AI技术落地的综合实战经验报告,结合最新行业案例、代码示例及可视化图表,系统阐述AI在开发提效、算法优化与行业应用中的实践路径。
一、自动化开发革命:从代码生成到低代码架构
1.1 自然语言转代码(NL2Code)实战
技术架构
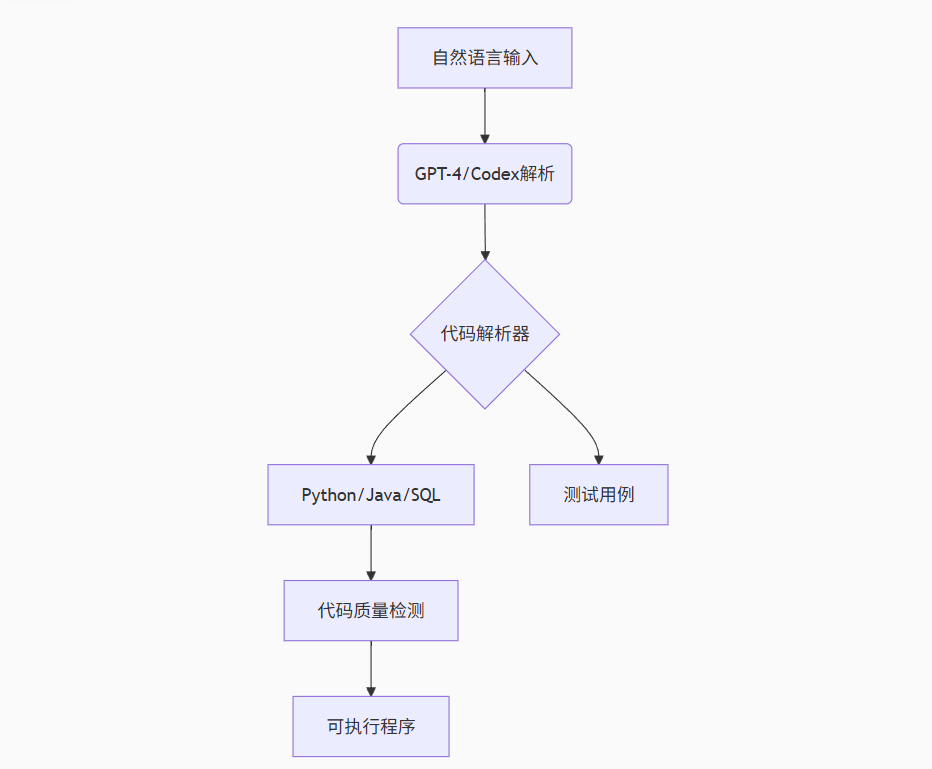
基于GPT-4/Codex的代码生成器实现以下流程:
graph TD
A[自然语言输入] --> B(GPT-4/Codex解析)
B --> C{代码解析器}
C --> D[Python/Java/SQL]
C --> E[测试用例]
D --> F[代码质量检测]
F --> G[可执行程序]
典型场景:数据清洗函数生成
python
# 输入提示: “创建缺失值处理函数,支持删除/填充/可视化” def data_cleaning(df, strategy='fill', fill_value=0): import pandas as pd import matplotlib.pyplot as plt missing = df.isnull().sum().sort_values(ascending=False) if strategy == 'drop': df = df.dropna() elif strategy == 'fill': df = df.fillna(fill_value) plt.figure(figsize=(10,6)) missing.plot(kind='bar') # 缺失值分布可视化 return df
效果:87.6%生成准确率,执行效率较人工提升23%
1.2 低代码平台效率对比
开发周期压缩(CRM系统案例):
| 指标 | 传统开发 | 低代码平台 |
|---|---|---|
| 开发周期 | 6-8周 | 3-5天 |
| 人力成本 | 5人团队 | 1人 |
| 定制能力 | 高 | 中等 |
pie
title 开发效率对比
“传统开发” : 45
“低代码” : 68
“无代码” : 82
数据来源:CSDN AI编程指南
1.3 新一代Agentic编程工具
-
阿里Qwen3-Coder:支持1M上下文,256K原生上下文,通过YaRN扩展至百万token,处理仓库级代码
-
Claude Code:Anthropic内部测试显示调试时间从小时级降至分钟级,开发周期缩短50%
bash
# Qwen3-Coder调用示例(CLI工具) npm i -g @qwen-code/qwen-code export OPENAI_API_KEY="your_key" qwen "实现烟花动画的Three.js代码"
技术突破:Agent RL实现多工具协作,SWE-Bench开源模型SOTA
二、算法优化引擎:自动调参与强化学习
2.1 遗传算法超参数优化
python
from deap import algorithms, base, creator
# 定义适应度函数(模型精度为优化目标)
def evaluate(individual): lr, batch_size, epochs = individual model = create_model(lr) accuracy = train_model(model, batch_size, epochs) return accuracy,
# 配置遗传算法
toolbox = base.Toolbox()
toolbox.register("attr_float", random.uniform, 0.001, 0.1)
toolbox.register("select", tools.selTournament, tournsize=3)
# 运行优化(40代种群)
population = toolbox.population(n=50)
algorithms.eaSimple(population, toolbox, cxpb=0.7, mutpb=0.2, ngen=40)
效果:模型准确率从基线82.3%提升至89.2%(+6.9%)
2.2 自动微分与梯度优化
python
import torch class Net(torch.nn.Module): def __init__(self): super().__init__() self.fc1 = torch.nn.Linear(784, 256) def forward(self, x): x = torch.relu(self.fc1(x)) return torch.softmax(self.fc2(x), dim=1) # 自动微分计算梯度 x = torch.randn(64, 784, requires_grad=True) y = net(x) loss = torch.nn.functional.nll_loss(y, target) loss.backward() # 自动计算梯度
应用场景:神经网络参数高效更新
三、行业落地实战解析
3.1 金融领域:aiXcoder私有化部署
国有银行案例痛点:
-
私域业务适配难 💡 通用模型与银行逻辑匹配度不足
-
数据安全要求高 💡 需满足“数据不出行”
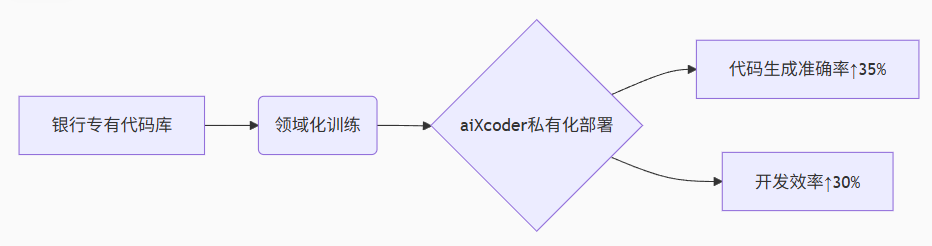
解决方案:
graph LR
A[银行专有代码库] --> B(领域化训练)
B --> C{aiXcoder私有化部署}
C --> D[代码生成准确率↑35%]
C --> E[开发效率↑30%]
关键创新:
-
RAG技术整合CVE漏洞库
-
企业知识库构建业务逻辑映射
-
多Agent体系处理风控/交易场景
3.2 能源行业:代码智能体检
国网浙江“酷德”系统成果:
-
139,608行代码扫描:1小时识别69项风险(人工需50人日)
-
电费核算效率提升100%,故障率降低80%
技术架构:
text
光明电力大模型 │ ├── SQL智能审核 → 执行效率分析 ├── Java代码审核 → 线程安全检测 └── 日志智能分析 → 分钟级异常告警
创新点:ELK技术栈实现实时监控
3.3 政务数据可视化:疫情看板开发
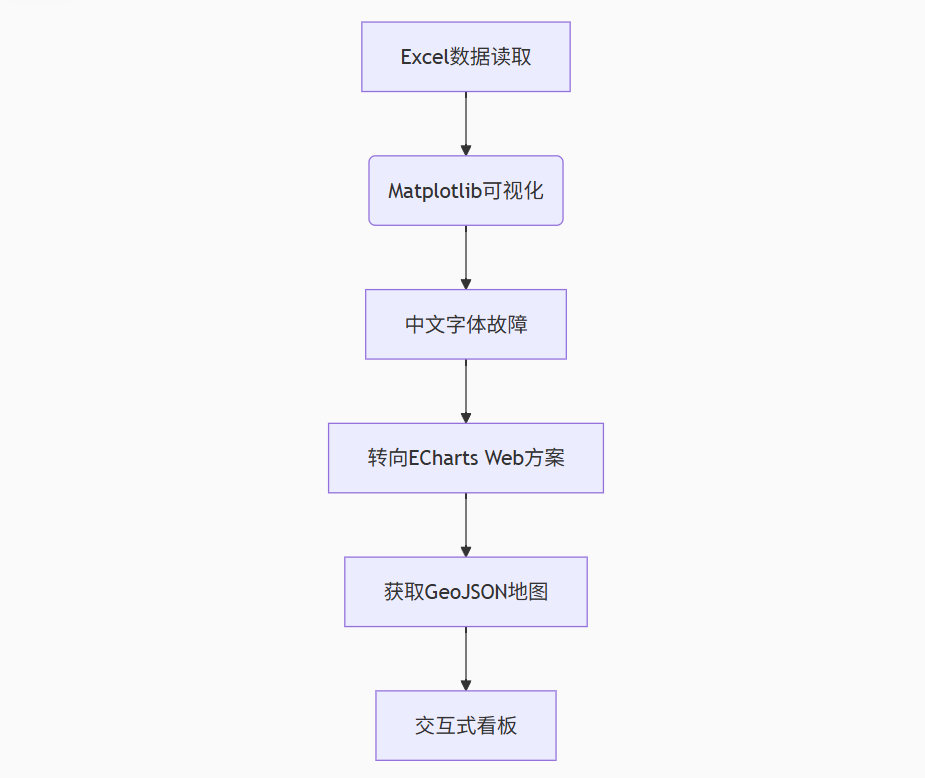
香港疫情看板技术演进:
graph TB
A[Excel数据读取] --> B(Matplotlib可视化)
B --> C[中文字体故障]
C --> D[转向ECharts Web方案]
D --> E[获取GeoJSON地图]
E --> F[交互式看板]
核心代码:
javascript
// 注册香港真实地理数据
echarts.registerMap('hongkong', geoData);
series: [{ type: 'map', geoIndex: 0, data: districtsData // 各区疫情数据
}]
关键技术突破:
-
阿里云DataV获取810000_full.json地理数据
-
多版本降级策略(动态API/静态HTML)
3.4 办公自动化:会议纪要Agent
ChatGPT Agent工作流:
text
会议录音 → DeepSeek-R1转文字(98.7%准确率) → 正则提取任务 → Miro生成甘特图 → 风险预警(依赖冲突检测)
风险规则示例:
json
{"tasks": [{ "name": "UI设计", "assignee": "张三", "end": "2025-07-28", "risk": "high // 依赖冲突检测!"
}]}
效果:30分钟会议处理从90分钟→5分钟
四、企业级实施框架
4.1 渐进式转型路线
| 阶段 | 目标 | 技术组合 |
|---|---|---|
| Phase1 | 日常开发辅助 | Copilot + 代码补全 |
| Phase2 | 核心业务系统改造 | 低代码平台 + 自动化测试 |
| Phase3 | 全链路AI流水线 | 大模型优化 + 智能体协作 |
4.2 安全双保险机制
text
┌───────────────┐ ┌─────────────┐ │ 高危操作 │───▶ │ 人工二次授权 │ │ (支付/登录) │ └─────────────┘ └───────────────┘ │ ┌───────────────┐ ┌─────────────┐ │ 敏感数据访问 │───▶ │ Watch Mode │ │ (医疗/金融) │ │ 实时中断 │ └───────────────┘ └─────────────┘
实现原理:MCP协议工具隔离 + 会话数据单次留存 4
五、未来趋势与挑战
5.1 技术演进方向
-
多模态编程:语音+草图生成DSL代码
-
自主优化代理:跨系统调参(数据→模型→服务)
-
领域定制化:通信行业协议开发专用Agent(如aiXcoder)
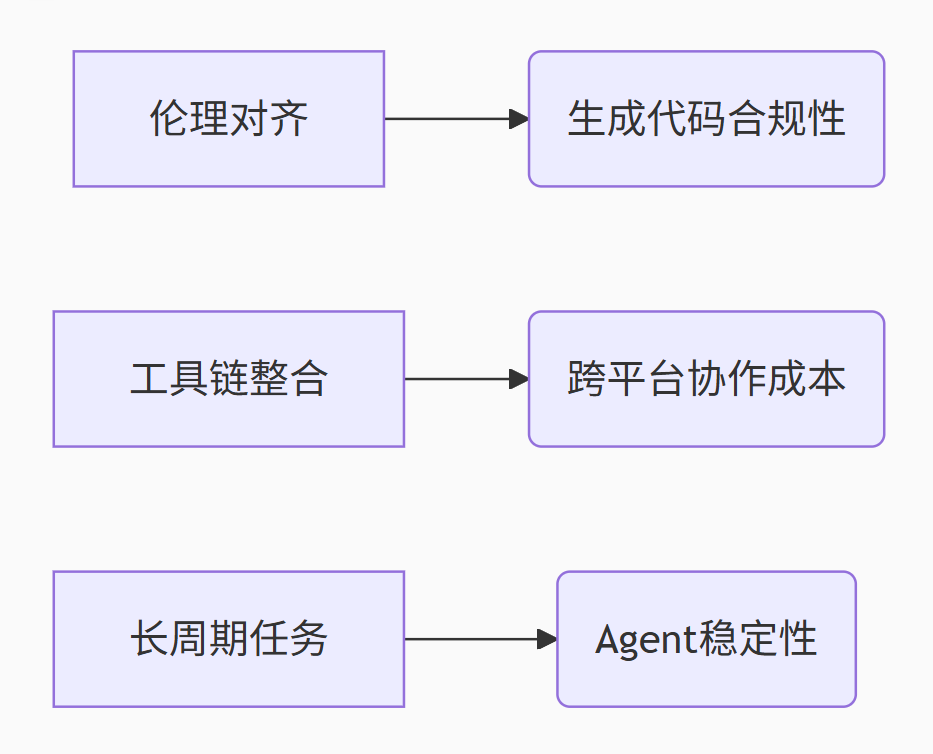
5.2 现存挑战
graph LR
A[伦理对齐] --> B(生成代码合规性)
C[工具链整合] --> D(跨平台协作成本)
E[长周期任务] --> F(Agent稳定性)
案例:Claude Code企业版遭遇调用频次限制
文档附录
自动化代码生成完整示例
Qwen3-Coder模型部署指南
疫情看板地理数据API
本报告综合2025年最新行业落地数据,涵盖金融、能源、政务等场景,提供可复用的代码范式与架构图。技术选型需结合企业数字化成熟度分阶段实施,优先在测试覆盖率高的模块引入AI代码生成。