打破数据质量瓶颈:用n8n实现30秒专业数据质量报告自动化
你刚拿到一个新数据集。在开始分析之前,你必须弄清楚自己手上的数据:有多少缺失值?哪些列存在问题?整体数据质量得分如何?
多数数据科学家每次拿到新数据集,都要花15-30分钟手动探索:用pandas加载,运行 .info()、.describe()、.isnull().sum(),再做可视化分析缺失模式。如果每天要评估多个数据集,这一流程就会变得极其繁琐。
如果你只需粘贴任何CSV链接,30秒内就能获得专业级的数据质量报告呢?无需Python环境、无需手动编程、无需在不同工具间切换。
解决方案:4节点n8n自动化工作流
n8n(发音为“n-eight-n”)是一款开源的工作流自动化平台,能通过可视化拖拽界面连接不同服务、API和工具。许多人将工作流自动化与邮件营销、客户支持等业务流程联系在一起,但n8n同样可以自动化传统上需要自定义脚本的数据科学任务。
与编写独立Python脚本不同,n8n的工作流具备可视化、可复用、易于修改的特点。你可以连接数据源、执行转换、运行分析并输出结果——无需在不同工具或环境间切换。每个工作流由多个“节点”组成,每个节点代表一个操作,通过连接形成自动化管道。
我们的自动化数据质量分析器由四个连接的节点组成:
用n8n自动生成数据质量报告:从CSV到专业分析
- 手动触发节点:点击“执行”启动工作流
- HTTP请求节点:从URL获取任何CSV文件
- 代码节点:分析数据并生成质量指标
- HTML节点:创建美观、专业的报告
工作流搭建:逐步实现
前置条件
- n8n账号(n8n.io可免费试用14天)
- 我们提供的预置工作流模板(JSON文件)
- 任意可通过公网URL访问的CSV数据集(下文有测试示例)
步骤1:导入工作流模板
无需从零开始,我们直接使用内含所有分析逻辑的配置模板:
- 下载工作流文件
- 打开n8n,点击“Import from File”
- 选择下载的JSON文件,四个节点将自动加载
- 用你喜欢的名字保存该工作流
导入的工作流中,四个节点已配置好所有复杂的解析与分析代码。
步骤2:了解你的工作流
逐步解析每个节点的功能:
- 手动触发节点:点击“执行工作流”时启动分析,适合按需检查数据质量。
- HTTP请求节点:从任意公开URL拉取CSV数据,默认支持大多数标准CSV格式,输出用于分析的原始文本数据。
- 代码节点:分析引擎,具备强大的CSV解析能力,能智能识别分隔符、引号字段、缺失值格式。自动完成:
- 智能字段检测并解析CSV数据
- 识别多种格式的缺失值(如null、空白、“N/A”等)
- 计算质量得分和严重等级
- 给出具体、可操作的改进建议
- HTML节点:将分析结果转化为美观的报告,采用颜色编码显示质量分数及清晰排版。
步骤3:自定义你的数据
分析你自己的数据集:
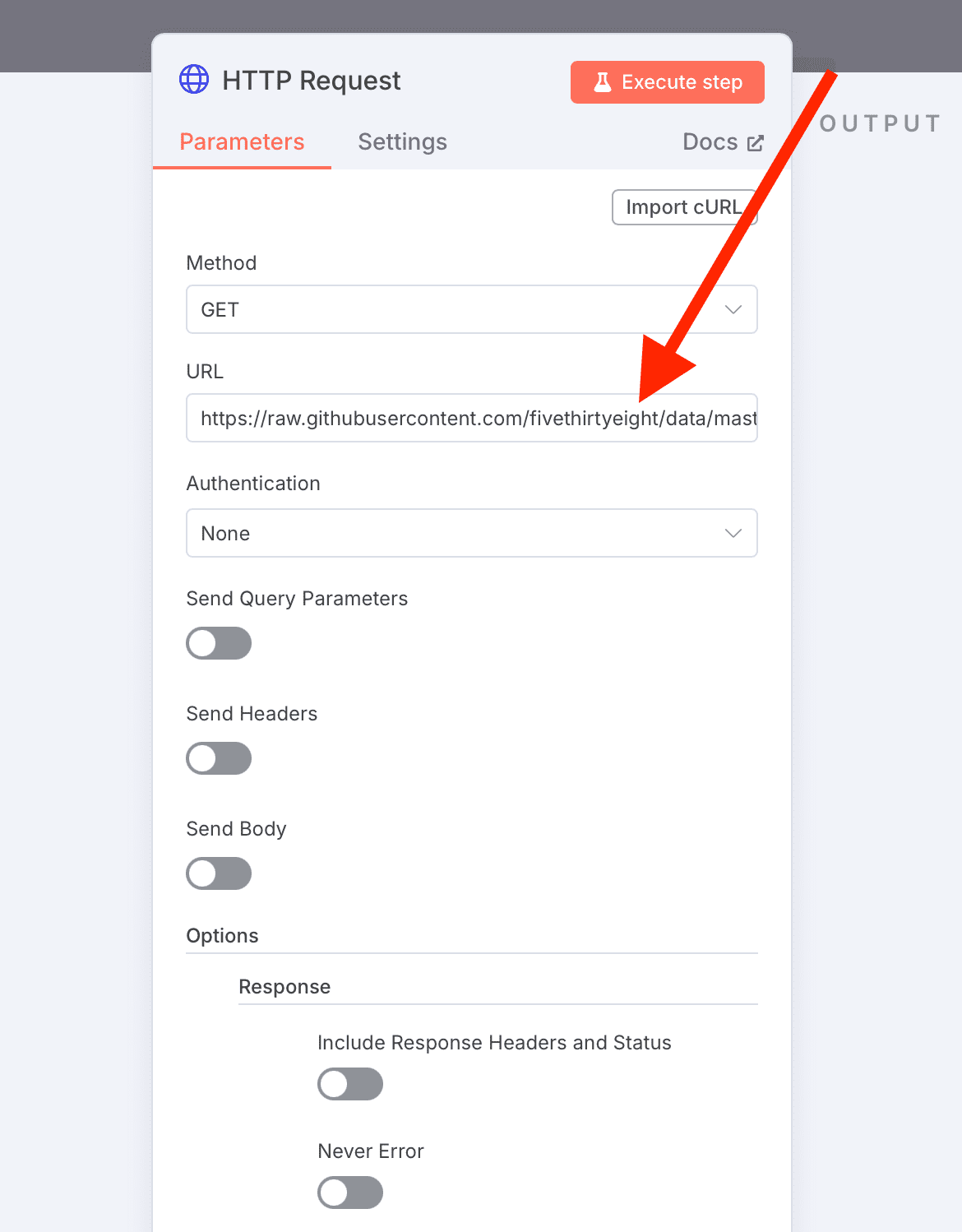
- 点击HTTP请求节点
- 替换URL为你自己的CSV数据集地址:
- 当前示例:https://raw.githubusercontent.com/fivethirtyeight/data/master/college-majors/recent-grads.csv
- 你的数据:https://your-domain.com/your-dataset.csv
- 保存工作流
分析逻辑会自动适配不同CSV结构、列名和数据类型。
步骤4:执行与查看结果
- 点击顶部工具栏的“Execute Workflow”
- 观察各节点处理进度——全部完成后会显示绿色勾选
- 点击HTML节点,并在“HTML”选项卡查看报告
- 可复制报告或截屏与团队分享
整个流程一旦搭建好,完整运行仅需30秒。
解读结果
颜色编码的质量分数让你一目了然地评估数据集:
- 95-100%:完美(或接近完美),可直接分析
- 85-94%:极佳,仅需极少清洗
- 75-84%:良好,需适量预处理
- 60-74%:一般,需中度清洗
- 低于60%:较差,需要大量处理
注:本实现采用基于缺失值的简单评分系统。后续可扩展如一致性检测、异常值检测、模式校验等高级指标。
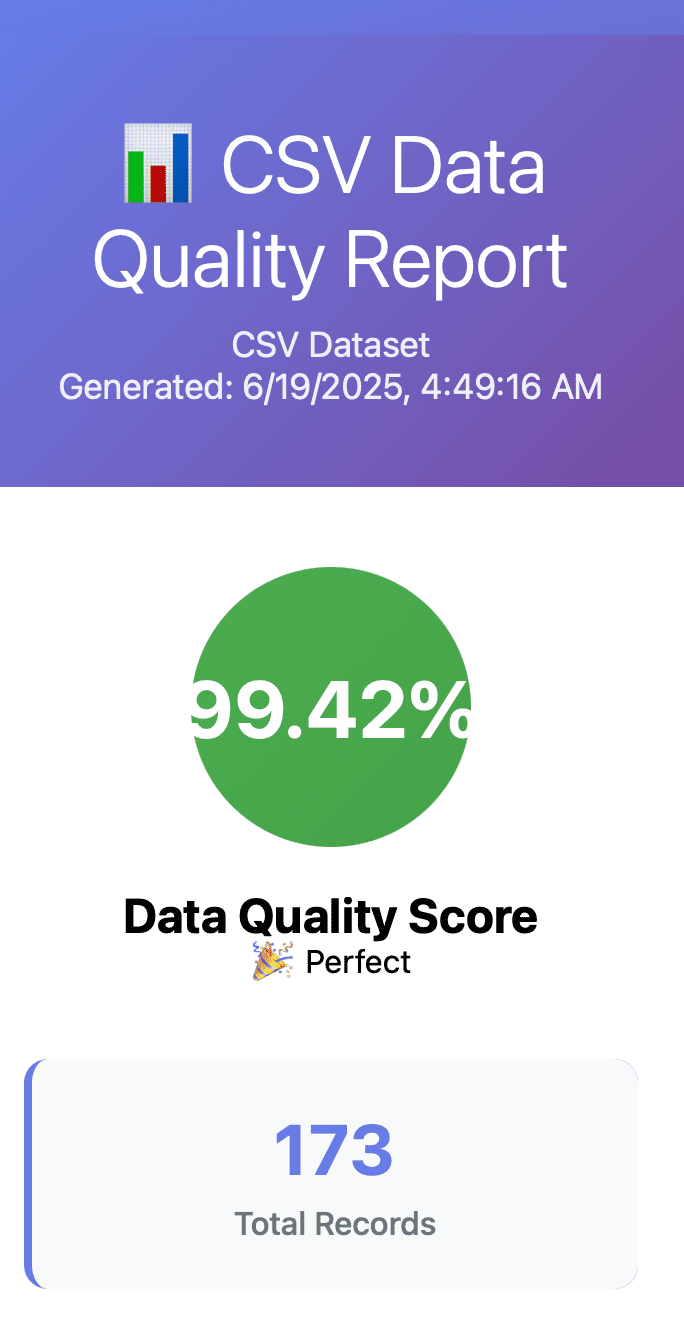
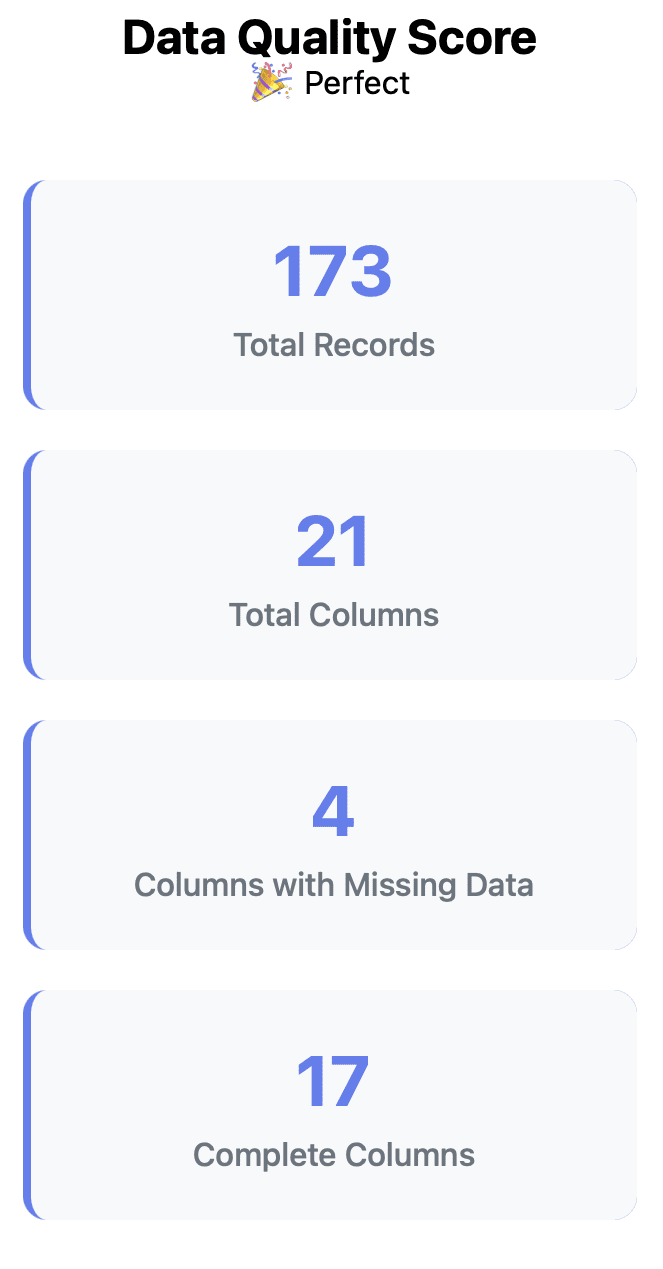
示例报告预览
我们的样例分析显示数据质量得分为99.42%——表明数据几乎完整,可直接用于分析,预处理需求极低。
数据集概览:
- 173条记录:小而精,适合快速探索性分析
- 21个字段:特征数量适中,便于聚焦洞察
- 4列存在缺失:部分字段有空缺
- 17列完整无缺失:大多数字段数据齐全
不同数据集的测试
你可以尝试以下数据集,观察工作流如何自动适应不同缺失模式:
- Iris数据集(https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv):通常得分100%,无缺失
- 泰坦尼克数据集(https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv):因Age、Cabin等字段缺失,得分约67.6%,更贴近实际场景
- 你的数据:上传到Github raw或使用任何公网CSV链接
根据得分,你可决定后续步骤:
- 95%以上:直接EAD
- 85-94%:仅清理少量问题列
- 75-84%:适度预处理
- 60-74%:需针对多列重点清理
- 低于60%:评估数据集是否值得投入大量清洗
工作流会自动适配任何CSV结构,助你高效评估多个数据集,科学分配数据准备精力。
进阶应用
1. 邮件集成
添加发送邮件节点,将报告自动分发给相关方。HTML节点后连接Send Email节点,即可将质量报告自动发给项目经理、数据工程师或客户。你还可自定义邮件模板,添加高管摘要或针对性建议。
2. 定时分析
将手动触发节点换成定时触发,实现定期自动分析,适合频繁更新的数据源。设置每日、每周或每月检查,及时发现数据质量变化,防止问题影响下游分析和模型表现。
3. 多数据集批量分析
让工作流接受CSV链接列表,批量生成多个数据集的质量对比报告。适用于新项目数据源筛选或组织内定期数据质量审计。还可生成汇总仪表盘,按得分排序,优先清理低质量数据。
4. 支持多种文件格式
拓展代码节点的解析逻辑,支持JSON、Excel等数据格式。JSON可自定义提取嵌套结构,Excel可先预处理为CSV。支持多格式让你的质量分析器成为组织通用工具,不受数据存储/交付方式限制。
结论
本n8n工作流展示了可视化自动化如何高效提升数据科学的日常工作,同时保留数据科学家所需的技术深度。你可利用已有的编程能力自定义JavaScript分析逻辑、扩展HTML报告模板,并集成到现有的数据基础设施——通通在直观的可视化界面下完成。
工作流的模块化结构,非常适合既懂技术又理解业务的数据科学家。与传统的零代码工具不同,n8n允许你灵活修改分析逻辑,并通过可视化使工作流易于共享、调试和维护。你可以以此为基础逐步扩展统计异常检测、自定义质量指标或集成到现有MLOps流程。
更重要的是,这种方案打通了数据科学专业能力与组织广泛可用性的桥梁——技术同事可自定义代码,非技术同事可直接执行工作流、即刻解读结果。技术深度与易用性的结合,让n8n成为数据科学家放大影响力的理想工具。