电商项目_性能优化_数据同步
1、缓存同步
使用场景
1. Redis缓存当做数据库
大促等场景,并发请求数量的基数过大,即便只有很小比率的请求直接访问数据库其绝对数量也仍然不小,还是会存在系统雪崩的风险。
构建Redis集群后,由于集群可以水平扩容,因此只要集群足够大,理论上支持海量并发就不是问题。
所以可将将Redis当做数据库使用,将所有数据都缓存到Redis。解决缓存不命中的问题。
2. 缓存一致性
电商项目_性能优化_高并发缓存一致性-CSDN博客
在缓存一致性章节讲到过,为了保证DB和缓存的数据一致性,DB变更时,需要删除Redis缓存。
思考:Redis缓存了这么多的DB数据,如何保证数据一致性呢?
1. 分布式事务保证DB和缓存一致性。 缺点:性能低,另外缓存的异常也不应该影响业务。
2. 写DB时发一条消息,消费端更新Redis。缺点:对代码侵入大,还要实现消息发送接收。
3. 使用开源组件,订阅Binlog日志,更新缓存。 GOOD!
使用Binlog实时更新Redis缓存
Canle组件
官方主页:https://github.com/alibaba/canal
它通过模拟MySOL主从复制的交互协议,把自己伪装成一个MySOL的从节点,向 MySOL主节点发送dump请求。MySOL收到请求后,就会向 Canal开始推送Binlog,Canal解析Binlog字节流之后,将其转换为便于读取的结构化数据,供下游程序订阅使用。实际运用后的运行架构如图:
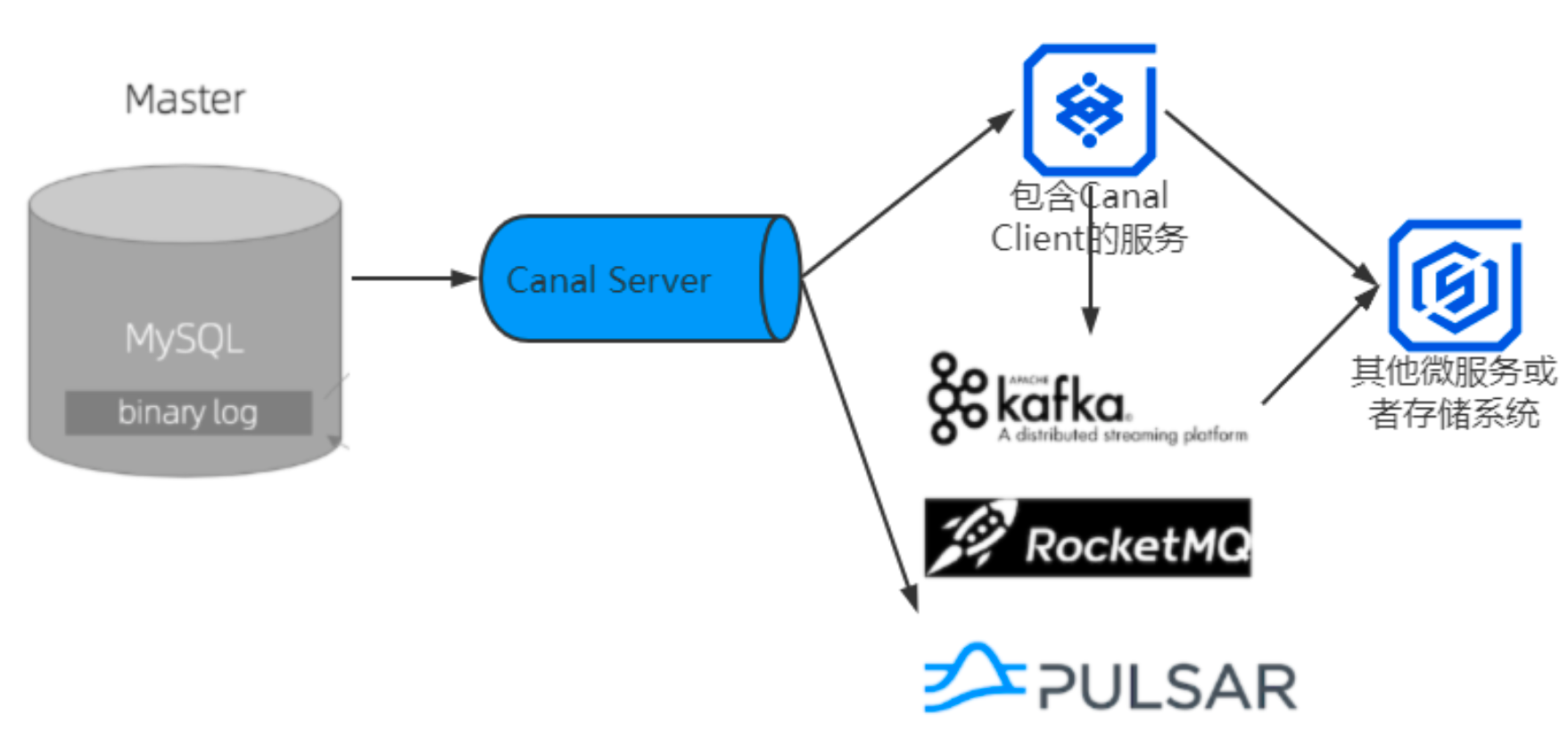
电商项目实现过程
1. 安装运行Canal服务
2.Mysql打开binlog日志
开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式
3. 给Canal设置一个用来复制数据的MySQL账号
-- 定这个用户名为Canal,密码Canal
CREATE USER canal IDENTIFIED BY 'canal';GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';FLUSH PRIVILEGES;4. 启动canel服务端
配置中的修改点:要同步的数据表、数据库
代码实现:
public class PromotionData implements IProcessCanalData { private final static String SMS_HOME_ADVERTISE = "sms_home_advertise";private final static String SMS_HOME_BRAND = "sms_home_brand";private final static String SMS_HOME_NEW_PRODUCT = "sms_home_new_product";private final static String SMS_HOME_RECOMMEND_PRODUCT = "sms_home_recommend_product";@Autowired@Qualifier("promotionConnector")private CanalConnector connector;@PostConstruct@Overridepublic void connect() {tableMapKey.put(SMS_HOME_ADVERTISE,promotionRedisKey.getHomeAdvertiseKey());tableMapKey.put(SMS_HOME_BRAND,promotionRedisKey.getBrandKey());tableMapKey.put(SMS_HOME_NEW_PRODUCT,promotionRedisKey.getNewProductKey());tableMapKey.put(SMS_HOME_RECOMMEND_PRODUCT,promotionRedisKey.getRecProductKey());connector.connect();if("server".equals(subscribe))connector.subscribe(null);elseconnector.subscribe(subscribe);connector.rollback();}@Async@Scheduled(initialDelayString="${canal.promotion.initialDelay:5000}",fixedDelayString = "${canal.promotion.fixedDelay:5000}")@Overridepublic void processData() {try {if(!connector.checkValid()){log.warn("与Canal服务器的连接失效!!!重连,下个周期再检查数据变更");this.connect();}else{Message message = connector.getWithoutAck(batchSize);long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {log.info("本次[{}]没有检测到促销数据更新。",batchId);}else{log.info("本次[{}]促销数据本次共有[{}]次更新需要处理",batchId,size);/*一个表在一次周期内可能会被修改多次,而对Redis缓存的处理只需要处理一次即可*/Set<String> factKeys = new HashSet<>();for(CanalEntry.Entry entry : message.getEntries()){if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN|| entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {continue;}CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());String tableName = entry.getHeader().getTableName();if(log.isDebugEnabled()){CanalEntry.EventType eventType = rowChange.getEventType();log.debug("数据变更详情:来自binglog[{}.{}],数据源{}.{},变更类型{}",entry.getHeader().getLogfileName(),entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(),tableName,eventType);}factKeys.add(tableMapKey.get(tableName));}for(String key : factKeys){/*此处未做删除缓存失败的补偿操作,可以自行加入*/if(StringUtils.isNotEmpty(key)) redisOpsExtUtil.delete(key);}connector.ack(batchId); // 提交确认log.info("本次[{}]处理促销Canal同步数据完成",batchId);}}} catch (Exception e) {log.error("处理促销Canal同步数据失效,请检查:",e);}}
}2、跨系统的数据同步
在大型互联网企业中、其核心业务数据,以不同的数据结构和存储方式,保存几十甚至上百份,都是非常正常的。
那么如何才能做到让这么多份数据实时地保持同步呢?分布式事务解决不了大规模数据的实时同步问题。
Canal同样可以应用到这个场景。但是并不能直接将Canal出来的 Binlog 数据肯定不能直接写入下游的众多数据库中。原因也很明显:一是写不过来;二是下游的每个数据库,在写入之前可能还要处理一些数据转换和过滤的工作。一般会增加一个消息队列来解耦上下游。
更换数据库
业务场景:
- 单库单表升级成多库多表
- 系统从传统部署方式向云上迁移的时候,也需要从自建的数据库迁移到云数据库上
- 在线分析类的系统,需要使用专门的分析类数据库,比如HBase
设计迁移方案的时候,一定要保证每一步都是可逆的。也就是必须保证,每执行完一个步骤, 一旦出现任何问题,都能快速回滚到上一个步骤。
更换数据库,已订单表为例,更换步骤:
1. 数据同步到新库
- 历史数据同步:提供数据同步任务,同步某个时间点之前的历史数据
- 实时数据同步:提供实时同步任务,利用Binlog实现两个异构数据库之间数据的实时同步。
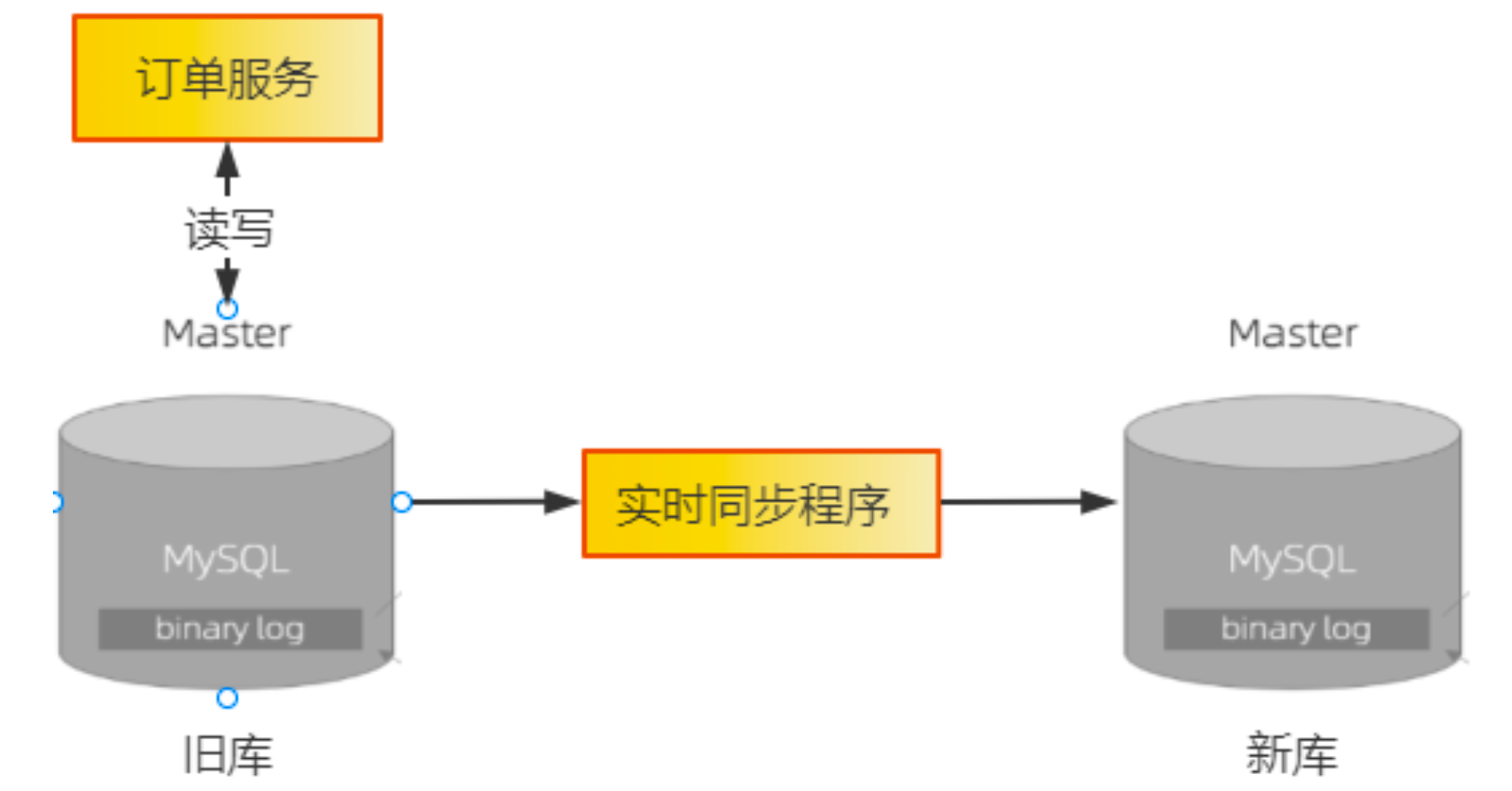
2. 订单服务升级
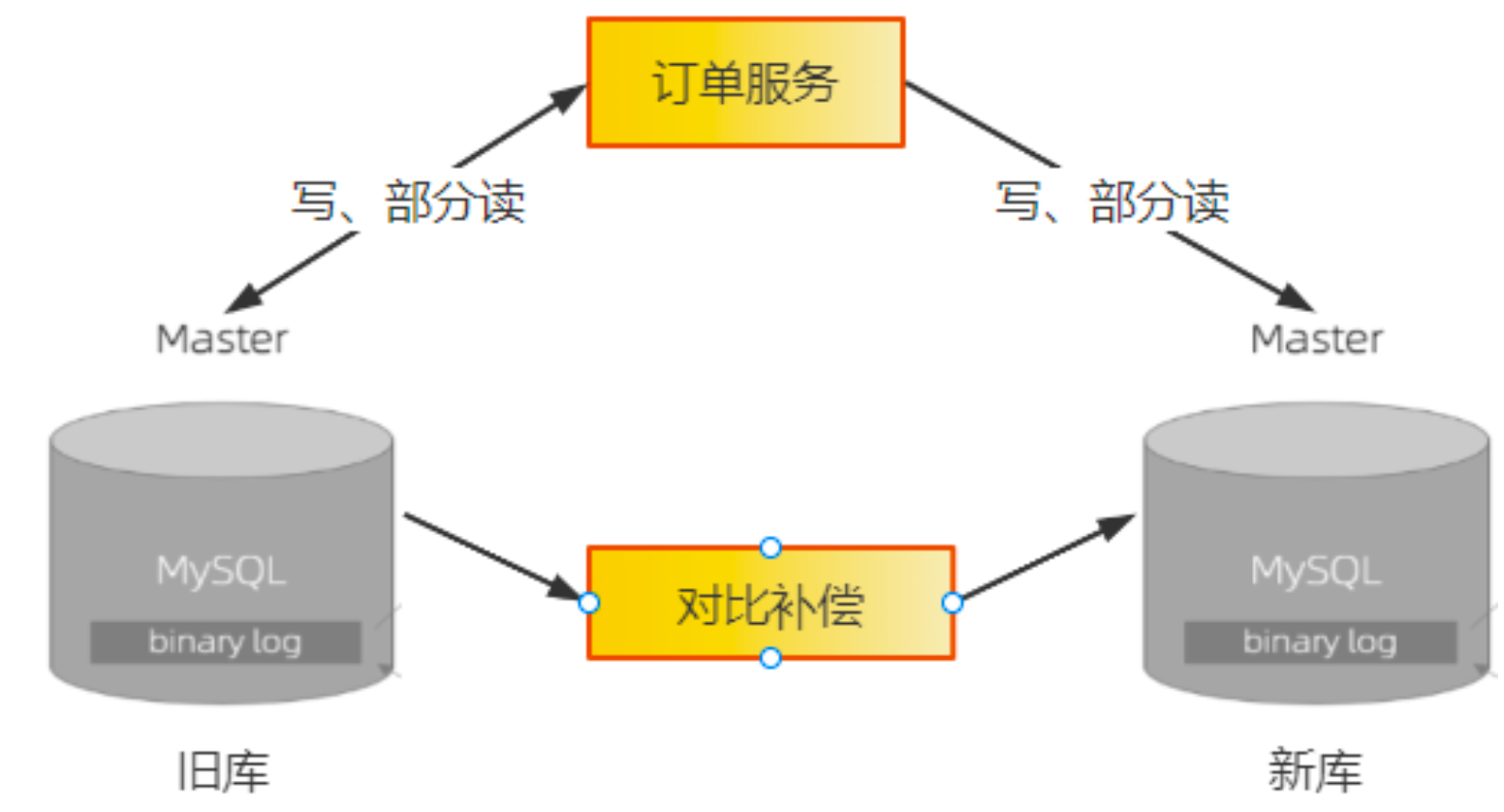
1)写:支持双写新旧两个库,并且预留热切换开关,能通过开关控制三种写状态:只写旧库、只写新库和同步双写。
2)读:支持读取新旧两个库,同样预留热切换开关,控制读取旧库还是新库。
3. 上线新版的订单服务
仍旧读写旧库一段时间,验证新版订单服务的稳定性,验证新库与旧库数据一致性。
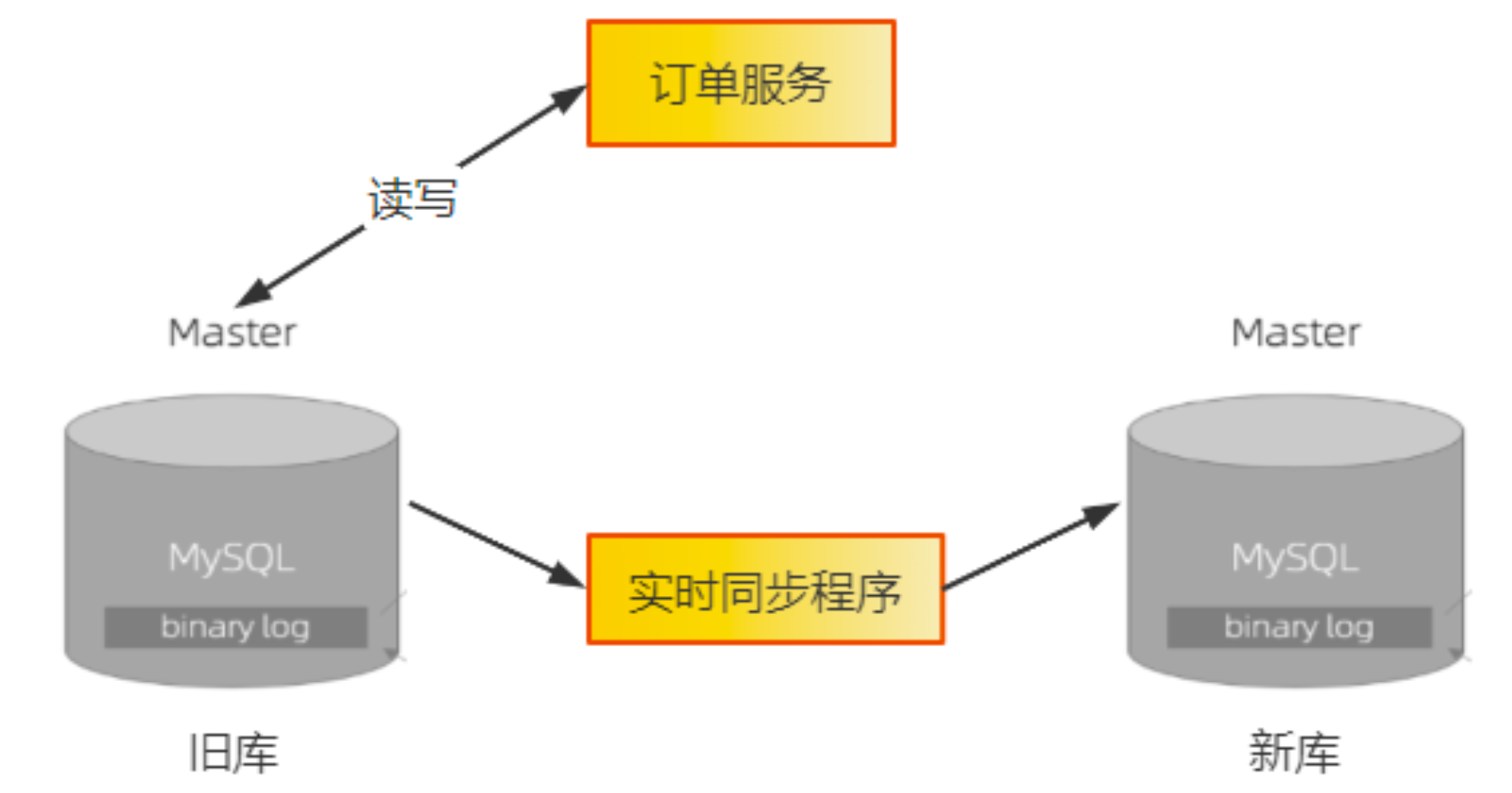
4. 开启双写开关
同时要停掉实时同步程序。双写是先写旧库再写新库:
- 如果旧库成功、新库失败,业务返回成功并记录日志;
- 如果旧库失败,直接返回失败。
出现任何形式的失败,都应该回滚到值写旧库开关。
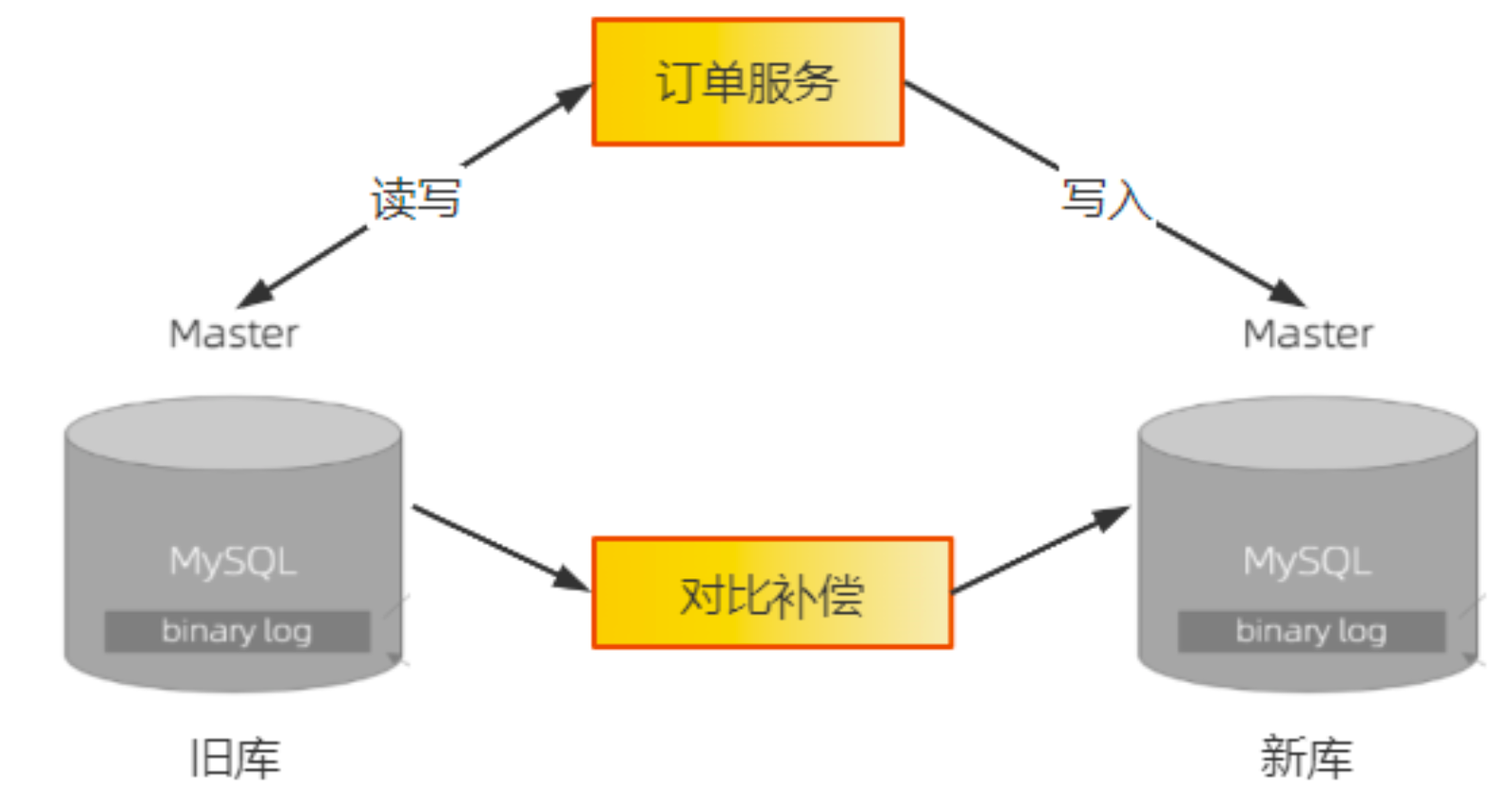
双写开关需要运行一段时间,这段时间需要不断验证 新库数据与旧库数据一致性。
一致性的验证需要提供个数据对比服务,用于比对旧库最近的数据变更,然后检查新库中的数据是否一致,如果不一致,则需要进行补偿。
5. 双读:类似灰度发布的方式把读请求逐步切换到新库上
运行一段时间,中间出现问题即使回滚到只读旧库开关
6. 读请求全部切换到新库
至此,读写请求全部都到新库了。稳定一段时间后,就可以停掉 数据对比服务,写开关也切换到只写新库(不可逆),旧库服务下线。
如果要实现 写开关切换到只写新库 这一步也可逆,把实时同步服务 和 数据对比服务,反过来再执行一段时间,保证这段时间旧库中也是完成的数据。做到一旦出现问题,就直接切回到旧库上。
数据比对服务
业务系统运行的期间,数据在不断变化,可以选择比当前时间早一点的时间,一段时间内的数据做比对。
订单这种时效性比较强的表,比对和补偿程序就可以根据订单完成时间,每次只比对这个时间窗口内完成的订单。