C++位图(Bitmap)与布隆过滤器(Bloom Filter)详解及海量数据处理应用

目录
一、位图
1. 基本概念
2.位图三大核心内容
(1).置1
(2).置0
(3).判断在不在
(4)以上代码的总代码
二、布隆过滤器
1. 基本原理
2.原理
(1)插入
(2)查找
(3)删除
三、海量数据处理
1、哈希切分
2、面试题
(1)给一个超过100G大小的logfile,log中存着IP地址,设计算法找到出现次数最多的IP地址/出现最多的K个地址?
编辑
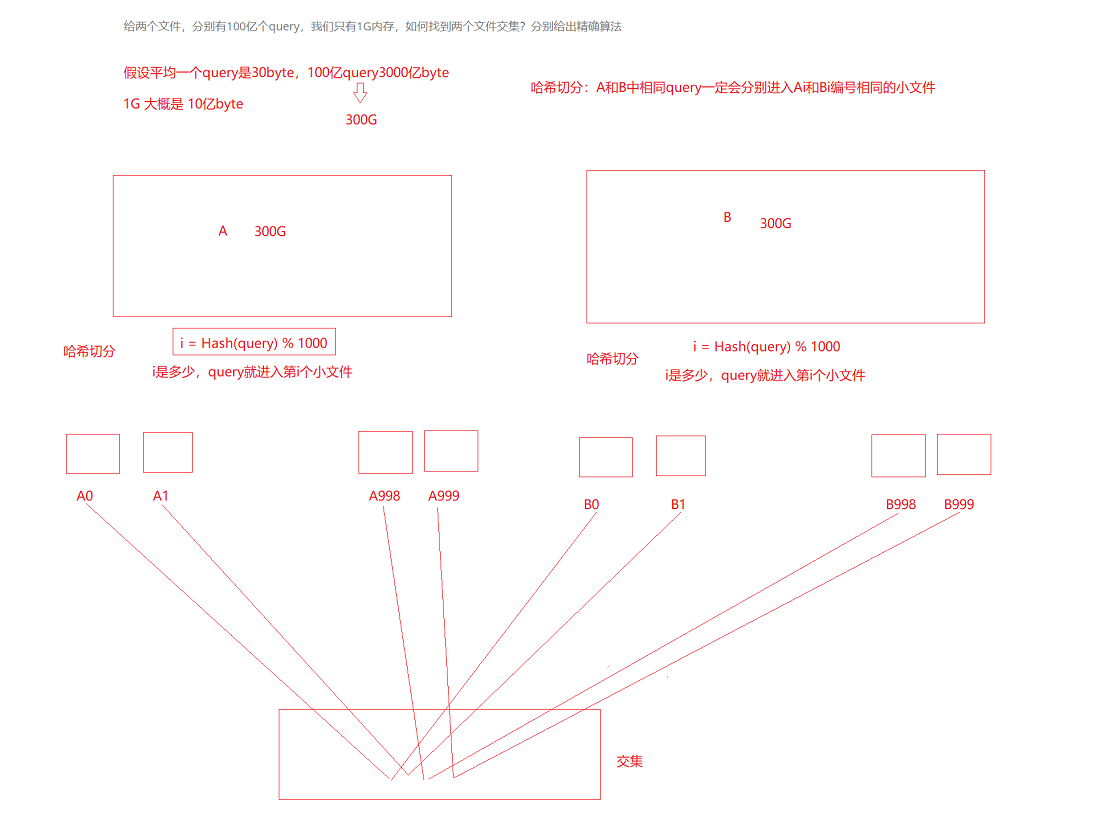
(2)给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法
(3)给定100亿个整数,设计算法找到只出现一次的整数?
(4)给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
编辑
(5)位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
一、位图
1. 基本概念
位图是一种使用bit位来存储数据状态的紧凑数据结构,每个bit位代表一个元素是否存在
我们以int来举例!!!,一个int有4个字节,一个字节有8个比特位,我们可以用一个比特位来映射一个值,比特位上的1或0来表示该数值在不在,1表示该数值在,0则表示该数值不在
怎么知道映射的位置在哪呢?
我们用一个int的数组_set来储,一个int数组有32个比特位,怎么知道数值为pos值的位置在哪呢?
int x=pos/32,得出pos位于_set[x]中
int y=pos%32,得出pos位于_set[x]中的第几位
2.位图三大核心内容
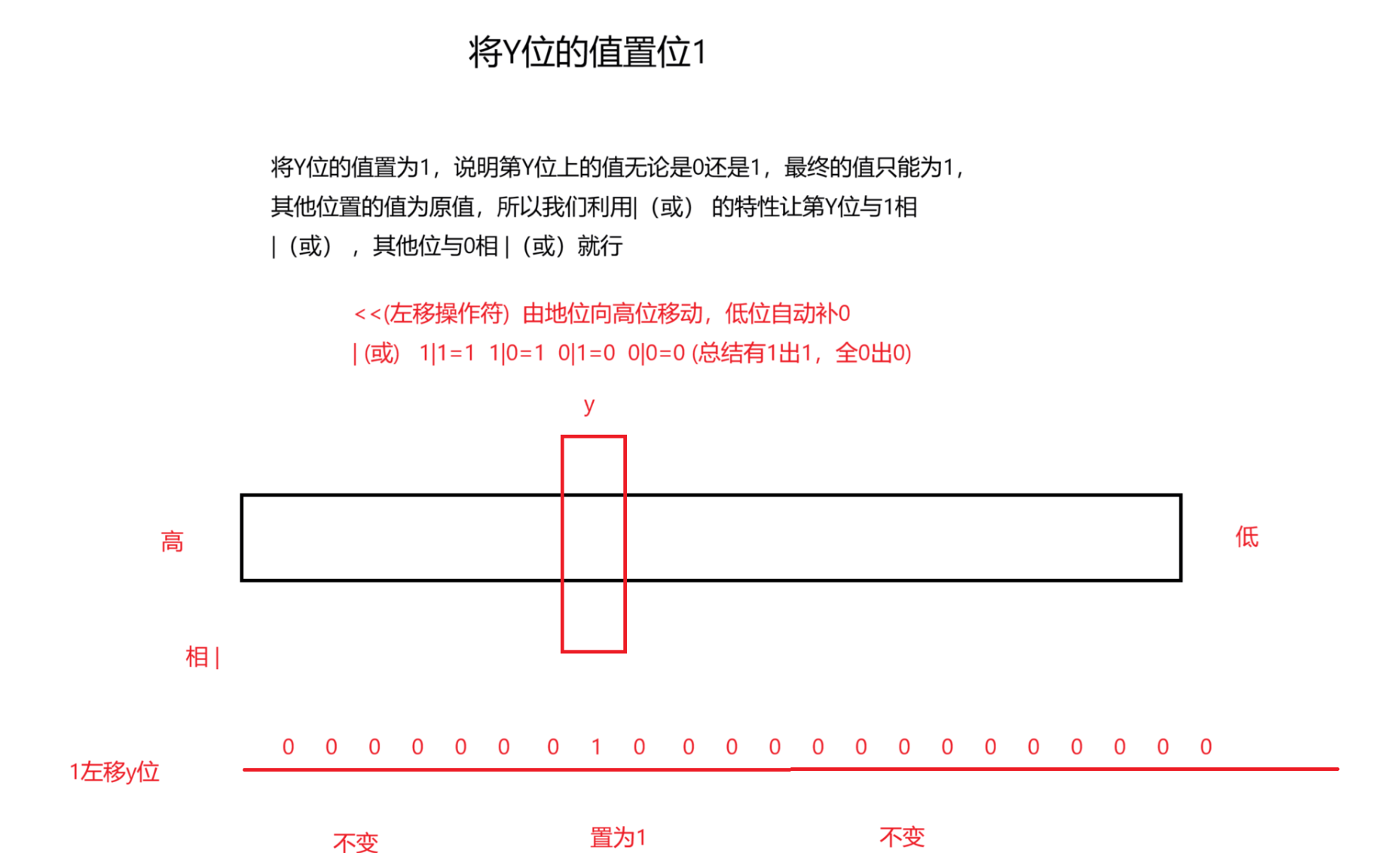
(1)置1
代码:
//1.第x位设置为1
void set(size_t x)
{//32是in有4个字节,然后一个字节=8个比特size_t i = x / 32;size_t j = x % 32;//这个~是位的取反_a[i] |= (1 << j);
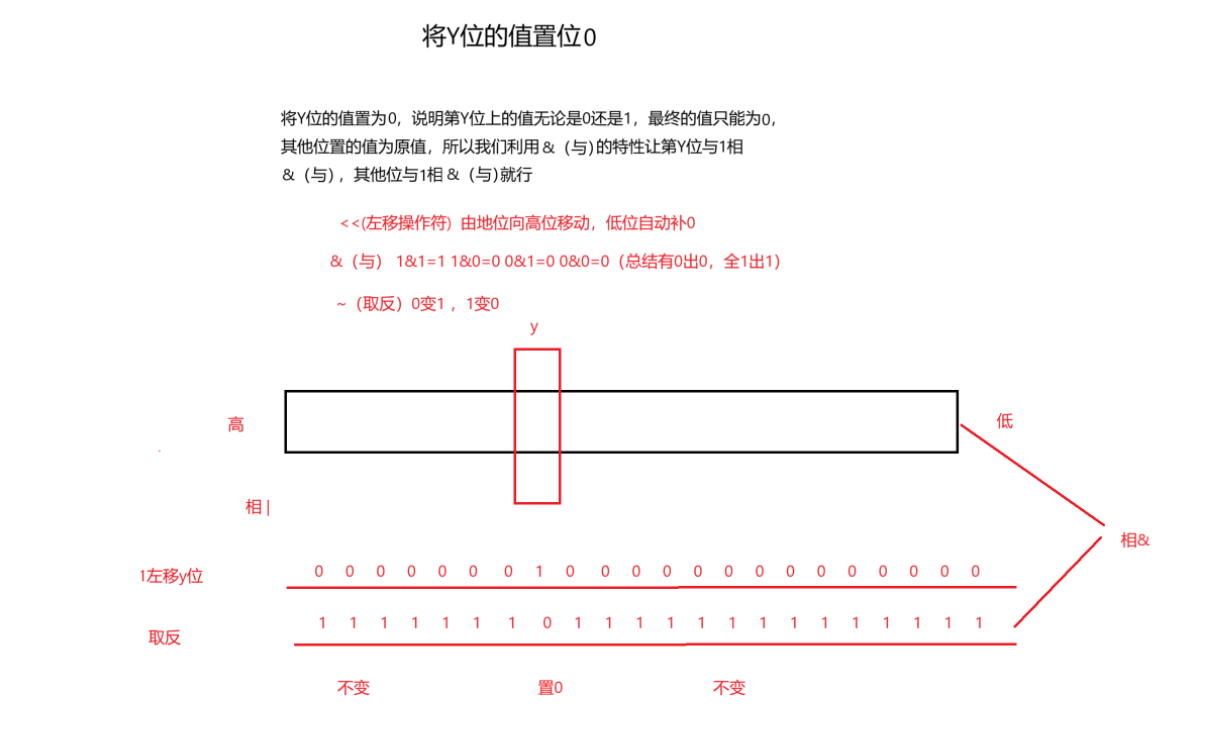
}(2)置0
代码:
//2.第x位设置为0
void reset(size_t x)
{//32是in有4个字节,然后一个字节=8个比特size_t i = x / 32;size_t j = x % 32;//这个~是位的取反_a[i] &= ~(1 << j);
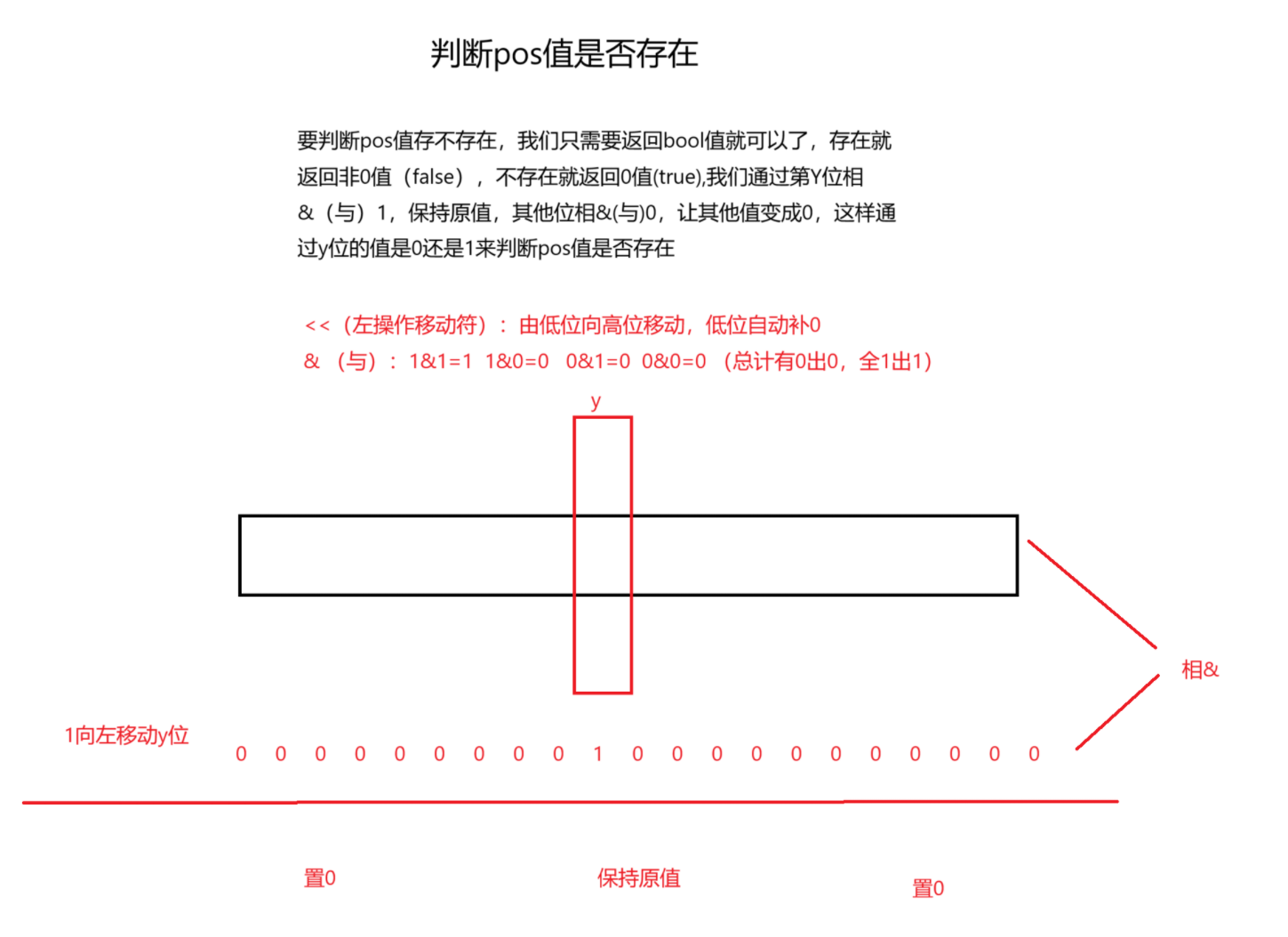
}(3)判断在不在
代码:
//3.检查第x位是否为1
bool test(size_t x)
{//判断这个位在不在size_t i = x / 32;size_t j = x % 32;//这个~是位的取反return _a[i] & (1 << j);
}(4)以上代码的总代码
namespace tyx
{template<size_t N>class bitset{public:bitset(){_a.resize(N / 32 + 1);}//1.第x位设置为1void set(size_t x){//32是in有4个字节,然后一个字节=8个比特size_t i = x / 32;size_t j = x % 32;//这个~是位的取反_a[i] |= (1 << j);}//2.第x位设置为0void reset(size_t x){//32是in有4个字节,然后一个字节=8个比特size_t i = x / 32;size_t j = x % 32;//这个~是位的取反_a[i] &= ~(1 << j);}//3.检查第x位是否为1bool test(size_t x){//判断这个位在不在size_t i = x / 32;size_t j = x % 32;//这个~是位的取反return _a[i] & (1 << j);}private:vector<int> _a;};};
二、布隆过滤器
1. 基本原理
布隆过滤器是位图的扩展,使用多个哈希函数来减少冲突概率。
2.原理
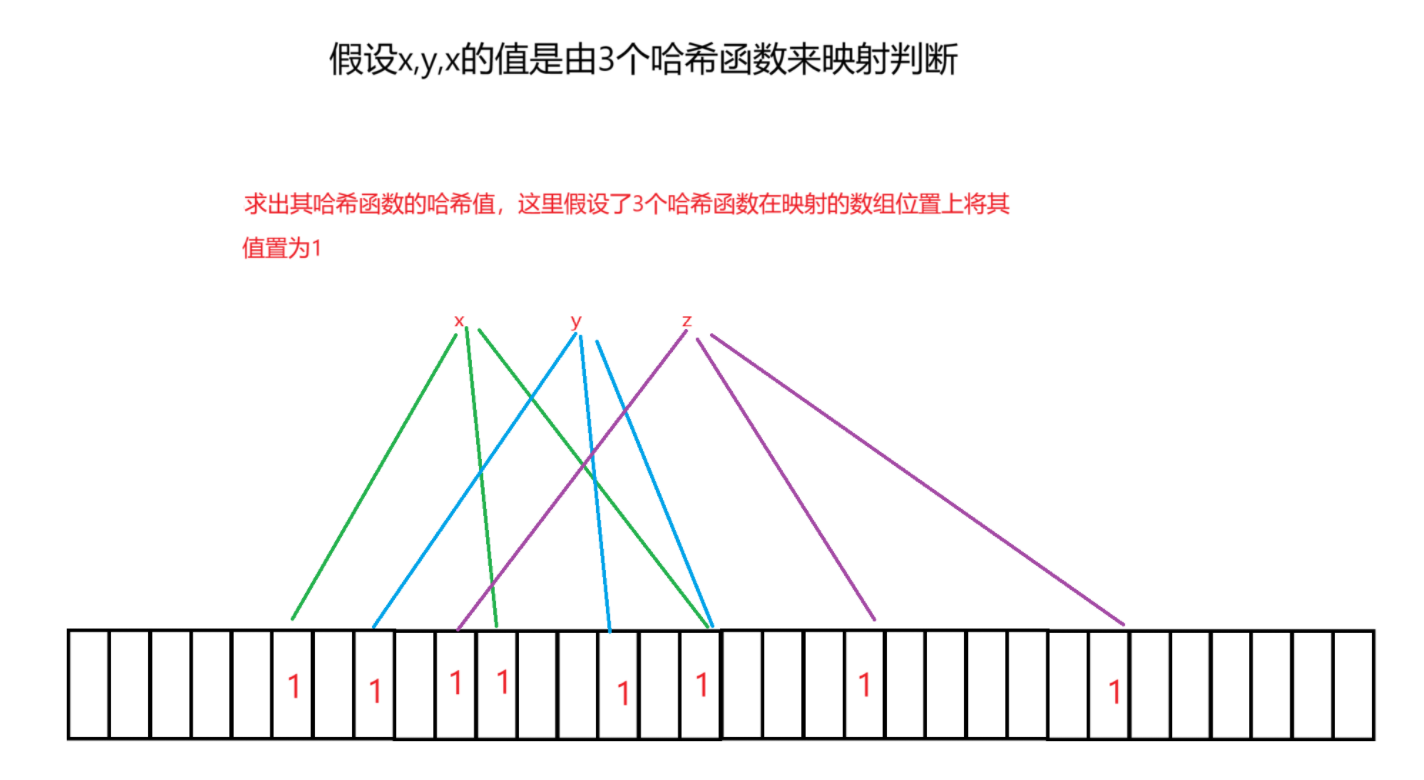
(1)插入
(2)查找
布隆过滤器是将哈希函数的哈希值映射到一个位图中,因此映射到的位图的位置一定为1,根据该值所有哈希函数映射到的位置是否全为1来(粗略)判断该值在不在,如果不是全为1(含0),那么这个值一定是不存在的,如果全为1那也不一定存在,以为其他的值的哈希函数也有可能映射到相同的位置,造成误判所以我们需要进入数据库进一步判断(这就体现了布隆过滤器的作用:减缓了数据库的压力)
(3)删除
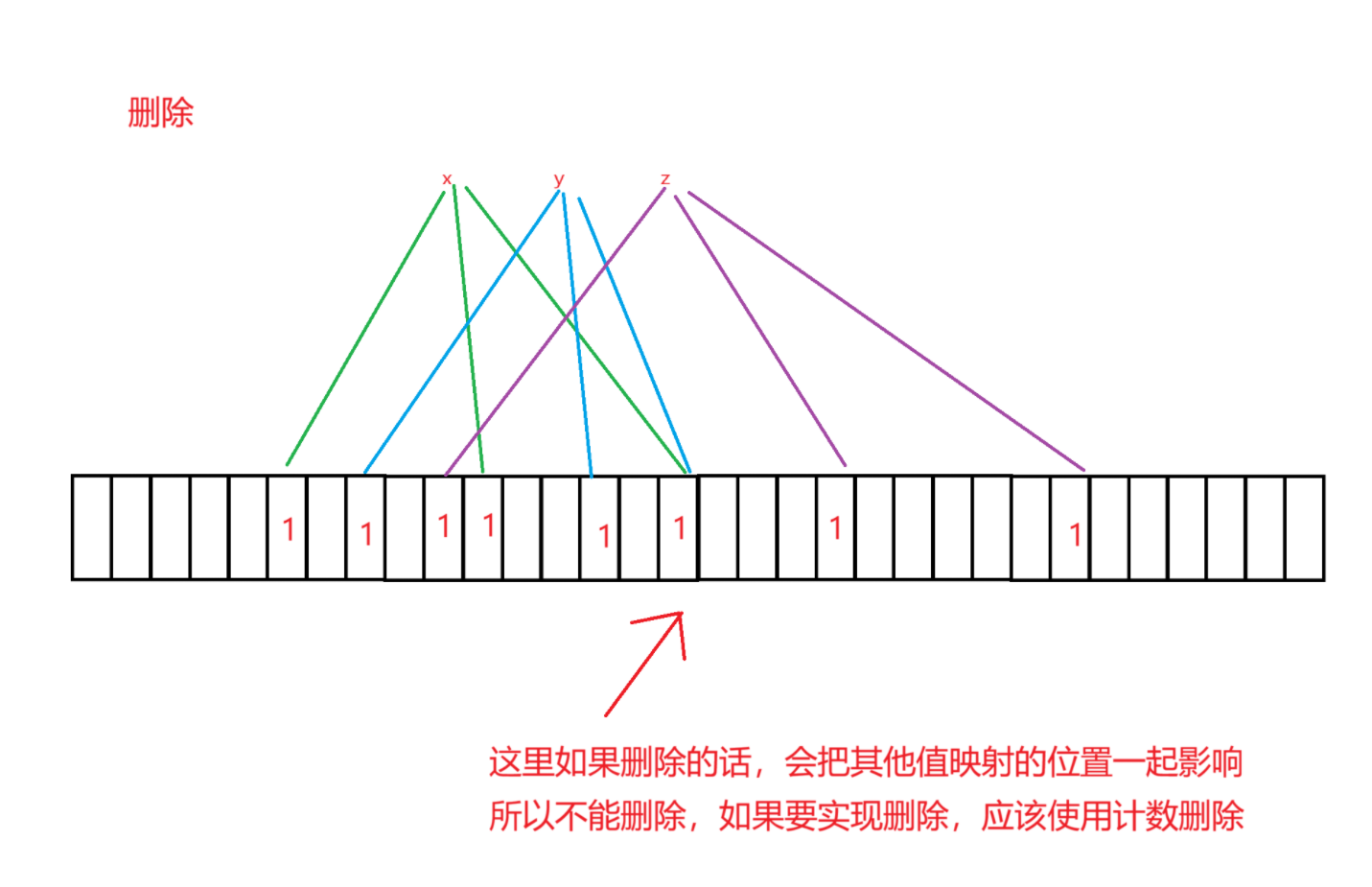
计数布隆过滤器(简略概述)
在映射的位置进行计数,映射一次就++,删除的时候就--,当值为0的时候就被删除掉了
三、海量数据处理
1、哈希切分
将一个文件切成n个,如果要在多个文件中寻找相交集的query,直接找从相同序号的小文件里找,而不要全部去遍历,节省了空间
2、面试题
(1)给一个超过100G大小的logfile,log中存着IP地址,设计算法找到出现次数最多的IP地址/出现最多的K个地址?

(2)给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法

(3)给定100亿个整数,设计算法找到只出现一次的整数?

大致思路: 先准备好两个位图 bitset1 bitset2 ,然后出现0次 bitset1和bitset2的值为0,出现1次的让bitset1的值为0 bitset2的值为1 ,出现两次及以上则让 bitser1的值为1,bitset2的值为1
(4)给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?

(5)位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数

