机器学习 集成学习之随机森林
目录
随机森林:从原理到实战,一文读懂这个 "万能" 机器学习模型
一、随机森林:不止是 "很多树" 的森林
1. 从决策树到集成学习:为什么需要 "森林"?
什么是集成学习
二.随机森林特点
三.随机森林的工作流程
四.随机森林的优缺点
五.随机森林的应用场景
1. 分类任务
2. 回归任务
3. 特征工程与数据探索
4. 异常检测
六.API参数
1.关键参数
七.随机森林调优:让模型更上一层楼
八.垃圾邮件判断案例
1.数据集介绍
2.读取数据,并划分数据
3.随机森林模型训练
4.测试模型
5.特征重要性排序
随机森林:从原理到实战,一文读懂这个 "万能" 机器学习模型
在机器学习的江湖中,有一个模型凭借其强大的性能、稳健的表现和广泛的适用性,成为了数据科学家手中的 "瑞士军刀"—— 它就是随机森林(Random Forest)。无论是分类任务(如信用评分、疾病诊断)还是回归任务(如房价预测、销量预估),随机森林都能交出令人满意的答卷。今天,我们就从原理到实战,彻底搞懂这个 "万能" 模型。
一、随机森林:不止是 "很多树" 的森林
提到随机森林,很多人会直观地想:"不就是很多决策树凑在一起吗?" 这句话对了一半,但忽略了其核心的 "随机性" 设计。要理解随机森林,我们需要先从它的 "积木"—— 决策树和 "组装方式"—— 集成学习说起。
1. 从决策树到集成学习:为什么需要 "森林"?
决策树是一种直观的机器学习模型,它像一棵倒置的树,通过对特征的逐步判断(如 "年龄是否大于 30?"" 收入是否超过 5 万?")来实现分类或回归。单棵决策树的优点是简单易懂、训练速度快,但缺点也很明显:容易过拟合(对训练数据拟合过好,泛化能力差),且预测结果受数据微小变化影响较大(稳定性差)。
为了解决单棵决策树的缺陷,集成学习(Ensemble Learning) 应运而生。集成学习的核心思想是:"三个臭皮匠顶个诸葛亮"—— 通过组合多个 "弱学习器"(性能略优于随机猜测的模型)的预测结果,得到一个更强大的 "强学习器"。随机森林就是集成学习中最成功的代表之一,它的 "弱学习器" 正是决策树。
什么是集成学习
- 集成学习:通过组合多个基础学习器(如决策树、逻辑回归等)提升模型性能,典型方法包括:
- Bagging(如随机森林)
- Boosting(如AdaBoost、XGBoost)
- 堆叠模型(Stacking)
二.随机森林特点
- 随机森林特点:
- 属于集成学习的Bagging分支,基础学习器仅为决策树。
- 核心思想:“三个臭皮匠顶一个诸葛亮”,通过多棵决策树投票或平均提升准确性。
- 三大随机性:
- 数据采样随机:每棵决策树仅训练部分数据(如80%)。
- 特征选取随机:每棵决策树仅使用部分特征(如80个特征中的70个)。
- 森林结构:由多棵决策树组成,最终结果通过投票(分类)或平均(回归)决定。
三.随机森林的工作流程
随机森林的训练和预测过程可以总结为四步:
- 抽样:用 Bootstrap 方法为每棵树生成独立的训练样本集;
- 建树:对每个样本集,用随机特征子集训练一棵决策树(不剪枝,让树充分生长);
- 预测:
- 分类任务:所有树投票,得票最多的类别为最终结果;
- 回归任务:所有树预测值的平均值为最终结果;
- 集成:综合所有树的结果,得到更稳健的预测。
简单来说,随机森林就像一个 "专家委员会":每个专家(决策树)基于不同的信息(样本和特征随机)独立判断,最后通过投票 / 平均得出结论,自然比单个专家更可靠。
四.随机森林的优缺点
- 应用场景:分类、回归、特征重要性评估。
- 优点:
- 高准确率(因数据随机采样):通过集成多棵树,大幅降低了过拟合风险,泛化能力强;
- 适用性广:同时支持分类和回归任务,对数据类型不敏感(连续型、离散型均可);
- 无需特征预处理:不需要归一化或标准化(决策树本身对特征尺度不敏感);
- 抗噪声能力强(因数据随机采样):对异常值和缺失值不敏感,稳定性高;
- 能评估特征重要性:可以计算每个特征对预测结果的贡献度,辅助特征工程;
- 可并行训练:每棵树的训练相互独立,能利用多核 CPU 加速。
- 相比传统线性相关度分析,随机森林能捕捉非线性关系(决策树通过条件判断构建,不受线性假设限制)。
- 随机森林的一大优势是能输出特征重要性
- 缺点:
- 计算成本高:训练时间和内存消耗较大(因多棵决策树)
- 解释性较弱:模型解释性较差(“黑盒”特性),虽然单棵决策树易解释,但 "森林" 的整体决策过程难以可视化(可通过特征重要性部分弥补);
- 对超高维稀疏数据(如文本)可能不如线性模型高效。
五.随机森林的应用场景
随机森林的稳健性和实用性,让它在各行各业都有广泛应用:
1. 分类任务
- 信用评分:银行用随机森林判断用户违约风险(特征:收入、负债、征信记录等);
- 疾病诊断:根据患者的症状、检查指标预测是否患病(如癌症早期筛查);
- 图像识别辅助:在特征提取后,用随机森林做分类(如识别垃圾邮件、欺诈交易)。
2. 回归任务
- 房价预测:结合面积、地段、房龄等特征预测房价;
- 销量预估:根据促销活动、季节、竞品价格预测商品销量;
- 风险评估:预测自然灾害(如洪水、地震)的损失金额。
3. 特征工程与数据探索
- 通过随机森林的特征重要性排序,筛选关键特征(如排除对预测无贡献的冗余特征);
- 识别特征间的交互关系(如 "年龄 + 收入" 对消费能力的联合影响)。
4. 异常检测
利用 "袋外数据" 的预测误差,识别与多数样本模式不符的异常点(如信用卡欺诈交易)。
六.API参数
from sklearn.ensemble import RandomForestClassifier随机森林参数源码如下:
1.关键参数
- 关键参数
-
n_estimators:决策树数量(默认100)。
-
max_depth:单棵树的最大深度(建议10-100)。
-
min_samples_split:节点继续分裂的最小样本数(默认2)。
-
max_features:控制每棵决策树在训练时使用的最大特征数量,可选值包括:
-
auto/sqrt:特征数量的平方根(如100个特征→10个)。 -
log2:以2为底的对数(如100个特征→log₂100)。 -
整数:直接指定特征数量。
-
-
bootstrap:采样方式:
-
True:有放回采样(默认),每次从80%数据中随机抽取。 -
False:无放回采样,从剩余数据中逐步抽取。
-
-
n_jobs:并行计算设置:
-
1:单核运行。 -
-1:使用全部CPU核心。
-
-
七.随机森林调优:让模型更上一层楼
要进一步提升随机森林的性能,关键在于参数调优。以下是几个核心参数及调优思路:
| 参数 | 作用 | 调优建议 |
|---|---|---|
n_estimators | 决策树数量 | 从 50/100 开始,逐步增加至性能稳定(避免过大导致计算量激增) |
max_depth | 树的最大深度 | 限制深度防止过拟合(默认无限制,可设 10-30,视数据复杂度而定) |
max_features | 每棵树可用的最大特征数 | 分类任务默认√n,回归任务默认 n/2,可尝试 0.3-0.7 的比例 |
min_samples_split | 分裂节点所需最小样本数 | 增大该值(如从 2 到 5)可降低过拟合风险 |
min_samples_leaf | 叶节点最小样本数 | 同上,建议 3-10 |
八.垃圾邮件判断案例
1.数据集介绍
- 数据集:
spambase.csv,用于垃圾邮件识别,包含4500行数据,57个特征列(A列到BED列),BFD列为标签结果(0和1)。 - 特征说明:
- 前48个连续特征为单词频率(如
make、address、3d等),用于识别垃圾邮件关键词。 - 后6个连续特征为字符频率(如数字
1、2等),用于监测QQ号、手机号等敏感字符。 - 其他特征包括:不间断大写字母序列的平均长度、连续整数的长度、大写字母总数等。
- 前48个连续特征为单词频率(如
spambase.csv部分内容如下

2.读取数据,并划分数据
- 数据划分:80%训练集,20%测试集。
import pandas as pd
from sklearn.model_selection import train_test_splitdata = pd.read_csv('spambase.csv')
X=data.iloc[:,:-1]
y=data.iloc[:,-1]train_x,test_x,train_y,test_y=train_test_split(X,y,test_size=0.3,random_state=100)
3.随机森林模型训练
- 模型参数:
- 决策树数量(
n_estimators):设为150。 - 最大特征比例(
max_features):0.8。 - 随机种子(
random_state)固定。
- 决策树数量(
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
rf=RandomForestClassifier(n_estimators=150,max_features=0.8,random_state=0
)
rf.fit(train_x,train_y)4.测试模型
rf.fit(train_x,train_y)
print('===============自测报告==============')
self_predicted=rf.predict(train_x)
print(metrics.classification_report(train_y,self_predicted))
print('===============测试报告==============')
test_predicted=rf.predict(test_x)
print(metrics.classification_report(test_y,test_predicted))===============自测报告==============precision recall f1-score support0 1.00 1.00 1.00 19751 1.00 1.00 1.00 1242accuracy 1.00 3217macro avg 1.00 1.00 1.00 3217
weighted avg 1.00 1.00 1.00 3217===============测试报告==============precision recall f1-score support0 0.94 0.96 0.95 8101 0.95 0.91 0.93 570accuracy 0.94 1380macro avg 0.94 0.94 0.94 1380
weighted avg 0.94 0.94 0.94 1380- 训练集准确率100%,测试集准确率为91%,未出现过拟合。
- 混淆矩阵和分类报告显示模型效果良好。
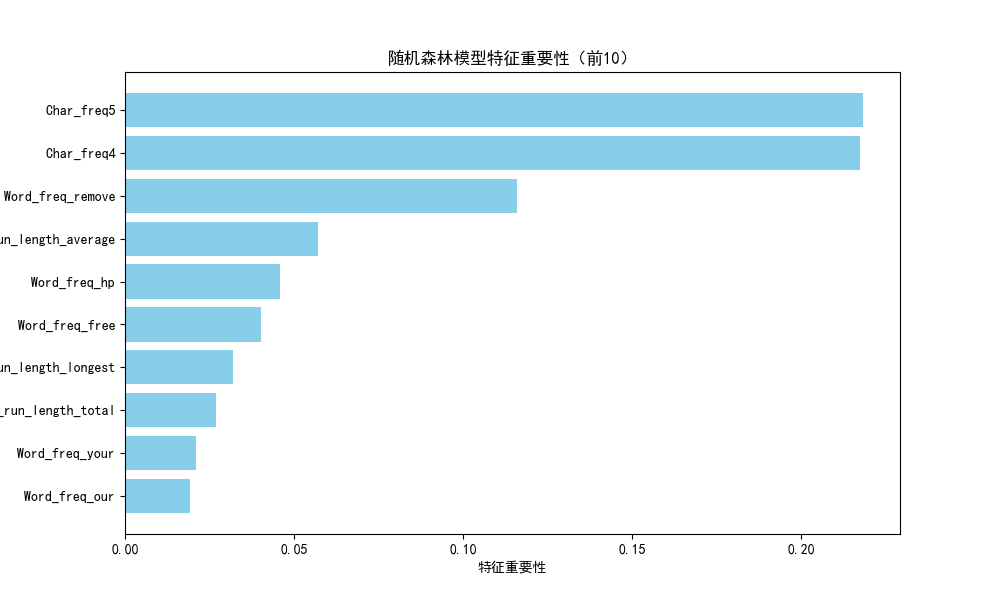
5.特征重要性排序
通过rf.feature_importance_获取57个特征的重要性
可视化:水平条形图展示前10个重要特征(使用plt.barh和pandas的sort_values方法)。
# 特征重要性排序
import matplotlib.pyplot as plt
import pandas as pd
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 特征重要性分析
importances = rf.feature_importances_
# 创建特征重要性DataFrame
importance_df = pd.DataFrame({'特征名称': X.columns, # 直接使用特征列名'重要性': importances
})# 按重要性降序排序并取前10
top10_features = importance_df.sort_values(by='重要性', ascending=False).head(10)# 绘制特征重要性条形图
plt.figure(figsize=(10, 6))
index = range(len(top10_features))
plt.yticks(index, top10_features['特征名称'])
plt.barh(index, top10_features['重要性'], color='skyblue')
plt.xlabel('特征重要性')
plt.title('随机森林模型特征重要性(前10)')
plt.gca().invert_yaxis() # 让最重要的特征显示在顶部
plt.show()# 显示图形
plt.show()