缓存一致性:从单核到异构多核的演进之路
上一篇我们聊了 CPU 为什么需要缓存,它如何通过数据局部性和分层设计填补 CPU 与内存的速度鸿沟。但缓存的引入也带来了一个棘手的问题 —— 当多个处理单元共享数据时,如何保证各自缓存中的数据是一致的?这就是缓存一致性(Cache Coherence)要解决的核心问题。
今天我们就从最简单的单核系统说起,逐步深入到对称多处理(SMP)系统,最后聊聊包含 CPU、NPU、ISP 等多种处理单元的异构多核系统,看看缓存一致性是如何从 “无问题” 演变为 “复杂工程挑战” 的。
一、单核系统:不存在缓存一致性问题
对于单核 CPU 系统,缓存一致性根本不是问题。因为整个系统只有一个处理核心,所有的内存访问请求都来自这个核心,缓存的读写操作是 “串行” 的。比如:
-
当 CPU 读取内存地址 A 的数据时,会将其加载到 L1、L2 缓存中;
-
后续对 A 的读写操作都会先操作缓存,修改后的数据最终会写回内存;
-
整个过程中,没有其他处理单元会访问缓存或内存,因此缓存中的数据始终是 “自洽” 的 —— 缓存与内存的不一致只是暂时的(如写回策略下的 Modified 状态),但这种不一致只会被单个核心感知,且会按预定策略(如替换时写回)同步,不会导致错误。
打个比方:单核系统就像一个人独自使用一个储物柜,你每次取东西、放东西都是自己操作,不可能出现 “你刚放进去的东西被别人偷偷换掉” 的情况。
但当系统进入多核时代,情况就完全不同了。
二、SMP 对称多处理系统:总线嗅探与 MESI 协议
对称多处理(SMP)系统的特点是:多个同构 CPU 核心共享同一块物理内存,且每个核心都有自己的私有缓存(L1、L2),通过共享总线连接到内存控制器。
多个 CPU 通过共享总线访问内存的结构示意图如下:
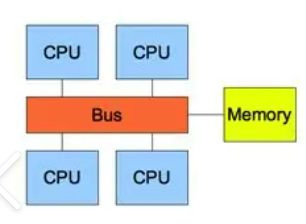
这时问题来了:如果两个核心同时缓存了同一个内存地址的数据,其中一个核心修改了数据,另一个核心的缓存就会变成 “脏数据”。比如核心 0 将内存地址 A 的值从 100 改成 200,而核心 1 的缓存中 A 的值还是 100,此时核心 1 基于 100 的计算就会出错。
SMP 系统解决缓存一致性的经典方案是 “总线嗅探 + MESI 协议”。
1. 共享总线:天然的 “信息广播通道”
SMP 系统的多个核心通过共享总线连接到内存,这为缓存一致性提供了天然的通信基础。每个核心的缓存控制器都会实时 “嗅探”(Snoop)总线上的所有内存访问事务,了解其他核心在做什么。
比如:
-
核心 0 要写内存地址 A,会先在总线上广播 “我要写 A” 的消息;
-
核心 1 的缓存控制器嗅探到这个消息后,会检查自己的缓存中是否有 A 的数据;
-
如果有,就会根据协议规则(如标记为无效)做出响应。
2. MESI 协议:缓存行的四种状态管理
为了规范缓存行的状态转换,SMP 系统普遍采用MESI 协议(也有其变种如 MOESI、MESIF 等)。MESI 为每个缓存行定义了四种状态:
-
M(Modified,修改态):缓存行的数据被修改过,与内存不一致,且仅存在于当前核心的缓存中(私有)。当该缓存行被替换时,必须写回内存。
-
E(Exclusive,独占态):缓存行的数据与内存一致,且仅存在于当前核心的缓存中。当核心要修改该数据时,可直接将状态转为 M,无需通知其他核心(因为没有其他核心持有该数据)。
-
S(Shared,共享态):缓存行的数据与内存一致,且可能存在于多个核心的缓存中。当核心要修改该数据时,必须先向其他核心发送 “失效请求”,待确认后才能转为 M 态。
-
I(Invalid,无效态):缓存行的数据无效(已过时),核心需要访问时必须从内存或其他核心的缓存中重新加载。
MESI 协议如何工作?举个例子:
-
核心 0 读取内存地址 A,将其加载到自己的缓存中,状态为 E(独占);
-
核心 1 也读取地址 A,此时总线嗅探到该请求,核心 0 会将 A 的数据通过总线发送给核心 1,两者的缓存行状态都转为 S(共享);
-
核心 0 要修改 A 的值,会先向总线发送 “Invalidate 请求”,通知所有持有 A 缓存行的核心(这里是核心 1);
-
核心 1 收到请求后,将自己的 A 缓存行标记为 I(无效),并向总线回复 “确认无效”;
-
核心 0 收到确认后,将自己的 A 缓存行状态转为 M(修改),然后修改数据;
-
后续核心 1 再访问 A 时,发现缓存行无效,会从核心 0(或内存,若核心 0 已写回)加载最新数据。
通过这种状态管理和总线嗅探机制,SMP 系统能保证多个核心的缓存数据一致。但这种方案有个明显的瓶颈 ——共享总线。当核心数量增加(如超过 8 核),总线会成为带宽和延迟的瓶颈,因为所有一致性消息都要通过总线广播,冲突会急剧增加。
三、多核异构系统:CMN 如何驯服复杂一致性?
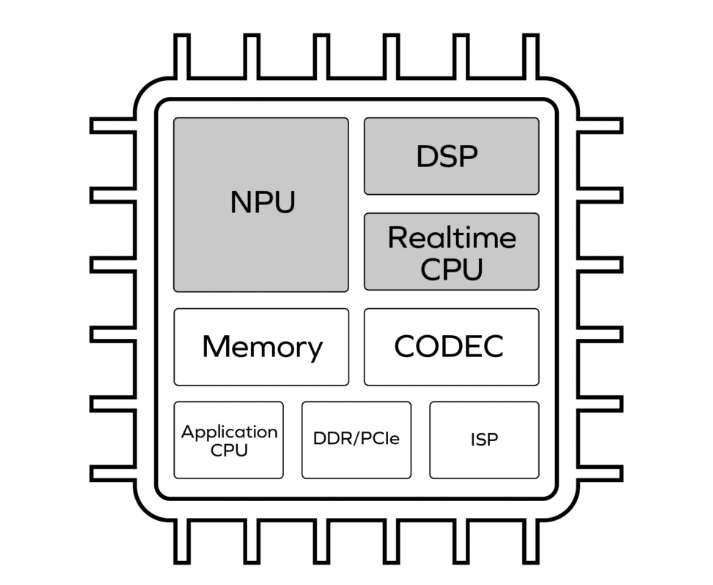
随着芯片技术的发展,系统不再是 “多个相同 CPU 核心” 的简单堆叠,而是集成了 CPU(大核 + 小核)、NPU(神经网络加速器)、ISP(图像信号处理器)、Codec(编解码器)等多种异构处理单元。这些单元共享物理内存,但各自的缓存结构、访问模式差异极大:
-
CPU 注重低延迟的随机访问,缓存层次深(L1/L2/L3);
-
NPU 需要高带宽的批量访问,可能只有简单的 L2 缓存;
-
ISP 和 Codec 则专注于流式数据处理,缓存设计更侧重吞吐量。
-
某些其它特殊功能的核心可能不使用缓存
这种异构系统的缓存一致性挑战远超 SMP:
-
处理单元类型多,无法用统一的协议(如 MESI)管理;
-
访问模式差异大(随机 vs 批量),一致性消息的流量和优先级难以协调;
-
互连结构从共享总线升级为 NoC(片上网络),广播机制效率极低。
这时,CMN(Coherent Mesh Network,一致性网状网络) 就成了异构系统缓存一致性的核心解决方案。
CMN 的核心设计:分布式目录与网状互连
CMN 是 ARM 公司提出的一种片上一致性互连架构,广泛应用于手机 SoC、自动驾驶芯片等异构系统中。它的核心思想是:用分布式目录(Directory)替代总线广播,用 Mesh 拓扑的 NoC 替代共享总线,实现高效的一致性管理。
1. 分布式目录:告别广播,精准定位
CMN 中,每个内存块(通常对应缓存行)都有一个 “目录项”,记录该块在哪些处理单元的缓存中存在,以及当前状态(如共享、独占、修改)。目录项由专门的目录控制器管理,分布在 NoC 的各个节点中。
当一个处理单元要访问某内存块时:
-
先查询目录,找到该块的持有者(如某个 CPU 核心或 NPU);
-
直接向持有者发送一致性请求(如 Invalidate、Read),无需广播;
-
持有者响应请求(如返回数据、标记无效),目录同步更新状态。
这种方式避免了 SMP 总线广播的带宽浪费,特别适合核心数量多的异构系统。
2. Mesh 拓扑 NoC:高带宽、低延迟的互连
CMN 采用 Mesh(网格)拓扑的 NoC,将各个处理单元、目录控制器、内存控制器连接成网状结构。每个节点(如一个 CPU 核心簇、一个 NPU)通过路由器与相邻节点通信,数据按最短路径传输。
这种结构的优势:
-
并行性:多个一致性请求可以在不同路径上并行传输,互不干扰;
-
可扩展性:增加处理单元时,只需扩展 Mesh 的规模,带宽随节点数线性增长;
-
低延迟:通过硬件路由算法(如 XY 路由),数据能快速到达目标节点。
3. 异构单元的 “一致性适配”
CMN 支持不同类型的处理单元接入,通过以下机制适配异构场景:
-
一致性代理(Coherence Agent):对于不支持复杂一致性协议的单元(如 ISP、Codec),CMN 提供专用代理模块,代理它们参与一致性交互。例如,ISP 要修改某内存块时,由代理向目录发送请求,协调其他单元的缓存状态。
-
分层一致性域:将系统划分为多个一致性域(如 CPU 域、NPU 域),域内采用更紧密的一致性策略(如 CPU 的 MESI),域间通过 CMN 的目录协议协调。例如,CPU 大核与小核组成一个域,共享 L3 缓存;NPU 作为独立域,通过 CMN 与 CPU 域交互。
-
QoS 优先级管理:CMN 允许为不同类型的一致性请求设置优先级。例如,自动驾驶芯片中,ISP 的实时图像数据请求优先级高于 Codec 的视频编码请求,确保关键数据的一致性响应不延迟。
缓存一致性与非一致性互连
一致性互连确保系统内的所有进程都拥有统一且一致的内存视图。相比之下,非一致性互连则无法保证这种一致性,可能需要显式的数据管理。一致性互连和非一致性互连之间的选择取决于特定系统的需求和设计考量。在维护缓存一致性的过程中,常见的同步缓存操作包括:
-
flush(刷新):将缓存中已修改的数据写回主存,确保主存中的数据与缓存保持一致,常用于数据持久化场景。
-
clean(清理):与 flush 类似,同样是将缓存中的数据写回主存,但 clean 操作更侧重于在缓存空间不足时,为新数据腾出空间 。
-
invalid(失效):使缓存中的数据失效,不再使用。当其他处理器修改了共享数据时,通过发送无效指令,让相关缓存中的旧数据失效,避免使用过期数据。。
总结:
从单核到异构多核,缓存一致性的解决方案随着系统复杂度提升而不断升级:
-
单核系统:无需考虑一致性,因为只有一个处理单元;
-
SMP 系统:通过总线嗅探 + MESI 协议实现,适合核心数量少的同构场景;
-
异构多核系统:依赖 CMN 等一致性互连架构,通过分布式目录、Mesh NoC 和异构适配机制,解决多类型处理单元的一致性问题。
缓存一致性的本质,是在 “数据共享” 与 “性能效率” 之间寻找平衡。随着芯片集成的处理单元越来越多(如未来的汽车芯片可能集成数十个 CPU 核、上百个 NPU 核),缓存一致性的挑战还会持续升级,但核心思路始终不变 —— 让数据在该一致的时候一致,在不影响正确性的前提下尽可能减少同步开销。
(注:文档部分内容可能由 AI 生成)