[论文阅读] 人工智能 + 软件工程 | 大型语言模型与静态代码分析工具:漏洞检测能力大比拼
大型语言模型与静态代码分析工具:漏洞检测能力大比拼
论文:Large Language Models Versus Static Code Analysis Tools: A Systematic Benchmark for Vulnerability Detection
arXiv:2508.04448
Large Language Models Versus Static Code Analysis Tools: A Systematic Benchmark for Vulnerability Detection
Damian Gnieciak, Tomasz Szandala
Subjects: Software Engineering (cs.SE)
一段话总结:
本研究对三种行业标准静态代码分析工具(SonarQube、CodeQL、SnykCode)和三种大型语言模型(GPT-4.1、Mistral Large、DeepSeek V3)在漏洞检测方面进行了系统对比。通过10个含63个漏洞的真实C#项目测试,发现LLMs的平均F1分数(0.797、0.753、0.750)显著高于静态工具(0.260、0.386、0.546),优势源于更强的召回率和跨代码上下文推理能力。但LLMs存在误报率高(如DeepSeek V3)、漏洞定位不精确(因分词问题)等问题,静态工具则更可靠但召回率有限。研究建议采用混合流程:开发早期用LLMs进行广泛分诊,关键验证阶段用静态工具。
研究背景
在现代软件开发中,代码漏洞就像隐藏在大楼里的安全隐患,稍不注意就可能被黑客利用。长期以来,开发者依靠静态代码分析工具(比如SonarQube、CodeQL)作为"第一道防线",它们能像安检仪一样,按照预设规则扫描代码中的问题。
但这些传统工具存在明显短板:就像只会检查固定类型行李的安检仪,面对新出现的漏洞模式常常"视而不见",还会频繁发出错误警报(误报),让开发者疲于应对。
与此同时,大型语言模型(LLMs)如GPT-4.1等迅速崛起,它们像经验丰富的安全顾问,能通过"理解"代码上下文来判断漏洞。但人们对它们的实际能力充满疑问:它们真的比传统工具更靠谱吗?会不会因为"想太多"而产生新的问题?这正是本研究要解答的核心问题。
主要作者及单位信息
本文作者为Damian Gnieciak和Tomasz Szandala,均来自波兰弗罗茨瓦夫科技大学信息与通信技术学院。
创新点
- 首次系统性头对头对比:同时评估3种主流静态分析工具(SonarQube、CodeQL、SnykCode)和3种先进LLMs(GPT-4.1、Mistral Large、DeepSeek V3),填补了该领域对比研究的空白。
- 多维评估体系:不仅关注传统的检测准确率(精确率、召回率、F1分数),还纳入了开发者实际工作中关心的指标——分析耗时、验证真阳性所需的工作量,以及结果解释的质量。
- 实用导向的基准测试:发布了包含10个真实C#项目、63个漏洞的公开基准数据集,为后续研究提供了可复现的基础。
研究方法和思路
实验设计步骤
-
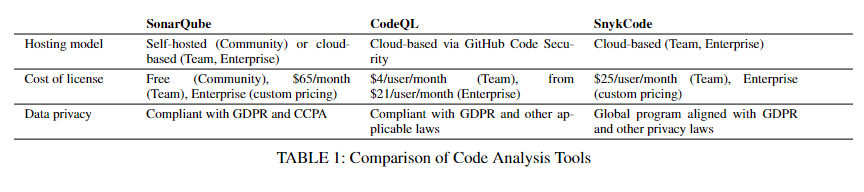
选择测试对象:
- 静态工具:SonarQube(老牌开源工具)、CodeQL(GitHub旗下,支持自定义规则)、SnykCode(结合机器学习的新型工具)。
- LLMs:GPT-4.1(大上下文窗口)、Mistral Large(平衡性能与成本)、DeepSeek V3(低成本选项)。
-
准备测试数据集:
精选10个C#项目,每个项目包含3-10个文件,字符数在3500-5500之间,嵌入了SQL注入、硬编码密钥、过时依赖等常见漏洞,共63个。 -
开发分析工具:
构建ProjectAnalyzer工具,自动将代码转换为适合LLMs的输入格式,接收模型输出后转换为标准化的SARIF报告(方便与静态工具结果对比)。 -
评估指标计算:
- 精确率:正确检测的漏洞占所有报告漏洞的比例。
- 召回率:正确检测的漏洞占实际总漏洞的比例。
- F1分数:精确率和召回率的调和平均数,综合反映检测能力。
- 执行时间:从开始分析到生成结果的耗时。
主要贡献
-
明确了两类工具的优劣势:
- LLMs在F1分数上显著领先(平均0.750-0.797),远超静态工具(0.260-0.546),优势源于更强的上下文推理能力,能发现跨文件的数据流漏洞。
- 静态工具更"稳重":SonarQube和CodeQL误报率最低,但召回率有限,容易漏掉复杂漏洞。
-
给出了实用的工具选择指南:
- 开发早期:用LLMs进行广泛筛查,利用其高召回率发现潜在问题。
- 关键验证阶段:用静态工具进行精确确认,减少误报带来的麻烦。
-
揭示了LLMs的关键局限:
- 定位不准:因分词机制问题,无法精确标注漏洞所在的行和列。
- 存在"幻觉":会虚构不存在的漏洞(如误报过时依赖)。
思维导图:

详细总结:
1. 研究背景与目的
- 现代软件依赖自动化工具检测漏洞,但静态代码分析工具(如SonarQube)存在误报和规则覆盖不足的问题;同时,大型语言模型(LLMs)在代码分析中展现潜力。
- 本研究旨在通过定量和定性分析,对比3种静态工具与3种LLMs的漏洞检测能力,为实践提供指导。
2. 研究对象
| 类型 | 工具/模型 | 关键特性 |
|---|---|---|
| 静态代码分析工具 | SonarQube | 支持30+语言,有社区版(免费)和付费版,误报率低 |
| CodeQL | 支持自定义查询,GitHub旗下,执行时间最长 | |
| SnykCode | 结合机器学习,侧重安全漏洞,FP率介于静态工具和LLMs之间 | |
| 大型语言模型 | GPT-4.1 | 上下文窗口1,047,576 tokens,F1分数最高(0.797) |
| Mistral Large | 上下文窗口32,000 tokens,平衡性能与成本 | |
| DeepSeek V3 | 成本低,误报率最高 |
3. 研究方法
- 数据集:10个C#项目,含3500-5500字符、3-10个文件,共63个漏洞(含SQL注入、硬编码密钥等)。
- 评估工具:ProjectAnalyzer,用于自动化分析并生成SARIF格式报告。
- 评估指标:精确率、召回率、F1分数( harmonic mean of 精确率和召回率)、执行时间、误报率。
4. 关键结果
-
性能对比(平均F1分数):
工具/模型 SonarQube CodeQL SnykCode GPT-4.1 Mistral Large DeepSeek V3 平均F1分数 0.260 0.386 0.546 0.797 0.753 0.750 -
执行时间:CodeQL最长(185-213秒),GPT-4.1最短(3.5-17.8秒)。
-
误报率:SonarQube、CodeQL最低;DeepSeek V3最高。
-
局限性:LLMs无法精确标注漏洞位置(因分词问题),存在幻觉(如误报过时依赖)。
5. 结论与建议
- LLMs在漏洞检测中表现优于静态工具,但误报和定位问题限制其独立用于安全关键审计。
- 建议混合流程:开发早期用LLMs进行广泛上下文感知分诊,关键阶段用静态工具进行高可信度验证。
- 未来方向:优化提示工程、开发混合解决方案。
关键问题:
-
问题:大型语言模型(LLMs)在漏洞检测中F1分数显著高于静态代码分析工具的主要原因是什么?
答案:LLMs的优势源于更强的召回率和跨代码上下文推理能力,能够识别传统静态工具依赖预定义规则难以覆盖的复杂、细微数据流缺陷,而静态工具受限于固定规则,对新或不常见漏洞识别能力较弱。 -
问题:在实际软件开发中,应如何根据场景选择静态代码分析工具或大型语言模型进行漏洞检测?
答案:对于安全关键审计(如医疗、金融系统),优先选择静态工具(如SonarQube、CodeQL),因其可靠性高、误报少;开发早期需快速广泛排查漏洞时,可使用LLMs(如GPT-4.1)进行上下文感知分诊;建议采用混合流程,结合两者优势。 -
问题:大型语言模型在漏洞检测中的主要局限性是什么,如何缓解?
答案:主要局限性包括:①误报率高(如DeepSeek V3);②漏洞定位不精确(因分词问题);③存在幻觉(如误报过时依赖)。缓解措施可包括:优化提示工程提升输出准确性,结合静态工具验证LLMs结果,开发混合模型融合两者优势。
总结
本研究通过严谨的实验对比发现,大型语言模型在代码漏洞检测中已能与传统静态分析工具抗衡,尤其在发现复杂漏洞方面更具优势,但误报率高和定位不精确的问题限制了其独立使用。
解决的核心问题:明确了LLMs和静态工具在漏洞检测中的适用场景,打破了"非此即彼"的选择困境。
主要成果:提出"早期用LLMs筛查+关键阶段用静态工具验证"的混合流程,为开发者提供了切实可行的代码安全检测方案,并发布了公开基准数据集供后续研究参考。