【完整源码+数据集+部署教程】耳镜耳部疾病分类系统源码和数据集:改进yolo11-HSFPN
背景意义
研究背景与意义
耳部疾病的早期诊断和分类对于提高患者的治疗效果和生活质量至关重要。耳部疾病种类繁多,其中急性中耳炎(AOM)、慢性中耳炎(Chronic)、正常耳部状态(Normal)以及耳道积液(OME)是最常见的四种类型。随着全球人口老龄化及环境因素的影响,耳部疾病的发病率逐年上升,尤其是在儿童和老年人群体中。因此,开发一种高效、准确的耳部疾病分类系统,能够帮助医生在临床实践中快速识别和诊断耳部疾病,具有重要的现实意义。
近年来,深度学习技术在计算机视觉领域取得了显著进展,尤其是目标检测和图像分类任务中。YOLO(You Only Look Once)系列模型因其高效性和实时性而受到广泛关注。YOLOv11作为该系列的最新版本,结合了更先进的特征提取和处理技术,能够在保持高准确率的同时显著提高检测速度。然而,针对耳部疾病的特定应用,现有的YOLO模型仍存在一定的局限性,如对小目标的检测能力不足和对复杂背景的适应性差。因此,基于改进YOLOv11的耳镜耳部疾病分类系统的研究显得尤为重要。
本研究将利用包含2100张耳部图像的数据集进行模型训练与评估,数据集中涵盖了四种耳部疾病的标注信息。通过对YOLOv11模型的改进,旨在提升其在耳部疾病分类任务中的表现,尤其是在处理不同类型耳部疾病时的准确性和鲁棒性。此外,本研究还将探讨如何通过优化数据预处理和模型参数设置,进一步提升模型的分类效果。最终,该系统的成功开发将为耳部疾病的早期诊断提供有力支持,为医疗工作者提供更为精准的决策依据,从而推动耳部疾病防治工作的进展。
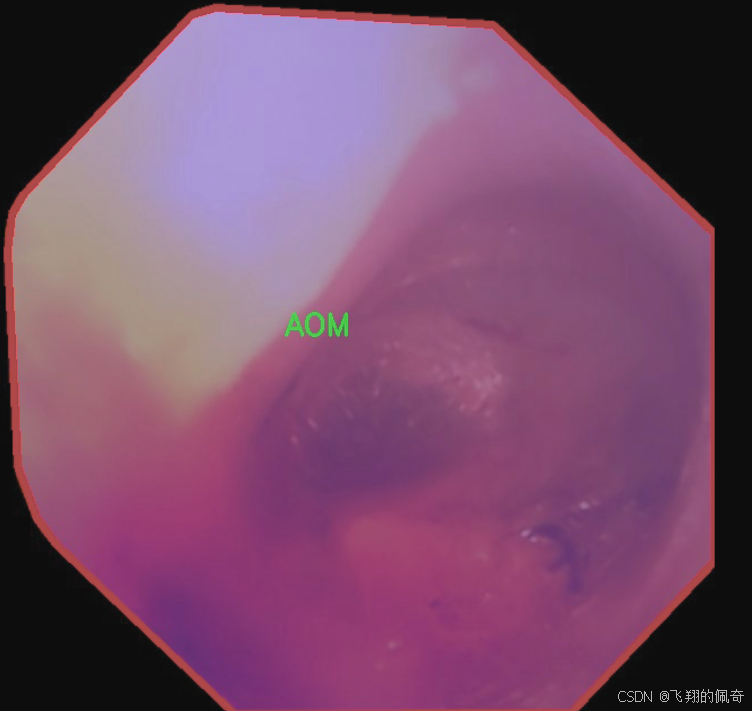
图片效果
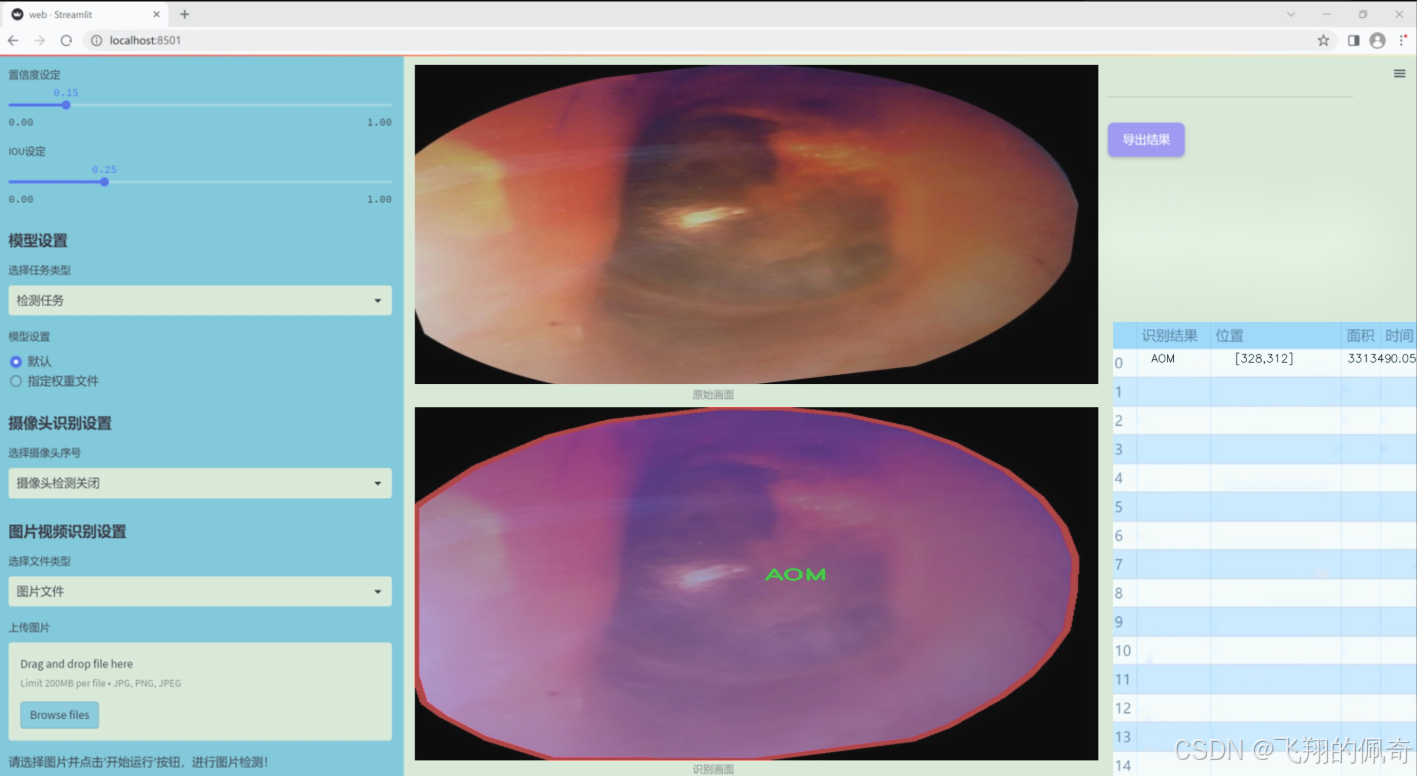
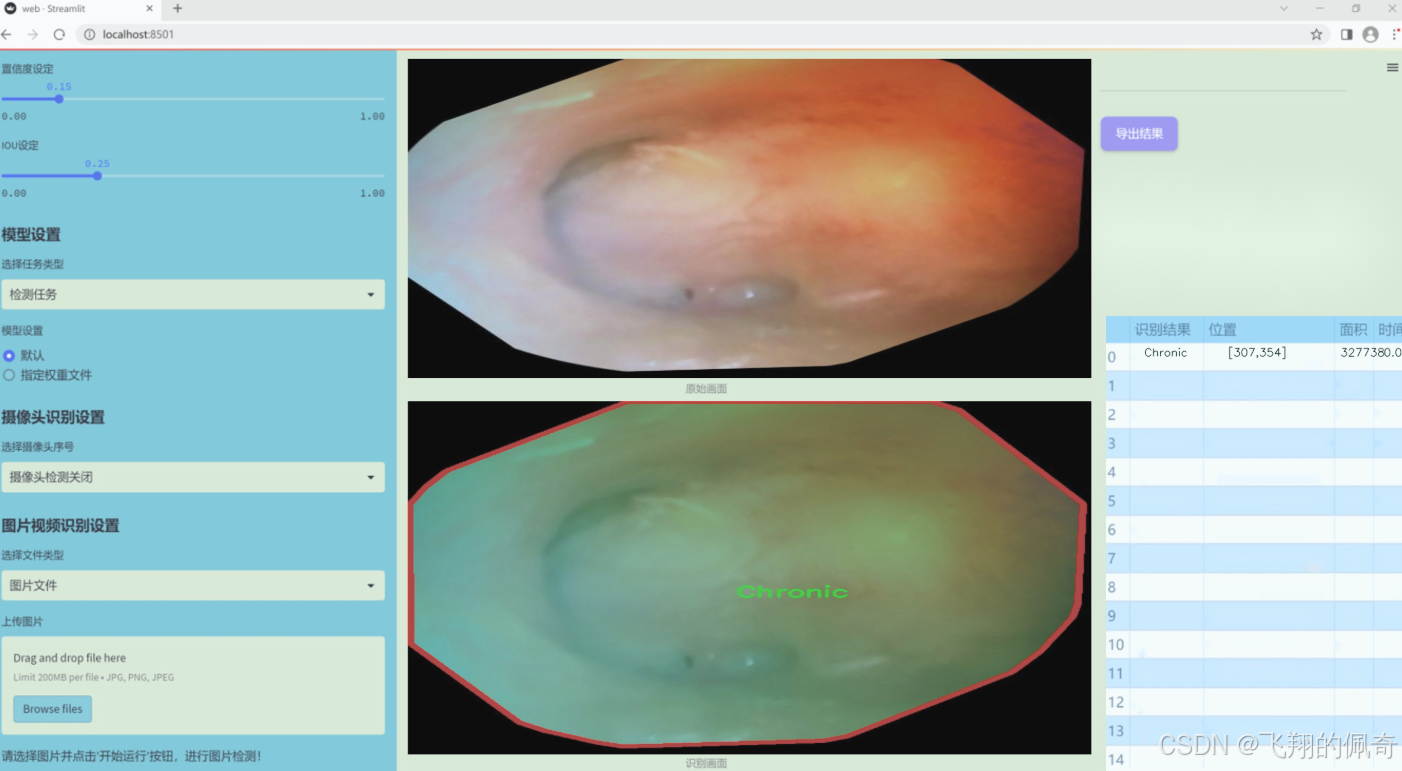
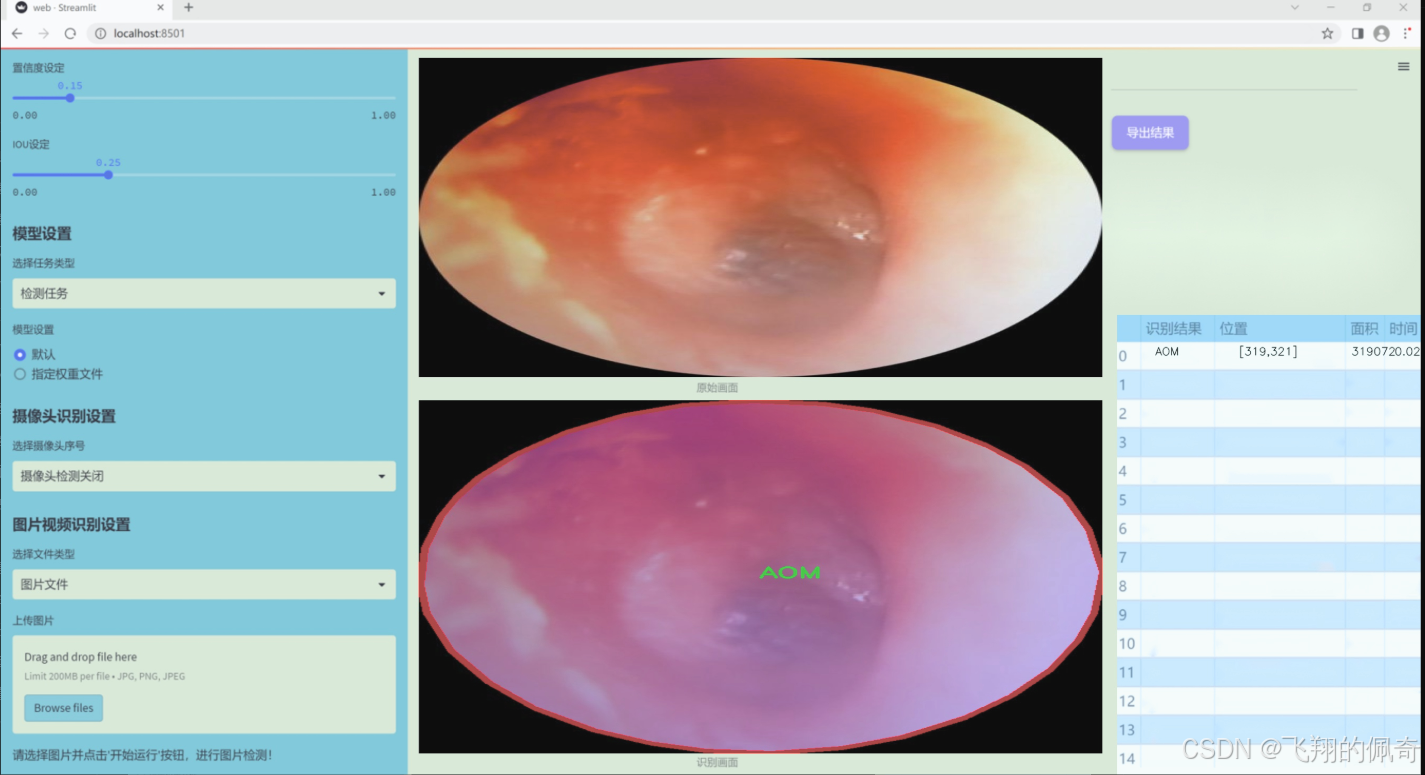
数据集信息
4.1 本项目数据集类别数&类别名
nc: 4 names: [‘AOM’, ‘Chronic’, ‘Normal’, ‘OME’]
该项目为【图像分割】数据集,请在【训练教程和Web端加载模型教程(第三步)】这一步的时候按照【图像分割】部分的教程来训练
4.2 本项目数据集信息介绍
本项目数据集信息介绍
本项目旨在开发一个改进版的YOLOv11耳镜耳部疾病分类系统,所使用的数据集名为“safEar”。该数据集专注于耳部疾病的分类,涵盖了四个主要类别,分别是急性中耳炎(AOM)、慢性中耳炎(Chronic)、正常耳部(Normal)以及耳朵积液(OME)。这些类别的选择基于耳部疾病的临床重要性和常见性,能够有效支持耳部疾病的早期诊断和治疗。
在数据集的构建过程中,确保了样本的多样性和代表性,以便模型能够学习到不同类型耳部疾病的特征。每个类别均包含大量的耳镜图像,这些图像来源于不同年龄段和性别的患者,涵盖了多种耳部病变的表现。通过对这些图像的精细标注,数据集为模型的训练提供了丰富的信息,使其能够更好地识别和分类耳部疾病。
数据集的设计考虑到了实际应用中的挑战,例如不同光照条件、耳部结构的变异以及患者的个体差异等。这些因素可能会影响耳镜图像的质量和可识别性,因此在数据集的构建过程中,特别注重了图像的质量控制和多样性,以确保模型在真实场景中的鲁棒性和准确性。
通过使用“safEar”数据集,改进后的YOLOv11模型将能够在耳部疾病的自动分类中发挥重要作用,为临床医生提供辅助决策支持,提高耳部疾病的诊断效率和准确性。这一研究不仅具有重要的临床应用价值,也为耳部疾病的相关研究提供了基础数据支持。
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
定义一个自定义的批量归一化类
class RepBN(nn.Module):
def init(self, channels):
super(RepBN, self).init()
# 定义一个可学习的参数 alpha,初始值为 1
self.alpha = nn.Parameter(torch.ones(1))
# 定义一个一维的批量归一化层
self.bn = nn.BatchNorm1d(channels)
def forward(self, x):# 将输入张量的维度进行转置,以适应 BatchNorm1d 的输入要求x = x.transpose(1, 2)# 进行批量归一化,并加上 alpha * xx = self.bn(x) + self.alpha * x# 再次转置回原来的维度x = x.transpose(1, 2)return x
定义一个线性归一化类
class LinearNorm(nn.Module):
def init(self, dim, norm1, norm2, warm=0, step=300000, r0=1.0):
super(LinearNorm, self).init()
# 注册一些缓冲区,用于控制训练过程中的参数
self.register_buffer(‘warm’, torch.tensor(warm)) # 预热步数
self.register_buffer(‘iter’, torch.tensor(step)) # 当前迭代步数
self.register_buffer(‘total_step’, torch.tensor(step)) # 总步数
self.r0 = r0 # 初始权重
# 初始化两个归一化层
self.norm1 = norm1(dim)
self.norm2 = norm2(dim)
def forward(self, x):if self.training: # 如果处于训练模式if self.warm > 0: # 如果还有预热步数self.warm.copy_(self.warm - 1) # 减少预热步数x = self.norm1(x) # 使用 norm1 进行归一化else:# 计算当前的 lamda 值lamda = self.r0 * self.iter / self.total_stepif self.iter > 0:self.iter.copy_(self.iter - 1) # 减少迭代步数# 分别使用 norm1 和 norm2 进行归一化x1 = self.norm1(x)x2 = self.norm2(x)# 线性组合两个归一化的结果x = lamda * x1 + (1 - lamda) * x2else:# 如果不在训练模式,直接使用 norm2 进行归一化x = self.norm2(x)return x
代码核心部分解释:
RepBN 类:自定义的批量归一化层,除了进行标准的批量归一化外,还引入了一个可学习的参数 alpha,用于调整输入特征的影响。
LinearNorm 类:实现了一种动态的归一化策略。在训练过程中,前 warm 步使用 norm1 进行归一化,之后根据当前迭代步数动态调整 norm1 和 norm2 的权重,形成一个平滑的过渡。这种方法可以在训练的不同阶段灵活调整归一化的方式,提高模型的性能。
这个程序文件 prepbn.py 定义了两个神经网络模块,分别是 RepBN 和 LinearNorm,它们都是继承自 PyTorch 的 nn.Module 类,用于实现特定的归一化操作。
RepBN 类的构造函数接受一个参数 channels,表示输入数据的通道数。在初始化过程中,它创建了一个可学习的参数 alpha,并实例化了一个一维批量归一化层 BatchNorm1d。在前向传播方法 forward 中,输入张量 x 首先进行维度转换,以便适应批量归一化的要求。接着,输入张量经过批量归一化处理后,与 alpha 乘以的原始输入相加,最后再进行一次维度转换以恢复原来的形状。这种结构可以增强模型的表达能力,允许网络在训练过程中自适应地调整归一化的影响。
LinearNorm 类的构造函数接受多个参数,包括维度 dim、两个归一化方法 norm1 和 norm2,以及一些用于控制训练过程的参数,如 warm(预热期)、step(当前迭代步数)和 r0(初始比例)。在初始化时,它将这些参数注册为缓冲区,以便在训练过程中进行管理。在前向传播方法中,如果模型处于训练状态且 warm 大于零,则会执行 norm1 归一化,并减少 warm 的值。当 warm 为零时,计算一个动态的比例 lamda,该比例依赖于当前的迭代步数和总步数。接着,输入数据分别经过 norm1 和 norm2 归一化,最终输出的结果是这两者的加权和。如果模型不在训练状态,则直接使用 norm2 进行归一化。
整体来看,这个文件实现了两种不同的归一化方法,旨在提高深度学习模型的训练效果和稳定性。RepBN 通过引入可学习的参数增强了批量归一化的灵活性,而 LinearNorm 则通过动态调整归一化策略来适应训练过程中的不同阶段。
10.3 transformer.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
from functools import partial
导入自定义的归一化模块
from .prepbn import RepBN, LinearNorm
from …modules.transformer import TransformerEncoderLayer
定义线性归一化和RepBN的组合
ln = nn.LayerNorm
linearnorm = partial(LinearNorm, norm1=ln, norm2=RepBN, step=60000)
class TransformerEncoderLayer_RepBN(TransformerEncoderLayer):
def init(self, c1, cm=2048, num_heads=8, dropout=0, act=…, normalize_before=False):
# 初始化父类的构造函数
super().init(c1, cm, num_heads, dropout, act, normalize_before)
# 使用线性归一化和RepBN进行归一化self.norm1 = linearnorm(c1)self.norm2 = linearnorm(c1)
class AIFI_RepBN(TransformerEncoderLayer_RepBN):
“”“定义AIFI变换器层。”“”
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):"""使用指定参数初始化AIFI实例。"""super().__init__(c1, cm, num_heads, dropout, act, normalize_before)def forward(self, x):"""AIFI变换器层的前向传播。"""c, h, w = x.shape[1:] # 获取输入张量的通道数、高度和宽度pos_embed = self.build_2d_sincos_position_embedding(w, h, c) # 构建位置嵌入# 将输入张量从形状[B, C, H, W]展平为[B, HxW, C]x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))# 将输出张量的形状从[B, HxW, C]转换回[B, C, H, W]return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):"""构建2D正弦-余弦位置嵌入。"""assert embed_dim % 4 == 0, "嵌入维度必须是4的倍数,以便进行2D正弦-余弦位置嵌入"grid_w = torch.arange(w, dtype=torch.float32) # 创建宽度的网格grid_h = torch.arange(h, dtype=torch.float32) # 创建高度的网格grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing="ij") # 生成网格坐标pos_dim = embed_dim // 4 # 计算位置嵌入的维度omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim # 计算频率omega = 1.0 / (temperature**omega) # 根据温度调整频率# 计算宽度和高度的正弦和余弦值out_w = grid_w.flatten()[..., None] @ omega[None]out_h = grid_h.flatten()[..., None] @ omega[None]# 返回组合的正弦和余弦位置嵌入return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]
代码注释说明:
导入模块:导入必要的PyTorch模块和自定义的归一化及变换器模块。
归一化定义:使用partial定义了一个结合了线性归一化和RepBN的归一化函数。
TransformerEncoderLayer_RepBN类:继承自TransformerEncoderLayer,在初始化时定义了两个归一化层。
AIFI_RepBN类:定义了AIFI变换器层,包含前向传播方法和位置嵌入构建方法。
前向传播:在前向传播中,输入张量被展平并传递给父类的前向方法,最后将输出张量恢复为原始形状。
位置嵌入构建:静态方法生成2D正弦-余弦位置嵌入,确保嵌入维度为4的倍数,并计算每个位置的正弦和余弦值。
这个程序文件定义了一个用于实现变换器(Transformer)模型的类,主要是对变换器编码器层进行扩展,加入了特定的归一化方法。代码中使用了PyTorch库,主要涉及到神经网络的构建和前向传播。
首先,文件导入了必要的库,包括PyTorch的核心模块和一些自定义的模块。RepBN和LinearNorm是自定义的归一化方法,而TransformerEncoderLayer和AIFI则是变换器的基本构件。
接下来,定义了一个名为TransformerEncoderLayer_RepBN的类,它继承自TransformerEncoderLayer。在构造函数中,调用了父类的构造函数,并定义了两个归一化层norm1和norm2,这两个层使用了之前定义的linearnorm,后者是一个偏函数,结合了层归一化和RepBN,并设置了一个步数参数。
然后,定义了另一个类AIFI_RepBN,它继承自TransformerEncoderLayer_RepBN,并实现了AIFI变换器层的功能。在构造函数中,除了调用父类的构造函数外,还可以指定激活函数(默认为GELU)。这个类的核心是forward方法,它实现了前向传播的逻辑。
在forward方法中,首先获取输入张量x的形状信息,包括通道数c、高度h和宽度w。接着,调用build_2d_sincos_position_embedding方法生成二维的正弦余弦位置嵌入,这对于变换器模型来说是非常重要的,因为它帮助模型理解输入数据的空间结构。然后,将输入张量从形状[B, C, H, W]转换为[B, HxW, C],并调用父类的forward方法进行处理,最后将输出结果恢复为原来的形状。
build_2d_sincos_position_embedding是一个静态方法,用于构建二维的正弦余弦位置嵌入。该方法首先检查嵌入维度是否能被4整除,这是生成位置嵌入的要求。接着,创建了宽度和高度的网格,并计算出相应的正弦和余弦值,最终返回一个包含这些值的张量。
整体来看,这个文件实现了一个自定义的变换器编码器层,结合了新的归一化方法和位置嵌入的生成方式,适用于处理具有空间结构的数据,如图像等。
10.4 val.py
以下是经过简化并添加详细中文注释的核心代码部分:
import os
import torch
from ultralytics.engine.validator import BaseValidator
from ultralytics.utils.metrics import DetMetrics, box_iou
from ultralytics.utils import LOGGER, ops
class DetectionValidator(BaseValidator):
“”"
扩展自BaseValidator类的检测模型验证器。
“”"
def __init__(self, dataloader=None, save_dir=None, args=None):"""初始化检测模型,设置必要的变量和参数。"""super().__init__(dataloader, save_dir, args)self.metrics = DetMetrics(save_dir=self.save_dir) # 初始化检测指标self.iouv = torch.linspace(0.5, 0.95, 10) # 定义IOU阈值范围self.niou = self.iouv.numel() # IOU数量def preprocess(self, batch):"""对图像批次进行预处理,以便于YOLO训练。"""batch["img"] = batch["img"].to(self.device, non_blocking=True) # 将图像转移到设备上batch["img"] = batch["img"].float() / 255 # 将图像归一化到[0, 1]for k in ["batch_idx", "cls", "bboxes"]:batch[k] = batch[k].to(self.device) # 将其他数据转移到设备上return batchdef postprocess(self, preds):"""对预测输出应用非极大值抑制(NMS)。"""return ops.non_max_suppression(preds,self.args.conf,self.args.iou,multi_label=True,max_det=self.args.max_det,)def update_metrics(self, preds, batch):"""更新检测指标。"""for si, pred in enumerate(preds):npr = len(pred) # 当前预测数量pbatch = self._prepare_batch(si, batch) # 准备当前批次数据cls, bbox = pbatch.pop("cls"), pbatch.pop("bbox") # 获取真实标签if npr == 0:continue # 如果没有预测,跳过predn = self._prepare_pred(pred, pbatch) # 准备预测数据stat = {"conf": predn[:, 4], # 置信度"pred_cls": predn[:, 5], # 预测类别"tp": self._process_batch(predn, bbox, cls) # 计算真阳性}self.metrics.process(**stat) # 更新指标def _process_batch(self, detections, gt_bboxes, gt_cls):"""返回正确的预测矩阵。"""iou = box_iou(gt_bboxes, detections[:, :4]) # 计算IOUreturn self.match_predictions(detections[:, 5], gt_cls, iou) # 匹配预测与真实标签def get_stats(self):"""返回指标统计和结果字典。"""stats = {k: torch.cat(v, 0).cpu().numpy() for k, v in self.stats.items()} # 转换为numpyif len(stats) and stats["tp"].any():self.metrics.process(**stats) # 处理指标return self.metrics.results_dict # 返回结果字典def print_results(self):"""打印每个类别的训练/验证集指标。"""pf = "%22s" + "%11i" * 2 + "%11.3g" * len(self.metrics.keys) # 打印格式LOGGER.info(pf % ("all", self.seen, self.nt_per_class.sum(), *self.metrics.mean_results())) # 打印总体结果
代码说明:
DetectionValidator类:这是一个用于验证YOLO检测模型的类,继承自BaseValidator。
初始化方法:设置必要的参数和指标,定义IOU的范围。
预处理方法:将输入的图像批次转移到指定设备,并进行归一化处理。
后处理方法:应用非极大值抑制(NMS)来过滤掉冗余的预测框。
更新指标方法:更新当前批次的检测指标,包括计算真阳性等。
处理批次方法:计算预测框与真实框之间的IOU,并返回匹配结果。
获取统计信息方法:返回当前的指标统计信息。
打印结果方法:打印整体和每个类别的检测结果。
这个程序文件 val.py 是一个用于目标检测模型验证的类 DetectionValidator 的实现,主要基于 Ultralytics YOLO 框架。该类继承自 BaseValidator,提供了一系列方法来处理验证过程中的数据预处理、指标计算、结果输出等功能。
在初始化方法中,DetectionValidator 设置了一些必要的变量和参数,包括数据加载器、保存目录、进度条、参数设置等。它还定义了一些用于计算检测指标的属性,如 DetMetrics 和 ConfusionMatrix,并初始化了一些用于后续计算的张量。
preprocess 方法负责对输入的图像批次进行预处理,包括将图像数据转移到指定设备(如 GPU),并进行归一化处理。它还处理了用于自动标注的边界框信息。
init_metrics 方法用于初始化评估指标,包括检查数据集是否为 COCO 格式,并设置相关的类映射和统计信息。
get_desc 方法返回一个格式化的字符串,用于总结每个类的指标信息。
postprocess 方法应用非极大值抑制(NMS)来处理模型的预测输出,以减少重叠的检测框。
_prepare_batch 和 _prepare_pred 方法分别用于准备输入批次和预测结果,以便进行后续的评估。
update_metrics 方法负责更新检测指标,处理每个批次的预测结果与真实标签的比较,并更新混淆矩阵和其他统计信息。
finalize_metrics 方法在验证结束时设置最终的指标值,包括计算速度和混淆矩阵。
get_stats 方法返回当前的指标统计信息,计算每个类的目标数量。
print_results 方法用于打印训练或验证集的每个类的指标信息,并可视化混淆矩阵。
_process_batch 方法计算正确预测的矩阵,使用 IoU(交并比)来评估预测框与真实框的匹配情况。
build_dataset 和 get_dataloader 方法用于构建 YOLO 数据集和返回数据加载器,以便在验证过程中使用。
plot_val_samples 和 plot_predictions 方法用于可视化验证样本和预测结果,生成带有标签和预测框的图像。
save_one_txt 和 pred_to_json 方法分别用于将检测结果保存为文本文件和 COCO 格式的 JSON 文件,以便后续分析和评估。
eval_json 方法用于评估 YOLO 输出的 JSON 格式结果,并返回性能统计信息,特别是计算 mAP(平均精度均值)。
总体而言,这个文件实现了一个完整的目标检测模型验证流程,包括数据预处理、指标计算、结果输出和可视化等功能,适用于使用 YOLO 模型进行目标检测任务的场景。

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻