LangGraph学习笔记 — LangGraph中State状态模式
目录
1. LangGraph中State的定义模式
1.1 使用字典类型定义状态
1.2 Reducer函数的机制
1.3 在图状态中处理消息的思路
1.4 MessageGraph源码功能解析
在LangGraph框架中,不论构建的代理简单或复杂,其本质都是通过节点(Node)和边(Edge)的有机组合来形成一个完整的图(Graph)。这种构建方式所形成的工作流逻辑十分清晰:每个节点在完成其任务后,都会通过边来指示下一个工作步骤,从而赋予整个应用系统更高的灵活性和可扩展性。
在AI Agent应用程序的设计中,场景的复杂性直接决定了构建图的复杂度。例如,最简单的场景可能仅涉及一个大模型的问答流程,形式为:START -> Node -> END(其中大模型的交互逻辑被封装在Node中)。而更复杂的场景则可能涉及多个AI Agent的协同工作,包括多个分支和循环的构成。无论是简单还是复杂的图,LangGraph的价值永远不在于如何去定义节点,如何去定义边,而是在于如何有效管理各个节点的输入和输出,以保持图的持续运行状态。LangGraph的底层图算法采用消息传递机制来定义和执行这些图中的交互流程,其中状态(State)组件扮演着关键的载体角色,负责在图的各个节点之间传递信息。这也就意味着,LangGraph框架的核心在于State的有效使用和掌握。在复杂的应用中,State组件需要存储和管理的信息量会显著增加。核心功能如工具使用、记忆能力和人机交互等,都依赖State来实现和维护。所以,接下来我们对LangGragh框架的探索,都将紧密围绕State的实现和应用机制展开,这包括LangGraph内置封装好的工具/方法的使用,以及我们自定义构建功能时的实现方法。
1. LangGraph中State的定义模式
为了更清晰地说明这一过程,我们可以借助如下流程图来理解消息在图结构中的流转过程:
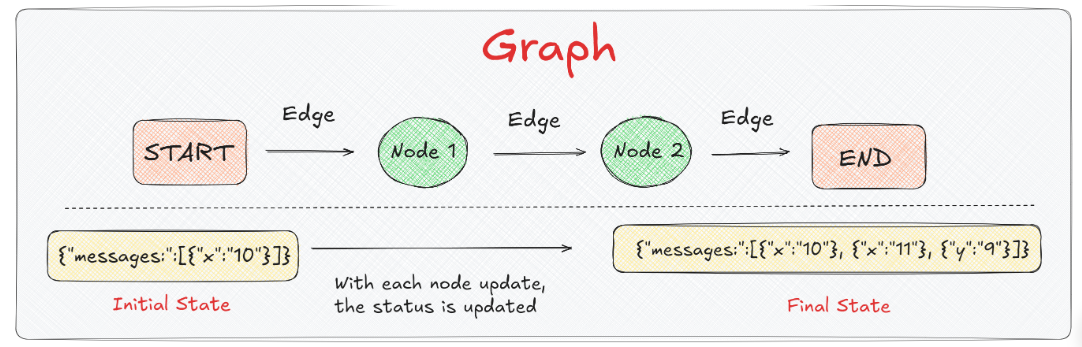
LangGraph构建的图中的每个节点都具备访问、读取和写入状态的权限。当某一个节点去修改状态时,它会将此信息广播到图中的所有其他节点。这种广播机制允许其他节点响应状态的变化并相应地调整其行为。如上图所示,从初始状态(Initial State)开始,其中包含了一条消息 { "x": "10" },随着消息在节点间通过边传递,每个节点根据其逻辑对状态进行更新。Node 1 和 Node 2 分别对状态进行了处理和变更,结果是在图的末端,我们得到了一个包含三条消息的最终状态 { "x": "10" }, { "x": "11" }, { "y": "9" }。从开发的角度来看,State实际上是一个共享的数据结构。如上图所示,状态表现为一个简单的字典。通过对这个字典进行读写操作,可以实现自左而右的数据流动,从而构建一个可运行的图结构。
1.1 使用字典类型定义状态
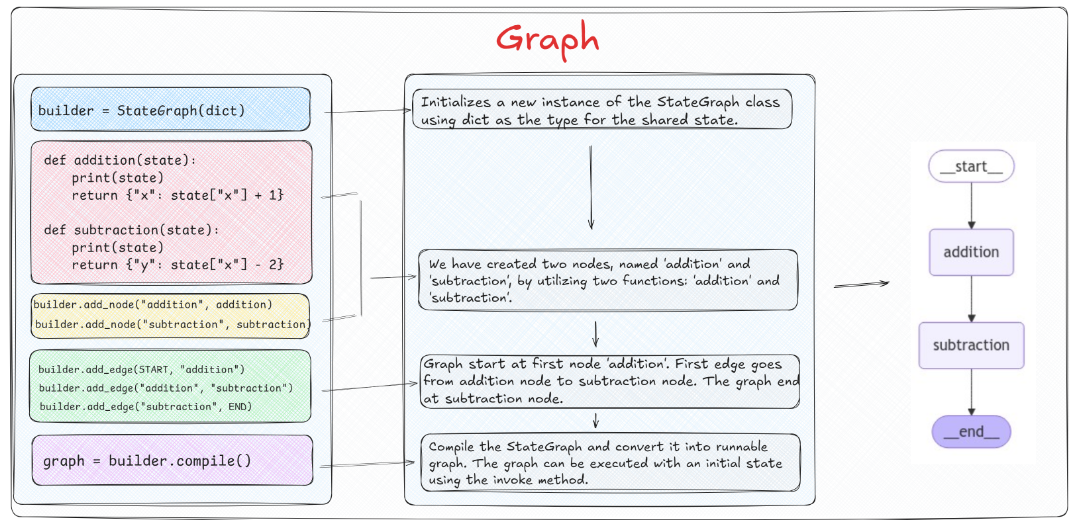
对于上图中的数据场景,我们来实际的进行代码复现。
首先,我们将图的状态设计为一个字典,用于在不同节点间共享和修改数据,然后使用StateGraph类进行图的实例化。代码如下:
from langgraph.graph import StateGraph# 构建图
builder = StateGraph(dict)
builder.schemadict
接下来,定义两个节点。addition节点是一个加法逻辑,接收当前状态,将字典中x的值增加1,并返回新的状态。而subtraction节点是一个减法逻辑,接收从addition节点传来的状态,从字典中的x值减去2,创建并返回一个新的键y。
def addition(state):print(state)return {"x": state["x"] + 1}def subtraction(state):print(state)return {"y": stat["x"] - 2} 然后,进行图结构的设计。具体来看,我们添加名为addition和subtraction的节点,并关联到上面定义的函数。设定图的起始节点为addition,并从addition到subtraction设置一条边,最后从subtraction到结束节点设置另一条边。代码如下:
from langgraph.graph import START, END# 向图中添加两个节点
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)# 构建节点之间的边
builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)#编译图
graph = builder.compile()# 定义一个初始化的状态
initial_state = {"x":10}graph.invoke(initial_state){'y': 9}
在图的执行过程中,每个节点的函数会被调用,并且接收到前一个节点返回的状态作为输入。每个函数处理完状态后,会输出一个新的状态,传递给下一个节点。这里需要注意的一个关键信息是:节点函数不需要返回整个状态,而是仅返回它们更新的部分。也就是说:在每个节点的函数内部逻辑中,需要使用和更新哪些State中的参数中,只需要在return的时候指定即可,不必担心未在当前节点处理的State中的其他值会丢失,因为LangGraph的内部机制已经自动处理了状态的合并和维护。
上述代码执行过程中图的运行状态如下图所示:
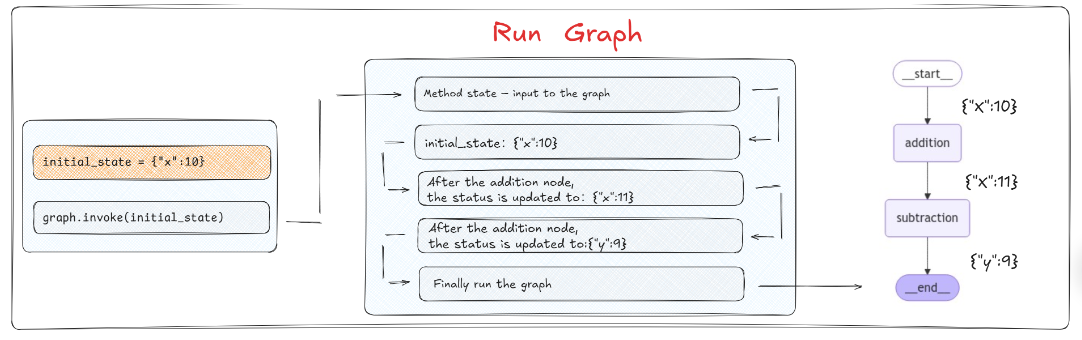
总体来看,该图设置了一个简单的工作流程。其中值首先在第一个节点通过加法函数增加,然后在第二个节点通过减法函数减少。这一流程展示了节点如何通过图中的共享状态进行交互。需要注意的是,状态在任何给定时间只包含来自一个节点的更新信息。这意味着当节点处理状态时,它只能访问与其特定操作直接相关的数据,从而确保每个节点的逻辑是隔离和集中的。使用字典作为状态模式非常简单,由于缺乏预定义的模式,节点可以在没有严格类型约束的情况下自由地读取和写入状态,这样的灵活性有利于动态数据处理。然而,这也要求开发者在整个图的执行过程中保持对键和值的一致性管理。因为如果在任何节点中尝试访问State中不存在的键,会直接中断整个图的运行状态。
到此为止,我们可以来思考一个问题:既然所有节点都会向状态(State)发出更新,为什么仅通过返回需要更新的键值,就能实现状态的全局共享呢?除此之外,如果我们需要对状态进行更复杂的操作,如新增、删除或修改等,应该如何构造这些操作呢?这就引出了我们需要深入理解的概念——在 LangGraph 中如何利用 Reducer 函数来精细控制状态的变化。
1.2 Reducer函数的机制
LangGraph内部原理是:State中的每个key都有自己独立的Reducer函数,通过指定的reducer函数应用状态值的更新。
Reducer 函数用来根据当前的状态(state)和一个操作(action)来计算并返回新的状态。它是一种设计模式,用于将业务逻辑与状态变更解耦,使得状态的变更预测性更强并且容易追踪。这样的函数通常接收两个参数:当前的状态(state)和一个描述应用了什么操作的对象(action), 根据 action 类型来决定如何修改状态。比如,在一个购物车应用中,可能会有添加商品、删除商品、修改商品数量等操作。返回一个新的状态对象,而不是修改原始状态对象。简单理解,Reducer函数做的就是根据给定的输入(当前状态和操作)生成新的状态。
LangGraph Update State 源码:Graphs
LangGraph中,如果没有显示的指定,则对该键的所有更新都执行的是覆盖操作。我们看一下下面这段代码:
from typing_extensions import TypedDict
from langgraph.graph import START, StateGraph, ENDdef addition(state):print(state)return {"x": state["x"] + 1}def subtraction(state):print(state)return {"y": state["x"] - 2}class State(TypedDict):x: inty: int# 构建图
builder = StateGraph(State) # 向图中添加两个节点
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)# 构建节点之间的边
builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)graph = builder.compile()# 定义一个初始化的状态
initial_state = {"x":10}graph.invoke(initial_state){'x': 11, 'y': 9}
在这里,我们通过使用 TypedDict 来定义 State 的模式,从而精确控制图结构中状态信息的格式和类型。与上面所使用的传统字典类型相比,TypedDict 允许我们明确指定每个键的类型,有助于防止在状态管理过程中出现类型错误。
接下来 我们再看另一种情况:在下面的图中,State还是一个结构化字典,其中包含一个名为 messages 的键,该键保存一个字符串列表。我们用这个状态管理节点在执行期间将处理的数据。状态的模式是使用TypedDict定义,它指定消息是带注释的字符串列表。该注释包括operator.add,表示可以通过使用添加操作将新消息与现有消息组合来更新列表。代码如下:
import operator
from typing import Annotated, TypedDict, Listclass State(TypedDict):messages: Annotated[List[str], operator.add]Annotated 是 Python的一个类型提示工具,属于 typing 模块。它被用来添加额外的信息或元数据到类型提示上。这些信息可以是关于如何使用该类型的指示,或者提供给静态类型检查器、框架和库的其他元数据。
当定义状态模式的结构发生了变化以后,在节点函数中的读取和存储逻辑也要发生相应的变化。流程图如下:
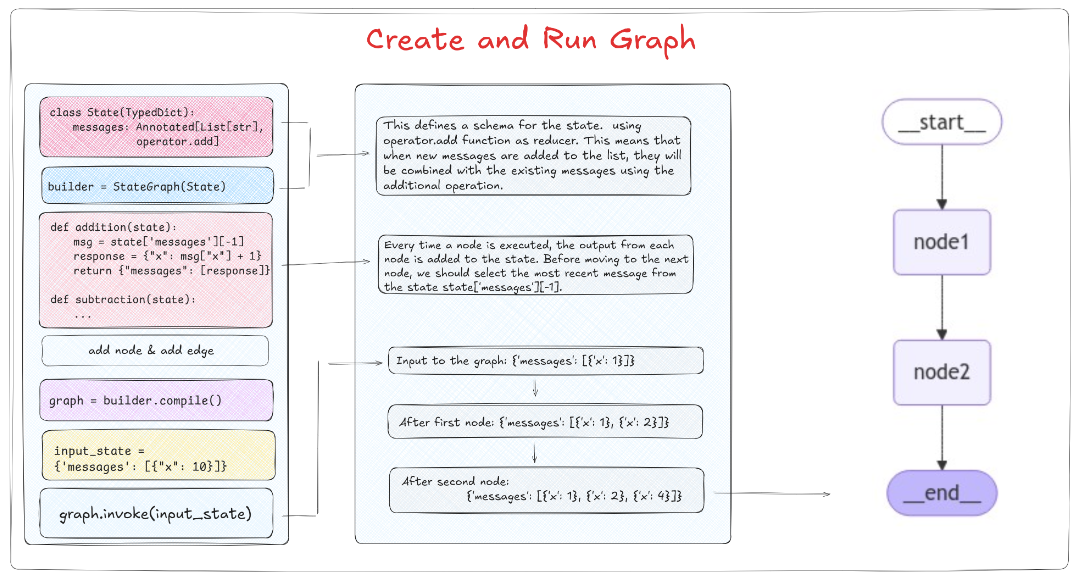
上图中的完整代码复现如下:
def addition(state):print(state)msg = state['messages'][-1]response = {"x": msg["x"] + 1}return {"messages": [response]}def subtraction(state):print(state)msg = state['messages'][-1]response = {"x": msg["x"] - 2}return {"messages": [response]}# 构建图
builder = StateGraph(State) # 向图中添加两个节点
builder.add_node("node1", addition)
builder.add_node("node2", subtraction)# 构建节点之间的边
builder.add_edge(START, "node1")
builder.add_edge("node1", "node2")
builder.add_edge("node2", END)graph = builder.compile()input_state = {'messages': [{"x": 10}]}graph.invoke(input_state){'messages': [{'x': 10}, {'x': 11}, {'x': 9}]}
通过这样的例子我们可以理解:Reducers的目的是在LangGraph框架中的状态管理系统中,允许更灵活地定义状态如何根据各种操作更新。通过指定不同的 reducer函数,我们可以控制状态的每个部分应如何响应特定的更新。
1.3 在图状态中处理消息的思路
Reducer机制的一个现实意义是:我们可以基于这种方式去构建历史对话记录。因为目前大多数大模型应用都是接受消息列表作为输入。 就像LangChain中的Chat Model,需要接收Message对象列表作为输入。这些消息有多种形式,例如HumanMessage (用户输入)或AIMessage ( 大模型响应)。
下面这个示例,我们进一步将大模型接入到 LangGraph 工作流程中,并允许动态消息处理以及与模型的交互。其余组件与先前定义的图中的组件相同。在这里,第一个节点调用大模型并生成一个输出,该输出是一个AIMessage对象类型,然后,第二个节点直接将前一个节点的 AIMessage 提取为具体的JSON格式,完整代码如下:
import getpass
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import operator
from typing import Annotated, TypedDict, List
from langgraph.graph import StateGraph, END
from IPython.display import Image, display
from langchain_core.messages import SystemMessage, HumanMessage, AIMessageif not os.environ.get("OPENAI_API_KEY"):os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")llm = ChatOpenAI(model='gpt-4o')# 定义图的状态模式
class State(TypedDict):messages: Annotated[List[str], operator.add]# 创建图的实例
builder = StateGraph(State)def chat_with_model(state):print(state)print("-----------------")messages = state['messages']response = llm.invoke(messages)return {"messages": [response]}def convert_messages(state):# "您是一位数据提取专家,负责从文本中检索关键信息。请为所提供的文本提取相关信息,并以 JSON 格式输出。概述所提取的关键数据点。"EXTRACTION_PROMPT = """You are a data extraction specialist tasked with retrieving key information from a text.Extract such information for the provided text and output it in JSON format. Outline the key data points extracted."""print(state)print("-----------------")messages = state['messages']messages = messages[-1] messages = [SystemMessage(content=EXTRACTION_PROMPT),HumanMessage(content=state['messages'][-1].content)]response = llm.invoke(messages)return {"messages": [response]}# 添加节点
builder.add_node("chat_with_model", chat_with_model)
builder.add_node("convert_messages", convert_messages)# 设置启动点
builder.set_entry_point("chat_with_model")# 添加边
builder.add_edge("chat_with_model", "convert_messages")
builder.add_edge("convert_messages", END)# 编译图
graph = builder.compile()query="你好,请你介绍一下你自己"
input_message = {"messages": [HumanMessage(content=query)]}result = graph.invoke(input_message)print(result) {'messages': [HumanMessage(content='你好,请你介绍一下你自己', additional_kwargs={}, response_metadata={})]}
-----------------
{'messages': [HumanMessage(content='你好,请你介绍一下你自己', additional_kwargs={}, response_metadata={}), AIMessage(content='你好!我是一个大型语言模型,由OpenAI开发,名为ChatGPT。我设计的目的是帮助回答各种问题,提供信息和协助解决问题。我的知识基于截至2021年9月之前的广泛数据,因此我可以回答许多关于历史、科学、文化、技术等方面的问题。不过,我没有个人经历或情感,因为我只是一个程序。如果你有什么问题或需要帮助,随时告诉我!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 92, 'prompt_tokens': 14, 'total_tokens': 106, 'prompt_tokens_details': {'cached_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_a7d06e42a7', 'finish_reason': 'stop', 'logprobs': None}, id='run-3787c3fd-c249-497a-a753-4eca34da80c5-0', usage_metadata={'input_tokens': 14, 'output_tokens': 92, 'total_tokens': 106, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})]}
print(result["messages"][-1].content) {"language_model": {"name": "ChatGPT","developer": "OpenAI","purpose": ["Answering questions","Providing information","Assisting with problem-solving"],"knowledge_cutoff": "September 2021","areas_of_knowledge": ["History","Science","Culture","Technology"],"attributes": ["No personal experiences","No emotions","Program-based"]}
}
如上所示,在许多现实开发情况下,将先前的对话历史记录存储为图形状态中的消息列表是必须要做的。而实现这一功能,在LangGraph框架中可以像存储Message对象列表的图状态添加一个键(通道),并使用Reducer函数对其进行注释,从而告诉图在每次状态更新时(例如,当节点发送更新时)更新状态中的Message对象列表。如上所演示的案例中,简单地将消息追加到现有列表中,就是通过operator.add实现。
1.4 MessageGraph源码功能解析
更复杂一点的,如果我们还想手动更新图形状态中的消息(例如人机交互),使用operator.add能做到的功能极限是:发送到图表的手动状态更新将被附加到现有的消息列表中,而不是更新现有的消息。为了避免这种情况,我们则需要一个可以跟踪消息 ID 并覆盖现有消息(如果更新)的Reducer函数。为此,就引出了LangGraph预构建的add_messages函数,这个更高级的Reducer所实现的是:对于全新的消息,它会附加到现有列表,但它也会正确处理现有消息的更新。如何理解这句话呢?我们接下来就从源码角度进行详细解析。
之前我们分析过LangGraph 中的 StateGraph类,这个类允许我们创建图,其节点通过读取和写入共享状态进行通信。 StateGraph 类由开发者定义的 State 对象进行参数化,该对象表示图中的节点将通过其进行通信的共享数据结构。
MessageGraph 是 StateGraph 的一个子类,使用了 Annotated[list[AnyMessage], add_messages] 来初始化其基类 StateGraph。这里的 list[AnyMessage] 指明了 MessageGraph 的状态由消息列表组成,而这个列表类型是一个可以不断添加消息的结构(因为列表是可变的数据类型),MessageGraph 中的每个节点都将消息列表作为输入,并返回零个或多个消息作为输出。add_messages函数用于将每个节点的输出消息合并进图的状态中已存在的消息列表。其源码定义如下:
MessageGraph 源码:https://github.com/langchain-ai/langgraph/blob/e3ef9adac7395e5c0943c22bbc8a4a856b103aa3/libs/langgraph/langgraph/graph/message.py#L150
class MessageGraph(StateGraph):def __init__(self) -> None:super().__init__(Annotated[list[AnyMessage], add_messages]])Messages图可以单独构建,如下代码所示:
import getpass
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplateif not os.environ.get("OPENAI_API_KEY"):os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")llm = ChatOpenAI(model="gpt-4o")def chatbot(state: State):print(state)return {"messages": [llm.invoke(state["messages"])]}from langgraph.graph.message import MessageGraphbuilder = MessageGraph()builder.add_node("chatbot", lambda state: [("assistant", "你好,最帅气的人!")])builder.set_entry_point("chatbot")builder.set_finish_point("chatbot")graph = builder.compile()graph.invoke([("user", "你好,请你介绍一下你自己.")]) [HumanMessage(content='你好,请你介绍一下你自己.', additional_kwargs={}, response_metadata={}, id='362af5dc-338e-4c53-81e0-3836ac83b3d5'),AIMessage(content='你好,最帅气的人!', additional_kwargs={}, response_metadata={}, id='9d631688-af5f-4daa-b00b-4362392f6730')]
graph.invoke([("user", "Hi 3213.")]) [HumanMessage(content='Hi 3213.', additional_kwargs={}, response_metadata={}, id='b4ef7019-7074-4029-8177-75ed28b2957c'),AIMessage(content='你好,最帅气的人!', additional_kwargs={}, response_metadata={}, id='8968e345-1d04-4138-998d-65b66cabb107')]
MessageGraph通过使用单个仅附加消息列表作为其整个状态来管理状态,其中每个节点处理该列表并可以返回其他消息。这种设计特别适合对话式应用程序,可以轻松跟踪对话历史和交互。
继而进一步来看add_messages这个Reducer函数的定义情况:
class MessagesState(TypedDict):messages: Annotated[list[AnyMessage], add_messages]def add_messages(left: Messages, right: Messages) -> Messages:"""Merges two lists of messages, updating existing messages by ID.By default, this ensures the state is "append-only", unless thenew message has the same ID as an existing message.Args:left: The base list of messages.right: The list of messages (or single message) to mergeinto the base list.Returns:A new list of messages with the messages from `right` merged into `left`.If a message in `right` has the same ID as a message in `left`, themessage from `right` will replace the messagage(content='Hello', id=...)]}```"""# coerce to listif not isinstance(left, list):left = [left] # type: ignore[assignment]if not isinstance(right, list):right = [right] # type: ignore[assignment]# coerce to messageleft = [message_chunk_to_message(cast(BaseMessageChunk, m))for m in convert_to_messages(left)]right = [message_chunk_to_message(cast(BaseMessageChunk, m))for m in convert_to_messages(right)]# assign missing idsfor m in left:if m.id is None:m.id = str(uuid.uuid4())for m in right:if m.id is None:m.id = str(uuid.uuid4())# mergeleft_idx_by_id = {m.id: i for i, m in enumerate(left)}merged = left.copy()ids_to_remove = set()for m in right:if (existing_idx := left_idx_by_id.get(m.id)) is not None:if isinstance(m, RemoveMessage):ids_to_remove.add(m.id)else:merged[existing_idx] = melse:if isinstance(m, RemoveMessage):raise ValueError(f"Attempting to delete a message with an ID that doesn't exist ('{m.id}')")merged.append(m)merged = [m for m in merged if m.id not in ids_to_remove]return merged add_messages整体的核心逻辑是合并两个消息列表,按 ID 更新现有消息。默认情况下,状态为“仅附加”,当新消息与现有消息具有相同的 ID时,进行更新。具体参数是:
- left ( Messages ) – 消息的基本列表。
- right ( Messages ) – 要合并到基本列表中的消息列表(或单个消息)。
而返回值是一个消息列表,其中的合并逻辑则是:如果right的消息与left的消息具有相同的 ID,则right的消息将替换left的消息,否则作为一条新的消息进行追加。
from langgraph.graph.message import add_messages
from langchain_core.messages import AIMessage, HumanMessagemsgs1 = [HumanMessage(content="你好。", id="1")]
msgs2 = [AIMessage(content="你好,很高兴认识你。", id="2")]add_messages(msgs1, msgs2) [HumanMessage(content='你好。', additional_kwargs={}, response_metadata={}, id='1'),AIMessage(content='你好,很高兴认识你。', additional_kwargs={}, response_metadata={}, id='2')]
msgs1 = [HumanMessage(content="你好。", id="1")]
msgs2 = [HumanMessage(content="你好呀。", id="1")]add_messages(msgs1, msgs2) [HumanMessage(content='你好呀。', additional_kwargs={}, response_metadata={}, id='1')]
消息状态管理不仅可以在MessageGraph中定义,还可以在StateGraph中定义。相比之下, StateGraph允许更复杂的状态结构,其中状态可以是任何 Python 类型(如 TypedDict 或 Pydantic 模型),并且可以通过各种方式更新。 StateGraph 中的每个节点都会接收当前状态并返回更新后的状态,从而实现除消息处理之外的更复杂的数据操作和工作流程。因此,MessageGraph 专门用于以消息为中心的工作流程,而 StateGraph 则更通用,适用于更广泛的应用程序。