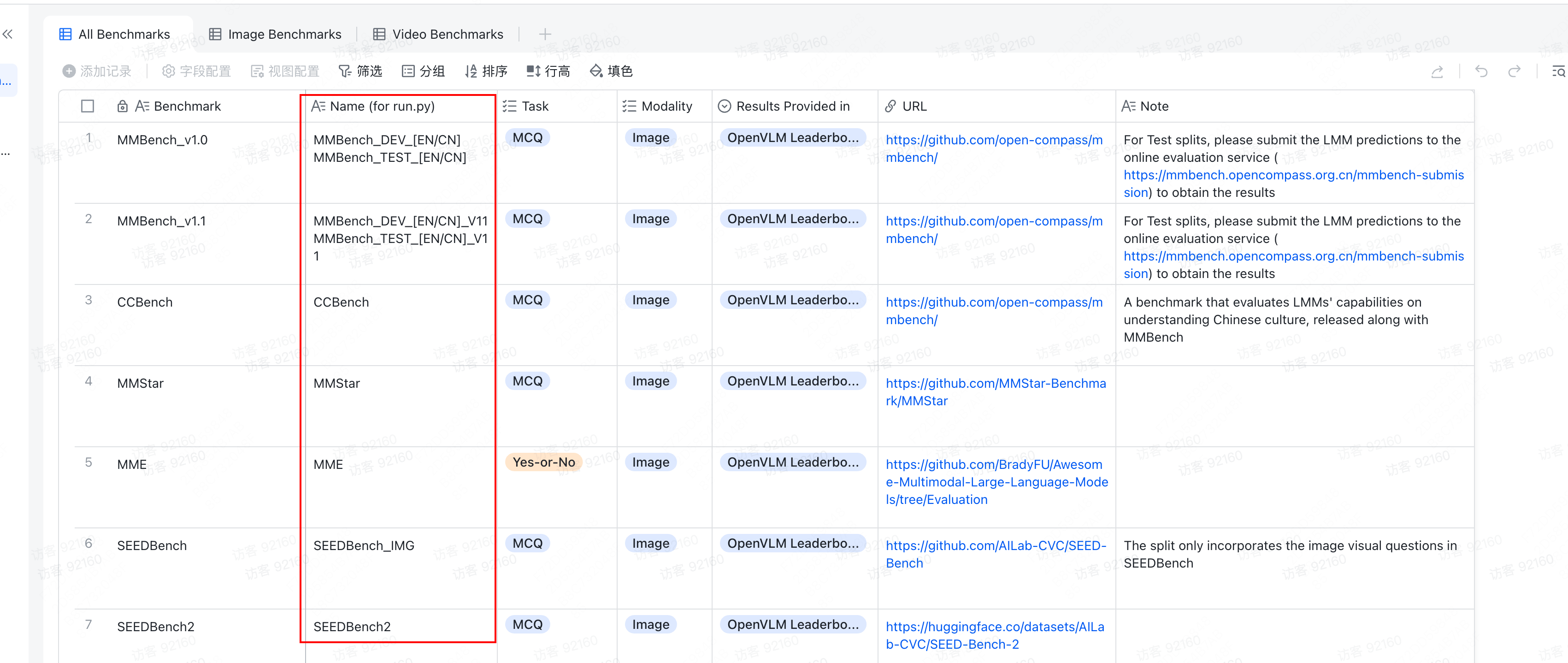
----停更----------