系统改造:一次系统领域拆分的实战复盘
引言
在互联网的浪潮中,每一个成功的产品背后都有着不为人知的技术挑战。当业务量从千级跃升到百万级,当用户从几百人暴增到几十万人,原本运行良好的系统突然变得不堪重负。这时候,架构师面临的不仅仅是技术问题,更是对业务理解深度和技术前瞻性的终极考验。
今天,我想跟大家分享一个真实的故事——一个关于系统拆分重构的故事!
当系统开始"呼救"
故事要从一个朋友的求助电话开始。那是一个周五的晚上,电话里传来他焦急的声音:"系统快撑不住了,能帮忙看看吗?"
他们公司是某行业知名电商的供货商,业务模式比较特殊。不像传统电商那样简单的买卖关系,他们的供应链很长,涉及多级供货商、多个工厂,还要协调各种材料商的生产排期。为了提高协调效率,他们在原有的订单系统基础上增加了排期协商功能。
刚开始一切都很顺利,但随着业务量的激增,问题开始暴露。订单数据在一年内增长到了一亿多条,系统响应越来越慢,到后来连基本的查询都要等几十秒。更要命的是,由于合作周期长、包含售后环节,这些数据根本无法按时间归档。
当我深入了解后发现,这不是简单的数据量问题,而是系统设计出现了根本性偏移。
深入业务流程,寻找问题根源
面对这样的问题,朋友的反应是对系统进行分库分表,但我觉得这是治标不治本。系统慢的根本原因在于设计的不合理,而不是数据量本身。
让我先给大家看看他们的业务流程图:
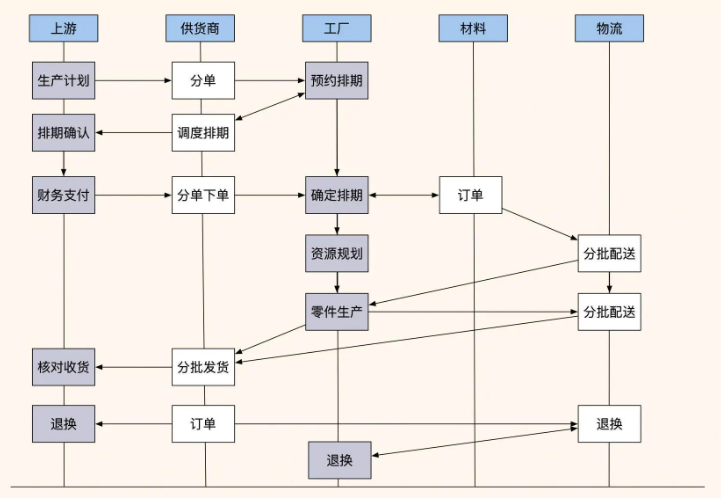
这个流程图很清楚地展示了他们的业务复杂性。上游项目先发布生产计划,供货商根据计划拆分采购列表,联系不同工厂协调预排期,然后是质量审核、下单支付、确认排期,工厂制定采购材料计划,分批生产制造,最后是验收和退换。
通过深入分析这个业务流程,我发现了一个关键问题:系统的核心已经从原来的"订单驱动"转变为"排期驱动",但技术架构却没有跟上这个变化。
原来的系统是围绕订单设计的,通过自动匹配实现上下游分单。但加入排期功能后,整个业务流程变了:现在是先有排期协商,再根据排期生成订单。可架构还是以订单为中心,这就导致了一个尴尬的局面——主订单承担了排期、生产、物流、财务等一大堆职责,变成了一个"超级胖子"。
解构现有系统架构
为了更好地理解问题,我绘制了当前系统的架构图:
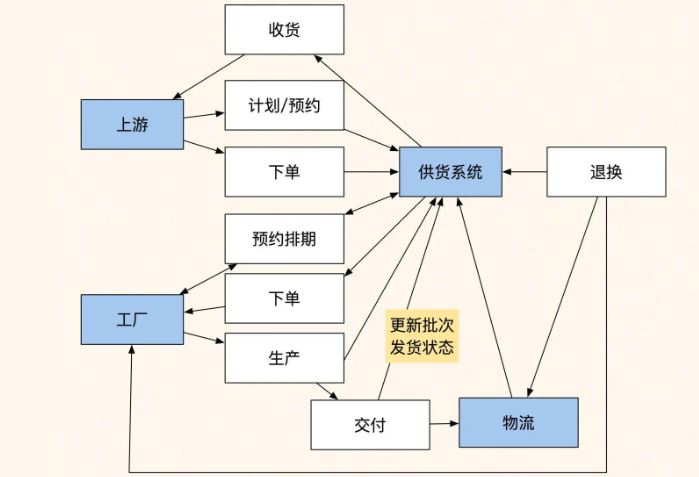
从这张图可以清楚地看到,多个角色都在使用这个"订单排期系统",但订单表承载的职能过多,导致多个流程依赖订单表无法做数据维护。订单存在多个和订单业务无关的状态,比如排期周期很长,导致订单一直不能关闭。
这种设计带来了三个严重问题:
性能问题:单表数据量过大,查询效率急剧下降。一个订单表要承担排期、生产、物流、财务等多重职责,每次查询都要处理大量不相关的数据。
维护性问题:一个实体承担多重职责,任何一个环节的变更都可能影响全局。比如修改排期逻辑可能会影响到订单处理,修改物流状态可能会影响到财务对账。
扩展性问题:新业务接入困难,开发效率低下。每次要增加新功能,都要考虑对现有复杂订单模型的影响。
重新定义系统边界
经过仔细分析,我按照用户角色重新梳理了整个业务流程:
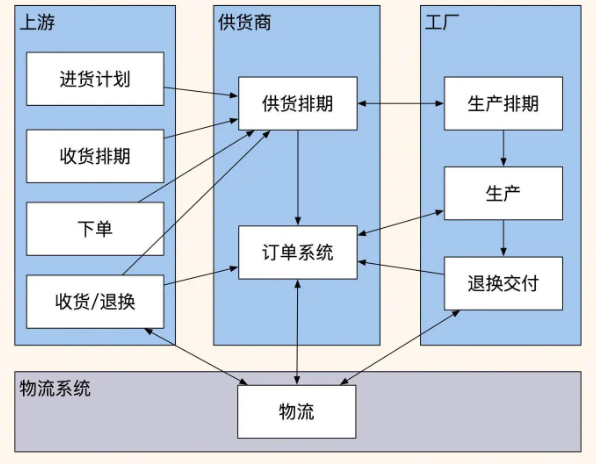
这张图按角色及其所需动作画出多个框,将他们需要做的动作和数据流穿插起来,让我们更清楚地看到了各个角色的职责:
上游采购方主要关注计划发布和收货验收,他们的核心动作是发布进货计划、收货排期、下单、收货/退换。
供货商负责协调排期和订单服务,主要做的是排期分单、协调工厂、提供订单相关服务。
工厂则专注于生产排期和产品制造,负责生产排期、产品制造、售后服务。
通过这样的梳理,我们发现整个流程可以明确分为三个阶段:
第一阶段是计划排期协调阶段,这个阶段不涉及订单,主要是上游和多个工厂的排期协商。
第二阶段是生产供货交付阶段,基于确认排期生成订单,执行生产和物流。
第三阶段是售后服务调换阶段,处理订单完成后的服务和问题。
系统拆分方案设计
基于这个发现,我设计了新的系统架构:
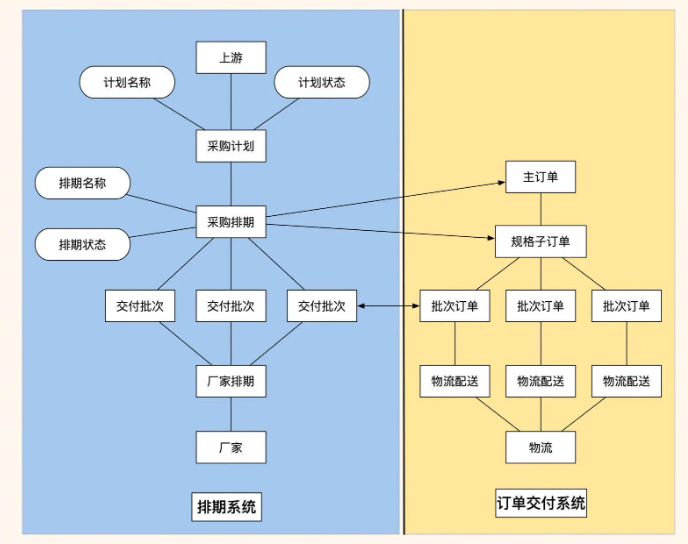
我们决定将系统拆分为两个子系统:排期调度系统和订单交付系统。
排期调度系统专门处理第一阶段的工作。上游在这里提交进货计划和收货排期,供货商与工厂协商分单和议价,多方达成一致后进行排期预占。这个系统的核心是"协商"和"调度",不涉及具体的交易行为。
核心功能包括进货计划管理、排期协商调度、产能预约管理、排期状态跟踪。数据模型包括schedule_plan(排期计划表)、capacity_booking(产能预约表)、supplier_coordination(供货商协调表)、schedule_status(排期状态表)。
订单交付系统则处理后两个阶段的工作。当排期确认后,系统会自动在订单系统中生成对应的订单,工厂根据排期进行生产,分批次发货,处理售后等等。这个系统的核心是"执行"和"交付"。
核心功能包括订单生命周期管理、生产执行跟踪、物流配送管理、财务对账结算。数据模型包括delivery_order(交付订单表)、production_batch(生产批次表)、logistics_tracking(物流跟踪表)、financial_settlement(财务结算表)。
两个系统通过排期ID和批次号进行关联,使用异步消息机制处理跨系统交互,并且有统一的主数据管理服务。
代码架构的重构过程
让我展示一下拆分前后的代码结构对比:
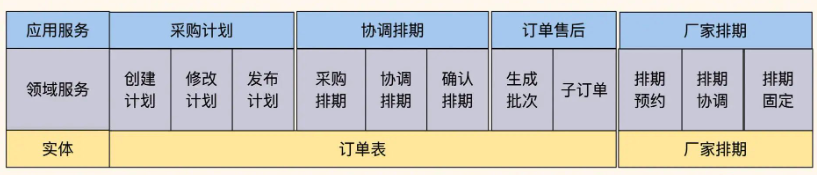
这是拆分前的代码结构。可以看到,单一订单服务承载过多职责,业务逻辑高度耦合,数据访问层职责不清晰。
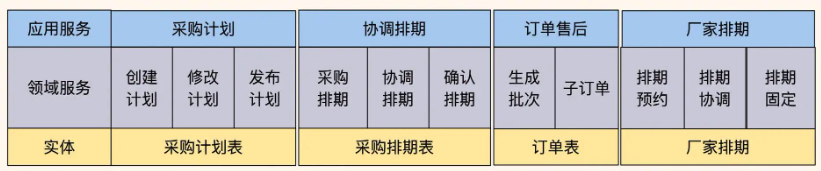
这是拆分后的代码结构。各系统职责边界清晰,减少了跨角色的实体调用,大大提高了系统的可维护性。
在具体实现上,我们采用了领域驱动设计的思想,为每个系统定义了清晰的聚合根和业务边界。
排期调度系统的核心实体是SchedulePlan(排期计划),负责管理整个排期的生命周期:
@Entity
publicclassSchedulePlan {private String scheduleId;private String demandId;private ScheduleStatus status;private LocalDateTime planStartTime;publicvoidconfirmSchedule(List<FactoryCapacity> capacities) {validateCapacities(capacities);this.status = ScheduleStatus.CONFIRMED;publishScheduleConfirmedEvent();}
}当排期确认后,系统会发布一个领域事件,订单交付系统监听这个事件,自动创建对应的订单:
@EventHandler
public void handleScheduleConfirmed(ScheduleConfirmedEvent event) {DeliveryOrder order = createDeliveryOrder(event);ProductionPlan plan = generateProductionPlan(event);order.startProduction(plan);
}这种事件驱动的架构既保证了数据的一致性,又实现了系统间的解耦。即使其中一个系统出现问题,也不会影响到另一个系统的正常运行。
拆分决策的科学方法
在拆分过程中,我们遵循了明确的拆分原则:
单一职责原则:每个数据实体只负责一个核心业务领域。订单实体只管理订单的完整生命周期,排期实体只负责排期协商和调度,避免实体承担多重、交叉的业务职责。
业务流程内聚原则:按业务流程的自然边界进行拆分。协调排期流程归到排期调度系统,生产执行流程和售后服务流程归到订单交付系统。
数据依赖解耦原则:最小化跨系统的数据依赖,减少频繁的JOIN操作,避免紧耦合的数据调用,每个系统维护完整的业务数据。
服务抽象的三重境界
在系统拆分的过程中,我们还遇到了一个重要问题:如何对底层服务进行合理的抽象?经过多年的实践,我总结出了服务抽象的三种境界。
第一种是被动抽象法,适合创业初期的团队。当发现多个服务使用相同的业务逻辑时,就将其抽象成公共服务。这种方式简单直接,但抽象程度不高,随着业务的发展可能需要大规模重构。
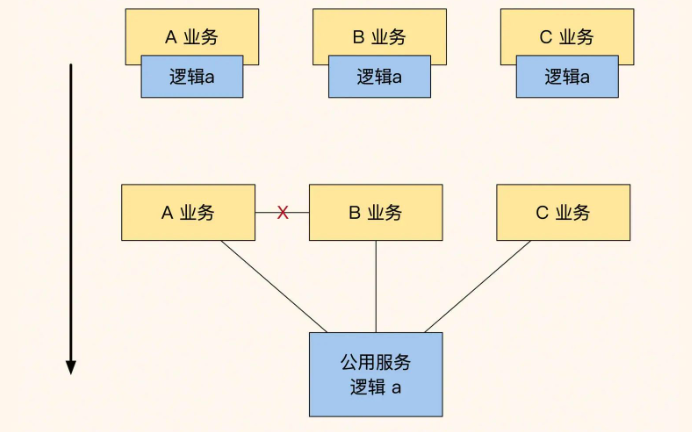
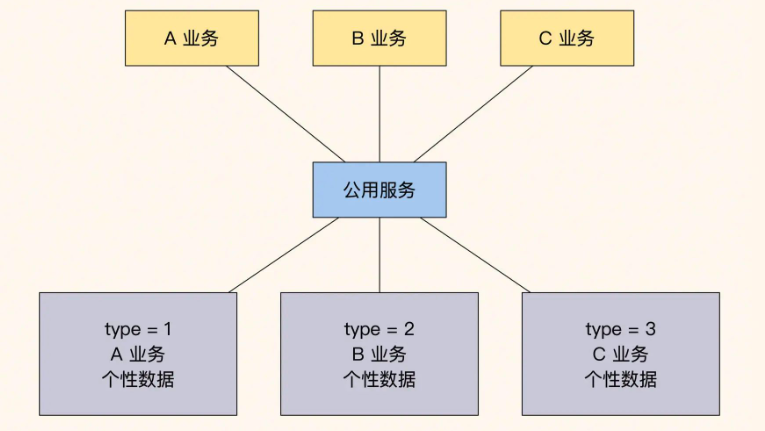
第二种是动态辅助表方式,适合业务相对稳定的中型团队。它的具体实现是这样的:当订单系统被几个开发小组共同使用,而不同业务创建的主订单有不同的type,不同的type会将业务特性数据存储在不同的辅助表内,比如普通商品保存在表order和表order_product_extra中,定制类商品的定制流程状态保存在order_customize_extra中。
动态辅助表可以让实体保持稳定,不同业务的特性数据存储在不同的辅助表中。这种方式在查询便利性和业务灵活性之间取得了平衡,但各业务之间的隔离性较差。
第三种是强制标准接口方式,适合大型企业的核心系统。底层服务只提供标准功能,业务的个性化部分完全由上层实现。这种方式的抽象程度最高,底层服务极其稳定,但对上层业务的技术要求也更高。
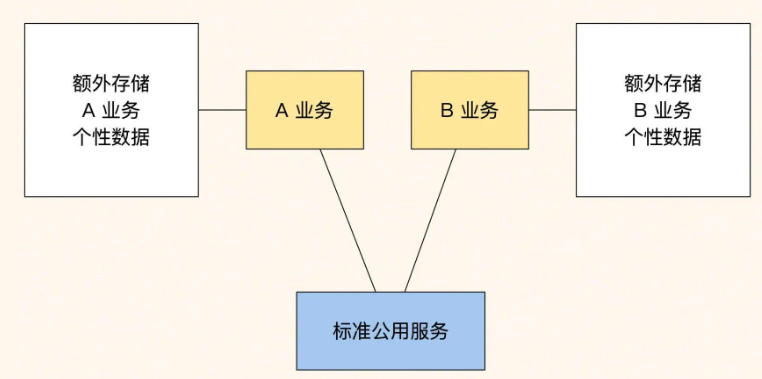
在我们这个项目中,考虑到团队规模和业务特点,我们选择了第二种方式。既保证了核心订单逻辑的稳定性,又为不同类型的业务保留了足够的灵活性。
改造效果令人惊喜
经过三个月的努力,新系统终于上线了。效果超出了预期:
性能大幅提升:系统响应时间从原来的几十秒降低到了秒级,数据库查询效率提升了90%,系统的整体吞吐量增加了5倍。
可维护性明显改善:各个模块职责清晰,开发团队可以并行工作,互不干扰。新功能的开发时间从原来的几周缩短到几天。
扩展性得到保障:新的架构为后续的业务发展奠定了坚实的基础,可以灵活应对各种业务变化。
但这个项目给我最大的启发不是技术本身,而是对业务的深度理解。很多时候,我们遇到的所谓"技术问题",实际上都是业务问题在技术层面的体现。如果不能深入理解业务的本质,仅仅从技术角度出发,往往只能治标不治本。
系统拆分的方法论总结
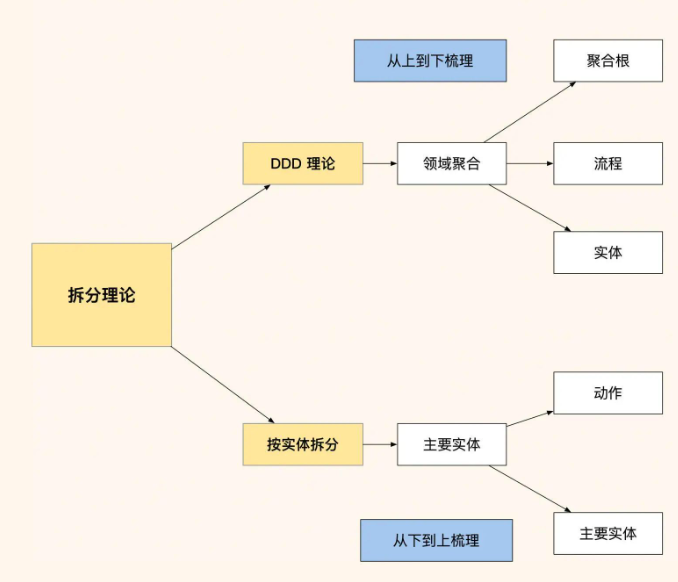
回头来看,这次改造的成功在于我们遵循了正确的方法论,我将其总结为"三步拆分法":
第一步:自上而下看流程。我们深入分析了业务流程,识别了关键的业务阶段,确定了流程边界和依赖关系。这为后续的系统拆分提供了清晰的指导。
第二步:自下而上看模块。我们分析了数据实体的职责,识别了数据依赖关系,确定了模块拆分的边界。这确保了拆分后的模块具有良好的内聚性和松耦合性。
第三步:综合考虑做决策。我们平衡了流程完整性和模块独立性,考虑了团队组织结构,评估了技术实现的复杂度。这保证了方案的可行性和可维护性。
写在最后的思考
技术的发展日新月异,但架构设计的核心原则却是相对稳定的。无论是微服务、云原生,还是未来可能出现的新技术,都离不开对业务的深度理解和对系统边界的准确划分。
在这个快速变化的时代,我们既要保持对新技术的敏感度,也要坚持对基础原则的坚守。记住一句话:没有银弹,只有最合适的解决方案。每一次架构调整都是对业务理解的深化,也是技术能力的提升。
另一个重要的感悟是,系统架构不是一成不变的。随着业务的发展和市场的变化,原有的设计可能会逐渐偏离初衷。这就需要我们定期回顾和反思,及时调整架构,让技术更好地服务于业务。