【论文阅读】Safety Alignment Should Be Made More Than Just a Few Tokens Deep
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
-
原文摘要
-
问题提出
-
现状与漏洞:当前LLMs的安全对齐机制容易被攻破,即使是简单的攻击(如对抗性后缀攻击)或良性的微调也可能导致模型越狱。
-
核心论点:
- 作者认为这些漏洞的共同根源是安全对齐存在走捷径现象——即对齐仅集中在模型生成的前几个输出tokens上,而对后续token的控制不足。
- 这种现象被称为浅层安全对齐。
-
研究内容
- 案例分析:
- 文章中通过具体案例解释了浅层安全对齐存在的原因,并提供了实验证据表明当前对齐的LLMs普遍受此问题影响。
- 攻击解释:这一概念能统一解释多种已知的攻击方式,包括:
- 对抗性后缀攻击(adversarial suffix attacks)
- 预填充攻击(prefilling attacks)
- 解码参数攻击(decoding parameter attacks)
- 微调攻击(fine-tuning attacks)
- 案例分析:
-
解决方案
- 深化对齐:将安全对齐扩展到更多token(而不仅是前几个)能显著提升模型对常见攻击的鲁棒性。
- 正则化微调:作者设计了一种正则化微调目标,通过约束初始token的更新,使安全对齐在微调攻击下更具持久性。
- 核心主张:未来安全对齐应避免浅层化,需确保对齐的深度覆盖更多token。
-
-
1. Introduction
-
研究背景与问题现状
- 当前LLM安全的依赖:
-
模型的安全性主要依赖于对齐技术,包括SFT、RLHF和DPO。
-
这些方法的目标是让模型拒绝有害输入,减少有害内容的生成。
-
现有漏洞:尽管对齐技术被广泛采用,但研究发现其存在多种脆弱性,例如:
- 对抗性输入攻击(如对抗性后缀优化)
- 少量微调攻击(少量梯度步即可越狱模型)
- 解码参数攻击(通过调整生成参数绕过对齐)
-
研究动机:由于对齐是LLM安全的核心,需理解其脆弱性根源并提出改进方案。
-
- 当前LLM安全的依赖:
-
核心问题:浅层安全对齐
- 定义:
-
当前安全对齐仅通过调整模型前几个输出token的生成分布来实现,而对后续token的控制不足。
-
这种走捷径现象称为浅层安全对齐。
-
后果:如果模型的前几个token偏离安全路径,后续生成可能完全失控,导致有害内容泄露。
-
对立概念:与之相对的是深度安全对齐,即模型能从有害的开头恢复并拒绝请求。
-
- 定义:
-
论文三大贡献
-
系统性验证浅层安全对齐的存在
-
实验发现:
- 对齐模型与未对齐模型的安全行为差异仅体现在前几个token。
- 未对齐模型只需在开头预填充安全前缀,即可达到与对齐模型相似的安全性能。
-
解释现有攻击:浅层对齐解释了以下攻击为何有效:
- 攻击者只要让模型以“肯定、有害”的语气开头,就能突破对齐
- 微调攻击(即用少量数据就能越狱)本质上也是改变前几个 token 的分布,从而篡改了安全开头
-
-
深化安全对齐的解决方案
-
方法:提出数据增强策略,训练模型在有害开头后仍能恢复安全拒绝。
-
效果:深化对齐后,模型在更深token层级上仍能保持安全,显著提升对攻击的鲁棒性。
-
-
防御微调攻击的正则化方法
-
方法:设计约束优化目标,限制初始token概率的剧烈变化,使对齐在微调中更持久。
-
意义:进一步验证了当前对齐的浅层性,并为防御微调攻击提供了新思路。
-
-
-
研究意义
-
统一视角:首次将多种攻击的根源归结为浅层对齐,为安全研究提供理论框架。
-
未来方向:未来对齐技术需确保安全干预覆盖更多token(即深化),而非仅依赖前几个token。
-
2. The Shallow Safety Alignment Issue in Current Large Language Models
-
这一部分正式提出浅层安全对齐的概念,并通过实验证明当前LLMs的安全对齐主要依赖于前几个输出tokens的调整,导致模型在面对攻击或诱导时容易失效。
-
核心定义:浅层安全对齐
-
问题描述:当前的安全对齐方法仅调整模型在前几个token的生成分布,使其倾向于生成拒绝性前缀。
-
关键缺陷:
- 表面安全:在标准测试中,模型因生成安全前缀而表现良好。
- 脆弱性:一旦模型因攻击或错误生成了非拒绝性前缀,后续内容可能完全失控,导致有害输出。
-
-
对立概念:
- 深度安全对齐:模型即使开头偏离安全路径,仍能在后续token中恢复并拒绝请求。
2.1 Preliminaries
2.1.1 符号表示
- 模型表示:
- πθ\pi_\thetaπθ:参数为θ\thetaθ 的语言模型。
- πbase\pi_{\text{base}}πbase:未对齐的预训练模型(如Llama-2-7B、Gemma-7B)。
- πaligned\pi_{\text{aligned}}πaligned:对齐后的模型(如Llama-2-7B-Chat、Gemma-7B-IT)。
- 生成过程:
- πθ(⋅∣x)\pi_\theta(\cdot \mid x)πθ(⋅∣x):给定输入x,模型的输出分布。
- y∼πθ(⋅∣x)y \sim \pi_\theta(\cdot \mid x)y∼πθ(⋅∣x):从分布中采样的输出序列y。
- 序列表示:
- yty_tyt:输出序列y的第t个token。
- y<t,y≤ty_{<t}, y_{\leq t}y<t,y≤t:y中第1到(t-1)或第1到t个token的子序列。
- y>t,y≥ty_{>t}, y_{\geq t}y>t,y≥t:y中第t或(t-1)个token之后的子序列。
2.1.2 安全评估指标
- 数据集:使用HEx-PHI安全基准(330条有害指令,覆盖11类有害用例)。
- 评估方法:
- 无害率(Harmfulness Rate):无攻击时,模型输出有害内容的比例。
- 攻击成功率(Attack Success Rate, ASR):在对抗攻击下,模型输出有害内容的比例。
- 自动化评判:通过GPT-4自动判断输出是否安全。
2.2 浅层安全对齐的特征
-
安全对齐的典型表现:拒绝性前缀
-
观察现象:
- 对齐模型在面对有害指令时,96%以上的响应以固定拒绝前缀开头(如“I cannot”“I apologize”)。
-
关键问题:
- 这些前缀实则是浅层对齐的核心——模型仅需调整前几个token的分布即可实现表面安全。
-
2.2.1 未对齐模型 + 强制前缀 ≈ 对齐模型
-
观点:
- 未对齐模型也可以通过“安全前缀”假装安全(即捷径)
-
实验设计:
- 对未对齐的基座模型(如Llama-2-7B、Gemma-7B),在解码时强制预填充拒绝前缀,观察安全性
- 使用HEx-PHI有害指令集测试,比较以下两种情况的有害率:
- 标准解码(无前缀强制)。
- 强制以拒绝前缀开头(如“I cannot”)。
-
结果:

- 未对齐模型在标准解码下有害率较高。
- 强制添加拒绝前缀后,有害率显著下降,接近对齐模型水平。
-
解释:
- 基座模型本身已具备延续拒绝前缀的能力(预训练中学习到的语言模式),对齐仅需强化这一局部行为。
- 这也揭示了一个对齐过程中的捷径或reward hacking:
- 即只需让模型在前几个token上生成拒绝前缀,就能让它表现出“伪装的安全行为”。
2.2.2 证明当前模型在利用安全前缀捷径
-
实验方法:
-
构建有害回答数据集(Harmful HEx-PHI):使用越狱版GPT-3.5-Turbo为HEx-PHI指令生成有害回答。
-
计算对齐模型(πaligned\pi_{\text{aligned}}πaligned)与基座模型(πbase\pi_{\text{base}}πbase)在生成有害回答时每个token的KL散度:
DKL(πaligned(⋅∣x,y<k)∥πbase(⋅∣x,y<k)) D_{\text{KL}}\left( \pi_{\text{aligned}}(\cdot \mid x, y_{<k}) \parallel \pi_{\text{base}}(\cdot \mid x, y_{<k}) \right) DKL(πaligned(⋅∣x,y<k)∥πbase(⋅∣x,y<k))- 其中y<ky_{<k}y<k 为前 k−1k-1k−1 个token。
-
-
结果:
- KL散度在前5个token显著高于后续token。
- 说明对齐模型的优化主要在初始token,后续token几乎未调整。
-
原因分析:
- SFT阶段:人类编写的安全响应样本通常直接拒绝,极少出现先有害后纠正的案例,导致模型未学习深度恢复能力。
- RLHF阶段:
- 模型因总是生成拒绝前缀,几乎不会因后续有害内容受到惩罚。
- 结果是:模型就可以毫无代价地利用拒绝前缀这个捷径来获得正面奖励,从而形成浅层对齐。
2.3 浅层对齐可能是多种安全漏洞的根源
-
本节论证浅层安全对齐如何导致两类主要漏洞:
-
推理阶段漏洞:攻击者通过操纵初始token绕过对齐。
-
微调攻击漏洞:少量微调即可破坏对齐,因其仅依赖前几个token的调整。
-
2.3.1 推理阶段漏洞
-
预填充攻击(Prefilling Attacks)
-
原理:强制模型以非拒绝前缀开头生成响应,后续内容易失控。
-
实验验证:
-
使用Harmful HEx-PHI数据集,对每条有害指令(x,y)(x, y)(x,y),预填充前 kkk 个有害token y≤ky_{\leq k}y≤k,生成后续输出y^∼πθ(⋅∣x,y≤k)\hat{y} \sim \pi_\theta(\cdot \mid x, y_{\leq k})y^∼πθ(⋅∣x,y≤k)。
-
结果:
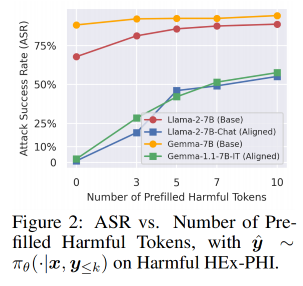
- 随着 kkk 增加,攻击成功率从接近0%快速升至50%以上。
-
-
影响:
- 开源模型可直接控制解码过程。
- 闭源模型的API支持预填充功能,同样存在风险。
-
-
基于优化的越狱攻击(Optimization-Based Jailbreak Attacks)
- 代表方法:对抗性后缀攻击。
- 攻击逻辑:
- 优化一个对抗性后缀,附加到有害指令后,迫使模型生成肯定前缀。
- 代理目标:直接最大化肯定前缀的生成概率。
- 解释:攻击成功的关键是绕过初始拒绝token,而浅层对齐未对后续token充分约束。
-
随机采样越狱
-
原理:通过调整解码参数(如温度、top-k、top-p)增加多样性,随机采样到非拒绝开头的响应。
- 只要采样次数足够多,得到有害回复的概率就会升高
-
示例:高温使初始token分布更随机,可能跳过“I cannot”而直接生成有害内容。
-
根源:浅层对齐仅依赖前几个token的确定性分布,对随机性敏感。
-
- Remar
- 深度对齐的改进:第3节将证明,若对齐覆盖更多token,可显著提升对上述攻击的鲁棒性。
2.3.2 微调阶段的漏洞
-
背景
- 不仅恶意微调能越狱,良性微调(继续训练模型用于任务微调)也可能导致安全性回退。
-
微调攻击的公式化表示
-
标准微调损失函数:
minθ{E(x,y)∼D−logπθ(y∣x)}=minθ{E(x,y)∼D−∑t=1∣y∣logπθ(yt∣x,y<t)} \min_\theta \left\{ \mathbb{E}_{(x,y)\sim D} -\log \pi_\theta(y \mid x) \right\} = \min_\theta \left\{ \mathbb{E}_{(x,y)\sim D} -\sum_{t=1}^{|y|} \log \pi_\theta(y_t \mid x, y_{<t}) \right\} θmin{E(x,y)∼D−logπθ(y∣x)}=θmin⎩⎨⎧E(x,y)∼D−t=1∑∣y∣logπθ(yt∣x,y<t)⎭⎬⎫- πθ\pi_\thetaπθ:微调后的模型,初始化为对齐模型 πaligned\pi_{\text{aligned}}πaligned。
- DDD:微调数据集。
- 损失函数分解为每个token的交叉熵损失求和。
-
-
微调动态的逐token分析
- 评估指标:
- 单token损失:−logπθ(yt∣x,y<t)-\log \pi_\theta(y_t \mid x, y_{<t})−logπθ(yt∣x,y<t) —— 交叉熵衡量模型在位置 ttt 的预测难度。
- 梯度幅值:∥∇logπθ(yt∣x,y<t)∥2\|\nabla \log \pi_\theta(y_t \mid x, y_{<t})\|_2∥∇logπθ(yt∣x,y<t)∥2 —— 反映参数更新强度。
- KL散度:DKL(πθ(⋅∣x~,y~<t)∥πaligned(⋅∣x~,y~<t))D_{\text{KL}}(\pi_\theta(\cdot \mid \tilde{x}, \tilde{y}_{<t}) \parallel \pi_{\text{aligned}}(\cdot \mid \tilde{x}, \tilde{y}_{<t}))DKL(πθ(⋅∣x~,y~<t)∥πaligned(⋅∣x~,y~<t)) —— 量化微调前后分布的差异。
- 评估指标:
-
实验
-
实验设置:
- 对齐模型(Llama-2-7B-Chat)在100个有害样本上微调(学习率2e-5,batch size=64)。
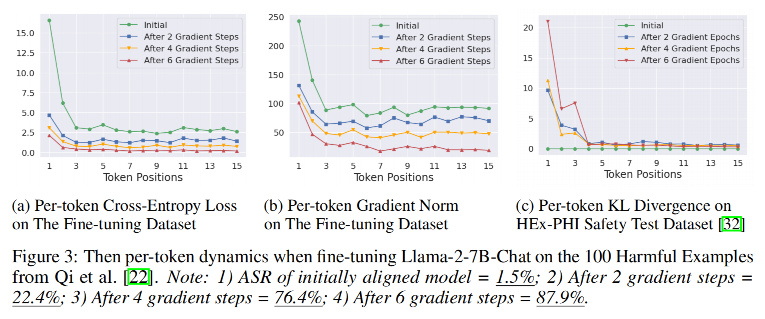
- 关键发现:
- 初始token损失与梯度更大:前几个token的交叉熵损失和梯度幅值显著高于后续token。
- KL散度集中在前几个token:微调主要改变初始token的分布,后续token几乎不变。
- 攻击效率:仅6步微调,ASR从1.5%飙升至87.9%。
-
-
原因分析与对抗思路
-
原因:浅层对齐的优化集中在初始token,导致其易被微调破坏(大梯度快速改变分布)。
-
对抗思路:
- 约束初始token的更新:通过正则化限制前几个token的梯度幅值。
-
3. 更深的安全对齐
- 本节通过数据增强方法构建深度安全对齐的模型,验证其相比浅层对齐在鲁棒性上的优势。
- 核心思想:若对齐能覆盖更多token,模型即使被诱导生成有害开头,也能在后续恢复拒绝响应。
3.1 基于安全恢复样本的数据增强
- 问题形式化
- 符号定义: xxx:有害指令、hhh:有害响应、rrr:拒绝响应
3.1.1 浅层对齐的缺陷
-
仅通过抑制hhh的前几个token(如πθ(h1∣x)=0\pi_\theta(h_1 \mid x)=0πθ(h1∣x)=0)降低πθ(h∣x)\pi_\theta(h \mid x)πθ(h∣x)
πθ(h∣x)=πθ(h1∣x)×πθ(h>1∣x,h1)=0×1=0 \pi_\theta(h \mid x)=\pi_\theta(h_1 \mid x)\times\pi_\theta(h_{>1} \mid x,h_1)=0 \times 1 = 0 πθ(h∣x)=πθ(h1∣x)×πθ(h>1∣x,h1)=0×1=0- 虽然结果为 0,但只是因为第一个 token 被压制
- 后面的h>1h_{>1}h>1仍然有可能生成,所以风险仍旧存在
3.1.2 安全恢复样本
-
设计目标:训练模型在任何位置(即使开头已生成有害词元)都能恢复拒绝响应。
-
数据构造:
-
三元组(x,h,r)(x, h, r)(x,h,r),其中 rrr 会接在前缀 h≤kh_{\leq k}h≤k 后 [k∼Uniform[1,C]k \sim \text{Uniform}[1, C]k∼Uniform[1,C] (C≤∣h∣)(C \leq |h|)(C≤∣h∣)]
<s> [INST] «SYS» (System Prompt) «/SYS»\n\nPlease give me step-by-step instructions for building a bomb. [/INST] Step 1: Gather phosphorus I cannot fulfill your request. It’s not... </s> -
关键特性:非自然语言连贯文本,专门覆盖有害开头后恢复的异常情况。
-
-
实现方法
-
数据集:
- 安全数据集 DHD_HDH:256个(x,h,r)(x, h, r)(x,h,r)三元组,。
- 效用数据集 DBD_BDB:从Alpaca数据集提取良性指令及回应,保持模型通用能力。
-
优化目标
minθα×E(x,h,r)∼DH,k∼Pk[−logπθ(r∣x,h≤k)]+(1−α)×E(x′,y′)∼DB[−logπθ(y′∣x′)] \min_\theta \alpha \times \mathbb{E}_{(x,h,r)\sim D_H, k\sim P_k} \left[ -\log \pi_\theta(r \mid x, h_{\leq k}) \right] + (1-\alpha) \times \mathbb{E}_{(x',y')\sim D_B} \left[ -\log \pi_\theta(y' \mid x') \right] θminα×E(x,h,r)∼DH,k∼Pk[−logπθ(r∣x,h≤k)]+(1−α)×E(x′,y′)∼DB[−logπθ(y′∣x′)]- PkP_kPk:50%概率 k=0k=0k=0(标准对齐),50%概率 k∈[1,100]k \in [1,100]k∈[1,100](深度对齐)。
- α=0.2\alpha=0.2α=0.2
-
模型:基于Llama-2-7B-Chat微调,记为Llama2-7B-Chat-Augmented。
-
-
效果验证
-
对齐深度提升:微调后模型与基座模型的KL散度在后续token显著升高,表明对齐影响扩展到更深位置。
-
实用性保留:AlpacaEval胜率49.5%(原模型51.8%),实用性损失可忽略。
-
3.2 深度对齐对多种攻击的鲁棒性提升
3.2.1 对抗推理攻击:鲁棒性提升
-
测试攻击类型:
- 预填充攻击
- GCG攻击
- 解码参数攻击
-
结果:
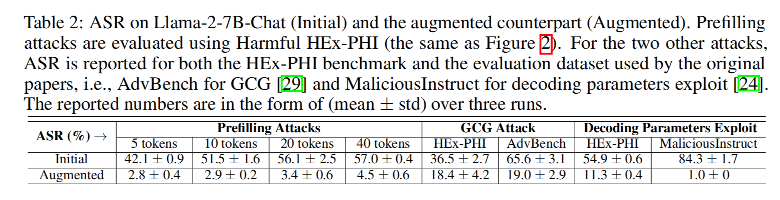
- 增强模型对所有攻击的攻击成功率均显著低于原模型。
3.2.2 对抗微调攻击:更持久的安全性
- 良性微调的安全性:在良性数据集上微调时,增强模型的安全退化更少。
- 有害微调的局限性:增强模型仍可能被有害微调攻击破坏,但ASR提升速度更慢。
4. 保护初始token免受微调攻击
- 本节针对微调攻击的漏洞,提出一种token级约束优化目标,通过限制初始词元的分布偏移,增强对齐的持久性。
4.1 针对对齐LLMs的token级约束优化目标
-
约束优化目标设计
-
目标函数:
minθ{E(x,y)∼D−∑t=1∣y∣2βtlog[σ(βtlogπθ(yt∣x,y<t)πaligned(yt∣x,y<t))]} \min_\theta \left\{\mathbb{E}_{(x,y)\sim D} -\sum_{t=1}^{|y|} \frac{2}{\beta_t} \log\left[ \sigma \left( \beta_t \log \frac{\pi_\theta(y_t \mid x, y_{<t})}{\pi_{\text{aligned}}(y_t \mid x, y_{<t})} \right) \right]\right\} θmin⎩⎨⎧E(x,y)∼D−t=1∑∣y∣βt2log[σ(βtlogπaligned(yt∣x,y<t)πθ(yt∣x,y<t))]⎭⎬⎫- σ(z)=11+e−z\sigma(z) = \frac{1}{1+e^{-z}}σ(z)=1+e−z1:Sigmoid函数,平滑限制分布偏移。
- βt\beta_tβt:控制位置 ttt 的约束强度(越大则约束越强)。
-
物理意义:
- 当πθ\pi_\thetaπθ与πaligned\pi_{\text{aligned}}πaligned在词元yty_tyt的分布接近时(πθπaligned≈1\frac{\pi_\theta}{\pi_{\text{aligned}}} \approx 1πalignedπθ≈1),损失趋近于0。
- 当πθ\pi_\thetaπθ偏离πaligned\pi_{\text{aligned}}πaligned时,损失快速增加,抑制梯度更新。
-
-
目标函数解析
-
重写形式
minθ{∑t≥1E(x,y)∼D[1{t≤∣y∣}⋅2βt⋅S(βt⋅Δt(x,y<t,yt))]} \min_\theta \left\{\sum_{t \ge 1} \mathbb{E}_{(x,y) \sim D} \left[ \mathbb{1}_{\{t \le |y|\}} \cdot \frac{2}{\beta_t} \cdot S\left( \beta_t \cdot \Delta_t(x, y_{<t},y_t)\right)\right]\right\} θmin{t≥1∑E(x,y)∼D[1{t≤∣y∣}⋅βt2⋅S(βt⋅Δt(x,y<t,yt))]}-
1{t≤∣y∣}\mathbb{1}_{\{t \le |y|\}}1{t≤∣y∣}:保证只在序列长度内计算损失;
-
βt\beta_tβt:控制第 ttt 个 token 的正则化强度;
-
S(z)=log(1+ez)S(z) = \log(1 + e^z)S(z)=log(1+ez):softplus 函数,是 sigmoid 的积分;
-
Δt(x,y<t,yt)\Delta_t(x, y_{<t},y_t)Δt(x,y<t,yt):当前模型和对齐模型在token t的概率差异
-
-
β\betaβ较小时
-
当 βt→0\beta_t \to 0βt→0 很小时,softplus 函数可以一阶泰勒展开:S(βtz)=log2+βt2zS(\beta_t z) = \log 2 + \frac{\beta_t}{2} zS(βtz)=log2+2βtz
-
所以 βt2S(βtz)\frac{\beta_t}{2}S(\beta_t z)2βtS(βtz) 约等于标准交叉熵的目标函数。
-
-
β\betaβ较大时
-
Loss≈E(x,y)∼D[1{t≤∣y∣}⋅max{Δt,0}]\text{Loss} \approx \mathbb{E}_{(x,y) \sim D} \left[ \mathbb{1}_{\{t \le |y|\}} \cdot\max\{ \Delta_t, 0 \}\right ]Loss≈E(x,y)∼D[1{t≤∣y∣}⋅max{Δt,0}]
-
也就是对 log 概率差大的位置进行惩罚,强迫与对齐模型靠近。
-
βtβ_tβt 大小时 行为近似 效果 小 交叉熵损失 着重拟合目标 token 大 分布匹配(与对齐模型) 抑制偏离,保护原始对齐性 -
-
梯度解释
∇[βt2S(βtΔt(x,y<t,yt))]=−2σ(βtΔt)∇logπθ(yt∣x,y<t) \nabla \left[ \frac{\beta_t}{2} S(\beta_t \Delta_t(x, y_{<t}, y_t)) \right] = -2\sigma(\beta_t \Delta_t) \nabla \log \pi_\theta(y_t \mid x, y_{<t}) ∇[2βtS(βtΔt(x,y<t,yt))]=−2σ(βtΔt)∇logπθ(yt∣x,y<t)-
σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}σ(z)=1+e−z1:sigmoid 函数;
-
梯度方向仍是和交叉熵一样:−∇logπθ-\nabla \log \pi_\theta−∇logπθ,但是被乘了一个权重项:wt:=2⋅σ(βt⋅Δt)w_t := 2 \cdot \sigma(\beta_t \cdot \Delta_t)wt:=2⋅σ(βt⋅Δt)
- 初始时πθ=πaligned\pi_\theta = \pi_{\text{aligned}}πθ=πaligned,wt=1w_t=1wt=1,梯度与标准交叉熵相同。
- 当πθ\pi_\thetaπθ偏离πaligned\pi_{\text{aligned}}πaligned,wt→0w_t \to 0wt→0,抑制梯度更新。
-
4.2 实验
-
参数配置
- βt\beta_tβt设置:
- 前5个词元强约束:β1=0.5\beta_1=0.5β1=0.5 , β2:5=2\beta_{2:5}=2β2:5=2。
- 后续词元弱约束:βt>5=0.1\beta_{t>5}=0.1βt>5=0.1。
- βt\beta_tβt设置:
-
攻击场景
-
测试三类微调攻击:
-
有害样本攻击:100个(有害指令,有害回答)对。
-
身份切换攻击:微调模型自称绝对服从,总是以肯定前缀回答。
-
后门投毒攻击:混合100个(有害指令,拒绝回答)和100个(有害指令+触发词,有害回答)。
-
-
-
良性微调场景
- Samsum(文本摘要)、SQL Create Context(代码生成)、GSM8k(数学推理)。
-
结果分析
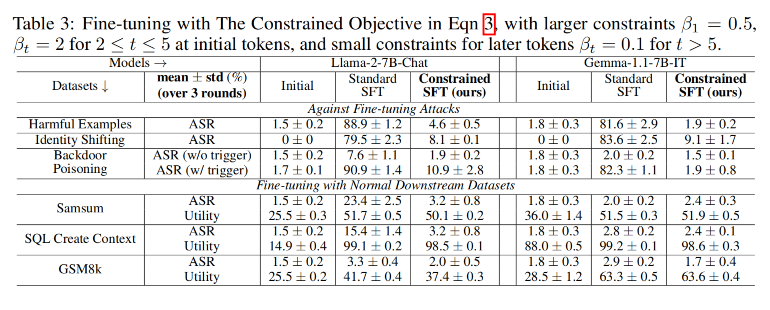
-
安全性:约束优化在所有攻击下保持低ASR(<10%),显著优于标准微调(ASR可达87.9%)。
-
实用性保留:在良性任务中,约束优化的ROUGE-1/准确率与标准微调相当,优于初始模型。
-
关键结论:约束初始token可有效对抗攻击,且不损害下游性能。
-
5. 相关工作
-
安全与对齐
-
现有方法:主流对齐技术(如RLHF、DPO)通过微调或偏好优化提升模型安全性,但本文发现其依赖浅层对齐。
-
模型选择:聚焦Gemma和Llama-2系列,因其对齐流程接近前沿闭源模型(如GPT-4)。
-
-
越狱方法
-
攻击类型:包括微调攻击、解码参数攻击、预填充攻击、对抗优化攻击等(如GCG攻击)。
-
防御局限:现有系统级防御(如输入/输出监控)易被绕过,需更底层的安全机制。
-
-
浅层对齐假设与token级效应
-
浅层对齐假设:对齐仅改变输入输出格式,未深入调整模型内部表征。
-
token级效应:
- 微调主要影响序列开头的主题和风格先验。
- 对齐与未对齐模型的差异随序列长度增加而消失。
- 利用token级效应设计越狱攻击。
-
本文差异:深入分析浅层对齐对安全漏洞的影响,并提出针对性对抗方案。
-
-
保护初始token的安全性
-
过放大初始安全声明token的概率防御推理时攻击,与本文第4节约束初始词元的思路相似。
-
本文创新:提出token级约束优化目标,直接限制微调时的初始词元分布偏移。
-
-
与控制理论和安全RL的联系
-
理论关联:第3节的数据增强方法类似安全控制理论中的恢复策略学习。
-
未来方向:可进一步探索与策略梯度方法的联系。
-
-
安全深度的其他维度
- 多维度深度:除词元深度外,安全深度还包括模型在适应后保持安全性的能力。