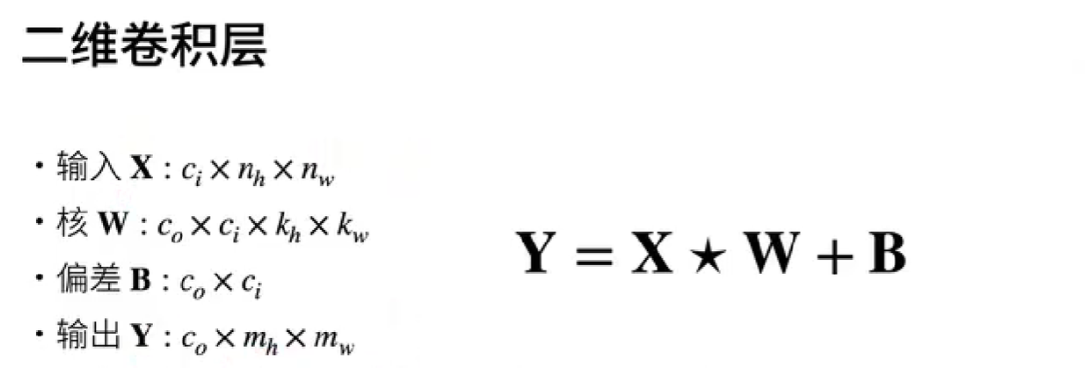深度学习-卷积神经网络CNN-多输入输出通道
每个图像有多个通道和多层卷积层。例如彩色图像具有标准的RGB通道来代表红、绿和蓝。 但是到目前为止(详细见前面几章知识点),我们仅展示了单个输入和单个输出通道的简化例子。 这使得我们可以将输入、卷积核和输出看作二维张量。
当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量。例如,每个RGB输入图像具有 3*h*w 的形状。
我们将这个大小为的轴称为通道(channel)维度。本节将更深入地研究具有多输入和多输出通道的卷积核。

1. 多输入通道
以彩色图像为例,包含三个通道,分别表示RGB三原色的像素值,输入为(3,5,5),分别表示3个通道,每个通道的高和宽都是5。假设卷积核只有1个,卷积核通道为3,每个通道的卷积核大小仍为3x3,padding=0,stride=1。
卷积过程如下,每一个通道的像素值与对应的卷积核通道的数值进行卷积,因此每一个通道会对应一个输出卷积结果,三个卷积结果对应位置累加求和,得到最终的卷积结果(这里卷积输出结果通道只有1个,因为卷积核只有1个。卷积多输出通道下面会继续讲到)。
可以这么理解:最终得到的卷积结果是原始图像各个通道上的综合信息结果。
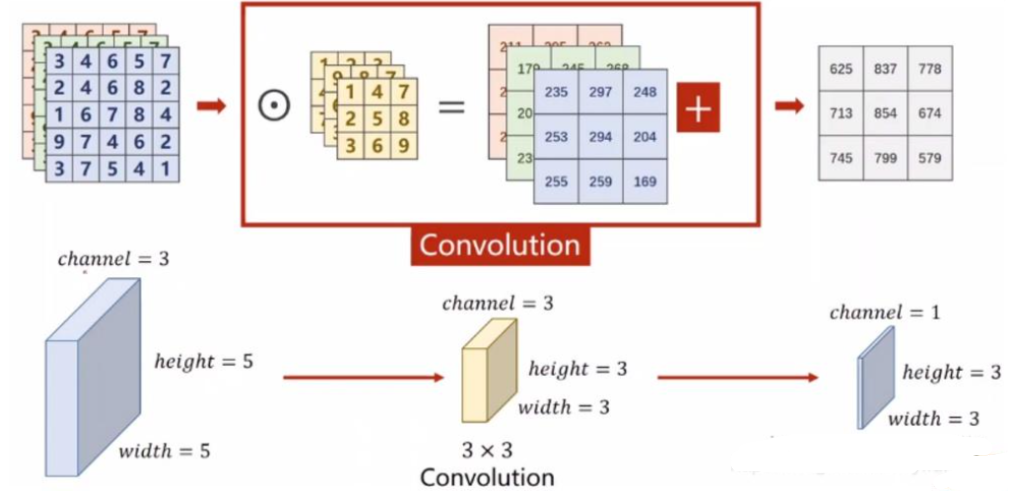
多通道卷积过程:输入一张三通道的图片,这时有多个卷积核进行卷积,并且每个卷积核都有三通道,分别对这张输入图片的三通道进行卷积操作。每个卷积核,分别输出三个通道,这三个通道进行求和,得到一个featuremap。
有多少个卷积核,就有多少个featuremap,代表提取出来的一个特征。
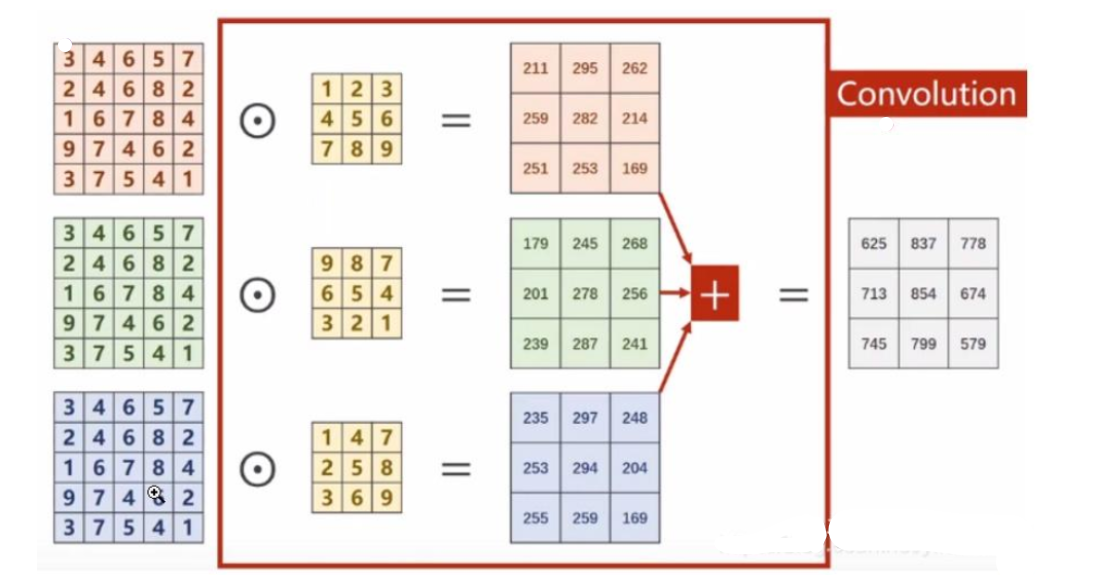
上述过程中,每一个卷积核的通道数量,必须要求与输入通道数量一致,因为要对每一个通道的像素值要进行卷积运算,所以每一个卷积核的通道数量必须要与输入通道数量保持一致。
我们把上述图像通道如果放在一块,计算原理过程还是与上面一样,堆叠后的表示如下:
代码示例如下:【代码源自《动手学深度学习》】
import torch
from d2l import torch as d2ldef corr2d_multi_in(X, K):# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])corr2d_multi_in(X, K)输出:
tensor([[ 56., 72.],[104., 120.]])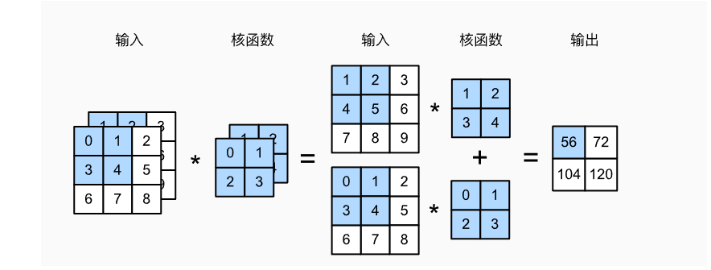
2.多输出通道

如果要卷积后也输出多通道,增加卷积核(filers)的数量即可,示意图如下:
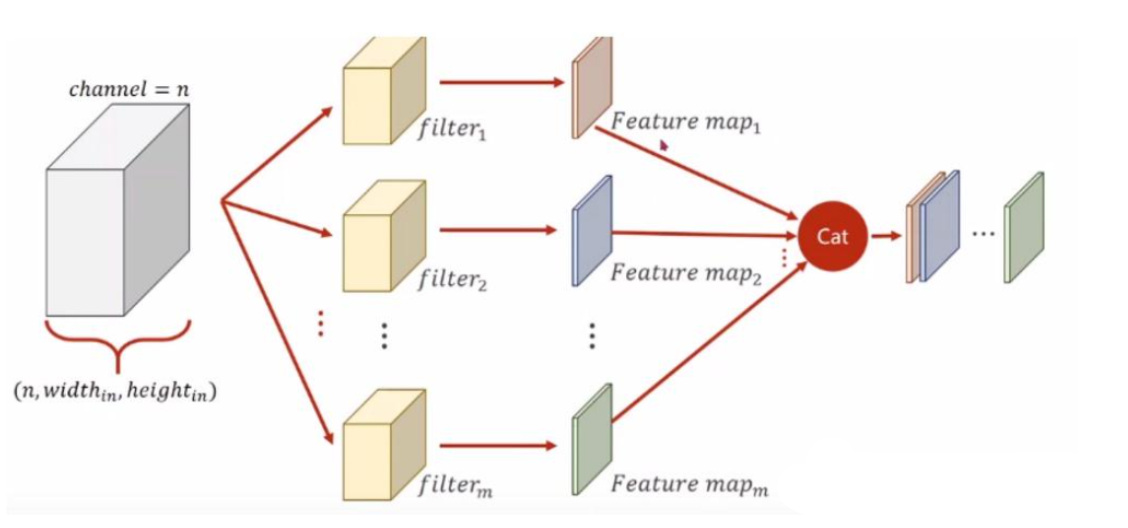
代码示例如下:【代码源自《动手学深度学习》】
def corr2d_multi_in_out(X, K):# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。# 最后将所有结果都叠加在一起return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
K = torch.stack((K, K + 1, K + 2), 0)
K.shape输出:torch.Size([3, 2, 2, 2])
corr2d_multi_in_out(X, K)计算结果如下:
tensor([[[ 56., 72.],[104., 120.]],[[ 76., 100.],[148., 172.]],[[ 96., 128.],[192., 224.]]])总结: