【第四章:大模型(LLM)】01.神经网络中的 NLP-(3)文本情感分类实战
第四章:大模型(LLM)
第二部分:神经网络中的 NLP
第三节:文本情感分类实战
本节将结合理论与实践,全面讲解文本情感分类的实现流程,包括数据准备、模型选择、训练与评估。
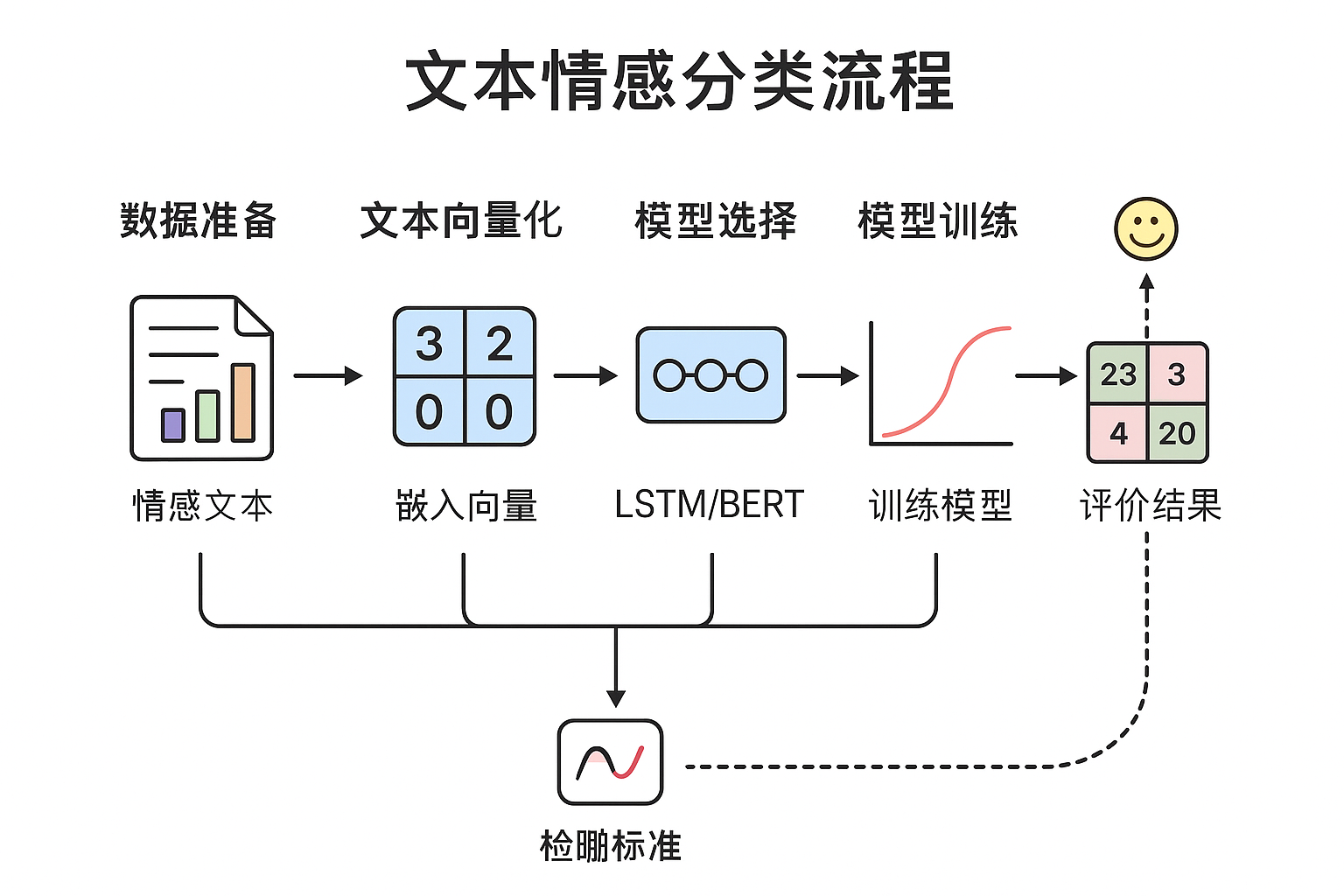
1. 文本情感分类简介
文本情感分类是一种常见的自然语言处理(NLP)任务,旨在自动判断一段文本所表达的情绪倾向(如正面、负面、中性)。该任务广泛应用于社交媒体分析、客户反馈、产品评论等领域。
2. 主要技术流程
(1)数据准备
数据集:常用 IMDB、SST-2、中文情感数据集(如ChnSentiCorp)
文本预处理:包括分词、去停用词、文本向量化(Tokenizer、Embedding)
(2)特征表示
传统方法:TF-IDF + 逻辑回归/朴素贝叶斯
深度学习方法:Word2Vec/Glove + RNN/LSTM/GRU
预训练模型方法:BERT、RoBERTa、ERNIE 等
3. 模型选择
| 模型 | 特点 | 优势 | 劣势 |
|---|---|---|---|
| RNN/LSTM | 能捕捉上下文依赖 | 适合长文本 | 训练耗时,梯度消失 |
| CNN | 局部特征提取 | 高效,速度快 | 缺乏长依赖 |
| Transformer/BERT | 全局上下文 | 高精度、强泛化 | 需要较多算力 |
4. PyTorch 实战示例(LSTM 版本)
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import IMDB
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator# 1. 数据加载与预处理
tokenizer = get_tokenizer("basic_english")
train_iter, test_iter = IMDB()def yield_tokens(data_iter):for label, line in data_iter:yield tokenizer(line)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])def text_pipeline(x): return vocab(tokenizer(x))# 2. LSTM 模型
class SentimentLSTM(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):super().__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, text):embedded = self.embedding(text)_, (hidden, _) = self.lstm(embedded)return self.fc(hidden[-1])model = SentimentLSTM(len(vocab), 100, 128, 2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)# 3. 训练流程(简化版)
for epoch in range(3):for label, line in train_iter:text = torch.tensor([text_pipeline(line)])target = torch.tensor([1 if label == 'pos' else 0])optimizer.zero_grad()pred = model(text)loss = criterion(pred, target)loss.backward()optimizer.step()print("训练完成!")
5. 模型评估
准确率、F1-score、混淆矩阵
可视化损失曲线与准确率曲线
在测试集上预测情感类别并评估模型泛化能力
6. 扩展:使用 BERT 提升效果
在实际应用中,可以直接使用 HuggingFace Transformers 库加载 bert-base-chinese 进行 fine-tuning,大幅提升准确率。
7. 总结
本节介绍了文本情感分类的核心流程和 PyTorch 实现方法。深度学习和预训练语言模型的应用,使情感分类精度显著提高。在实际业务中,可结合 BERT 或大模型(LLM)进行微调以获得最佳效果。