Mysql使用Canal服务同步数据->ElasticSearch
目录
1、Canal
1.1、工作原理
1.2、Canal 使用流程
2、环境准备
2.1、MySQL 配置
2.2、Canal 服务端部署
2.3、配置客户端canal-adapter
3、Canal 客户端实现
3.1、直接写入 Elasticsearch 方案
3.2、通过消息队列中转
4、Elasticsearch 数据映射处理
5、注意事项
前言
Canal 是阿里巴巴开源的一款基于 MySQL 数据库增量日志解析的组件。
它通过模拟 MySQL Slave 的交互协议,伪装自己为 MySQL Slave,向 MySQL Master 发送 dump 协议,获取 binlog 日志并进行解析,然后将解析后的数据发送到下游系统如 Elasticsearch。
如下图所示:
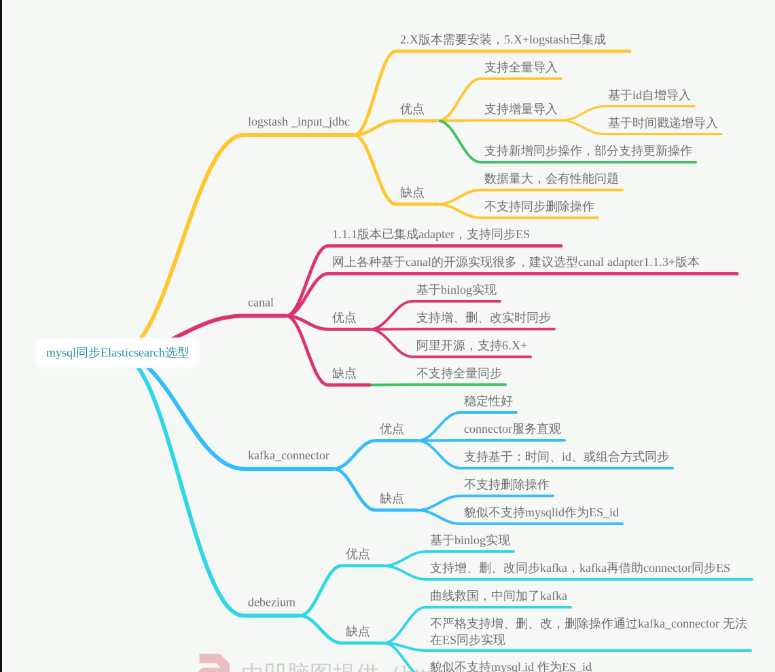
1、Canal
1.1、工作原理
如下图所示:
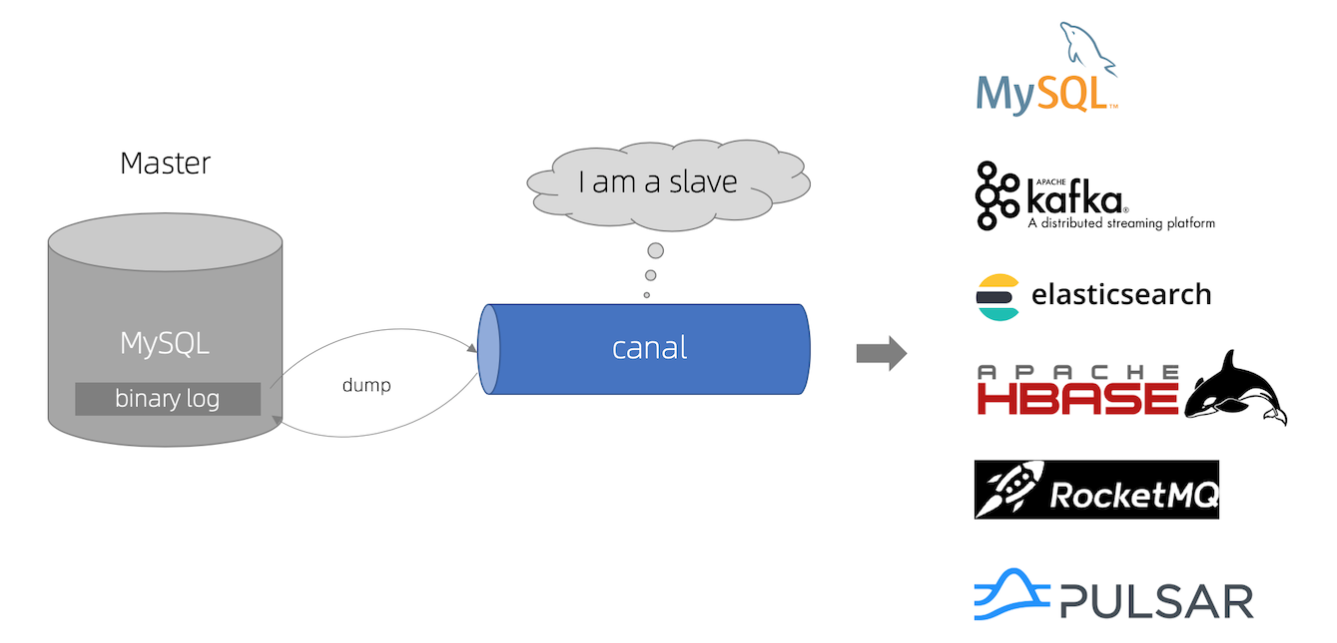
-
MySQL 主从复制原理:
-
Master 将变更写入二进制日志(binlog)
-
Slave 请求 Master 的 binlog
-
Master 推送 binlog 到 Slave
-
Slave 重放 binlog 实现数据同步
-
-
Canal 模拟 Slave:
-
Canal 伪装成 MySQL Slave
-
从 Master 获取 binlog
-
解析 binlog 为结构化数据
-
将数据发送到消息队列或直接写入 Elasticsearch
-
1.2、Canal 使用流程
如下所示:

1、部署Deployer服务,该服务负责从上游拉取binlog数据、记录位点等。
2、部署Client-Adapter服务,该服务负责对接Deployer解析过的数据,并将数据传输到目标库中。
3、部署完成后,canal默认会自动同步MySQL增量数据。
4、如果需要同步MySQL全量数据,请手动调用Client-Adapter服务的方法触发同步任务。
待全量数据同步完成后,canal会自动开始增量同步。
2、环境准备
2.1、MySQL 配置
必须开启 binlog 并设置为 ROW 模式:
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 设置为 ROW 模式
server_id=1 # 设置 server_id
binlog_row_image=FULL # 记录完整行数据创建 Canal 专用账号:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;创建从库权限账号canal,用于订阅binlog。
2.2、Canal 服务端部署
下载 Canal:https://github.com/alibaba/canal/releases

配置服务端 canal-deployer
canal-deployer伪装成mysql的从库,监听binlog接收数据,目录结构如下:

1、修改配置
/conf/canal.properties
#canal的server地址:127.0.0.1,除了ip和port外,其他配置可不改动
canal.ip =127.0.0.1
#canal端口,用于客户端监听
canal.port = 111112、修改配置
/conf/example/instance.properties
#被同步的mysql地址
canal.instance.master.address=127.0.0.1:3306
#数据库从库权限账号
canal.instance.dbUsername=canal
#数据库从库权限账号的密码
canal.instance.dbPassword=Password@123
#数据库连接编码
canal.instance.connectionCharset = UTF-8
#需要订阅binlog的表过滤正则表达式
#canal.instance.filter.regex=.*\\..*
#我们只监听数据同步表
canal.instance.filter.regex=cxstar_oa.data_sync_es
#这里与文件夹名保持一致,后面会用到
canal.mq.topic=example
3、启动canal-deployer
进入bin目录,执行启动命令:
sh bin/startup.sh查看日志:/logs/canal/canal.log
2023-02-02 15:28:16.016 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler
2023-02-02 15:28:16.043 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations
2023-02-02 15:28:16.054 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server.
2023-02-02 15:28:16.112 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[127.0.0.1(127.0.0.1):11111]
2023-02-02 15:28:17.824 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......
查看日志:/logs/canal/canal.log
2023-02-02 15:28:17.590 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2023-02-02 15:28:17.619 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
2023-02-02 15:28:17.619 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$
2023-02-02 15:28:17.757 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2023-02-02 15:28:17.776 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
2023-02-02 15:28:17.776 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status
2023-02-02 15:28:18.382 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mall-mysql-bin.000008,position=12380,serverId=101,gtid=,timestamp=1675309792000] cost : 610ms , the next step is binlog dump
日志如上就已经成功启动。
2.3、配置客户端canal-adapter
canal-adapter:
作为canal的客户端,会从canal-server中获取数据,然后同步数据到MySQL、Elasticsearch等存储中去。
目录结构如下:
1、替换client-adapter.es7的jar文件
下载v1.1.5-alpha-2,解压后找到plugin目录下的
client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar
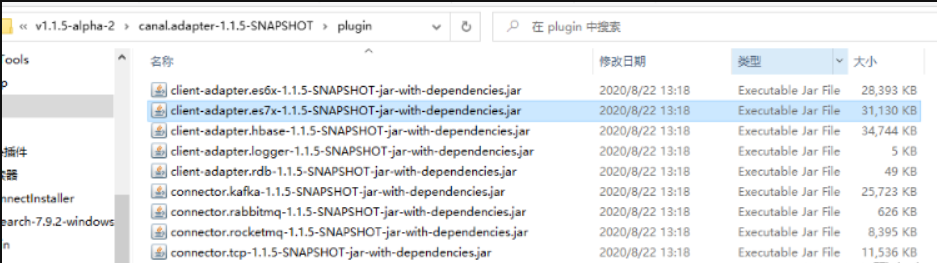
增加执行权限:
chmod -R 755 /home/canal-1.1.5/canal.adapter-1.1.5/plugin
原因:
如果不替换,在启动的时候会报错:
java.lang.ClassCastException: com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSource
2.修改配置/conf/application.yml
server:port: 8081
spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8default-property-inclusion: non_nullcanal.conf:mode: tcp # 客户端的模式,可选tcp kafka rocketMQflatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效zookeeperHosts: # 对应集群模式下的zk地址syncBatchSize: 1000 # 每次同步的批数量retries: 0 # 重试次数, -1为无限重试timeout: # 同步超时时间, 单位毫秒accessKey:secretKey:consumerProperties:# canal tcp consumercanal.tcp.server.host: 127.0.0.1:11111 #设置canal-server的地址canal.tcp.zookeeper.hosts:canal.tcp.batch.size: 500canal.tcp.username:canal.tcp.password:srcDataSources: # 源数据库配置defaultDS:url: jdbc:mysql://127.0.0.1:3306/canal?useUnicode=true&useSSL=true #测试数据库连接username: root #数据库账号password: Passwd@2014 #数据库密码canalAdapters: # 适配器列表- instance: example # canal实例名或者MQ topic名groups: # 分组列表- groupId: g1 # 分组id, 如果是MQ模式将用到该值outerAdapters:- name: logger # 日志打印适配器- name: es7 # ES同步适配器hosts: 192.168.0.182:9200 # ES连接地址properties:mode: rest # 模式可选transport(9300) 或者 rest(9200)#security.auth: elastic:123456 # 连接es的用户和密码,仅rest模式使用cluster.name: elasticsearch # ES集群名称, 与es目录下 elasticsearch.yml文件cluster.name对应
3、增加mysql同步es的映射文件
进入/conf/es7目录下,复制mytest_user.yml命名为test_book.yml,同时修改:
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # canal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:_index: test_book # es 的索引名称_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配sql: "SELECTtb.id AS _id,tb.title,tb.isbn,tb.author,tb.publisher_name as publisherNameFROMtest_book tb" # sql映射etlCondition: "where p.id>={}" #etl的条件参数commitBatch: 3000 # 提交批大小
4.启动canal-adapter
启动canal-adapter,进入bin目录,执行启动命令:
./startup.sh
日志如下即表示启动成功
2023-04-02 13:22:52.337 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## syncSwitch refreshed.
2023-04-02 13:22:52.337 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## start the canal client adapters.
2023-04-02 13:22:52.338 [main] INFO c.a.otter.canal.client.adapter.support.ExtensionLoader - extension classpath dir: /home/canal-1.1.5/canal.adapter-1.1.5/plugin
2023-04-02 13:22:52.372 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: logger succeed
2023-04-02 13:22:52.679 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## Start loading es mapping config ...
2023-04-02 13:22:52.751 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## ES mapping config loaded
2023-04-02 13:22:52.951 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 succeed
2023-04-02 13:22:52.960 [main] INFO c.alibaba.otter.canal.connector.core.spi.ExtensionLoader - extension classpath dir: /home/canal-1.1.5/canal.adapter-1.1.5/plugin
2023-04-02 13:22:52.982 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal-client mq topic: cxstar_oa-g1 succeed
2023-04-02 13:22:52.983 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ......
2023-04-02 13:22:52.983 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Start to connect destination: cxstar_oa <=============
2023-04-02 13:22:52.990 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8081"]
2023-04-02 13:22:52.991 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2023-04-02 13:22:53.013 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8081 (http) with context path ''
2023-04-02 13:22:53.028 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 5.259 seconds (JVM running for 6.378)
2023-04-02 13:22:53.081 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Subscribe destination: cxstar_oa succeed <============5、canal-adapter启动可能的报错问题
1.com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
[main] ERROR com.alibaba.druid.pool.DruidDataSource - init datasource error, url: jdbc:mysql://127.0.0.1:3306/canal?useUnicode=true&useSSL=true
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet successfully received from the server was 216 milliseconds ago. The last packet sent successfully to the server was 210 milliseconds ago.解决方法:/conf/application.yml 中的mysql连接去除&useSSL=true
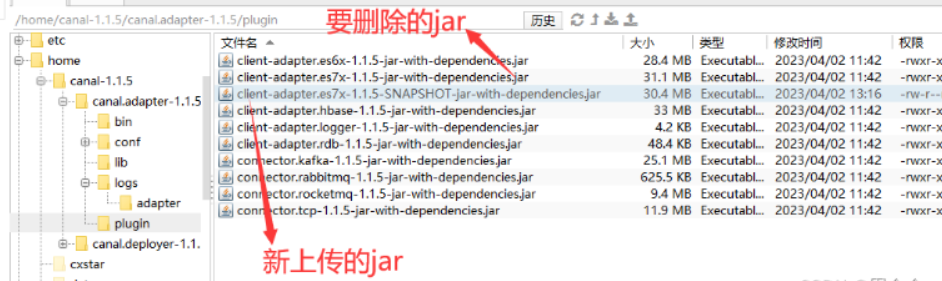
2. com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSource
ERROR c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 failed
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassCastException: com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSourceat com.alibaba.otter.canal.client.adapter.es7x.ES7xAdapter.init(ES7xAdapter.java:54) ~[client-adapter.es7x-1.1.5-jar-with-dependencies.jar:na]
原因:druid 包冲突
解决方法:
方法1.下载源码包 ,修改client-adapter/escore/pom.xml
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><scope>provided</scope></dependency>
打包后将client-adapter/es7x/target/client-adapter.es7x-1.1.5-jar-with-dependencies.jar上传到服务器,替换adataper/plugin下的同名jar文件
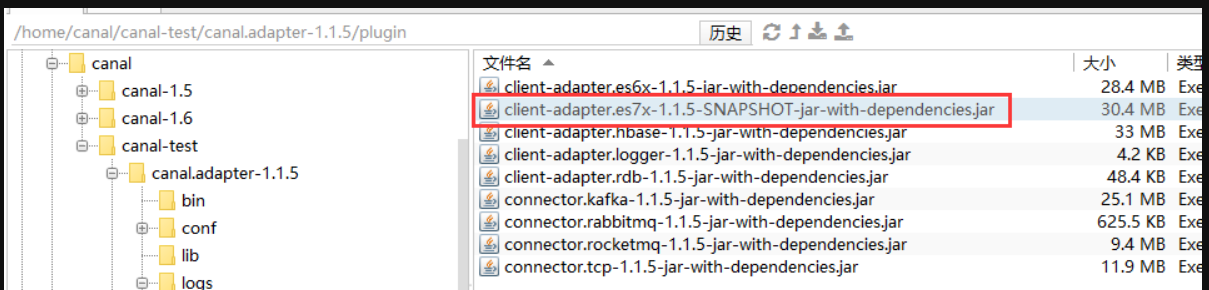
方法2.下载v1.1.5-alpha-2:
找到plugin目录下的client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar
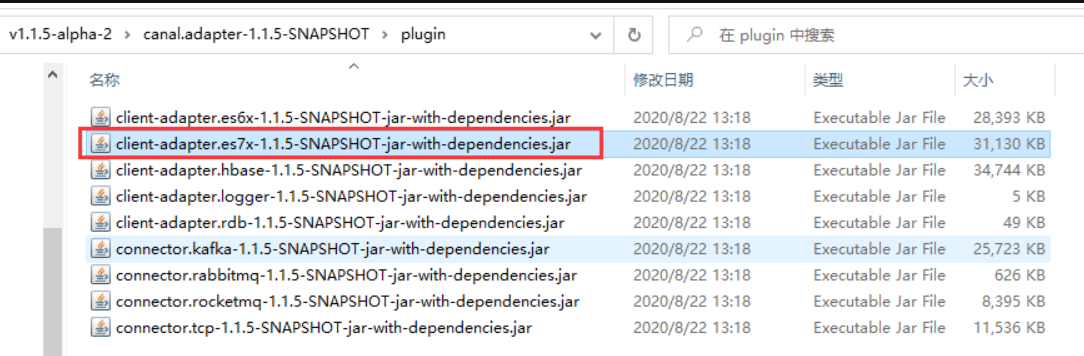
上传到服务器 canal.adapter-1.1.5/plugin目录下,同时删除client-adapter.es7x-1.1.5-jar-with-dependencies.jar
3、Load canal adapter: es7 failed,Name or service not known
ERROR c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 failed
java.lang.RuntimeException: java.net.UnknownHostException: http: Name or service not knownat com.alibaba.otter.canal.client.adapter.es7x.ES7xAdapter.init(ES7xAdapter.java:54) ~[client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
解决方案:/conf/application.yml配置中 ,hosts不要带http://
4、java.lang.NullPointerException: esMapping._type
ERROR c.a.o.c.client.adapter.es.core.monitor.ESConfigMonitor - esMapping._type
java.lang.NullPointerException: esMapping._typeat com.alibaba.otter.canal.client.adapter.es.core.config.ESSyncConfig.validate(ESSyncConfig.java:35) ~[client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]at com.alibaba.otter.canal.client.adapter.es.core.monitor.ESConfigMonitor$FileListener.onFileChange(ESConfigMonitor.java:102) ~[client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]at org.apache.commons.io.monitor.FileAlterationObserver.doMatch(FileAlterationObserver.java:400) [commons-io-2.4.jar:2.4]at org.apache.commons.io.monitor.FileAlterationObserver.checkAndNotify(FileAlterationObserver.java:334) [commons-io-2.4.jar:2.4]at org.apache.commons.io.monitor.FileAlterationObserver.checkAndNotify(FileAlterationObserver.java:304) [commons-io-2.4.jar:2.4]at org.apache.commons.io.monitor.FileAlterationMonitor.run(FileAlterationMonitor.java:182) [commons-io-2.4.jar:2.4]at java.lang.Thread.run(Thread.java:748) [na:1.8.0_221]
解决方案:canal.adapter-1.1.5/conf/es7目录下的yml中增加一个官方配置的属性
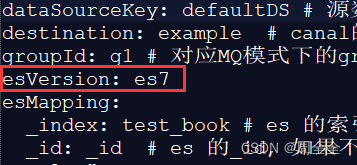
hosts: 192.168.0.182:9200 # ES连接地址
验证canal-adapter是否启动成功
查看日志 canal.adapter-1.1.5/logs/adapter/adapter.log
[org.springframework.cloud.context.properties:name=configurationPropertiesRebinder,context=2b76ff4e,type=ConfigurationPropertiesRebinder]
2023-02-03 09:34:13.373 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## syncSwitch refreshed.
2023-02-03 09:34:13.374 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## start the canal client adapters.
2023-02-03 09:34:13.375 [main] INFO c.a.otter.canal.client.adapter.support.ExtensionLoader - extension classpath dir: /home/canal/canal-test/canal.adapter-1.1.5/plugin
2023-02-03 09:34:13.418 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: logger succeed
2023-02-03 09:34:13.643 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## Start loading es mapping config ...
2023-02-03 09:34:13.726 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## ES mapping config loaded
2023-02-03 09:34:13.995 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 succeed
2023-02-03 09:34:14.005 [main] INFO c.alibaba.otter.canal.connector.core.spi.ExtensionLoader - extension classpath dir: /home/canal/canal-test/canal.adapter-1.1.5/plugin
2023-02-03 09:34:14.029 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal-client mq topic: example-g1 succeed
2023-02-03 09:34:14.029 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Start to connect destination: example <=============
2023-02-03 09:34:14.029 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ......
2023-02-03 09:34:14.037 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8081"]
2023-02-03 09:34:14.039 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2023-02-03 09:34:14.067 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8081 (http) with context path ''
2023-02-03 09:34:14.080 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 5.221 seconds (JVM running for 5.807)
2023-02-03 09:34:14.169 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Subscribe destination: example succeed <=============
3、Canal 客户端实现
3.1、直接写入 Elasticsearch 方案
<dependencies><!-- Canal Client --><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.5</version></dependency><!-- Elasticsearch Client --><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.10.2</version></dependency><!-- Jackson for JSON processing --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.12.3</version></dependency>
</dependencies>
public class CanalToESClient {public static void main(String[] args) {// 创建 Canal 连接CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111),"example", "", "");// 创建 Elasticsearch 客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));int batchSize = 1000;try {connector.connect();connector.subscribe(".*\\..*");while (true) {Message message = connector.getWithoutAck(batchSize);long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {Thread.sleep(1000);} else {processEntries(message.getEntries(), esClient);}connector.ack(batchId);}} catch (Exception e) {e.printStackTrace();} finally {connector.disconnect();try {esClient.close();} catch (IOException e) {e.printStackTrace();}}}private static void processEntries(List<Entry> entries, RestHighLevelClient esClient) {for (Entry entry : entries) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {continue;}RowChange rowChange;try {rowChange = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("解析出错", e);}EventType eventType = rowChange.getEventType();String indexName = entry.getHeader().getTableName();for (RowData rowData : rowChange.getRowDatasList()) {if (eventType == EventType.DELETE) {processDelete(rowData.getBeforeColumnsList(), indexName, esClient);} else if (eventType == EventType.INSERT) {processInsert(rowData.getAfterColumnsList(), indexName, esClient);} else if (eventType == EventType.UPDATE) {processUpdate(rowData.getAfterColumnsList(), indexName, esClient);}}}}private static void processInsert(List<Column> columns, String indexName, RestHighLevelClient esClient) {Map<String, Object> jsonMap = new HashMap<>();String id = null;for (Column column : columns) {jsonMap.put(column.getName(), column.getValue());if (column.getIsKey()) {id = column.getValue();}}IndexRequest request = new IndexRequest(indexName).id(id).source(jsonMap);try {esClient.index(request, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}}// 类似实现 processUpdate 和 processDelete 方法
}3.2、通过消息队列中转
通过 Kafka/RocketMQ 中转:
-
Canal 将数据发送到 Kafka
-
独立的消费者服务从 Kafka 消费并写入 Elasticsearch
Canal 配置 conf/canal.properties:
# 启用 Kafka
canal.serverMode = kafka
# Kafka 配置
kafka.bootstrap.servers = 127.0.0.1:9092
canal.mq.topic = canal_topic
canal.mq.partition = 04、Elasticsearch 数据映射处理
在同步数据前,建议先创建索引并定义映射:
PUT /your_index
{"mappings": {"properties": {"id": {"type": "keyword"},"name": {"type": "text"},"price": {"type": "double"},"create_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss||epoch_millis"}}}
}5、注意事项
-
数据一致性:
-
确保 Canal 能正确处理事务
-
考虑失败重试机制
-
实现幂等性处理
-
-
性能优化:
-
批量写入 Elasticsearch
-
合理设置 Canal 的批次大小
-
考虑使用消息队列缓冲
-
-
监控:
-
监控 Canal 的延迟
-
监控 Elasticsearch 的写入性能
-
建立报警机制
-
-
初始全量同步:
-
Canal 主要用于增量同步
-
初始数据需要通过其他方式(如 Logstash)先导入
-
-
Schema 变更:
-
MySQL 表结构变更时,需要同步更新 Elasticsearch 的 mapping
-
考虑使用动态 mapping 或提前规划好字段类型
-
总结
canal作为一个用于数据库增量数据同步的工具,能够实现数据库镜像、实时备份、索引维护等功能。通过模拟MySQL slave,接收并解析MySQL的binary log,将增量数据同步到目标存储。
参考文章:
1、canal实时同步mysql数据到elasticsearch(部署,配置,测试)(一)_canal mysql-CSDN博客![]() https://blog.csdn.net/qq_29864051/article/details/128833785?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522742995008c8166920b3c9fe48dd88a59%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=742995008c8166920b3c9fe48dd88a59&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-128833785-null-null.142^v102^pc_search_result_base1&utm_term=%E5%85%B3%E4%BA%8Ecanal%E6%9C%8D%E5%8A%A1%E5%AE%9E%E7%8E%B0mysql%E5%88%B0elasticserach%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_29864051/article/details/128833785?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522742995008c8166920b3c9fe48dd88a59%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=742995008c8166920b3c9fe48dd88a59&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-128833785-null-null.142^v102^pc_search_result_base1&utm_term=%E5%85%B3%E4%BA%8Ecanal%E6%9C%8D%E5%8A%A1%E5%AE%9E%E7%8E%B0mysql%E5%88%B0elasticserach%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5&spm=1018.2226.3001.4187