数据处理--生成Excel文档
一、实现路径总览
- 安装必要库 → 2. 准备 / 处理数据(列表、字典、DataFrame 等) → 3. 创建 Excel 文件(基础写入) → 4. 高级格式化(可选,如单元格样式、合并单元格、公式等) → 5. 保存文件
二、详细步骤与代码示例
1. 安装必要库
pandas:核心数据处理库,提供简洁的 Excel 操作接口openpyxl:用于写入.xlsx格式文件的引擎(支持 Excel 2007+)xlsxwriter:可选引擎,支持更多高级功能(如图表、条件格式)
2. 数据准备与处理
假设我们有一组处理后的结构化数据(例如:学生成绩、销售数据等),可以是列表、字典或 pandas 的 DataFrame(推荐,最便捷)。
import pandas as pd# 方法1:从字典创建DataFrame(最常用)
data = {"姓名": ["张三", "李四", "王五", "赵六"],"语文": [88, 92, 78, 95],"数学": [95, 89, 92, 85],"英语": [90, 85, 88, 92]
}
df = pd.DataFrame(data)# 数据处理:计算平均分(新增一列)
df["平均分"] = df[["语文", "数学", "英语"]].mean(axis=1).round(1) # 保留1位小数print("处理后的数据:")
print(df)运行结果:
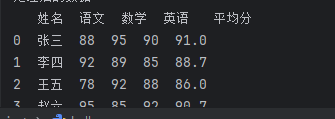
该代码可以进阶为更方便维护的具体代码:
import pandas as pd
import logging
from typing import Dict, List, Optional# 配置日志系统
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s'
)def create_score_dataframe(data: Dict[str, List]) -> Optional[pd.DataFrame]:"""从字典数据创建成绩DataFrame并进行基本验证参数:data: 包含学生信息和成绩的字典返回:验证通过的DataFrame,若验证失败则返回None"""try:# 创建DataFramedf = pd.DataFrame(data)# 基本数据验证required_columns = ['姓名']score_columns = [col for col in df.columns if col not in required_columns]if not score_columns:logging.error("数据中未包含成绩列")return None# 检查成绩是否为数值类型for col in score_columns:if not pd.api.types.is_numeric_dtype(df[col]):logging.error(f"成绩列 '{col}' 包含非数值数据,请检查")return None# 检查是否有缺失值if df.isnull().any().any():logging.warning("数据中存在缺失值,将自动填充为0")df[score_columns] = df[score_columns].fillna(0)logging.info(f"成功创建成绩数据框 | 学生数量: {len(df)} | 科目: {', '.join(score_columns)}")return dfexcept Exception as e:logging.error(f"创建数据框时出错: {str(e)}", exc_info=True)return Nonedef calculate_average_score(df: pd.DataFrame,score_columns: Optional[List[str]] = None,round_decimals: int = 1) -> pd.DataFrame:"""计算学生平均分并添加到DataFrame中参数:df: 包含成绩数据的DataFramescore_columns: 用于计算平均分的科目列,若为None则自动检测round_decimals: 保留的小数位数返回:添加了平均分列的DataFrame"""try:# 确定用于计算平均分的列if not score_columns:score_columns = [col for col in df.columns if col != '姓名']logging.info(f"自动检测到成绩列: {', '.join(score_columns)}")# 计算平均分df['平均分'] = df[score_columns].mean(axis=1).round(round_decimals)logging.info(f"成功计算平均分 | 保留 {round_decimals} 位小数")return dfexcept KeyError as e:logging.error(f"计算平均分时出错: 缺少列 {str(e)}")raiseexcept Exception as e:logging.error(f"计算平均分时出错: {str(e)}", exc_info=True)raisedef display_dataframe(df: pd.DataFrame, title: str = "数据预览") -> None:"""展示DataFrame内容"""print(f"\n{title}:")print(df.to_string(index=False)) # 不显示索引列def main():"""主函数:处理学生成绩数据"""# 学生成绩数据(可根据实际情况修改或从外部加载)score_data = {"姓名": ["张三", "李四", "王五", "赵六"],"语文": [88, 92, 78, 95],"数学": [95, 89, 92, 85],"英语": [90, 85, 88, 92]}# 创建并验证数据框df = create_score_dataframe(score_data)if df is None:logging.error("数据处理失败,退出程序")return# 计算平均分df = calculate_average_score(df=df,# 可指定科目列,如: score_columns=["语文", "数学"],round_decimals=1)# 展示结果display_dataframe(df, title="处理后的学生成绩数据")# 可选:保存结果到文件# output_path = "student_scores.csv"# df.to_csv(output_path, index=False, encoding="utf-8")# logging.info(f"成绩数据已保存至: {output_path}")if __name__ == "__main__":main()
代码:
import pandas as pd# 方法1:从字典创建DataFrame(最常用)
data = {"姓名": ["张三", "李四", "王五", "赵六"],"语文": [88, 92, 78, 95],"数学": [95, 89, 92, 85],"英语": [90, 85, 88, 92]
}
df = pd.DataFrame(data)# 数据处理:计算平均分(新增一列)
df["平均分"] = df[["语文", "数学", "英语"]].mean(axis=1).round(1) # 保留1位小数print("处理后的数据:")
print(df)# 基础写入:生成Excel文件
output_path = "学生成绩表基础版.xlsx"# index=False:不保留DataFrame的行索引
df.to_excel(output_path, sheet_name="成绩表", index=False, engine="openpyxl")print(f"基础版Excel已生成:{output_path}")运行结果:
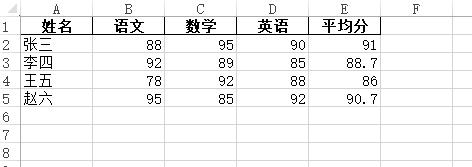
其中:
sheet_name:指定工作表名称(默认为 “Sheet1”)index=False:避免将 DataFrame 的行号写入 Excel- 生成的文件可直接用 Excel 打开,包含所有数据列(在执行文件所在的pychace里面)
3. 进阶:生成带格式的 Excel 文件
如果需要美化 Excel(如标题样式、单元格颜色、列宽调整等),可结合openpyxl或xlsxwriter进行高级格式化。
import pandas as pd
from openpyxl import load_workbook
from openpyxl.styles import Font, Alignment, PatternFill, Border, Side
from openpyxl.utils import get_column_letter # 用于安全获取列字母
import osdef create_formatted_score_excel(df, output_path="学生成绩表进阶版.xlsx"):try:# 确保输出目录存在output_dir = os.path.dirname(output_path)if output_dir and not os.path.exists(output_dir):os.makedirs(output_dir)# 1. 写入基础数据df.to_excel(output_path, sheet_name="成绩表", index=False, startrow=1, engine="openpyxl")# 2. 加载Excel文件准备格式化wb = load_workbook(output_path)ws = wb["成绩表"]# 3. 设置标题行title = "2023年秋季学期学生成绩表"max_col_letter = chr(65 + len(df.columns) - 1) # 自动计算最后一列字母ws.merge_cells(range_string=f"A1:{max_col_letter}1")ws["A1"].value = titlews["A1"].font = Font(name="微软雅黑", size=14, bold=True, color="FFFFFF")ws["A1"].alignment = Alignment(horizontal="center", vertical="center")ws["A1"].fill = PatternFill(fgColor="4F81BD", fill_type="solid")# 4. 设置表头样式(第2行)header_font = Font(name="微软雅黑", size=11, bold=True)header_fill = PatternFill(fgColor="C0C0C0", fill_type="solid")for cell in ws[2]: # 第2行是表头,无合并单元格cell.font = header_fontcell.fill = header_fillcell.alignment = Alignment(horizontal="center")# 5. 调整列宽(修复核心:用列索引获取字母,而非合并单元格)column_widths = {"姓名": 10,"语文": 8,"数学": 8,"英语": 8,"平均分": 10}# 遍历表头所在的第2行,获取列名和对应列索引(避免合并单元格)for col_idx, cell in enumerate(ws[2], 1): # col_idx从1开始(Excel列索引从1开始)col_name = cell.valuecol_letter = get_column_letter(col_idx) # 用索引安全获取列字母if col_name in column_widths:ws.column_dimensions[col_letter].width = column_widths[col_name]else:ws.column_dimensions[col_letter].width = 10# 6. 条件格式green_fill = PatternFill(fgColor="92D050", fill_type="solid")red_fill = PatternFill(fgColor="FF0000", fill_type="solid")avg_col_letter = None# 遍历表头找"平均分"列for col_idx, cell in enumerate(ws[2], 1):if cell.value == "平均分":avg_col_letter = get_column_letter(col_idx)breakif avg_col_letter:for row in range(3, ws.max_row + 1):avg_cell = ws[f"{avg_col_letter}{row}"]try:avg_value = float(avg_cell.value)if avg_value >= 90:avg_cell.fill = green_fillelif avg_value < 60:avg_cell.fill = red_fillexcept (ValueError, TypeError):continue# 7. 添加边框thin_border = Border(left=Side(style='thin'),right=Side(style='thin'),top=Side(style='thin'),bottom=Side(style='thin'))for row in ws.iter_rows(min_row=2, max_row=ws.max_row,min_col=1, max_col=len(df.columns)):for cell in row:cell.border = thin_border# 8. 保存文件wb.save(output_path)print(f"格式化Excel已生成:{os.path.abspath(output_path)}")except Exception as e:print(f"生成Excel时出错:{str(e)}")if __name__ == "__main__":# 准备数据data = {"姓名": ["张三", "李四", "王五", "赵六", "钱七"],"语文": [88, 92, 78, 95, 59],"数学": [95, 89, 92, 85, 76],"英语": [90, 85, 88, 92, 63]}df = pd.DataFrame(data)df["平均分"] = df[["语文", "数学", "英语"]].mean(axis=1).round(1)# 输出路径output_file = "学生成绩表进阶版.xlsx"# output_file = r"C:\Users\你的用户名\Desktop\学生成绩表.xlsx" # 绝对路径create_formatted_score_excel(df, output_file)
运行结果:
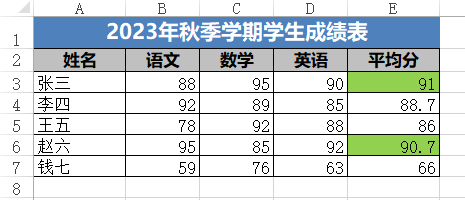
4、总结
- 基础需求:用
pandas.to_excel()快速生成 Excel,适合简单数据导出。 - 格式美化:结合
openpyxl设置单元格样式、合并单元格等,提升可读性。 - 数据可视化:用
xlsxwriter插入图表,实现 Excel 内的数据可视化。 - 灵活性:支持多工作表、大数据处理和已有文件修改,满足各类场景。