机器学习之线性回归与逻辑回归
本文章所介绍的机器学习算法在演示过程中使用的API都基于sklearn库
一、线性回归
在之前的算法介绍中主要介绍了分类算法,这些分类算法的目标变量大多是标称型数据,回归则是对连续型数据做出预测。
标称型数据:表示类别或标签,没有大小、顺序之分。只能进行“是否相同”的判断,无法进行排序、加减等数值操作。
例如:性别–男 / 女
连续性数据:数值型数据,可以在某个区间内取无限多的值。可以进行加减乘除等数学运算,有大小和顺序关系。
例如:身高–175.5 cm
1.概念
我们先说回归。什么是回归呢?回归其实就是预测数值型的目标值y。
简单的来说,回归就好比我们中学时期学过的函数,我们已知函数的公式,即使给我们一个没有见过的变量x,我们也能根据x求出y的值,这就是回归。
线性回归是最基本的回归方法,它假设输入特征与目标变量之间存在线性关系,并尝试用一个线性函数来拟合这些数据点。
例如:
我们已知x和y,能够在一个二维坐标系上找出对应的坐标点。
y=kx+b
y = kx+b
y=kx+b
要通过找出斜率k和一个常数b来确定一条直线,这条直线通过我们前面找出的坐标点。
这就是线性回归的本质,但是需要注意的是:
- 我们通常用w来表式这个斜率,并非用k。
- 上述求解k和b是理想型的数学逻辑,在人工智能领域,数据集中往往找不到一个完美的方程来满足所有的目标y。
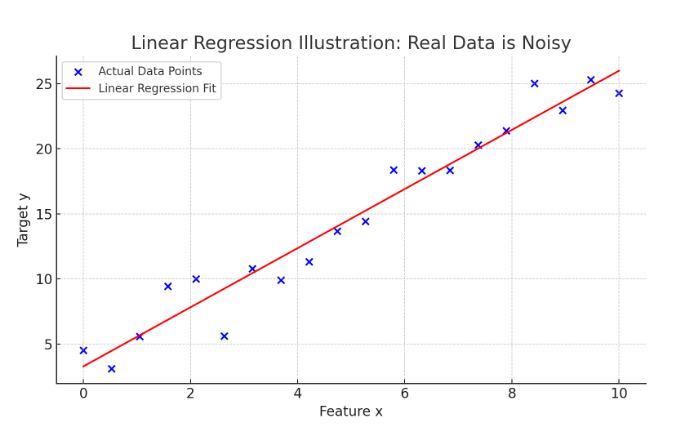
2.损失函数
我们在前面已经提到:往往我们找不到一条完美的方程满足所有的目标y。因此我们引入一个新的概念——损失函数。
损失函数衡量的是模型预测值 yyy '与真实值 y 之间的差距。
- 损失越小,说明模型预测越准确;
- 损失越大,说明预测效果差,需要优化模型参数。
这里列举一些回归任务中常用的损失函数:
| 损失函数 | 表达式 | 说明 |
|---|---|---|
| 均方误差(MSE) | MSE=1n∑(yi−y^i)2MSE=\frac{1}{n} \sum (y_i - \hat{y}_i)^2MSE=n1∑(yi−y^i)2 | 对大误差敏感,常用于线性回归 |
| 均绝对误差(MAE) | (MAE=1n∑i=1nyi−y^i( \text{MAE} = \frac{1}{n} \sum_{i=1}^{n}y_i-\hat{y}_i(MAE=n1∑i=1nyi−y^i | |
| Huber损失 | 分段函数,结合了 MSE 与 MAE 的优点 | 对小误差使用 MSE,大误差使用 MAE,平衡鲁棒性与可导性 |
| 对数双曲余弦损失(Log-Cosh) | LogCosh=∑i=1nlog(cosh(yi−y^i))LogCosh=\sum_{i=1}^{n}log(cosh(y_i−\hat{y}_i))LogCosh=∑i=1nlog(cosh(yi−y^i)) | 类似 MSE,但更平滑,兼顾稳定性和优化性 |
下面我们基于MSE介绍损失函数。
y=wx+by=wx+by=wx+b
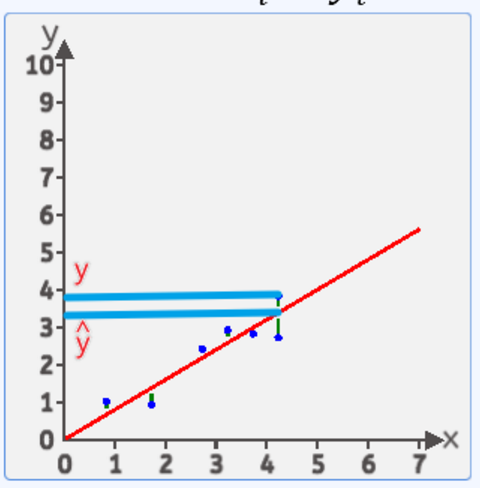
对于这张图里的这条直线:每个yyy与y^\hat{y}y^的差值为误差,将每个点的差值平方求和再平均,我们就能得到误差的均方差。而这个均方差我们用eˉ\bar{e}eˉ表示,并且,能够使用www写出一个公式表示这个eˉ\bar{e}eˉ:
eˉ=1n∑i=1n(yi−wxi−b)2\bar e = \frac{1}{n} \textstyle\sum_{i=1}^{n}(y_{i}-w x_{i} - b)^{2}eˉ=n1∑i=1n(yi−wxi−b)2
这个函数就称为损失函数。
当损失函数的值最低时,这个www就是这个直线的最佳www。
所以总结一下:线性回归的任务就是拟合一个数学函数,这个函数里面的www要根据训练集里给出的数据计算出来,计算这个www所用到的就是损失函数,即当损失函数的值最小时的www。
3.多参数回归
上述我们提到的案例只用到了一个xxx(就是一个特征),那么如果有很多个xxx怎么办呢?
在线性回归中解决这个问题用的是矩阵的思想。
我们将每一个特征当作一个列向量,每一个样本最为一行,得到的就是一个样本数为mmm,特征数量为nnn的m∗nm*nm∗n矩阵;每个特征xxx的特征系数www组成一个列向量,用这个列向量去左乘前面的m∗nm*nm∗n矩阵就得到了我们的预测结果,这个预测结果还是一个列向量,即一个m∗1m*1m∗1的矩阵。
例如:
X=X=X=(014805−29−31−41064−14−2−1481−1−65−123−32−215−23105114−81−15−15−8−157−4−122111−10−243−9−671−1404−35101371−3−7−2−80−6−5−91)\begin{pmatrix} 0& 14& 8& 0& 5& -2& 9& -3&1 \\ -4& 10& 6& 4& -14& -2& -14& 8&1\\-1& -6& 5& -12& 3& -3& 2& -2&1\\5& -2& 3& 10& 5& 11& 4& -8&1\\-15& -15& -8& -15& 7& -4& -12& 2&1\\11& -10& -2& 4& 3& -9& -6& 7&1\\-14& 0& 4& -3& 5& 10& 13& 7&1\\-3& -7& -2& -8& 0& -6& -5& -9&1\end{pmatrix}0−4−15−1511−14−31410−6−2−15−100−78653−8−24−204−1210−154−3−85−14357350−2−2−311−4−910−69−1424−12−613−5−38−2−8277−911111111
W=(w1w2w3w4w5w6w7w8w0)W=\begin{pmatrix} w_1&\\ w_2&\\ w_3&\\ w_4&\\ w_5&\\ w_6&\\ w_7&\\ w_8&\\w_0\end{pmatrix}W=w1w2w3w4w5w6w7w8w0
y=(339−11430126−395−87422−309)y=\begin{pmatrix} 339&\\ -114&\\ 30&\\ 126&\\ -395&\\ -87&\\ 422&\\ -309 \\\end{pmatrix}y=339−11430126−395−87422−309
这里的数据只是作为上述思路的参考,无实际意义。
4.梯度下降
1.概念
梯度下降(Gradient Descent)是一种优化算法,其核心思想是通过不断迭代地调整参数,使目标函数(通常是损失函数)逐步趋向最小值。
在线性回归、逻辑回归、神经网络、支持向量机等众多机器学习与人工智能算法中,梯度下降几乎是不可或缺的工具。在训练模型时,我们往往无法直接知道使损失函数最小的那组参数(比如线性回归中的权重 www 和偏置 bbb),而梯度下降就充当了“向导”的角色,帮助我们一步一步逼近最优解。
梯度下降的重要性在于它为高维空间中的优化问题提供了一种通用、可计算、可迭代的解法,不仅在回归任务中用于最小化误差,在深度学习中也用于训练神经网络中成千上万个参数,从而让模型具备预测、识别、生成等智能能力。因此,梯度下降不仅是一个算法,更是一种构建整个机器学习和人工智能系统的基础工具。
2.梯度下降的过程
在讲解梯度下降之前你必须要想起来之前提到过的一个知识点——“损失函数”。梯度下降的整个过程的核心点就在于在损失函数中“猜”出www。
首先,对于单特征的损失函数:
eˉ=aw2+bw+c
\bar{e}= {a w^{2}+b w+c} \\
eˉ=aw2+bw+c
我们知道,它的特征损失函数在坐标系中表示为一条抛物线,比如像这样
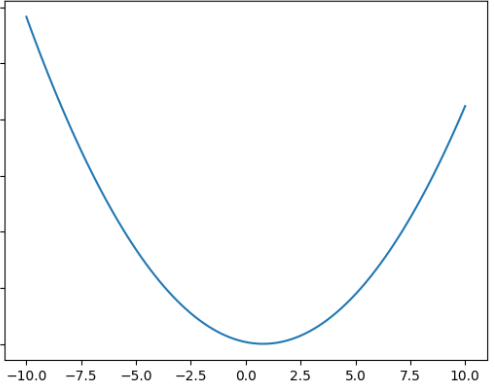
我们随机找一个www,但是我们并不知道这个点求出的误差eee是不是最小值。那么,我们仔细回忆中学中的知识,导数就解决了这一问题。
我们求出这个损失函数的导函数:
e′=2aw+b
e'=2aw+b
e′=2aw+b
再结合图我们可以知道,当这个导函数即梯度的值为0,损失函数的值最小,对应的www就是我们要求的www。
由此我们也可以看出,梯度的大小也能反映损失值的大小,梯度越大,损失值越大;梯度越小,损失值越小
但是这知识数学理论上,在实际中我们应该怎么去找这个导数值(也就是斜率为0)的点呢?
回到第一步,我们随机找一个www并在图上画出它的点和斜率
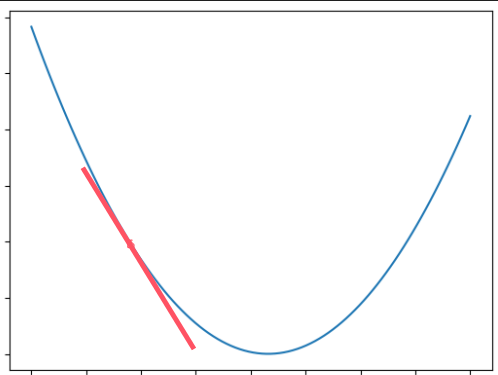
可以出此时斜率k为一个负值,由于我们要找的是最低值,所以我们在这个www的基础上猜一个比它更大的www。
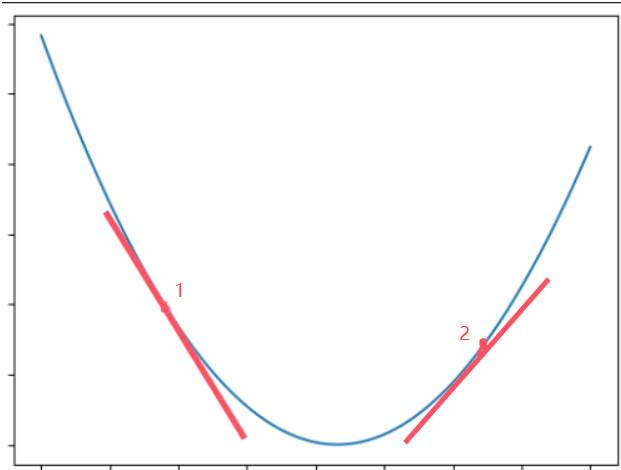
可以看到,我们第二次猜的www当前斜率k为正,说明第二次猜的www大了,我们又在此基础上往小的www猜。一直重复这两个操作,最后找到斜率为0的点,这个点的www就是我们要求的www。
这就是梯度下降的过程,实际中的最后解雇往往不是这个斜率点为0的点,而是在接近0的某一个收敛域中。
3.梯度下降的公式
接着上面的思路,我们在知道如何找www后,就会想:我要怎么有规律的找这个www从而让斜率变为0呢?
这时候,就能够用到梯度下降的公式:
wn+1=wn−α∗gradient
w_{n+1}=w_{n}-\alpha*gradient
wn+1=wn−α∗gradient
- wn+1w_{n+1}wn+1:新的www值
- α\alphaα:学习率
- gradient:当前w的导函数值(也就是斜率)
这个时候,我们就可以通过学习率来控制函数最低点www的收敛范围
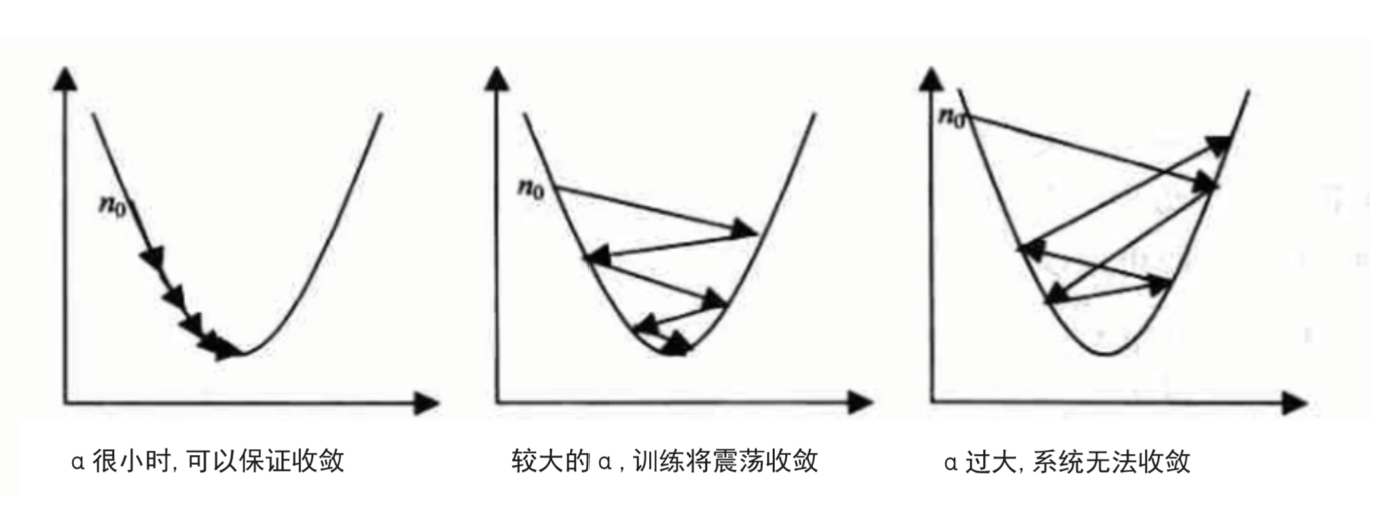
在实际的代码中,也可以设置成随着迭代次数增多学习率逐渐变小,因为越靠近山谷我们就可以步子迈小点,可以更精准的走入最低点,同时防止走过,这是一种优化思路。
有了这个逻辑,我们可以自己通过代码手动实现梯度下降
例:手动实现单个特征系数的梯度下降
import randomloss = lambda w: 10 * w**2 - 15.9*w + 6.5def grid_down(alpha,n):w = random.randint(0,20)print(w)grid = lambda w: 20 * w - 15.9for _ in range(n):w = w - grid(w) * alphareturn w, loss(w)print(grid_down(0.01,100))
# (0.7950000010602772, 0.1797499999999994)
4.多参数梯度下降
了解了单个特征,也就是只有一个www的梯度下降以后,我们尝试想象一下,如果有两个www,三个www呢?
通过上述我们知道,对于一个www而言,我们要找的就是能够使损失函数eˉ\bar eeˉ的值最小的www,那么多个www也是一样的思路,就是找到w1,w2,w3....w_1,w_2,w_3....w1,w2,w3....等多个www同时满足eˉ\bar{e}eˉ的值最小。
我们拿两个特征的例子来举例。(即只有w1和w2w_1和w_2w1和w2)
对于两个www而言,它的损失函数公式为:
LMSE(w1,w2)=1n∑i=1n(y(i)−(w1x1(i)+w2x2(i)+b))2
L_{\text{MSE}}(w_1, w_2) = \frac{1}{n} \sum_{i=1}^{n} \left( y^{(i)} - (w_1 x_1^{(i)} + w_2 x_2^{(i)} + b) \right)^2
LMSE(w1,w2)=n1i=1∑n(y(i)−(w1x1(i)+w2x2(i)+b))2
我们把w1w1w1看作变量,把w2w_2w2当作常数,对w1w_1w1求导(即对w1w_1w1求偏导),能够得到上述单特征损失函数的导函数:
e1′=2aw1+b
e'_1=2aw_1+b
e1′=2aw1+b
又对w2w_2w2求偏导,能够得到:
e2′=2aw2+b
e_2'=2aw_2+b
e2′=2aw2+b
这两个式子加起来相加就是我们的梯度值。
而梯度是有方向的,对于单个www而言,梯度就是二维坐标系中的斜率,梯度下降指的就是梯度值(斜率的绝对值)下降,下降的方向与梯度方向相反。
而对于两个www而言,我们需要单独计算w1和w2w_1和w_2w1和w2的偏导数,在几何中的表现就是用一个www作为分割线,计算另一个www的梯度,那么两个梯度合在一起就是总的梯度,梯度方向就是两个梯度方向的矢量和。而这个方向的反方向就是损失值下降的最快方向。
5.正则化
正则化一种为了防止模型训练过拟合,增强模型鲁棒性的操作,鲁棒是Robust 的音译,也就是强壮的意思。就像计算机软件在面临攻击、网络过载等情况下能够不死机不崩溃,这就是软件的鲁棒性,鲁棒性调优就是让模型拥有更好的鲁棒性,也就是让模型的泛化能力和推广能力更加的强大。
y=0.2x1+0.3x2+0.4
y=0.2x_1+0.3x_2+0.4
y=0.2x1+0.3x2+0.4
y=2x1+3x2+4 y=2x_1+3x_2+4 y=2x1+3x2+4
例如上述两个描述直线的公式,这两个方程描述的直线是同一条直线,但第一个公式的www更小,当出现某个噪点时,该噪点造成的误差也相对会减少,但是w太小时(比如都趋近0),模型就没有意义了,无法应用。
在线性回归中,由于模型复杂度过高,模型的训练结果十分显著,准确率高,同时也造成了模型完美地学习了噪点的规律,所以在实际测试的过程中的误差往往会变高,这种情况我们称之为过拟合。而L1、L2正则化的目的就是通过减小特征系数矩阵W从而提升模型的抗干扰能力、泛化能力(也就是增强鲁棒性),正则化后的模型受到噪声点的影响就会大幅减少。
正则化的公式往往是模型的损失函数加上损失公式,其中损失公式中的λ称之为惩罚系数,也称之为正则化力度。当我们将λ调高时,系数矩阵W的值也会随之降低,但是同时模型的损失值也会上升(体现在于损失值是预测值和实际值的插值,当w减小,代表着这个插值也会变大,误差就会变大),并且当λ过大时,由于W矩阵的w变得很小,就会导致模型过于简单,从而产生欠拟合。
1.lasso回归—L1正则化
lasso回归损失函数公式:
J(w)=12n∑i=1n(hw(xi)−yi)2+λ∑j=1p∣wj∣\text{J(w)}= \frac{1}{2n}\sum_{i=1}^n (h_w(x_i)-y_i)^2 + \lambda \sum_{j=1}^p |w_j|J(w)=2n1∑i=1n(hw(xi)−yi)2+λ∑j=1p∣wj∣
其中:
- $n $ 是样本数量,
- $ p $ 是特征的数量,
- $ y_i $是第 $ i $ 个样本的目标值,
- $ x_i $ 是第 $ i $ 个样本的特征向量,
- www是模型的参数向量,
- $\lambda $ 是正则化参数,控制正则化项的强度。
特点:
- 拉索回归可以将一些权重压缩到零,从而实现特征选择。这意味着模型最终可能只包含一部分特征。
- 适用于特征数量远大于样本数量的情况,或者当特征间存在相关性时,可以从中选择最相关的特征。
- 拉索回归产生的模型可能更简单,因为它会去除一些不重要的特征。
L1正则化是Lasso回归,Lasso回归的惩罚公式为系数λ乘上特征参数的绝对值之和,我们用一个二维特征从图像上看,即w1、w2为横纵坐标的平面坐标系,在这个平面坐标系中,损失函数以等高线形式被投影到坐标系中,而惩罚公式作为约束条件限制w1和w2的取值,L1正则化的惩罚公式在坐标系中以正方形的形式存在且四个顶点分别在坐标系两轴的两侧,所以处于等高线的w1和w2,在梯度值不变的情况下,也就是沿着等高线方向“行走”找到与菱形的交点,且当这个也有可能过这个菱形的顶点,即某个w的值为0,也就是说L1正则化一定程度上能够做到特征选择的功能,所以L1往往用于处理特征数>>样本数的数据。
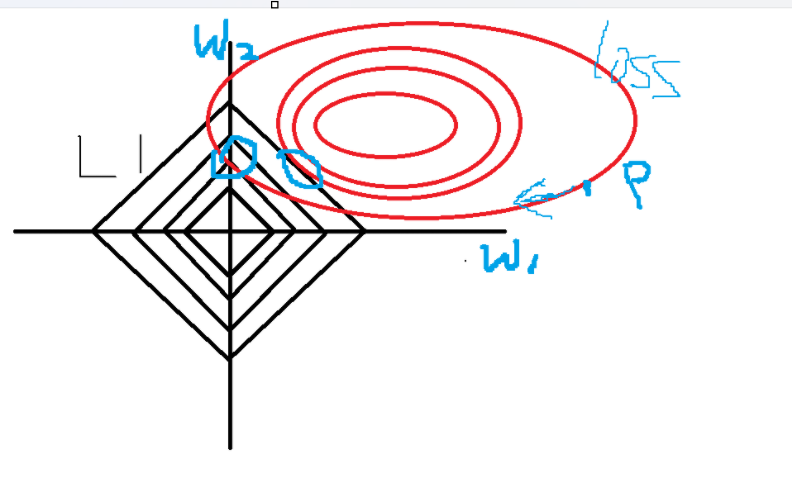
lasso回归API:
sklearn.linear_model.Lasso()
参数:
-
alpha (float, default=1.0):
- 控制正则化强度;必须是非负浮点数。较大的 alpha 增加了正则化强度。
-
fit_intercept (bool, default=True):
- 是否计算此模型的截距。如果设置为 False,则不会使用截距(即数据应该已经被居中)。
-
precompute (bool or array-like, default=False):
- 如果为 True,则使用预计算的 Gram 矩阵来加速计算。如果为数组,则使用提供的 Gram 矩阵。
-
copy_X (bool, default=True):
- 如果为 True,则复制数据 X,否则可能对其进行修改。
-
max_iter (int, default=1000):
- 最大迭代次数。
-
tol (float, default=1e-4):
- 精度阈值。如果更新后的系数向量减去之前的系数向量的无穷范数除以 1 加上更新后的系数向量的无穷范数小于 tol,则认为收敛。
-
warm_start (bool, default=False):
- 当设置为 True 时,再次调用 fit 方法会重新使用之前调用 fit 方法的结果作为初始估计值,而不是清零它们。
-
positive (bool, default=False):
- 当设置为 True 时,强制系数为非负。
-
random_state (int, RandomState instance, default=None):
- 随机数生成器的状态。用于随机初始化坐标下降算法中的随机选择。
-
selection ({‘cyclic’, ‘random’}, default=‘cyclic’):
- 如果设置为 ‘random’,则随机选择坐标进行更新。如果设置为 ‘cyclic’,则按照循环顺序选择坐标。
常用属性:
-
coef_
- 系数向量或者矩阵,代表了每个特征的权重。
-
**intercept_ **
- 截距项(如果 fit_intercept=True)。
-
**n_iter_ **
- 实际使用的迭代次数。
-
n_features_in_ (int):
- 训练样本中特征的数量。
2.岭回归—L2正则化
岭回归损失函数公式:
J(w)=12n∑i=1n(hw(xi)−yi)2+λ∑j=1pwj2\text{J(w)}= \frac{1}{2n}\sum_{i=1}^n (h_w(x_i)-y_i)^2 + \lambda \sum_{j=1}^p w_j^2J(w)=2n1∑i=1n(hw(xi)−yi)2+λ∑j=1pwj2
wjw_jwj指所有的权重系数, λ指惩罚型系数,又叫正则项力度
特点:
- 岭回归不会将权重压缩到零,这意味着所有特征都会保留在模型中,但它们的权重会被缩小。
- 适用于特征间存在多重共线性的情况。
- 岭回归产生的模型通常更为平滑,因为它对所有特征都有影响。
L2正则化也称为岭回归,L2正则化与L1的思想相同,只不过L2的惩罚公式变成了惩罚系数λ乘上所有特征参数w的平方和,与L1相比,L2的处理由于平方的原因,处理的就相对平滑,所有w都会被缩小但通常不会被压缩到0。同样的,在w1、w2为横纵坐标的平面坐标系,L2正则化的惩罚公式以圆的形式存在于坐标系中,且损失函数与L2惩罚公式(也就是这个圆)的相切点,通常为正则化处理后的结果。
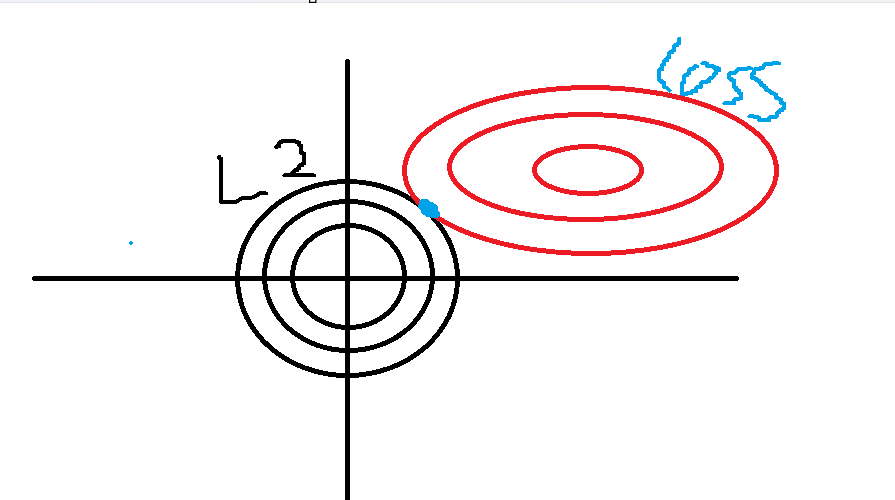
岭回归API:
csklearn.linear_model.Ridge()
参数:
-
alpha:
- default=1.0,正则项力度
-
fit_intercept:
- 是否计算偏置, default=True
-
solver:
- {‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, default=’auto’
当值为auto,并且数据量、特征都比较大时,内部会随机梯度下降法。
- {‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, default=’auto’
-
normalize:
- default=True, 数据进行标准化,如果特征工程中已经做过标准化,这里就该设置为False
-
max_iter:
- 梯度解算器的最大迭代次数,默认为15000
属性:
-
coef_:
- 回归后的权重系数
-
intercept_:
- 偏置
正则化示例:
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge,Lasso
from sklearn.metrics import mean_squared_error# 获取数据集
x, y = fetch_california_housing(return_X_y=True,data_home="../src")
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=23)
# 标准化
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 训练模型1 ——岭回归
model1 = Ridge(max_iter=20000, alpha=1)
model1.fit(x_train,y_train)
# 评估1
# score = model.score(x_test, y_test)
# print(score)
y_hat1 = model1.predict(x_test)
print("model1--loss:",mean_squared_error(y_hat1, y_test))
print("w1:", model1.coef_)# 训练模型2 —— lasso回归
model2 = Lasso(alpha=0.05, max_iter=10000)
model2.fit(x_train, y_train)
# 评估2
y_hat2 = model2.predict(x_test)
print("model2--loss:",mean_squared_error(y_hat2, y_test))
print("w2:", model2.coef_)
二、逻辑回归
逻辑回归是一种基于回归的分类算法,是的没错虽然名字中带着回归,但其实目的是分类。逻辑回归使用了线性回归的思想,再通过激活函数将原本的输出值映射到一个概率区间中。
原理
通过将线性回归的结果传入激活函数中得到预测概率,根据概率判断类别。
线性回归:h(w)=w1x1+w2x2+....+bh(w)=w_1x_1+w_2x_2+....+bh(w)=w1x1+w2x2+....+b
sigmoid激活函数 :f(x)=11+e−xf(x)=\frac{1}{1+e^{-x}}f(x)=1+e−x1
最终的逻辑回归函数:
f(w)=11+e−h(w)f(w)=\frac{1}{1+e^{-h(w)}}f(w)=1+e−h(w)1
这个函数的值域图像为:
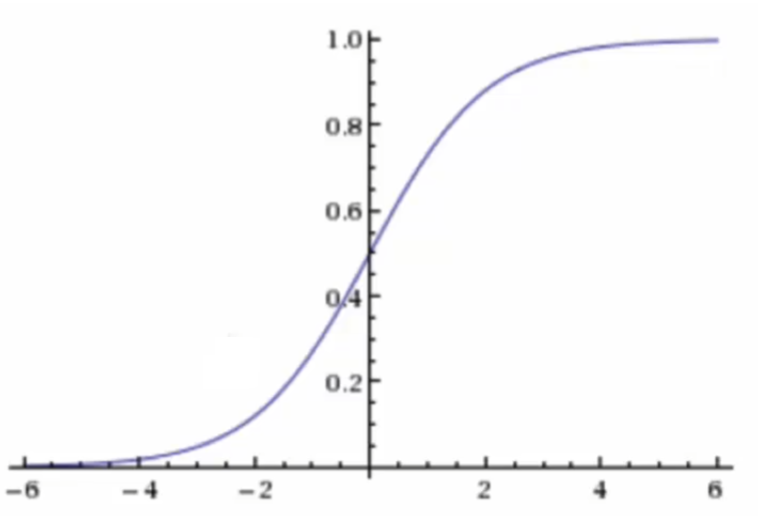
即概率在[0, 1]范围区间内。
注意:这里的sigmoid函数是针对于二分类问题的激活函数。
其交叉熵损失函数为:
Loss=−∑i=1n[yilogyi^+(1−yi)log(1−yi^)]
Loss=-\sum_{i=1}^n[y_i\log\hat{y_i}+(1-y_i)\log(1-\hat{y_i})]
Loss=−i=1∑n[yilogyi^+(1−yi)log(1−yi^)]
(交叉熵损失:专门用来衡量概率预测结果和真实标签之间差异的损失函数。)
逻辑回归API
sklearn.linear_model.LogisticRegression()
参数:
- fit_intercept
- max_iter
用法与前面的API相同
返回的对象方法:
-
predict()预测分类
-
predict_proba()预测分类(对应的概率)
-
score()准确率
示例:
泰坦尼克号数据集进行逻辑回归预测是否生还。
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression# 获取数据集
data = pd.read_csv("../src/titanic/titanic.csv")
print(data.columns)
# 数据清洗
y = data["survived"]
x = data[['pclass', 'age', 'sex', 'ticket','room']]
x.loc[:,'age'] = x['age'].fillna(x['age'].mean())
# print(x["room"].isnull().sum())
# print(x["ticket"].isnull().sum())
x.loc[:,["ticket","room"]] = x[["ticket","room"]].fillna("Unknown")
x = x.to_dict(orient="records")
# print(x["ticket"].isnull().sum())
dict = DictVectorizer(sparse=False)
x = dict.fit_transform(x)
print(x[:10])# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 标准化
scaler = StandardScaler()
scaler.fit_transform(x_train)
scaler.transform(x_test)
# 训练
model = LogisticRegression(max_iter=1000)
model.fit(x_train, y_train)
# 评估
score = model.score(x_test, y_test)
print(score)
以上就是博主在学习机器学习时的一些总结,此文章为个人学习中所作笔记,如有任何错误请及时指正博主,感谢浏览~ovo