图片PDF识别工具:扫描PDF文件批量OCR区域图识别改名,识别大量PDF区域内容一次性改名
以下是使用“咕嘎批量OCR识别图片PDF多区域内容重命名导出表格系统”进行操作的具体步骤:
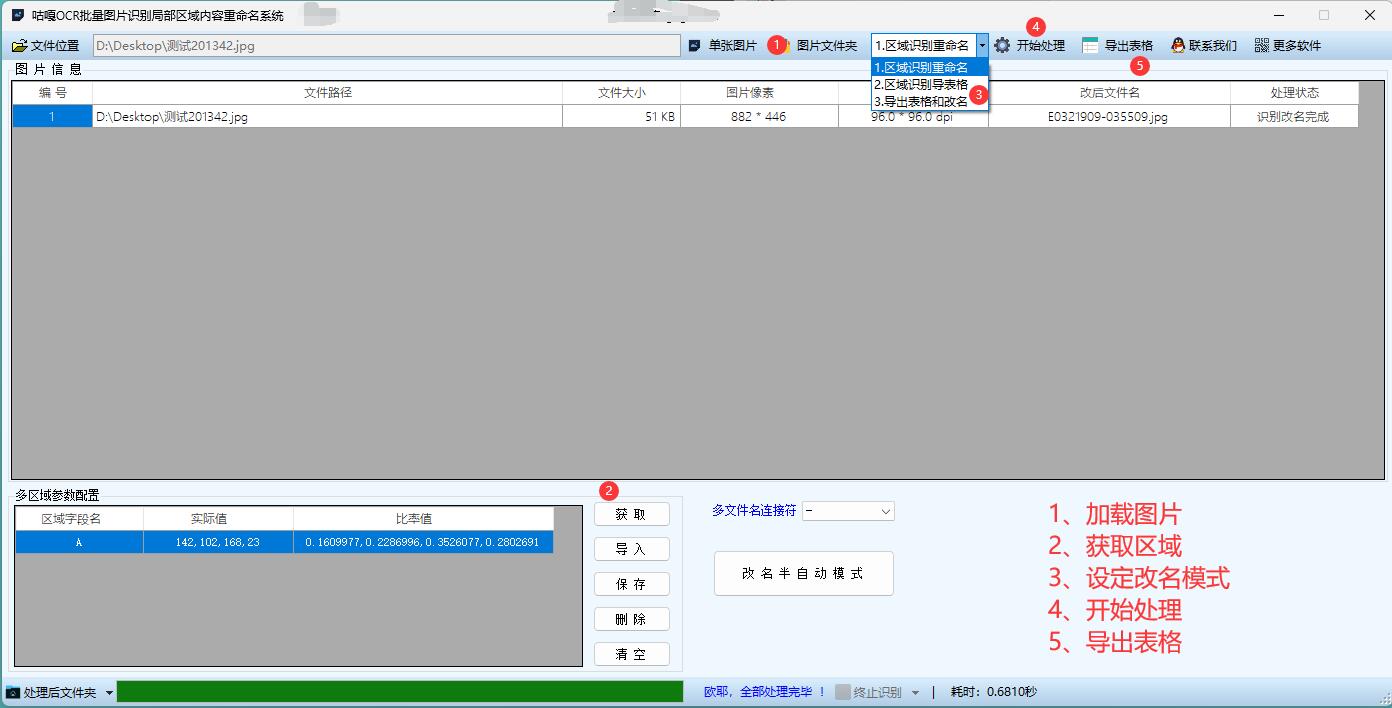
1. 打开工具并获取区域坐标
打开软件后,选择“PDF识别模式”。
导入一个PDF文件作为样本,框选需要提取文字的区域,并保存区域坐标。如果有多个区域需要识别,可多次框选并保存。
3. 导入文件并批量处理
点击“导入PDF”按钮,选择待处理的PDF文件所在的文件夹。
加载之前保存的区域坐标,点击“开始处理”按钮,软件将自动提取指定区域的文字内容。
4. 批量重命名
识别完成后,软件会根据提取的内容对文件进行批量重命名。例如,可以根据提取的标题或关键信息对文件进行重命名。
5. 导出到Excel表格(可选)
点击“导出到Excel”按钮,将提取的内容保存为Excel表格。
注意事项
文件格式与质量:确保处理的PDF文件格式正确,文字清晰、无干扰。
识别区域设置:框选识别区域时要精准,避免包含过多无关内容或遗漏关键信息。
文件权限与备份:确保软件有读取和写入文件的权限,处理重要文件前,最好先备份原始文件