基于KMeans、AgglomerativeClustering、DBSCAN、PCA的聚类分析的区域经济差异研究
文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 项目技术介绍:
- 一、技术架构与工具选择
- 二、数据预处理与清洗策略
- 三、多维数据可视化分析(共14类图形)
- (1)时间维度分析
- (2)空间维度分析
- (3)结构与分布分析
- 四、聚类建模分析
- (1)预处理与降维
- (2)聚类模型比较与优化
- A. **KMeans聚类**
- B. **层次聚类(Agglomerative Clustering)**
- C. **DBSCAN 密度聚类**
- 五、分析结论与模型成果
- 六、成果输出与延展建议
- 七、结语
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目技术介绍:
本项目以“区域经济发展不平衡”为核心议题,充分利用 Python 数据科学工具链,结合机器学习与可视化技术,系统性地从数据预处理、多维可视化分析到聚类建模,构建了一套完整的数据分析工作流程。通过定量分析与图形呈现的结合,深度揭示了不同区域经济结构与发展模式的异同,为后续政策制定与区域调控提供了有力的技术支撑。
一、技术架构与工具选择
项目基于 Python 语言开发,主要采用以下技术栈:
- 数据处理与分析:
pandas、numpy、scikit-learn - 可视化分析:
matplotlib、seaborn、pyecharts - 机器学习与聚类建模:
KMeans、AgglomerativeClustering、DBSCAN、PCA - 网页输出与交互图形:使用
pyecharts输出地图与雷达图,生成交互式 HTML 页面
二、数据预处理与清洗策略
- 从
data.xlsx中加载区域年度数据,数据结构包含“时间”、“地区”及若干经济指标(如地区生产总值、各产业增加值、人均GDP等)。 - 删除缺失值较多的列(最后3列),确保后续模型训练的稳定性。
- 统一时间格式、区域名称,并保留核心数值字段以支持横向和纵向比较。
三、多维数据可视化分析(共14类图形)
数据可视化是本项目的重要组成部分,旨在从不同维度和层级对区域经济差异展开直观探索。
(1)时间维度分析
-
折线图:展示各地区“地区生产总值”随年份变化的趋势;
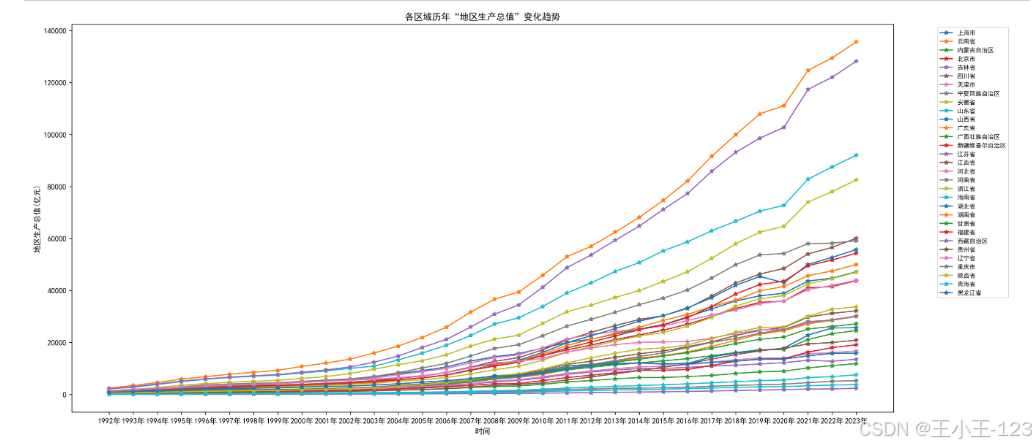
-
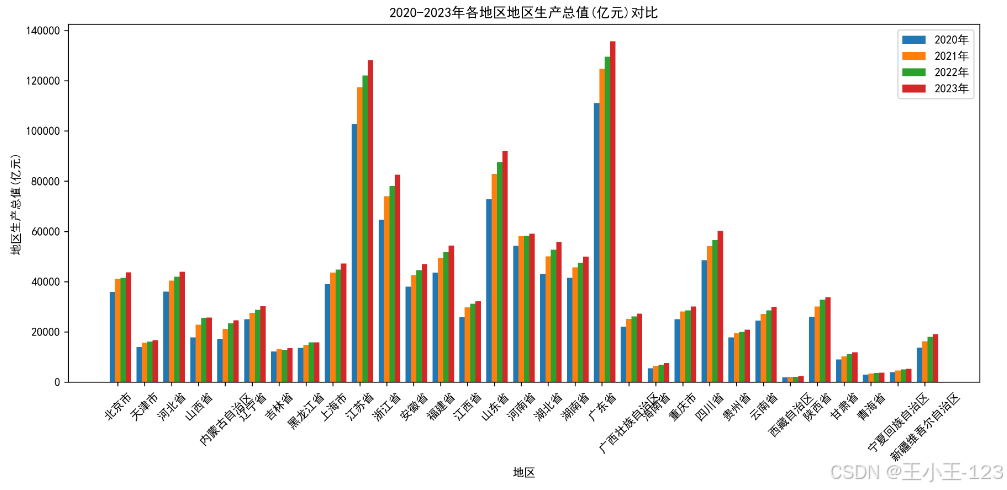
分组柱状图:对比2020–2023年各地GDP水平变化,观察增长轨迹与波动性;
-
多指标时间折线图:选定地区(如江苏省)各经济指标的历史演化过程。
(2)空间维度分析
- 中国地图(pyecharts):2023年各地区GDP空间分布;
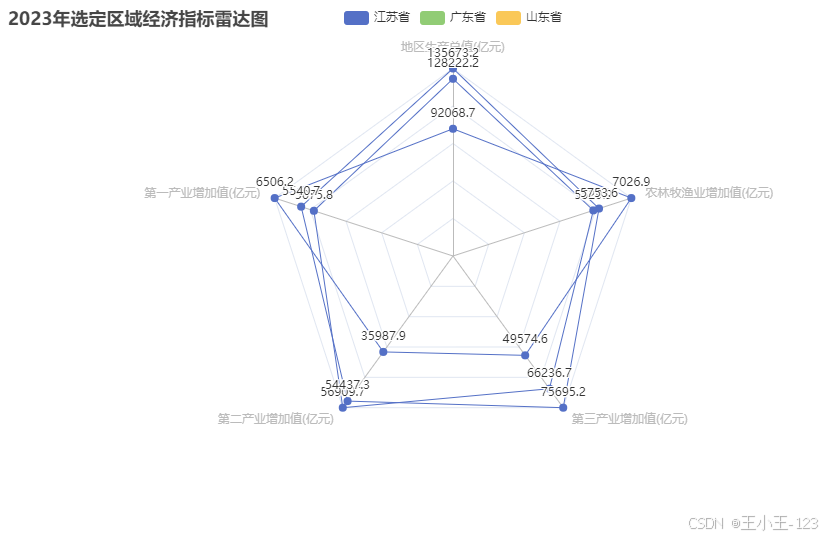
- 雷达图:江苏、广东、山东等重点区域主要经济指标构成;
- 同比增长柱状图:2023年相对2022年GDP增长率排序,直观展示增长快慢。
(3)结构与分布分析
- 饼图:单一区域(如江苏省)在2023年内各经济构成指标的占比;
- 箱线图 & 提琴图:GDP与第二产业增加值等变量在不同地区的分布与波动;
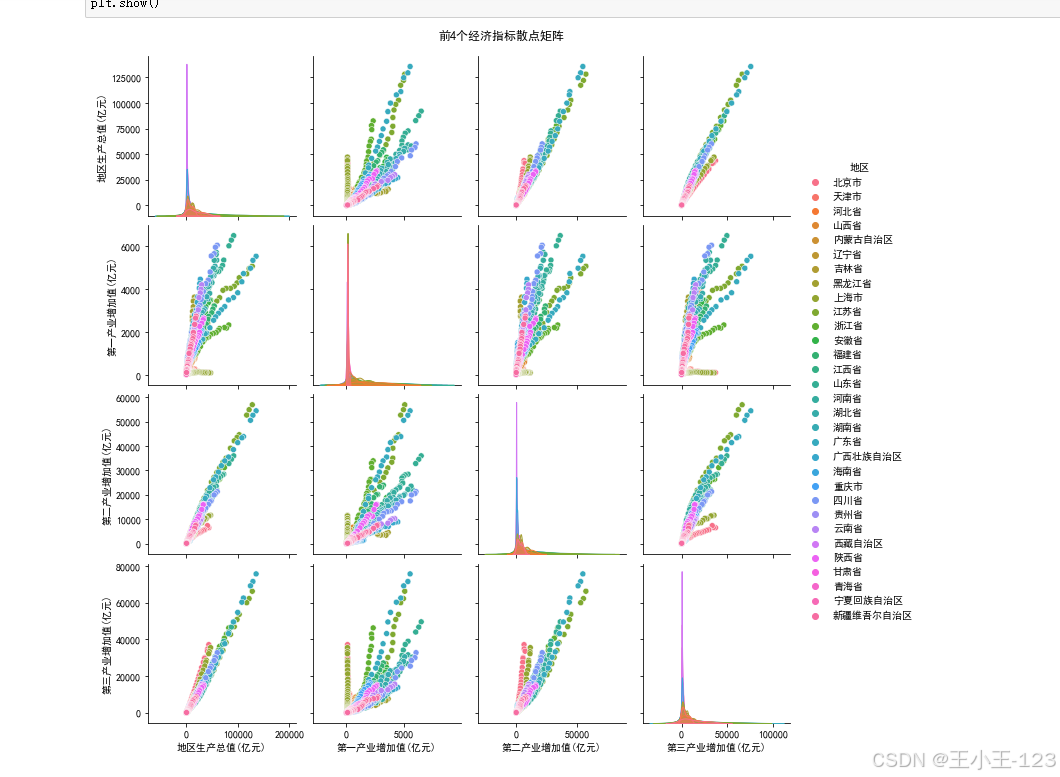
- 散点图 & 散点矩阵(pairplot):分析各指标之间的相关性及区域聚类特征;
- 热力图:变量间相关系数矩阵,识别可能存在的因果或替代关系。
四、聚类建模分析
本项目通过对2023年各地区数据标准化处理后,应用多种聚类模型识别区域经济的内在分层结构。
(1)预处理与降维
- 仅保留2023年数据;
- 去除非数值字段后进行
StandardScaler标准化; - 为可视化展示采用
PCA降维至二维空间。
(2)聚类模型比较与优化
A. KMeans聚类
- 使用肘部法(SSE折线图)与轮廓系数分析,确定最佳聚类数
K=3; - 模型效果通过主成分平面中的颜色分组与区域分布可视化呈现;
- 每个聚类代表不同经济特征群体,便于定向政策支持。
B. 层次聚类(Agglomerative Clustering)
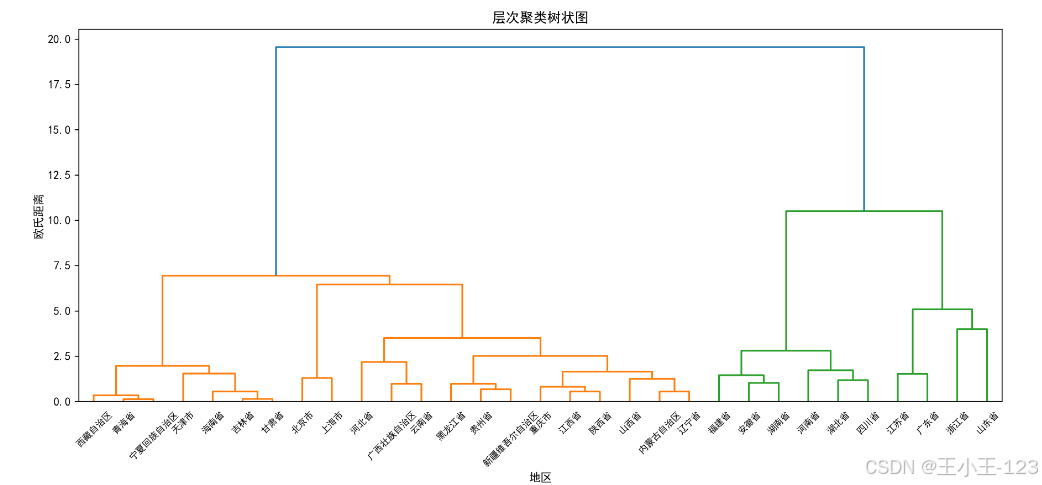
- 基于Ward法计算链接距离,构建树状图(dendrogram);
- 分群结果在PCA降维后空间中呈现出清晰聚集性,支持多尺度观察。
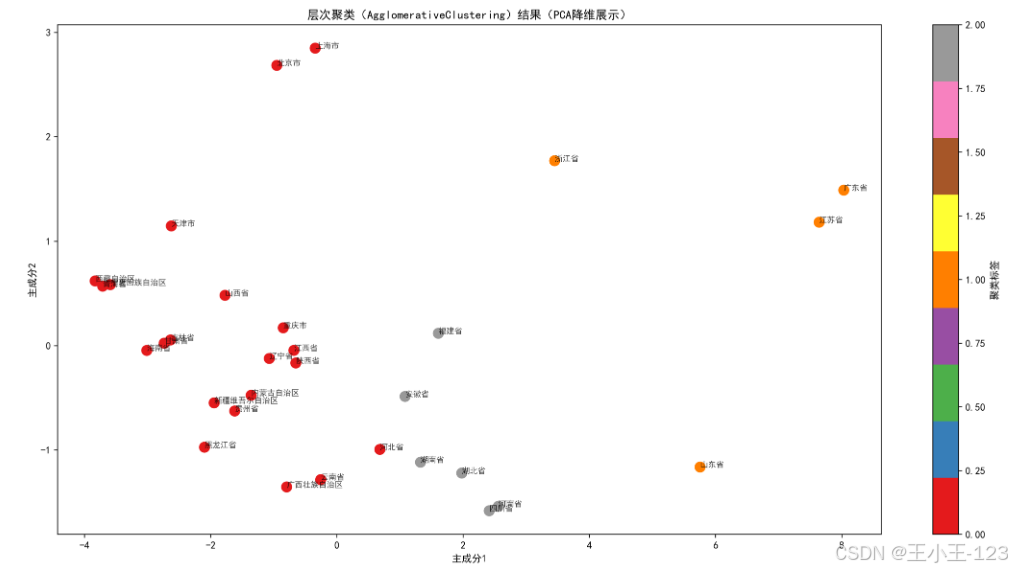
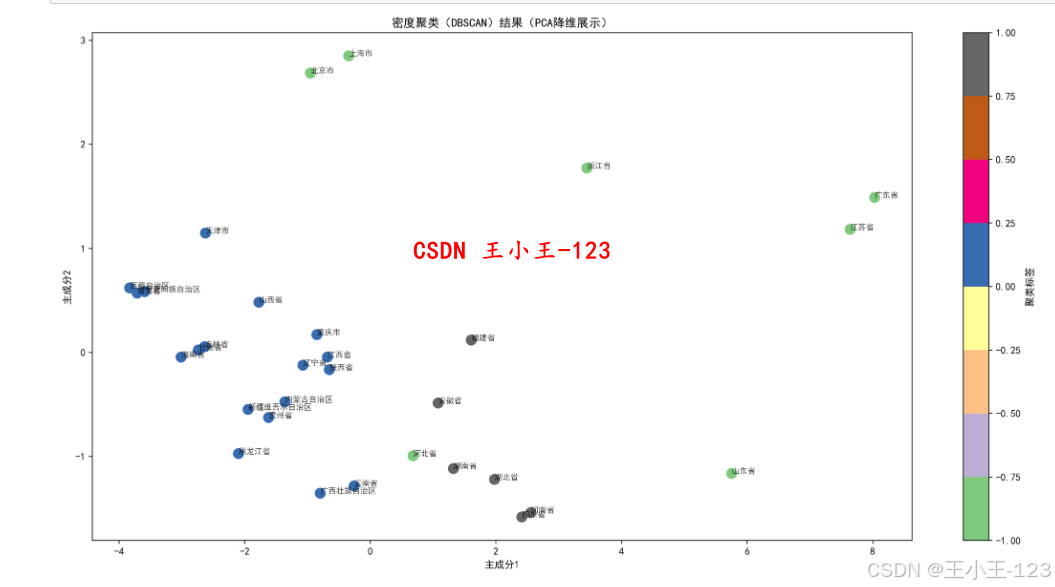
C. DBSCAN 密度聚类
- 采用
eps=1.5和min_samples=3; - 模型可识别非球状或不规则聚集现象,并有效剔除“噪声区域”;
- 适合捕捉边缘或特殊经济体(如直辖市、港澳地区)独立走势。
五、分析结论与模型成果
- 数据分析结果表明,地区间经济发展存在明确的梯度和分群现象,东部沿海地区与中西部地区在产业结构、人均GDP、发展趋势上存在系统性差异;
- 可视化展示结果将定量信息以多维图像形式直观呈现,增强了数据可解释性和政策沟通能力;
- 聚类分析成果实现了对区域“类型化”的初步划分,为后续“区域画像”与“定制化发展策略”提供可量化依据。

六、成果输出与延展建议
- 生成静态图表 10+ 张,交互图表(HTML)3 个,具备直接报告展示与在线可视化能力;
七、结语
本项目在数据分析方法、可视化表达和模型选择上实现了高度集成,不仅有效展示了区域经济发展的不均衡现象,也为区域治理与发展政策提供了清晰的数据依据。未来,该框架亦可迁移至如人口流动、城市群协同、产业结构演进等更广泛的研究主题,为构建“数据驱动型决策体系”提供范例支持。
本项目通过构建区域经济多维数据体系,结合Python数据分析与机器学习技术,系统开展了对我国区域经济发展不平衡问题的定量研究。首先对原始数据进行了清洗与整理,剔除缺失严重字段,确保分析质量。随后采用折线图、柱状图、地图、雷达图、热力图等多种可视化手段,从时间、空间、结构等维度全面呈现区域经济发展态势。在聚类分析部分,通过肘部法和轮廓系数确定最佳聚类数,并分别应用KMeans、层次聚类和DBSCAN三种方法对2023年数据进行分群,最终在PCA降维后进行可视化展示。结果显示,不同区域之间存在显著的经济结构与增长水平差异,聚类模型可有效识别出区域分层特征。整体上,本项目为理解区域经济不平衡的成因提供了数据支撑和方法框架,同时具备良好的可扩展性,后续可用于动态监测、政策模拟与区域发展评估等应用场景,对推动数据驱动型区域经济决策具有重要意义。
每文一语
人生有时候需要乐观面对,当时间流逝在最后的时候,一切在你的面前都是浮云