第四章:分析 Redis 性能高原因和核心字符串类型命令
一.引出单线程模型
假设现在开启了三个 redis-cli 客户端同时执行命令。
客户端 1 设置一个字符串键值对:
127.0.0.1:6379> set hello world客户端 2 对 counter 做自增操作:
127.0.0.1:6379> incr counter
客户端 3 对 counter 做自增操作:
127.0.0.1:6379> incr counter
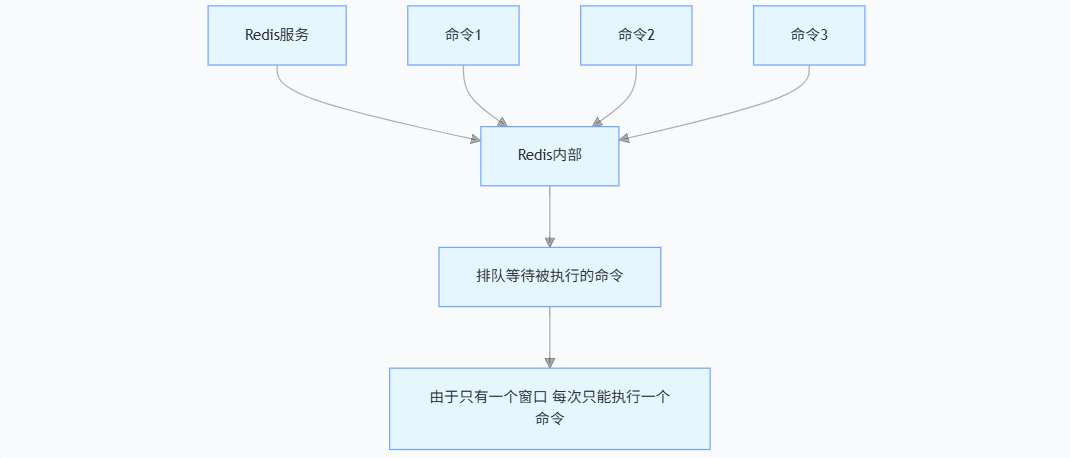
我们已经知道从客户端发送的命令经历了:发送命令、执行命令、返回结果三个阶段,其中我们重点关注第 2 步。我们所谓的 Redis 是采用单线程模型执行命令的是指:虽然三个客户端看起来是同时要求 Redis 去执行命令的,但微观角度,这些命令还是采用线性方式去执行的,只是原则上命令的执行顺序是不确定的,但一定不会有两条命令同步执行,如上 所示,可以想象 Redis 内部只有一个服务窗口,多个客户端按照它们达到的先后顺序被排队在窗口前(任务放在队列中),依次接受 Redis 的服务,所以两条 incr 命令无论执行顺序,结果一定是 2,不会发生并发问题,这个就是 Redis 的单线程执行模型。
简而言之,请求可能同时到达,但是处理请求肯定不会是同时进行(redis是单线程啊)
宏观上,3 个客户端是同时请求 Redis 服务的
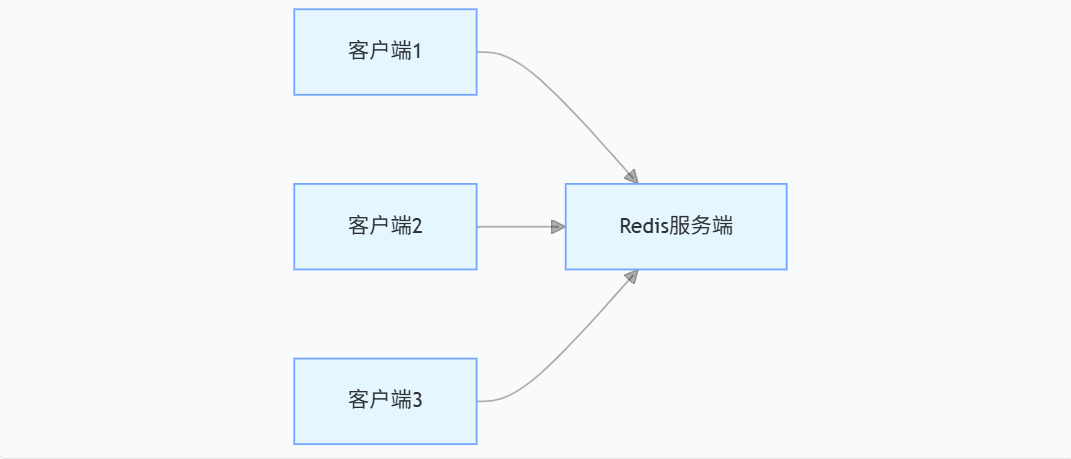 微观上,客户端是有前后次序的,虽然顺序不确定
微观上,客户端是有前后次序的,虽然顺序不确定
二.*为什么redis这么“快”,效率这么“高”
redis的“快”要看谁对比,我们一般对比的是mysql。
1.存储介质差异:Redis 访问内存,而传统数据库(如 mysql、oracle、sql server)访问硬盘。内存的读写速度远快于硬盘,这是 Redis 速度快的重要基础
举个栗子~
Redis 场景:数据存储在内存中,读取时直接通过内存地址访问,耗时约 0.1 毫秒(内存读写速度通常为 GB/s 级别)。
MySQL 场景:数据存储在硬盘文件中,读取时需要先通过机械硬盘的磁头寻址(约 10 毫秒)或固态硬盘的闪存寻址(约 0.1 毫秒),再加载数据到内存,总耗时可能达到 10-100 毫秒(硬盘读写速度通常为 MB/s 级别)。
结论:内存的物理特性(无机械延迟、电子信号传输)让 Redis 在数据访问速度上远超依赖硬盘的传统数据库。
2.功能复杂度不同:Redis 核心功能相对简单,而数据库核心功能更复杂。数据库对于数据的插入、删除、查询等操作有更复杂的功能支持,这些复杂功能需要花费更多的计算开销,例如数据库中的各种约束会使数据库做额外的工作。Redis 提供的功能相比于 mysql 等数据库少了不少,干的活少,做的事情也简单(大部分的查询操作),所以速度快。
举个栗子~
以 “插入一条用户数据” 为例:
Redis 操作:执行SET user:1 "name:张三,age:20",仅需在内存中分配空间并写入键值对,无额外校验,耗时约 1 微秒。
MySQL 操作:执行INSERT INTO user (name, age) VALUES ('张三', 20),需完成:检查字段类型是否匹配(age 必须为数字)、验证主键是否重复、更新索引树(如 B + 树)、记录事务日志(redo/undo log)等,耗时约 10-100 微秒。
结论:Redis 省略了传统数据库的约束校验、事务管理等复杂功能,操作更轻量化。
3.避免线程竞争开销:Redis 采用单线程模型,避免了不必要的线程竞争开销。Redis 的每个基本操作都很快速,只是简单操作内存,不是特别消耗 CPU 的操作,就算搞多个线程,性能提升也不大。
举个栗子~
假设有 1000 个并发请求同时读取一个热门商品的库存:
Redis 场景:单线程按顺序处理请求,每个请求直接读取内存中的库存值,无需加锁,总耗时约 10 毫秒(单线程无切换开销)。
多线程数据库场景:为了并发处理,可能启动 10 个线程,每个线程处理 100 个请求。但线程间需要通过锁(如行锁)保证数据一致性,线程切换和锁竞争会额外消耗 50 毫秒,总耗时可能达到 60 毫秒。
结论:Redis 的单线程模型避免了线程切换、锁竞争等开销,适合高频简单操作
I/O 多路复用机制:Redis 在处理网络 I/O 时,使用了 epoll 这样的 I/O 多路复用机制。一个线程就可以管理多个 socket。对于 TCP 服务来说,服务器端为每个客户端安排一个 socket,当有很多客户端时会有很多 socket,但很多情况下客户端和服务器之间的通信并不频繁,大部分 socket 处于静默状态。而 I/O 多路复用机制可以让一个线程处理多个 socket,避免了为每个客户端分配一个线程导致的系统开销增大问题。在 Linux 系统上,epoll 是效率最高的 I/O 多路复用 API(2006 年左右出现),C++ 可以直接使用 Linux 原生的 epoll api,Java 可以使用 NIO(标准库提供的一组类,底层封装了 epoll)。
举个栗子~
假设你要帮自己、同学 A 和同学 B 分别买蛋炒饭、肉夹馍和饺子,这就相当于 Redis 要处理多个客户端的请求。
传统方式的问题
方案 1(单线程串行):你一个人去买,先买蛋炒饭,等做好了再去买肉夹馍,再等做好了去买饺子。这种方式效率很低,就像 Redis 单线程串行处理每个客户端请求,一个请求处理完再处理下一个,中间等待的时间都被浪费了。
方案 2(多线程并行):你们三个人一起去买,各自买自己的。这种方式效率高,但需要多个人(多线程),系统开销大,就像传统的多线程处理方式,需要为每个客户端请求分配一个线程,资源消耗大。
epoll 的作用
还有一个方案 就是 epoll 的工作方式。你一个人去买,先去买蛋炒饭,在等蛋炒饭做好的过程中,你可以去买肉夹馍,在等肉夹馍做好的过程中,你又可以去买饺子。当其中任何一个做好了,老板会喊你(事件通知),你就去取。这样你一个人(单线程)就可以同时处理多个任务(多个客户端请求),大大提高了效率。
对应到 Redis
Redis 使用 epoll 这种 I/O 多路复用机制,就像方案 3 中的你。Redis 单线程可以同时监听多个客户端的连接和数据读写请求(就像你同时处理买三种小吃的任务)。当某个客户端有数据要读取或写入时(就像某份小吃做好了),epoll 会通知 Redis 线程,Redis 线程就会去处理这个客户端的请求,处理完后又可以继续监听其他客户端。这样 Redis 用单线程就高效地处理了大量的客户端请求,避免了多线程的开销,同时也避免了单线程串行处理的低效。
三.Redis 字符串类型核心命令
3.1SET和PX EX,NX XX的组合
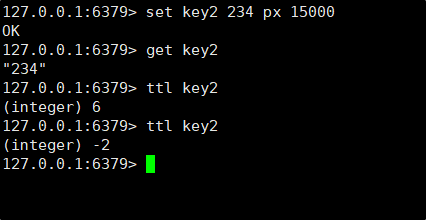
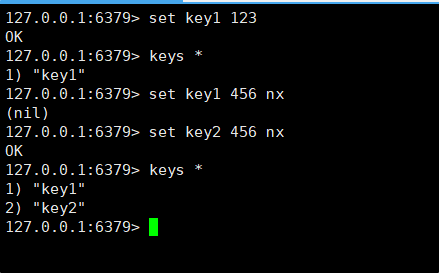
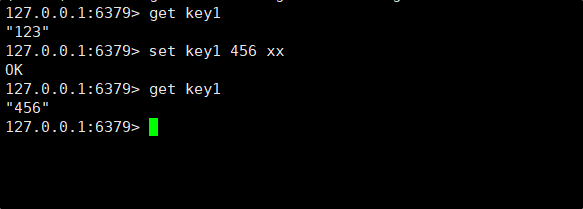
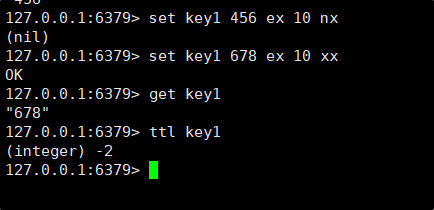
- EX seconds⸺使用秒作为单位设置 key 的过期时间。
- PX milliseconds⸺使用毫秒作为单位设置 key 的过期时间。
- NX ⸺只在 key 不存在时才进行设置,即如果 key 之前已经存在,设置不执行。
- XX ⸺只在 key 存在时才进行设置,即如果 key 之前不存在,设置不执行。
3.2Redis 的 GET ,MSET,MGET命令
对于 `GET` 来说,只支持字符串类型的 `value`。
如果 `value` 是其他类型,使用 `GET` 获取就会出错
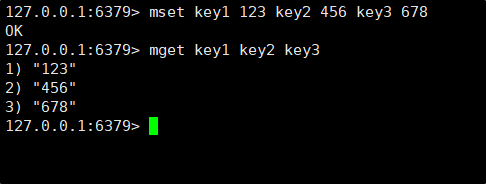
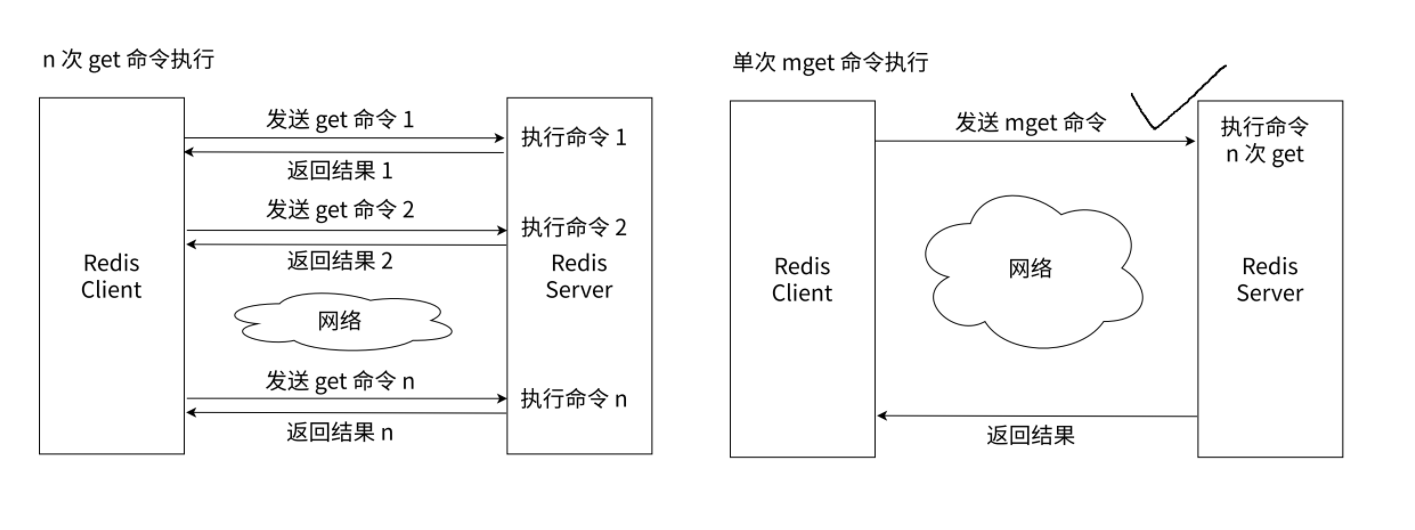
MSET 命令:一次操作多组键值对。
注意:一次设置 10w 个键值对可能会把 Redis 给阻塞住。
MGET 命令:一次获取多个键的值。
时间复杂度:O(N),N 是 `key` 数量,可以认为是 O(1)。
此处的 N 不是整个 Redis 服务器中所有 `key` 的数量,而只是当前命令中给出的 `key` 的数量。

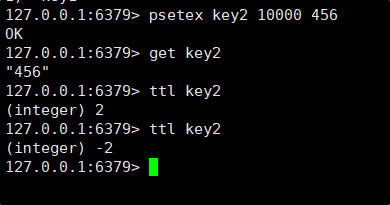
3.3SETNX,SETEX(秒),PSETEX(毫秒)
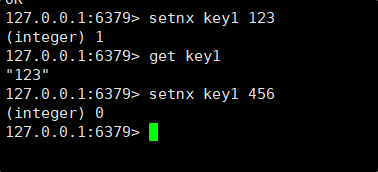
在 Redis 中,SETNX 是一个条件性设置键值对的命令,它的全称是 "SET if Not eXists",即仅当指定的键不存在时才会成功设置键值对,并返回 1;如果键已存在,则不会进行任何操作,并返回 0。
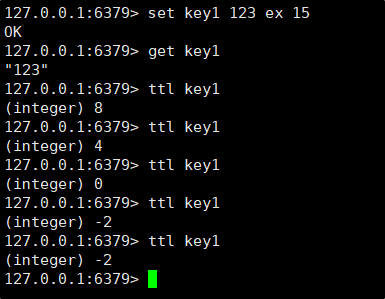
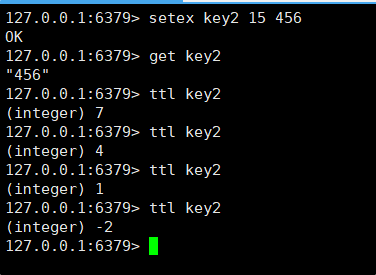
SETEX 是一个带过期时间的键值设置命令,它允许在设置键值对的同时指定一个以秒为单位的生存时间(TTL)。当过期时间到达后,Redis 会自动删除该键值对。
PSETEX 的功能与 SETEX 类似,但它的时间精度更高,支持以毫秒为单位设置键值对的生存时间。
3.4Redis 的自增自减命令
3.4.1INCR 命令
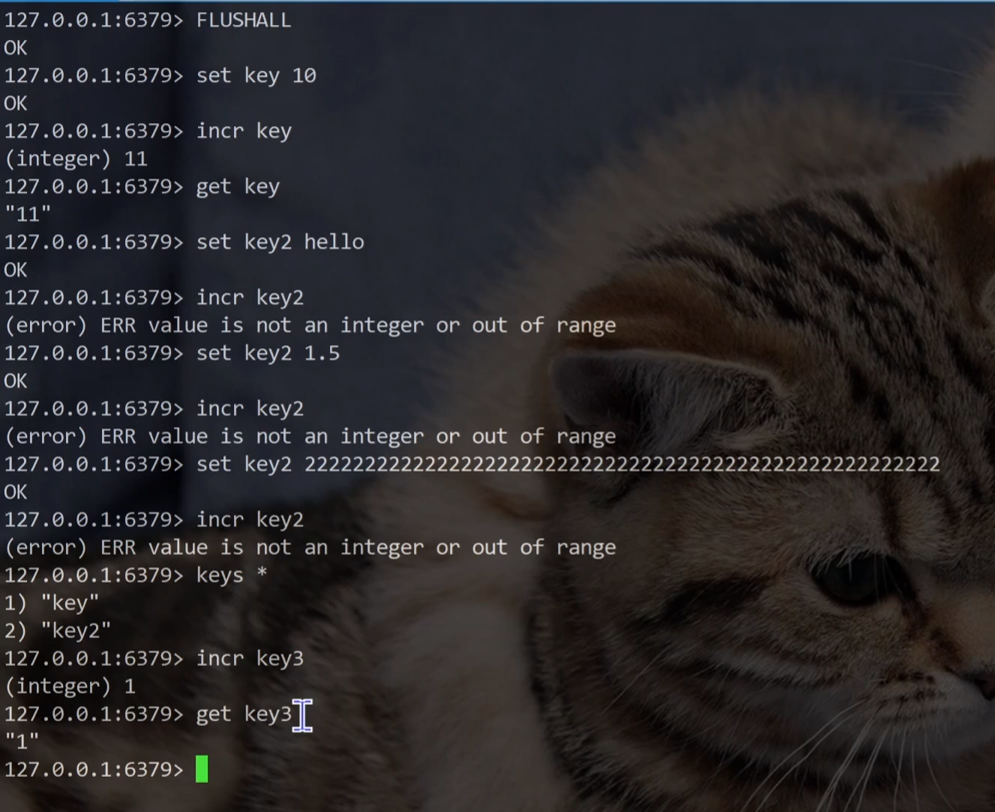
INCR 命令:针对 value + 1。
3.4.2INCRBY
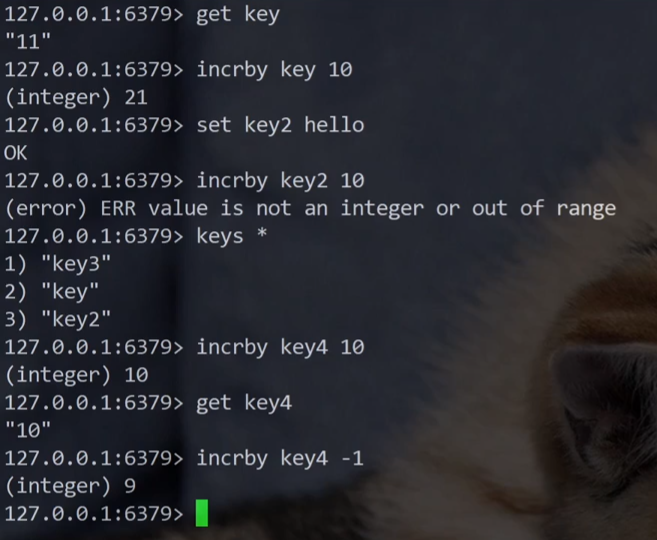
INCRBY :可以针对 key 对应的 value 进行 +n 操作。
注意:此时 key 对应的 value 必须是整数。
此操作的返回值是 +1 之后的值。
incr 操作的 key 如果不存在,就会把这个 key 的 value 当做 0 来使用。
除了非整数,超过64位的数字不能自增
3.4.3DECR
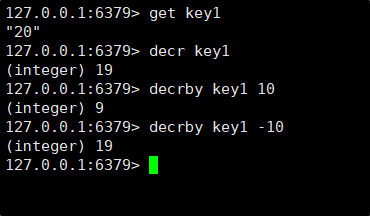
DECR:把 key 对应的 value 进行 -1 操作。
3.4.4DECRBY
DECRBY :把 key 对应的 value 进行 -n 的操作。
注意:key 对应的 value 必须是整数,在 64 位的范围内,如果这个 key 对应的 value 不存在,则当做 0 来处理。
decr 的运算结果,也是计算之后的值。
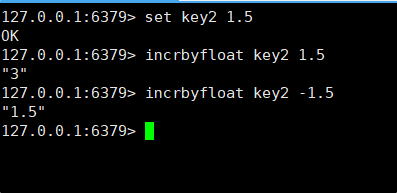
3.4.5 INCRBYFLOAT
INCRBYFLOAT :把 key 对应的 value 进行 +- 运算,运算的操作数可以是浮点数。
只能用加上负数的形式来实现减法。
时间复杂度:上述操作的时间复杂度都是 O (1)。
由于 Redis 处理命令的时候是单线程模型,多个客户端同时针对同一个 key 进行 incr 操作,不会引起 “线程安全” 问题。
3.5Redis 的字符串操作命令
3.5.1APPEND
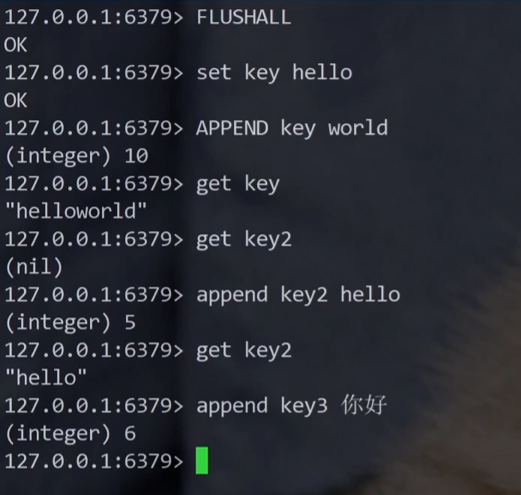
APPEND 命令:拼接字符串。
APPEND 返回值,长度的单位是字节。
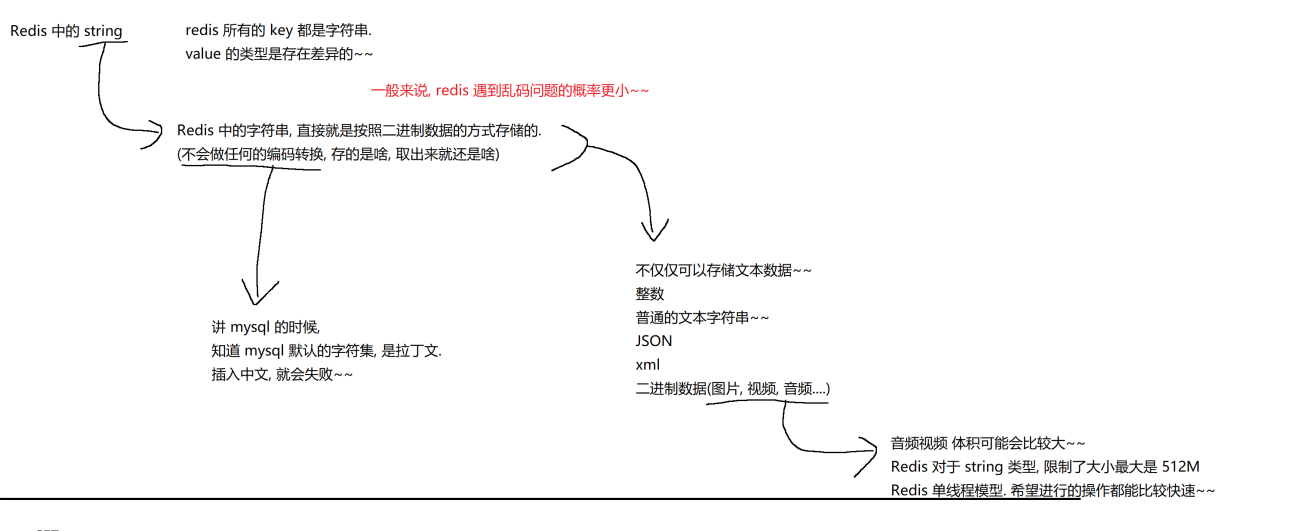
Redis 的字符串不会对字符编码做任何处理(Redis 不认识字符,只认识字节)。
当前 xshell 终端默认的字符编码是 utf8,在终端中输入汉字之后,也就是按照 utf8 编码的,一个汉字在 utf8 字符集中通常是 3 个字节。

3.5.2GETRANGE
GETRANGE 命令:获取字符串的子串,由 start 和 end 确定(左闭右闭),Redis 指定的区间是闭区间。
C++ 和 Java 中,谈到一个区间,大多都是前闭后开(左闭右开)。
正常下标都是从 0 开始的整数,Redis 的下标是可以支持负数的,-1 倒数第一个元素(下标为 len - 1 的元素),这和 Python 的设定是一致的。
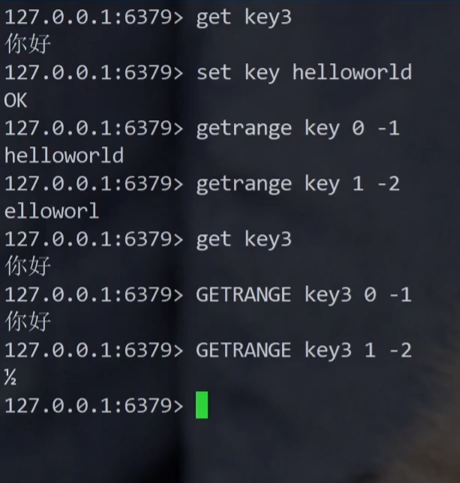
如果字符串中保存的是汉字,此时进行子串切分,很可能切出来的就不是完整的汉字了,上述代码是强行切出了中间的四个字节,随便这么一切,切出的结果在 utf8 码表上不知道能查出啥了。
上述问题在 C++ 中同样存在,Java 中就没有,因为 Java 中字符串的基本单位是字符(Java 的字符占 2 个字节),Java 中相当于 String 帮我们把汉字的编码转换都处理好了,而 C++ 中字符串的基本单位是字节,对于汉字的处理需要程序猿手动处理。
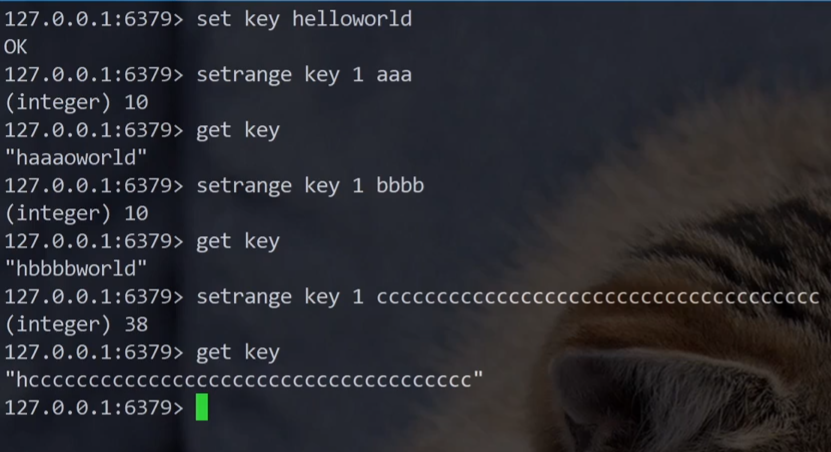
3.5.3SETRANGE
SETRANGE 命令:从指定的偏移量开始替换字符串的部分内容。
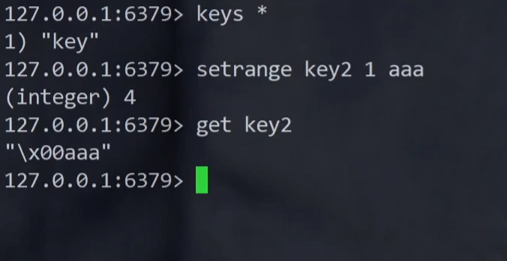
凭空生成了一个字节,这个字节里的内容就是 0x00,aaa 就被追加到 0x00 的后面了。
setrange 针对不存在的 key 也是可以操作的,不过会把 offset 之前的内容填充成 0x00。
如果当前 value 是一个中文字符串,进行 setrange 的时候,可能会出问题。
3.5.4STRLEN
STRLEN 命令功能:获取字符串的长度,单位是字节。
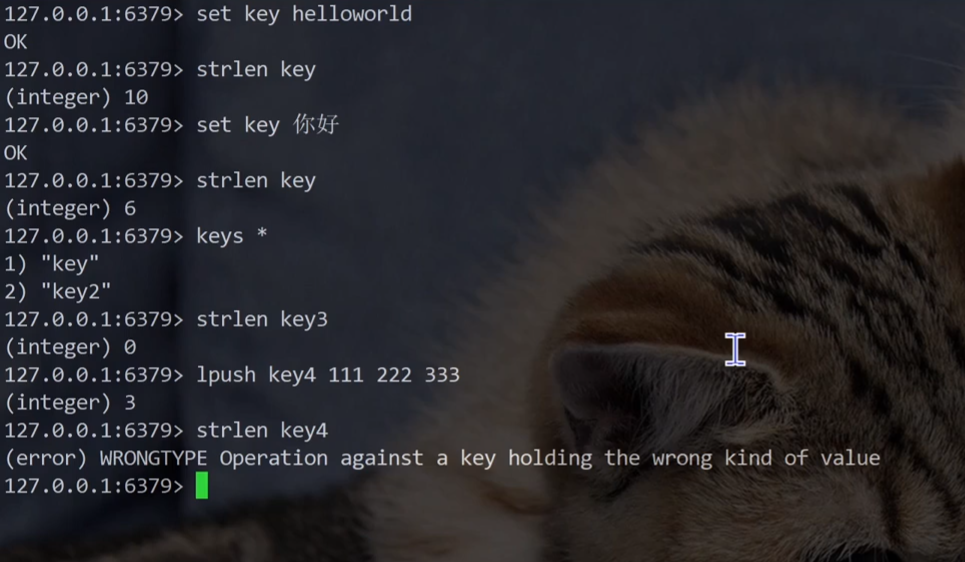
C++ 中,字符串的长度本身就是用字节为单位。
Java 中,字符串的长度则是以字符为单位的,Java 中的一个 char 等于 2 字节,Java 中的 char 基于 unicode 这样的编码方式,就能够表示中文等符号。
MySQL 的 varchar(N) 中,N 的单位是字符,MySQL 中的字符也可以是完整的汉字,这样的一个字符也可能是多个字节。
一个汉字通常是 3 个字节(编码方式是 utf8),但 Java 中一个 char 是 2 字节(使用 unicode),Java 中的 String 则是用的 utf8,一个汉字就是 3 个字节,Java 的标准库内部在进行上述操作过程中,程序一般是感知不到编码方式的变换的。
总结:
1. 多个客户端可同时向 Redis 发送命令请求,如设置字符串键值对、对同一个计数器做自增操作。
2. Redis 采用单线程模型执行命令,微观上命令按线性顺序执行,执行顺序虽不确定,但不会有两条命令同步执行,能保证像两个自增命令执行后结果一定正确,不会出现并发问题。宏观上客户端是同时请求的,微观上有先后次序。
3. Redis 基于内存存储数据,传统数据库如 MySQL 等基于硬盘存储。内存读写速度远快于硬盘,这是 Redis 速度快的重要基础。
4. Redis 核心功能相对简单,而传统数据库功能复杂,在数据操作上有更多复杂功能支持,如各种约束等,这些会增加计算开销。Redis 功能少且操作简单,主要是查询操作,所以速度快。
5. Redis 采用单线程模型,避免了线程竞争带来的额外开销。Redis 基本操作都是快速的内存操作,不怎么消耗 CPU,多线程对性能提升不大。
6. Redis 使用 epoll 等 I/O 多路复用机制处理网络 I/O,一个线程可管理多个 socket。避免了为每个客户端分配线程带来的系统开销增大问题,提高了 I/O 处理效率。
7. `EX seconds`:以秒为单位设置 key 的过期时间。
8. `PX milliseconds`:以毫秒为单位设置 key 的过期时间。
9. `NX`:仅当 key 不存在时才设置。
10. `XX`:仅当 key 存在时才设置。
11. `GET`:仅支持获取字符串类型的 value,若 value 为其他类型则获取出错。
12. `MSET`:可一次操作多组键值对,但一次设置过多(如 10w 个)可能阻塞 Redis。
13. `MGET`:可一次获取多个键的值,时间复杂度为 O(N)(N 为当前命令中 key 的数量,可视为 O(1))。
14. `SETNX`:仅当 key 不存在时设置键值对。
15. `SETEX`:设置键值对的同时指定以秒为单位的生存时间。
16. `PSETEX`:设置键值对的同时指定以毫秒为单位的生存时间。
17. `INCR`:将 key 对应的 value 加 1。
18. `INCRBY`:将 key 对应的 value 加指定整数 n。
19. `DECR`:将 key 对应的 value 减 1。
20. `DECRBY`:将 key 对应的 value 减指定整数 n。
21. `INCRBYFLOAT`:将 key 对应的 value 进行加减浮点数运算。
22. 这些操作时间复杂度均为 O(1),且因 Redis 单线程模型,多客户端同时操作同一 key 不会有线程安全问题。
23. `APPEND`:用于拼接字符串,返回值为拼接后字符串的字节长度,Redis 字符串按二进制存储,不做编码转换。
24. `GETRANGE`:获取字符串子串,区间为左闭右闭,若字符串含汉字,切分可能得到不完整汉字,该问题在 C++ 中也存在,Java 因字符串基本单位是字符所以无此问题。
25. `SETRANGE`:从指定偏移量开始替换字符串部分内容,对不存在的 key 操作会在偏移量前填充 0x00,若 value 是中文字符串可能出问题。
26. `STRLEN`:获取字符串的长度,单位是字节。