门控激活函数:GLU/GTU/Swish/HSwish/Mish/SwiGLU
10 门控激活函数
10.1 GLU:门控线性单元函数Gated Linear Unit
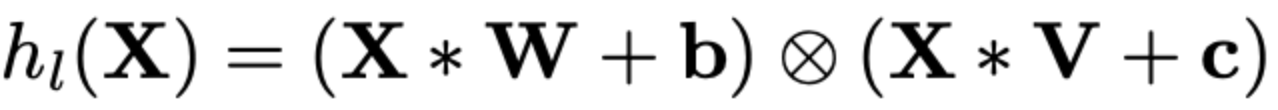
10.2 GTU:门控Tanh单元函数Gated Tanh Unit
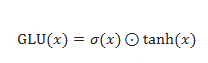
自门控激活函数(Self-gated activation function)
是一种通过自身机制动态调节信息流动的激活函数,其核心在于模型能够根据输入数据自身的特征自动调整信息传递的强度,无需外部控制信号。
核心特点
- 动态调节:根据输入数据的内在属性(如数值大小、梯度变化等)自动开启或关闭信息传递,增强模型对复杂数据的处理能力。
- 非线性特性:通过非线性变换实现更复杂的特征提取,提升模型表达能力。
- 可微性:所有点均可微,便于训练过程中优化参数。
- 典型应用
在深度学习模型中(如Transformer、FFN层),自门控激活函数通过动态调整信息流动,优化长序列处理和复杂语义关系的建模能力。
- 与传统激活函数的区别
传统激活函数(如ReLU)仅对输入信号进行固定阈值处理,而自门控激活函数通过内部机制实现更精细的信息筛选,尤其在处理小数值输入时能起到正则化效果。
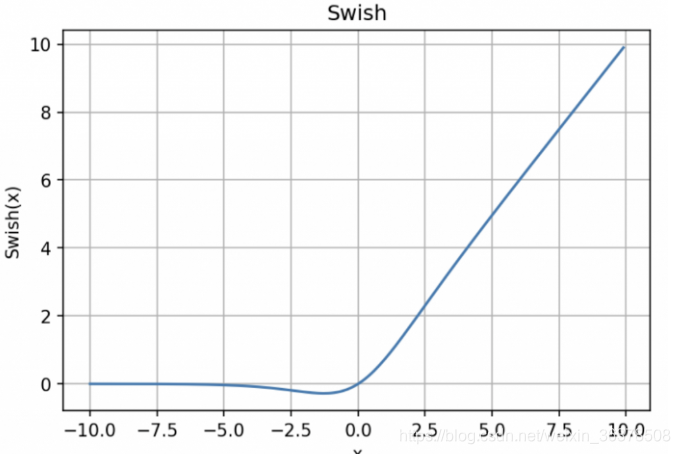
10.3 Swish:自门控激活函数
y = x * sigmoid (x)
Swish 的设计受到了 LSTM 和高速网络中 gating 的 sigmoid函数使用的启发。我们使用相同的 gating 值来简化 gating 机制,这称为 self-gating。
self-gating的优点在于它只需要简单的标量输入,而普通的 gating 则需要多个标量输入。这使得诸如 Swish 之类的 self-gated激活函数能够轻松替换以单个标量为输入的激活函数(例如 ReLU),而无需更改隐藏容量或参数数量。Swish 激活函数的主要优点如下:
「无界性」有助于防止慢速训练期间,梯度逐渐接近 0并导致饱和;(同时,有界性也是有优势的,因为有界激活函数可以具有很强的正则化,并且较大的负输入问题也能解决);
导数恒 > 0;
平滑度在优化和泛化中起了重要作用。
Swish在原点附近不是饱和的,只有负半轴远离原点区域才是饱和的,而ReLu在原点附近也有一半的空间是饱和的。而我们在训练模型时,一般采用的初始化参数是均匀初始化或者正态分布初始化,不管是哪种初始化,其均值一般都是0,也就是说,初始化的参数有一半处于ReLu的饱和区域,这使得刚开始时就有一半的参数没有利用上。特别是由于诸如BN之类的策略,输出都自动近似满足均值为0的正态分布,因此这些情况都有一半的参数位于ReLu的饱和区。相比之下,Swish好一点,因为它在负半轴也有一定的不饱和区,所以参数的利用率更大。[FROM 苏剑林 https://kexue.fm/archives/4647]
10.3.1 hswish
激活函数 h-swish是MobileNetV3相较于V2的一个创新,是在谷歌大脑2017年的论文Searching for Activation Functions中swish数的基础上改进而来,用于替换V2中的部分ReLU6。
优点: 与 swish相比 hard swish减少了计算量,具有和 swish同样的性质。
缺点: 与 relu6相比 hard swish的计算量仍然较大。
10.4 Mish:自门控激活函数
里面是softplus

Mish优点:
- 和Swish一样
- 比 ReLU慢
- Cannot 100% guarantee
- Could pair with Ranger Optimizer(2019,Hinton)
- 比Swish稳定。
- 补充:
1.无上界有下界:无上界是任何激活函数都需要的特征,因为它避免了导致训练速度急剧
下降的梯度饱和,因此加快训练过程。无下界有助于实现强I正则化效果(适当的拟合模
型)。(这个性质类似于ReLU和Swish的性质,其范围是[≈0.31,[])
2.非单调函数:这种性质有助于保持小的负值,从而稳定网络梯度流。大多数常用的激活
函数,如ReLU[f(x)=max(0,x)], Leaky ReLU[f(x)=max (0, x),1],由于其差分为0,
不能保持负值,因此大多数神经元没有得到更新。
3.无穷阶连续性和光滑性:Mish函数是光滑函数,具有较好的泛化能力和结果的有效优化
能力,可以提高结果的质量。
10.5 SwiGLU:自门控激活函数
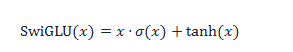
10.5.1 为什么现在的大模型要高精度跑GeLU或SwiGLU,而不是改回ReLU跑低精度?
现在大模型往往是bf16或fp8跑矩阵乘法,但是激活函数都会用fl32来确保精度。
主要原因是,常用的激活函数如GeLU和SwiGLU都很复杂,低精度掉点非常显著
GeLU和SwiGLU的优势在于它们提供了更平滑、更丰富的非线性特征表达。
根据Shazeer(2020)的研究,SwiGLU相比于ReLU在Transforme架构+下能降低约1-2%的困惑
度,这种性能差距虽然看似不大,但对动辄几十亿甚至千亿参数的LLM+而言,能带来的性能收益
非常明显。
至于的"低精度下掉点严重"的现象,确实存在。英特尔实验室在FP8+超低精度训练LLaMA+2-7B时
就发现,SwiGLU激活函数在长时间训练后会出现非常严重的数直不稳定,具体表现为训练后期loss
剧烈上升甚至训练发散。分析显示这是由于SwiGLU的门控机飞制极易放大激活输出中的少数离群
值,这在FP8这种低精度下非常致命,最终导致梯度爆炸。
但值得注意的是,在稍高一些的精度(如BF16+)下,GeLU和SwiGLU并不会表现出明显的性能下
降或者数值问题。谷歌的PaLM+、Meta的LLaMA训练时都使用BF16精度,几乎无性能损失(与
FP32相比误差在统计波动范围内)。也就是说BF16精度已经足以支撑GeLU/SwiGLU这类激活函数
的稳定训练与推理。
那么问题来了,既然ReLU在低精度上数值更稳定(毕竟只涉及简单的截断操作,没有复杂的指数或
高阶函数),为什么大家还是不用呢?我认为ReLU的劣势主要体现在两个方面:
- 第一是早期观念上的误区,认为ReLU容易出现负值梯度为零导致的"神经元死亡"(deadReLU)
现象;但实际上在Transformer这种带有LayerNorm+的架构里,ReLU死亡现象并不明显,这一点最
近已经逐渐被学术界重新证实。- 第二个因素更关键:业界刚刚开始注意到ReLU的潜在优势,比如激活值高稀疏性带来的效率提
升。大船掉头需要时间。Mirzadeh(2023)等人发现,使用ReLU激活后模型推理时可以跳过大量
的零值运算,FLOPs甚至可以减少30%~50%。他们在大模型微调实验中验证过,使用ReLU或其变
种(如ReGLU,Squared ReLU)替换原始的GeLU/SWiGLU,模型性能几乎不受影响,但推理效率
却能明显提高。这种"回归简单激活函数"的思潮,已经在低资源推理场景(如BitNet)得到了实际验证。BitNet就通
过ReLU搭配1-bit权重和8-bit激活,成功实现了Transformer模型的超低精度训练和部署,且性能与
标准FP16模型几乎持平。
所以综合来看,目前大模型仍广泛使用GeLU/SwiGLU激活函数更多是历史延续及微小性能增益的综
合结果,BF16精度足够支撑它们的正常表现。只有在追求极致低精度部署(如FP8或更低)或更极
端的效率优化场景下,ReLU才开始重新受到关注。