一文读懂:什么是CLIP
首先,让我给你看一张图片,你能描述一下你所看到的吗?

你的描述:一只鸟安静地坐在栏杆上。
现在,让我们翻转一下。我将描述一些东西,然后你想象它会是什么样子:
“一只坐在铁轨上的小狗。”

好!这样的事情可能会直接出现在你的脑海中,不是吗?
这感觉是无缝的,同时将我们人类的视觉和语言联系起来。
但对于计算机来说,这是一个巨大的挑战。机器如何才能真正理解图像的内容,而不仅仅是像素的集合,而是以一种与人类语言的丰富性联系起来的方式?
直到 CLIP 出现。
CLIP 代表对比语言-图像预训练,是 OpenAI 的革命性人工智能模型,它从根本上改变了机器感知我们世界的方式。它弥合了图像和文字之间的差距,为人工智能创造了一种强大的新学习和理解方式。这篇文章将解释 CLIP 是什么、它是如何工作的、为什么它的能力如此改变游戏规则,以及它已经解锁的令人难以置信的应用程序。
什么是 CLIP?(简单的解释)
让我们分解一下名称以了解核心思想。
语言-图像:从本质上讲,CLIP 从成对的图像和与之相关的文本描述中学习。
预训练:在应用于任何特定任务之前,它会在绝对庞大的数据集上进行“预训练”。这使它对世界有了广泛、普遍的了解。
对比:这描述了它是如何学习的。在大量图像和文本标题中,模型学会找出哪个图像属于哪个标题。这就像一个巨大而复杂的匹配游戏,模型因正确将图像与其文本配对而获得奖励,并因建立错误连接而受到惩罚。
所以,核心思想是这样的:CLIP是一个学习视觉数据(图像)和文本数据(语言)之间关系的模型。为了实现这一目标,它接受了从互联网上抓取的惊人的 4 亿个图像文本对的训练。这种巨大的规模使它对概念有如此广泛而细致的理解。
它实际上是如何工作的?
为了实现其目标,CLIP 使用了巧妙的两部分架构。你可以把它想象成有一个“两部分的大脑”。
图像编码器:这部分模型是计算机视觉专家。它查看图像并将其转换为数字列表,称为“嵌入”。这种嵌入是图像关键视觉特征的数学表示。它使用 Vision Transformer (ViT) 或 ResNet 等众所周知的架构来做到这一点。
文本编码器:这部分是语言专家。它采用一段文本(如句子或标签),并将其转换为嵌入,即表示单词语义含义的数字列表。它使用标准的 Transformer 架构来完成此任务。
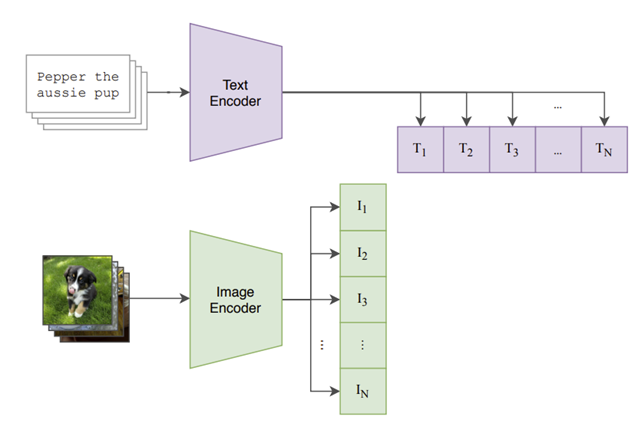
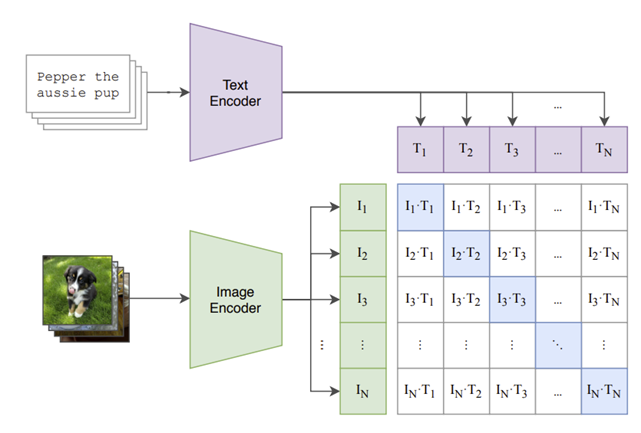
真正的魔力发生在所谓的共享嵌入空间中。图像编码器和文本编码器都经过训练,可以将其输出映射到这个公共空间中。目标是将匹配图像和文本描述的嵌入彼此非常接近放置。
想象一下一个巨大的图书馆,其中每本关于“在公园里玩耍的狗”的书(文本)和每张图片(图像)都位于同一个书架上。这就是 CLIP 学会做的。在“对比”训练期间,它学会最大化正确对之间的相似性(通常通过称为余弦相似度的指标来衡量),同时将所有不正确的对推得更远。
超能力:零样本学习
这种训练方法产生的最不可思议的能力是零样本学习。这是执行未明确训练的任务的能力。
例如,大多数较旧的人工智能模型需要针对特定任务在特定数据集上进行艰苦的训练。如果你想要一个模型来对狗品种进行分类,你必须向它展示数千张贵宾犬、猎犬等的标记图片。

CLIP 则不同。您可以给它一张斑马的图像,并要求它在文本标签之间进行选择:“马的照片”、“老虎的照片”和“斑马的照片”。即使 CLIP 从未在精选的“斑马”数据集上进行过专门训练,它也可以高精度地识别正确的标签。它之所以能做到这一点,是因为它从互联网上看到的数百万张图像和标题中学习了斑马的概念。
这是一个巨大的飞跃。它使人工智能更加灵活,并且无需为每个新的分类任务创建专门的数据集和重新训练模型。
实际应用:CLIP 在哪些方面产生了影响?
CLIP 的独特功能使其成为新一波人工智能工具的基础组成部分。
为图像生成提供动力:CLIP 是 DALL-E 2 和 Stable Diffusion 等令人难以置信的文本到图像模型背后的“指导大脑”。当这些模型根据文本提示生成图像时(例如,“在火星上骑马的宇航员”),它们使用 CLIP 不断检查正在进行的图像与文本的匹配程度。CLIP 的分数指导生成过程,引导其获得准确反映提示的最终图像。
更智能的图像搜索:您现在不仅可以搜索“猫”等关键字,还可以搜索“睡在红色沙发上的黑猫”等概念。由 CLIP 提供支持的搜索引擎可以理解语义上下文并找到视觉相关的图像,即使元数据中没有确切的单词。
内容审核:CLIP 可以通过理解其中的概念来自动识别和标记不适当或有害的图像,而不是依赖于预定义的、严格的类别。
创意工具:艺术家和设计师正在使用基于 CLIP 的工具通过简单的文本命令生成和编辑图像,从而为创造力开辟新的途径。
机器人:CLIP 正在帮助机器人更好地了解世界并遵循人类命令,例如“从桌子上捡起红球”。
CLIP 的局限性
尽管 CLIP 功能强大,但它并不完美。了解其局限性很重要:
与细粒度细节作斗争:虽然它知道什么是汽车,但它可能无法可靠地区分 2021 款本田思域和 2022 款车型之间的区别。
不善于计数:它经常会错误地显示图像中的对象数量。它理解“苹果”,但不一定是“三个苹果的照片”。
继承偏见:因为它是在互联网上大量未经过滤的数据集上训练的,所以它可以拾取甚至放大与性别、种族和文化相关的有害人类偏见。
抽象概念的困难:它可能会难以处理需要逻辑推理的高度抽象、无意义或复杂的提示。
CLIP 的实际应用:一个简单的代码示例
谈话很便宜,所以让我们看看它有效!使用 Hugging Face 变压器库,使用 CLIP 非常简单。以下 Python 代码演示了如何对来自 Web 的图像执行零样本分类。
# You'll need to install the necessary libraries first:
# pip install transformers torch Pillow requests
import requests
from PIL import Image
import torch
from transformers import CLIPProcessor, CLIPModel# 1. Load the pre-trained CLIP model and its processor
# The processor handles preparing the image and text for the model
model_name = "openai/clip-vit-base-patch32"
model = CLIPModel.from_pretrained(model_name)
processor = CLIPProcessor.from_pretrained(model_name)
# 2. Load an image from a URL
# Let's use a well-known image of a cat from the COCO dataset
url = ""
try:image = Image.open(requests.get(url, stream=True).raw)
except Exception as e:print(f"Could not load image from URL: {e}")# As a fallback, create a simple placeholder imageimage = Image.new('RGB', (224, 224), color = 'red')
# 3. Define your candidate text labels
# This is our "zero-shot classifier"
text_labels = ["a photo of a cat", "a photo of a dog", "a photo of a car"]
# 4. Process the image and text
# The processor converts the image and text into a numerical format (embeddings)
# that the CLIP model understands.
inputs = processor(text=text_labels, images=image, return_tensors="pt", padding=True)
# 5. Get the model's predictions
# The model will output "logits," which are raw scores representing the similarity
# between the image and each text label.
with torch.no_grad():outputs = model(**inputs)
# The logits_per_image gives us the similarity scores
logits_per_image = outputs.logits_per_image
# 6. Convert scores to probabilities and print the results
# We use the softmax function to convert the raw scores into probabilities.
probs = logits_per_image.softmax(dim=1)
# Print the results nicely
print("Image-Text Similarity Probabilities:")
for i, label in enumerate(text_labels):print(f"- {label}: {probs[0][i].item():.4f}")
# Find the label with the highest probability
highest_prob_index = probs.argmax().item()
print(f"\n--> Predicted Label: '{text_labels[highest_prob_index]}'")当你运行这段代码时,模型会以非常高的概率正确识别出图像最好用“一张猫的照片”来描述,只需几行代码即可展示其强大的零样本能力。
CLIP 代表了人工智能的范式转变。通过学习以一种有意义的方式连接图像和文本,它解锁了曾经是科幻小说中的东西的能力。其革命性的零样本学习能力使人工智能比以往任何时候都更加灵活、强大和适应性强。
虽然 CLIP 有其局限性,但它作为当前人工智能热潮背后的引擎的作用是不可否认的。这是一项基础技术,正在帮助我们构建功能更强大、更智能的系统,这些系统可以第一次开始像我们一样更多地了解我们丰富的多模式世界。