yolo8+阿里千问图片理解(华为简易版小艺看世界)
✅ 实现目标
-
按下空格键 → 获取摄像头当前画面;
-
将图片上传给 大模型 接口,让其“看图说话”;
-
获取返回描述后,以字幕形式展示在图像画面上;
-
持续显示识别结果,直到下次按空格。
🧠 需要准备的
-
✅ Python 环境(3.8+)
-
✅ OpenCV (
cv2) -
✅ 阿里千问 API 的 Key
-
✅ 安装以下依赖:
pip install opencv-python requests pillow
需要同时保留 YOLOv8 的实时目标检测,并在按下空格时截屏上传给 大模型 接口做“看图说话”,然后将返回的中文描述以字幕形式叠加在画面中。
✅ 总体功能整合:
| 功能项 | 描述 |
|---|---|
| ✅ YOLOv8 实时检测 | 保留,检测物体并标注 |
| ✅ 空格触发 千问 描述 | 按下空格键拍照并上传 |
| ✅ 显示中文字幕 | 将 DeepSeek 返回文字叠加到图像上 |
| ✅ 中文字体支持 | 使用 PIL 实现中文绘图支持 |
import cv2
import numpy as np
from ultralytics import YOLO
from PIL import ImageFont, ImageDraw, Image
import requests
from io import BytesIO
import os
from openai import OpenAI
import base64
from typing import Optional, Union
import logging
import json
import time
from collections import deque
import threading# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 文字
current_caption = ""
# 存储字幕:(text, timestamp)
captions = deque()def img2text(image_path: str, prompt: str = "这张图片是什么,一句话来描述") -> Optional[Union[str, dict]]:global current_caption # 关键:修改全局变量"""将图像转换为文本描述Args:image_path (str): 图像文件路径prompt (str): 提示词,默认为"这张图片是什么"Returns:Optional[Union[str, dict]]: API响应结果,失败时返回None"""# base64_image = image_to_base64(image_path)base64_image = image_pathif not base64_image:return Noneclient = OpenAI(api_key="sk-02128251fc324da9800c2553d67fa2ca",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)try:completion = client.chat.completions.create(model="qwen-vl-plus-2025-01-25",messages=[{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}]}],# stream=False,stream=True,stream_options={"include_usage": False})# print(completion.model_dump_json())full_text = ""# for chunk in completion:# result = json.loads(chunk.model_dump_json())# text = result["choices"][0]["delta"]["content"]# current_caption = text# print("响应:",current_caption)current_line = ""for chunk in completion:result = json.loads(chunk.model_dump_json())word = result["choices"][0]["delta"]["content"]current_line += wordprint("响应:", word)if "。" in word or "?" in word or "!" in word:timestamp = time.time()captions.append((current_line.strip(), timestamp))current_line = ""if current_line.strip(): # 最后一段未结束的也保留captions.append((current_line.strip(), time.time()))except Exception as e:logger.error(f"API调用错误: {e}")return None# ========== 中文字体 ==========
font_path = "font/AlimamaDaoLiTi-Regular.ttf" # MacOS 示例
font = ImageFont.truetype(font_path, 28)# ========== 加载 YOLO 模型 ==========
model = YOLO("/Users/lianying/Desktop/yolo/yolov8n.pt") # 可换为 yolov8n.pt/yolov8s.pt 等# ========== 摄像头 ==========
cap = cv2.VideoCapture(0)while True:ret, frame = cap.read()if not ret:break# YOLOv8 实时检测results = model(frame, verbose=False)[0]annotated_frame = results.plot() # 获取带标注的帧# 叠加 DeepSeek 返回的字幕(如果有)frame_pil = Image.fromarray(cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(frame_pil)# 绘制字幕(只显示近3秒的)now = time.time()frame_pil = Image.fromarray(cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(frame_pil)y_offset = 30for caption, ts in list(captions):if now - ts <= 3:draw.rectangle([20, y_offset - 10, 1200, y_offset + 35], fill=(0, 0, 0, 128))draw.text((30, y_offset), caption, font=font, fill="yellow")print(caption)y_offset += 50else:captions.popleft() # 删除过期字幕frame_final = cv2.cvtColor(np.array(frame_pil), cv2.COLOR_RGB2BGR)cv2.imshow("YOLOv8 实时检测 + 图像描述(按空格)", frame_final)key = cv2.waitKey(1)if key == 27: # ESC 退出breakelif key == 32: # 空格触发print("正在发送当前帧给 DeepSeek,请稍等...")_, buffer = cv2.imencode(".jpg", frame)image_bytes = BytesIO(buffer.tobytes())base64_str = base64.b64encode(buffer).decode('utf-8')print("Base64 (PNG):", base64_str[:50] + "...")img2text(base64_str)cap.release()
cv2.destroyAllWindows()
✅ 按下空格的时候为什么卡顿?
你这段代码里,空格按下时调用的是这个同步过程:img2text(base64_str)
这一段是网络请求 + AI处理 + 流式输出 + 截图处理,在本地和远程服务器之间来回传输数据,因此:
-
YOLO 视频帧不再刷新;
-
cv2.imshow()阻塞; -
显示“卡住”不动,直到接口响应。
✅ 如何解决卡顿问题?
✅ 使用 线程 异步处理图片描述,避免主线程阻塞:
在你主程序中添加多线程工具包:
import threading将触发图像描述的代码改成:
elif key == 32: # 空格触发print("正在发送当前帧给 DeepSeek,请稍等...")# 异步处理图像上传与字幕生成def async_caption():_, buffer = cv2.imencode(".jpg", frame)base64_str = base64.b64encode(buffer).decode('utf-8')img2text(base64_str) # 你之前写的函数threading.Thread(target=async_caption, daemon=True).start()
✅ 整体流程优化后效果
-
主线程负责视频帧采集 + YOLO 检测 + 字幕显示
-
图像描述调用单独在线程中执行,后台上传+接收,不影响主线程
-
效果:按下空格后,摄像头不会卡顿;字幕几秒后自动出现
✅ 完整代码
import cv2
import numpy as np
from ultralytics import YOLO
from PIL import ImageFont, ImageDraw, Image
import requests
from io import BytesIO
import os
from openai import OpenAI
import base64
from typing import Optional, Union
import logging
import json
import time
from collections import deque
import threading# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 文字
current_caption = ""
# 存储字幕:(text, timestamp)
captions = deque()def img2text(image_path: str, prompt: str = "这张图片是什么,一句话来描述") -> Optional[Union[str, dict]]:global current_caption # 关键:修改全局变量"""将图像转换为文本描述Args:image_path (str): 图像文件路径prompt (str): 提示词,默认为"这张图片是什么"Returns:Optional[Union[str, dict]]: API响应结果,失败时返回None"""# base64_image = image_to_base64(image_path)base64_image = image_pathif not base64_image:return Noneclient = OpenAI(api_key="sk-02128251fc324da9800c2553d67fa2ca",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)try:completion = client.chat.completions.create(model="qwen-vl-plus-2025-01-25",messages=[{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}]}],# stream=False,stream=True,stream_options={"include_usage": False})# print(completion.model_dump_json())full_text = ""# for chunk in completion:# result = json.loads(chunk.model_dump_json())# text = result["choices"][0]["delta"]["content"]# current_caption = text# print("响应:",current_caption)current_line = ""for chunk in completion:result = json.loads(chunk.model_dump_json())word = result["choices"][0]["delta"]["content"]current_line += wordprint("响应:", word)if "。" in word or "?" in word or "!" in word:timestamp = time.time()captions.append((current_line.strip(), timestamp))current_line = ""if current_line.strip(): # 最后一段未结束的也保留captions.append((current_line.strip(), time.time()))except Exception as e:logger.error(f"API调用错误: {e}")return None# ========== 中文字体 ==========
font_path = "font/AlimamaDaoLiTi-Regular.ttf" # MacOS 示例
font = ImageFont.truetype(font_path, 28)# ========== 加载 YOLO 模型 ==========
model = YOLO("/Users/lianying/Desktop/yolo/yolov8n.pt") # 可换为 yolov8n.pt/yolov8s.pt 等# ========== 摄像头 ==========
cap = cv2.VideoCapture(0)while True:ret, frame = cap.read()if not ret:break# YOLOv8 实时检测results = model(frame, verbose=False)[0]annotated_frame = results.plot() # 获取带标注的帧# 叠加 DeepSeek 返回的字幕(如果有)frame_pil = Image.fromarray(cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(frame_pil)# 绘制字幕(只显示近3秒的)now = time.time()frame_pil = Image.fromarray(cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(frame_pil)y_offset = 30for caption, ts in list(captions):if now - ts <= 3:draw.rectangle([20, y_offset - 10, 1200, y_offset + 35], fill=(0, 0, 0, 128))draw.text((30, y_offset), caption, font=font, fill="yellow")print(caption)y_offset += 50else:captions.popleft() # 删除过期字幕# if current_caption:# print(current_caption)# draw.text((30, 30), current_caption, font=font, fill="yellow")frame_final = cv2.cvtColor(np.array(frame_pil), cv2.COLOR_RGB2BGR)cv2.imshow("YOLOv8 实时检测 + 图像描述(按空格)", frame_final)key = cv2.waitKey(1)if key == 27: # ESC 退出breakelif key == 32: # 空格触发print("正在发送当前帧给 DeepSeek,请稍等...")# 异步处理图像上传与字幕生成def async_caption():_, buffer = cv2.imencode(".jpg", frame)base64_str = base64.b64encode(buffer).decode('utf-8')img2text(base64_str) # 你之前写的函数threading.Thread(target=async_caption, daemon=True).start()# elif key == 32: # 空格触发# print("正在发送当前帧给 DeepSeek,请稍等...")# _, buffer = cv2.imencode(".jpg", frame)# image_bytes = BytesIO(buffer.tobytes())# base64_str = base64.b64encode(buffer).decode('utf-8')# print("Base64 (PNG):", base64_str[:50] + "...")# img2text(base64_str)cap.release()
cv2.destroyAllWindows()
✅ 效果图:
展示部分截图,其他不方便展示
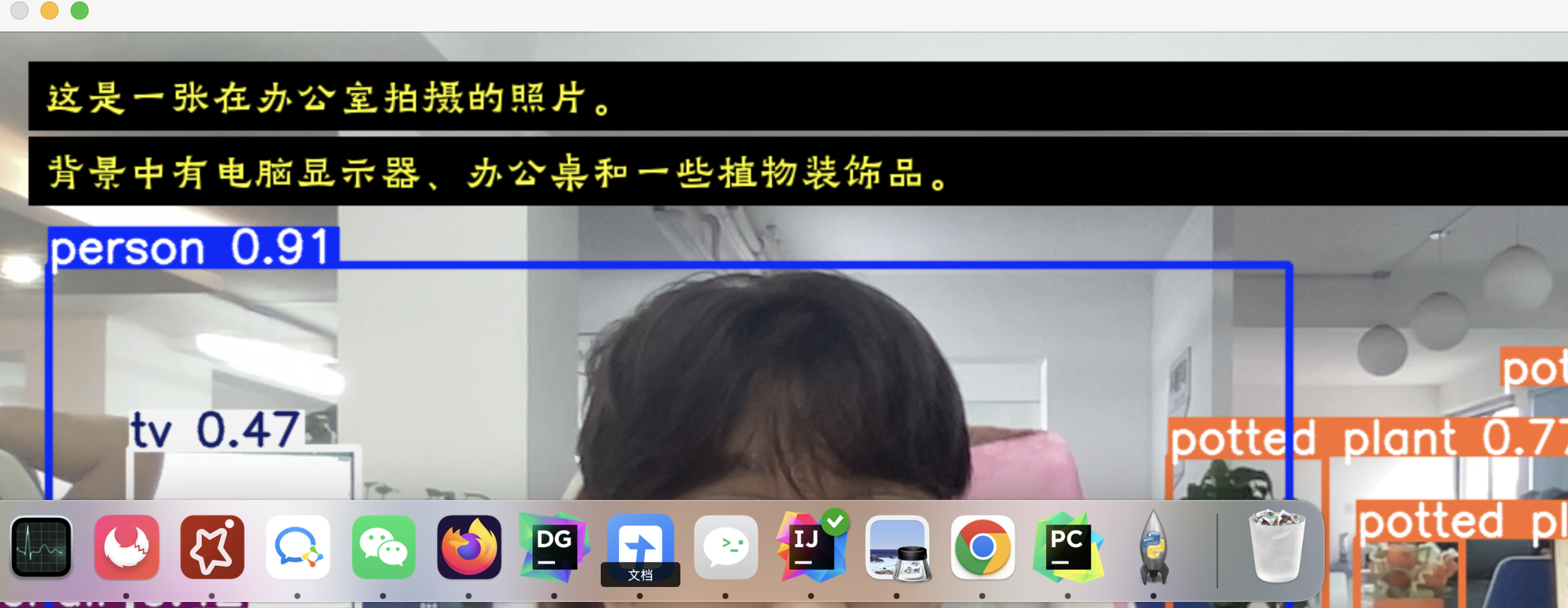
视频:
yolo8实现小艺看世界