深度学习----视觉里程计
一、视觉里程计介绍
视觉里程计(Visual Odometry,简称VO)是一种通过分析连续图像序列来估计摄像头在空间中的运动(位置和姿态)的方法。它是一种基于视觉信息的自主定位与导航技术,广泛应用于机器人、无人驾驶汽车、增强现实等领域。
视觉里程计是指使用相机获取的图像序列,通过对图像中的特征点提取、匹配与跟踪或深度学习方法,估计相机在三维空间中的相对运动轨迹(位置与姿态变化)的过程。其本质是对相机在一段时间内的位姿变换(translation + rotation)进行估计。
视觉里程计的类型
| 分类标准 | 类型 | 描述 |
|---|---|---|
| 相机配置 | 单目视觉里程计 (Monocular VO) | 使用单个相机,缺乏深度信息,存在尺度不确定性,需通过IMU融合或已知物体尺寸等方法解决。 |
| 双目视觉里程计 (Stereo VO) | 使用两个标定的相机,通过视差获取深度信息,直接估计真实尺度运动,通常比单目更鲁棒和精确。 | |
| RGB-D 视觉里程计 (RGB-D VO) | 使用RGB-D相机(如Kinect、RealSense),直接获取彩色图像和深度图像,深度信息更直接和稠密,适合特征稀疏环境。 | |
| 多相机视觉里程计 (Multi-camera VO) | 使用两个以上相机,提供更广视野或更丰富信息,提升鲁棒性和精度,但系统复杂性增加。 | |
| 处理方法 | 基于特征点法 (Feature-based) | 提取、匹配和跟踪特征点(如SIFT、ORB、FAST等),利用对极几何等约束估计位姿。 |
| 直接法 (Direct Method) | 不显式提取特征,直接利用像素灰度信息最小化光度误差来估计运动,纹理丰富场景表现好,但对光照变化和运动模糊敏感。 | |
| 半直接法 (Semi-direct Method) | 结合特征点法和直接法,稀疏提取特征点并跟踪,利用像素梯度信息优化,平衡效率和精度。 | |
| 基于深度学习法 (Deep Learning-based) | 使用神经网络(CNN、RNN等)学习图像到位姿的映射,或辅助特征提取、光流估计等,适合复杂环境,但依赖大量训练数据。 | |
| 传感器融合 | 视觉惯性里程计 (VIO) | 融合相机和IMU(加速度计+陀螺仪)数据,IMU提供高频运动信息,弥补VO在快速运动或纹理缺失时的不足,解决单目尺度问题,提升精度和鲁棒性。 |
传统几何方法视觉里程计的工作流程

| 步骤 | 关键操作 | 技术细节 |
|---|---|---|
| 1. 图像获取 | 从相机捕获连续帧(单目/双目/RGB-D)。 | 帧率需满足实时性要求(如30Hz)。 |
| 2. 图像预处理 | 去畸变、灰度化、降噪(如高斯滤波)。 | 去畸变依赖相机标定参数;灰度化减少计算量。 |
| 3. 特征提取 | 检测特征点(ORB/SIFT/FAST)并计算描述子。 | ORB(速度快)、SIFT(精度高)。 |
| 4. 特征匹配与跟踪 | 匹配当前帧与前一帧特征点(描述子匹配或光流法)。 | 使用RANSAC剔除误匹配;光流法适合连续帧。 |
| 5. 运动估计 | 根据匹配点估计相机位姿(R, t)。 | 单目:对极几何分解本质矩阵;双目/RGB-D:PnP或ICP求解3D-2D/3D-3D对应。 |
| 6. 尺度估计 | 仅单目VO需通过IMU、BA或已知物体恢复尺度。 | 尺度漂移是单目VO的主要挑战。 |
| 7. 局部优化 | 对局部窗口内的帧执行Bundle Adjustment(BA)。 | 优化相机位姿和3D点,最小化重投影误差。 |
| 8. 位姿累积 | 将相对位姿累积到全局轨迹。 | 累积误差可能导致轨迹漂移,需闭环检测修正。 |
应用场景
自动驾驶: 作为激光雷达、GPS等的辅助定位系统,提供车辆的实时位姿估计。在隧道、城市峡谷等GPS信号不稳定环境下尤为重要,能够实现车辆的连续定位。
机器人导航: 室内服务机器人、仓储机器人等利用视觉里程计实现自主定位与路径规划,使其能够在复杂环境中自由移动和执行任务。
无人机飞行: 小型无人机中视觉里程计可以代替重量较大的GPS/IMU系统,用于室内/室外自主飞行,尤其是在GPS受限的环境下提供精准定位。
增强现实(AR)/虚拟现实(VR): 用于头部跟踪与环境感知,实现虚拟物体在现实世界中的精准叠加和交互,为用户提供沉浸式体验。
三维重建与SLAM系统: 作为SLAM(Simultaneous Localization and Mapping,即同步定位与建图)系统的前端,为后端提供精确的相机运动估计,进而实现环境建图与自身定位的同步进行。
优缺点
| 类别 | 优点 | 缺点 |
|---|---|---|
| 成本 | 低成本:相机价格低廉,适合大规模部署。 | —— |
| 信息维度 | 信息丰富:提供纹理、颜色、几何等多维度环境信息。 | 计算量大:图像处理(特征提取、匹配、优化)消耗大量计算资源。 |
| 适用场景 | 非接触式:不受地面接触影响(如车轮打滑)。 适用性广:可在GPS失效环境(室内、水下)工作。 | 对环境敏感: • 纹理缺失(白墙、空旷场景)导致特征失效。 • 动态物体(人群、车辆)干扰位姿估计。 |
| 精度与鲁棒性 | 环境感知:输出位姿的同时提供环境地图,支持避障等下游任务。 | 误差累积:相对位姿累积导致轨迹漂移,需闭环检测修正。 单目VO存在尺度不确定性,需额外传感器恢复。 |
| 抗干扰能力 | —— | 光照敏感:强光/弱光下特征匹配不稳定。 运动模糊:快速移动或长曝光导致图像模糊。 |
二、数据集介绍
KITTI官方里程计彩色数据集(KITTI Odometry Color Dataset)是KITTI视觉基准套件(KITTI Vision Benchmark Suite)中的一个子集,专为评估视觉里程计(Visual Odometry, VO)和SLAM(Simultaneous Localization and Mapping)算法而设计。该数据集由德国卡尔斯鲁厄理工学院(KIT)和丰田技术研究中心联合发布。
KITTI数据集包含了真实世界场景下的城市背景立体图像序列及 激光雷达数据,精确位置车辆的位姿真值数据。KITTI数据集共22个序列,从乡村地区 的高速公路到市区的道路,场景丰富,其中使用地面真值的前11个序列(sequence00到 sequence10)用于训练。这些真值数据通过多个高分辨率传感器共同标定。

Sequence | Number | Scale |
00 | 4541 | 1241×376 |
01 | 1100 | 1241×376 |
02 | 4661 | 1226×370 |
03 | 801 | 1241×376 |
04 | 271 | 1226×370 |
05 | 2761 | 1226×370 |
06 | 1101 | 1226×370 |
07 | 1101 | 1226×370 |
08 | 4071 | 1226×370 |
09 | 1591 | 1226×370 |
10 | 1201 | 1226×370 |
三、网络结构
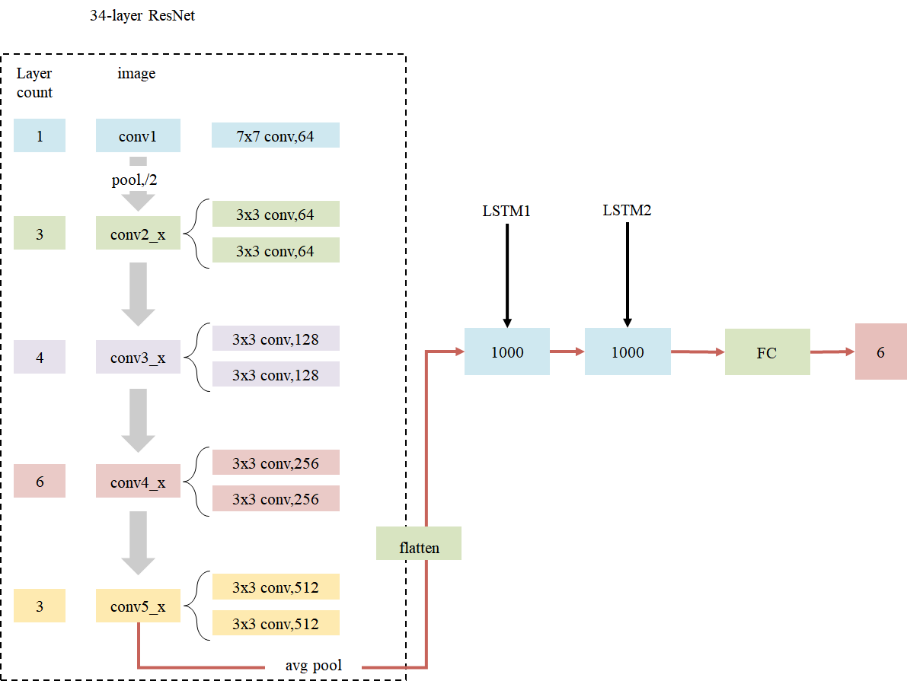
DeepVOResNet是一个端到端的视觉里程计深度学习模型,其核心设计思路是通过卷积神经网络提取视觉特征,再结合循环神经网络建模时序运动信息,最终直接预测相机的6自由度位姿变化。该网络采用双帧输入的设计,将相邻两帧图像在通道维度拼接后输入网络,这种显式的双帧输入方式强制网络学习帧间运动特征,类似于传统视觉里程计中的特征匹配与光流计算过程,为运动估计提供了直接的视觉线索。
在网络架构方面,模型使用ResNet作为特征提取骨干网络,支持从ResNet18到ResNet152等多种深度变体。为了适配双帧输入,对原始ResNet进行了针对性修改:将第一层卷积的输入通道扩展为6,并采用预训练权重复制策略进行初始化;移除了原网络的分类头,保留全局平均池化后的高维特征向量。这种设计既利用了ResNet强大的特征提取能力,又针对VO任务进行了定制化调整。在时序建模部分,网络采用双层LSTM结构处理特征序列,通过门控机制捕捉长时间依赖关系,并使用梯度裁剪和特殊的参数初始化策略确保训练稳定性。
该网络的损失函数设计体现了视觉里程计任务的特点,对旋转和平移分量采用差异化加权,由于旋转误差对轨迹漂移的影响更大,因此给予旋转损失100倍的权重系数。在优化策略上,模型综合运用了预训练权重适配、Kaiming参数初始化、梯度裁剪等技术,既保证了特征提取的质量,又确保了循环神经网络的训练效果。整体而言,DeepVOResNet通过精心设计的深度神经网络架构,实现了从原始图像到位姿估计的端到端映射,避免了传统方法中复杂的特征提取和几何优化过程,为视觉里程计提供了一种数据驱动的解决方案。
import torch
import torch.nn as nn
from params import par
from torch.autograd import Variable
from torch.nn.init import kaiming_normal_, orthogonal_
import numpy as npdef conv(batchNorm, in_planes, out_planes, kernel_size=3, stride=1, dropout=0):if batchNorm:return nn.Sequential(nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, bias=False),nn.BatchNorm2d(out_planes),nn.LeakyReLU(0.1, inplace=True),nn.Dropout(dropout)#, inplace=True))else:return nn.Sequential(nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, bias=True),nn.LeakyReLU(0.1, inplace=True),nn.Dropout(dropout)#, inplace=True))def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):"""3x3 convolution with padding"""return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,padding=dilation, groups=groups, bias=False, dilation=dilation)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class BasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,base_width=64, dilation=1, norm_layer=None):super(BasicBlock, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dif groups != 1 or base_width != 64:raise ValueError('BasicBlock only supports groups=1 and base_width=64')if dilation > 1:raise NotImplementedError("Dilation > 1 not supported in BasicBlock")# Both self.conv1 and self.downsample layers downsample the input when stride != 1self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = norm_layer(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes)self.bn2 = norm_layer(planes)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,base_width=64, dilation=1, norm_layer=None):super(Bottleneck, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dwidth = int(planes * (base_width / 64.0)) * groups# Both self.conv2 and self.downsample layers downsample the input when stride != 1self.conv1 = conv1x1(inplanes, width)self.bn1 = norm_layer(width)self.conv2 = conv3x3(width, width, stride, groups, dilation)self.bn2 = norm_layer(width)self.conv3 = conv1x1(width, planes * self.expansion)self.bn3 = norm_layer(planes * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, layers, in_channels=3, zero_init_residual=False,groups=1, width_per_group=64, replace_stride_with_dilation=None,norm_layer=None):super(ResNet, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dself._norm_layer = norm_layerself.inplanes = 64self.dilation = 1if replace_stride_with_dilation is None:# each element in the tuple indicates if we should replace# the 2x2 stride with a dilated convolution insteadreplace_stride_with_dilation = [False, False, False]if len(replace_stride_with_dilation) != 3:raise ValueError("replace_stride_with_dilation should be None ""or a 3-element tuple, got {}".format(replace_stride_with_dilation))self.groups = groupsself.base_width = width_per_groupself.conv1 = nn.Conv2d(in_channels, self.inplanes, kernel_size=7, stride=2, padding=3,bias=False)self.bn1 = norm_layer(self.inplanes)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2,dilate=replace_stride_with_dilation[0])self.layer3 = self._make_layer(block, 256, layers[2], stride=2,dilate=replace_stride_with_dilation[1])self.layer4 = self._make_layer(block, 512, layers[3], stride=2,dilate=replace_stride_with_dilation[2])self.avgpool = nn.AdaptiveAvgPool2d((1, 1))# 注意:这里我们不使用 ResNet 的原始 FC 层进行分类self.feature_dim = 512 * block.expansionfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)# Zero-initialize the last BN in each residual branch,# so that the residual branch starts with zeros, and each residual block behaves like an identity.# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677if zero_init_residual:for m in self.modules():if isinstance(m, Bottleneck):nn.init.constant_(m.bn3.weight, 0)elif isinstance(m, BasicBlock):nn.init.constant_(m.bn2.weight, 0)def _make_layer(self, block, planes, blocks, stride=1, dilate=False):norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilationif dilate:self.dilation *= stridestride = 1if stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(conv1x1(self.inplanes, planes * block.expansion, stride),norm_layer(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample, self.groups,self.base_width, previous_dilation, norm_layer))self.inplanes = planes * block.expansionfor _ in range(1, blocks):layers.append(block(self.inplanes, planes, groups=self.groups,base_width=self.base_width, dilation=self.dilation,norm_layer=norm_layer))return nn.Sequential(*layers)def forward(self, x):# print("Shape of input to ResNet:", x.shape)x = self.conv1(x)# print("Shape after conv1:", x.shape)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)# print("Shape after maxpool:", x.shape)x = self.layer1(x)# print("Shape after layer1:", x.shape)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)return x # 返回展平的特征向量,不再经过原始的 FC 层def resnet18x(in_channels=3, pretrained=False):# model=models.resnet18()model = ResNet(BasicBlock, [2, 2, 2, 2], in_channels=in_channels)if pretrained:try:pretrained_w = torch.load('./pretrained_models/resnet18.pth')model_dict = model.state_dict()pretrained_dict = {k: v for k, v in pretrained_w.items() if k in model_dict and 'fc' not in k}# 处理第一个卷积层if 'conv1.weight' in model_dict and 'conv1.weight' in pretrained_dict:pretrained_conv1_weight = pretrained_dict['conv1.weight']current_conv1_weight = model_dict['conv1.weight']if current_conv1_weight.shape[1] == 6 and pretrained_conv1_weight.shape[1] == 3:with torch.no_grad():# 将预训练的权重复制到当前权重的两个通道组current_conv1_weight[:, :3, :, :] = pretrained_conv1_weightcurrent_conv1_weight[:, 3:, :, :] = pretrained_conv1_weight # 可以尝试其他初始化方式pretrained_dict['conv1.weight'] = current_conv1_weightmodel_dict.update(pretrained_dict)model.load_state_dict(model_dict, strict=False)except FileNotFoundError:print("预训练权重文件未找到,将随机初始化 ResNet 权重。")except Exception as e:print(f"加载预训练权重时发生错误: {e}")return modeldef resnet34x(in_channels=3, pretrained=False):model = ResNet(BasicBlock, [3, 4, 6, 3], in_channels=in_channels)if pretrained:try:pretrained_w = torch.load('./pretrained_models/resnet34.pth')model_dict = model.state_dict()pretrained_dict = {k: v for k, v in pretrained_w.items() if k in model_dict and 'fc' not in k}if 'conv1.weight' in model_dict and 'conv1.weight' in pretrained_dict:pretrained_conv1_weight = pretrained_dict['conv1.weight']current_conv1_weight = model_dict['conv1.weight']if current_conv1_weight.shape[1] == 6 and pretrained_conv1_weight.shape[1] == 3:with torch.no_grad():current_conv1_weight[:, :3, :, :] = pretrained_conv1_weightcurrent_conv1_weight[:, 3:, :, :] = pretrained_conv1_weightpretrained_dict['conv1.weight'] = current_conv1_weightmodel_dict.update(pretrained_dict)model.load_state_dict(model_dict, strict=False)except FileNotFoundError:print("预训练权重文件未找到,将随机初始化 ResNet 权重。")except Exception as e:print(f"加载预训练权重时发生错误: {e}")return modeldef resnet50x(in_channels=3, pretrained=False):model = ResNet(Bottleneck, [3, 4, 6, 3], in_channels=in_channels) # 注意这里使用了 Bottleneckif pretrained:try:pretrained_w = torch.load('./pretrained_models/resnet50.pth')model_dict = model.state_dict()pretrained_dict = {k: v for k, v in pretrained_w.items() if k in model_dict and 'fc' not in k}if 'conv1.weight' in model_dict and 'conv1.weight' in pretrained_dict:pretrained_conv1_weight = pretrained_dict['conv1.weight']current_conv1_weight = model_dict['conv1.weight']if current_conv1_weight.shape[1] == 6 and pretrained_conv1_weight.shape[1] == 3:with torch.no_grad():current_conv1_weight[:, :3, :, :] = pretrained_conv1_weightcurrent_conv1_weight[:, 3:, :, :] = pretrained_conv1_weightpretrained_dict['conv1.weight'] = current_conv1_weightmodel_dict.update(pretrained_dict)model.load_state_dict(model_dict, strict=False)except FileNotFoundError:print("预训练权重文件未找到,将随机初始化 ResNet 权重。")except Exception as e:print(f"加载预训练权重时发生错误: {e}")return modeldef resnet101x(in_channels=3, pretrained=False):model = ResNet(Bottleneck, [3, 4, 23, 3], in_channels=in_channels) # 注意这里使用了 Bottleneckif pretrained:try:pretrained_w = torch.load('./pretrained_models/resnet101.pth')model_dict = model.state_dict()pretrained_dict = {k: v for k, v in pretrained_w.items() if k in model_dict and 'fc' not in k}if 'conv1.weight' in model_dict and 'conv1.weight' in pretrained_dict:pretrained_conv1_weight = pretrained_dict['conv1.weight']current_conv1_weight = model_dict['conv1.weight']if current_conv1_weight.shape[1] == 6 and pretrained_conv1_weight.shape[1] == 3:with torch.no_grad():current_conv1_weight[:, :3, :, :] = pretrained_conv1_weightcurrent_conv1_weight[:, 3:, :, :] = pretrained_conv1_weightpretrained_dict['conv1.weight'] = current_conv1_weightmodel_dict.update(pretrained_dict)model.load_state_dict(model_dict, strict=False)except FileNotFoundError:print("预训练权重文件未找到,将随机初始化 ResNet 权重。")except Exception as e:print(f"加载预训练权重时发生错误: {e}")return modeldef resnet152x(in_channels=3, pretrained=False):model = ResNet(Bottleneck, [3, 8, 36, 3], in_channels=in_channels) # 注意这里使用了 Bottleneckif pretrained:try:pretrained_w = torch.load('./pretrained_models/resnet152.pth')model_dict = model.state_dict()pretrained_dict = {k: v for k, v in pretrained_w.items() if k in model_dict and 'fc' not in k}if 'conv1.weight' in model_dict and 'conv1.weight' in pretrained_dict:pretrained_conv1_weight = pretrained_dict['conv1.weight']current_conv1_weight = model_dict['conv1.weight']if current_conv1_weight.shape[1] == 6 and pretrained_conv1_weight.shape[1] == 3:with torch.no_grad():current_conv1_weight[:, :3, :, :] = pretrained_conv1_weightcurrent_conv1_weight[:, 3:, :, :] = pretrained_conv1_weightpretrained_dict['conv1.weight'] = current_conv1_weightmodel_dict.update(pretrained_dict)model.load_state_dict(model_dict, strict=False)except FileNotFoundError:print("预训练权重文件未找到,将随机初始化 ResNet 权重。")except Exception as e:print(f"加载预训练权重时发生错误: {e}")return modelclass DeepVOResNet(nn.Module):def __init__(self, imsize1, imsize2, batchNorm=True, resnet_variant='resnet18', pretrained_resnet=False):super(DeepVOResNet, self).__init__()self.img_h = imsize1self.img_w = imsize2# CNN (ResNet)self.batchNorm = batchNormself.clip = par.clipself.resnet_variant = resnet_variantself.pretrained_resnet = pretrained_resnetif self.resnet_variant == 'resnet18':self.resnet = resnet18x(in_channels=6, pretrained=self.pretrained_resnet)resnet_out_channels = self.resnet.feature_dimelif self.resnet_variant == 'resnet34':self.resnet = resnet34x(in_channels=6, pretrained=self.pretrained_resnet)resnet_out_channels = self.resnet.feature_dimelif self.resnet_variant == 'resnet50':self.resnet = resnet50x(in_channels=6, pretrained=self.pretrained_resnet)resnet_out_channels = self.resnet.feature_dim# print("ResNet50 Layer1 First Bottleneck:", self.resnet.layer1[0])elif self.resnet_variant == 'resnet101':self.resnet = resnet101x(in_channels=6, pretrained=self.pretrained_resnet)resnet_out_channels = self.resnet.feature_dimelif self.resnet_variant == 'resnet152':self.resnet = resnet152x(in_channels=6, pretrained=self.pretrained_resnet)resnet_out_channels = self.resnet.feature_dimelse:raise ValueError(f"Unsupported ResNet variant: {resnet_variant}")__tmp = Variable(torch.zeros(1, 6, self.img_h, self.img_w))with torch.no_grad():__tmp = self.encode_image(__tmp)# RNNself.rnn = nn.LSTM(input_size=int(np.prod(__tmp.size())),hidden_size=par.rnn_hidden_size,num_layers=2,dropout=par.rnn_dropout_between,batch_first=True)self.rnn_drop_out = nn.Dropout(par.rnn_dropout_out)self.linear = nn.Linear(in_features=par.rnn_hidden_size, out_features=6)# Initialization (可以根据需要调整 ResNet 权重的初始化)for m in self.modules():if isinstance(m, nn.LSTM):# layer 1kaiming_normal_(m.weight_ih_l0)kaiming_normal_(m.weight_hh_l0)m.bias_ih_l0.data.zero_()m.bias_hh_l0.data.zero_()n = m.bias_hh_l0.size(0)start, end = n//4, n//2m.bias_hh_l0.data[start:end].fill_(1.)# layer 2kaiming_normal_(m.weight_ih_l1)kaiming_normal_(m.weight_hh_l1)m.bias_ih_l1.data.zero_()m.bias_hh_l1.data.zero_()n = m.bias_hh_l1.size(0)start, end = n//4, n//2m.bias_hh_l1.data[start:end].fill_(1.)elif isinstance(m, nn.Linear):kaiming_normal_(m.weight.data)if m.bias is not None:m.bias.data.zero_()elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def forward(self, x):x = torch.cat(( x[:, :-1], x[:, 1:]), dim=2)batch_size = x.size(0)seq_len = x.size(1)# CNN (ResNet)x = x.view(batch_size*seq_len, x.size(2), x.size(3), x.size(4))x = self.encode_image(x)x = x.view(batch_size, seq_len, -1)# RNNout, hc = self.rnn(x)out = self.rnn_drop_out(out)out = self.linear(out)return outdef encode_image(self, x):return self.resnet(x) # 直接使用 ResNet 的前向传播,它会返回展平的特征def weight_parameters(self):return [param for name, param in self.named_parameters() if 'weight' in name]def bias_parameters(self):return [param for name, param in self.named_parameters() if 'bias' in name]def get_loss(self, predicted, target): # Now accepts 'predicted' as inputy = target[:, 1:, :]angle_loss = torch.nn.functional.mse_loss(predicted[:,:,:3], y[:,:,:3])translation_loss = torch.nn.functional.mse_loss(predicted[:,:,3:], y[:,:,3:])loss = (100 * angle_loss + translation_loss)return lossdef step(self, x, y, optimizer):optimizer.zero_grad()predicted = self.forward(x) # Call forward onceloss = self.get_loss(predicted, y) # Pass the predicted output to get_lossloss.backward()if self.clip is not None:if isinstance(self.rnn, nn.LSTM):torch.nn.utils.clip_grad_norm_(self.rnn.parameters(), self.clip)else:torch.nn.utils.clip_grad_norm_(self.parameters(), self.clip)optimizer.step()return loss四、模型训练
import math
import torch
from torch.utils.data import DataLoader
import numpy as np
import os
import time
import pandas as pd
from params import par
from restnet_deepvo import DeepVOResNet
from data_helper import get_data_info, SortedRandomBatchSampler, ImageSequenceDataset, get_partition_data_info
from tqdm import tqdm
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
from tensorboardX import SummaryWriter
import torchvision
import warnings
from show import monitor_gpu# 禁用Python警告
warnings.filterwarnings("ignore")# 创建保存目录
os.makedirs(par.save_model_path, exist_ok=True)
os.makedirs(par.save_optimzer_path, exist_ok=True)
tensorboard_log_dir = os.path.join(par.save_model_path, 'tensorboard_logs')
os.makedirs(tensorboard_log_dir, exist_ok=True)# 初始化TensorBoard Writer
writer = SummaryWriter(log_dir=tensorboard_log_dir, flush_secs=30)# 记录超参数到文件和TensorBoard
def record_hyperparameters():with open(par.record_path, 'w') as f:f.write('\n' + '=' * 50 + '\n')f.write('\n'.join(f"{k}: {v}" for k, v in vars(par).items()))f.write('\n' + '=' * 50 + '\n')# 记录到TensorBoardwriter.add_hparams({k: str(v) for k, v in vars(par).items()},{'hparam/loss': 0, 'hparam/accuracy': 0})record_hyperparameters()# 数据准备
def prepare_data():if os.path.isfile(par.train_data_info_path) and os.path.isfile(par.valid_data_info_path):print('Load data info from {}'.format(par.train_data_info_path))train_df = pd.read_pickle(par.train_data_info_path)valid_df = pd.read_pickle(par.valid_data_info_path)else:print('Create new data info')if par.partition != None:partition = par.partitiontrain_df, valid_df = get_partition_data_info(partition, par.train_video, par.seq_len, overlap=1,sample_times=par.sample_times, shuffle=True, sort=True)else:train_df = get_data_info(folder_list=par.train_video, seq_len_range=par.seq_len, overlap=1,sample_times=par.sample_times)valid_df = get_data_info(folder_list=par.valid_video, seq_len_range=par.seq_len, overlap=1,sample_times=par.sample_times)# save the data infotrain_df.to_pickle(par.train_data_info_path)valid_df.to_pickle(par.valid_data_info_path)return train_df, valid_dftrain_df, valid_df = prepare_data()# 数据加载器
def create_dataloader(df, batch_size):sampler = SortedRandomBatchSampler(df, batch_size, drop_last=True)dataset = ImageSequenceDataset(df, par.resize_mode, (par.img_w, par.img_h),par.img_means, par.img_stds, par.minus_point_5)return DataLoader(dataset,batch_sampler=sampler,num_workers=par.n_processors,pin_memory=par.pin_mem)train_dl = create_dataloader(train_df, par.batch_size)
valid_dl = create_dataloader(valid_df, par.batch_size)print(f'\n{"="*50}')
print(f'Train Samples: {len(train_df):,}\nValid Samples: {len(valid_df):,}')
print(f'Batch Size: {par.batch_size}\nTotal Steps per Epoch: {len(train_dl)}')
print(f'{"="*50}\n')# 设备设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')# 模型初始化
def initialize_model():model = DeepVOResNet(par.img_h, par.img_w,par.batch_norm,resnet_variant='resnet34',pretrained_resnet=True).to(device)# 记录模型结构try:sample_batch = next(iter(train_dl))[1].to(device)print(f'Input shape: {sample_batch.shape}')writer.add_graph(model, sample_batch)print('Model graph recorded to TensorBoard')except Exception as e:print(f'Failed to record model graph: {str(e)}')return modelM_deepvo = initialize_model()# 配置优化器
def configure_optimizer():# AdamW优化器optimizer = optim.AdamW(M_deepvo.parameters(),lr=par.optim['lr'],betas=par.optim['betas'],weight_decay=par.optim['weight_decay'],eps=par.optim['eps'])# 学习率调度器if par.optim['scheduler'] == 'Cosine':# 带预热的余弦退火def lr_lambda(step):# 预热阶段if step < par.optim['warmup_epochs'] * len(train_dl):warmup_progress = step / (par.optim['warmup_epochs'] * len(train_dl))return par.optim['warmup_factor'] + (1 - par.optim['warmup_factor']) * warmup_progress# 余弦退火阶段progress = (step - par.optim['warmup_epochs'] * len(train_dl)) / \(par.optim['T'] * len(train_dl))return 0.5 * (1 + math.cos(math.pi * progress)) * \(1 - par.optim['eta_min']) + par.optim['eta_min']scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)else:scheduler = Nonereturn optimizer, scheduleroptimizer, lr_scheduler = configure_optimizer()# 可视化工具函数
def inverse_normalize(tensor):"""反归一化图像张量"""img_mean = torch.tensor(par.img_means).view(3, 1, 1).to(device)img_std = torch.tensor(par.img_stds).view(3, 1, 1).to(device)return tensor * img_std + img_meandef log_images(images, tag, step):"""记录图像到TensorBoard"""try:# 取batch中第一个样本的前两帧frame1 = inverse_normalize(images[0, 0]).cpu()frame2 = inverse_normalize(images[0, 1]).cpu()# 创建网格grid = torch.stack([frame1, frame2], dim=0)grid = torchvision.utils.make_grid(grid, nrow=2, normalize=True)writer.add_image(tag, grid, step)except Exception as e:print(f'Image logging failed: {str(e)}')# 训练循环
best_valid_loss = float('inf')
early_stop_counter = 0
log_file = open(par.record_path, 'a')
early_stop_patience = 3
try:for epoch in range(par.epochs):epoch_start = time.time()print(f'\n{"="*30} Epoch {epoch+1}/{par.epochs} {"="*30}')# 训练阶段M_deepvo.train()train_losses = []train_bar = tqdm(train_dl, desc='Training', unit='batch')for batch_idx, (_, images, poses) in enumerate(train_bar):# 数据迁移到设备images = images.to(device, non_blocking=par.pin_mem)poses = poses.to(device, non_blocking=par.pin_mem)# 前向传播和优化loss = M_deepvo.step(images, poses, optimizer)# 记录训练指标train_losses.append(loss.item())train_bar.set_postfix(loss=f"{loss.item():.4f}")# 学习率调度 (每个 step)if lr_scheduler:lr_scheduler.step()# 记录batch级指标if batch_idx % 10 == 0:writer.add_scalar('Loss/Train_batch', loss.item(), epoch * len(train_dl) + batch_idx)# 记录epoch级训练指标mean_train_loss = np.mean(train_losses)writer.add_scalar('Loss/Train', mean_train_loss, epoch)writer.add_scalar('Metrics/Train_Std', np.std(train_losses), epoch)# 验证阶段M_deepvo.eval()valid_losses = []valid_bar = tqdm(valid_dl, desc='Validation', unit='batch')with torch.no_grad():for batch_idx, (_, images, poses) in enumerate(valid_bar):images = images.to(device, non_blocking=par.pin_mem)poses = poses.to(device, non_blocking=par.pin_mem)# 前向传播pred_poses = M_deepvo(images)loss = M_deepvo.get_loss(pred_poses, poses)valid_losses.append(loss.item())valid_bar.set_postfix(loss=f"{loss.item():.4f}")# 记录第一个batch的图像log_images(images, 'Validation/InputFrames', epoch)# 记录验证指标mean_valid_loss = np.mean(valid_losses)writer.add_scalar('Loss/Validation', mean_valid_loss, epoch)writer.add_scalar('Metrics/Valid_Std', np.std(valid_losses), epoch)# 记录学习率current_lr = optimizer.param_groups[0]['lr']writer.add_scalar('LearningRate', current_lr, epoch)# 记录参数分布for name, param in M_deepvo.named_parameters():writer.add_histogram(f'Params/{name}', param.cpu().detach().numpy(), epoch)if param.grad is not None:writer.add_histogram(f'Grads/{name}', param.grad.cpu().detach().numpy(), epoch)# 记录日志文件log_str = (f"Epoch {epoch+1}: "f"Train Loss: {mean_train_loss}±{np.std(train_losses)}, "f"Valid Loss: {mean_valid_loss}±{np.std(valid_losses)}, "f"LR: {current_lr:.2e}, "f"Time: {time.time()-epoch_start:.1f}s\n")log_file.write(log_str)print(log_str)# 早停机制和模型保存if mean_valid_loss < best_valid_loss:best_valid_loss = mean_valid_lossearly_stop_counter = 0torch.save(M_deepvo.state_dict(), os.path.join(par.save_model_path, 'best_model.pth'))torch.save(optimizer.state_dict(), os.path.join(par.save_optimzer_path, 'best_optimizer.pth'))print(f"Saved best model at epoch {epoch+1}")else:early_stop_counter += 1print(f"Early stopping {early_stop_counter}/5")if early_stop_counter >= early_stop_patience:print(f"Early stopping at epoch {epoch+1}")breakmonitor_gpu()
finally:# 确保资源释放log_file.close()writer.close()print('\nTraining completed. Cleaning up resources...')print('\nVisualization commands:')
print(f'TensorBoard: tensorboard --logdir={tensorboard_log_dir} --port=6006')
print(f'Model checkpoints: {par.save_model_path}')# tensorboard --logdir=models/tensorboard_logs --port=6006该代码实现了一个基于深度学习的视觉里程计(DeepVO)训练框架,其核心设计思路围绕数据准备、模型构建、训练优化和监控评估四个关键环节展开。在数据准备阶段,采用双帧输入策略构建序列数据集,通过自定义的SortedRandomBatchSampler确保每个batch内的序列长度一致,同时使用ImageSequenceDataset实现图像加载、归一化和时序处理,这种设计既保留了帧间运动信息,又提高了数据加载效率。模型架构上选择ResNet34作为视觉特征提取器,配合双层LSTM进行时序建模,形成"CNN+RNN"的混合结构,其中ResNet部分采用预训练权重初始化并针对双帧输入调整了第一层卷积,LSTM部分则通过梯度裁剪和特殊初始化确保训练稳定性。
训练流程采用带预热的余弦退火学习率调度策略,结合AdamW优化器平衡收敛速度和泛化性能。监控体系包含多层次的指标记录:batch级损失实时反馈训练状态,epoch级统计反映整体趋势,TensorBoard集成记录了损失曲线、参数分布、梯度直方图和输入样本可视化,形成完整的训练监控网络。验证阶段引入早停机制防止过拟合,当验证损失连续3个epoch未改善时终止训练,并始终保存最佳模型。该框架特别注重工程细节,包括GPU内存监控、异常处理、资源释放和可视化支持,通过多进程数据加载、非阻塞传输和混合精度训练等技术优化训练效率,最终实现了一个鲁棒、可扩展的端到端视觉里程计训练系统。
五、预测模型
from params import par
from restnet_deepvo import DeepVOResNet
import numpy as np
from PIL import Image
import glob
import os
import time
import torch
from data_helper import get_data_info, ImageSequenceDataset
from torch.utils.data import DataLoader
from helper import eulerAnglesToRotationMatrix
import matplotlib.pyplot as plt# Path for saving individual pose component plots
output_plot_dir = './pose_plots/'
if not os.path.exists(output_plot_dir):os.makedirs(output_plot_dir)if __name__ == '__main__':
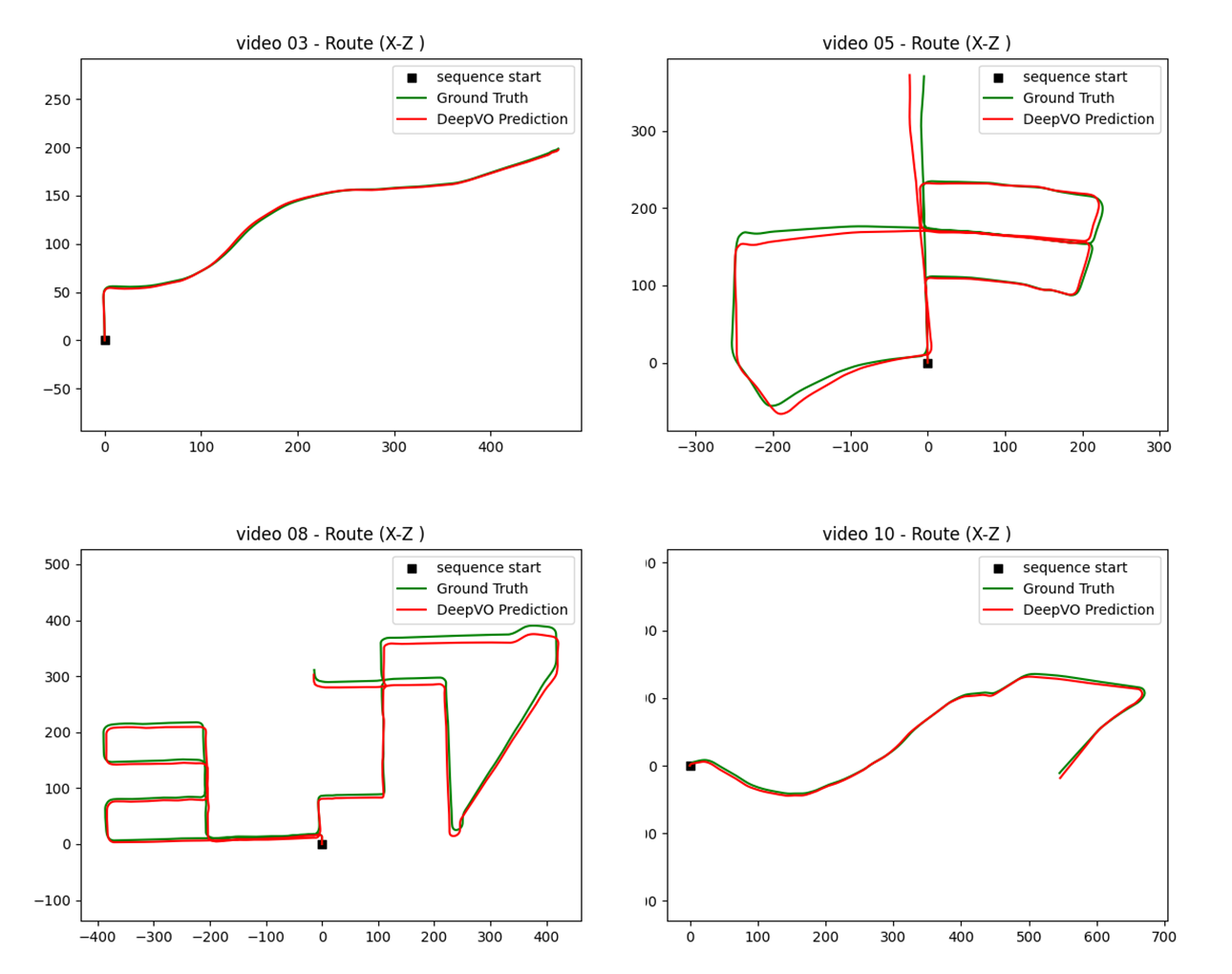
#./models/t000102050809_v0304060710_im184x608_s5x7_b8_rnn1000_optAdamW.model/epoch_6.pthvideos_to_test = ['00', '01', '02', '03', '04', '05', '06', '07', '08', '09', '10']# videos_to_test = ['00']# Pathload_model_path = './models/best_model.pth' # choose the model you want to loadsave_dir = 'result/' # directory to save prediction answerif not os.path.exists(save_dir):os.makedirs(save_dir)# Load modelM_deepvo = DeepVOResNet(par.img_h, par.img_w, par.batch_norm,resnet_variant='resnet34')use_cuda = torch.cuda.is_available()if use_cuda:M_deepvo = M_deepvo.cuda()M_deepvo.load_state_dict(torch.load(load_model_path))else:M_deepvo.load_state_dict(torch.load(load_model_path, map_location={'cuda:0': 'cpu'}))print('Load model from: ', load_model_path)# Datan_workers = 1seq_len = int((par.seq_len[0] + par.seq_len[1]) / 2)overlap = seq_len - 1print('seq_len = {}, overlap = {}'.format(seq_len, overlap))batch_size = par.batch_sizefd = open('test_dump.txt', 'w')fd.write('\n' + '=' * 50 + '\n')all_predictions = {}all_losses = {} # Dictionary to store losses for each videofor test_video in videos_to_test:df = get_data_info(folder_list=[test_video], seq_len_range=[seq_len, seq_len], overlap=overlap,sample_times=1, shuffle=False, sort=False)df = df.loc[df.seq_len == seq_len] # drop lastdataset = ImageSequenceDataset(df, par.resize_mode, (par.img_w, par.img_h), par.img_means, par.img_stds,par.minus_point_5)df.to_csv('test_df.csv')dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False, num_workers=n_workers)gt_pose = np.load('{}{}.npy'.format(par.pose_dir, test_video)) # (n_images, 6)# PredictM_deepvo.eval()answer = [[0.0] * 6, ]st_t = time.time()n_batch = len(dataloader)for i, batch in enumerate(dataloader):print('{} / {}'.format(i, n_batch), end='\r', flush=True)_, x, y = batchif use_cuda:x = x.cuda()y = y.cuda()batch_predict_pose = M_deepvo.forward(x)# Record answerfd.write('Batch: {}\n'.format(i))for seq, predict_pose_seq in enumerate(batch_predict_pose):for pose_idx, pose in enumerate(predict_pose_seq):fd.write(' {} {} {}\n'.format(seq, pose_idx, pose))batch_predict_pose = batch_predict_pose.data.cpu().numpy()if i == 0:for pose in batch_predict_pose[0]:# use all predicted pose in the first predictionfor j in range(len(pose)):# Convert predicted relative pose to absolute pose by adding last posepose[j] += answer[-1][j]answer.append(pose.tolist())batch_predict_pose = batch_predict_pose[1:]# transform from relative to absolutefor predict_pose_seq in batch_predict_pose:ang = eulerAnglesToRotationMatrix([0, answer[-1][0], 0])location = ang.dot(predict_pose_seq[-1][3:])predict_pose_seq[-1][3:] = location[:]# use only last predicted pose in the following predictionlast_pose = predict_pose_seq[-1]for j in range(len(last_pose)):last_pose[j] += answer[-1][j]# normalize angle to -Pi...Pi over y axislast_pose[0] = (last_pose[0] + np.pi) % (2 * np.pi) - np.pianswer.append(last_pose.tolist())print('len(answer): ', len(answer))print('expect len: ', len(glob.glob('{}{}/*.png'.format(par.image_dir, test_video))))print('Predict use {} sec'.format(time.time() - st_t))# Save answerwith open('{}/out_{}.txt'.format(save_dir, test_video), 'w') as f:for pose in answer:if type(pose) == list:f.write(', '.join([str(p) for p in pose]))else:f.write(str(pose))f.write('\n')# Calculate lossgt_pose = np.load('{}{}.npy'.format(par.pose_dir, test_video)) # (n_images, 6)total_loss = 0for t in range(len(gt_pose)):angle_loss = np.sum((np.array(answer[t][:3]) - gt_pose[t, :3]) ** 2)translation_loss = np.sum((np.array(answer[t][3:]) - gt_pose[t, 3:6]) ** 2)total_loss += (100 * angle_loss + translation_loss)mean_loss = total_loss / len(gt_pose)print('Loss = ', mean_loss)print('=' * 50)all_predictions[test_video] = np.array(answer[1:]) # Store predictions (excluding initial zero pose)all_losses[test_video] = mean_loss # Store the calculated lossfd.close()# Visualization partpose_GT_dir = par.pose_dir # 'KITTI/pose_GT/'predicted_result_dir = './result/'gradient_color = Truepose_labels = ['roll (rad)', 'pitch (rad)', 'yaw (rad)', 'x (m)', 'y (m)', 'z (m)']def plot_route(gt, out, c_gt='g', c_out='r'):x_idx = 3y_idx = 5x = [v for v in gt[:, x_idx]]y = [v for v in gt[:, y_idx]]plt.plot(x, y, color=c_gt, label='Ground Truth')x = [v for v in out[:, x_idx]]y = [v for v in out[:, y_idx]]plt.plot(x, y, color=c_out, label='DeepVO')plt.gca().set_aspect('equal', adjustable='datalim')# Open a file to write the losseswith open('prediction_losses.txt', 'w') as loss_file:loss_file.write("Prediction Losses per Video:\n")loss_file.write("=" * 30 + "\n")for video in videos_to_test:print('=' * 50)print('Video {}'.format(video))loss_file.write(f"Video {video}: Loss = {all_losses[video]:.6f}\n")GT_pose_path = '{}{}.npy'.format(pose_GT_dir, video)gt = np.load(GT_pose_path)pose_result_path = '{}out_{}.txt'.format(predicted_result_dir, video)try:with open(pose_result_path) as f_out:out_lines = [l.split('\n')[0] for l in f_out.readlines()]out = np.array([[float(v) for v in line.split(',')] for line in out_lines])mse_rotate = 100 * np.mean((out[:, :3] - gt[:, :3]) ** 2)mse_translate = np.mean((out[:, 3:] - gt[:, 3:6]) ** 2)print('mse_rotate: ', mse_rotate)print('mse_translate: ', mse_translate)time_steps = np.arange(len(gt))# Plot individual pose componentsfor i in range(6):plt.figure(figsize=(10, 6))plt.plot(time_steps, gt[:, i], label='Ground Truth', color='g')plt.plot(time_steps, out[:, i], label='DeepVO Prediction', color='r')plt.xlabel('Time Step')plt.ylabel(pose_labels[i])plt.title(f'Video {video} - {pose_labels[i]}')plt.legend()plt.grid(True)save_name = f'{output_plot_dir}video_{video}_{pose_labels[i].replace(" ", "_")}.png'plt.savefig(save_name)plt.close()print(f'Individual pose plots for video {video} saved to {output_plot_dir}')# Plot route (X-Z plane)plt.clf()plt.scatter([gt[0][3]], [gt[0][5]], label='sequence start', marker='s', color='k')plot_route(gt, out, 'g', 'r')plt.legend()plt.title(f'Video {video} - Route (X-Z Plane)')save_name_route = f'{predicted_result_dir}route_{video}.png'plt.savefig(save_name_route)print(f'Route plot for video {video} saved to {predicted_result_dir}')except FileNotFoundError:print(f"Warning: Prediction file not found for video {video} at {pose_result_path}")loss_file.write(f"Warning: Prediction file not found for video {video} at {pose_result_path}\n")except Exception as e:print(f"An error occurred while processing video {video}: {e}")loss_file.write(f"An error occurred while processing video {video}: {e}\n")loss_file.write("=" * 30 + "\n")print('=' * 50)print('Prediction and visualization complete.')print('Prediction losses saved to prediction_losses.txt')该代码实现了视觉里程计(DeepVO)预测与评估流程,主要包含数据加载、模型推理、结果保存和可视化分析四个核心模块。在数据准备阶段,代码通过get_data_info函数构建测试序列数据集,采用固定长度(seq_len)和最大重叠(overlap=seq_len-1)的滑动窗口策略处理图像序列,确保连续帧间的运动信息完整保留,同时使用ImageSequenceDataset实现图像标准化和批量加载。模型推理部分加载预训练的DeepVOResNet模型(基于ResNet34+LSTM架构),通过逐批次处理测试视频序列,将模型输出的相对位姿转换为绝对轨迹,其中特别处理了旋转角度的周期性(归一化到[-π,π]范围)和坐标系的转换(通过eulerAnglesToRotationMatrix实现欧拉角到旋转矩阵的转换)。
评估体系采用多维度误差度量,分别计算旋转分量(roll/pitch/yaw)和平移分量(x/y/z)的均方误差,其中旋转误差赋予100倍权重以反映其对轨迹精度的关键影响。可视化模块生成两类分析图表:一是六自由度位姿分量(3个欧拉角+3个平移坐标)随时间变化的曲线对比图,通过分组件显示直观呈现模型在各维度上的预测偏差;二是X-Z平面的轨迹对比图,以鸟瞰视角展示预测轨迹与真实轨迹的空间一致性。所有结果均按测试视频序列分别保存,包括原始预测数据(TXT格式)、损失记录(prediction_losses.txt)和可视化图表(PNG格式),形成完整的可追溯分析体系。该实现特别注重工程鲁棒性,包含异常文件检测、错误处理机制和内存管理,通过CUDA加速和批量处理优化推理效率,最终输出可定量评估的精度指标和定性分析的视觉对比结果,为模型性能评估提供多角度依据。