基于京东评论的文本挖掘与分析,使用LSTM情感分析算法以及网络语义分析
思路步骤:
本文实现了从评论数据中提取有用信息,分析其主题分布,并通过可视化展示。以下是具体步骤和思路:
1、数据准备与预处理
加载数据:通过 pandas 读取数据。
文本清洗与分词:使用正则表达式提取中文字符,并调用 jieba 对文本进行分词,同时去除停用词,保留有意义的词语。
文本筛选:筛选数据,剔除重复内容,以确保分析的效率和数据质量。
2、情感分析与可视化
情感分析:利用lstm模型对评论数据进行训练,分类为“正面”“中性”或“负面”。
可视化展示:统计情感分布并绘制饼图,用不同颜色表示情感类别,直观反映用户反馈。
数据处理实现:
数据准备与预处理在文本分析中至关重要,是后续建模与分析的基础。本文中的数据准备与预处理主要包括以下步骤:
1、数据加载:通过 pandas 读取数据 DataFrame 格式。
2、数据清洗与筛选:通过 drop_duplicates 去重,避免因重复数据影响分析结果。

3、文本预处理:对评论内容进行分词和清洗。利用正则表达式提取中文字符后,通过 jieba 进行分词,并加载停用词表过滤掉无意义的高频词和单字。最后将处理后的分词结果重新拼接成文本,便于后续特征提取。

词频分析:
在词频分析中,核心目标是统计文本中每个词出现的频率,以发现高频词和潜在的关键词。实现过程中,首先需要对文本进行预处理,包括去除停用词、标点符号等无效信息,并通过分词工具(如 jieba)将句子拆分为词语。然后,利用数据结构(如字典或 Counter)统计每个词的出现次数。将结果按频率从高到低排序,提取高频词以生成词云或柱状图进行可视化。此外,结合 TfidfVectorizer 提取权重更高的关键词,与简单词频分析的结果进行对比分析,从而提升分析的精准性和有效性。这种方法广泛应用于文本挖掘、舆情监控等领域。词频结果如下:

通过对用户评论的词频分析,可得出以下结论:
核心需求聚焦教育场景:高频词“孩子”(14250次)、“学习”(10517次)、“学习机”(7988次)直接体现用户群体以家长为主,关注点集中于儿童教育类智能硬件(如学习平板)的使用体验。护眼功能(4555次)、教学内容(2572次)和同步课程(1846次)等词频表明家长对产品的内容适配性、健康保护及教育效果高度敏感。
产品性能与体验并重:硬件层面,“屏幕”(6185次)、“音质”(2783次)、“流畅”(1036次)等高频词反映用户对显示效果、声音质量及运行流畅度的重视;软件层面,“功能”(5074次)、“智能”(2168次)、“操作”(1478次)等词凸显用户对产品智能化、功能实用性的需求。负面评价中“不好”(741次)多与功能局限或体验瑕疵相关,提示需优化细节设计。
服务与性价比影响决策:服务维度,“客服”(2878次)、“物流”(1866次)、“售后”(591次)等词显示用户对售前咨询、配送效率及售后支持的关注,而“性价比”(1891次)、“价格”(1607次)、“赠品”(702次)则表明价格敏感度较高,需平衡产品价值与成本。高频词“推荐”(2250次)和“值得”(2139次)进一步印证用户倾向于口碑好、综合性价比高的产品。
建议:品牌应强化教育内容生态建设,升级护眼技术以提升健康属性;优化智能交互功能(如错题识别584次、语音控制922次),增强用户体验流畅度;完善客服响应机制,通过增值服务(如会员权益737次)提高用户粘性,同时加强“学而思”“科大”等教育IP合作,凸显差异化优势。。
网络语义分析
网络语义分析通过构建关键词之间的关系网络来揭示文本中的潜在联系和语义结构。使用CountVectorizer对文本进行词频矩阵化处理,得到每个单词的出现频率。应用TruncatedSVD(即潜在语义分析,LSA)降维技术,将高维的词频矩阵压缩到较低的维度(最多1000个特征),并通过Normalizer进行标准化,以便更好地捕捉词汇之间的语义关系。
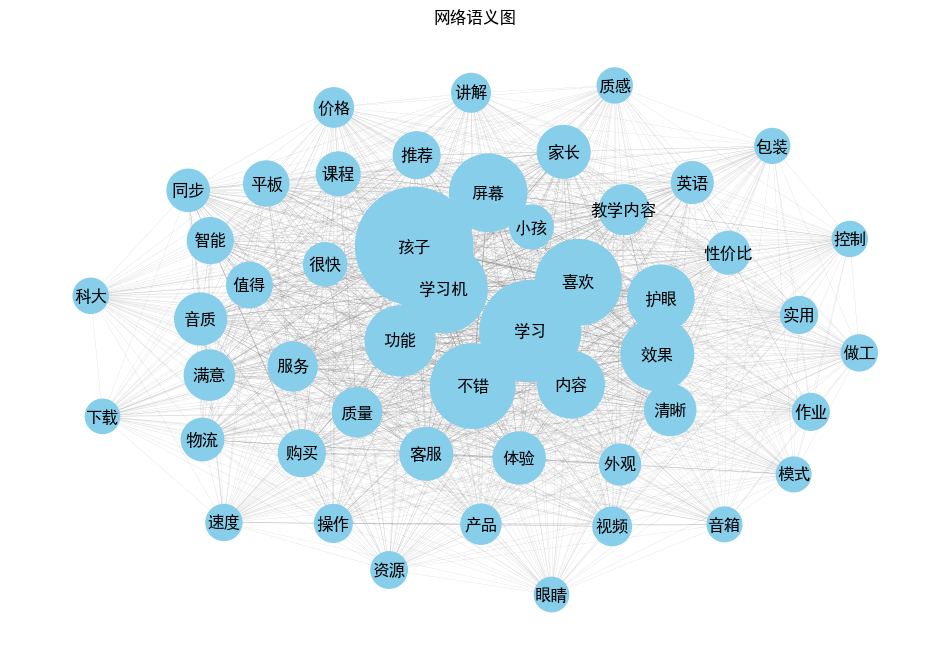
通过计算每个词汇的频率,选出最常见的前50个关键词,并利用networkx库构建一个图网络。每个关键词作为网络中的节点,其频率决定节点的大小。节点之间的边表示关键词之间的语义关系,边的权重是由节点频率的最小值决定的,反映了它们之间的紧密程度。使用matplotlib绘制词频语义图,通过节点和边的可视化,展示关键词之间的关系强度及其在文本中的重要性。这种方法能够有效地揭示文本中词汇的聚类趋势以及它们的关联性。博文网络语义如下图:
情感分析:
情感分类的目标是根据文本数据预测文本的情感倾向,通常包括负面、中性、正面三种类别。上述代码通过构建基于LSTM(长短时记忆网络)的模型来实现这一任务。下面将详细介绍如何实现情感分类。
1. 数据准备与预处理
首先,需要准备训练集和测试集数据。数据集包括文本(如用户评论、社交媒体内容等)和相应的标签(如负面、中性、正面情感)。代码中使用 load_excel 函数从 Excel 文件加载训练数据和测试数据,并将文本数据转化为适合模型处理的格式。
2. 词向量表示
在文本数据中,每个单词或词语通常被表示为数字向量。为了将文本数据转化为数值格式,代码使用了 Word2Vec 模型。Word2Vec 是一种将每个词映射为固定维度向量的技术,能够捕捉词与词之间的语义关系。通过训练 Word2Vec 模型,可以得到每个单词的向量表示。
加载了所有训练和测试数据后,通过 Word2Vec 对每个文本中的词语进行处理,得到文本的向量表示。text_to_vector 函数将每个文本转换为其词向量的平均值,这样每个文本就变成了一个固定长度的向量,适合用于深度学习模型。
3. LSTM模型
情感分类任务的核心是使用 LSTM 模型对文本进行分类。LSTM 是一种常见的递归神经网络(RNN),适用于处理时序数据,如文本。LSTM 能够有效地捕捉文本中长距离依赖的关系,这是情感分析中非常重要的特性,因为情感的表达往往需要考虑上下文信息。
LSTM 模型的结构包括:
输入层:输入的文本是由每个词的 Word2Vec 向量组成的,作为 LSTM 的输入。
LSTM 层:负责处理输入文本的时序依赖。
全连接层(FC层):将 LSTM 输出的最后一个隐藏状态传递给全连接层进行分类。
4. 模型训练
训练过程中,使用交叉熵损失函数(CrossEntropyLoss),它是多分类问题常用的损失函数。在优化器方面,使用了 Adam 优化器(Adam),因为它通常能在大多数任务中提供良好的性能。每次训练时,通过反向传播和梯度更新优化模型参数。
5. 模型评估
模型训练完成后,使用测试数据对模型进行评估。为了评价模型的分类性能,计算了AUC(曲线下面积)分数,它是衡量分类器性能的一个常见指标。AUC越大,模型性能越好。
此外,还通过混淆矩阵展示了每个类别的分类结果,并通过 ROC 曲线可视化模型的性能。ROC 曲线是展示分类器在不同阈值下表现的图形,能够直观地反映模型的分类效果。
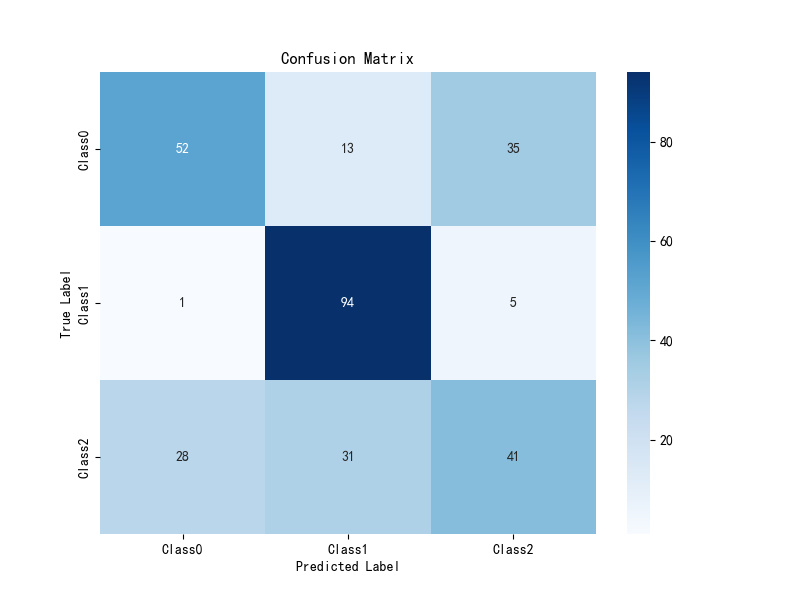
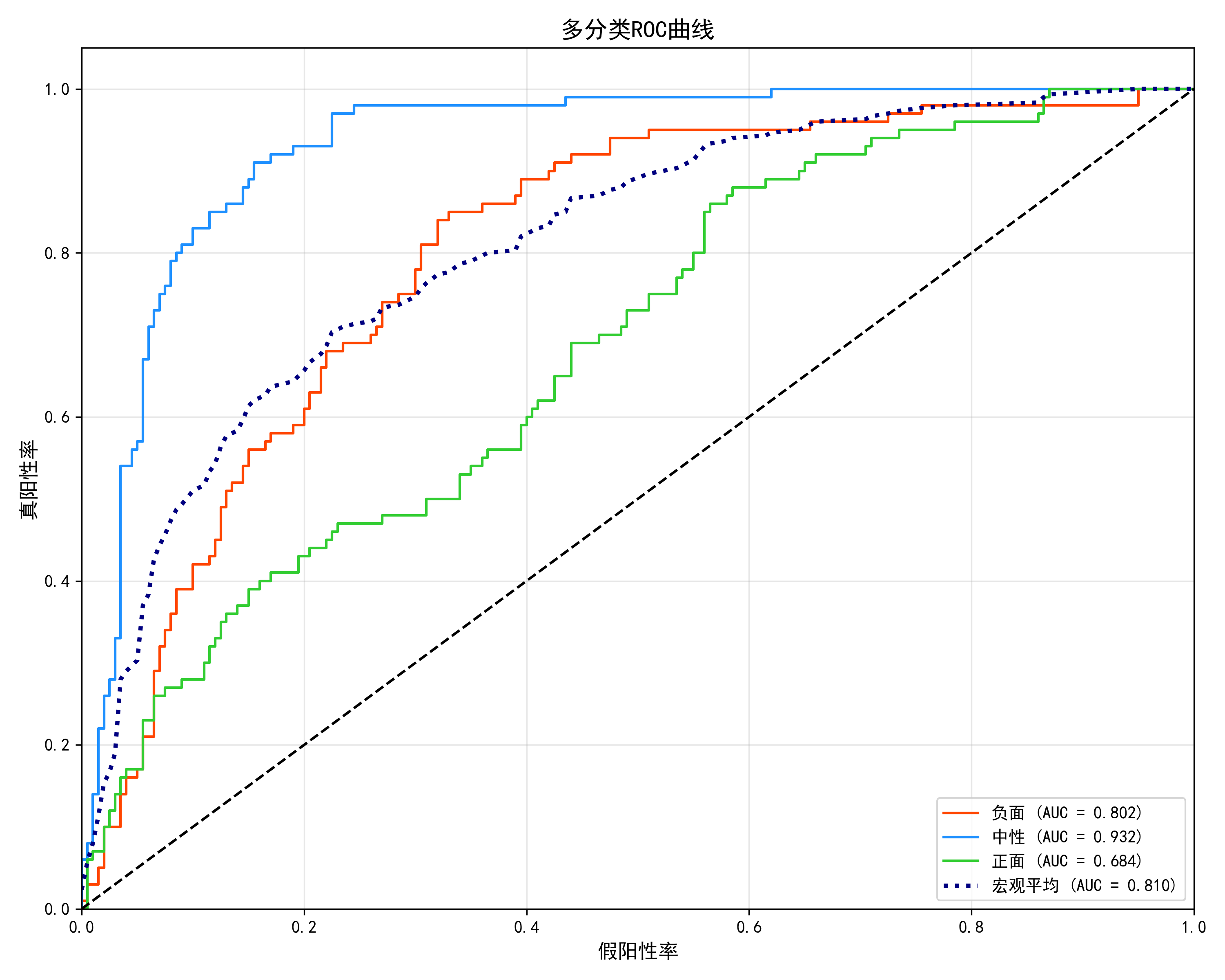
根据提供的混淆矩阵图和ROC曲线的评估结果,可以得出以下结论:
从混淆矩阵来看,模型在三个类别上的分类表现差异较大。对于Class0(负面情感),模型表现较好,大多数样本正确分类为Class0(52个)。但是,存在一定的误分类情况,尤其是将负面情感误分类为Class2(35个)或Class1(13个)。对于Class1(积极情感),模型的分类准确率较高,有大多数样本被正确分类(94个)。然而,仍有一定数量的样本被误分类为Class2(5个)。对于Class2(),尽管准确分类的样本较多(41个),但仍有不少误分类,尤其是误分类为Class0(28个)和Class1(31个)。
根据ROC曲线来看,模型在所有类别上的AUC值都较高,表明其分类性能较好。尤其是在多类别的ROC曲线中,所有类别的AUC值都接近1,表示模型在区分不同情感类别时有较强的能力。
虽然模型在一些类别上存在误分类,特别是负面情感和正面情感之间的误判,但整体分类性能依然表现出色,能够较好地处理情感分类任务。
通过这一系列操作,实现了对评论内容进行情感分析并可视化呈现不同情感类别的占比情况,为进一步分析用户情感倾向提供了重要参考。这样的分析和可视化有助于了解用户对产品的情感态度,为满意度分析提供了有益的信息支持,情感分析如下图:
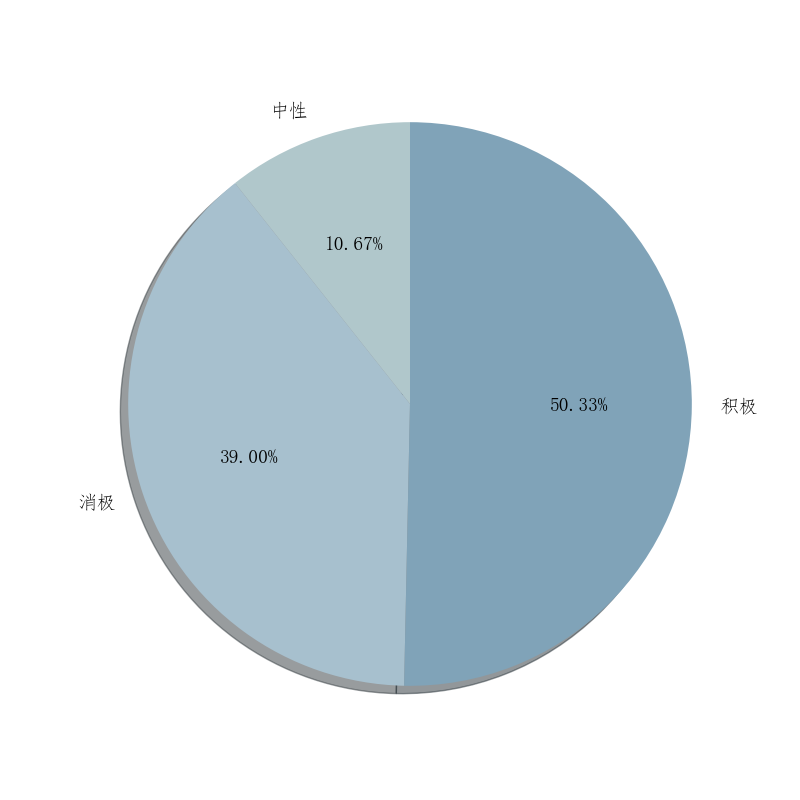
情感分析结果显示,消极情感占主要,其次是积极,中性最少。