[AI 生成] 大数据数仓面试题
大数据数仓面试题
以下是针对大数据数仓岗位的高频面试题及深度解析,涵盖架构设计、建模方法、ETL优化和新技术应用,帮助您系统性备战:
一、数仓架构设计
1. 分层架构核心思想
图表
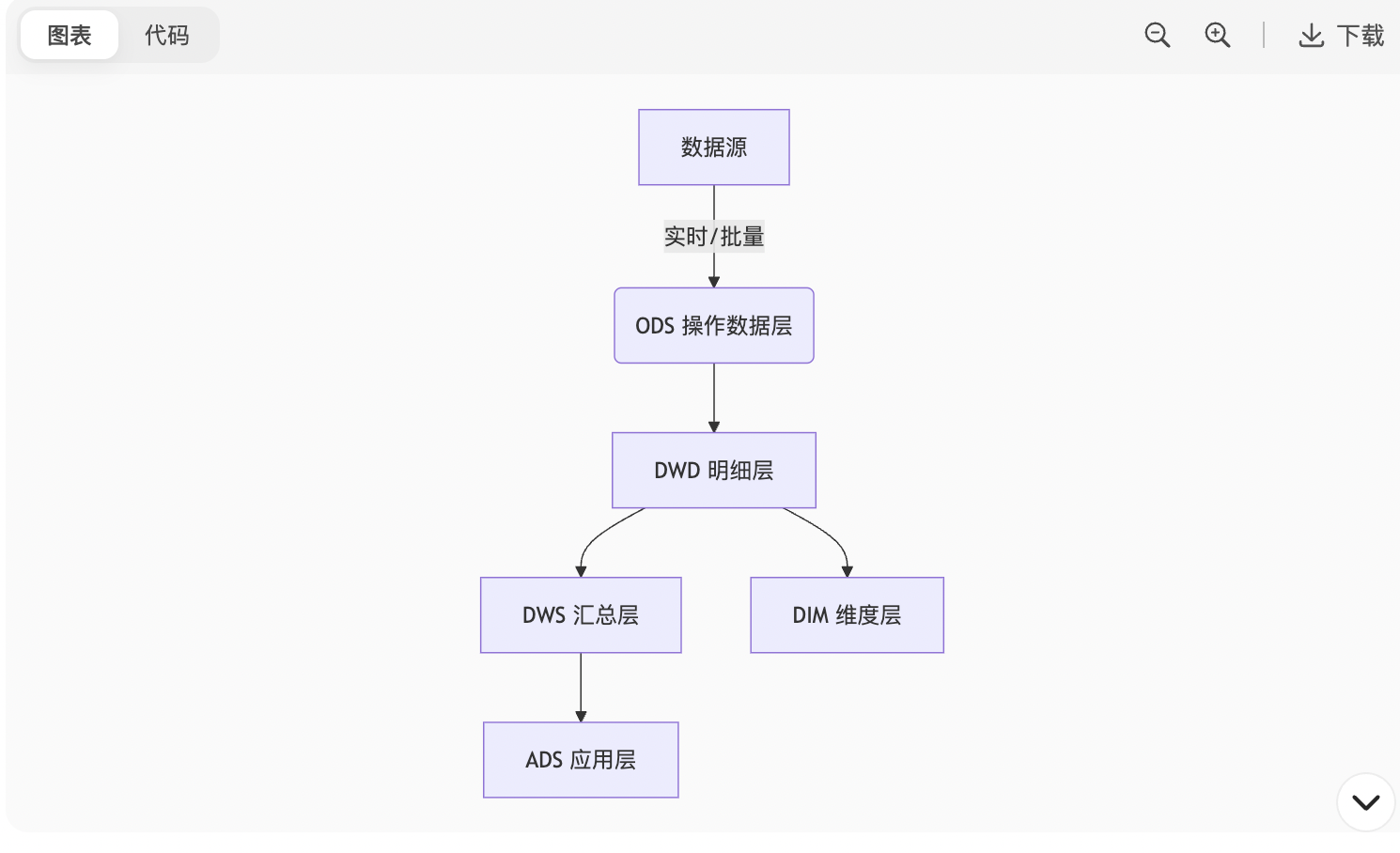
各层作用:
ODS:原始数据备份,保留历史变更(拉链存储)
DWD:数据清洗、维度退化(如将用户ID转用户名)
DWS:按主题预聚合(如用户7日行为汇总)
ADS:面向业务报表的直接输出
DIM:统一维度管理(用户、商品等)
2. 实时与离线数仓对比
| 维度 | 离线数仓 | 实时数仓 |
|---|---|---|
| 数据延迟 | T+1 | 秒级/分钟级 |
| 技术栈 | Hive+Spark | Flink+Kafka+ClickHouse |
| 适用场景 | 日报、历史分析 | 监控、实时风控 |
| 数据修正 | 可重跑 | 需事务支持 |
二、数据建模实战
3. 维度建模三大核心
事实表设计:
事务事实表:原子操作记录(如订单流水)
周期快照表:每日账户余额
累积快照表:多事件链路(如订单创建→支付→发货)
缓慢变化维(SCD)解决方案:
sql
-- Type2:拉链表实现 CREATE TABLE user_dim (user_id BIGINT,name STRING,start_date STRING, -- 生效日期end_date STRING -- 失效日期('9999-12-31'表示当前有效) );
Type1:覆盖历史值
Type2:保留历史版本(最常用)
Type3:新增历史字段
数据一致性保障:
原子性:使用分布式事务(如Hudi/Iceberg)
去重方案:
sql
INSERT OVERWRITE TABLE dwd_order SELECT order_id, user_id, amount FROM (SELECT *, ROW_NUMBER() OVER(PARTITION BY order_id ORDER BY update_time DESC) AS rnFROM ods_order ) t WHERE rn = 1;
三、ETL 优化策略
4. 数据倾斜处理方案
| 场景 | 解决方案 |
|---|---|
| Join倾斜 | 热点Key分离:/*+ MAPJOIN(small) */ + UNION ALL |
| Group By倾斜 | 两阶段聚合:随机盐桶 → 去盐聚合 |
| 动态分区小文件 | 开启合并:hive.merge.mapfiles=true |
5. 增量同步方案对比
| 方式 | 原理 | 适用场景 |
|---|---|---|
| 时间戳增量 | WHERE update_time > last_max | 含更新时间字段的表 |
| CDC日志解析 | Kafka Connect+Debezium | 数据库实时同步 |
| 全量对比 | MD5校验文件差异 | 小表(<10GB) |
四、新技术应用
6. 数据湖与湖仓一体
核心组件:
技术 特点 Hudi 支持ACID、增量查询(COW/MOR模式) Iceberg 隐藏分区、Schema演进 Delta 事务日志+Z-Order优化(Databricks生态) 湖仓一体优势:
统一存储:原始数据与数仓同层管理
支持流批一体:同一份数据实时离线共用
Schema强约束:避免数据沼泽
7. OLAP引擎选型
图表代码
pietitle 企业OLAP引擎使用率“ClickHouse” : 45“Doris” : 30“StarRocks” : 15“Kylin” : 10
场景建议:
宽表查询:ClickHouse(单表性能极致)
复杂多表Join:StarRocks(CBO优化器)
预计算场景:Kylin(Cube预聚合)
五、生产问题排查
8. 数据质量监控方案
监控指标:
python
# 脚本示例:空值率检测 if df.select([count(when(isnan(c) | col(c).isNull(), c)) for c in df.columns]).first()[0] > threshold:alert("数据空值超标!")工具链:
Great Expectations:数据断言测试
Apache Griffin:开源数据质量平台
自建监控:Prometheus + Grafana看板
9. 元数据管理实践
核心能力:
血缘分析:追踪表级/字段级来源与影响
数据地图:全局数据资产检索
敏感数据识别:自动标记手机号/身份证
开源方案:Apache Atlas + Amundsen
六、高频场景题
10. 如何设计电商数仓?
事实表:
交易事实表(事务型)
用户行为日志事实表(累积快照)
维度表:
商品维度(SCD Type2)
用户维度(拉链表)
促销活动维度
指标体系:
GMV、转化率、留存率、复购率
11. 缓慢变化维处理实战
sql
-- 拉链表更新(新数据:temp_user) INSERT OVERWRITE TABLE user_dim SELECT * FROM (-- 历史数据失效SELECT user_id, name, start_date, CASE WHEN end_date='9999-12-31' AND user_id IN (SELECT user_id FROM temp_user) THEN '2023-07-20' ELSE end_date END AS end_dateFROM user_dimUNION ALL-- 新增当前有效数据SELECT user_id, name, '2023-07-20' AS start_date, '9999-12-31' AS end_dateFROM temp_user ) t;
附:调优技巧速查表
| 问题类型 | 解决工具 |
|---|---|
| 小文件过多 | ALTER TABLE ... CONCATENATE |
| Map阶段长尾 | set mapred.max.split.size=256000000 |
| Reduce阶段OOM | set hive.exec.reducers.max=100 |
| 动态分区写入失效 | set hive.exec.dynamic.partition.mode=nonstrict |
💡 面试心法:
回答架构题先画分层图,再解释各层设计理由
被问新技术时强调落地场景(如:“我们用Hudi解决实时数据入湖的事务问题”)
遇到故障排查展示标准化流程:监控发现 → 定位瓶颈 → 验证方案 → 预防机制
大数据数仓建模相关面试题
以下是针对大数据数仓建模的高频面试题及深度解析,涵盖建模方法论、实战场景、解决方案和新技术整合,帮助您系统掌握核心考点:
一、建模方法论
1. 维度建模 vs 范式建模
| 维度 | 维度建模(Kimball) | 范式建模(Inmon) |
|---|---|---|
| 结构 | 星型/雪花模型 | 3NF/BCNF 规范化 |
| 查询性能 | 高(宽表冗余) | 低(多表关联) |
| 适用场景 | 分析型业务(OLAP) | 事务型系统(OLTP) |
| 开发速度 | 快(快速响应需求) | 慢(需深度设计) |
2. 星型模型 vs 雪花模型
图表
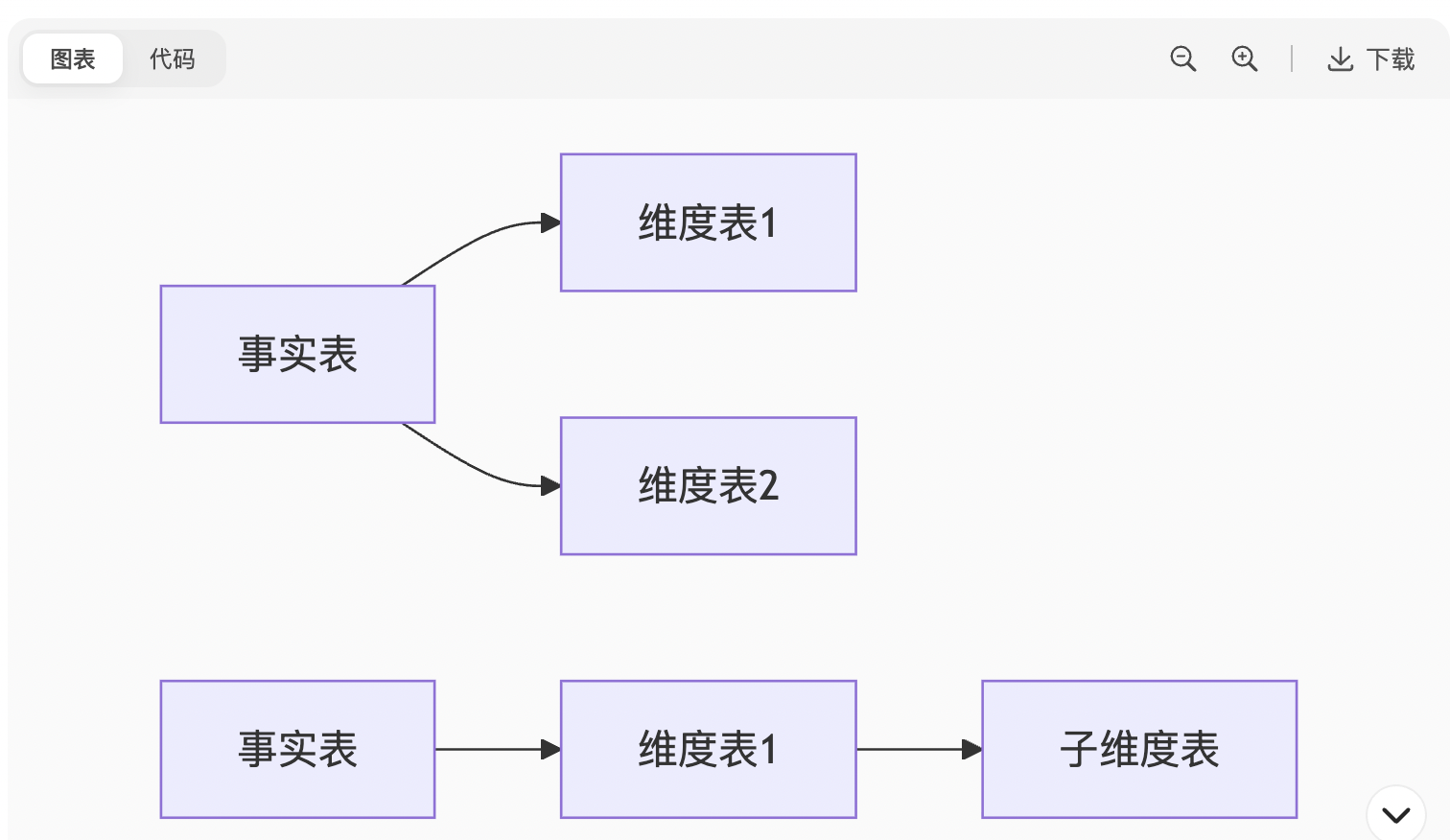
星型模型:维度表不进一步拆分(如商品维度含品牌、类目)
雪花模型:维度表多层拆分(品牌→独立维度表)
选择原则:优先星型模型(减少Join),雪花仅当维度层级极复杂时使用
二、事实表设计核心
3. 事实表三大类型
| 类型 | 特点 | 示例场景 |
|---|---|---|
| 事务事实表 | 记录原子事件(增删) | 订单支付流水 |
| 周期快照表 | 定期状态记录(每日/月) | 账户余额日报 |
| 累积快照表 | 跟踪业务流程(多时间点) | 订单全链路状态 |
4. 退化维度(Degenerate Dimension)
定义:将业务过程标识(如订单号)直接存入事实表
作用:
避免创建无意义的维度表
保留关键业务标识(用于精确查询)
示例:
sql
CREATE TABLE fact_order (order_id STRING, -- 退化维度user_id BIGINT,amount DECIMAL(10,2),dt STRING );
三、维度表高级设计
5. 缓慢变化维(SCD)解决方案
| 类型 | 处理方式 | 适用场景 | HQL实现示例 |
|---|---|---|---|
| Type1 | 覆盖历史值 | 无需追踪历史变更 | UPDATE SET col=new_value |
| Type2 | 拉链表(保留历史版本) | 用户资料变更审计 | 见下方拉链表代码 |
| Type3 | 新增历史字段列 | 少量关键属性回溯 | ALTER TABLE ADD prev_name |
拉链表核心实现:
sql
-- 1. 初始全量数据 CREATE TABLE user_dim_scd2 (user_id BIGINT,name STRING,start_date STRING DEFAULT '2020-01-01',end_date STRING DEFAULT '9999-12-31' );-- 2. 增量更新(假设增量表为user_updates) INSERT OVERWRITE TABLE user_dim_scd2 SELECT user_id, new_name AS name, '2023-07-01' AS start_date, -- 生效日期'9999-12-31' AS end_date FROM user_updates UNION ALL -- 历史数据失效 SELECT old.user_id,old.name,old.start_date,CASE WHEN new.user_id IS NOT NULL THEN '2023-06-30' -- 失效日期ELSE old.end_date END FROM user_dim_scd2 old LEFT JOIN user_updates new ON old.user_id = new.user_id;
6. 杂项维度(Junk Dimension)
场景:将多个低基数标志位合并到单一维度表
优点:减少事实表关联,提升查询性能
示例:
将订单状态(10种)、支付方式(5种)、是否优惠(2种)组合成order_attributes维度表
四、实时数仓建模挑战
7. CDC数据建模方案
图表
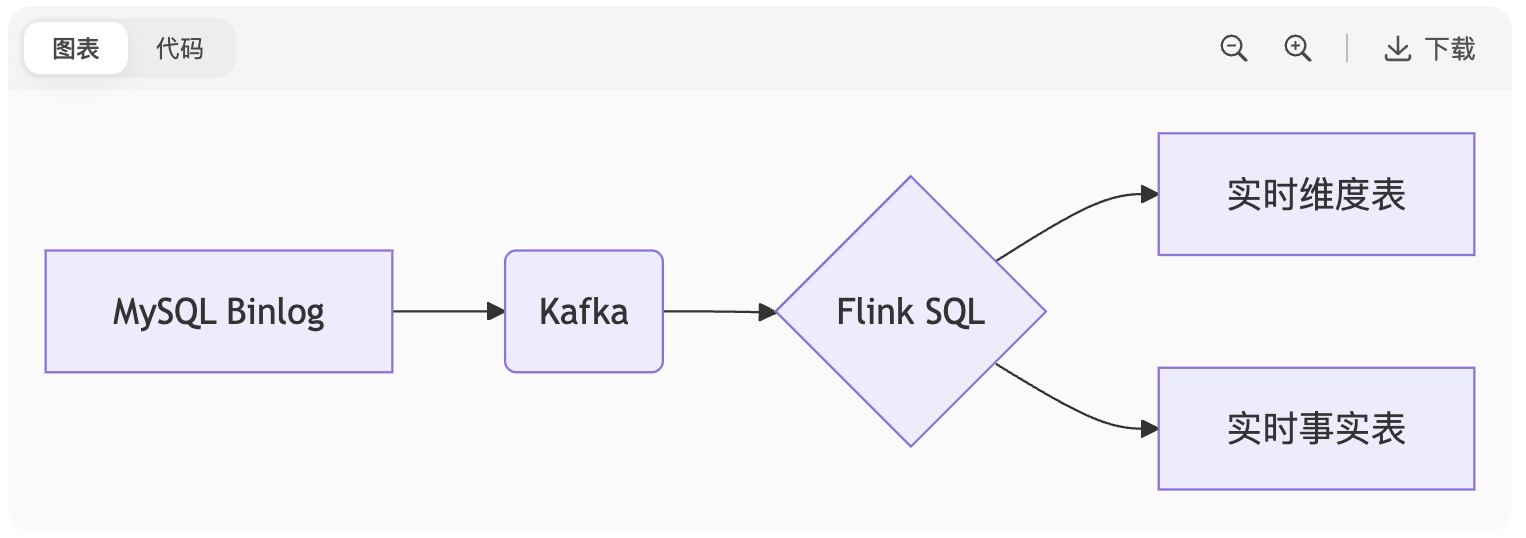
维度表更新:使用
Hudi MOR表实现实时维度更新事实表保证:
Exactly-Once:Flink+Kafka事务写入
顺序性:Kafka分区键保序(如
user_id)
8. 流批一体建模
Lambda架构痛点:两套代码维护、数据不一致
Kappa架构方案:
sql
-- Flink SQL 实现当日实时+历史批处理 SELECT user_id, SUM(amount) FROM (SELECT * FROM kafka_real_time -- 实时流UNION ALLSELECT * FROM hive_historical -- 离线批 ) GROUP BY user_id;
五、生产调优实战
9. 数据倾斜优化方案
| 场景 | 解决方案 | 实现方式 |
|---|---|---|
| Join倾斜 | 热点Key分离 | SELECT /*+ SKEWJOIN(skewed_keys) */ + 广播小表 |
| Group By倾斜 | 两阶段聚合 | 局部聚合(加盐)→ 全局聚合 |
| 动态分区倾斜 | 分桶写入 | DISTRIBUTE BY CAST(RAND()*N AS INT) |
10. 数据质量保障
三大核心检查:
sql
-- 1. 唯一性约束 SELECT COUNT(1) != COUNT(DISTINCT order_id) FROM fact_order;-- 2. 空值率监控 SELECT COUNT(1) FROM user_dim WHERE name IS NULL;-- 3. 值域校验 SELECT COUNT(1) FROM fact_order WHERE amount < 0;
工具推荐:
Great Expectations(数据测试框架) + Airflow(自动调度)
六、高频考点速查
| 问题类型 | 标准答案要点 |
|---|---|
| 如何选择事实表类型? | “根据业务过程特性:原子事件用事务表,状态记录用快照表,流程跟踪用累积快照表” |
| 维度建模核心优势? | “查询性能高(减少Join)、开发迭代快、业务理解直观” |
| 拉链表如何更新? | “三步法:新增变更记录 → 关闭旧记录失效日期 → 开放新记录(end_date=9999-12-31)” |
| 实时数仓难点? | “数据乱序处理(Watermark)、维度变更及时性(CDC延迟)、资源动态伸缩” |
💡 面试心法:
被问建模方法时先明确业务场景(如:“这是交易分析场景,适合星型模型+事务事实表”)
解释技术选型要对比优缺点(如:“选Type2拉链表是因业务需追踪历史用户画像变更”)
故障解决展示完整链路:
“定位倾斜(Spark UI)→ 选择方案(随机盐桶)→ 参数调优(hive.groupby.skewindata=true)→ 效果验证(任务耗时从2h降至15min)”
大数据数仓建模性能与优化相关面试题
以下是针对大数据数仓建模性能与优化的高频面试题及深度解析,涵盖分层优化、存储策略、计算加速等核心场景,助您掌握生产级调优方案:
一、分层架构优化
1. 数据分层性能影响
图表
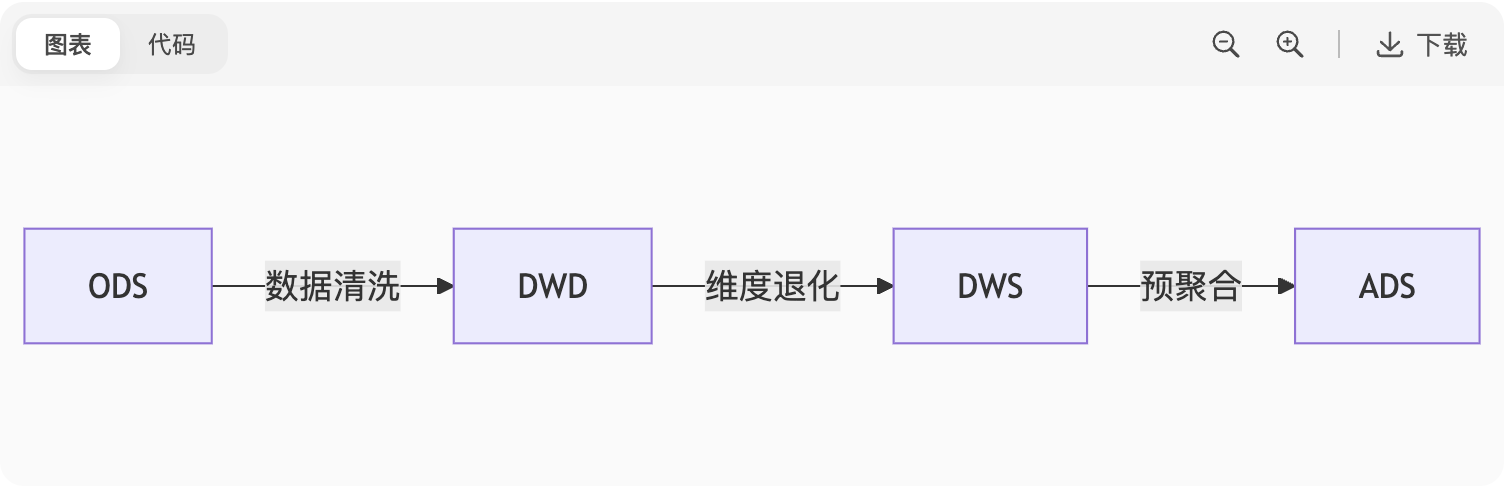
优化策略:
ODS层:原始数据压缩存储(Snappy/LZO)
DWD层:列式存储(ORC/Parquet) + 分区剪裁(
dt=202307)DWS层:预聚合(
SUM(sales) BY category) + 分桶(CLUSTERED BY user_id)ADS层:结果表缓存(Redis/Alluxio)
2. 宽表冗余 vs 多表关联
| 方案 | 查询性能 | 存储成本 | 适用场景 |
|---|---|---|---|
| 宽表冗余 | ⭐⭐⭐⭐ (毫秒级) | ⭐⭐ (TB级) | 高频分析(BI报表) |
| 多表关联 | ⭐⭐ (秒级) | ⭐ (GB级) | 低频即席查询 |
取舍原则:
存储空间充足 + 高频查询→ 宽表;存储受限 + 低频查询→ 多表关联
二、存储优化实战
3. 存储格式选型
| 格式 | 压缩率 | 查询速度 | 特性 |
|---|---|---|---|
| ORC | 高 | 快 | 内置索引(布隆过滤) |
| Parquet | 中 | 快 | 嵌套结构支持好 |
| TextFile | 低 | 慢 | 可读性强 |
sql
-- ORC索引加速(Hive 3.0+)
CREATE TABLE orders_orc (order_id BIGINT,user_id BIGINT
) STORED AS ORC
TBLPROPERTIES ("orc.create.index"="true", "orc.bloom.filter.columns"="user_id");4. 分区与分桶策略
分区优化:
sql
-- 动态分区避免全表扫描 SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict; INSERT INTO TABLE sales PARTITION(dt) SELECT ..., dt FROM source_table;
分桶加速Join:
sql
CREATE TABLE user_bucketed (user_id BIGINT,name STRING ) CLUSTERED BY(user_id) INTO 32 BUCKETS; -- 分桶表Join可避免Shuffle SELECT /*+ MAPJOIN(u) */ * FROM orders o JOIN user_bucketed u ON o.user_id = u.user_id;
三、计算层优化
5. 数据倾斜解决方案
| 倾斜类型 | 优化方案 | 实现代码 |
|---|---|---|
| GroupBy倾斜 | 两阶段聚合(局部+全局) | SELECT key, SUM(cnt) FROM (SELECT key%10 AS salt, COUNT(*) AS cnt ... GROUP BY salt, key) GROUP BY key |
| Join倾斜 | 热点Key分离 + MapJoin广播 | SELECT /*+ MAPJOIN(small) */ ... UNION ALL SELECT /*+ SKEWJOIN(large) */ ... |
| 动态分区倾斜 | 分桶写入 + 控制Reducer数 | DISTRIBUTE BY CAST(RAND()*100 AS INT) |
6. 向量化执行引擎
sql
-- Hive 2.3+ 开启向量化 SET hive.vectorized.execution.enabled=true; SET hive.vectorized.execution.reduce.enabled=true;
效果:CPU利用率提升3-5倍(减少虚函数调用)
四、实时数仓性能优化
7. 流批一体查询加速
图表
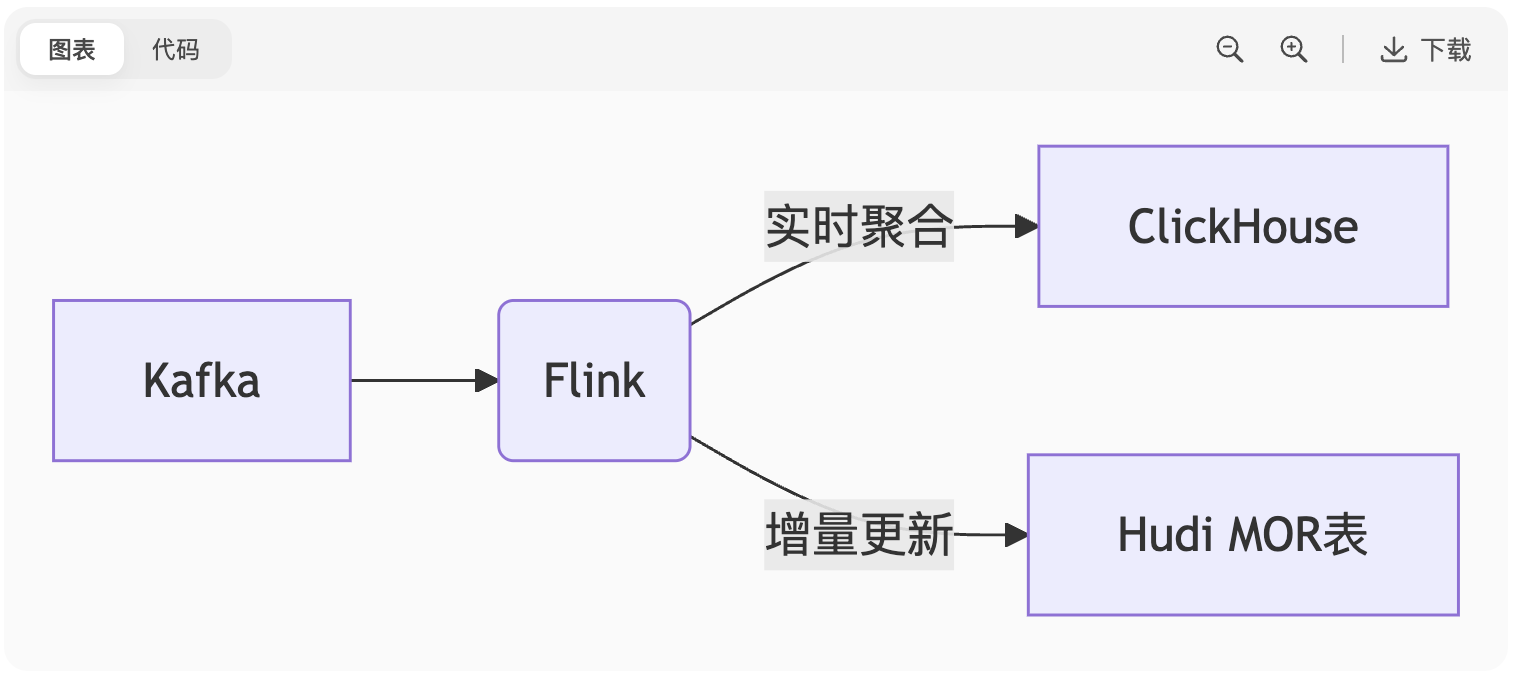
技术组合:
实时聚合:Flink窗口函数 + 状态后端(RocksDB)
增量查询:Hudi MOR表(Merge On Read)
亚秒响应:OLAP引擎(ClickHouse/Doris)
8. 增量计算策略
场景:每日UV统计(避免全量扫描)
方案:
sql
-- Flink SQL增量计算 SELECT DATE_FORMAT(ts, 'yyyy-MM-dd') AS dt, COUNT(DISTINCT user_id) FROM user_clicks GROUP BY TUMBLE(ts, INTERVAL '1' DAY), user_id
五、高级优化技术
9. Z-Order索引优化
sql
-- Iceberg Z-Order加速多维查询 ALTER TABLE sales ADD PARTITION FIELD zorder(category, region);
原理:将多维数据映射到一维空间,提升范围查询效率
效果:
WHERE category='A' AND region='Asia'查询提速5-10倍
10. 物化视图加速
sql
-- Hive 3.0 物化视图 CREATE MATERIALIZED VIEW sales_summary AS SELECT category, SUM(amount) FROM sales GROUP BY category; -- 自动查询重写 SET hive.materializedview.rewriting=true;
适用场景:固定维度聚合报表
六、生产案例剖析
11. 亿级用户标签查询优化
问题:
SELECT * FROM user_tags WHERE tag='VIP'扫描全表耗时10min优化步骤:
存储层:转ORC格式 + 对
tag列建布隆过滤计算层:分桶表(
CLUSTERED BY tag INTO 64 BUCKETS)查询层:启用向量化执行
结果:查询耗时降至3s
12. 跨集群数据同步优化
问题:每日全量同步PB级数据(耗时8h+)
优化方案:
bash
# 1. 增量同步(Hudi CDC) hudi-cli --table-type COPY_ON_WRITE --op upsert --target-table sales# 2. 分布式复制加速(DistCp+Snappy) hadoop distcp -Dmapreduce.map.memory.mb=8192 \-bandwidth 100 /source /target
效果:同步时间缩短至1h
调优思维回答模板
面试官:“千万级大表JOIN百亿级事实表,如何优化?”
回答框架:
诊断瓶颈:通过执行计划定位Shuffle或数据倾斜
存储优化:转为ORC格式 + 对Join键分桶
计算优化:
小表广播:
SET hive.auto.convert.join=true;倾斜处理:
SET hive.optimize.skewjoin=true;资源调整:增加Reducer内存 + 开启AQE动态调整
案例佐证:“曾优化双十亿表Join,通过分桶+MapJoin从2h降至8min”
💡 性能优化黄金法则:
存储:列式压缩 > 分区剪裁 > 分桶
计算:减少Shuffle > 避免数据倾斜 > 资源合理分配
架构:预聚合 > 增量更新 > 实时/离线链路分离