算法训练之哈希表

♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨
这一篇博客开启算法学习的另外一个篇章——哈希表,准备好了吗~我们发车去探索算法的奥秘啦~🚗🚗🚗🚗🚗🚗
目录
前言😁
哈希表基础概念😍
适用场景😊
实现方式😁
关键注意事项😜
容器使用参考博客🐷
两数之和😊
判断是否为字符串重排😋
存在重复元素Ⅱ🤪
字母异位词分组😀
总结🙃
前言😁
哈希表基础概念😍
哈希表是一种用于存储数据的容器,本质是通过键值对(key-value)的形式组织数据。它的核心优势在于能实现元素的快速查找,理想情况下时间复杂度可达 O(1),远超二分查找的 O(log N)。
适用场景😊
当需要频繁查找某个特定元素时(例如统计字符出现频率、检测重复值),哈希表是最优选择。尤其适合处理需要高频查询的场景,以空间换时间显著提升效率。
实现方式😁
方法一:直接使用容器:
利用编程语言内置的哈希表结构(如 C++的map和set)
方法二:数组模拟简易哈希表
适用条件:键为字符或小范围整数(如 ASCII 字符)
原理:用数组索引直接表示键(如 index),存储值(如 n[index])
示例:统计字母出现次数时,可通过 char - 'a' 将字符映射到数组下标
关键注意事项😜
-
数组模拟法要求键的范围小且连续,否则会造成空间浪费。
-
实际应用中需处理哈希冲突(常用链地址法或开放寻址法)。
-
与二分查找对比:哈希表查询更快但耗内存;二分查找节省空间但要求数据有序且速度较慢。
容器使用参考博客🐷
前面C++专栏有讲解过map和set容器的使用,具体可以看看这几篇博客~
今天你学C++了吗?——set
今天你学C++了吗?——map
题目练习之set的奇妙使用
题目练习之map的奇妙使用
说了这么多,光说不练岂不是假把式,我们结合题目一起来看看~
两数之和😊
两数之和
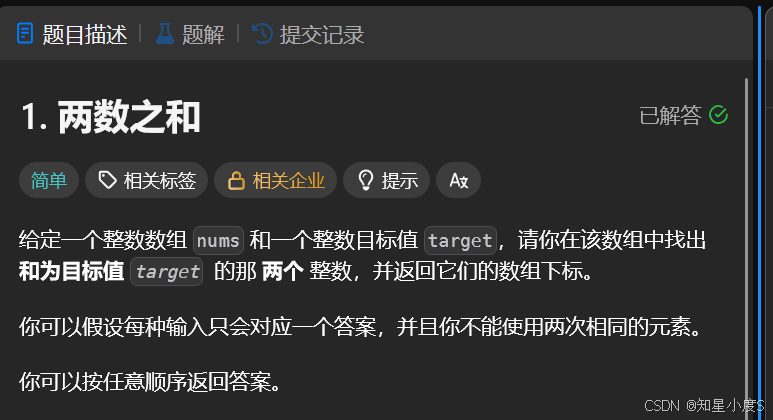

题目要求十分简单,给出一个数组,找出两个数和为target~一看这个题目,暴力解法先来试一试,一一列举找到这两个数~
暴力解法代码实现:
class Solution
{
public:vector<int> twoSum(vector<int>& nums, int target) {int n=nums.size();for(int i=0;i<n;i++){for(int j=i+1;j<n;j++){if(nums[i]+nums[j]==target)return {i,j};}}return {-1,-1};//满足编译器要求}
};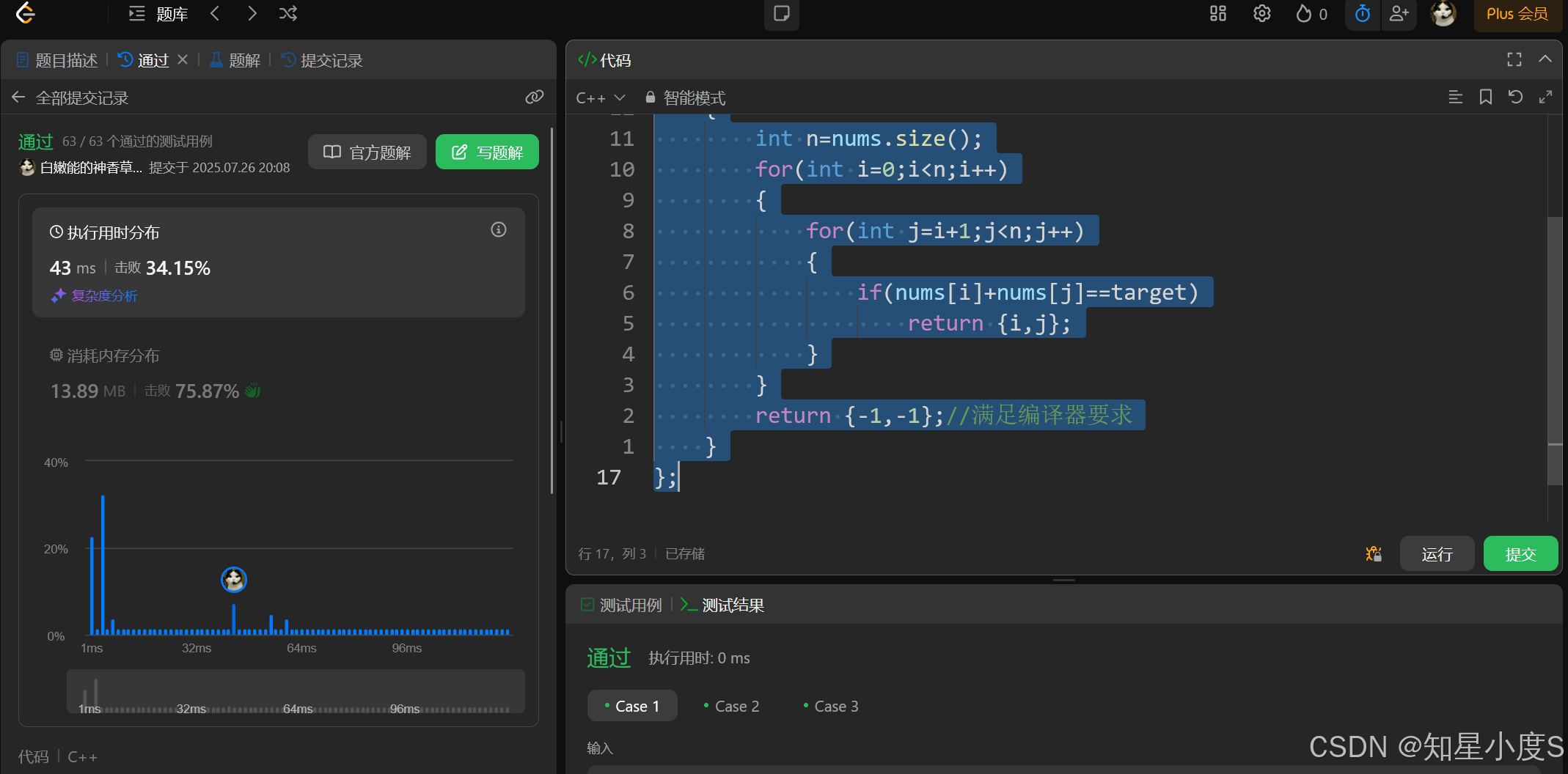
顺利通过~但是时间复杂度为O(n*n),再加上这不是要使用哈希表解决问题吗?怎么一点哈希表的影子也没有看见,别急,我们接着分析。
前面的常规暴力解法我们固定一个数,在这个数后面找另外一个数加起来为target,接下来我们换一种暴力解法方式固定一个数,在这个数前面找另外一个数加起来为target【只需要修改for循环即可】,为我们后面哈希表的引入作铺垫~
暴力解法二代码实现:
class Solution
{
public:vector<int> twoSum(vector<int>& nums, int target) {int n=nums.size();for(int i=1;i<n;i++){for(int j=0;j<i;j++){if(nums[i]+nums[j]==target)return {i,j};}}return {-1,-1};//满足编译器要求}
};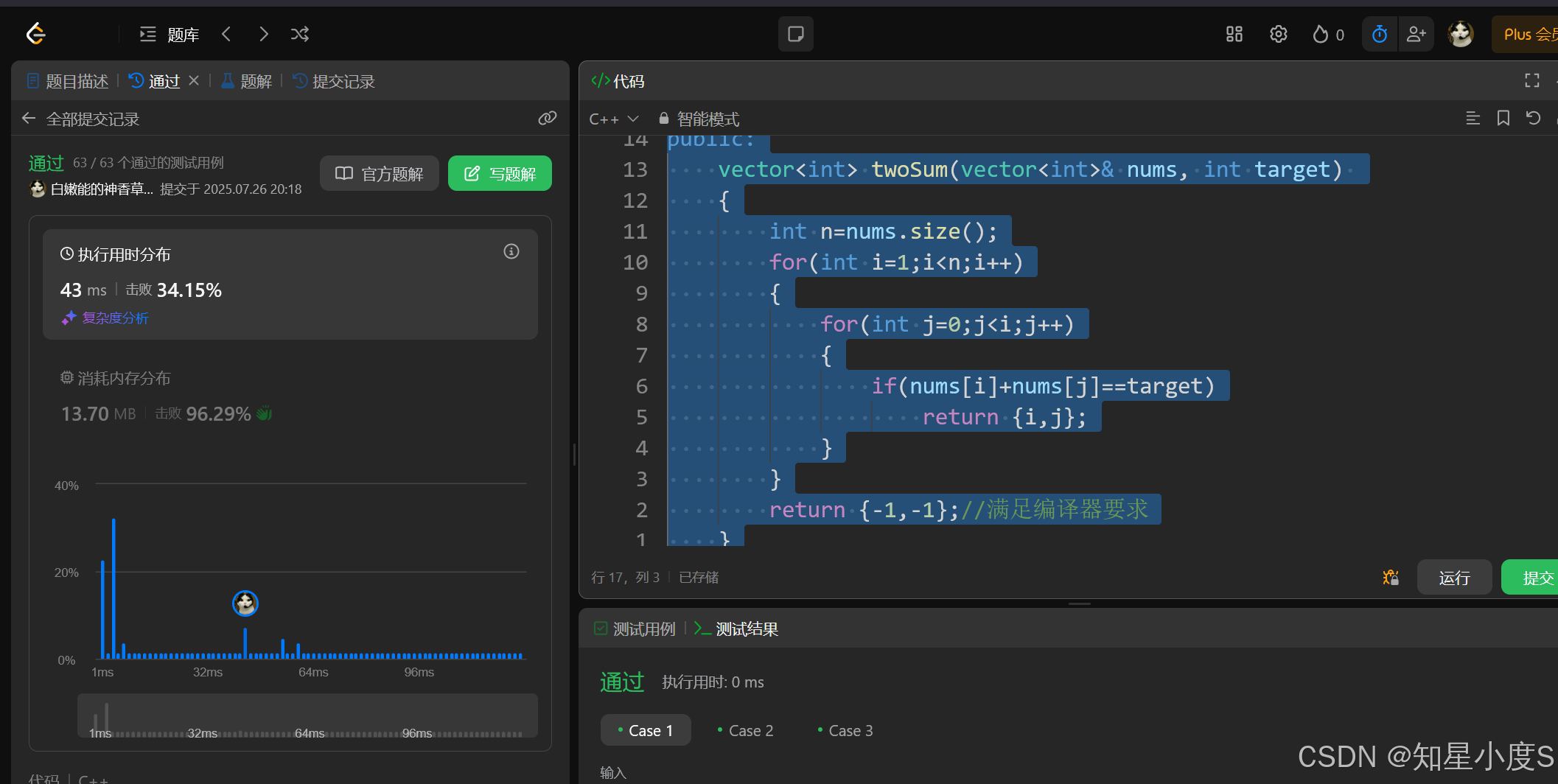
顺利通过~时间复杂度依然为O(n*n),接下来就需要我们的哈希表出马了~
算法思路:
从前往后遍历整个数组,前面的数入哈希表,到一个数到哈希表中找另外一个目标值即可,因为需要返回下标,所以哈希表要将数据和下标进行绑定~
看了这个算法思路,相信大家也看出来使用哈希表事实上是用空间换时间的策略~
代码实现:
class Solution
{
public:vector<int> twoSum(vector<int>& nums, int target) {unordered_map <int,int> hash;//<nums[i],i>for(int i=0;i<nums.size();i++){int tmp=target-nums[i];//目标值if(hash.count(tmp)){return {hash[tmp],i};}hash[nums[i]]=i;//当前数入哈希表}return {-1,-1};}
};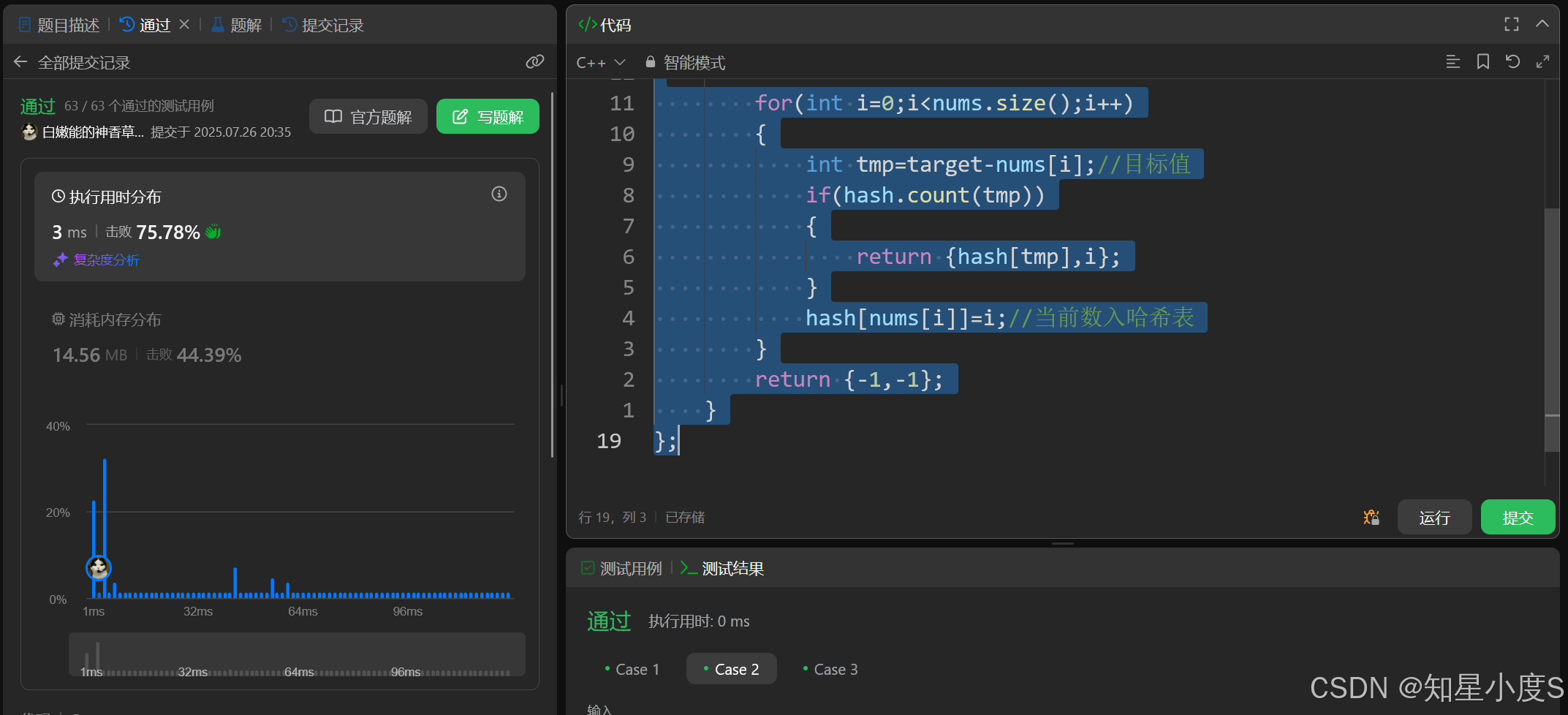
顺利通过~遍历数组 n 次,每次哈希表的插入(hash[nums[i]] = i)和查询(hash.count(tmp))操作的平均时间复杂度为 O(1),所以时间复杂度为O(n),因为创建了哈希表,所以空间复杂度为O(n)~典型的空间换时间策略
判断是否为字符串重排😋
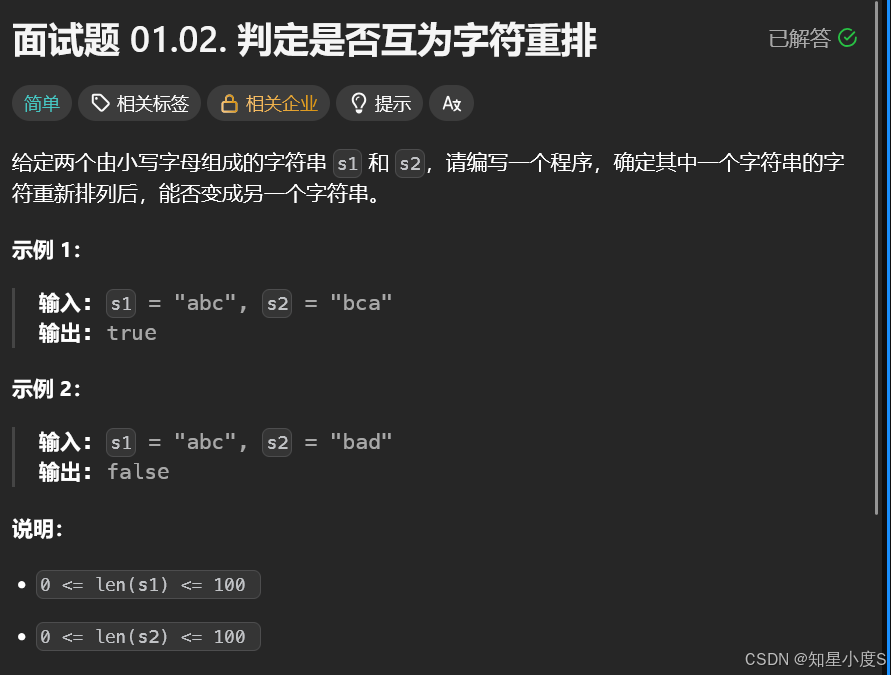
算法思路:
优先判断长度——长度不同,一定不是重排,使用数组模拟哈希表统计每一个字母出现的次数,两个字符串每一个字母出现的次数都相同,那么是字符串重排
代码实现:
//判断是否为字符串重新排序
class Solution
{
public:bool CheckPermutation(string s1, string s2){//优先判断长度——长度不同,一定不是重排if (s1.size() != s2.size())return false;//长度相同int hash[26] = { 0 };//下标对应字母,数组值对应出现次数for (auto& e : s1){//统计字符串s1每个字母出现次数hash[e - 'a']++;}//判断两个字符串字母出现次数是否相等for (auto& e : s2){hash[e - 'a']--;if (hash[e - 'a'] < 0)return false;}return true;}
};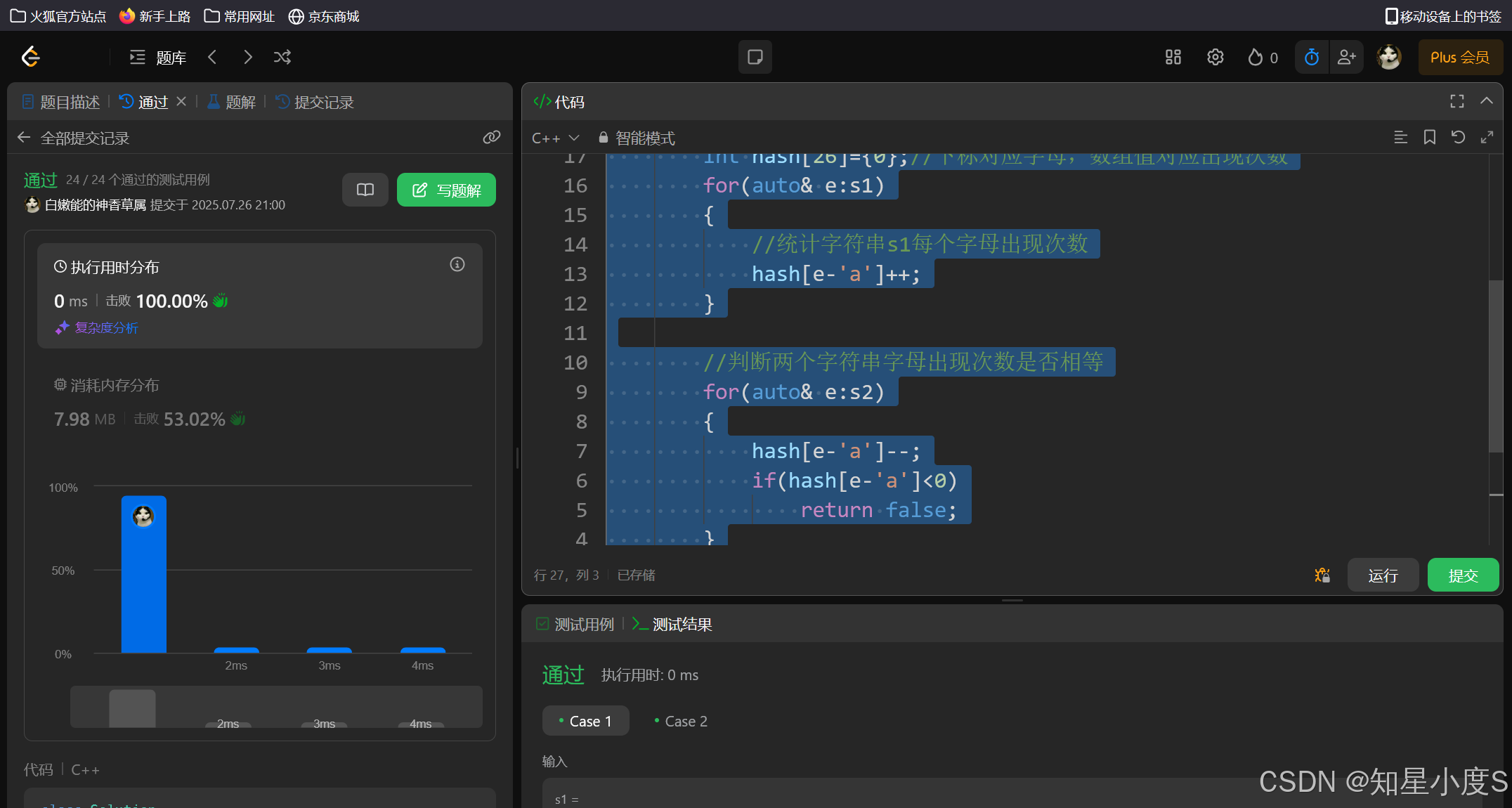
顺利通过~
存在重复元素Ⅱ🤪
存在重复元素Ⅱ


算法思路:
使用哈希表记录数据和下标,循环判断当前元素是否出现过,出现过直接返回,没有出现过
代码实现:
//是否存在重复的数Ⅱ
class Solution
{
public:bool containsNearbyDuplicate(vector<int>& nums, int k){unordered_map<int, int> hash;//<nums[i],i>for (int i = 0; i < nums.size(); i++){int tmp = nums[i];if (hash.count(tmp) && abs(i - hash[tmp]) <= k){return true;}hash[nums[i]] = i;//哈希表加入当前元素}return false;}
};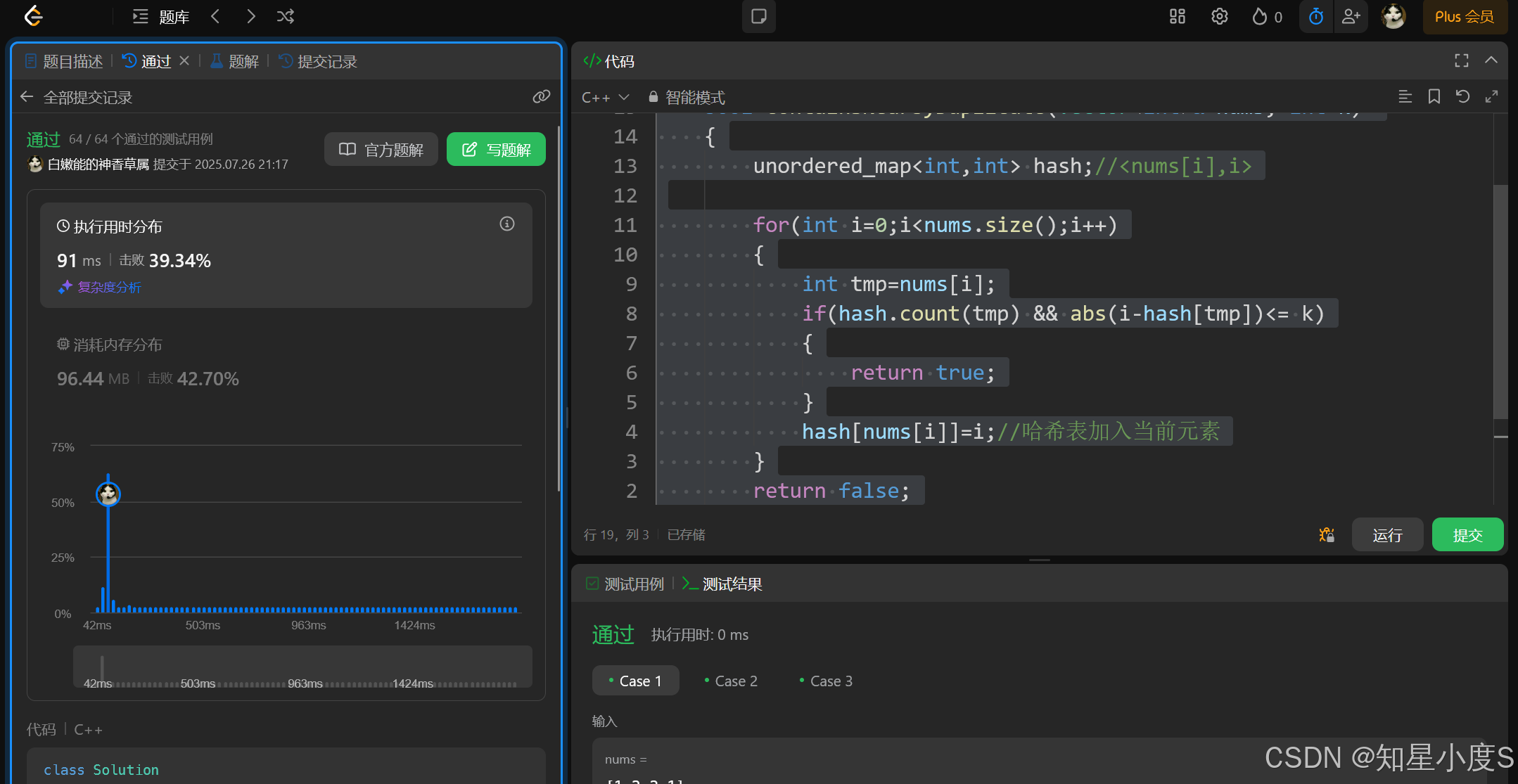
顺利通过~
字母异位词分组😀
字母异位词分组
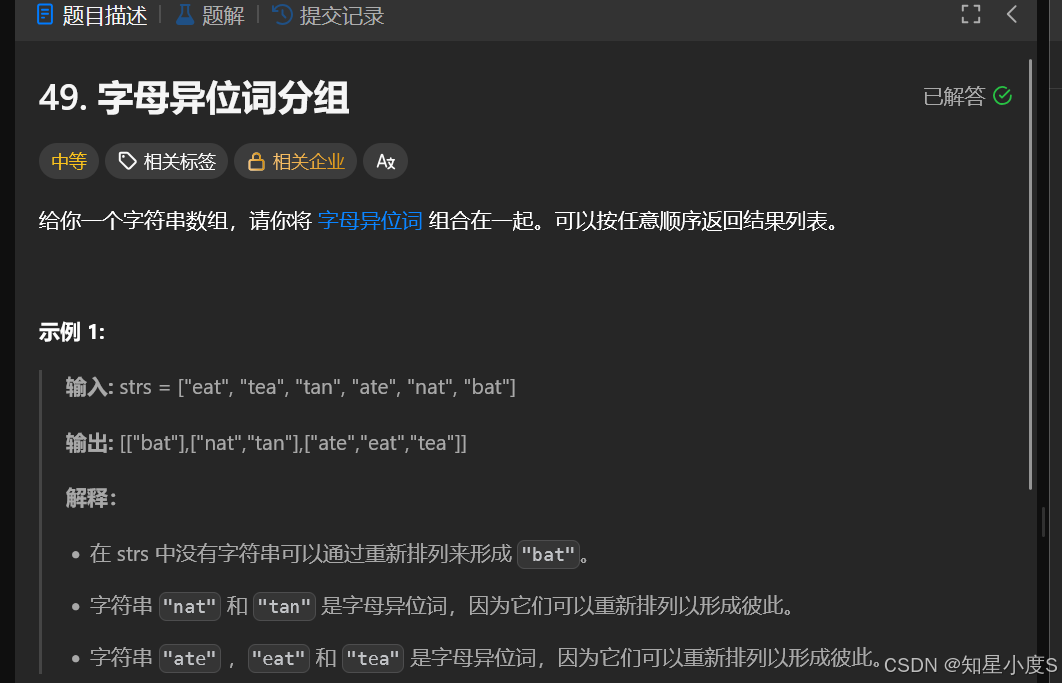

通俗理解题目要求我们把这些是字母异位词的放在一块,这就又得使用到我们强大的哈希表了~
算法思路:
创建一个key为string(排序后的字符串,方便判断),value为vector<string>(排序前的字符串)的哈希表,遍历字符串数组,先对当前字符串进行排序,看哈希表中是否存在,存在就在对应value进行存储,不在就插入新的key~最后返回每一个value即可~
代码实现:
//字母异位词分组
class Solution
{
public:vector<vector<string>> groupAnagrams(vector<string>& strs){unordered_map<string, vector<string>> hash;for (auto& e : strs){string tmp = e;sort(tmp.begin(), tmp.end());if (hash.count(tmp)){hash[tmp].push_back(e);//对应数组添加当前字符串}else{hash[tmp] = { e };//添加当前排序字符串}}//提取结果vector<vector<string>> ret;for (auto& [x, y] : hash)//[x,y]——[key,value]{ret.push_back(y);}return ret;}
};
顺利通过~这道题目是哈希表和排序的组合,如果知道思路的话,相信也是不在话下了~
总结🙃
哈希表的核心优势在于以空间换时间,实现高效操作,一定程度上时间复杂度优化,处理动态数据更灵活,所以学会灵活使用哈希表这个强有力的工具事半功倍哦~
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨