一万字讲解Java中的IO流——包含底层原理
目录
IO流简介
基本流
分类
字节流
InputStream(字节输入流)(抽象类)
OutputStream(字节输出流)(抽象类)
文件拷贝
try...catch异常处理
字符流
字符集
乱码问题
Reader(字符输入流)(抽象类)
Writer(字符输出流)(抽象类)
字符流底层原理
高级流
缓冲流
字节缓冲流
字符缓冲流
转换流
序列化流(ObjectOutputStream)
反序列化流(ObjectInputStream)
序列化流以及反序列化流的注意点
打印流
字节打印流(printStream)
字符打印流(printWriter)
解压缩流
压缩流
Commons-io工具包
Hutool工具包
IO流简介
存储和读取数据的解决方案。
作用:用于读写数据,本地文件和网络中都可以。
基本流
分类
按流的方向,分为输入流(把本地文件中的数据读取到程序中)和输出流(把程序中的数据写出到文件中)
按操作文件类型,分为字节流(可以操作所有类型文件)和字符流(纯文本文件)。
注意:excel文件和后缀位.docx的文件都不是纯文本文件;后缀为.md和.txt等是纯文本文件。
字节流
InputStream(字节输入流)(抽象类)
FileInputStream
操作本地文件的字节输入流,可以把本地文件中的数据读取到程序中
步骤:
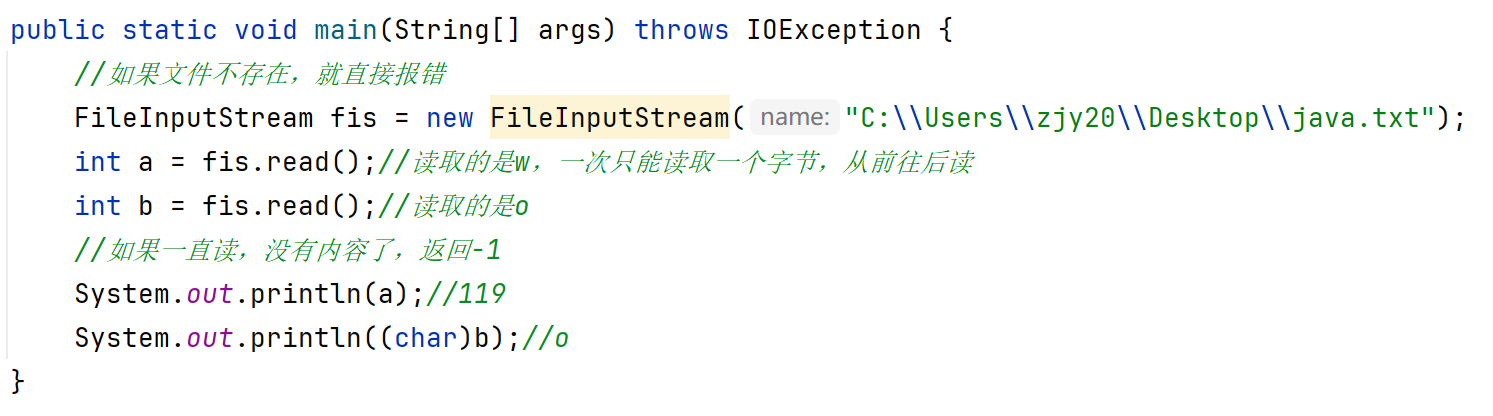
1、创建字节输入流对象。一旦创建程序和本地文件之间会产生一个数据通道。
2、读取数据。
循环读取:
public int read():一次读一个字节数据。
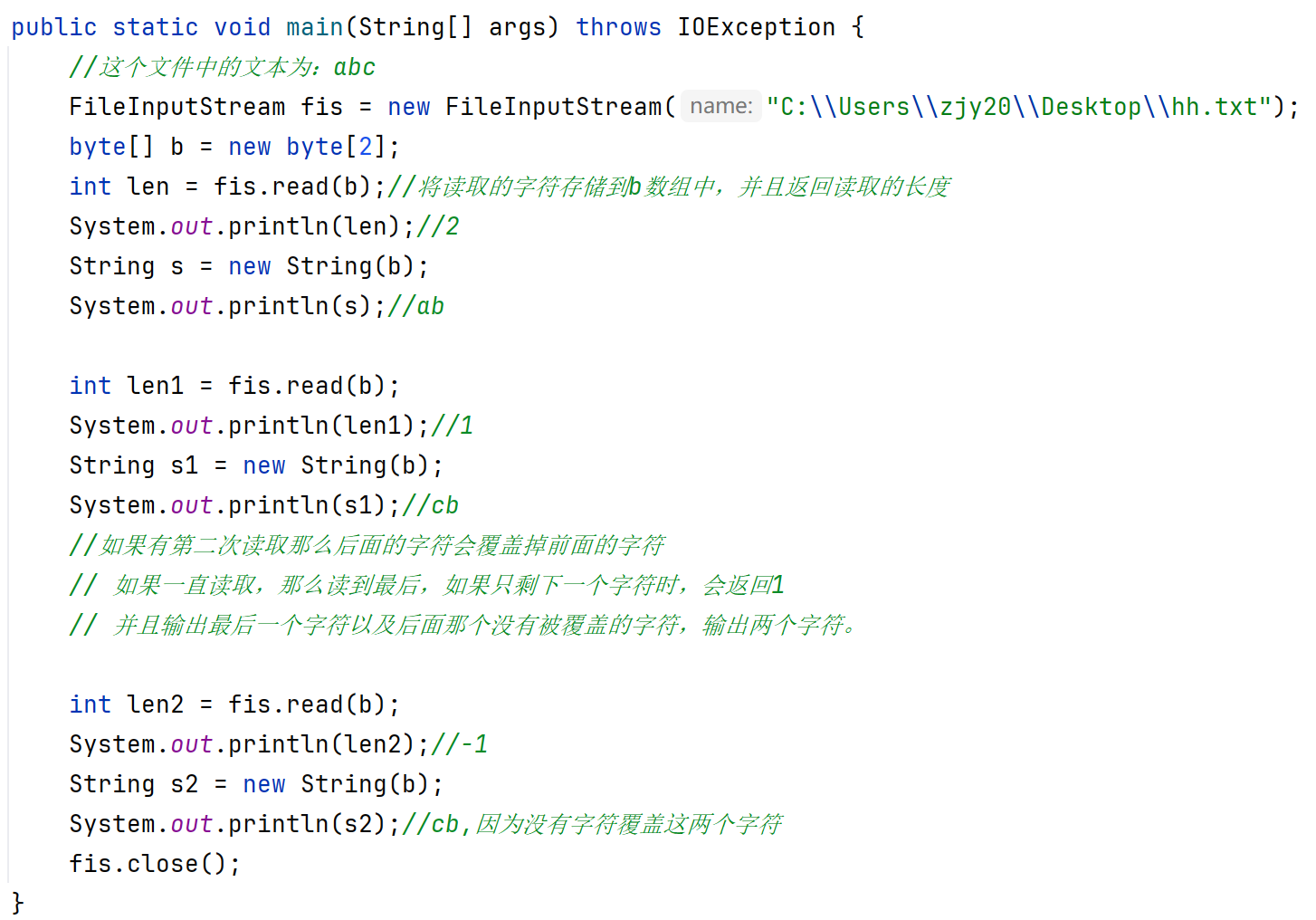
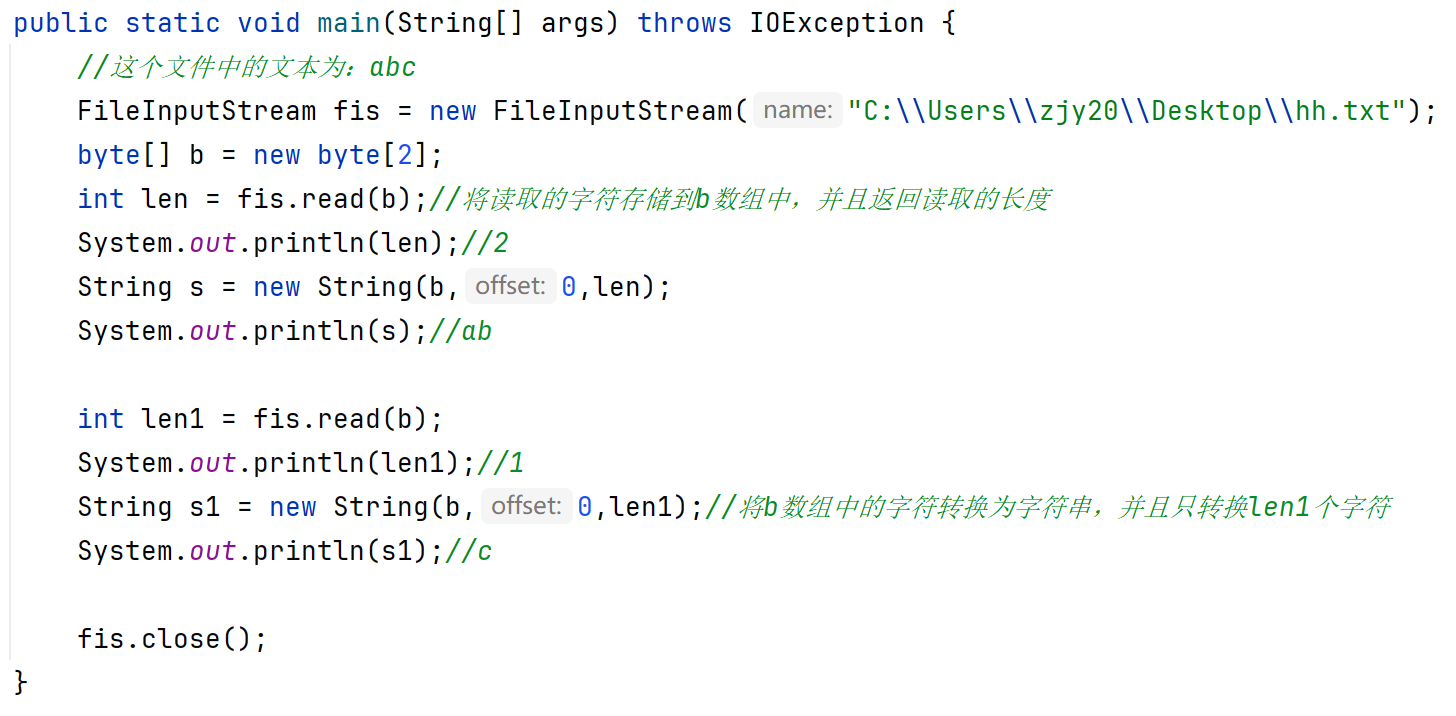
public int read(byte[] buffer):一次读一个字节数组数据。(每次读取会尽可能把数组装满,数组大小一般设置为1024的整数倍)
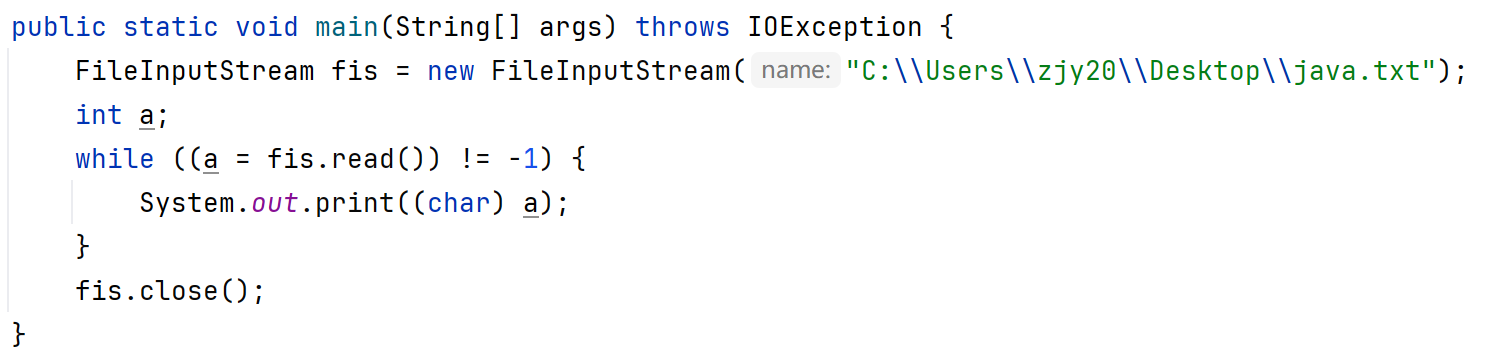
代码改进:
3、释放资源。释放数据通道
OutputStream(字节输出流)(抽象类)
FileOutputStream
操作本地文件的字节输出流,可以把程序中的数据写到本地文件中
如下代码,就会在桌面上创建一个java.txt文本,并且写入'a'字符
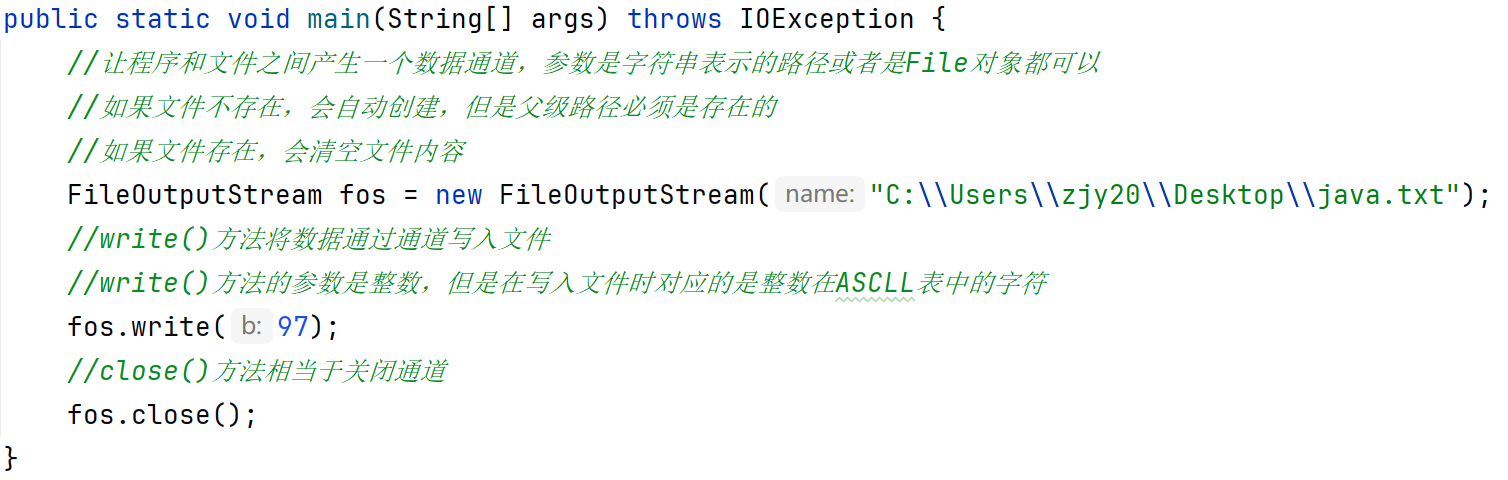
步骤:
1、创建字节输出流对象
2、写数据
void write(int b):一次写一个字节的数据
void write(byte[] b):一次写一个字节数组的数据
void write(byte[] b,int off,int len):一次写一个字节数组的部分数据(参数二:起始索引,参数三:个数)
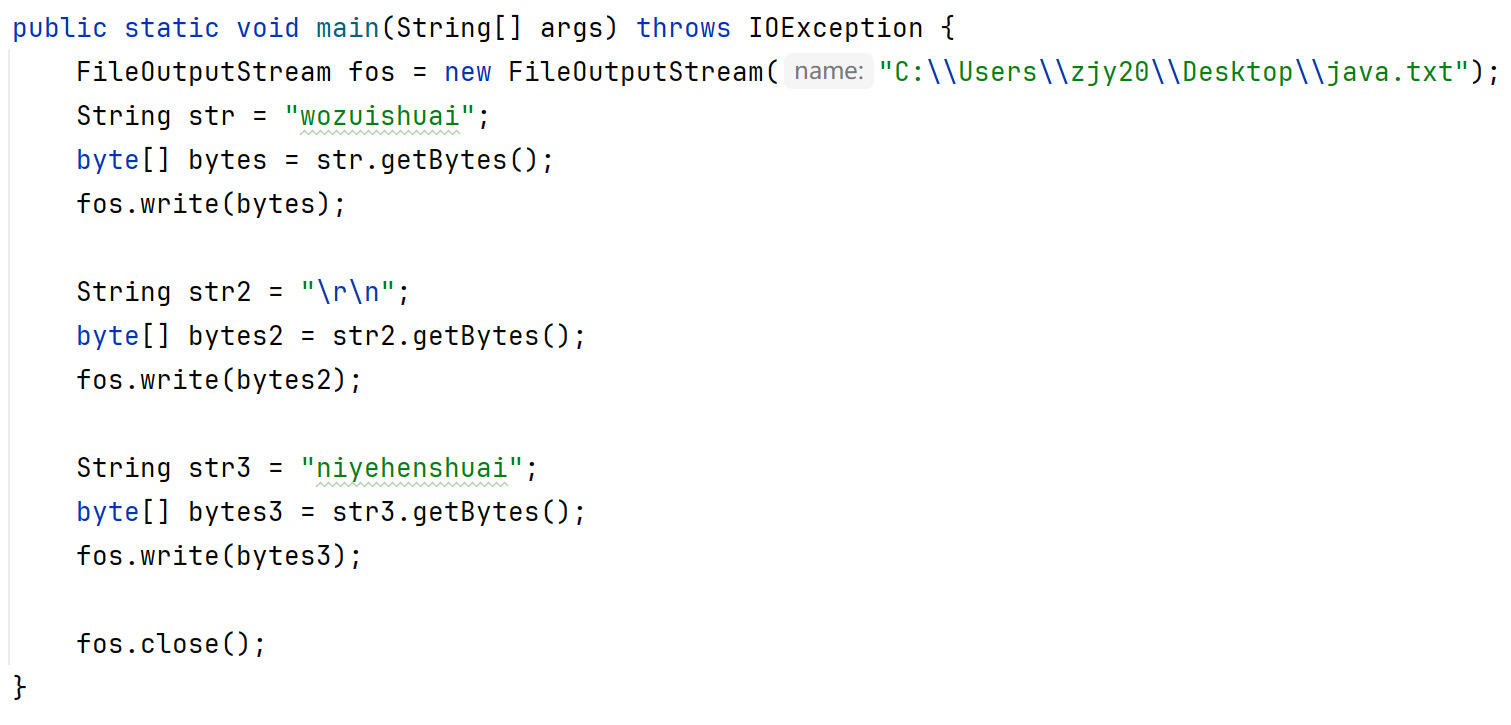
换行写
再写出一个换行符就行了
windows:\r\n Linux:\n Mac:\r
注意:window操作系统中,java对其做了优化,只写\r或者只写\n都是可以的。
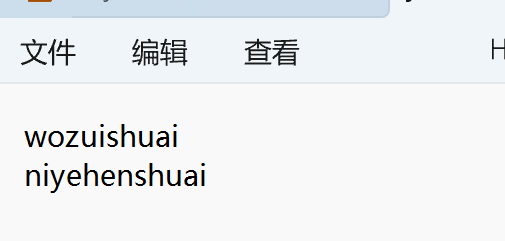
执行完毕,文件变成:
续写
FileOutputStream fos = new FileOutputStream("C:\\Users\\zjy20\\Desktop\\java.txt", true);
第二个参数是续写开关,默认为false,只用手动设置为true就不会清空文件了,就会接着文件的内容写。
3、释放资源
文件拷贝
小文件:
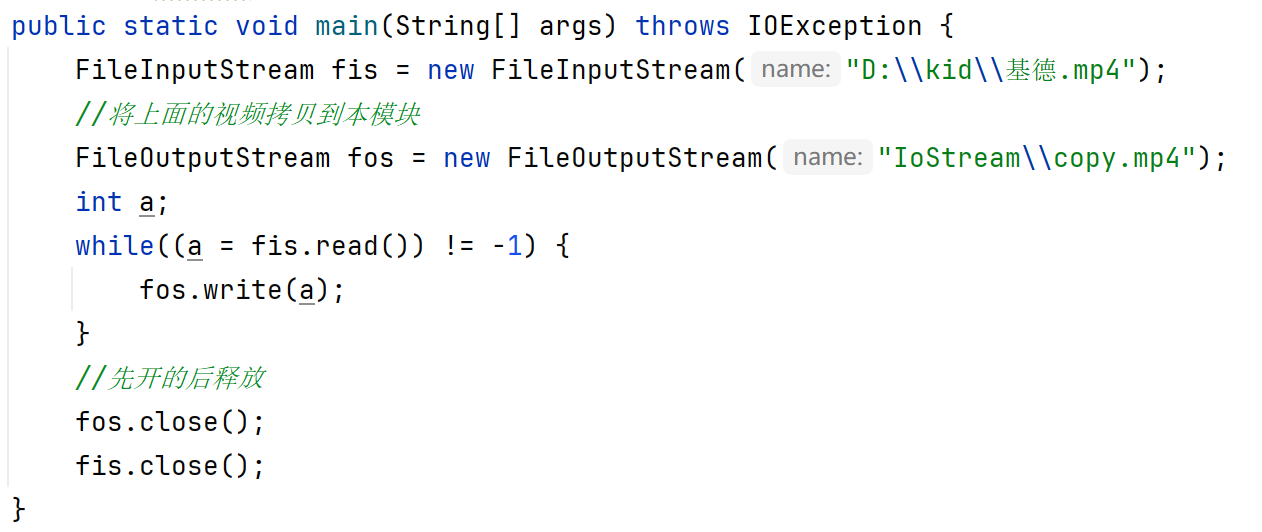
大文件:
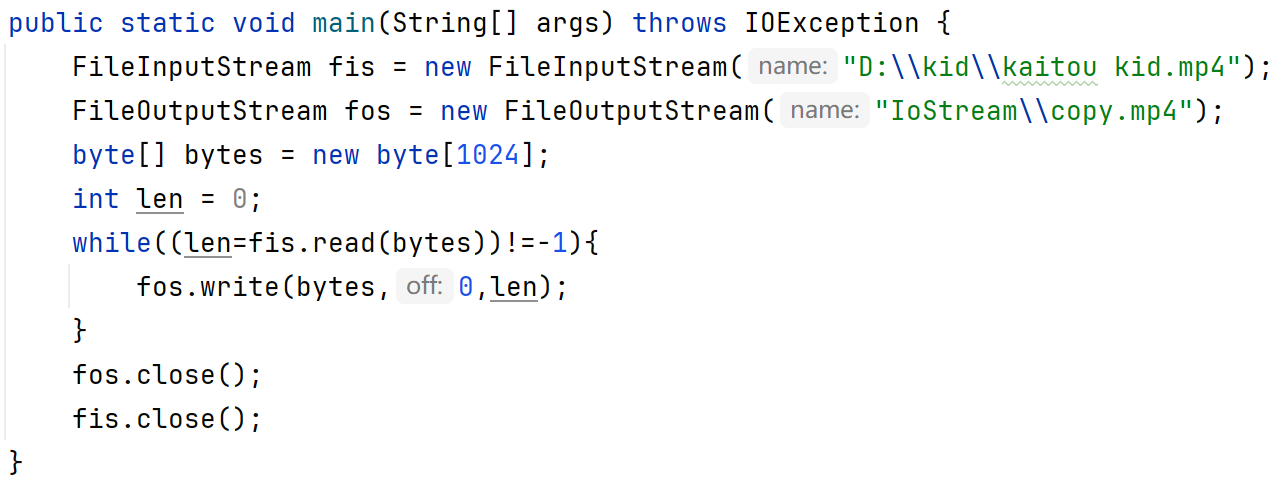
try...catch异常处理
finally里面的代码一定被执行,除非虚拟机停止
注意:异常在实际开发中一般都是抛出处理的,因为Spring框架的底层会把我们抛出的异常统一处理。
用try...catch...finally完整格式:(了解)(手动释放资源)
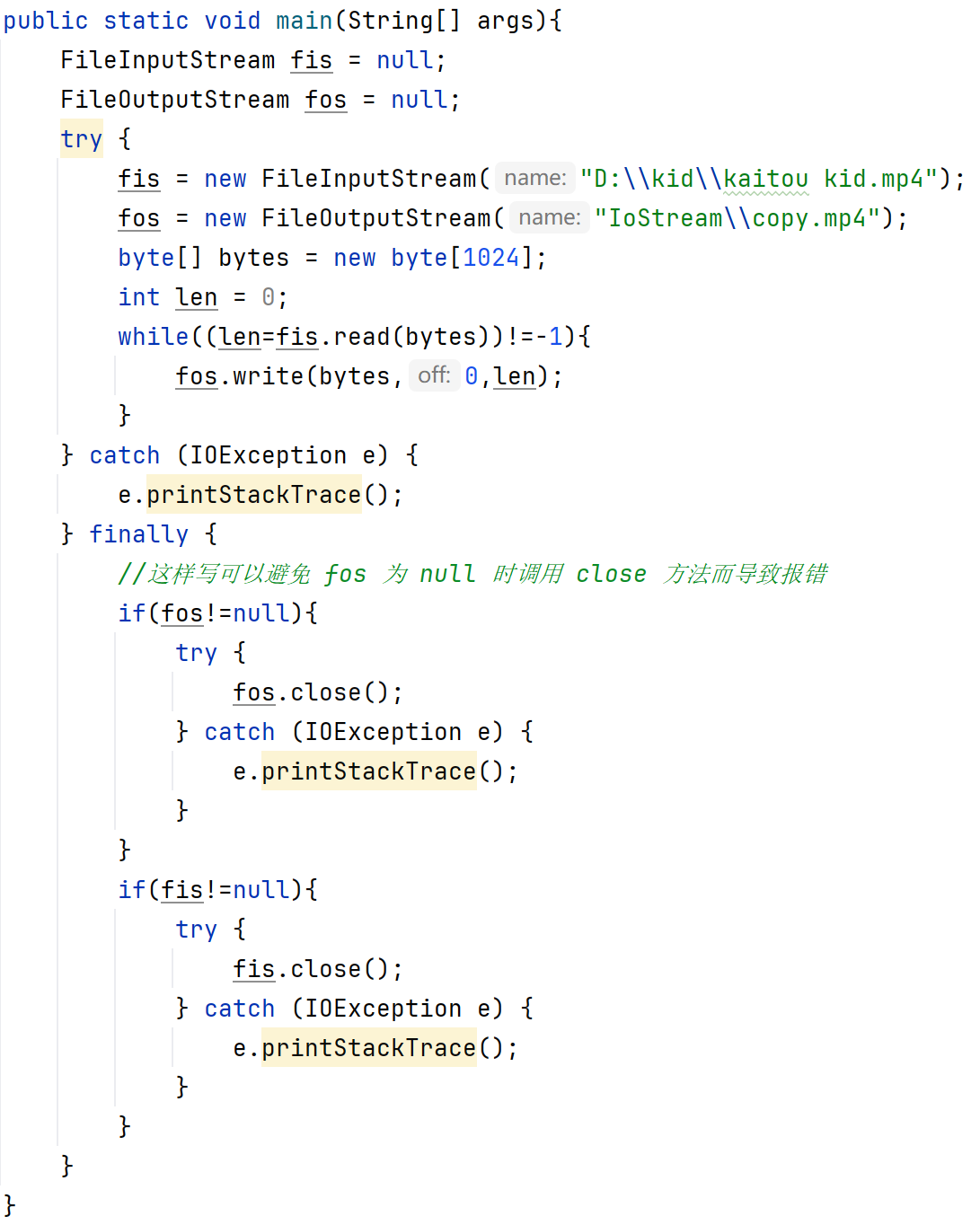
JDK9自动释放资源格式:(了解)
创建流对象1;创建流对象2;
try(流1;流2){可能出现异常的代码;}catch(异常类名 变量名){...}
资源用完自动释放
注意:流1、流2的类需要实现了AutoCloseable接口的类,才能在try括号里写。
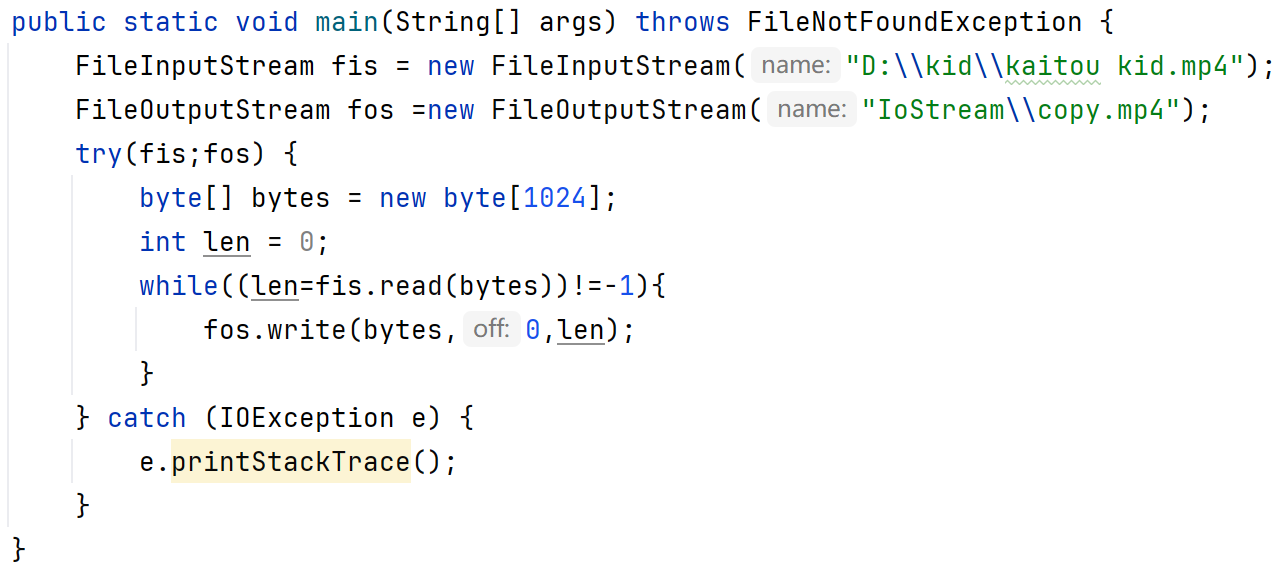
以上的文件中读取的全是英文,因为字节流读取中文会出现乱码。
字符流
字符集
1、GB2312字符集:1980年发布,1981年5月1日实施的简体中文汉字编码国家标准。
收录7445个图形字符,其中包括6763个简体汉字
2、BIG5字符集:台湾地区繁体中文标准字符集,共收录13053个中文字,1984年实施。
3、GBK字符集:2000年3月17日发布,收录21003个汉字。包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。(windows系统默认使用的就是GBK。系统显示:ANSI)
要存储英文a:查询GBK对应的数字是97,转成二进制,GBK编码规则是不足八位前面补0(完全兼容ASCLL)
要存储中文”汉“:查询GBK对应的数字是47802,转成二进制,汉字由两个字节存储,高位字节二进制一定以1开头,编码规则是什么都不变,转成十进制后是一个负数。
这样规定为了区分中文和英文:
GBK中,一个英文字母一个字节,二进制第一位是0;
一个中文汉字两个字节,二进制第一位是1。
4、Unicode字符集:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
UTF-8编码规则是用1~4个字节保存。(这里主要知道ASCLL表是1个字节,简体中文3个字节)
一个字节:直接在前面补0.
三个字节:第一个字节前补1110,第二个字节前补10,第三个字节前也补10
要存储英文a:查询UTF-8对应的数字是97,转成二进制,UTF-8编码:前面补0,后面按照97的二进制进行填补就可以了(完全兼容ASCLL)
要存储中文”汉“:查询UTF-8对应的数字是27721,转成二进制,按照UTF-8编码三个字节的规则,剩下的空位根据”汉“的二进制进行填补就可以了。
乱码问题
原因:
1、读取数据时未读完整个汉字。
字节流:一次只读一个字节,而汉字占三个字节,所以出现了乱码。
2、编码和解码时的方式不一样。
如果用UTF-8编码(汉字占三个字节),用GBK解码(汉字占两个字节),也会出现乱码。
解决方法:
1、不使用字节流读取文本文件。
2、编码解码时使用同一个码表,同一个编码方式。
编码:把我们要存储的数据变成能真正的能存储在硬盘的字节数据。
public byte[] getBytes():使用默认方式进行编码
public bytel] getBytes(String charsetName):使用指定方式进行编码
默认UTF-8编码,如果想用GBK,那么getByte("GBK");就可以了
解码:把字节数据变成我们想要查看的内容。
new String(byte[) bytes):使用默认方式进行解码
new String(byte[] bytes, String charsetName):使用指定方式进行解码
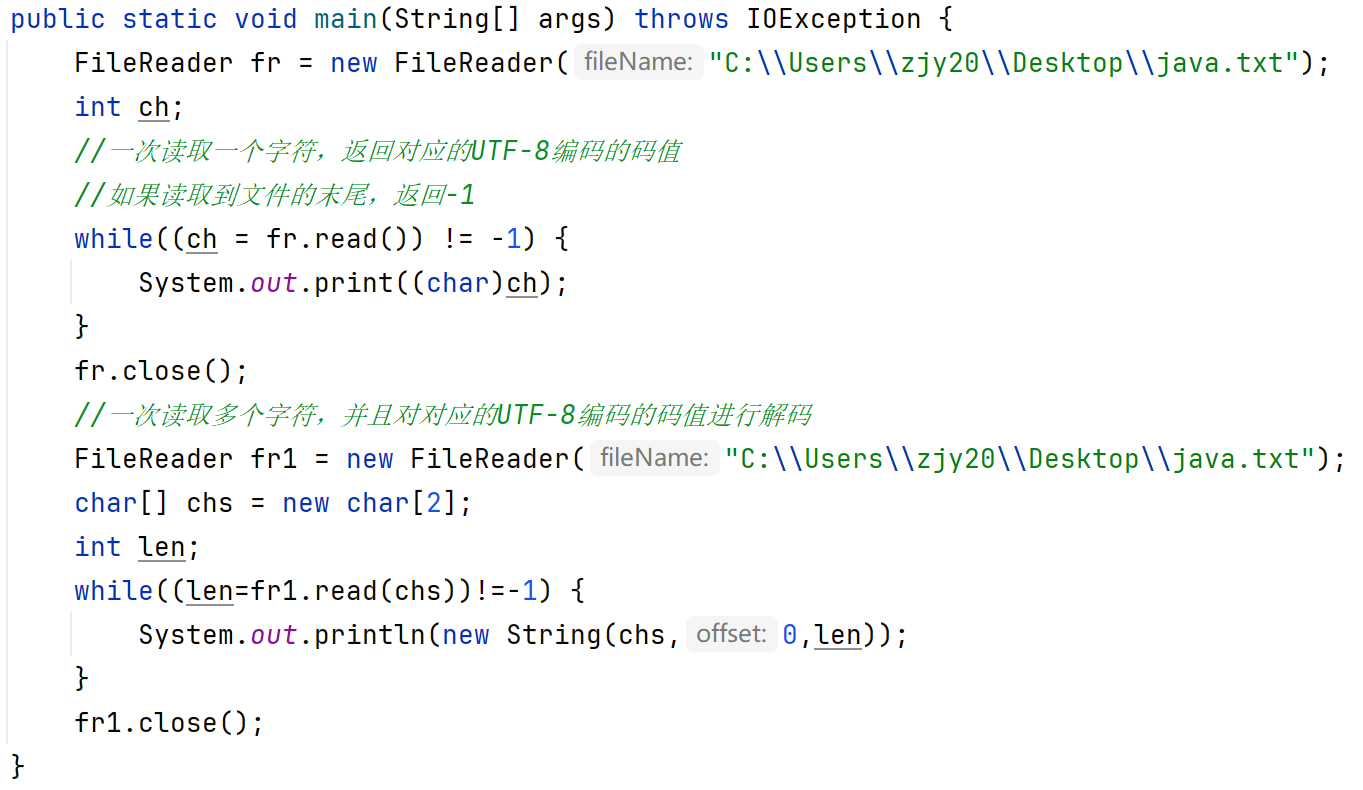
Reader(字符输入流)(抽象类)
输入流:一次读一个字节,遇到中文时,一次都多个字节。
FileReader
操作本地文件的字符输入流
步骤:
1、创建字符输入流对象
如果文件不存在,报错。
public FileReader(File file):创建字符输入流关联本地文件
public FileReader(String pathname):创建字符输入流关联本地文件
2、读取数据
public int read():读取数据,读到末尾返回-1(按字节进行读取,遇到中文,一次读多个字节,读取后解码,返回一个整数)
public int read(char[] buffer):读取多个数据,读到未尾返回-1
3、释放资源
Writer(字符输出流)(抽象类)
输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中。
FileWriter
操作本地文件的字符输出流
步骤:
1、创建字符输出流对象
如果文件不存在会创建一个新的文件,但是要保证父级路径一定存在。
如果文件已经存在,咋会清空文件,如果不想清空,则打开续写开关。
public FileWriter(File file):创建字符输出流关联本地文件
public FileWriter(String pathname):创建字符输出流关联本地文件
public FileWriter(File file, boolean append):创建字符输出流关联本地文件,续写
public Filewriter(String pathname, boolean append):创建字符输出流关联本地文件,续写
2、写数据
void write(int c):写出一个字符
void write(String str):写出一个字符串
void write(String str, int off, int len):写出一个字符串的一部分
void write(char[] cbuf):写出一个字符数组
void write(charl] cbuf, int off, int len):写出字符数组的一部分
3、释放资源
字符流底层原理
创建字符输入流对象
底层:关联文件,并创建缓冲区(长度为8192的字节数组)
读取数据
底层:
1.判断缓冲区中是否有数据可以读取
2.缓冲区没有数据:就从文件中获取数据,装到缓冲区中,每次尽可能装满缓冲区如果文件中也没有数据了,返回-1
3.缓冲区有数据:就从缓冲区中读取。
空参的read方法:一次读取一个字节,遇到中文一次读多个字节,把字节解码并转成十进制返回
有参的read方法:把读取字节,解码,强转三步合并了,强转之后的字符放到数组中。
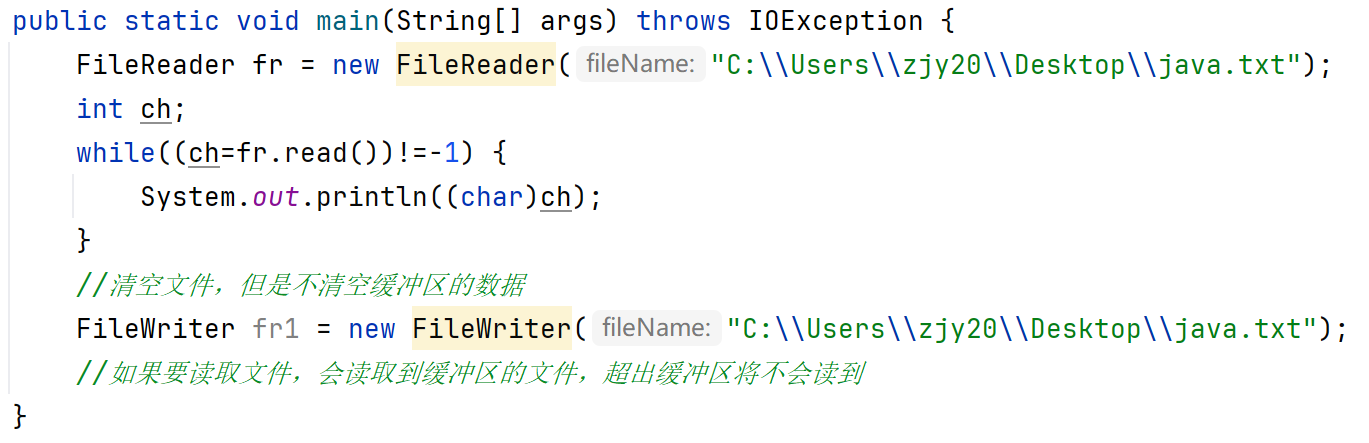
创建字符输出流对象与写数据
也会有一个缓冲区,fr.write()是把数据写到缓冲区。
当缓冲区装满了,自动到本地文件。
使用flush方法刷新,也会保存到本地文件,但是数据通道不会关闭
使用close方法,会保存到本地文件,数据通道也会关闭。
使用场景:
字节流:拷贝任意类型的文件。
字符流:读取纯文本中的数据;往纯文本文件中写出数据。
字节流没有缓冲区,字符流有缓冲区。
高级流
对基本流进行了封装,额外又添加了一些功能。
缓冲流
字节缓冲流
底层自带了长度为8192的缓冲区提高性能。
字节缓冲输入流(BufferedInputStream)
字节缓冲输出流(BufferedOutputStream)
public BufferedInputStream(InputStream is):把基本流包装成高级流,提高读取数据的性能
public BufferedOutputstream(OutputStream os):把基本流包装成高级流,提高写出数据的性能
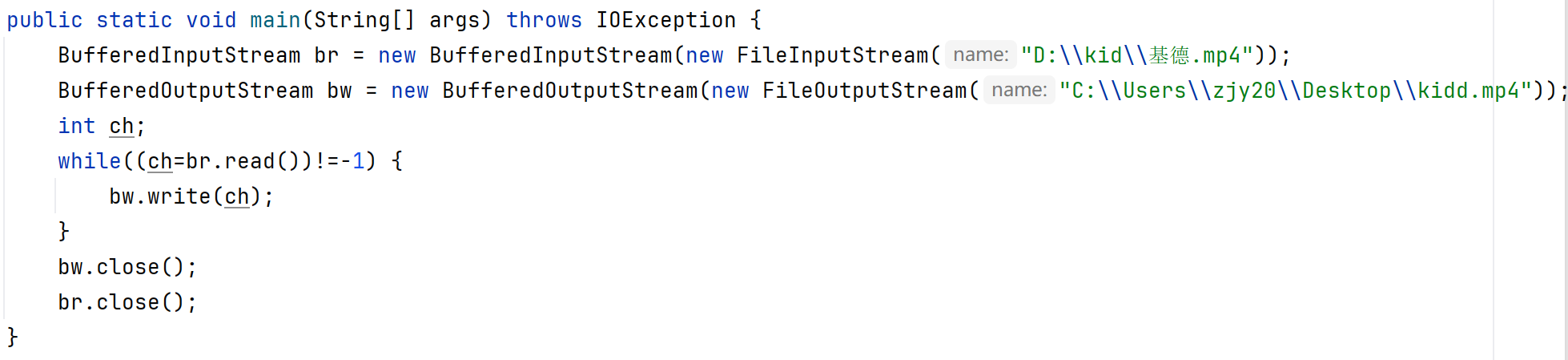
也可以用byte数组一次读取多个字节(和上面基本流的方法一样)
底层原理
在输入流时,会有一个缓冲区;底层原理在输出流时,也会有一个缓冲区;但是这两缓冲区不是共用一个缓冲区,而是两个不同的缓冲区。(两个缓冲区的大小都是8192个字节)
用以上代码来解释,内存中会有输入流的缓冲区,输出流的缓冲区以及自己定义的变量ch这三个空间,read方法读数据时,会把输入流的缓冲区的数据,读到ch这个小空间,再经过write方法把ch中的数据写入输出流的缓冲区中。
字符缓冲流
底层自带了长度为8192的缓冲区提高性能。
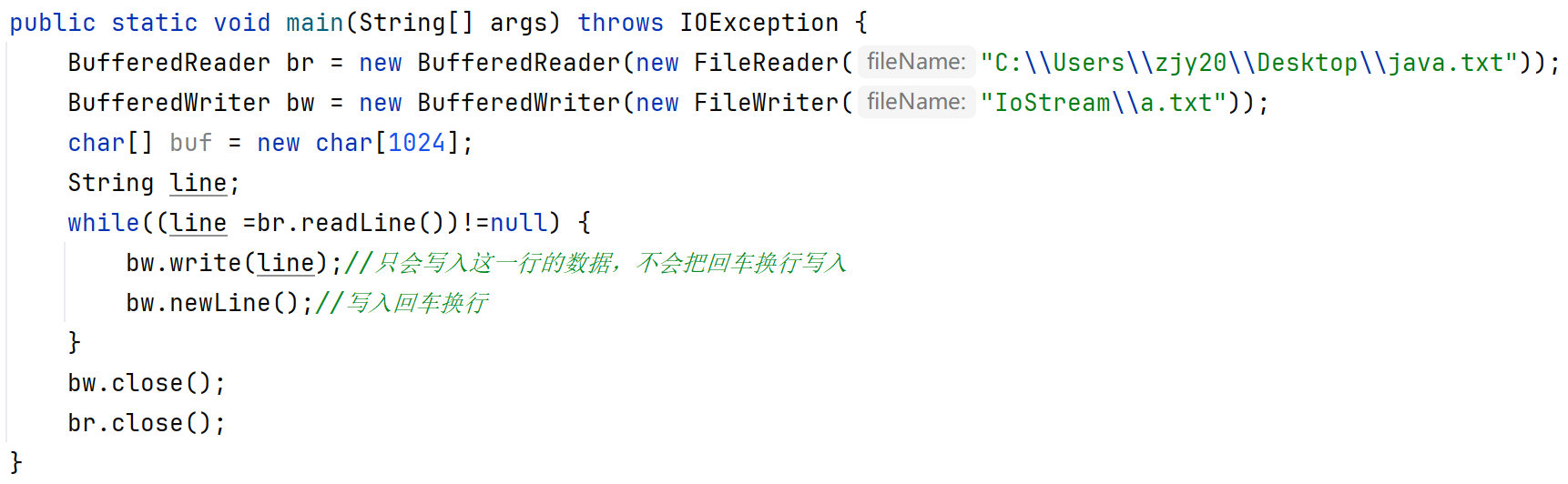
字符缓冲输入流(BufferedReader)
特有方法
public String readLine():速取一行数据,如果没有数据可读了,会返回null(一次读一整行,遇到回车换行结束,但是不会把回车读到内存当中)
字符缓冲输出流(BufferedWriter)
特有方法
public void newLine():跨平台的换行(前面说了Mac、Window、Linux的换行符号都不同,用这个方法,可以解决这个问题)
public BufferedReader (Reader r):把基本流变成高级流
public BufferedWriter(Writer r):把基本流变成高级流
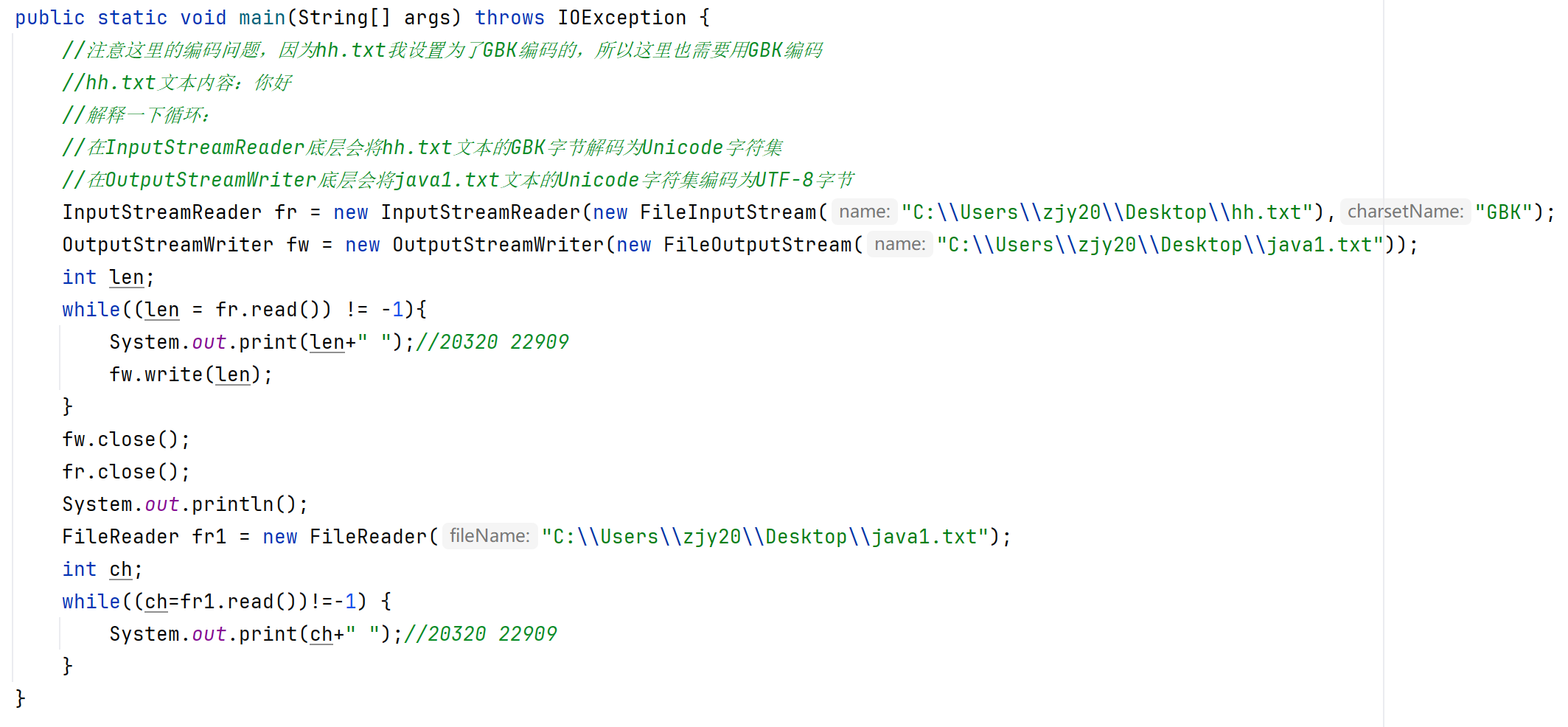
转换流
属于字符流
是字符流和字节流之间的桥梁。
将字节流转换成字符流存入内存中,再把字符流转成字节流写出到本地文件中。
转换输入流(InputStreamReader)
用指定编码方式读取数据的两种方法:
第一种(已经淘汰,了解):InputStreamReader isr = new InputStreamReader(new FileInputStream("路径"),"指定的编码方式(GBK等)")
第二种(掌握):FileReader fr = new FileReader("路径",Charset.forName("指定的编码方式(GBK等)"))
转换输出流(OutputStreamWriter)
用指定编码方式写出数据的两种方法:
第一种(已经淘汰,了解):OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("路径"),"指定的编码方式(GBK等)")
第二种(掌握):FileWriter fw = new FileWriter("路径",Charset.forName("指定的编码方式(GBK等)"))
序列化流(ObjectOutputStream)
属于字节流的一种,负责输出数据。
可以把Java中的对象写到本地文件中,但是我们看不懂,但是我们只需要把数据传到本地文件中就可以,因为反序列化流可以把看不懂的数据转成我们能看懂的样子。
应用场景:当我们要保存的数据,不想让别人看懂,也不想让别人改的时候,就可以用序列化流
public ObjectOutputStream(OutputStream out):把基本流包装成高级流。
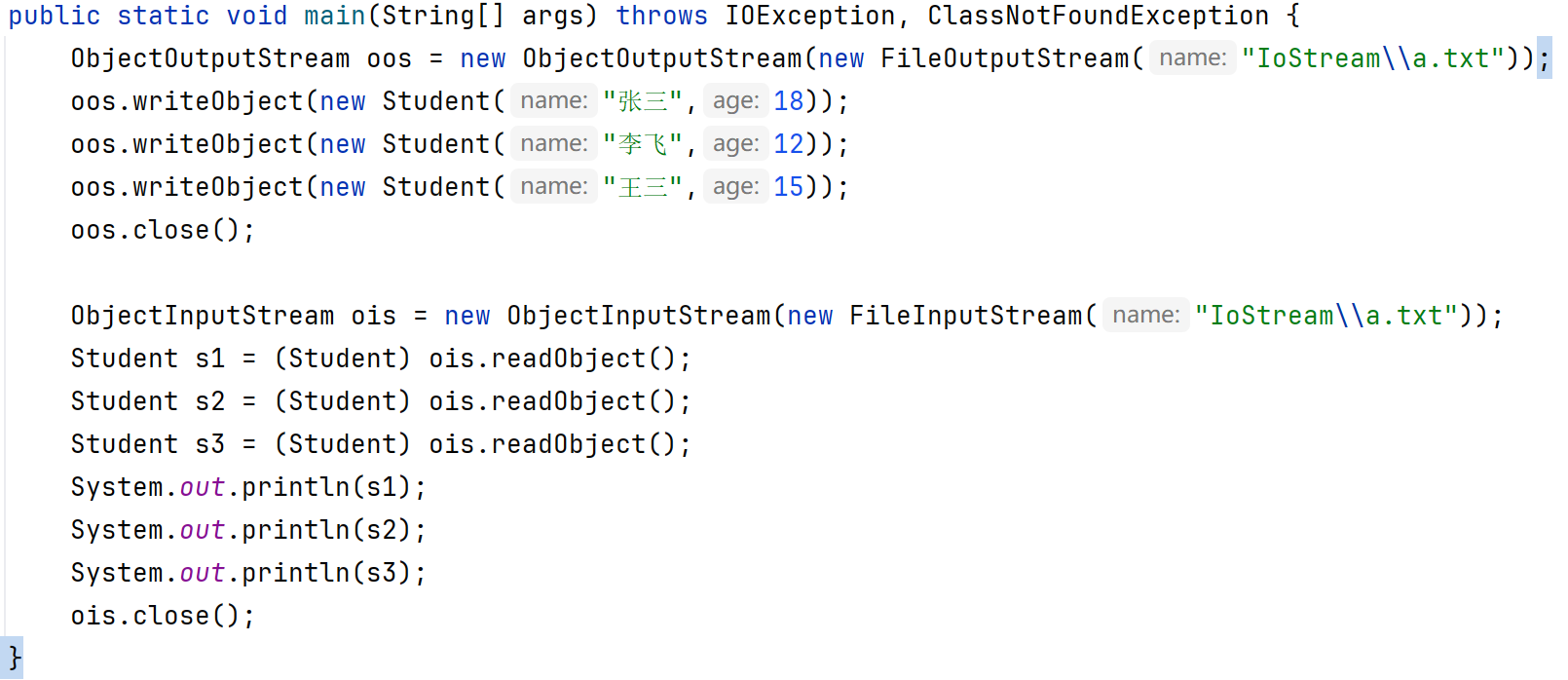
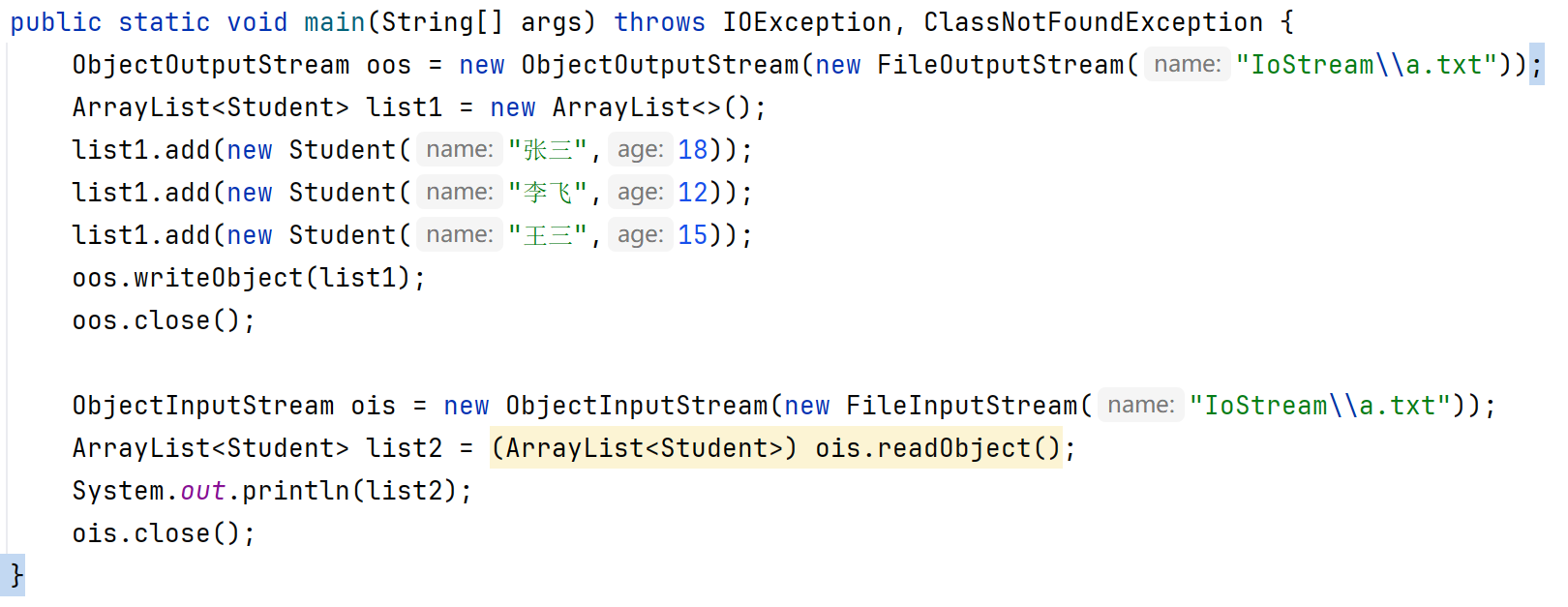
public final void writeObject(Object obj):把对象序列化到文件中去。(一次只能写一个对象)
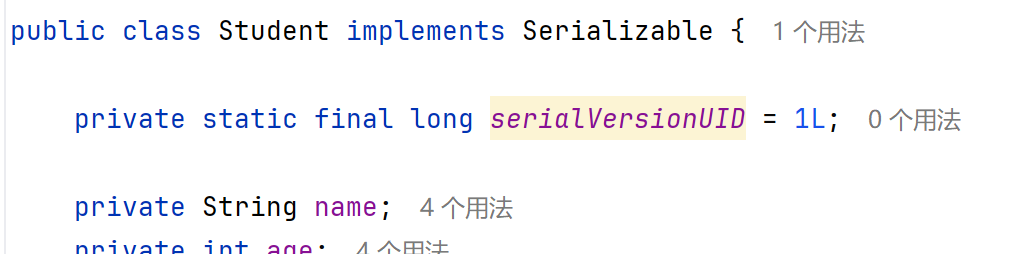
使用对象输出流将对象保存到文件时会出现NotSerializableException异常(解决方法:要让Javabean类实现Serializable接口)
Serializable接口里面没有抽象方法,称作标记型接口。一旦实现了这个接口,那么就表示当前的Student类可以被序列化。

反序列化流(ObjectInputStream)
属于字节流的一种,负责输入数据,与序列化流对应。
可以把序列化到本地文件中的对象,读取到程序中来。
public ObjectInputStream(InputStream out):把基本流变成高级流。
public object readObject():把序列化到本地文件中的对象,读取到程序中来。(一次只能读一个对象,并且如果文件中对象读到没有但是还在使用这个方法时会报错)
序列化流以及反序列化流的注意点
注意一:
一开始Student类有两个私有变量name和age,序列化之后,再反序列化,依旧成功(不会报错)。
但是如果现在在Student类中再加入一个私有变量score,直接继续反序列化,就会报错。
因为Student类实现了Serializable接口,表示可被序列化,则java底层会根据它的静态方法、成员方法、成员变量以及构造方法等的所有内容进行计算,计算出一个long类型的序列号(也可以理解为版本号),当在创建Student对象时,其实对象里面也包含了这个序列号,用序列化流写到本地文件中时,也包含这个序列号。
所以报错的原因是文件中的序列号和Javabean中的序列号不一致所导致的。
解决方式:
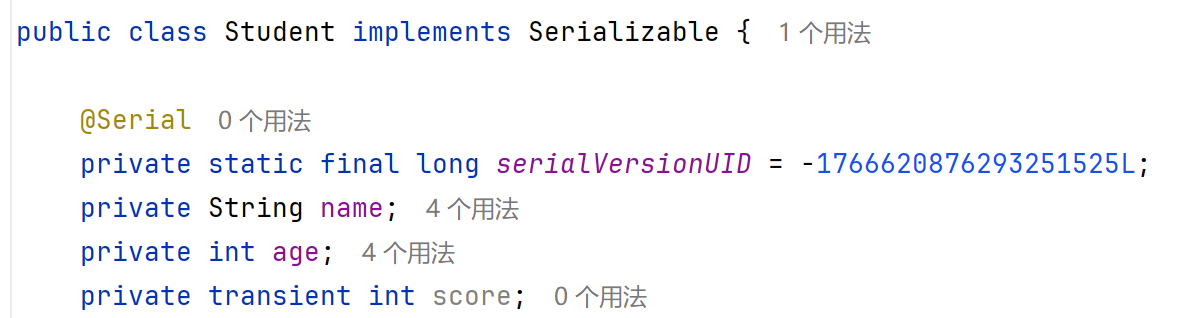
方法一:直接给这个类设置一个固定的版本号。
方法二:
第一步:在设置里面搜索Serializable勾选transient字段在反序列化时未被初始化以及JVM下的不带SerializableUID下的可序列化类。
第二步:鼠标放在Student上Alt+回车系统自动帮我们写

设置序列号之后无论怎么改Student中的内容,序列化与反序列化都不会报错。
注意二:
transient(瞬态关键字)
表示不会把当前属性序列化到本地文件中。
代码示例:
一次读一个Student对象:
一次读多个Student对象,一次读一个ArrayList<E>对象:
打印流
特点:
不能读,只能写。
有特有的写出方法,可以实现数据的原样写出。
特有的写出方法,可以实现自动刷新和自动换行。(打印一次数据=写出+换行+刷新)
字节打印流(printStream)
构造方法:
public PrintStream(OutputStream/File/String):关联字节输出流/文件/文件路径
public PrintStream(String fileName, Charset charset):指定字符编码
public PrintStream(OutputStream out, boolean autoFfush):自动刷新
public PrintStream(Outputstream out, boolean autoFlush, String encoding):指定字符编码且自动刷新
字节流底层没有缓冲区,开不开自动刷新都一样
成员方法:
public void write (...):常规方法:规则跟之前一样,写出指定的字节或字符串
public void println(...):特有方法:打印任意数据,自动刷新,自动换行
public void print (...):特有方法:打印任意数据,不换行
public void printf(String format, Object... args):特有方法:带有占位符的打印语句,不换行
占位符:
%s:字符串(双引号);%b:布尔类型;%n:换行; %c:字符(用单引号括起来);%d:整数等等

文本中的数据:
字符打印流(printWriter)
字符流底层有缓冲区,想要自动刷新需要开启。
public PrintWriter(Write/OutputStream/File/String):关联字节输出流/文件/文件路径
public PrintWriter(String fileName, Charset charset):指定字符编码
public PrintWriter(Write w, boolean autoFlush):自动刷新(如果没有写close方法,直接运行也能把写在写入的成员方法里的内容,写出到本地文件中;如果没有打开自动刷新,那么只有调用close方法之后才会刷新本地文件。)
public Printwriter(OutputStream out, boolean autoFlush, Charset charset):指定字符编码且自动刷新
成员方法:
public void write (...):常规方法:规则跟之前一样,写出指定的字节或字符串
public void println(Xxx xx):特有方法:打印任意数据,自动刷新,自动换行
public void print (Xxx xx):特有方法:打印任意数据,不换行
public void printf(String format, Object... args):特有方法:带有占位符的打印语句,不换行
解压缩流
解压缩流是读取压缩包中的文件,所以属于输入流。
压缩包中的每一个文件,在java中都是一个ZipEntry对象。
解压本质:把每一个ZipEntry按照层级拷贝到本地另一个文件夹中
public ZipInputStream(InputStream):关联字节输入流
ZipInputStream是一个特殊的输入流,能够逐层解压ZIP文件内容
解释一下getNextEntry方法:把计算机代码这个解压文件中的所有文件以及文件夹都获取出来,如果没有了返回null。

示例:
解释一下zis.read(buffer),每次调用getNextEntry方法后,ZipInputStream的内部状态就会切换到调用getNextEntry方法获得的路径,read读取的就是当前的这个条目,并且读取的数据是自动解压后的原始文件(因为ZipInputStream.read()在内部会处理解压过程,返回的是解压后的数据;和FileInputStream.read()不一样,这个直接读取原始字节)。
简单理解:
可以把 ZIP 文件想象成一个包含多个文件的容器。
getNextEntry()相当于打开容器取出一个文件
然后read()就是读取这个被取出的文件的内容
读取完一个文件后,再调用getNextEntry()取出下一个文件
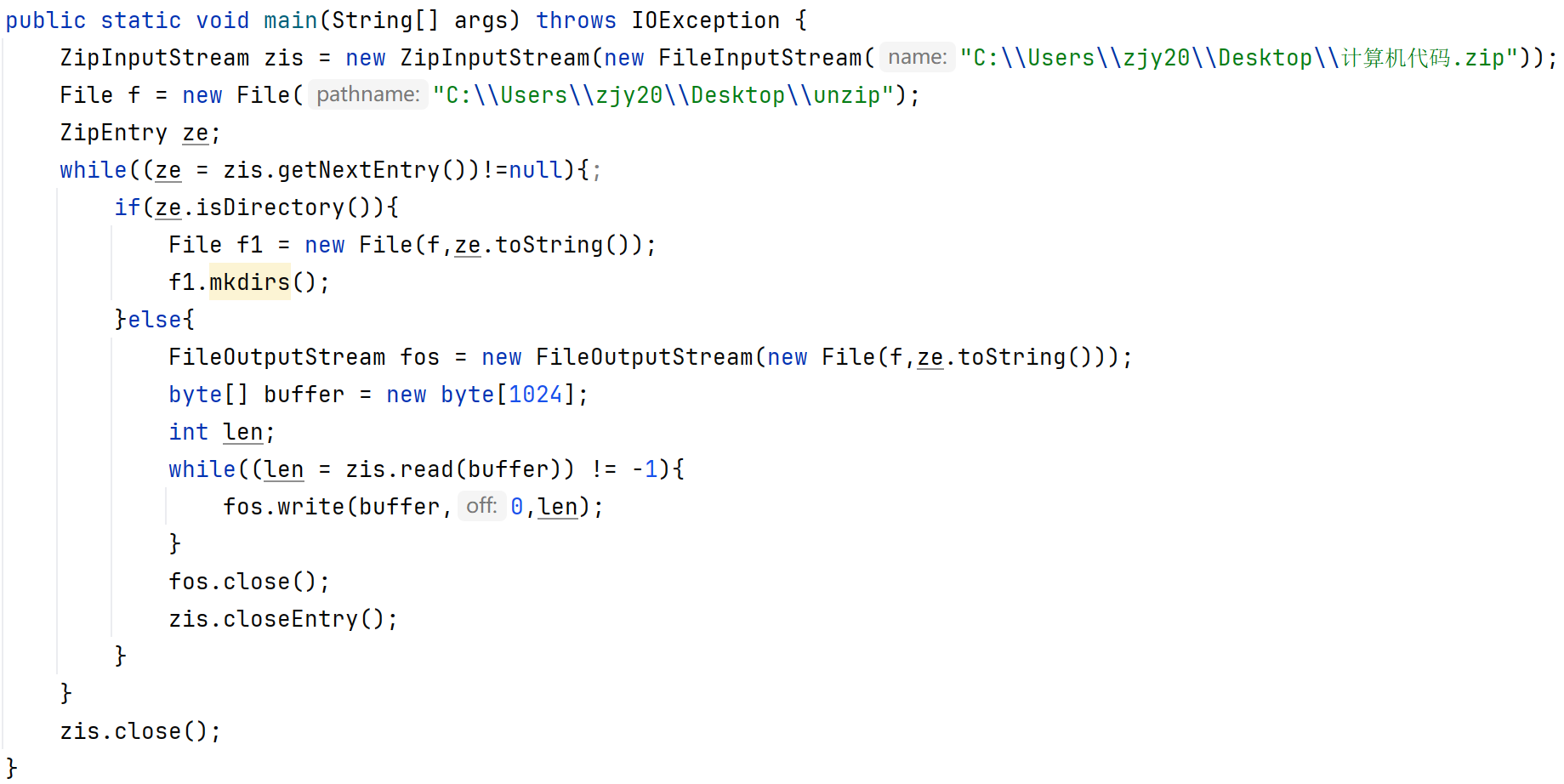
这个代码执行完毕,就会把计算机代码.zip解压到unzip文件中。
压缩流
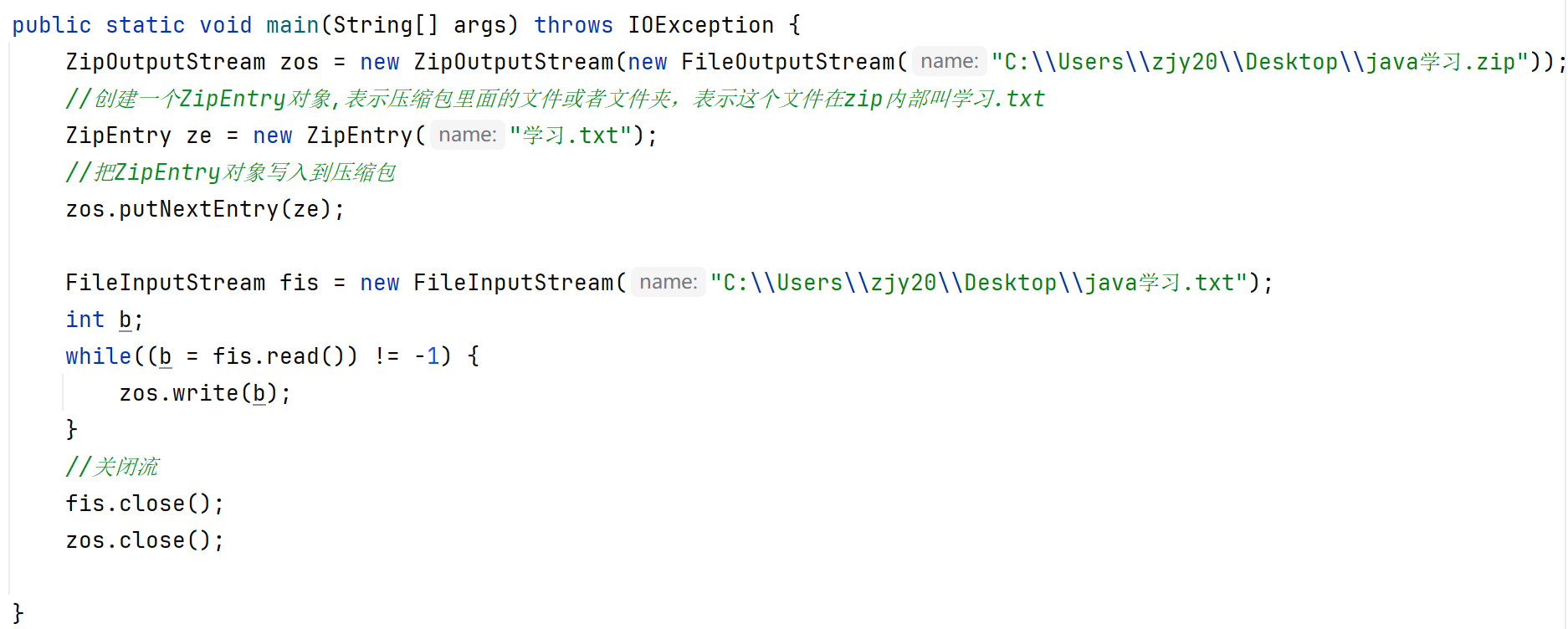
压缩流是把文件中的数据写到压缩包中,所以属于输出流。
压缩包中的每一个文件,在java中都是一个ZipEntry对象。
压缩本质:把每一个(文件/文件夹)看成ZipEntry对象放到压缩包中。
压缩一个文件:
putNextEntry(ze)的作用:它会在 ZIP 文件中创建一个条目(学习.txt),并准备好写入压缩后的数据。此时 ZIP 文件的头部信息(如文件名、压缩方法等)已写入。并且声明当前要写入的是zip内的哪个文件(如下代码表示要写入的是学习.txt这个文本文件)。
zos.write(b)的底层行为
当调用zos.write(b)时:
1.ZipOutputStream会自动压缩传入的原始数据(b)。
2. 将压缩后的数据写入到 ZIP 文件中当前条目(学习.txt)对应的位置。
3. ZIP 文件格式会自动处理文件结构、校验和等细节。
注意点:
1. ZIP 文件的本质
ZIP 文件(如 `java学习.zip`)是一个“二进制容器文件”,它内部可以包含多个文件(如 `学习.txt`),但这些文件并不是真实存在于 `java学习.zip\` 目录下,而是以“压缩数据 + 元信息”的方式存储在 ZIP 文件中。
错误理解:
认为 `java学习.zip` 是一个文件夹,`java学习.txt` 在 `java学习.zip\学习.txt`(物理路径)。
正确理解:
java学习.zip是一个二进制文件,`学习.txt` 是它的内部条目(逻辑路径),并不是真实的文件系统路径。
ZIP 文件不是文件夹:
操作系统看到的 `java学习.zip` 是一个二进制文件,不是目录,所以 `java学习.zip\学习.txt` 这样的路径不存在。
压缩一个文件夹:
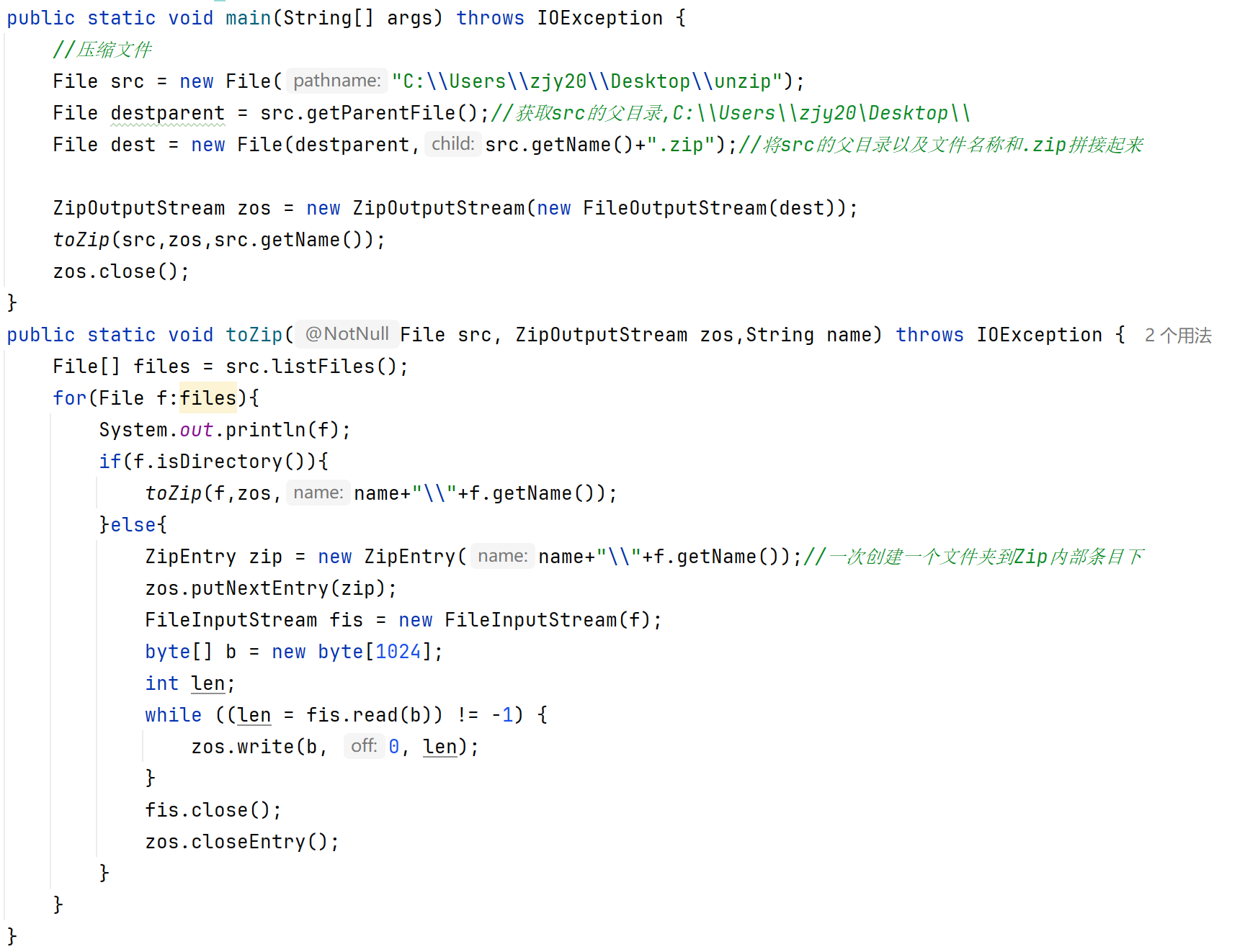
Commons-io工具包
Commons-io是apache开源基金组织提供的一组有关IO操作的开源工具包。
作用:提高IO流的开发效率。
Apache是专门为支持开源软件项目而办的一个非盈利性组织。
Commons工具包中有很多的工具类,而现在我要说的是IO流有关的工具类
Commons-io不是java底层写的,而是Apache提供的,Apache会把写好的代码打包成一个压缩包(在java中压缩包的后缀是.jar),所以我们在使用的时候需要先把别人的代码导入到自己的项目中。
使用步骤:
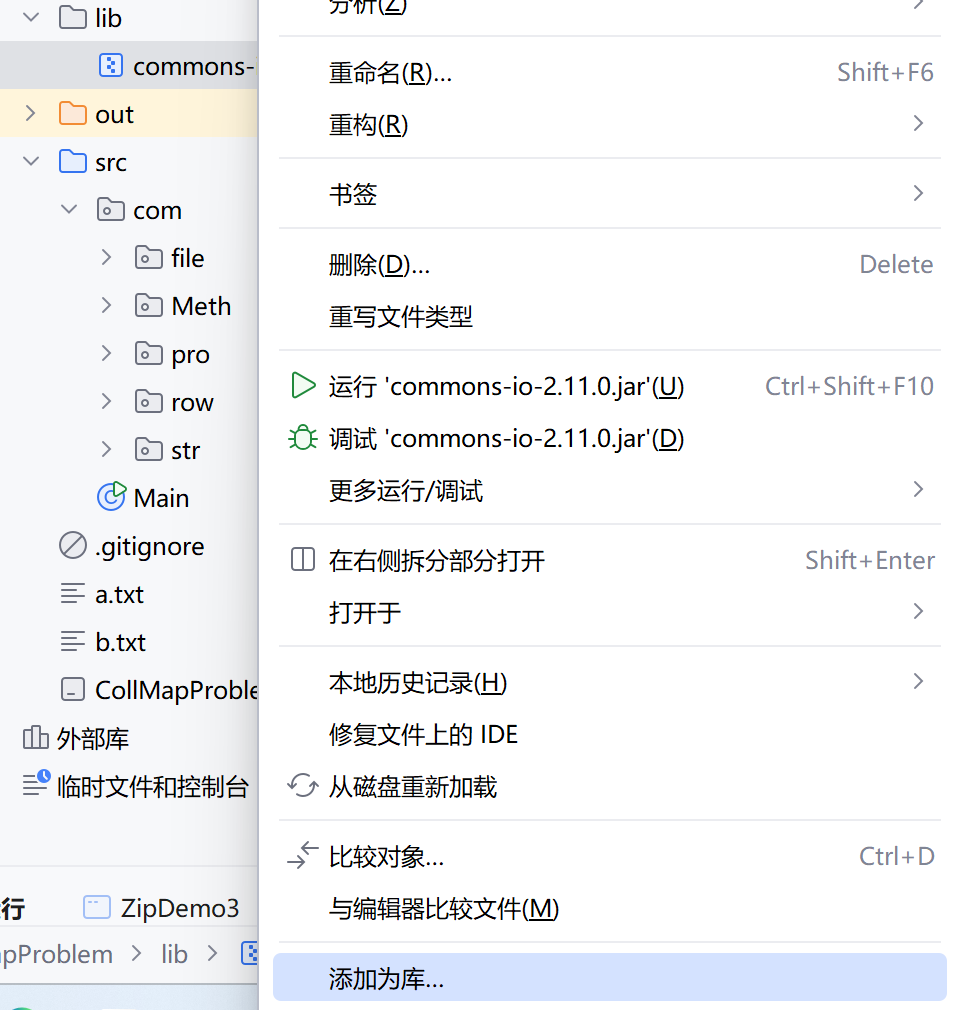
1、在项目中创建一个文件夹:lib
2、将jar包复制粘贴到lib文件夹
3、右键jar包,选择添加为库,点击OK
4、在类中导包使用
在我的电脑中之前下载maven的时候,包含这个.jar包,所以直接使用:
Commons-io常见方法
FileJtils类:(跟文件或者文件夹相关)
static void copyFile(File srcFile, File destFile):复制文件
static void copyDirectory(File srcDir, File destDir):复制文件夹(直接拷贝文件夹里面的内容)
static void copyDirectoryToDirectory(File srcDir, File destDir):复制文件夹(拷贝文件夹名字,以及文件夹里面的内容)
static void deleteDirectory(File directory):删除文件夹
static void cleanDirectory(File directory):清空文件夹
static String readFileToString(File file, Charset encoding):读取文件中的数据变成成字符串
static void write(File file, CharSequence data, String encoding):写出数据
IOUtils类(流相关相关)
public static int copy(InputStream input, OutputStream output):复制文件
public static int copyLarge(Reader input, Writer output):复制大文件
public static String readLines(Reader input):读取数据
public static void write(String data, OutputStream output):写出数据
Hutool工具包
Hutool工具包中也有很多的工具类,但是现在我也之说跟IO有关的工具类
点击这个官网查看下载过程。以及其中的API文档中的一些方法
Hutool🍬一个功能丰富且易用的Java工具库,涵盖了字符串、数字、集合、编码、日期、文件、IO、加密、数据库JDBC、JSON、HTTP客户端等功能。Hutool是一个功能丰富且易用的Java工具库,封装的工具涵盖了字符串、数字、集合、编码、日期、文件、IO、加密、数据库JDBC、JSON、HTTP客户端等一系列操作。![]() https://hutool.cn/
https://hutool.cn/
相关类:
IoUtil:流操作工具类
FileUtil:文件读写和操作的工具类
FileTypeUtil:文件类型判断工具类
WatchMonitor:目录、文件监听
ClassPathResource:针对 ClassPath中资源的访问封装和字符流两个类名重复了,所以一定要注意自己的导包。
FileReader:封装文件读取
FileWriter:封装文件写入