机器学习之随机森林
一、什么是随机森林?
提到随机森林,很多人会直观地想:"不就是很多决策树凑在一起吗?" 这句话对了一半,但忽略了其核心的 "随机性" 设计。要理解随机森林,我们需要先从它的 "积木"—— 决策树和 "组装方式"—— 集成学习说起。
1. 从决策树到集成学习:为什么需要 "森林"?
决策树是一种直观的机器学习模型,它像一棵倒置的树,通过对特征的逐步判断(如 "年龄是否大于 30?"" 收入是否超过 5 万?")来实现分类或回归。单棵决策树的优点是简单易懂、训练速度快,但缺点也很明显:容易过拟合(对训练数据拟合过好,泛化能力差),且预测结果受数据微小变化影响较大(稳定性差)。
为了解决单棵决策树的缺陷,集成学习(Ensemble Learning) 应运而生。集成学习的核心思想是:"三个臭皮匠顶个诸葛亮"—— 通过组合多个 "弱学习器"(性能略优于随机猜测的模型)的预测结果,得到一个更强大的 "强学习器"。随机森林就是集成学习中最成功的代表之一,它的 "弱学习器" 正是决策树。
2.什么是集成学习
• 集成学习:通过组合多个基础学习器(如决策树、逻辑回归等)提升模型性能,典型方法包括:
• Bagging(如随机森林)
• Boosting(如AdaBoost、XGBoost)
• 堆叠模型(Stacking)
二、随机森林的工作原理
随机森林的核心在于 "随机" 二字,主要体现在两个方面:
1. 数据随机:使用 Bootstrap 抽样法从原始数据中随机抽取样本,为每棵树创建不同的训练集
2. 特征随机:在构建每棵树的每个节点时,随机选择部分特征进行分裂
3.森林结构:由多棵决策树组成,最终结果通过投票(分类)或平均(回归)决定。
其具体工作流程如下:
1. 从原始数据集中随机有放回地抽取 N 个样本,形成新的训练集
2. 对于每个样本集,随机选择部分特征,构建一棵决策树
3. 重复上述过程,构建多棵决策树
4. 对于分类问题,通过投票决定最终类别;对于回归问题,取平均值作为结果
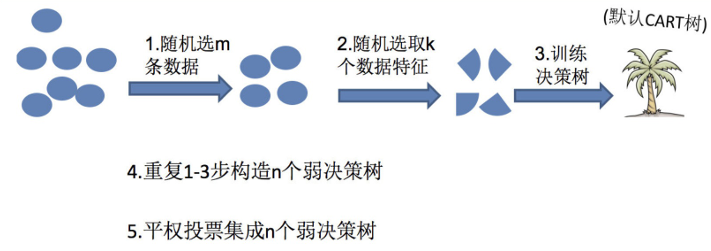
三、随机森林构造过程
在机器学习中,随机森林是⼀个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数⽽定。
随机森林 = Bagging + 决策树
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True
随机森林够造过程中的关键步骤(M表示特征数⽬):
1)⼀次随机选出⼀个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2) 随机去选出m个特征, m <<M,建⽴决策树
四、随机森林api介绍
以下是随机森林的源码参数:
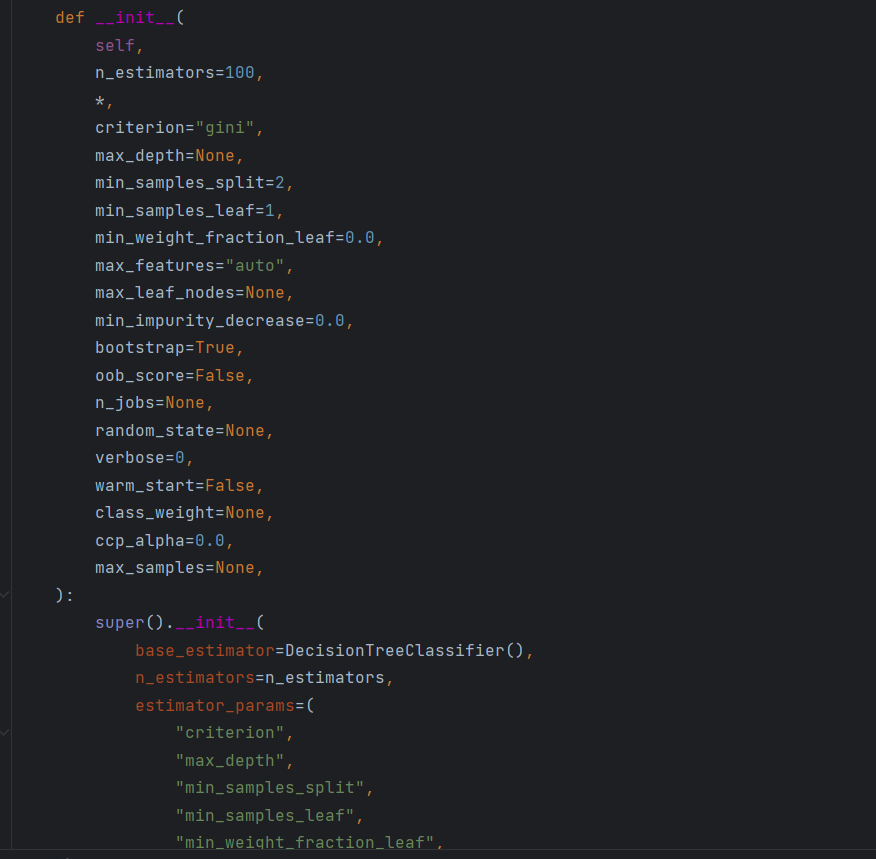
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True,random_state=None, min_samples_split=2)
n_estimators:integer,optional(default = 10)森林⾥的树⽊数量120,200,300,500,800,1200
在利⽤最⼤投票数或平均值来预测之前,你想要建⽴⼦树的数量。
Criterion:string,可选(default =“gini”)
分割特征的测量⽅法
max_depth:integer或None,可选(默认=⽆)
树的最⼤深度 5,8,15,25,30
max_features="auto”,每个决策树的最⼤特征数量
If "auto", then max_features=sqrt(n_features) .
If "sqrt", then max_features=sqrt(n_features) (same as "auto").
If "log2", then max_features=log2(n_features) .
If None, then max_features=n_features .
bootstrap:boolean,optional(default = True)
是否在构建树时使⽤放回抽样
min_samples_split 内部节点再划分所需最⼩样本数
这个值限制了⼦树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进⾏划分,默认是2。
如果样本量不⼤,不需要管这个值。如果样本量数量级⾮常⼤,则推荐增⼤这个值。
min_samples_leaf 叶⼦节点的最⼩样本数
这个值限制了叶⼦节点最少的样本数,如果某叶⼦节点数⽬⼩于样本数,则会和兄弟节点⼀起被剪枝,默认是1。
叶是决策树的末端节点。 较⼩的叶⼦使模型更容易捕捉训练数据中的噪声。
⼀般来说,我更偏向于将最⼩叶⼦节点数⽬设置为⼤于50。
min_impurity_split: 节点划分最⼩不纯度
这个值限制了决策树的增⻓,如果某节点的不纯度(基于基尼系数,均⽅差)⼩于这个阈值,则该节点不再⽣成⼦节点。即为叶⼦节点 。
⼀般不推荐改动默认值1e-7。
上⾯决策树参数中最重要的包括
最⼤特征数max_features,
最⼤深度max_depth,
内部节点再划分所需最⼩样本数min_samples_split
叶⼦节点最少样本数min_samples_leaf。
五、随机森林的优缺点
优点:
1.准确率高:通常优于单一决策树,甚至在很多情况下表现优于 SVM、神经网络等算法
2. 抗过拟合能力强:通过多棵树的集成,有效降低了过拟合风险
3. 处理高维数据能力强:不需要特征选择,可以自动处理高维数据
4. 能处理非线性数据:无需对数据进行复杂转换
5. 对缺失值不敏感:有较好的容错能力
6. 可以评估特征重要性:帮助理解数据
缺点:
计算成本高:训练时间和内存消耗较大(因多棵决策树)
解释性较弱:模型解释性较差(“黑盒”特性),虽然单棵决策树易解释,但 "森林" 的整体决策过程难以可视化(可通过特征重要性部分弥补);
对超高维稀疏数据(如文本)可能不如线性模型高效。
六、垃圾邮件判断案例
1.数据集介绍
我们使用的是经典的spambase.csv数据集,该数据集包含了 4601 条邮件记录,每条记录有 57 个特征和 1 个标签。这些特征主要包括:
邮件中某些特定单词出现的频率
某些特定字符出现的频率
邮件的平均长度、最长连续大写字母长度等
标签为 0(正常邮件)或 1(垃圾邮件),我们的目标是根据这些特征预测一封邮件是否为垃圾邮件。
2.代码解析
(1) 导入必要的库
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split这部分代码导入了后续需要用到的库:
• RandomForestClassifier:随机森林分类器,是我们要使用的核心算法
• metrics:sklearn 中的评估指标模块,用于模型性能评估
• pandas:数据处理库,用于读取和处理数据
• matplotlib.pyplot:绘图库,用于可视化特征重要性
• train_test_split:用于将数据集分割为训练集和测试集
(2) 数据读取与准备
data = pd.read_csv('spambase.csv')使用 pandas 的read_csv函数读取垃圾邮件数据集spambase.csv,将其存储在data变量中,这是一个 DataFrame 对象。
X = data.iloc[:, :-1]
y = data.iloc[:, -1]X = data.iloc[:, :-1]:提取所有行,除最后一列外的所有列作为特征数据(特征矩阵)
y = data.iloc[:, -1]:提取所有行的最后一列作为标签数据(目标变量),其中 1 表示垃圾邮件,0 表示正常邮件
(3) 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)使用train_test_split函数将数据集划分为训练集和测试集
• test_size=0.2:表示测试集占总数据的 20%,训练集占 80%
• random_state=100:设置随机种子,确保每次运行代码时得到相同的划分结果,保证实验的可重复性
• 返回的四个变量分别是:训练特征、测试特征、训练标签、测试标签
(4)创建并训练随机森林模型
rf = RandomForestClassifier(n_estimators=100, max_depth=10, min_samples_split=3)创建随机森林分类器实例,并设置超参数:
• n_estimators=100:森林中包含 100 棵决策树
• max_depth=10:每棵树的最大深度限制为 10,防止树过度生长导致过拟合
• min_samples_split=3:节点分裂所需的最小样本数为 3,即当节点样本数少于 3 时不再分裂
rf.fit(x_train, y_train)使用训练集对模型进行训练,fit方法会根据输入的训练数据调整模型参数,使模型能够学习到特征与标签之间的关系。
(5) 模型预测与评估
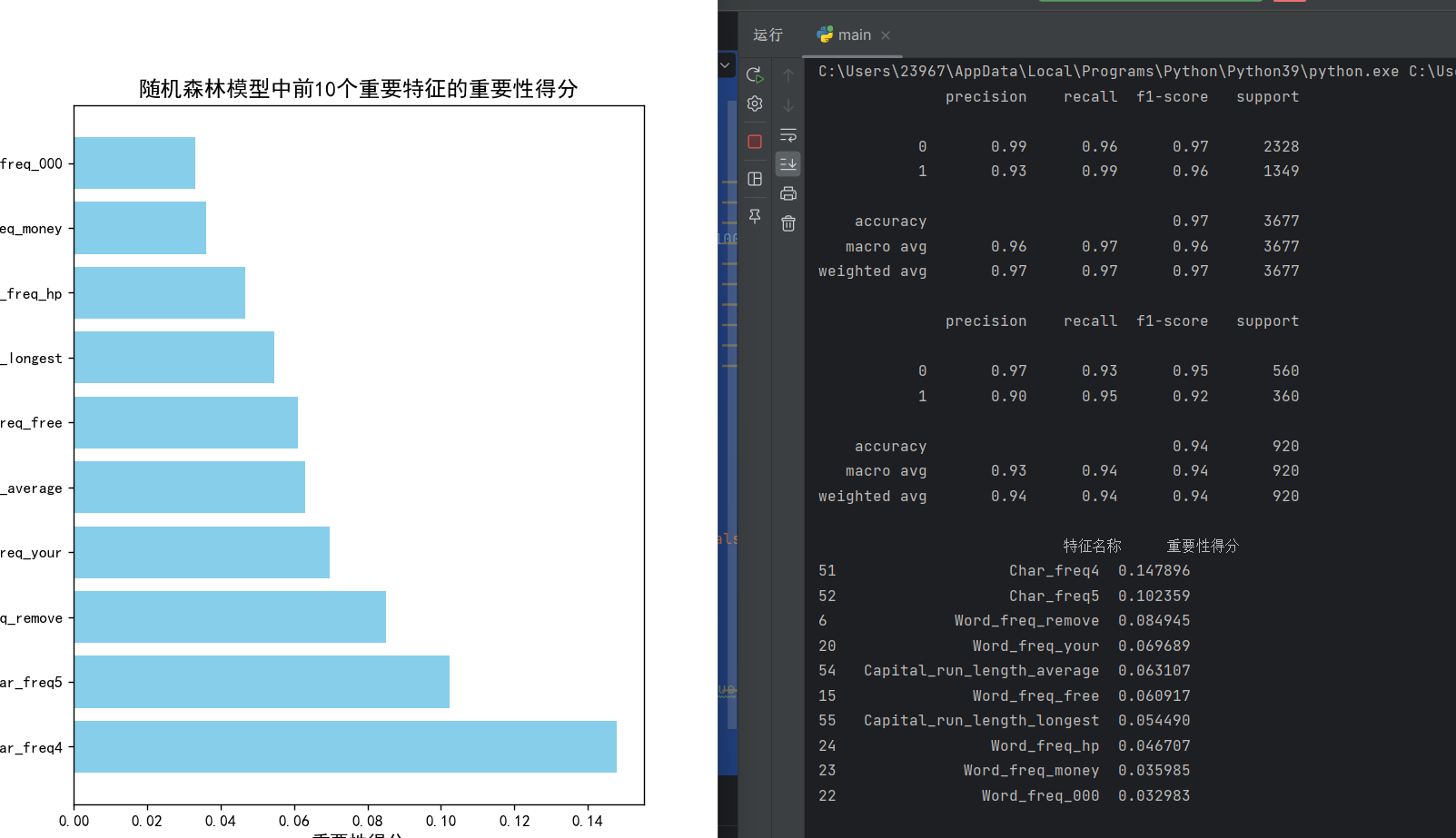
predict = rf.predict(x_train)
print(metrics.classification_report(predict, y_train))- 用训练好的模型对训练集进行预测,得到预测结果
predict - 使用
classification_report生成详细的分类评估报告,包括精确率(precision)、召回率(recall)、F1 分数(f1-score)和支持度(support) - 这一步主要是查看模型在训练数据上的表现,判断是否存在欠拟合
predict1 = rf.predict(x_test)
print(metrics.classification_report(predict1, y_test))用模型对测试集进行预测,得到预测结果predict1
• 同样生成分类评估报告,这是评估模型泛化能力的关键步骤
• 比较训练集和测试集的评估结果,可以判断模型是否过拟合
(6) 特征重要性分析
feature_names = X.columns
feature_importance = pd.DataFrame({'特征名称': feature_names,'重要性得分': rf.feature_importances_
})X.columns获取所有特征的名称
• 创建一个 DataFrame 来存储特征名称及其对应的重要性得分
• rf.feature_importances_获取随机森林计算出的各特征重要性得分,得分越高表示该特征对分类结果的影响越大
feature_importance = feature_importance.sort_values(by='重要性得分', ascending=False)
print(feature_importance.head(10))按 "重要性得分" 降序排列特征
打印出前 10 个最重要的特征,帮助我们理解哪些特征对垃圾邮件分类最关键
(7)特征重要性可视化
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False设置 matplotlib 的字体参数,确保中文能正常显示,避免负号显示异常。
top_features = feature_importance.head(10)
plt.figure(figsize=(12, 8))
bars = plt.barh(top_features['特征名称'], top_features['重要性得分'], color='skyblue')
plt.title('随机森林模型中前10个重要特征的重要性得分', fontsize=14)
plt.xlabel('重要性得分', fontsize=12)
plt.ylabel('特征名称', fontsize=12)
plt.show()提取前 10 个最重要的特征
创建一个大小为 12x8 的图形
使用水平条形图barh可视化这些特征的重要性得分
设置图表标题、x 轴标签和 y 轴标签
plt.show()显示图表
完整代码如下:
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
data=pd.read_csv('spambase.csv')
X=data.iloc[:,:-1]
y=data.iloc[:,-1]
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=100)
rf=RandomForestClassifier(n_estimators=100,max_depth=10,min_samples_split=3)
rf.fit(x_train,y_train)
predict=rf.predict(x_train)
print(metrics.classification_report(predict,y_train))
predict1=rf.predict(x_test)
print(metrics.classification_report(predict1,y_test))
feature_names = X.columns
feature_importance = pd.DataFrame({'特征名称': feature_names,'重要性得分': rf.feature_importances_
})
feature_importance = feature_importance.sort_values(by='重要性得分', ascending=False)
print(feature_importance.head(10))
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
top_features = feature_importance.head(10)
plt.figure(figsize=(12, 8))
bars = plt.barh(top_features['特征名称'], top_features['重要性得分'], color='skyblue')
plt.title('随机森林模型中前10个重要特征的重要性得分', fontsize=14)
plt.xlabel('重要性得分', fontsize=12)
plt.ylabel('特征名称', fontsize=12)
plt.show()