Go语言unsafe包深度解析
1.引言
Go语言核心设计哲学
Go语言以简洁、高效、并发特性著称,强调类型安全和内存安全,通过自动垃圾回收和严格类型系统降低内存错误风险,为开发者提供可靠编程环境。
unsafe包引入原因
在与底层硬件交互、极致性能优化等特殊场景下,Go的严格类型系统可能受限。unsafe包应运而生,允许绕过类型安全检查,直接操作内存,但使用风险较高。
Go语言特性与unsafe包背景
为什么要有unsafe指针?
unsafe.Pointer 存在的根本原因是为了突破 Go 语言严格的类型安全限制和内存管理限制。直接与底层内存、硬件或外部系统(如 C 库)进行高性能或特殊交互的场景中,提供必要的工具
unsafe指针与普通指针的区别
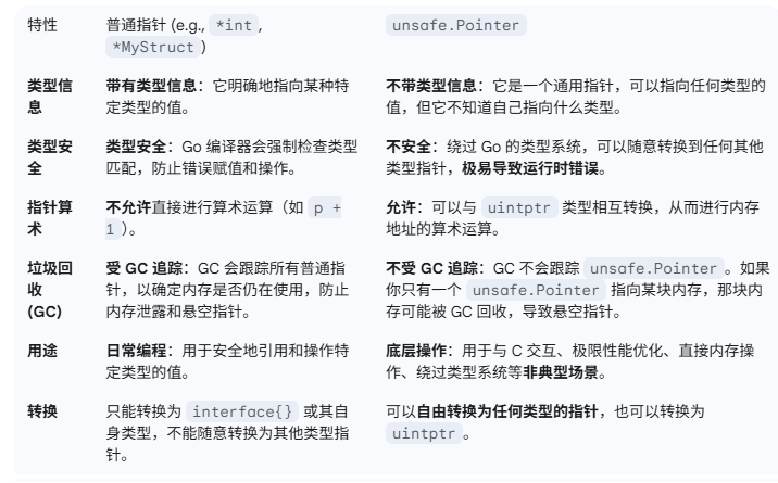
2.unsafe包的由来与核心概念
Go语言类型安全与内存管理机制
Go的类型特性:
Go通过限制指针使用、禁止直接指针算术和不同类型指针转换,确保内存访问合法性,防止悬空指针、缓冲区溢出等问题,保障程序内存安全。 特点:编译时运行
内存管理机制:
Go引入垃圾回收机制,自动管理内存分配和回收,避免C/C++中常见的内存管理复杂性和安全漏洞,简化系统编程。
unsafe包的诞生背景:
Go的类型安全虽有优势,但在特定场景下带来性能或功能挑战。为解决这些问题,unsafe包提供“逃生舱”机制,允许开发者绕过类型和内存安全限制。
unsafe包的核心类型与函数
unsafe.Pointer
源码实现
type ArbitraryType inttype Pointer *ArbitraryType
源码注释:

unsafe.Pointer是特别定义的一种指针类型(译注:类似C语言中的void*类型的指针),它可以包含任意类型变量的地址.
它代表一个指向任意类型的指针 ,可以指向任何数据类型,并且不携带任何类型信息 。
unsafe.Sizeof
unsafe.Sizeof函数返回操作数在内存中的字节大小,参数可以是任意类型的表达式,但是它并不会对表达式进行求值。一个Sizeof函数调用是一个对应uintptr类型的常量表达式,因此返回的结果可以用作数组类型的长度大小,或者用作计算其他的常量。

Sizeof函数返回的大小只包括数据结构中固定的部分,例如字符串对应结构体中的指针和字符串长度部分,但是并不包含指针指向的字符串的内容。
unsafe.Alignof(expression)
unsafe.Alignof 函数返回对应参数的类型需要对齐的倍数。和 Sizeof 类似, Alignof 也是返回一个常量表达式,对应一个常量。
内存对齐
什么是内存对齐呢?
内存对齐就是指数据在内存中的起始地址必须是某个特定数字(对齐值)的倍数。这个“特定数字”通常是 2 的幂次方,比如 1、2、4、8、16 字节。
为什么需要内存对齐呢?
-
CPU 访问效率: CPU 并不是一个字节一个字节地从内存中读取数据。它通常会以为单位(比如 4 字节、8 字节、16 字节)进行批量读取。如果一个数据类型(例如一个 8 字节的
int64)的起始地址不是其字长的倍数,那么 CPU 可能需要:-
进行多次内存访问(比如一次读取前半部分,另一次读取后半部分)。
-
或者进行额外的位移操作来提取所需的数据。 这些都会增加 CPU 的负担,降低程序运行速度。如果数据是对齐的,CPU 就能在一个内存周期内高效地读取整个数据。
-
-
缓存优化: CPU 有高速缓存(Cache),它一次性会加载一块内存数据到缓存中(称为缓存行)。如果数据对齐,并且能完整地放入一个或几个缓存行中,就能提高缓存命中率,进一步提升性能。
有内存对齐,就肯定要有内存对齐规则
-
每个数据类型都有一个默认的对齐值。
-
通常,一个基本数据类型的对齐值等于它在内存中占用的字节数。
-
bool、byte:1 字节对齐 -
int16:2 字节对齐 -
int32、float32:4 字节对齐 -
int64、float64、指针、string(头部)、slice(头部)、interface(头部):8 字节对齐(在 64 位系统上)
-
-
在 Go 语言中,可以通过
unsafe.Alignof()函数来查看任何变量的对齐值。
-
-
结构体(Struct)的对齐值。
-
整个结构体的对齐值是其所有字段中最大那个字段的对齐值。
-
-
填充(Padding)字节。
-
为了满足对齐要求,编译器会在结构体字段之间以及结构体末尾插入额外的填充(Padding)字节。这些填充字节不存储任何实际数据,只是为了确保下一个字段(或下一个结构体实例)能够从正确的对齐地址开始。
-
你可以通过
unsafe.Sizeof()来查看结构体的实际大小,这个大小包含了填充字节。
-
-
结构体总大小必须是对齐值的倍数。
-
即使结构体的所有字段都正确对齐了,如果结构体的总大小不是其自身对齐值的倍数,编译器也会在结构体末尾添加填充字节,以确保当这个结构体作为数组元素或嵌套在其他结构体中时,下一个元素也能正确对齐。
-
unsafe. Offsetof
函数返回结构体中某个字段相对于结构体起始地址的字节偏移量。这个偏移量是考虑了字段大小和内存对齐后,该字段实际开始的字节位置。
目的: 这个函数揭示了编译器在内存中如何排列结构体字段,包括为了对齐而插入的任何填充。
示例:
对于一个结构体:
var x struct {a boolb int16c []int
}
下面显示了对x和它的三个字段调用unsafe包相关函数的计算结果:
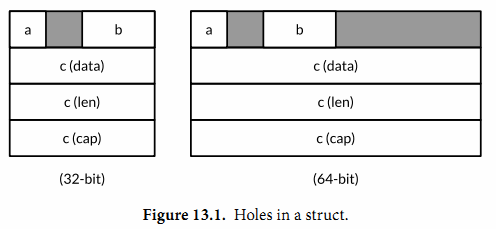
显示了一个结构体变量 x 以及其在32位和64位机器上的典型的内存。灰色区域是空洞。
对于不同的系统计算是不一样的:
32位系统:
Sizeof(x) = 16 Alignof(x) = 4
Sizeof(x.a) = 1 Alignof(x.a) = 1 Offsetof(x.a) = 0
Sizeof(x.b) = 2 Alignof(x.b) = 2 Offsetof(x.b) = 2
Sizeof(x.c) = 12 Alignof(x.c) = 4 Offsetof(x.c) = 464位系统:
Sizeof(x) = 32 Alignof(x) = 8
Sizeof(x.a) = 1 Alignof(x.a) = 1 Offsetof(x.a) = 0
Sizeof(x.b) = 2 Alignof(x.b) = 2 Offsetof(x.b) = 2
Sizeof(x.c) = 24 Alignof(x.c) = 8 Offsetof(x.c) = 8
unsafe.Add(ptr Pointer, len IntegerType) Pointer
此函数将一个偏移量 len 添加到 ptr 指向的地址,并返回一个新的 unsafe.Pointer,代表新的内存地址。这部分地覆盖了之前通过 uintptr 进行指针算术的常见用法,并提供了更清晰的语义 。
unsafe.Slice(ptr *ArbitraryType, len IntegerType)ArbitraryType:
从一个安全指针 ptr 和指定长度 len 创建一个切片。ArbitraryType 是结果切片的元素类型。这允许在不复制数据的情况下将底层数组解释为切片 。
unsafe.String(ptr *byte, len IntegerType) string:
从一个 byte 指针 ptr 和指定长度 len 创建一个字符串。由于Go字符串是不可变的,通过此函数创建的字符串,其底层字节在返回后不应被修改 。 =
unsafe.StringData(str string) *byte:
返回字符串 str 底层字节的指针。对于空字符串,返回值是不确定的,可能为 nil。同样,返回的字节不应被修改 。
unsafe.SliceData(sliceArbitraryType) *ArbitraryType:
返回切片 slice 底层数组的指针。这有助于在不进行额外内存分配的情况下,获取切片底层数据的直接引用 。
示例:
package mainimport ("fmt""unsafe"
)type Employee struct {ID int32Name stringAge int16Active bool
}func main() {emp := Employee{ID: 101, Name: "Alice", Age: 30, Active: true}basePtr := unsafe.Pointer(&emp)fmt.Println(basePtr)ageOffset := unsafe.Offsetof(emp.Age)agePtr := unsafe.Add(basePtr, ageOffset)// add函数是将原始的地址加上一个偏移量,返回一个新的地址fmt.Println(agePtr)data := [5]byte{10, 20, 30, 40, 50}fmt.Printf("原始 Go 数组: %v (地址: %p)\n", data, &data[0])// 使用 unsafe.Slice 将原始数组的底层内存转换为 []byte 切片// 第一个参数是原始内存的起始指针// 第二个参数是切片的长度// 这是 Go 1.17+ 用于安全创建切片的方式slice := unsafe.Slice(&data[0], len(data))fmt.Printf("通过 unsafe.Slice 创建的切片: %v (地址: %p)\n", slice, &slice[0])// 验证地址是否一致 (零拷贝)fmt.Printf("原始数组起始地址 == 切片起始地址? %t\n", unsafe.Pointer(&data[0]) == unsafe.Pointer(&slice[0]))slice[0] = 100fmt.Printf("修改切片后原始数组: %v\n", data) // Output: [100 20 30 40 50]}
运行结果:
0xc0000943a0
0xc0000943b8
原始 Go 数组: [10 20 30 40 50] (地址: 0xc00008c0a8)
通过 unsafe.Slice 创建的切片: [10 20 30 40 50] (地址: 0xc00008c0a8)
原始数组起始地址 == 切片起始地址? true
修改切片后原始数组: [100 20 30 40 50]3.unsafe包的应用场景与代码示例
不同类型间的零拷贝转换:
Go通常不允许不同类型间直接零拷贝转换,unsafe包打破限制,实现底层内存布局兼容的类型转换,避免内存分配和复制,提高性
package mainimport ("fmt""reflect""unsafe"
)// Float64bits 返回 f 的 IEEE 754 浮点数的二进制表示
func Float64bits(f float64) uint64 {return *(*uint64)(unsafe.Pointer(&f)) // 将 float64 的地址转换为 *uint64 类型,然后解引用
}// Float64frombits 返回 IEEE 754 浮点数的二进制表示 b 对应的 float64 值
func Float64frombits(b uint64) float64 {return *(*float64)(unsafe.Pointer(&b)) // 将 uint64 的地址转换为 *float64 类型,然后解引用
}func main() {f := 3.1415926535bits := Float64bits(f)fmt.Printf("Original float64: %f\n", f)fmt.Println(reflect.TypeOf(bits).Name())newFloat := Float64frombits(bits)fmt.Println(reflect.TypeOf(newFloat).Name())fmt.Printf("Converted back: %f\n", newFloat)// 演示byte 和 string 的零拷贝转换byteSlice := []byte{'H', 'e', 'l', 'l', 'o', ' ', 'G', 'o'}fmt.Printf("原始 byteSlice 地址: %p\n", &byteSlice[0])// 将byte 转换为 string,避免复制。// 注意:转换后的 string 不应再修改原始 byteSlice 的内容。s := unsafe.String(unsafe.SliceData(byteSlice), len(byteSlice))fmt.Printf("转换为 string (s) 的底层数据地址: %p\n", unsafe.StringData(s))fmt.Printf("Byte slice to string (zero-copy): %s\n", s)// 将 string 转换为byte,避免复制。// 注意:转换后的byte 不应修改,因为原始 string 是不可变的。b := unsafe.Slice(unsafe.StringData(s), len(s))fmt.Printf("转换为 []byte (b) 的底层数据地址: %p\n", unsafe.SliceData(b))fmt.Printf("String to byte slice : %v\n", b)
}
运行结果:
Original float64: 3.141593
uint64
float64
Converted back: 3.141593
原始 byteSlice 地址: 0xc00000a128
转换为 string (s) 的底层数据地址: 0xc00000a128
Byte slice to string (zero-copy): Hello Go
转换为 []byte (b) 的底层数据地址: 0xc00000a128
String to byte slice : [72 101 108 108 111 32 71 111]
结构体内部字段的直接访问与修改:
Go语言的结构体字段默认是可访问的,但对于未导出的(小写字母开头)字段,外部包无法直接访问。unsafe 包可以绕过这种访问限制,允许直接通过内存地址计算来访问和修改结构体的任何字段,包括未导出的字段 。
package mainimport ("fmt""unsafe"
)type MyStruct struct {id int // 未导出字段Name string // 导出字段
}func main() {s := MyStruct{id: 123,Name: "Original Name",}fmt.Printf("Original struct: %+v\n", s)// 1. 通过 unsafe.Offsetof 获取未导出字段 id 的偏移量idOffset := unsafe.Offsetof(s.id)fmt.Printf("Offset of 'id' field: %d bytes\n", idOffset)// 2. 获取结构体 s 的内存地址,并转换为 uintptrsPtr := uintptr(unsafe.Pointer(&s))// 3. 计算 id 字段的内存地址idAddr := sPtr + idOffset// 4. 将 id 字段的内存地址转换为 *int 类型指针,并修改其值idPtr := (*int)(unsafe.Pointer(idAddr))*idPtr = 456fmt.Printf("Modified struct: %+v\n", s)// 验证修改是否成功fmt.Printf("Accessing modified id: %d\n", s.id)}
运行结果;
Original struct: {id:123 Name:Original Name}
Offset of 'id' field: 0 bytes
Modified struct: {id:456 Name:Original Name}
Accessing modified id: 456具体性能提升:
这里从类型转化和字段修改,两个方面具体,通过测试体现出使用unsafe的速度提升:
可以看出由于unsafe直接可以操作底层内存,对于性能的提升是很大的。
类型转换:
package mainimport ("fmt""strings""testing" // 导入 testing 包,用于基准测试函数"unsafe"
)// stringFromBytesSafe 是安全、常规的 []byte 到 string 转换(有复制)
func stringFromBytesSafe(b []byte) string {return string(b)
}// stringFromBytesUnsafe 是不安全、零拷贝的 []byte 到 string 转换
func stringFromBytesUnsafe(b []byte) string {// 确保传入的 []byte 在 string 的生命周期内不会被修改!return unsafe.String(unsafe.SliceData(b), len(b))
}func main() {// 创建一个大字节切片,模拟需要转换的数据data := []byte(strings.Repeat("A", 1024*1024)) // 1MB 的字节数据fmt.Println("--- []byte 到 string 转换性能比较 ---")// 模拟基准测试,实际项目中应使用 go test -bench=.fmt.Println("运行安全转换 (string(b))...")safeResult := testing.Benchmark(func(b *testing.B) {for i := 0; i < b.N; i++ {_ = stringFromBytesSafe(data)}})fmt.Printf("安全转换平均耗时: %s/op\n", safeResult.T)fmt.Printf("安全转换平均内存分配: %d B/op (每次操作的内存分配量)\n", safeResult.AllocedBytesPerOp())fmt.Printf("安全转换平均内存分配次数: %d allocs/op\n", safeResult.AllocsPerOp())fmt.Println("\n运行不安全零拷贝转换 (unsafe.String())...")unsafeResult := testing.Benchmark(func(b *testing.B) {for i := 0; i < b.N; i++ {_ = stringFromBytesUnsafe(data)}})fmt.Printf("不安全转换平均耗时: %s/op\n", unsafeResult.T)fmt.Printf("不安全转换平均内存分配: %d B/op\n", unsafeResult.AllocedBytesPerOp())fmt.Printf("不安全转换平均内存分配次数: %d allocs/op\n", unsafeResult.AllocsPerOp())
}
--- []byte 到 string 转换性能比较 ---
运行安全转换 (string(b))...
安全转换平均耗时: 1.0996818s/op
安全转换平均内存分配: 1048583 B/op (每次操作的内存分配量)
安全转换平均内存分配次数: 1 allocs/op运行不安全零拷贝转换 (unsafe.String())...
不安全转换平均耗时: 320.9903ms/op
不安全转换平均内存分配: 0 B/op
不安全转换平均内存分配次数: 0 allocs/op
修改结构体字段:
package mainimport ("fmt""reflect""testing" // 导入 testing 包,用于基准测试"unsafe"
)type MyData struct {id intname stringvalue float64
}// 通过 unsafe 直接修改私有字段 'id'
func unsafeSetID(data *MyData, newID int) {basePtr := unsafe.Pointer(data)idOffset := unsafe.Offsetof(data.id)idPtr := unsafe.Add(basePtr, idOffset)*(*int)(idPtr) = newID
}type MyDataPublic struct {ID int // 公共字段name stringvalue float64
}// 通过 reflect 修改公共字段 'ID'
func reflectSetID(data *MyDataPublic, newID int) {v := reflect.ValueOf(data).Elem()idField := v.FieldByName("ID")idField.SetInt(int64(newID))
}func main() {privateData := &MyData{id: 1, name: "private", value: 1.23}publicData := &MyDataPublic{ID: 1, name: "public", value: 1.23}// 基准测试:通过 unsafe 修改私有字段 'id'fmt.Println("unsafe 修改私有字段 'id':")unsafeResult := testing.Benchmark(func(b *testing.B) {for i := 0; i < b.N; i++ {unsafeSetID(privateData, i)}})fmt.Printf(" 平均耗时: %s/op\n", unsafeResult.T)fmt.Printf(" 内存分配: %d B/op (bytes allocated per operation)\n", unsafeResult.AllocedBytesPerOp())fmt.Printf(" 分配次数: %d allocs/op (allocations per operation)\n", unsafeResult.AllocsPerOp())// 基准测试:通过 reflect 修改公共字段 'ID'fmt.Println("\nreflect 修改公共字段 'ID':")reflectResult := testing.Benchmark(func(b *testing.B) {v := reflect.ValueOf(publicData).Elem()idField := v.FieldByName("ID")b.ResetTimer() // 重置计时器,从这里开始测量for i := 0; i < b.N; i++ {idField.SetInt(int64(i))}})fmt.Printf(" 平均耗时: %s/op\n", reflectResult.T)fmt.Printf(" 内存分配: %d B/op\n", reflectResult.AllocedBytesPerOp())fmt.Printf(" 分配次数: %d allocs/op\n", reflectResult.AllocsPerOp())}
运行结果:
unsafe 修改私有字段 'id':平均耗时: 213.3485ms/op内存分配: 0 B/op (bytes allocated per operation)分配次数: 0 allocs/op (allocations per operation)reflect 修改公共字段 'ID':平均耗时: 1.1784909s/op内存分配: 0 B/op分配次数: 0 allocs/op
具体使用案例:
unsafe在GO标准库使用:
reflect 包
runtime包
bytes 包和 strings 包
go内置的还有map、slice、chan 等
unsafe在第三方库使用:
jsoniter/go (json-iterator/go):(高性能JSON库)
valyala/fasthttp:(高性能HTTP框架)
高性能核心:
规避不必要的内存分配和数据复制。
绕过运行时类型系统和反射的开销,直接与内存打交道。
4.使用unsafe包的风险
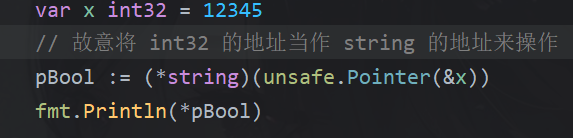
1. 破坏类型安全
如果你转换的类型与实际内存中的数据不匹配,那么在解引用或操作时,就会读取到无意义的数据,或者更糟糕,导致程序崩溃(panic)。
2.悬空指针 (Dangling Pointers) 和垃圾回收问题
首先我们要先理解Go GC工作方式(这里作简要描述):
Go GC 的工作方式
Go 语言的垃圾回收器是精确的 (precise)。这意味着 GC 能够准确地识别内存中的哪些值是指针,以及这些指针指向了哪里。为了做到这一点,GC 严重依赖于 Go 语言在编译时和运行时维护的类型信息。
当 GC 扫描内存时,它会:
知道每个对象的类型:
根据类型信息追踪指针:
如果 GC 发现某个对象没有任何活跃的指针指向它(即从根对象,如全局变量、活跃 Goroutine 的栈等,都无法到达它),那么 GC 就会认为这个对象是“垃圾”,可以在后续阶段将其内存回收。
为什么会出现这个问题?
unsafe.Pointer的设计目的就是为了摆脱类型信息,它只是一个纯粹的内存地址。
1.GC无法跟踪unsafe.Pointer所指向的对象:
当 Go GC 看到一个 unsafe.Pointer 时,它不知道这个指针指向的内存区域包含什么类型的数据。它无法判断这个内存区域里是否有其他 Go 对象指针,也无法判断这个 unsafe.Pointer 是否是某个 Go 对象的唯一“活着”的引用。
因此,Go GC 明确选择不追踪 unsafe.Pointer 本身所指向的内存。它将其仅仅视为一个普通的数字 (uintptr)
2.悬空指针的产生:
由于 GC 不追踪 unsafe.Pointer 所指向的对象,这可能导致一个严重的后果:当你通过 unsafe.Pointer 获得了某个 Go 对象的内存地址,但这个对象却没有其他 “可追踪的 Go 指针” 指向它时,GC 可能会错误地认为这个对象是垃圾并将其回收。
这时unsafe.Pointer 就变成了一个“悬空指针”。
如何避免
1.你所操作的内存区域不会在其生命周期内被 GC 回收,除非你已经明确知道并处理了回收后的行为。
2.通常情况下,你所操作的 Go 对象至少有一个普通 Go 指针在活跃地引用它,从而阻止 GC 回收它。
5.unsafe包的替代方案与常规方法
1.性能优化方面:
优化数据结构布局 (内存对齐):
算法和数据结构的优化:
2.绕过类型系统
Go 1.18+ 的泛型:
访问私有字段:reflect 包
6.总结
价值:
unsafe包为Go语言提供底层内存操作能力,在特定场景下实现极致性能和灵活性,是Go生态系统的重要补充。
限制:
使用unsafe面临非可移植性、安全问题、未定义行为和调试困难等风险,
文章参考:unsafe.Pointer - Go语言圣经
深度解密Go语言之unsafe - Stefno - 博客园
unsafe package - unsafe - Go Packages