Java WEB技术-序列化和反序列化认识(SpringBoot的Jackson序列化行为?如何打破序列化过程的驼峰规则?如何解决学序列化循环引用问题?)
一、什么是序列化和反序列化
在java项目中,对象序列化和反序列化通常用于对象的存储或网络传输等。如:服务端创建一个JSON对象,对象如何在网络中进行传输呢?我们知道网络传输的数据通常都是字节流的形式,对象想要在网络上传输,不例外,也必须要转化成字节流才行。
将对象转换为字节流的过程就是对象的序列化过程,转化后的字节数据就可以在网络中进行传输了;接收端接收到这些字节数据后将其还原为原始对象的过程,也就是反序列化。通过序列化和反序列化的方式,即可以实现对象在不通节点之间进行网络传输了。
1、服务端对象创建与序列化
1、对象创建
首先,在服务端根据业务逻辑或用户请求创建相应的Java对象。例如,一个包含用户信息的对象User。
2、选择序列化方式
通常有两种方式:
(1)、手动实现Serializable接口
如果使用Java原生的序列化机制,需要让该类实现java.io.Serializable接口。这是一种标记接口,表明该类的对象可以被序列化。
(2)、使用第三方库(推荐)
也可以使用如Jackson(JSON)、Gson(JSON)、Fastjson或者Protocol Buffers等第三方库进行序列化,这些库提供了更灵活的数据格式支持(如JSON、XML等),并可能具有更好的性能或易用性。
3、触发序列化
当你需要通过网络发送对象(比如HTTP响应、RPC调用等)或保存对象到文件系统时,就会触发序列化过程。这通常涉及到将对象转换为字节流或特定格式的字符串。如:Controller类上添加了@RestController注解,或接口上添加了@ResponseBody注解。
代码示例:
@ResponseBody
public MyDto getData() {return myDto; // 自动转为 JSON
}
解释:
如上示例,在接口上添加@ResponseBody注解,springboot会在接口返回结果时,自动将对象转JSON字符串进行序列化处理。
或,对于第三方库,比如使用Jackson来序列化一个对象为JSON字符串:
代码示例:
ObjectMapper mapper = new ObjectMapper();
String jsonInString = mapper.writeValueAsString(user);
2、网络传输
序列化后的数据(字节流或字符串形式)通过网络协议(如HTTP、TCP/IP等)从服务端发送给客户端。在这个过程中,数据可能会经过编码、加密等处理以确保安全性和兼容性。
说明下:
字节流和字符流是可以通过编码的方式相互转换的。如下的示例展示通过UTF-8编码,进行字符串和字节流的互转:
String originalString = "Hello, 世界!";byte[] byteArray = originalString.getBytes(StandardCharsets.UTF_8);String decodedString = new String(byteArray, StandardCharsets.UTF_8);
**Springboot处理序列化的方式:**会先将返回的对象转json文本字符串,之后在通过编码方式,如UTF-8,将JSON字符串编码为二进制流。在封装到HTTP包的请求体中,同时在请求头中指定content-type:application/json,浏览器会根据返回内容类型自动解析文件内容。
3、接收端处理
1、接收数据
客户端接收到从服务端传来的字节流或字符串数据。
2、反序列化
如果是Java原生序列化格式,可以使用ObjectInputStream来读取字节流并恢复对象。
代码示例:
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.dat"))) {User user = (User) ois.readObject();} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}
如果是使用了第三方库进行序列化,则需要相应的反序列化方法。例如,使用Jackson将JSON字符串转换回Java对象:
代码示例:
ObjectMapper mapper = new ObjectMapper();
User user = mapper.readValue(jsonInString, User.class); // jsonInString为接收的字符串
3、处理对象
一旦对象被成功反序列化,就可以在客户端进行进一步的操作,比如显示给用户、存储在本地数据库中等。
4、序列化和反序列化的整体流程
返回对象–>json字符串–>编码为二进制流–>封装HTTP报文–>网络传输–>客户端解码–>反序列化为对象。
二、SpringBoot中的Jackson ObjectMapper是如何工作的?
1、Java原生Serializable序列化和第三方的Jackson序列化
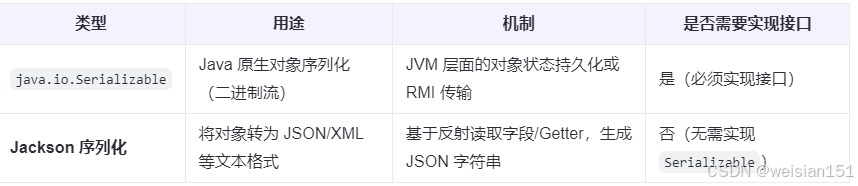
- Serializable主要用于Java对象的深拷贝、RMI、缓存(如Redis存为二进制)等场景。
- Jackson主要用于Web接口的数据交换(JSON/XML)。
2、Spring Boot中的ObjectMapper是如何工作的?
1、注入ObjectMapper对象(即Jackson的序列化器)
代码示例:
@Bean
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {ObjectMapper objectMapper = builder.createXmlMapper(false).build();
// objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL) // 为null字段不返回objectMapper.setSerializationInclusion(JsonInclude.Include.ALWAYS) // 返回所有字段,包含null值的字段.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS).registerModule(new ParameterNamesModule()).registerModule(new Jdk8Module()).registerModule(new JavaTimeModule());/*** 序列换成json时,将所有的long变成string* 因为js中得数字类型不能包含所有的java long值*/SimpleModule module = new SimpleModule();module.addSerializer(Long.class, ToStringSerializer.instance);module.addSerializer(Long.TYPE, ToStringSerializer.instance);// Double类型对象到前端自动去除小数点末尾无效的0module.addSerializer(Double.class, new SmartNumberSerializer());module.addSerializer(Double.TYPE, new SmartNumberSerializer());objectMapper.registerModule(module);return objectMapper;}
解释:
如上配置并注入Jackson 的序列化器后,Spring Boot的行为会如下:
1、Spring Boot会使用Jackson作为默认的JSON处理库(通常是jackson-databind),而不是在Java默认的序列化器。
2、这个ObjectMapper实例会被注入到Spring MVC的HttpMessageConverter中,特别是:
- MappingJackson2HttpMessageConverter
3、当你使用:
@ResponseBody
@RestController
public MyDto getData() {return myDto; // 自动转为 JSON
}
Spring就会调用ObjectMapper.writeValueAsString(myDto) 把对象转成JSON字符串,写入HTTP响应体。
2、自动进行序列化和反序列化”是如何触发的?
(1)、序列化(Java对象 → HTTP响应)
当你返回一个对象,如下:
@GetMapping("/user")
public User getUser() {return new User("张三", 25);
}
Spring 执行流程:
1、调用getUser()方法,得到User对象。
2、发现方法上有@ResponseBody(或类上是@RestController)。
3、查找合适的HttpMessageConverter。
4、找到MappingJackson2HttpMessageConverter。
5、调用objectMapper.writeValueAsString(user) → 得到JSON字符串。
6、写入响应体,Content-Type设为 application/json。
如上就是Spring的“自动序列化”行为。
(2)、反序列化(HTTP请求体 → Java对象)
当你接收一个JSON请求体。如下:
@PostMapping("/user")
public String createUser(@RequestBody User user) {// user 已经从 JSON 自动解析出来了return "OK";
}
Spring 执行流程:
1、收到POST请求,Content-Type: application/json。
2、发现参数上有@RequestBody。
3、查找合适的HttpMessageConverter。
4、找到MappingJackson2HttpMessageConverter。
5、调用objectMapper.readValue(jsonString, User.class) → 构造出User对象。
6、注入到方法参数。
如上就是Spring的“自动反序列化”行为。
3、总结:
在Spring Boot Web项目中,对象通过网络传输时的“序列化”指的是Jackson将对象转为JSON串的过程,而不是Java原生的Serializable机制。只要配置了ObjectMapper,Spring就会在@ResponseBody和@RequestBody处自动完成序列化和反序列化,对象类无需实现Serializable接口。
三、序列化过程中的循环引用是什么问题?怎么解决?
这是一个非常重要且常见的问题:序列化过程中的循环引用(Circular Reference)。它在Java对象序列化(尤其是JSON序列化)中非常容易出现,如果不处理,会导致错误或无限递归。
1、什么是循环引用?
当两个或多个对象之间相互引用,形成一个闭环时,就产生了循环引用。
代码示例:
public class User {private Long id;private String name;private List<Order> orders;// getter/setter
}public class Order {private Long id;private User user;// getter/setter
}
解释:
如果集合orders中包含的元素存在相同的值,就会产生循环引用的问题。
造成序列化结果如:

2、为什么循环引用在序列化时会出问题?
当你尝试将user对象序列化成JSON串:
代码示例:
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(user);
会发生如下行为:
1、开始序列化user。
2、发现orders字段,开始序列化Order。
3、在Order中发现user字段,又去序列化这个user。
4、这个user又有orders,继续序列化…
5、→ 无限递归!栈溢出(StackOverflowError)
结果:程序崩溃!
3、不同序列化库如何处理循环引用?
1、Jackson(推荐方案)
Jackson 默认不会抛异常,而是使用**@id和@ref**机制来避免重复和循环。
这也是现在系统的默认行为,更安全,能有效防止栈溢出。
序列化的json示例:
{"id": 1,"name": "张三","orders": [{"id": 101,"user": {"@id": "1"}}]
}
解释:
- 第一次出现的user被标记为@id: “1”。
- 后续再引用时,用{“@id”: “1”}表示“这是之前那个对象”
这样,程序不会崩溃,也不会无限递归。
2、FastJSON
FastJSON默认会检测循环引用,并用$ref表示重复对象。
默认行为示例:
{"id": 1,"name": "张三","orders": [{"id": 101,"user": {"$ref": "$"} // $ 表示根对象}]
}
结果:前端可能看不懂$ref,导致解析失败。
4、解决方案
方案1:关闭循环检测(有风险)
代码示例:
JSON.toJSONString(user, SerializerFeature.DisableCircularReferenceDetect);
存在风险(StackOverflowError),但实际项目中用的比较多。
方案2:使用 @JSONField(serialize = false) 忽略反向字段
代码示例:
public class Order {@JSONField(serialize = false)private User user;
}
4、如何打破驼峰命名规则
Java对象字段名是小写(驼峰命名),但有时候需要生成的JSON报文字段必须是大写字母开头(如ProtocolType),而Jackson默认使用驼峰转小写开头,这会导致生成的JSON字段名变成小写(如protocolType)。
1、问题原因
Jackson序列化时默认使用Java驼峰命名到JSON小驼峰(lowerCamelCase)的映射规则。
代码示例:
private Integer ProtocolType; // → JSON: "protocolType"(首字母小写)
解释:
定义的字段都是大写开头的ProtocolType,因为Jackson默认使用Java的驼峰命名规则,造成返回的json中是protocolType开头小写的字段。
2、解决方案:使用@JsonProperty显式指定字段名
需要在需要大写的字段上加上@JsonProperty(“原始大写名”)注解,告诉Jackson序列化时使用指定名称。
代码示例:
import com.fasterxml.jackson.annotation.JsonProperty;
import lombok.Data;
import java.util.List;@Data
public class InfraredConfigDTO {@JsonProperty("ProtocolType") // 指定的属性名为我们要求的大写开头的格式private Integer protocolType; // 属性定义必须是小写@JsonProperty("Type")private Integer type;@JsonProperty("Preset")private Integer preset;
}
注意:
属性字段必须定义成小写开头的驼峰规则。@JsonProperty注解注定满足要求的大写规则。
生成的JSON效果:
{"ProtocolType": 1,"Type": 2,"Preset": 0
}
向阳前行,Dare To Be!!!