《Moco: Momentum Contrast for Unsupervised Visual Representation Learning》论文精读笔记
视频链接:MoCo 论文逐段精读【论文精读】_哔哩哔哩_bilibili
无监督表征模型
预备知识
什么是对比学习?
图1,2 是人,图3是狗,一起输出网络,得到f1,f2,f3三个特征,希望f1和f2在特征空间相邻,f3特征远离。
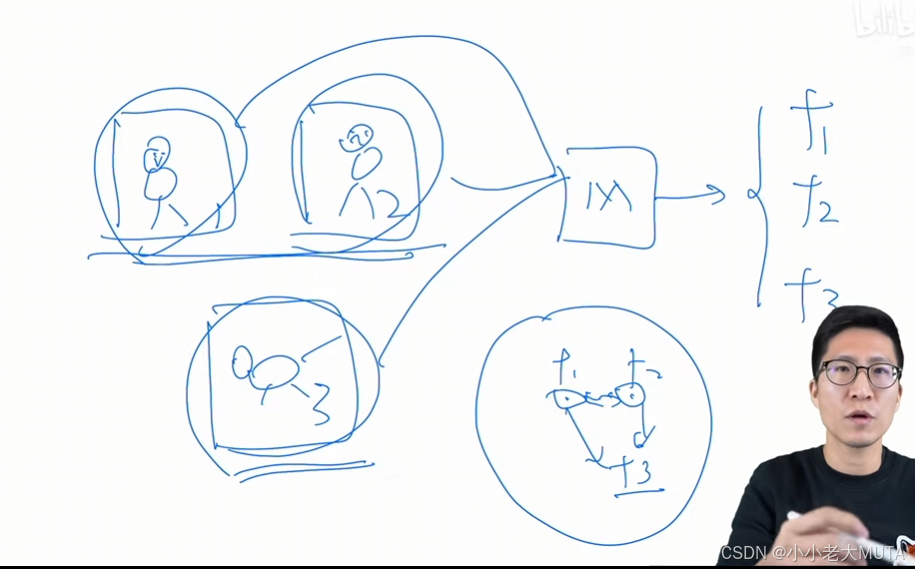
通过代理任务人为定义规则,从而提供监督信号去学习。
什么是代理任务Pretext task?
人为定义哪些图片相似,哪些不相似。
实例判别(Instance Discrimination)是一种在对比学习中使用的技术,通过区分不同实例之间的相似性和差异性来学习有效的特征表示。
例如在一个数据集中,拿出其中一张图片,将一张图片做随机裁剪,得到几张区域照片,这几个区域图片以为从属于同一张图,所以他们的特征相似,规定为正样本,那么数据集中其他的图片就都为负样本。
什么是动量?
题目:Momentum Contrast for Unsupervised Visual Representation Learning
动量对比学习的方法去做无监督的表征学习
什么是Momentum动量?
数学上理解为是加权移动平均:
m:动量,超参数(0-1);
: 上一时刻的输出;
:当前时刻输出;
:当前时刻输入。
摘要
我们提出了动量对比(MoCo)用于无监督视觉表示学习。
从对比学习的角度看,我们将其视为字典查找,构建了一个动态字典,使用队列和移动平均编码器。这使得我们能够实时构建一个大型且一致的字典,从而促进对比无监督学习。
MoCo 在 ImageNet 分类上的常用线性协议下提供了具有竞争力的结果。更重要的是,MoCo 学习到的表示在下游任务中迁移效果良好。在 PASCAL VOC、COCO 和其他数据集的 7 个检测/分割任务中,MoCo 的表现超过了其监督预训练的对手,有时差距甚至很大。这表明,在许多视觉任务中,无监督与监督表示学习之间的差距已经大大缩小。
引言
无监督表示学习在自然语言处理领域取得了显著成功,例如 GPT 和 BERT 的表现。但在计算机视觉中,监督预训练仍然占主导地位,而无监督方法通常落后于其前者。造成这种情况的原因可能源于两者在信号空间上的差异。
语言任务具有离散的信号空间(如单词、子词单元等),可以用于构建基于标记的字典,而无监督学习可以基于此进行。
相反,计算机视觉则涉及字典构建,因为原始信号处于连续的高维空间,并且并不是为了人与人之间的沟通而结构化的(例如,与单词不同)。
一些近期的研究表明,利用与对比损失相关的方法在无监督视觉表示学习中取得了良好的效果。尽管这些方法出发点各异,但可以将其视为构建动态字典。这些字典中的“键”(令牌)从数据中采样(例如,图像或图像块),并由编码器网络进行表示。无监督学习训练编码器进行字典查找:编码的“查询”应与其匹配的键相似,与其他键则应不相似。学习被表述为最小化对比损失。
通过将x1这张图像经过变换得到
和
;
将
通过query 对字典中的key 计算相似度。
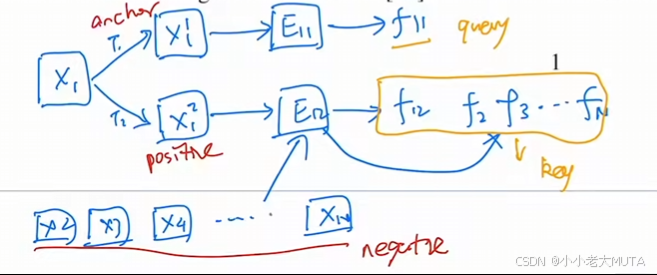
从这个角度(对比学习当作动态字典)来看,我们假设在训练过程中构建的字典应当具备:
(i)大规模和(ii)一致性。
直观地说,较大的字典可能更好地采样潜在的连续高维视觉空间,而字典中的键应由相同或相似的编码器进行表示,以保证它们与查询的比较是一致的。然而,现有使用对比损失的方法可能在这两个方面之一受到限制(稍后将在上下文中讨论)。
(1) 大规模:字典越大,就能更好的从连续的高维视觉特征做抽样。因为字典越大,key越多,所能表示的视觉信息特征就越丰富;更能学习到把物体区分开的本质的特征。
(2) 一致性:字典中的key应该都是通过相同的编码器去产生得到。
我们提出动量对比(MoCo)作为一种构建大型且一致的字典的方法,以用于带有对比损失的无监督学习。
我们将字典维护为数据样本的队列:当前小批次的编码表示被入队,而最旧的样本被出队。该队列将字典大小与小批次大小解耦,使其能够大规模。此外,由于字典键来源于之前的几个小批次,我们提出采用基于动量的移动平均查询编码器来实现缓慢进展的键编码器,从而保持一致性。MoCo 是一种为对比学习构建动态字典的机制,可与各种前置任务结合使用。
受限于显卡的内存,如果一个字典很大,输入很多张图片,没办法一次性处理;
因此作者使用队列的形式,每次前向传播将batch_size大小的图片取出来;
但这样有个问题,每一批次的key不是使用的同一个encoder提取的(这里的相同指的是encoder中的参数相同,每一次更新都会使得参数更新);
所以这里采用了动量方法,将m设置的很大的情况下,很大程度被上一时刻的encoder影响,很小一部分因素收到当前输入的encoder的影响,使得更新缓慢,从而使得字典中的key保持一致性。
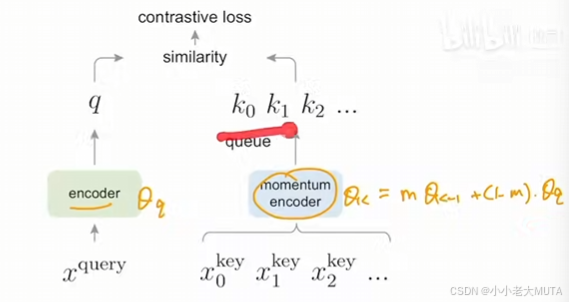
在本文中,我们遵循一种简单的个体判别instance discrimination任务:如果查询和键是同一图像的不同编码视图(例如,不同的裁剪),则它们匹配。
利用这一前置任务,MoCo 在 ImageNet 数据集的线性分类常用协议下显示了具有竞争力的结果。
无监督学习的主要目的之一是预训练可以通过微调转移到下游任务的表示(即特征)。我们展示了在与检测或分割相关的 7 个下游任务中,MoCo 的无监督预训练可以超越其在 ImageNet 上的监督对应模型,在某些情况下差距甚至相当显著。
在这些实验中,我们探索了在 ImageNet 或十亿张 Instagram 图像集上进行预训练的 MoCo,证明了 MoCo 在更真实的十亿图像规模和相对未经过整理的场景下也能良好运作。
这些结果表明,MoCo 在许多计算机视觉任务中大大缩小了无监督与监督表示学习之间的差距,并且可以在多个应用中作为 ImageNet 监督预训练的替代方案。
后续待读~