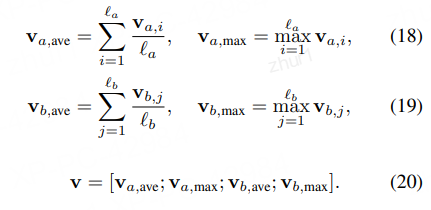句子表征-文本匹配--representation-based/interactive-based
传统匹配模型
1)tf-idf
2)Bm25
3)隐式模型:一般是将query、title都映射到同一个空间的向量,然后用向量的距离或者相似度作为匹配分,例如使用主题模型
4)翻译、转换模型:将doc映射到query空间,然后做匹配;或者计算将doc翻译成query的概率(同语言的翻译问题)
深度学习语义匹配的方法分类
从输入句子embedding上,主要分为如下3个方向
1).单语义,两个句子分别编码后计算相似度;
2).多粒度编码提取特征,字、短语;
3).匹配矩阵模型,句子间两两交互,交互后用深度网络提取特征。
模型发展上主要分为如下三种类型
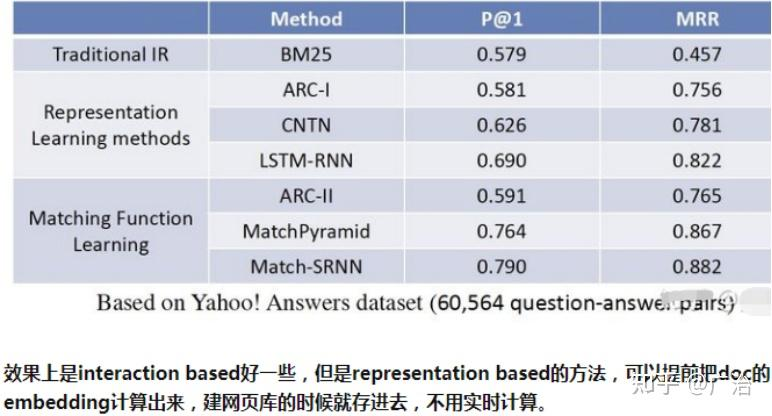
1)representation-based,DSSM、CNN、RNN、attention
这类方法是先分别学习出query和doc的语义向量表示,然后用两个向量做简单的cosine(或者接MLP也可以),重点是学习语义表示(representation learning)
2)interaction based,ARC-2、MatchPyramid、
这种方法不直接学习query和doc的语义表示向量,而是在底层,就让query和doc提前交互,建立一些基础的匹配信号,例如term和term层面的匹配,再想办法把这些基础的匹配信号融合成一个匹配分
3)representation-based 和interaction-based方法的融合 Duet, WWW17,微软
两者各有千秋、各有各自的适用场景。interaction based的方案对长的、冷门的query更有效,representation based的模型对短的、热门的query更有效。
搜索里的query和doc的相关性匹配
相关方法也主要分为2类:
1)基于全局分布的匹配
Deep Relevance Matching Model;
K-NRM: Kernel Pooling as Matching Function;
2)基于局部内容term的匹配
DeepRank;
Position-Aware Neural IR Model;
一 representation-based
1.1 词袋句向量
最简单的就是直接从词向量计算句向量。
首先可以用mean、max池化,相比字面n-gram重合度肯定是有提升的。但当句子中的噪声多起来之后,如果两个句子有大量重合的无意义词汇,分数也会很高,这时候就可以考虑加权求和,比如TF-IDF。
1.1.2 2016 WMD
题目:From Word Embeddings To Document Distances
论文:http://proceedings.mlr.press/v37/kusnerb15.pdf
代码:https://github.com/mkusner/wmd
之前提到的相似度任务都适用cosine相似度衡量的,也有学者研究了其他metric。2016年的WMD提出了Word Mover’s Distance这一概念,用句子A走到句子B的最短距离来衡量两者的相似程度。表示在下图中就是非停用词的向量转移总距离:
1.1.3 2017 SIF
题目:A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS
论文:https://openreview.net/pdf?id=SyK00v5xx
代码:https://github.com/PrincetonML/SIF
ICLR2017论文SIF提出了名为smooth inverse frequency的方法,先由词向量加权平均得到句向量,再对多个句子组成的句向量矩阵进行PCA,让每个句向量减去第一主成分,去掉“公共”的部分,保留更多句子本身的特征。该方法在相似度任务上有10%-30%的提升,甚至超过了一些RNN模型,十分适合对速度要求高、doc相似度计算的场景。
1.2 有监督模型
1.2.1 2013 DSSM
1.2.2 2015 siamCNN
1.2.3 2016 siamLSTM
1.2.4 2016 Multi-view
1.3 预训练 + 迁移
1.3.1 2015 skip-thought
基本思想: 采用seq2seq思想,通过当前句去预测文章中当前句的上一句和下一句,最后产生副产物句向量
优点: 适用于具有句子连贯性的数据集,比如文章,小说,对话等
缺点:训练耗时耗时长,使用场景有限
1.3.2 2016 fastSent
1.3.3 2016 SDAE
1.3.4 2017 joint-many
1.3.5 2017 inferSent
该模型是由facebook AI提出的。
论文链接:https://arxiv.org/pdf/1705.02364.pdf
代码链接:https://github.com/facebookresearch/InferSent
1.3.5.1 模型解读
该模型也是一个古老的产物,主要是较于经典,模型的整体也不复杂,它属于特征式实现方案,编码器的参数共享(uses a shared sentence encoder),和上一篇介绍的ESIM有很多相似之处,特别是文本向量的特征交互处
图中蓝色的部分代表编码器,对于编码器作者比较了7个不同的网络架构:LSTM、GRU、concatenate GRU的前向和后向的最后一个隐层状态、双向BiLSTM分别取最大和平均pooling、self–attentive网络、分层卷积网络。
作者指出具有最大池化的BiLSTM网络是最好的通用文本编码方法。
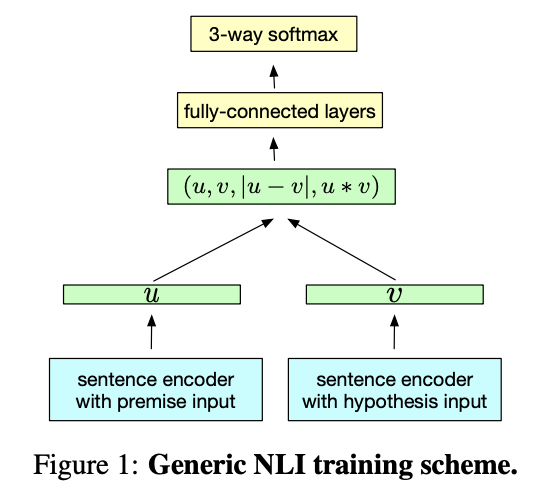
图中绿色部分是文本向量产出和文本向量的特征交互部分
图中黄色的部分是结全连接层进一步进行特征抽取,最后接分类器进行分类部分(使用的数据是关于相似度的三分类)。
具体流程
1)句子对中的句子分别通过sentence encoder获得句向量u和v
2)句向量u,v经过连接、element-wise 向量差(取绝对值)、element-wise 向量积三种交互。
3)经过全连接层传给3-way softmax进行句子关系的预测
模型的缺点
回想下前面讲解的特征式实现方案的优势,相比于交互式效果确实差一些,但最主要的优势是快。使用方法是把候选文本通过训练好的模型编码成向量后存到向量化数据库,线上只需要把待查询文本通过模型进行编码,然后计算余弦相似度获取相似度得分。
所以在这里就会出现训练和预测不统一的问题,训练的是分类模型,预测却要通过cos计算相似度。

1.3.6 2017 SSE
1.3.7 2018 GenSen
1.3.8 2018 quick-thought
基本思想: 是对Skip-Thought的一种改进,将skip thoughts的预测行为修改成了分类问题
优点: 训练得到的句向量相比Skip-Thought有提升,训练速度有明显提升
缺点: 适用场景有限,句向量表现仍不突出
1.3.9 2019 USE
1.3.10 2019 sentence-BERT
1.3.11 2020 BERT-flow
1.3.12 2020 cross-thought
二 interactive-based
1.4.1 2016 DEC-att
1.4.2 2016 PWIM
1.4.3 2016 Match pyramid
1.4.4 2017 ESIM
ESIM(Enhanced LSTM for Natural Language Inference)
论文链接:https://arxiv.org/pdf/1609.06038.pdf
模型的核心主要有三部分:Input Encoding、Local Inference Modeling 和Inference Composition。
此外这里要特殊说明下,图的左半部分就是我们要讲的ESIM,右半部分的区别在于使用了一种叫Tree-LSTM的变种LSTM结构,可用于做句子的语法分析。在具体的文本匹配应用中可以不管这部分,所以这里也不讲解,我们只结合左半边的图来理解。
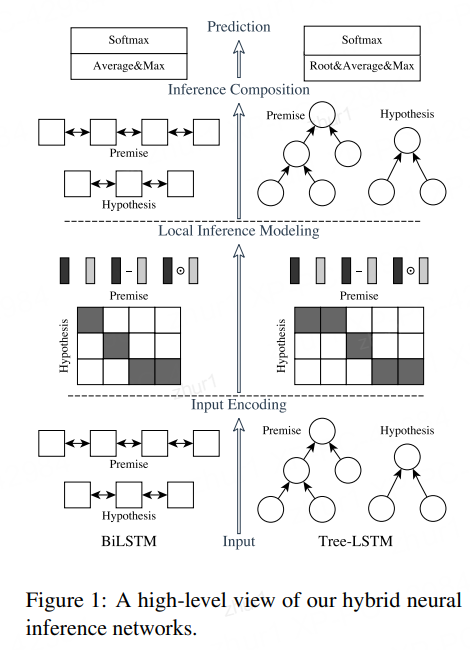
1.4.4.1 Input Encoding
这部分就是选用Bi-LSTM模型作为编码器对两个文本向量分别进行编码
1.4.4.2 Local Inference Modeling
这部分主要是进行特征交互以及特征加强从而形成新的特征。
1)首先是特征交互
这部分是一个交叉attention的过程,结合两条文本相互之间的关注程度对各自的特征进行加权
特征增强
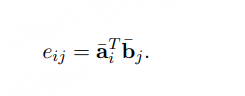
2)特征增强
具体就是特征拼接以及计算差和点积。
计算差是为了计算本身和关注另一个句子的差异性,更利于相似度的计算。
点积是特征加权。
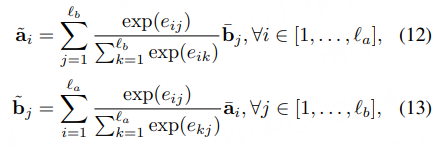
1.4.4.3 Inference Composition
这部分就是再次通过Bi-LSTM进行特征提取
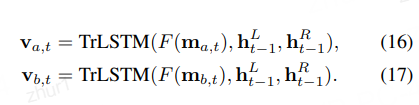
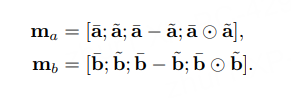
1.4.4.4 全局特征和局部特征的获取
结合上图可以发现在进行最后的Prediction时还有个Average&Max的操作,用于获取全局特征和局部特征
因为对于不同的句子,得到的向量v长度是不同的,为了方便最后一步的分析,这里把BiLSTM得到的值进行了池化处理,把结果储存在一个固定长度的向量中。
值得注意的是,因为考虑到求和运算对于序列长度是敏感的,因而降低了模型的鲁棒性,所以ESIM选择同时对两个序列进行average pooling和max pooling,再把结果放进一个向量中