《算法导论》第 7 章 - 快速排序

大家好!今天我们来深入学习《算法导论》第 7 章的内容 —— 快速排序(QuickSort)。快速排序是一种经典的分治算法,以其平均时间复杂度优秀、原地排序(空间效率高)等特点,在实际应用中被广泛使用。本文将按照原书结构,详细讲解快速排序的原理、性能分析、随机化版本,并提供完整可运行的 C++ 代码实现。

7.1 快速排序的描述
快速排序的核心思想是分治(Divide and Conquer),其工作过程主要分为三个步骤:
- 分解(Divide):选择一个基准元素(pivot),将数组分为两部分,使得左半部分的元素都小于等于基准元素,右半部分的元素都大于等于基准元素。
- 解决(Conquer):递归地对左右两部分数组进行快速排序。
- 合并(Combine):由于排序是原地进行的,不需要额外的合并操作。
核心步骤:PARTITION(划分)操作
划分是快速排序的关键,其目标是选择一个基准元素,然后重排数组,使得基准元素左侧的元素都不大于它,右侧的元素都不小于它。
伪代码(来自《算法导论》)
PARTITION(A, low, high)pivot = A[high] // 选择最右侧元素作为基准i = low - 1 // i是小于等于基准区域的边界for j = low to high - 1if A[j] <= pivoti = i + 1交换A[i]和A[j]交换A[i+1]和A[high] // 将基准元素放到正确位置return i + 1 // 返回基准元素的索引
QUICKSORT(A, low, high)if low < highq = PARTITION(A, low, high)QUICKSORT(A, low, q-1)QUICKSORT(A, q+1, high)
C++ 代码实现
下面是快速排序的完整 C++ 实现,包含划分函数和递归排序函数,并附带测试用例:
#include <iostream>
#include <vector>
using namespace std;/*** @brief 划分函数:将数组A[low..high]划分为两部分,返回基准元素的索引* @param A 待划分的数组* @param low 划分的起始索引* @param high 划分的结束索引(基准元素初始位置)* @return 基准元素最终的索引位置*/
int partition(vector<int>& A, int low, int high) {int pivot = A[high]; // 选择最右侧元素作为基准int i = low - 1; // i标记小于等于基准区域的边界(初始为-1,即空)// 遍历数组,将小于等于基准的元素放到左侧区域for (int j = low; j < high; ++j) {if (A[j] <= pivot) {i++; // 扩展左侧区域swap(A[i], A[j]); // 将当前元素加入左侧区域}}// 将基准元素放到左侧区域的右侧(即正确位置)swap(A[i + 1], A[high]);return i + 1; // 返回基准元素的索引
}/*** @brief 快速排序递归函数* @param A 待排序的数组* @param low 排序的起始索引* @param high 排序的结束索引*/
void quickSort(vector<int>& A, int low, int high) {if (low < high) { // 递归终止条件:子数组长度为1或0时无需排序// 划分数组,得到基准元素位置qint q = partition(A, low, high);// 递归排序左侧子数组(小于等于基准的部分)quickSort(A, low, q - 1);// 递归排序右侧子数组(大于基准的部分)quickSort(A, q + 1, high);}
}// 测试函数
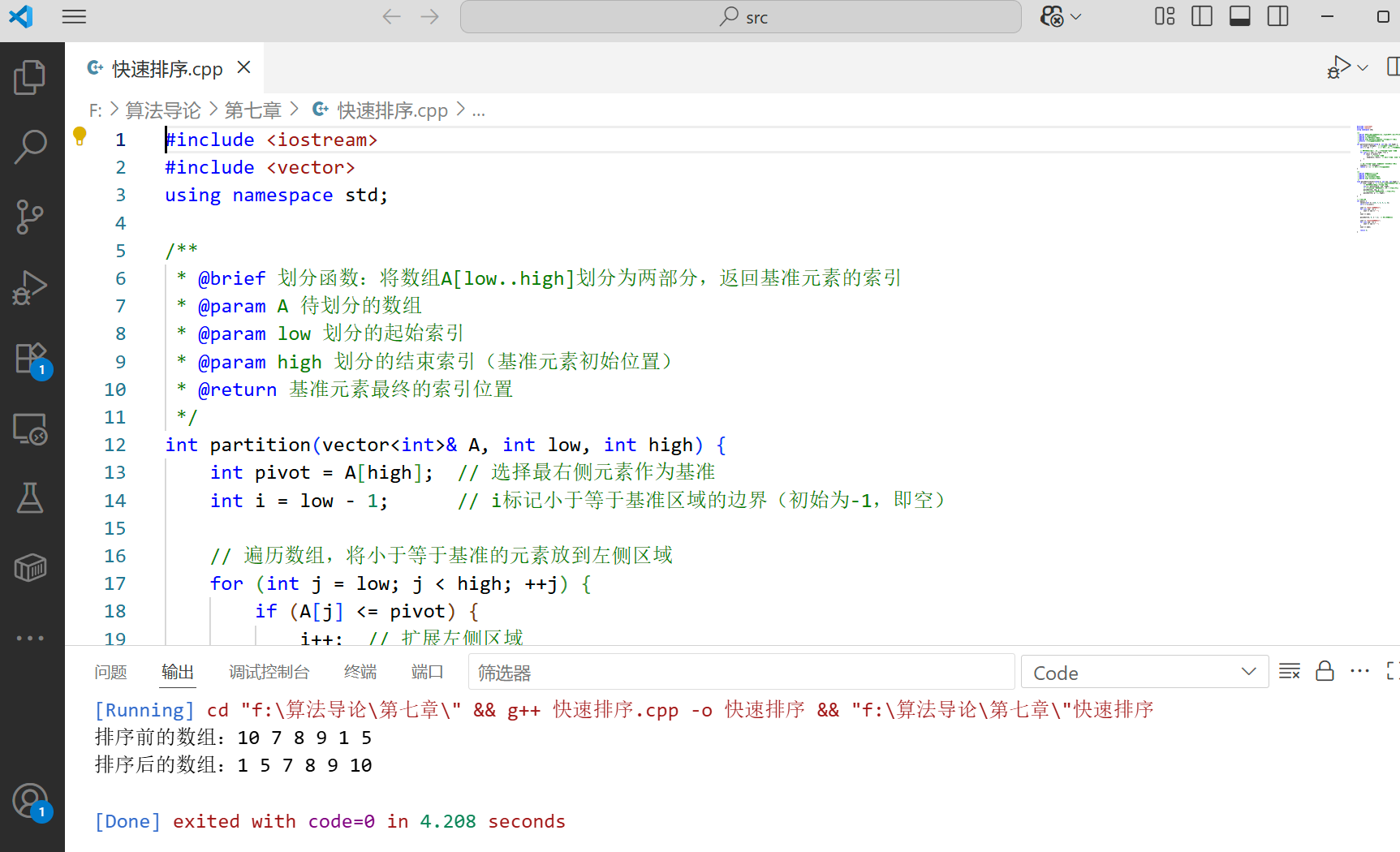
int main() {vector<int> A = {10, 7, 8, 9, 1, 5};int n = A.size();cout << "排序前的数组:";for (int num : A) {cout << num << " ";}cout << endl;quickSort(A, 0, n - 1); // 调用快速排序cout << "排序后的数组:";for (int num : A) {cout << num << " ";}cout << endl;return 0;
}
运行结果:
7.2 快速排序的性能
快速排序的性能取决于划分的平衡性—— 即划分后左右两个子数组的规模是否接近。
三种常见情况的时间复杂度
| 情况 | 划分特点 | 时间复杂度 |
|---|---|---|
| 最好情况 | 每次划分都平衡(左右子数组规模接近) | O(n log n) |
| 最坏情况 | 每次划分都极不平衡(如一侧为空) | O(n²) |
| 平均情况 | 随机划分下的期望性能 | O(n log n) |
性能分析说明
- 最好情况:当每次划分都将数组分为规模大致相等的两部分时,递归树的深度为 O (log n),每层的总操作时间为 O (n),因此总时间为 O (n log n)。
- 最坏情况:当数组已经有序(或逆序),且选择最右侧元素为基准时,每次划分后右侧子数组为空,左侧子数组规模为 n-1。此时递归树退化为单链,总时间为 O (n²)。
- 平均情况:通过概率分析可知,即使划分不是完全平衡的,快速排序的期望时间复杂度仍为 O (n log n),且常数因子较小,实际性能优于堆排序等其他 O (n log n) 算法。
7.3 快速排序的随机化版本
为了避免最坏情况(尤其是在数组有序时),可以采用随机化选择基准的策略:从数组中随机选择一个元素作为基准,而非固定选择最右侧元素。这能保证在概率意义上,划分的平衡性不受输入数据分布的影响。
随机化划分的 C++ 实现
#include <iostream>
#include <vector>
#include <cstdlib> // 用于rand()和srand()
#include <ctime> // 用于time()
using namespace std;/*** @brief 划分函数:将数组A[low..high]划分为两部分,返回基准元素的索引* @param A 待划分的数组* @param low 划分的起始索引* @param high 划分的结束索引(基准元素初始位置)* @return 基准元素最终的索引位置*/
int partition(vector<int>& A, int low, int high) {int pivot = A[high]; // 选择最右侧元素作为基准int i = low - 1; // i标记小于等于基准区域的边界(初始为-1,即空)// 遍历数组,将小于等于基准的元素放到左侧区域for (int j = low; j < high; ++j) {if (A[j] <= pivot) {i++; // 扩展左侧区域swap(A[i], A[j]); // 将当前元素加入左侧区域}}// 将基准元素放到左侧区域的右侧(即正确位置)swap(A[i + 1], A[high]);return i + 1; // 返回基准元素的索引
}/*** @brief 随机选择基准并交换到末尾,然后执行划分* @param A 待划分的数组* @param low 划分的起始索引* @param high 划分的结束索引* @return 基准元素最终的索引位置*/
int randomizedPartition(vector<int>& A, int low, int high) {// 只需要初始化一次随机数种子,放在函数外或只调用一次static bool initialized = false;if (!initialized) {srand(time(0)); // 初始化随机数种子initialized = true;}// 生成[low, high]范围内的随机索引int randomIndex = low + rand() % (high - low + 1);// 将随机选择的元素与最右侧元素交换(作为新的基准)swap(A[randomIndex], A[high]);// 调用普通划分函数return partition(A, low, high); // 现在partition函数已定义
}/*** @brief 随机化快速排序递归函数* @param A 待排序的数组* @param low 排序的起始索引* @param high 排序的结束索引*/
void randomizedQuickSort(vector<int>& A, int low, int high) {if (low < high) {int q = randomizedPartition(A, low, high); // 使用随机化划分randomizedQuickSort(A, low, q - 1);randomizedQuickSort(A, q + 1, high);}
}// 测试函数
int main() {vector<int> A = {1, 2, 3, 4, 5, 6}; // 有序数组(易触发普通快排的最坏情况)int n = A.size();cout << "排序前的数组(有序):";for (int num : A) {cout << num << " ";}cout << endl;randomizedQuickSort(A, 0, n - 1); // 调用随机化快速排序cout << "排序后的数组:";for (int num : A) {cout << num << " ";}cout << endl;// 再测试一个随机数组vector<int> B = {9, 3, 7, 5, 1, 8, 2, 4, 6};cout << "\n另一个数组排序前:";for (int num : B) {cout << num << " ";}cout << endl;randomizedQuickSort(B, 0, B.size() - 1);cout << "另一个数组排序后:";for (int num : B) {cout << num << " ";}cout << endl;return 0;
}
运行结果:
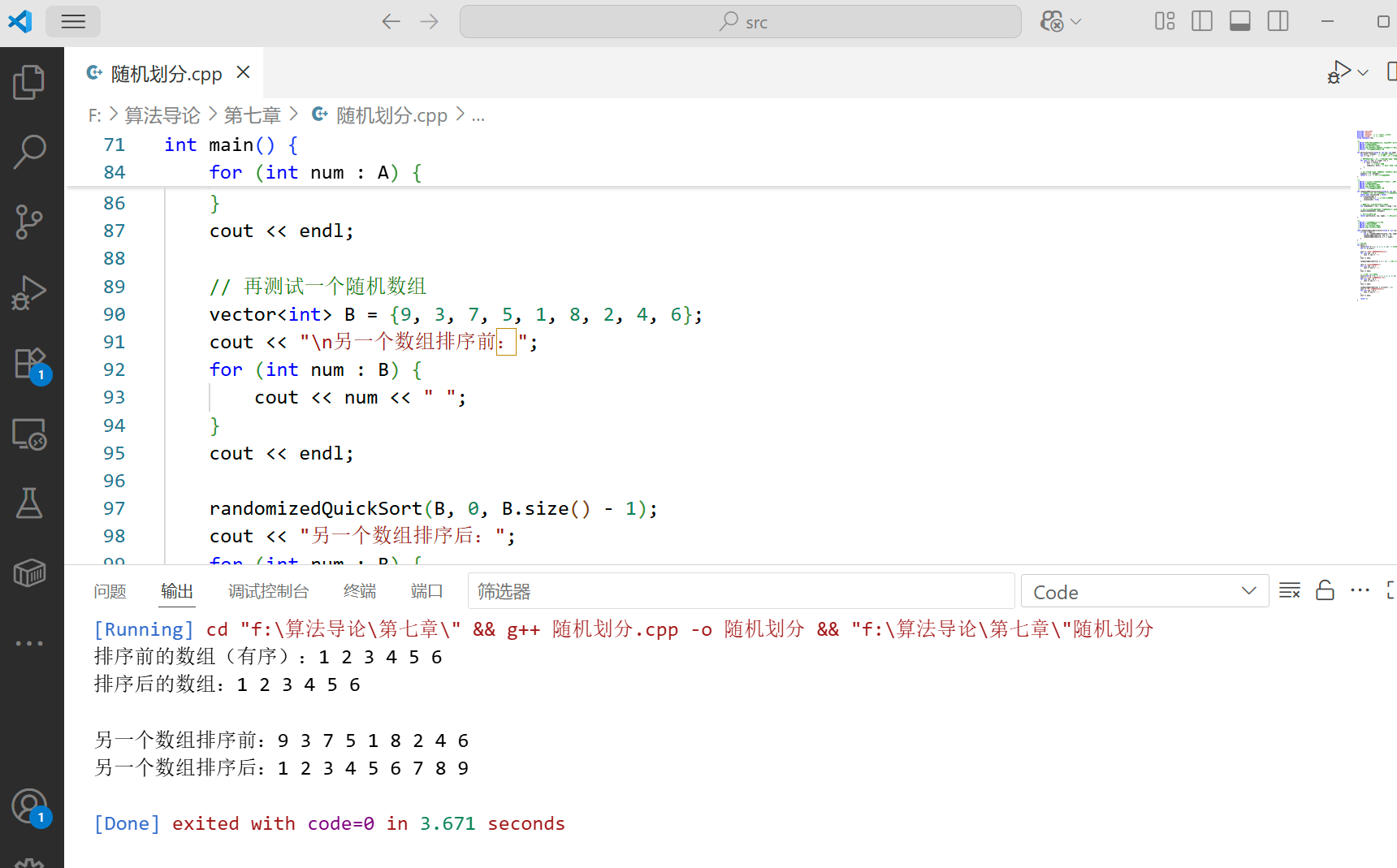
说明:对于有序数组,随机化版本通过随机选择基准,避免了每次划分都极不平衡的情况,将时间复杂度稳定在 O (n log n) 级别。
7.4 快速排序分析
7.4.1 最坏情况分析
最坏情况发生在每次划分都将数组分为规模为 0 和 n-1 的两部分(即基准是当前子数组的最大或最小元素)。此时递归式为:
T (n) = T (n-1) + T (0) + O (n)
由于 T (0) = O (1),递归式可简化为:
T (n) = T (n-1) + O (n)
展开递归式:
T (n) = T (n-1) + O (n)
= T (n-2) + O (n-1) + O (n)
= ...
= O (1) + O (2) + ... + O (n)
= O (n²)
7.4.2 期望运行时间
随机化快速排序的期望运行时间分析基于指示器随机变量和线性期望。核心结论是:
- 对于规模为 n 的数组,随机化快速排序的期望运行时间为 O (n log n)。
关键思路:
- 定义指示器随机变量 X_{ij}:表示元素 A [i] 和 A [j](i < j)在排序过程中是否被比较。
- 总比较次数 X = ΣΣX_{ij}(i < j)。
- 计算 E [X] = ΣΣE [X_{ij}],通过分析可知每个 E [X_{ij}] = 2/(j-i+1)。
- 求和后得到 E [X] = O (n log n),因此期望运行时间为 O (n log n)。
思考题
1. 如何优化快速排序以处理小数组?
提示:当子数组规模较小时(如 n ≤ 10),插入排序的性能可能优于快速排序(因为快速排序的递归开销在小数组上占比更大)。可在快速排序中设置阈值,当子数组规模小于阈值时改用插入排序。
优化代码示例:
// 插入排序函数(用于小数组优化)
void insertionSort(vector<int>& A, int low, int high) {for (int i = low + 1; i <= high; ++i) {int key = A[i];int j = i - 1;while (j >= low && A[j] > key) {A[j + 1] = A[j];j--;}A[j + 1] = key;}
}// 优化的快速排序(结合插入排序)
void optimizedQuickSort(vector<int>& A, int low, int high) {const int THRESHOLD = 10; // 阈值,小于该值时用插入排序if (high - low + 1 <= THRESHOLD) {insertionSort(A, low, high);} else if (low < high) {int q = randomizedPartition(A, low, high);optimizedQuickSort(A, low, q - 1);optimizedQuickSort(A, q + 1, high);}
}
2. 如何实现三路快速排序(处理重复元素)?
提示:当数组中存在大量重复元素时,普通快速排序会将数组分为 “小于” 和 “大于” 两部分,而重复元素可能被多次划分。三路快速排序将数组分为 “小于”“等于”“大于” 三部分,避免重复元素的递归处理。
三路快排代码示例:
/*** @brief 三路快速排序(处理重复元素)* @param A 待排序的数组* @param low 起始索引* @param high 结束索引*/
void threeWayQuickSort(vector<int>& A, int low, int high) {if (low >= high) return;// 随机选择基准srand(time(0));int randomIndex = low + rand() % (high - low + 1);swap(A[randomIndex], A[low]);int pivot = A[low];int lt = low; // lt左侧元素均小于pivotint gt = high; // gt右侧元素均大于pivotint i = low + 1; // 当前遍历的元素while (i <= gt) {if (A[i] < pivot) {swap(A[lt++], A[i++]);} else if (A[i] > pivot) {swap(A[i], A[gt--]);} else {i++; // 等于pivot的元素不交换,直接跳过}}// 递归排序小于和大于pivot的部分(等于的部分已就位)threeWayQuickSort(A, low, lt - 1);threeWayQuickSort(A, gt + 1, high);
}

本章注记
- 快速排序由计算机科学家 Tony Hoare 于 1960 年提出,其原地排序特性和优秀的平均性能使其成为实际应用中最常用的排序算法之一(如 C++ 的
std::sort通常采用快速排序的变种)。 - 实际应用中,快速排序的变种(如 introsort)会结合堆排序处理最坏情况,进一步优化性能。
- 快速排序的空间复杂度为 O (log n)(递归栈开销),最坏情况下为 O (n),但通过尾递归优化可将空间复杂度降至 O (log n)。

总结
本文详细讲解了快速排序的原理、性能分析和实现方法,包括:
- 快速排序的分治思想和划分操作;
- 不同情况下的时间复杂度(最好 O (n log n)、最坏 O (n²)、平均 O (n log n));
- 随机化版本的实现(避免最坏情况);
- 优化技巧(结合插入排序、三路快排)。

快速排序的核心优势在于平均性能优异且原地排序,是处理大规模数据排序的首选算法之一。建议大家动手实现代码,感受其效率和分治思想的魅力!

如果有任何问题或建议,欢迎在评论区留言讨论~