idea编译报错 java: 非法字符: ‘\ufeff‘ 解决方案
问题描述
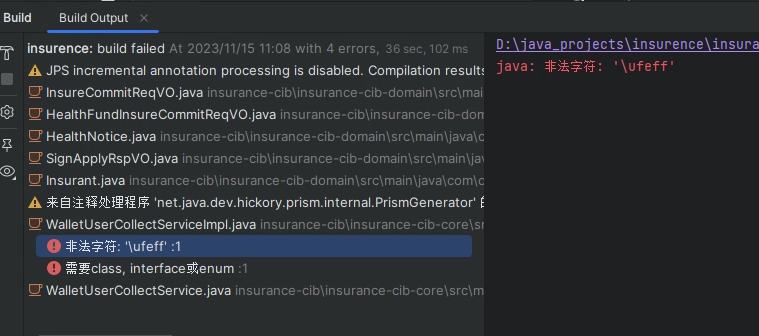
今天在项目中新建了一个class类,编译后却报错了
java: 非法字符: '\ufeff'
出现问题的原因
出现这样的问题来源于这个BOM,一般在编写时候会给你默认添加这样的一个BOM头,是隐藏起来的,编译时候就会给出现编码混乱问题;
BOM是什么玩意?
编码带BOM(字节顺序标记)是指在文本文件的开头添加特殊的字节序列,用于指示文件的编码方式和字节顺序。BOM通常用于Unicode编码的文本文件,如UTF-8、UTF-16等。
BOM的作用是帮助解析器确定文本文件的编码方式和字节顺序,以正确地解析和显示文件内容。它是一个特殊的标记,由几个字节组成,放置在文件的开头位置。
在UTF-8编码中,BOM由3个字节组成(0xEF, 0xBB, 0xBF),用于表示文件采用UTF-8编码。在UTF-16编码中,BOM由2个字节组成,有两种形式:大端序(Big-Endian)和小端序(Little-Endian)。大端序的BOM由两个字节(0xFE, 0xFF)组成,小端序的BOM由两个字节(0xFF, 0xFE)组成。
编码带BOM的文件可以帮助解析器自动检测文件的编码方式,使其能够正确地解析和处理文件内容。然而,有些应用程序可能不支持带BOM的文件,或者BOM可能会被错误地解释为文件内容的一部分,因此在某些情况下,使用带BOM的编码方式可能会带来一些问题。
解决方案
方案一、治标不治本
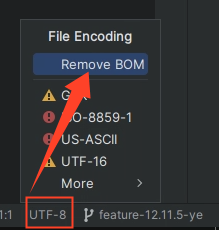
在右下角先点击 UTF-8 ,在弹出的窗口中选择Remove BOM,意思是移除这个 BOM;
方案二、治标不治本
打开文件的所在目录,右击文件 -> Open In -> Explorer
然后用Notepad++ 打开文件,点击编码后发现,当前的编码是 UTF-8 带 BOM的,所以我们只需要点击下面转为UTF-8编码即可解决问题
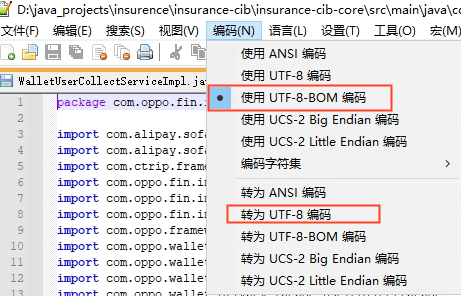
方案三、治标不治本
点击右下角的 UTF-8 ,将其先转为GBK编码,然后在转回UTF-8即可;
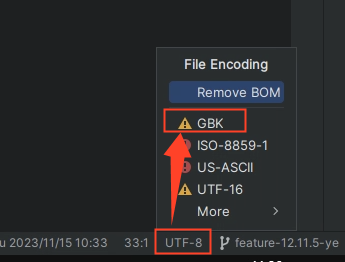
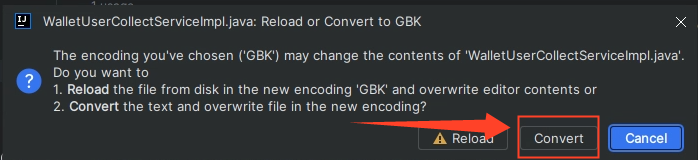
一定要选择 Convert, 是转换的意思
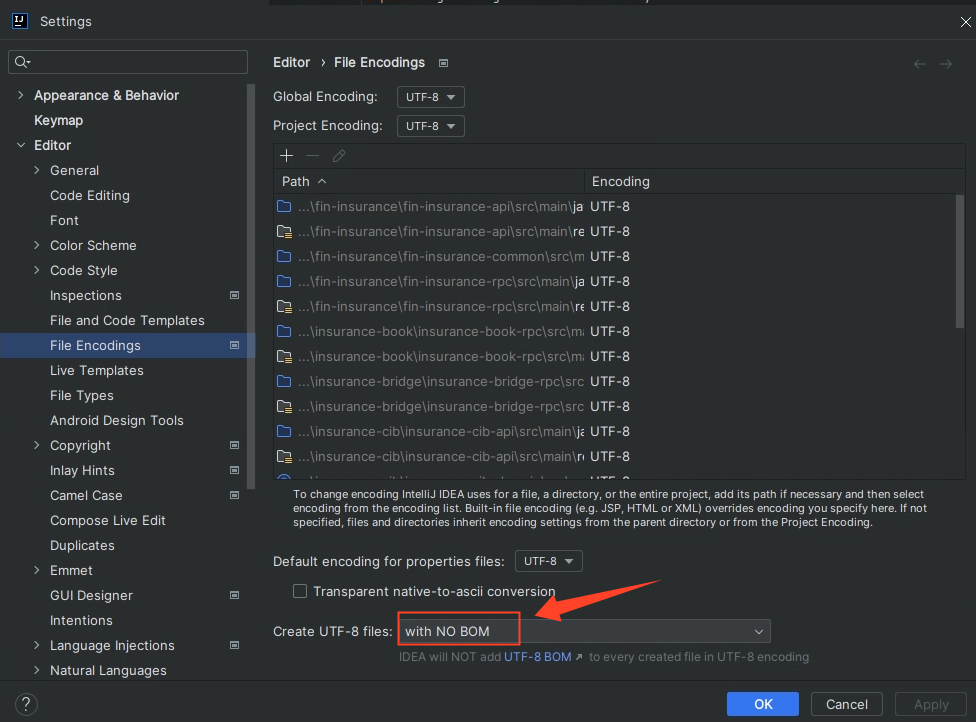
方案四、一劳永逸解决
想要不会每次新建项目时候都会出现这种问题,那就在idea设置-文件编码这里选择with NO BOM。然后应用,确定下次新建时候就不会出现这样的问题了;