常见sql深入优化( 二)
这里写目录标题
- 分页优化
- 原因:
- 优化:
- jion关联查询优化
- NLJ算法
- BNL算法
- 区别
- 对于关联SQL的优化
- count查询优化
本次用到的数据库表
app_user :100w条数据
app_userw: 10w条数据
分页优化
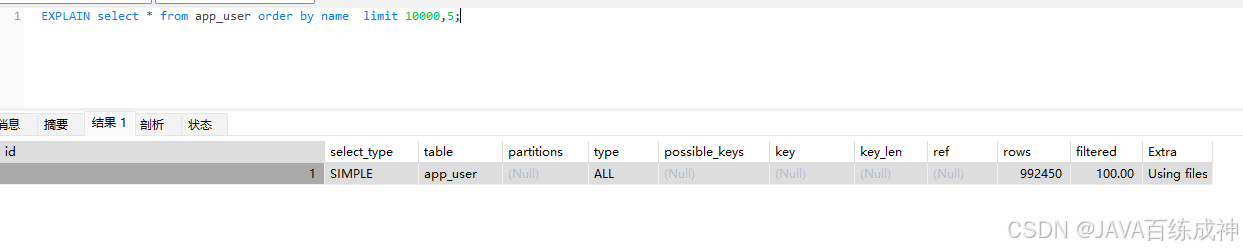
EXPLAIN select * from app_user order by name limit 10000,5; 想过滤出10000后面的用户名出来,但是没有走name的索引
原因:
优化器认为 “全表扫描 + 排序” 比 “走索引” 更高效
即使name上有 B-tree 索引,优化器也可能选择不使用,核心原因是使用索引的成本更高:
索引需要 “回表” 查询:你的查询是select *(获取所有字段),而name索引只包含name和主键id。如果用name索引,需要先通过索引找到id,再回到主键索引查其他字段(回表操作)。当偏移量很大(limit 10000,5需要跳过 1 万行),回表次数太多,优化器可能认为还不如全表扫描后直接排序更划算。
优化:
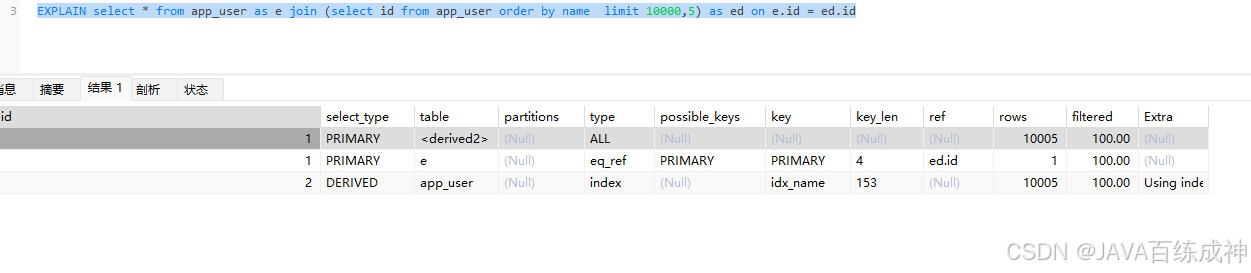
select * from app_user as e join (select id from app_user order by name limit 10000,5) as ed on e.id = ed.id
让子查询(select id from app_user order by name limit 10000,5)走name索引,避免全表扫描和排序。
确保主查询select * from app_user as e join …通过id快速关联,利用主键索引。
jion关联查询优化
先查看执行计划
EXPLAIN select * from app_user t1 JOIN app_userw t2 on t1.name = t2.name
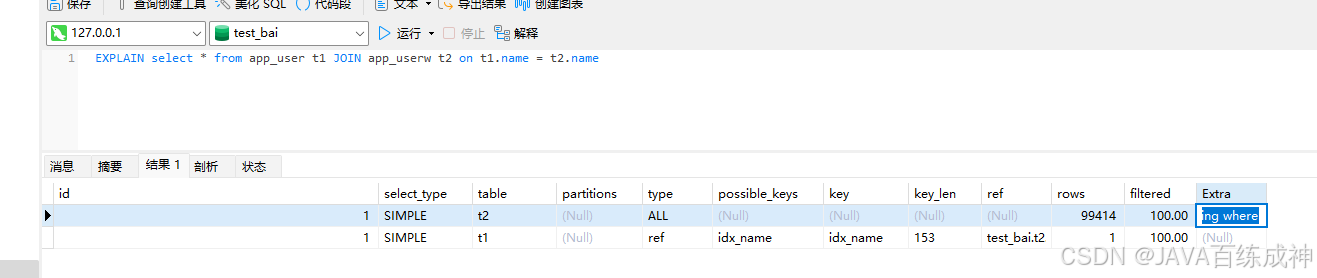
执行过程先执行t2表,因为t2表只有10w条数据所以mysql会先拿小表做驱动表 大表做被驱动表,执行完t2表拿到数据后在关联t1表把结果返回。这次查询优化器使用了NLJ算法,因为id有索引所以每次拿T2的结果去t1匹配一行,如果没有索引就要匹配1百亿行。
因为没有索引会使用BNL算法
拿t1的每一条数据也就是100w条数据去匹配t2的1w条数据。
小表的定义:不是按数据量来判断,而是通过关联的数据来判断,如果100w的数据库表里面有10条要关联的数据那么他也是算小表。
NLJ算法
一、NLJ 算法的基本原理
NLJ 算法的核心是 “外层循环” 和 “内层循环” 的嵌套执行,类似编程语言中的嵌套循环:
选择驱动表(外层表):通常是数据量较小的表,或被索引优化的表。
外层循环:遍历驱动表的每一行记录。
内层循环:对于外层表的每一行,到被驱动表(内层表)中查找满足连接条件(t1.name = t2.name)的记录。
结果合并:将匹配的记录组合后返回。
优势:当驱动表较小,且被驱动表上有连接字段的索引时,效率较高。
劣势:若驱动表数据量大,或被驱动表无索引,内层循环会频繁全表扫描,性能极差(时间复杂度接近 O (N*M),N 为驱动表行数,M 为被驱动表行数)。
BNL算法
一、BNL 算法的核心原理
当被驱动表没有合适的索引时,NLJ 算法会对被驱动表进行全表扫描(内层循环效率极低)。BNL 算法通过 “批量处理外层数据” 来减少内层循环的全表扫描次数,核心思路是:
将驱动表(外层表)的数据分块加载到内存缓冲区(join buffer):
缓冲区大小由 join_buffer_size 参数控制(默认 256KB,可调整),一次加载多行会减少 I/O 次数。
用缓冲区中的所有驱动表数据,批量匹配被驱动表(内层表)的一行数据:
遍历被驱动表的每一行时,同时与缓冲区中所有驱动表的行比较连接条件(如 t1.name = t2.name),匹配则合并结果。
循环处理所有数据块:
若驱动表数据量超过缓冲区大小,会分多块处理,每块重复步骤 2。
1.简单来说把t2的数据放到了join buff的缓冲区
2.然后在把t1的数据取出来一条条的跟join buff里面的数据去做对比
3.返回满足join的数据
区别
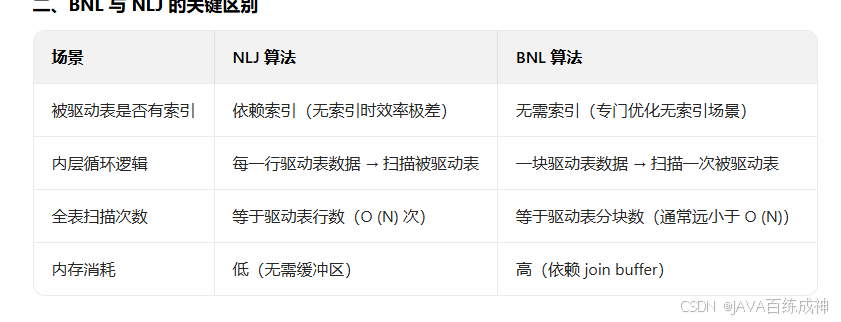
还有一个区别就是BNL是内存扫描,NLJ是硬盘扫描,所以在没有索引的情况下使用BNL算法是最快的。内存速度》硬盘速度
对于关联SQL的优化
1.使用小表驱动大表,有时候myql也会选择错误,需要手动去查原因
这时候就可以使用STRAIGHT_JOIN 来强制 t1 作为驱动表,t2 作为被驱动表
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.id = t2.t1_id;
但是尽量使用优化器的选择因为人为使用的STRAIGHT_JOIN 不一定有优化器优化的好。
2.关联字段加索引,让mysql尽量选择NLJ算法。
count查询优化
以下四条查询的差别
explain SELECT count(1) from app_user
explain SELECT count(id) from app_user
explain SELECT count(name) from app_user
explain SELECT count(*) from app_user根据查询可以发现count()扫描的行数跟以上三条的行数都是一样的没什么差别,说明他们四个的执行效率都是差不太多的。

字段有索引:count() ≈ count(1) ≥ count(字段) > count(主键)
字段有索引所以count统计走二级索引,二级索引比count主键索引少所以count的速度大于主键索引的速度。
字段没索引:count(*) ≈ count(1) ≥ count(主键) > count(字段)
因为字段没索引主键id还能走索引,所以主键速度比字段快
count(1)和count(字段)执行结果相似,count(1)只需要存储1的个数(常量值)来判断有多少个,但是count(字段)需要取出字段在通过计数器来计数,所以理论上count(1)比count(字段)快一些
count()是例外,count()不会把任何字段的数据取出来,mysql专门做了优化不取值而是按行来累加,效率更高,所以不需要用count(1)或者count(常量)来替代count(*)