语义分割-FCN-听课记录
1.视频课1:FCN论文解读


翻译:
卷积网络是一种强大的视觉模型,能够产生层次化的特征。我们证明了**仅使用卷积网络本身,采用端到端、像素到像素的训练方式**,即可在语义分割任务中**超越现有最佳结果**。
我们的核心洞见在于构建“**全卷积网络**”(Fully Convolutional Networks),这种网络**可以接收任意尺寸的输入,并生成对应尺寸的输出**,同时具备高效的推理和学习能力。
我们定义并详细阐述了全卷积网络的设计空间,解释了其在**空间密集型预测任务**中的应用,并**与先前模型建立了联系**。
我们将现代分类网络(AlexNet、VGGNet 和 GoogLeNet)**改造为全卷积网络**,并通过**微调**将其学习到的表示迁移到语义分割任务中。
此外,我们设计了一种**跳跃结构(skip architecture)**,将**深层粗糙的语义信息**与**浅层精细的表观信息**相结合,从而生成**准确且细节丰富的分割结果**。
我们的全卷积网络在 PASCAL VOC(2012 年数据集上相对提升 20%,达到 62.2% 的 mean IU)、NYUDv2 和 SIFT Flow 数据集上均达到了**当时的最佳分割精度**,且对典型图像的推理时间**不到 0.2 秒**。
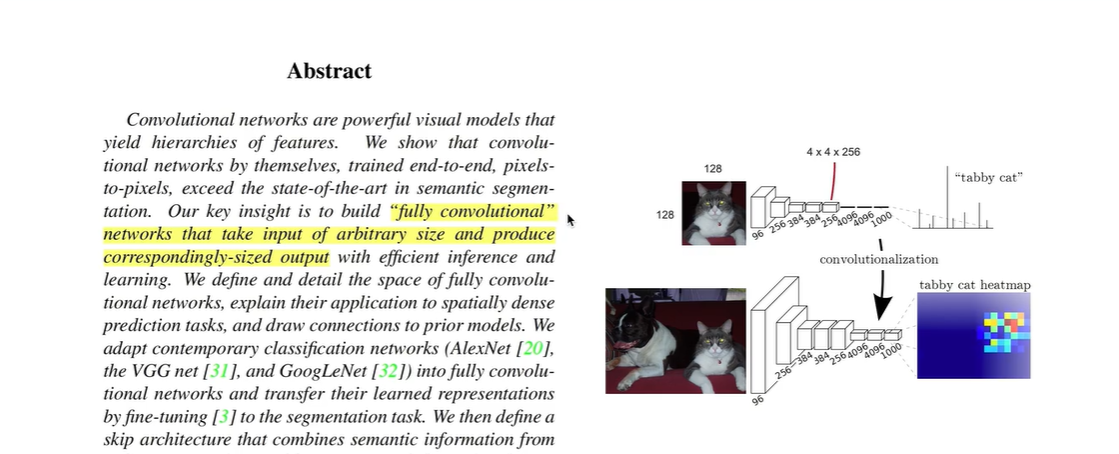
使用全卷积层 替换 全连接层
使用全连接层,则输入固定位4X4X256=4096,这就要求图像固定大小(128x128))
使用全卷积层,对输入图像的尺寸大小没有限制。

骨干网络使用 当时流行的分类网络(VGGnet, GoogLeNet)
up这里使用 改动的 ResNet
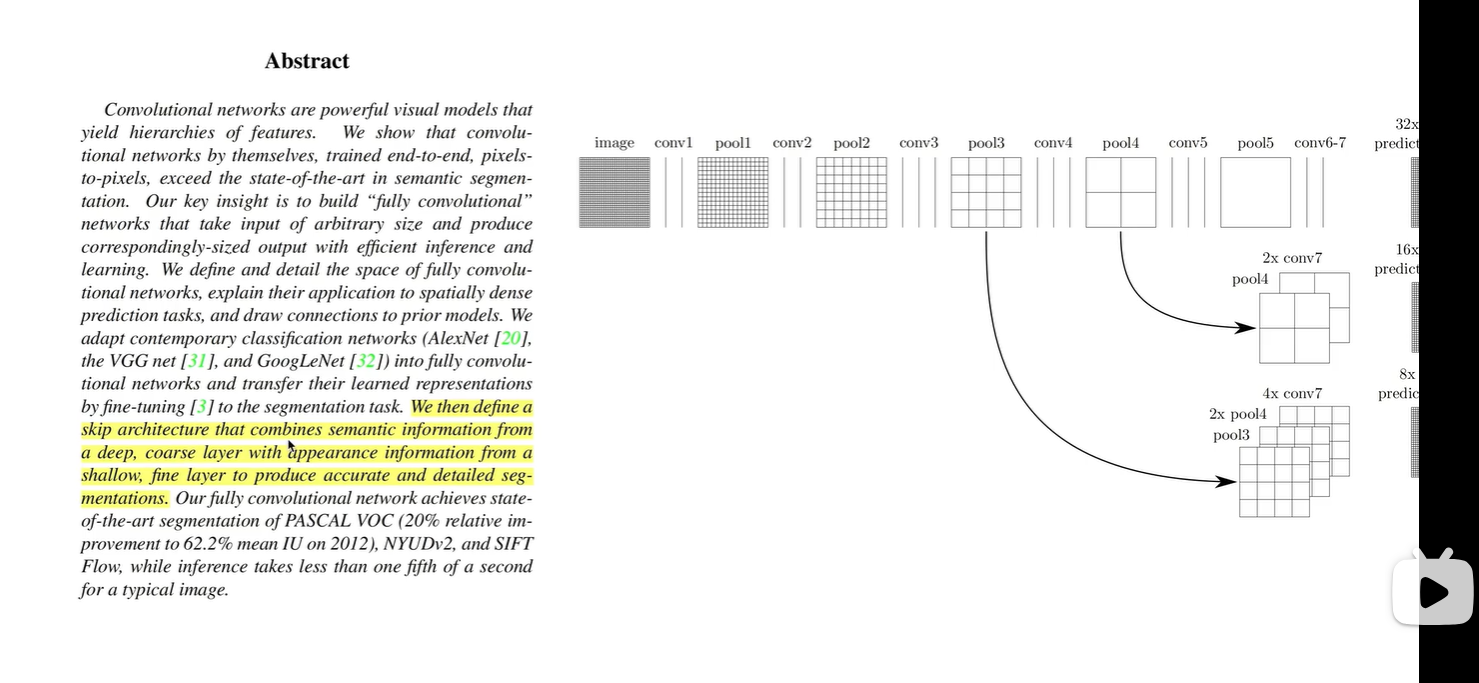
使用跨层结构,将深层的、更粗颗粒的语义信息 与 浅层、更细颗粒的表层信息 相结合,
产生更精确的分割结果
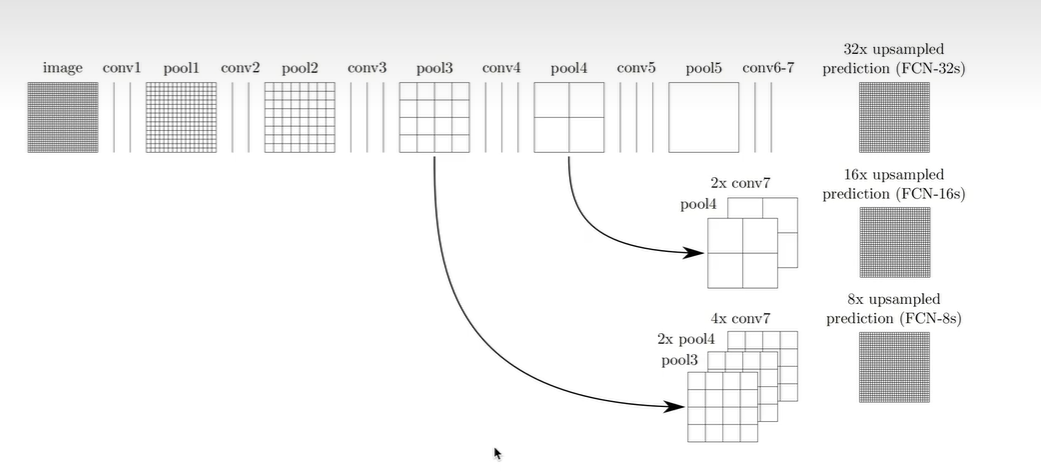
观察上图,
(1)将conv7上采样2倍,然后与pool4拼接,再进行上采样16倍,得到与原图尺寸大小相同的输出
(2)将conv7上采样4倍,pool4上采样2倍,然后与pool3进行拼接,再上采样8倍,得到与原图尺寸大小相同的输出
注意:
最右边3个图,不是三个输出头, 而是分别对应三种输出方案
2.视频课2:膨胀卷积
膨胀卷积_哔哩哔哩_bilibili
见之前记录
3.视频课3:转置卷积
转置卷积_哔哩哔哩_bilibili
见之前记录
4.视频课4:模型搭建-网络讲解
模型搭建 - 网络讲解_哔哩哔哩_bilibili
将代码分成三个阶段讲解:traiin-训练阶段, evaluation-验证阶段,predict-测试阶段
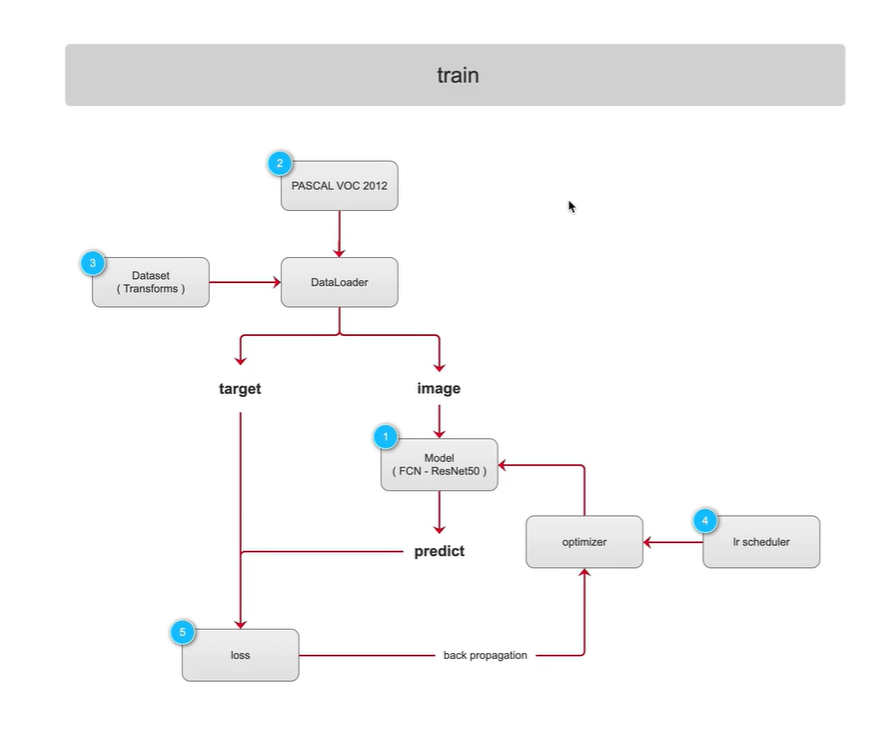
back propagation 反向传播
scheduler 调度器,时间调度员
重点:
搭建以ResNet50为骨干的 FCN网络
PASCAL_VOC数据集介绍
Dataset(Transforms) 如何对数据集进行预处理
lr scheduler 学习率调度器,观察学习策略,在整个训练过程中是如何变化的
loss是如何计算的, 主网络和辅佐网络输出在 损失函数中起到什么作用
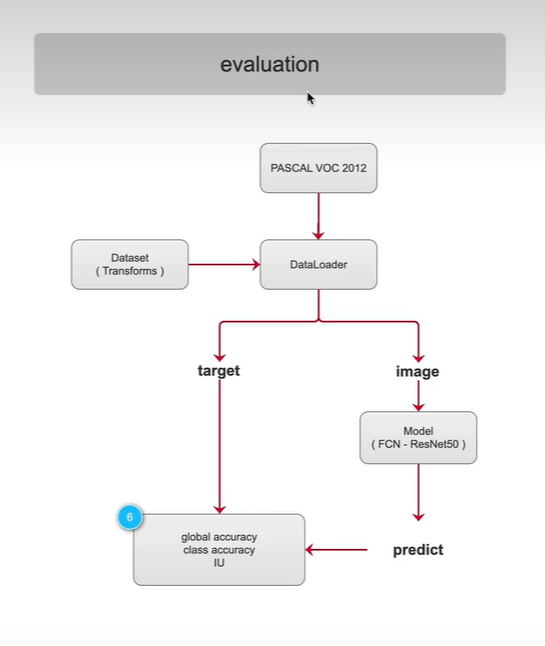
在验证阶段:
参看语义分割的三个指标,以及是如何定义的,如何计算,代码实现
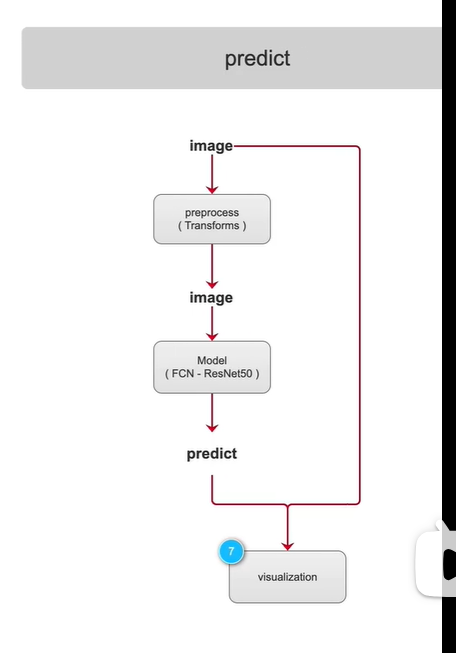
测试阶段:
将原图和可视化化结果一并显示出来,肉眼评估检测效果
训练阶段-train
模型搭建
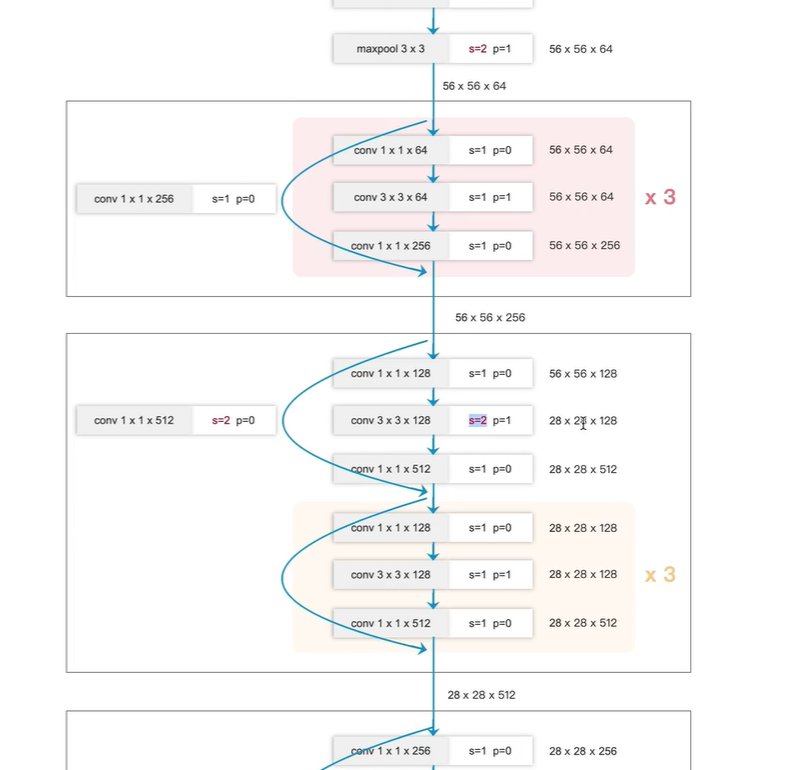
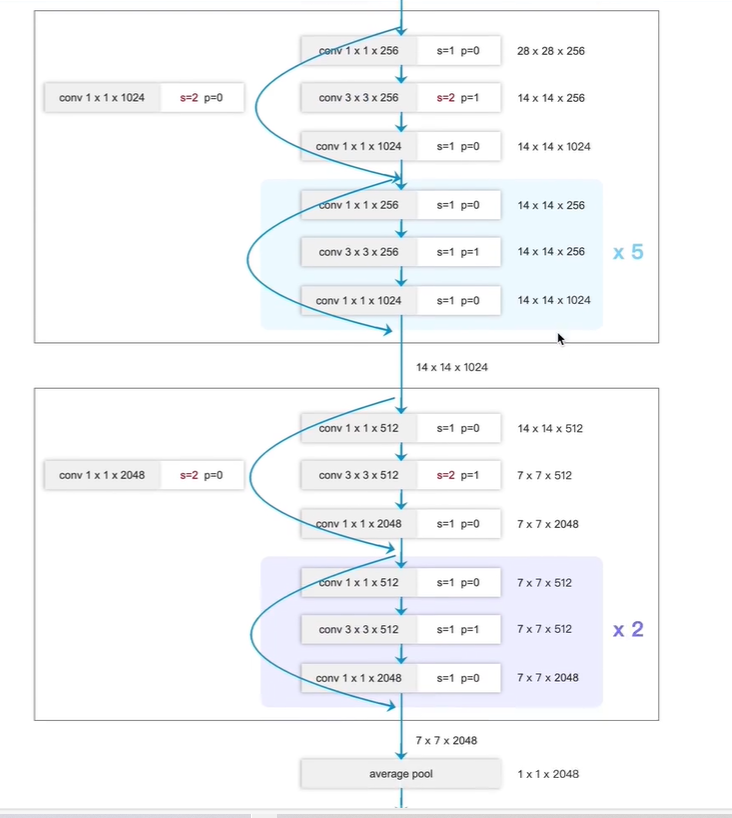
ResNet-50分类网络
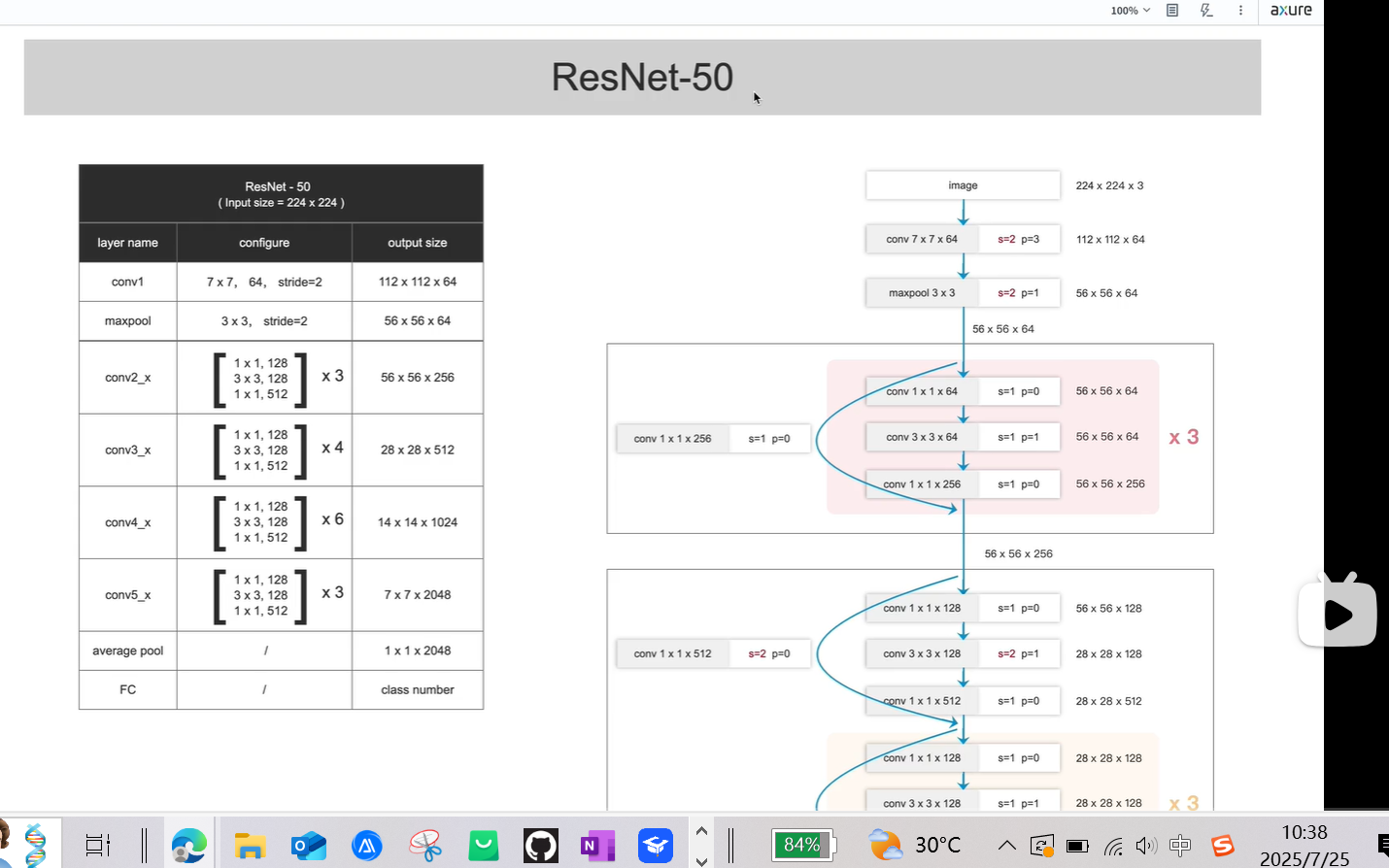
左边图:
4个block,
第一个block有3个残差块;
第二个block有4个残差块;
第三个block有6个残差块;
第四个block有3个残差块;
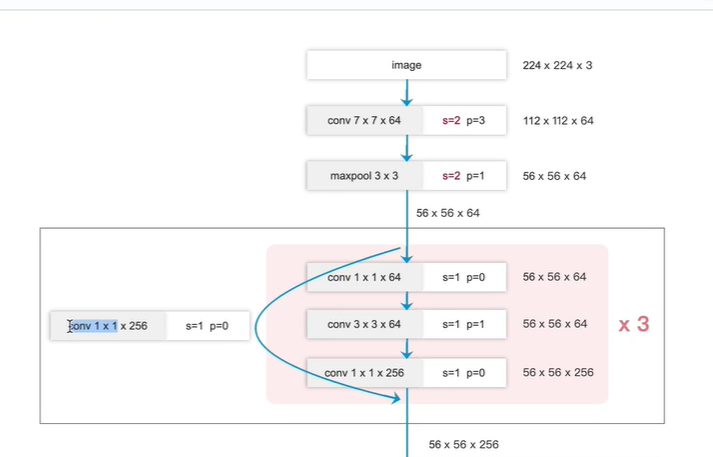
输出类别数
ImageNet 数据集 ,类别数1000
PASCAL_VOC数据集, 类别数 20
MS_COCO数据集, 类别数80
FCN-ResNet-50
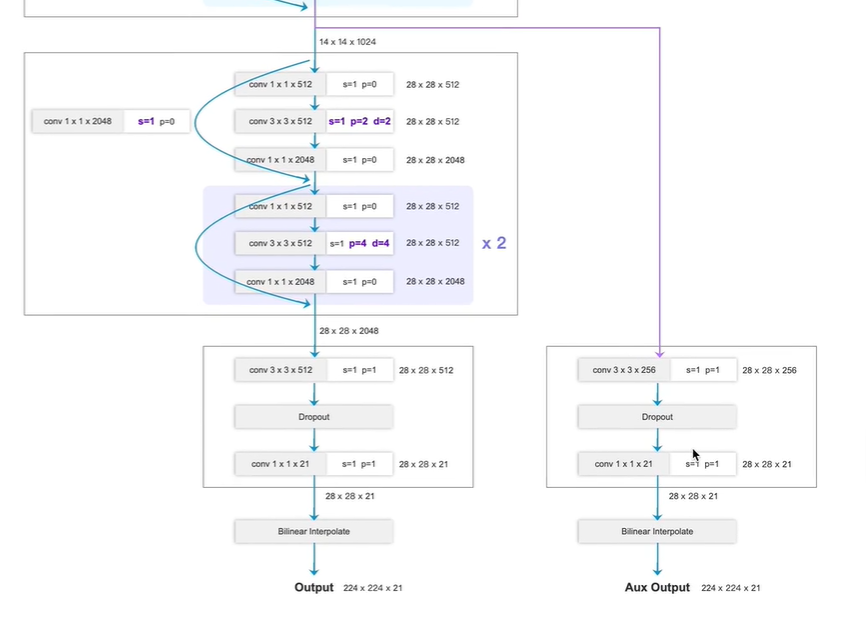
对ResNet-50进行改造,使其更适合语义分割任务
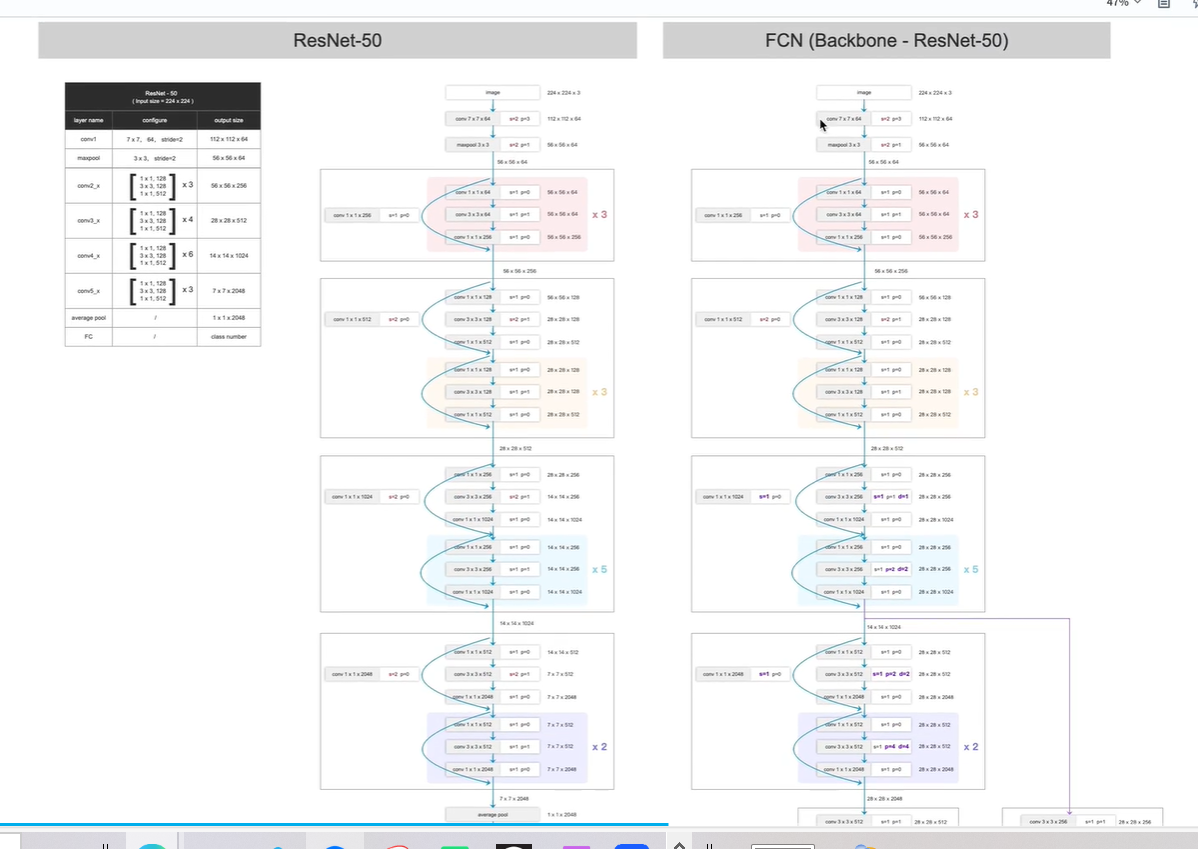
改进点1:
改动block3,4
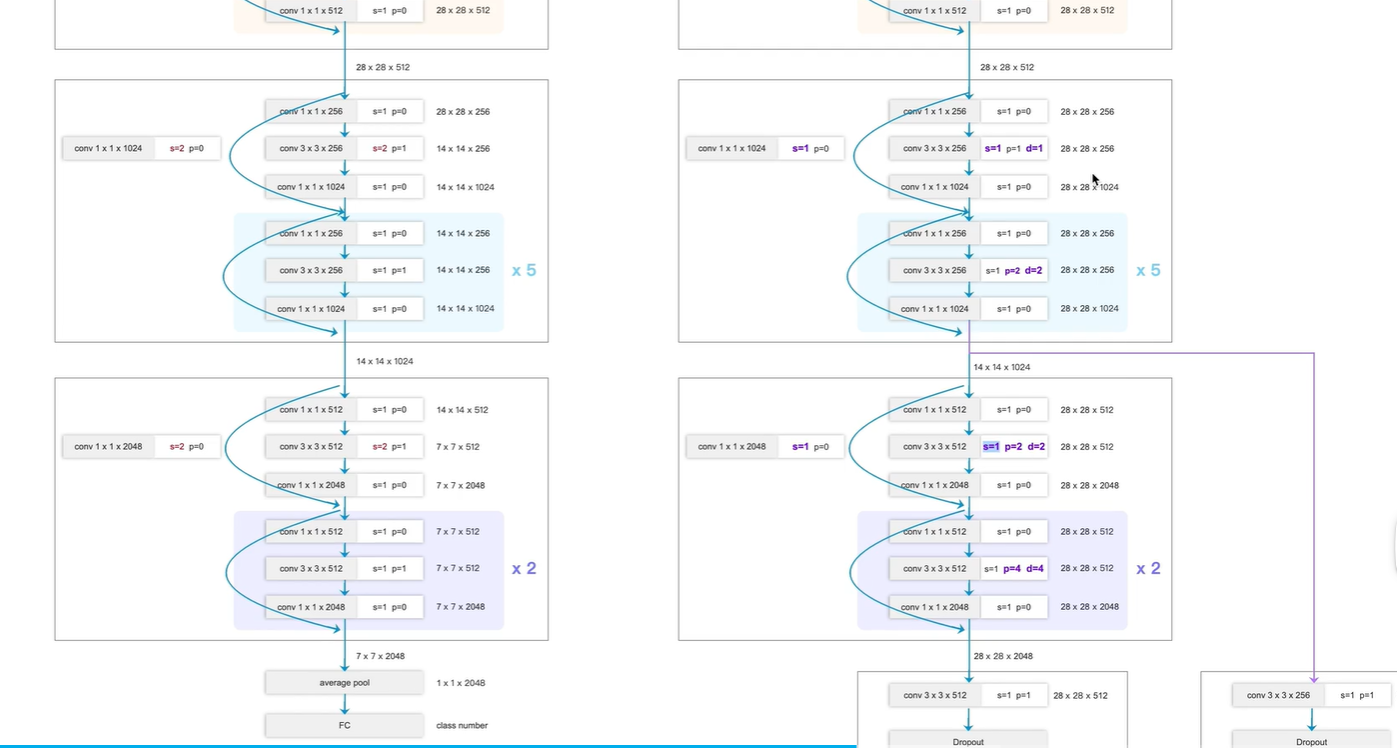
原本分类网络block4,5均是 进行2倍下采样, s=2
现在,FCN-ResNet-50,取消两倍下采样, s=1
为什么不进行下采样, FCN最终输出是需要将下采样的特征图还原到原图尺寸大小
因为如果下采样,则 从7x7 上采样到 224x224, 会丢失很多细节信息
因此,选择从 28x28上采样到224x224

卷积从普通卷积 改变 使用 d=1的膨胀卷积, (注意:d=1 ,就是一个普通卷积)

这里d=2
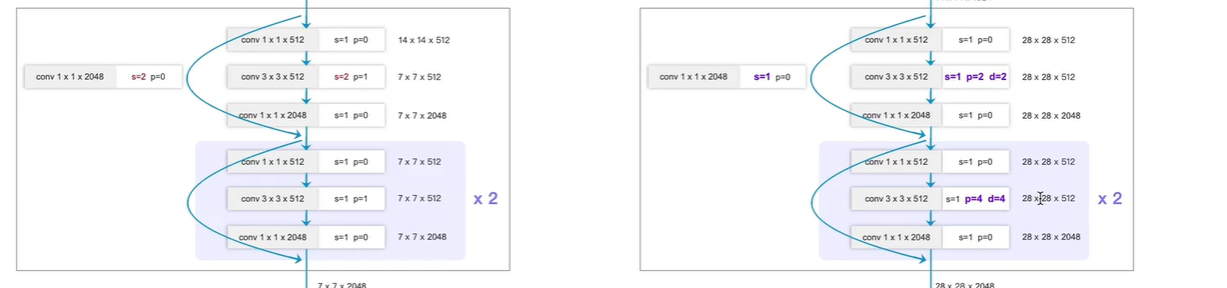 改变:s=1,不进行下采样,p,d也进行改变
改变:s=1,不进行下采样,p,d也进行改变
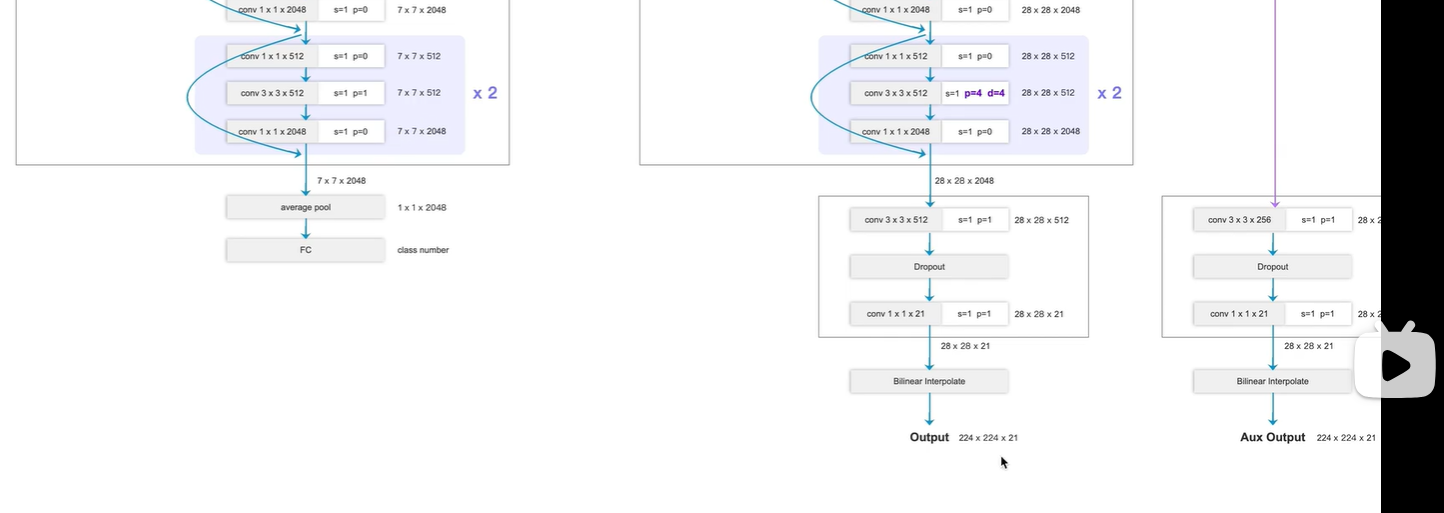
改变点2:
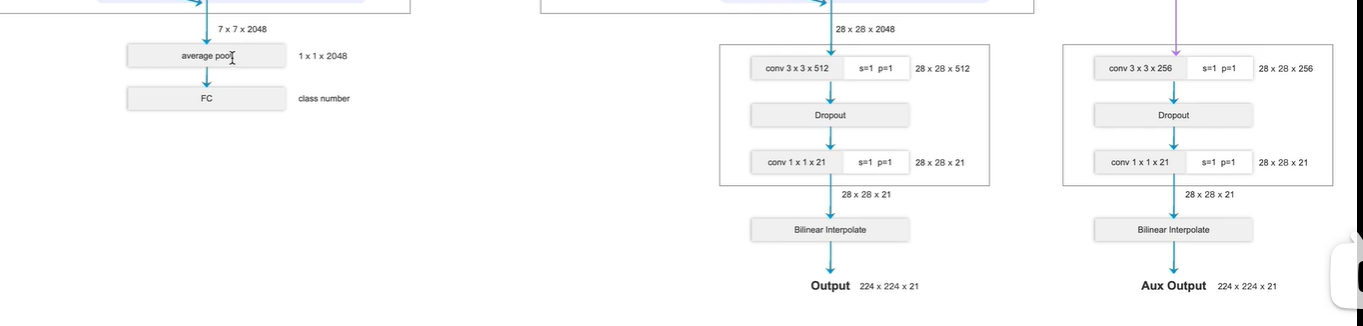
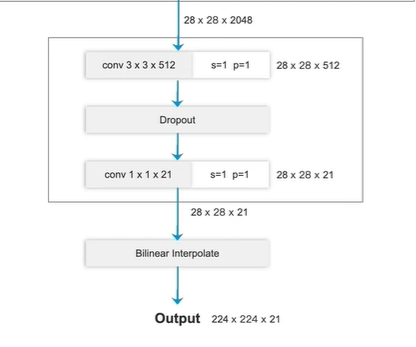
输出端
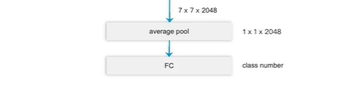
原始:
池化层+全连接层
更改:
换为 卷积层
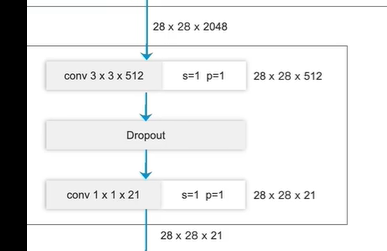
第二个卷积输出通道数为21 (PASCAL_VOC数据集 20个类别+1背景)
最终输出224x224x21
224x224 原图像素尺寸
21 对应每个像素的类别概率(每个像素对应这个21个类别的概率分别是多少,取最大概率作为结果)
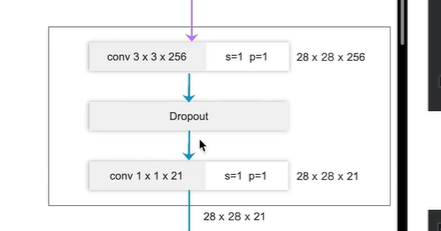
辅助分支(右边)
注意:
上采样操作
方法1:转置卷积
方法2:双线性插值
当转置卷积的权重进行设置, 则效果与 使用双线性插值 一样,
为简单期间,本次使用双线性插值
5.模型搭建 - 代码解读
模型搭建 - 代码解读_哔哩哔哩_bilibili
backbone.py ResNet-50网络构建
fcn_model.py 对ResNet-50 进行修改,最终构建FCN网络
13:59
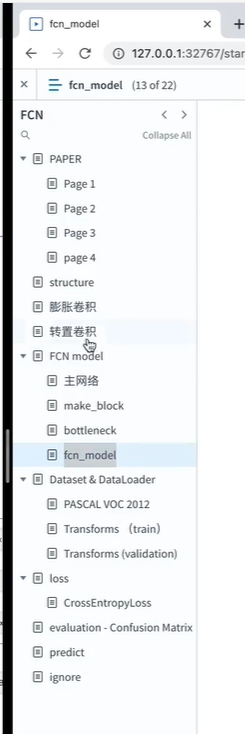
红色-搭建主网络
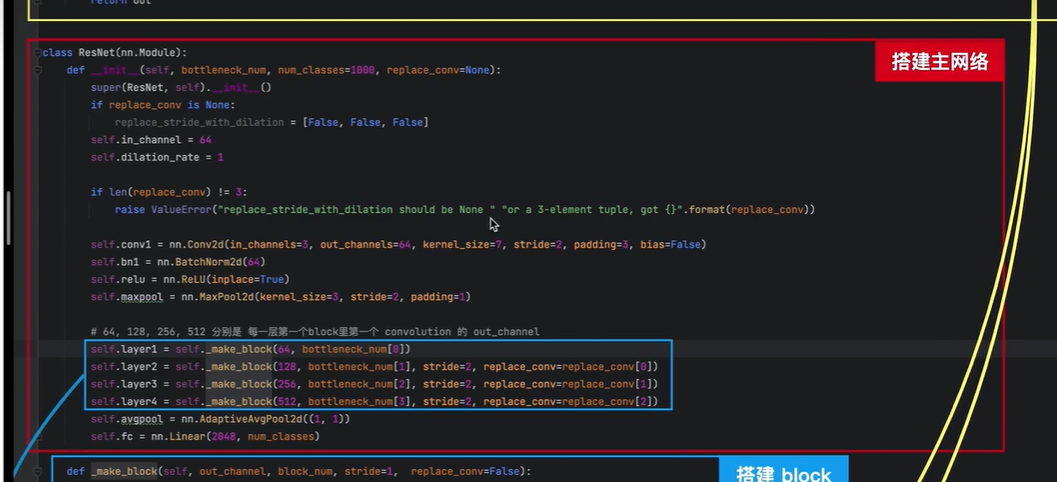
蓝色-搭建四个块
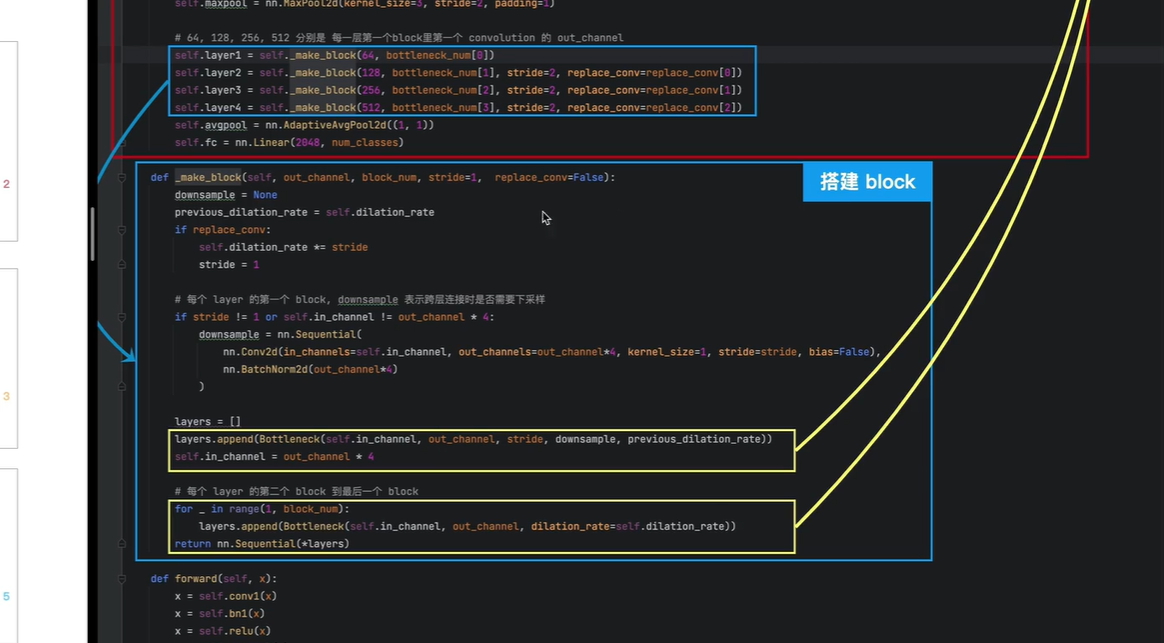
黄色-搭建残差块

每个block分别有 3,4,6,3个残差块
红色框-搭建主网络
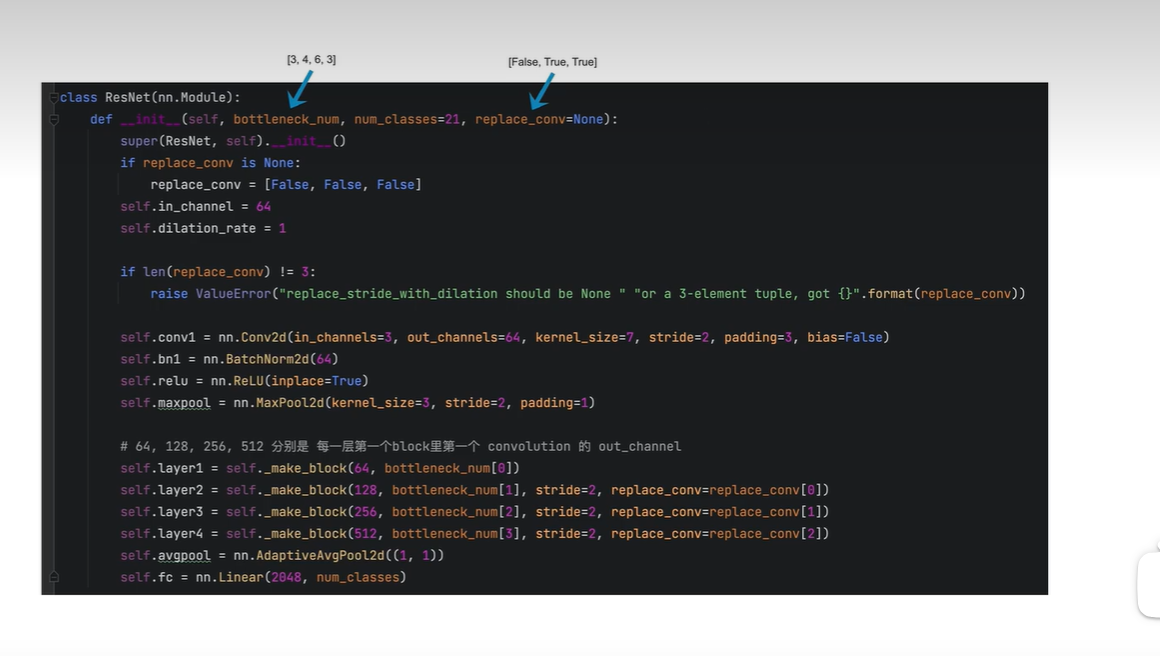
bottleneck_num=[3,4,6,3]
第一个block有3个残差块
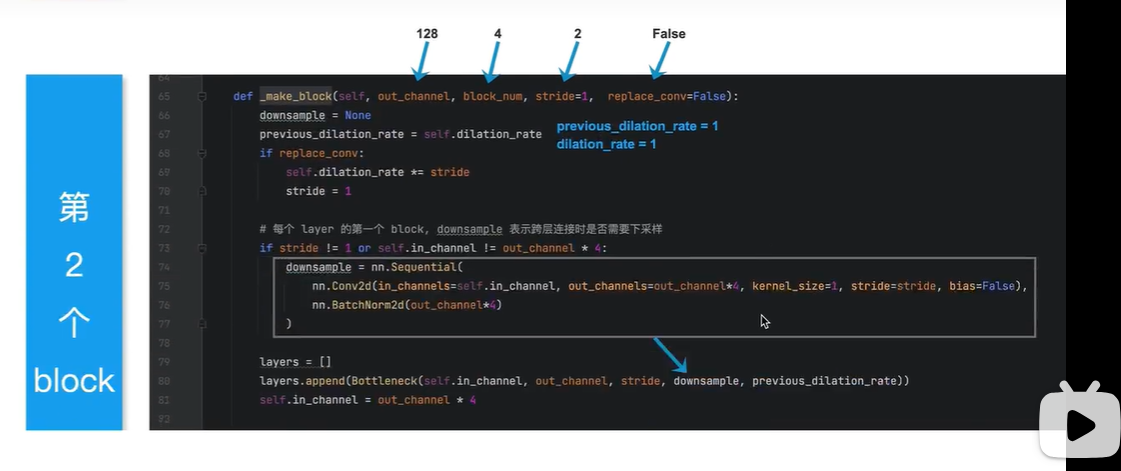
第二个block有4个残差块
第三个block有6个残差块
第四个block有3个残差块
repalce_conv 表示 是否要把每个block里面的卷积 替换为 膨胀卷积
[False,True,True]
表示将第二个block内部conv不用替换
第3,4个block需要替换
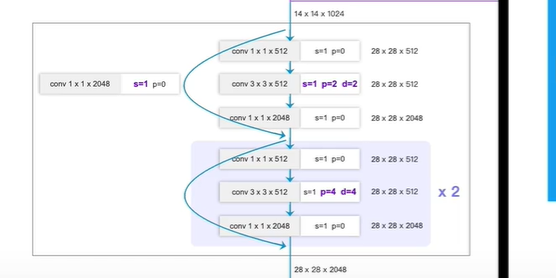
注意下图:从上往下, 第1,2,3,4 block


对应初始两层

up:因为有BN层,且bias作用不大,所以偏置bias设为零,可以节省参数
不太懂?什么原理

对应最后一层
第一个block
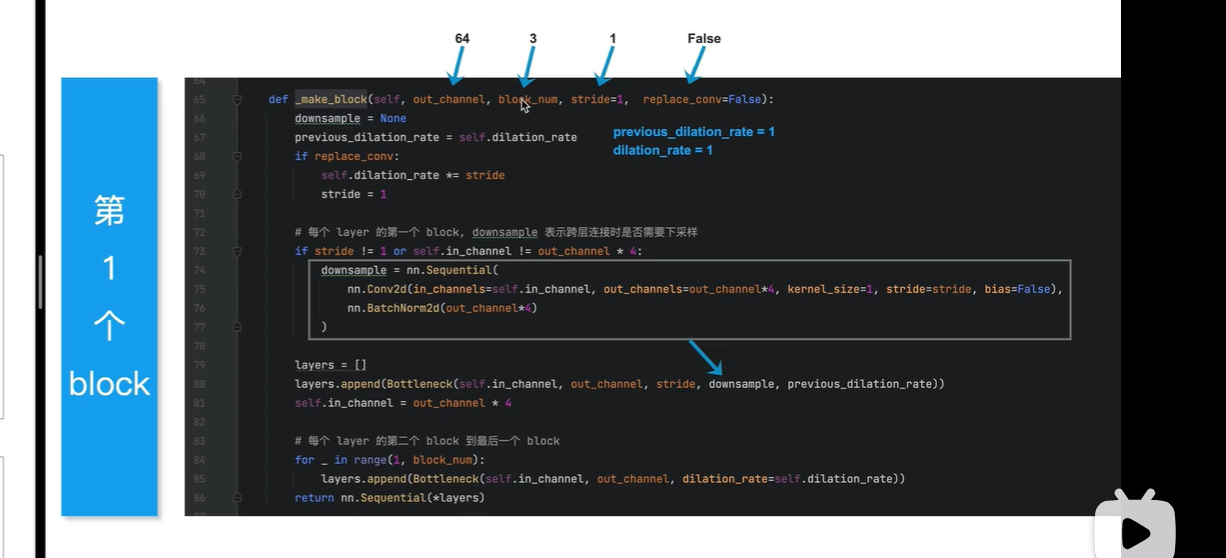

out_channel=64, 表示block内部第一个conv的输出通道数为64
block_num=3 ,表示block内部有三个残差块
表示残差块里面 3x3的conv是否需要替换为膨胀卷积, 默认第一个block不替换

表示block内部第一个残差块需要一个1x1的conv ,将输入通道数变换4倍
下图表示第四个block
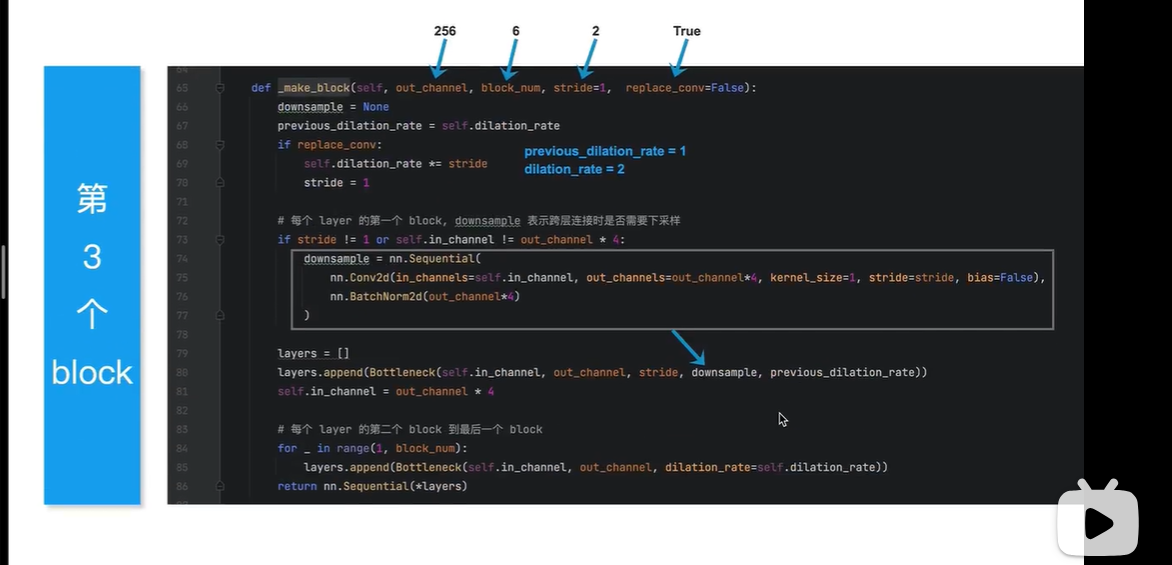
replace_conv=True
表示将3x3的普通conv 替换为 膨胀卷积
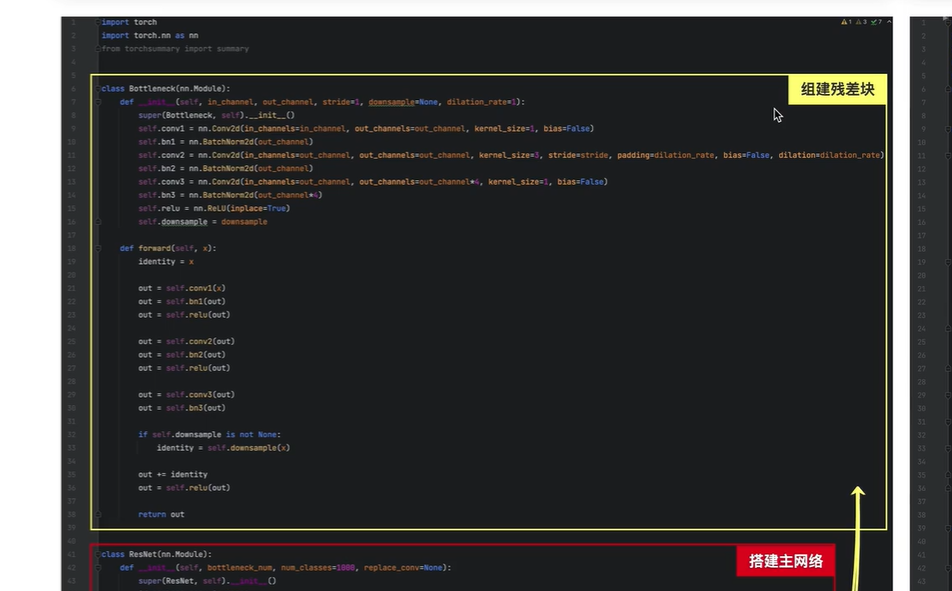
Bottleneck
残差块
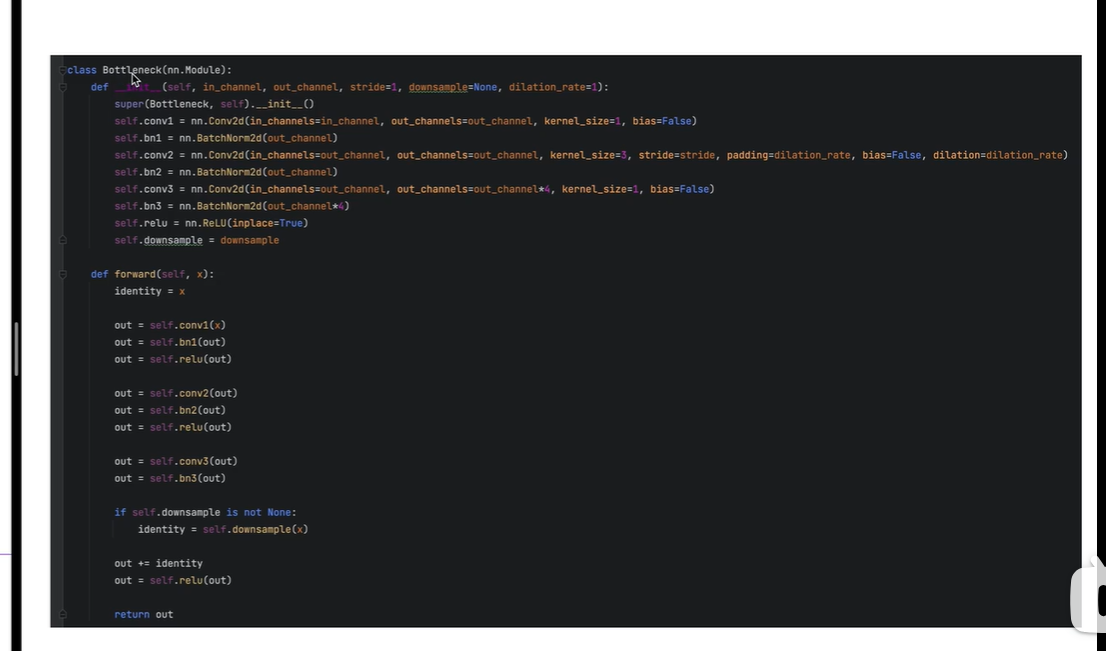
先做相加,再做relu激活
fcn_model
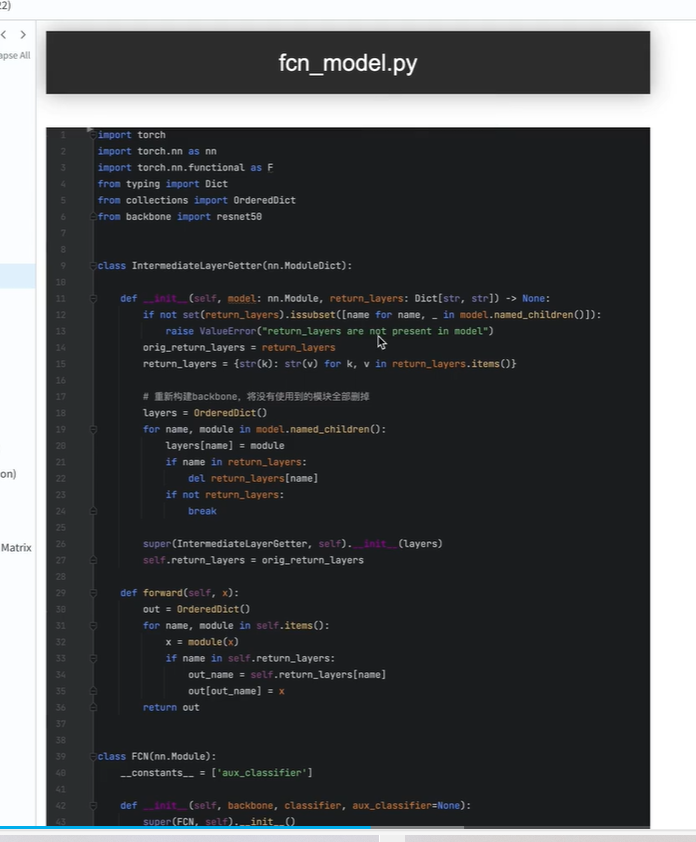
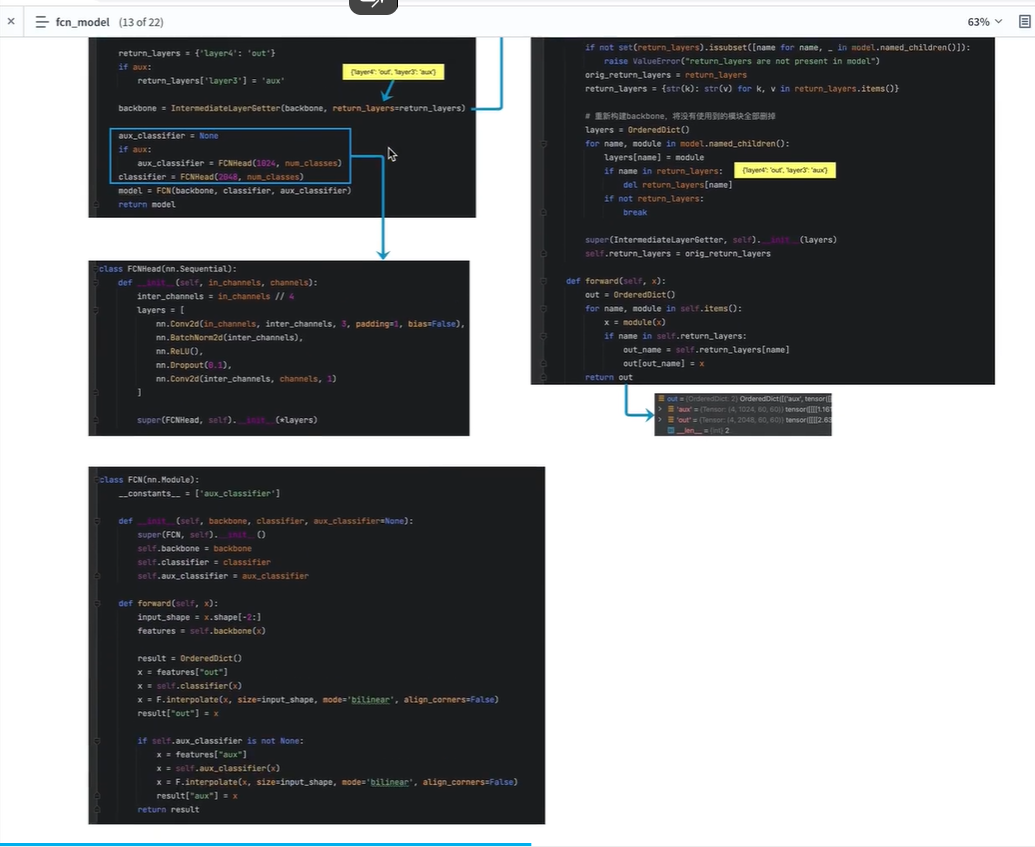
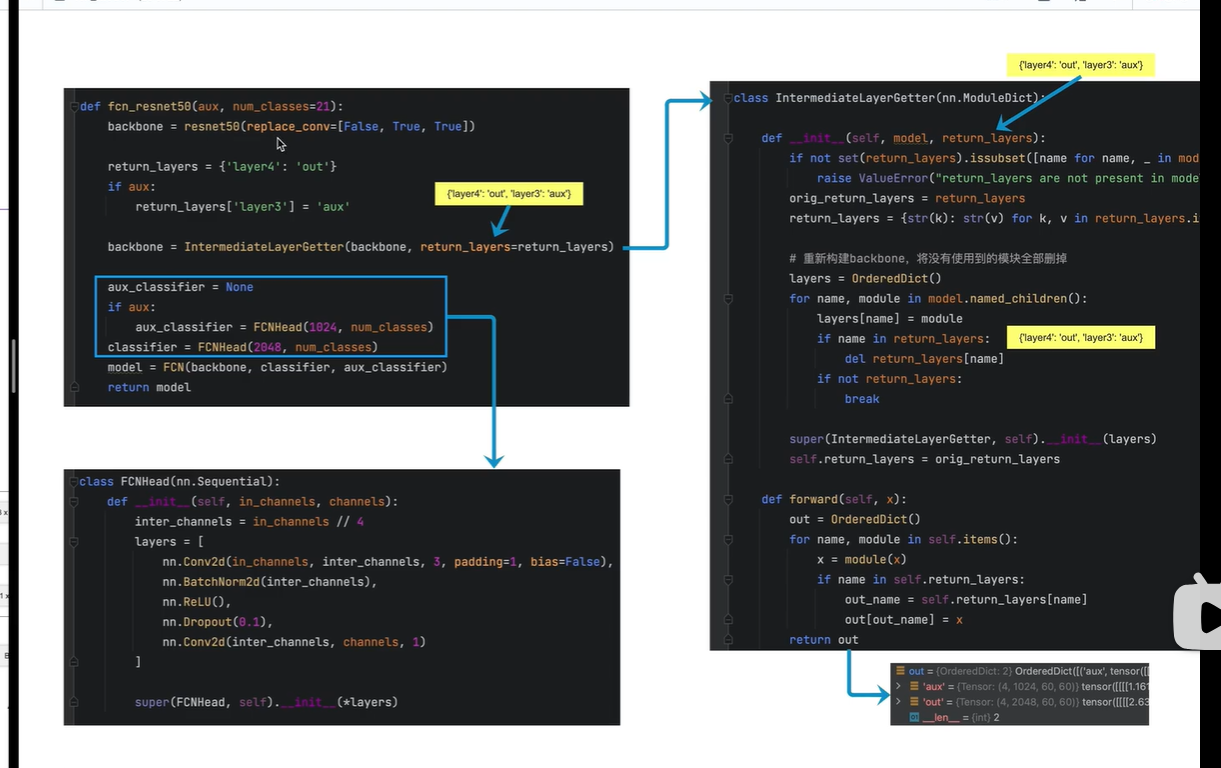

剔除了backbone的最后两层
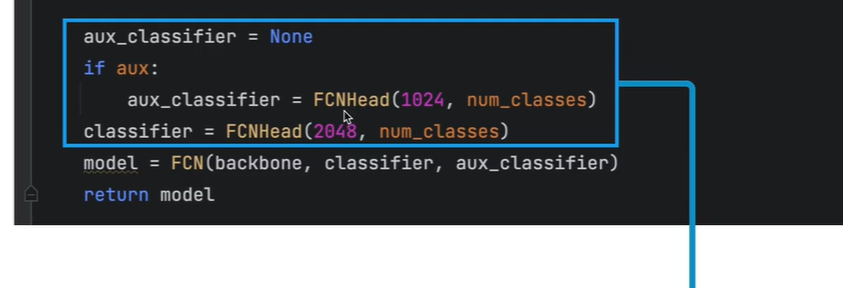
是否需要辅佐分支,需要搭建
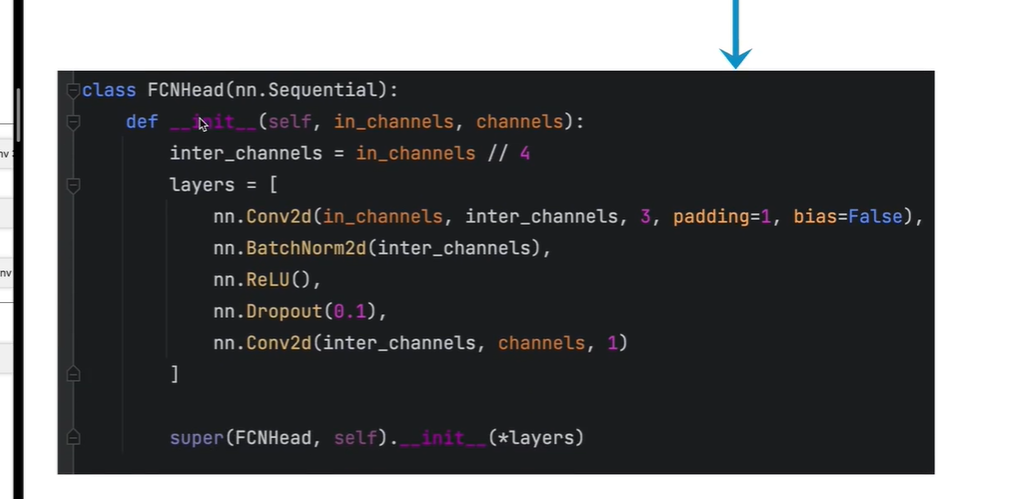
搭建主分支
搭建FCN
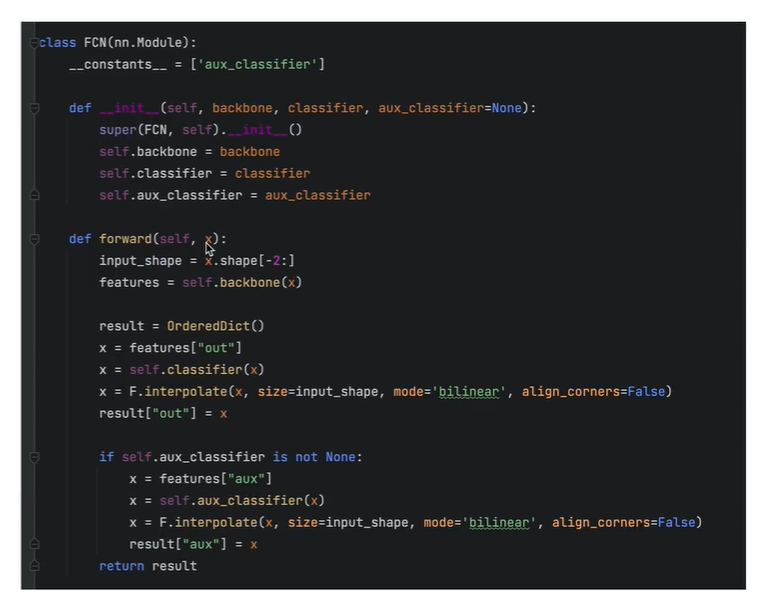
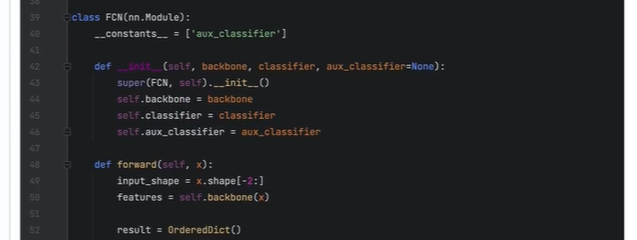
将主干网络(对原来进行修改),主分支网络,辅佐分支网络结合在一起
输入数据x的传递
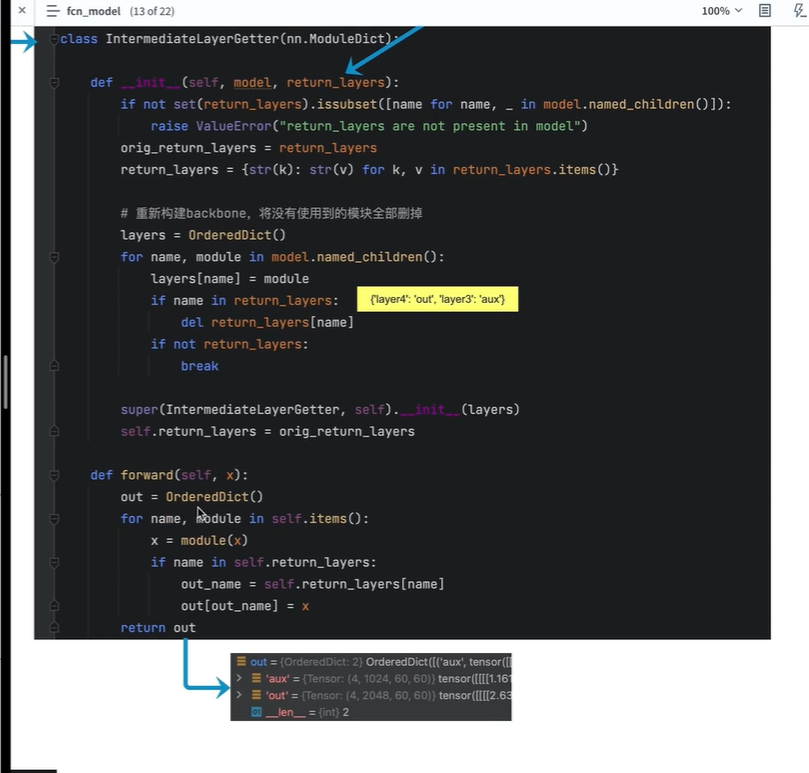
记录两个分支(主分支,辅佐分支)的输入
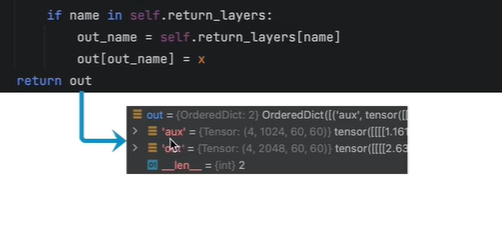
第三个block的输出,辅佐分支的输入

第四个block的输出,主分支的输入

处理两个分支的输入
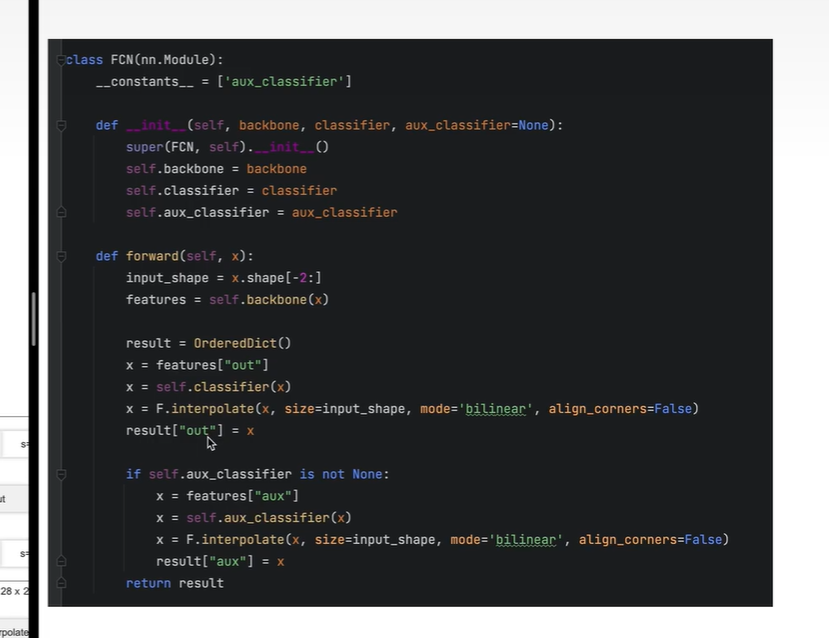
主分支输入处理
辅佐分支处理

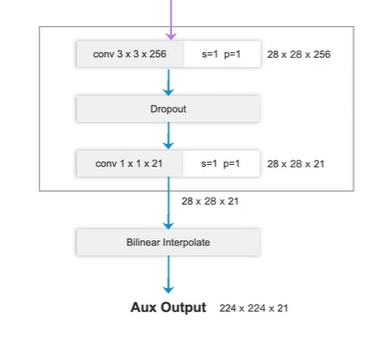
最终返回的result 包含 两个结果 Output, Aux Output.
个人:代码听得有些晕
6.视频课6:数据文件结构与标注图像详解
这里也可以去看up :霹雳wz
霹雳吧啦Wz的个人空间-霹雳吧啦Wz个人主页-哔哩哔哩视频
数据文件结构与标注图像详解_哔哩哔哩_bilibili

数据结构
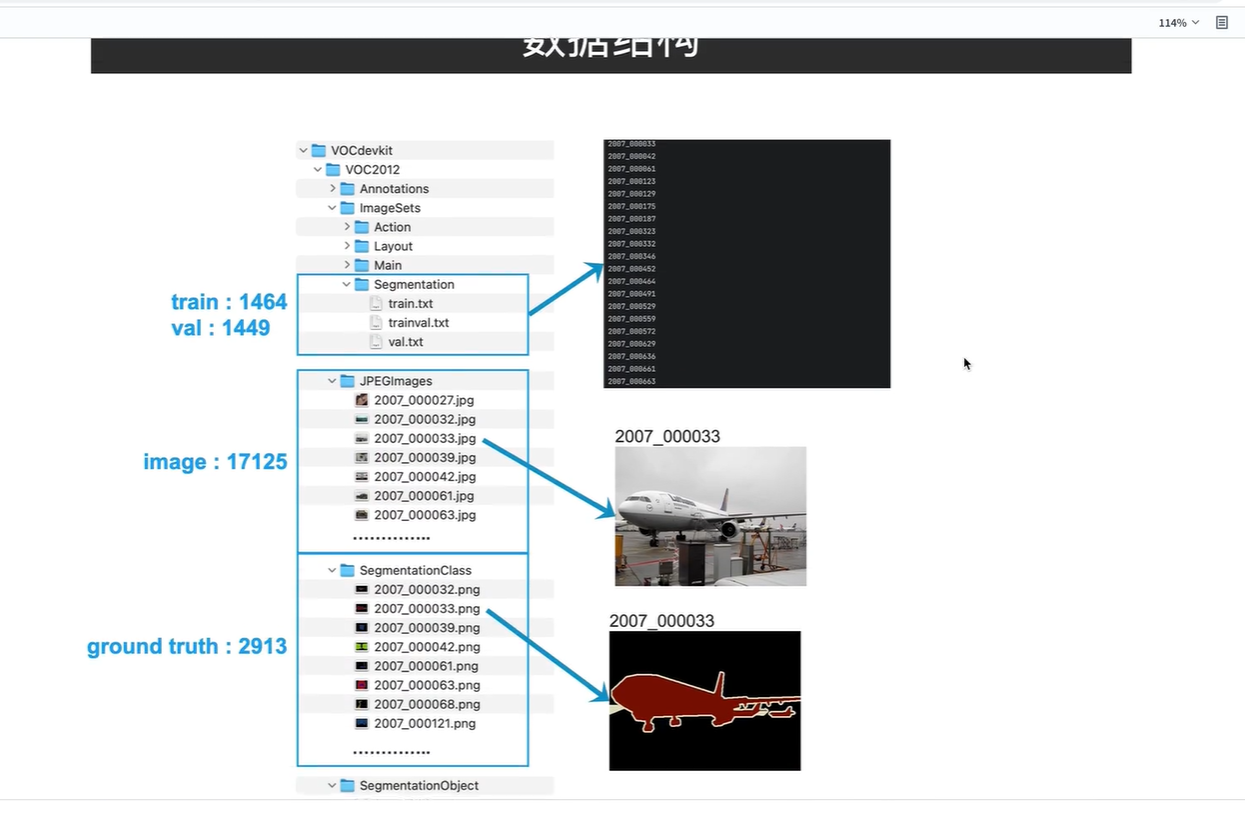
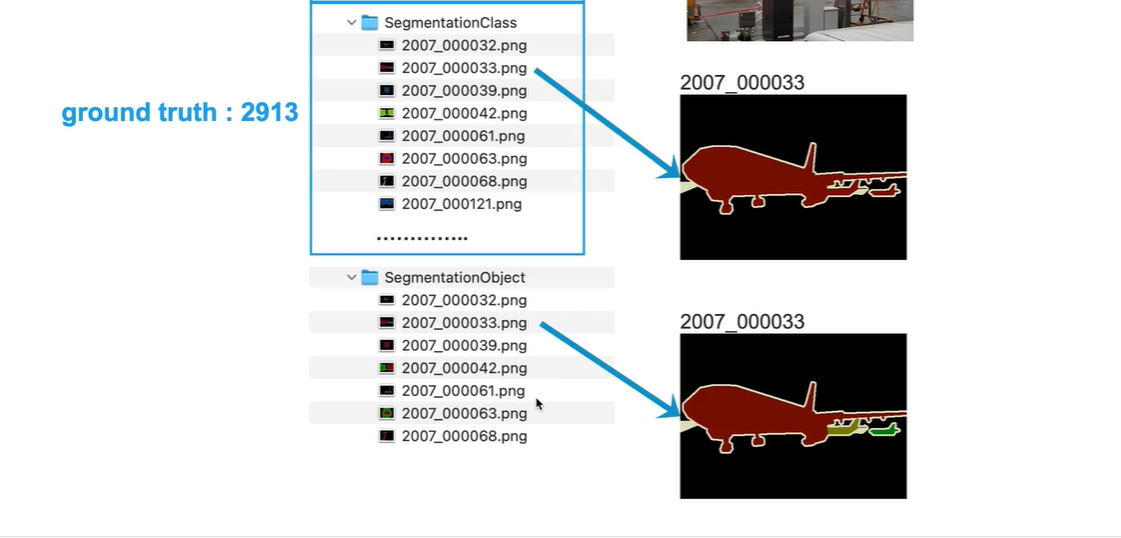
JPEGImages 存放原图像
SegmentationClass 语义分割的标签文件,三个飞机都被标注成相同的颜色
SegmentationObject 实例分割的标签文件, 三个飞机被标注为不同的颜色
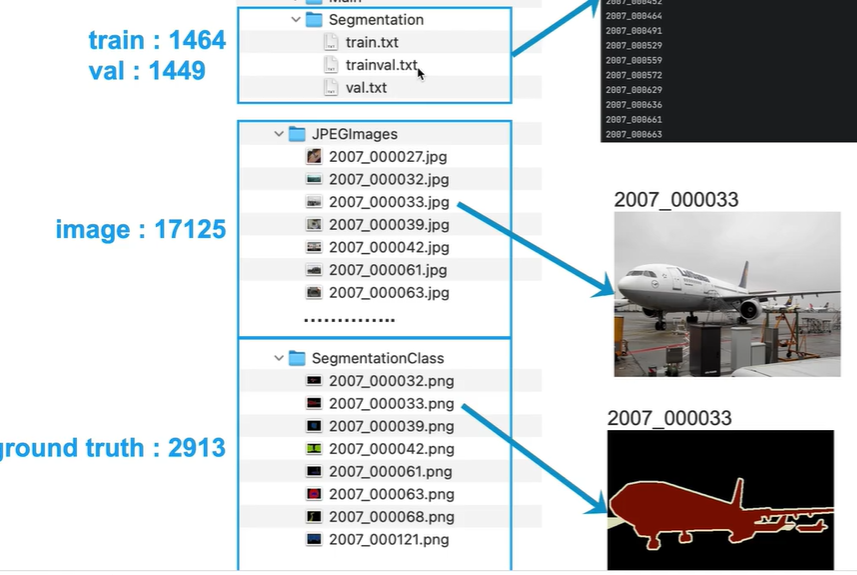
由于原图像有17125张,语义分割标签图像2913张
因此需要train+val 文件夹搜索图、标签文件名。
显示标签图像
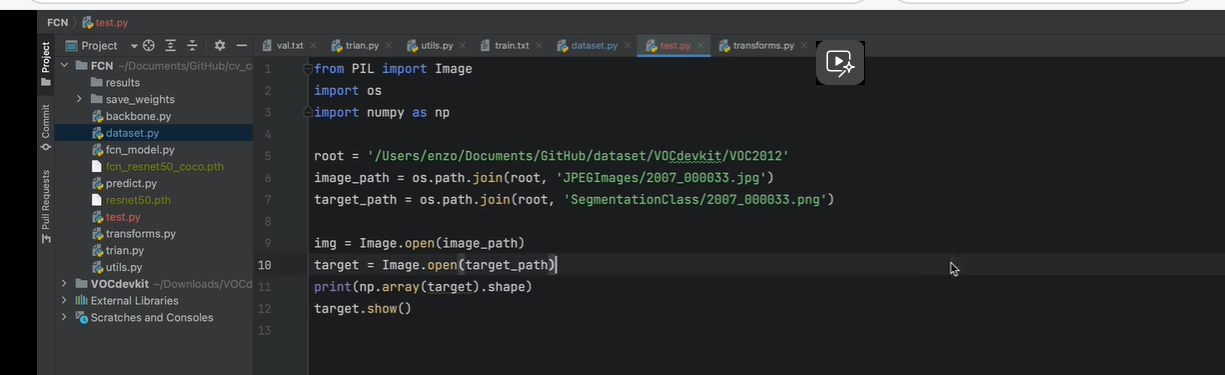

有黑色背景,白色边界,红色内容,
这个标签图像看起来像是 RGB三通道,
其实不是,该图像shape为 (366,500),因此是一张灰度图像
灰度图像显示为彩色的原因:

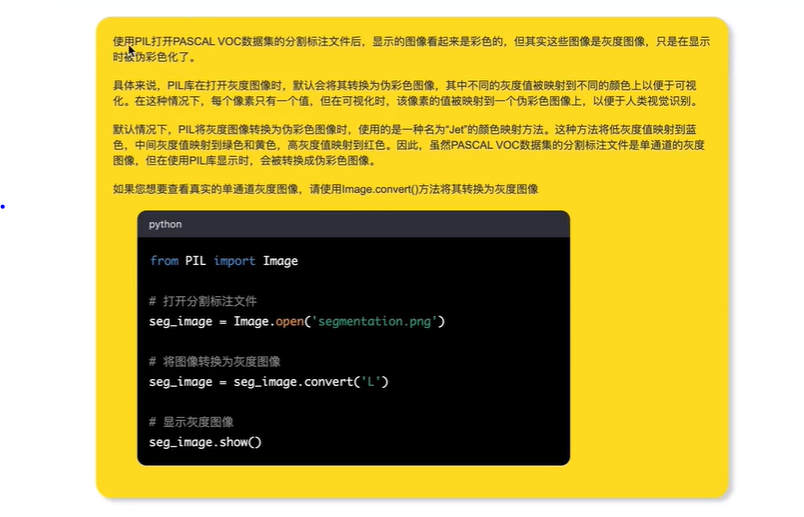
标注图像(灰度图)的内部像素值:
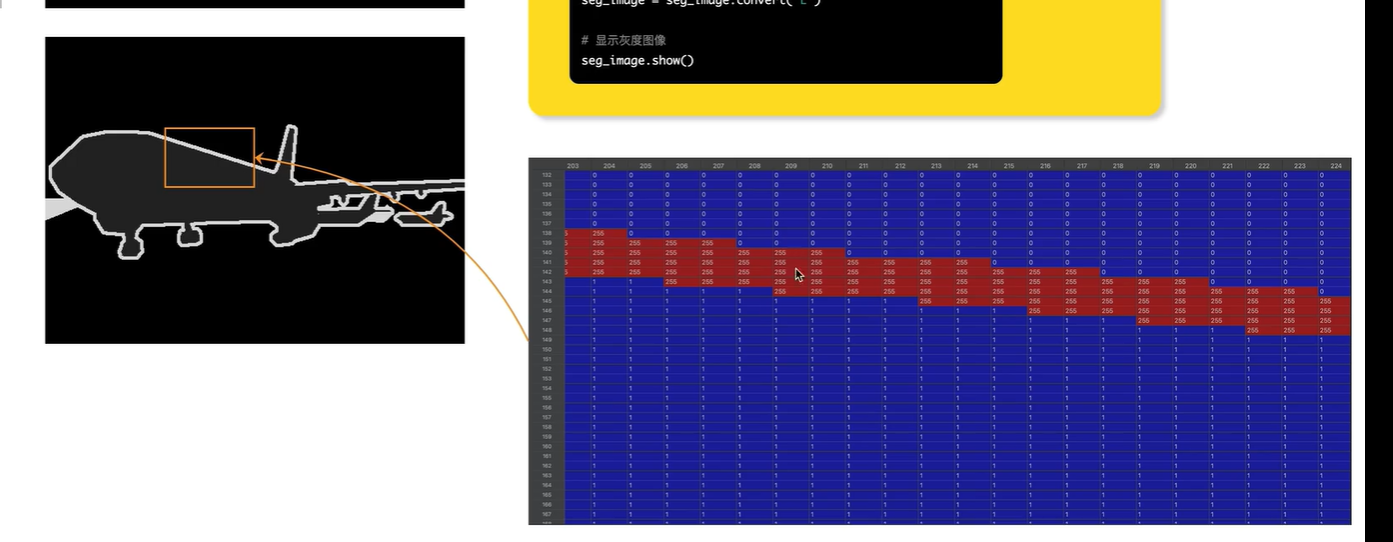
255表示边界(白色),0表示背景,1表示标签内容
7.视频课7:图像预处理 (Dataset & DataLoader)
图像预处理 (Dataset & DataLoader)_哔哩哔哩_bilibili
解读程序
训练阶段图像处理
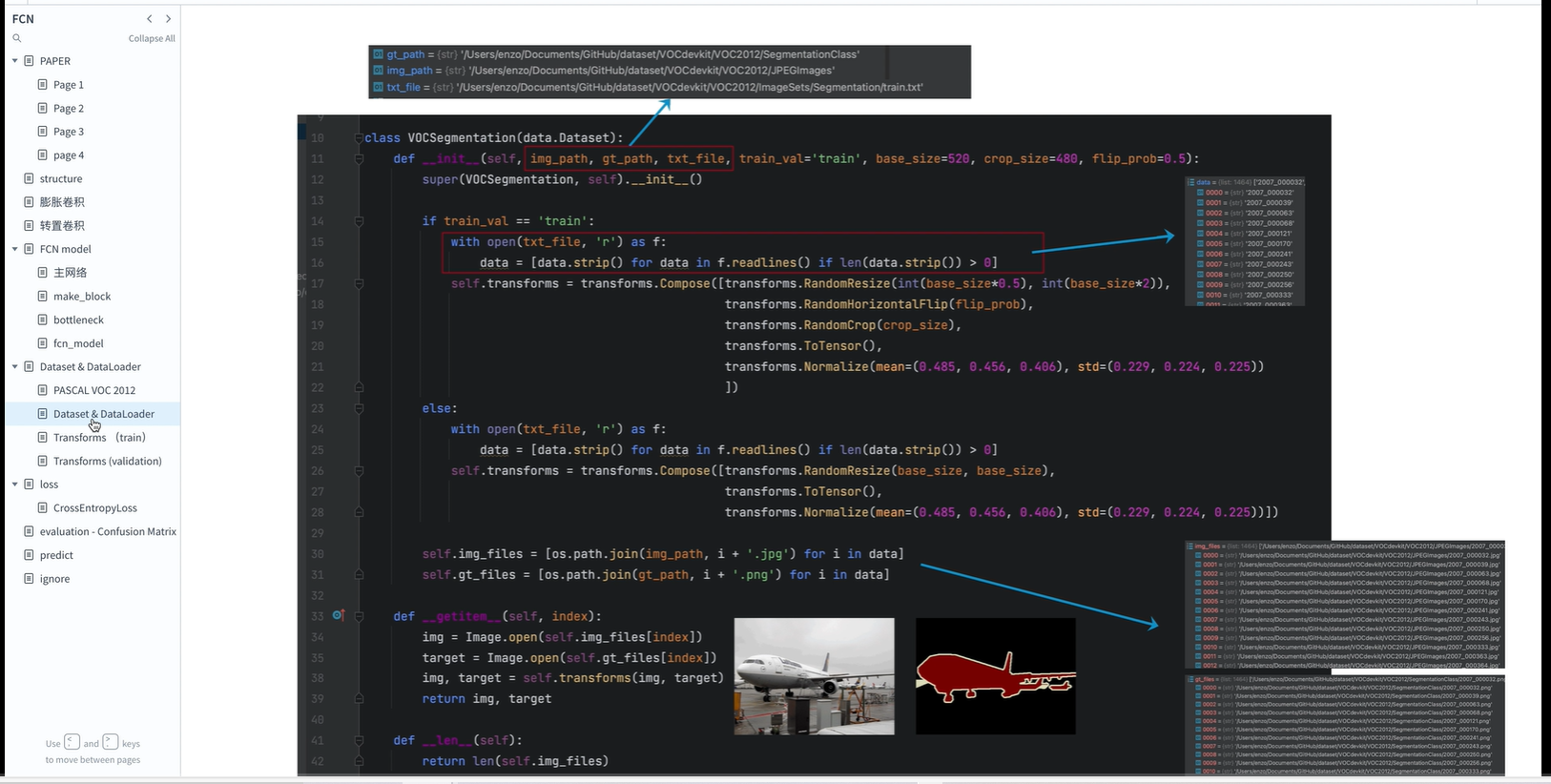
transform图像预处理, (up之前有出过相关视频)
预处理:
1.图像尺寸同一
2.数据格式为tensor格式,且是浮点型,并且做了归一化
3.对图像做增强处理
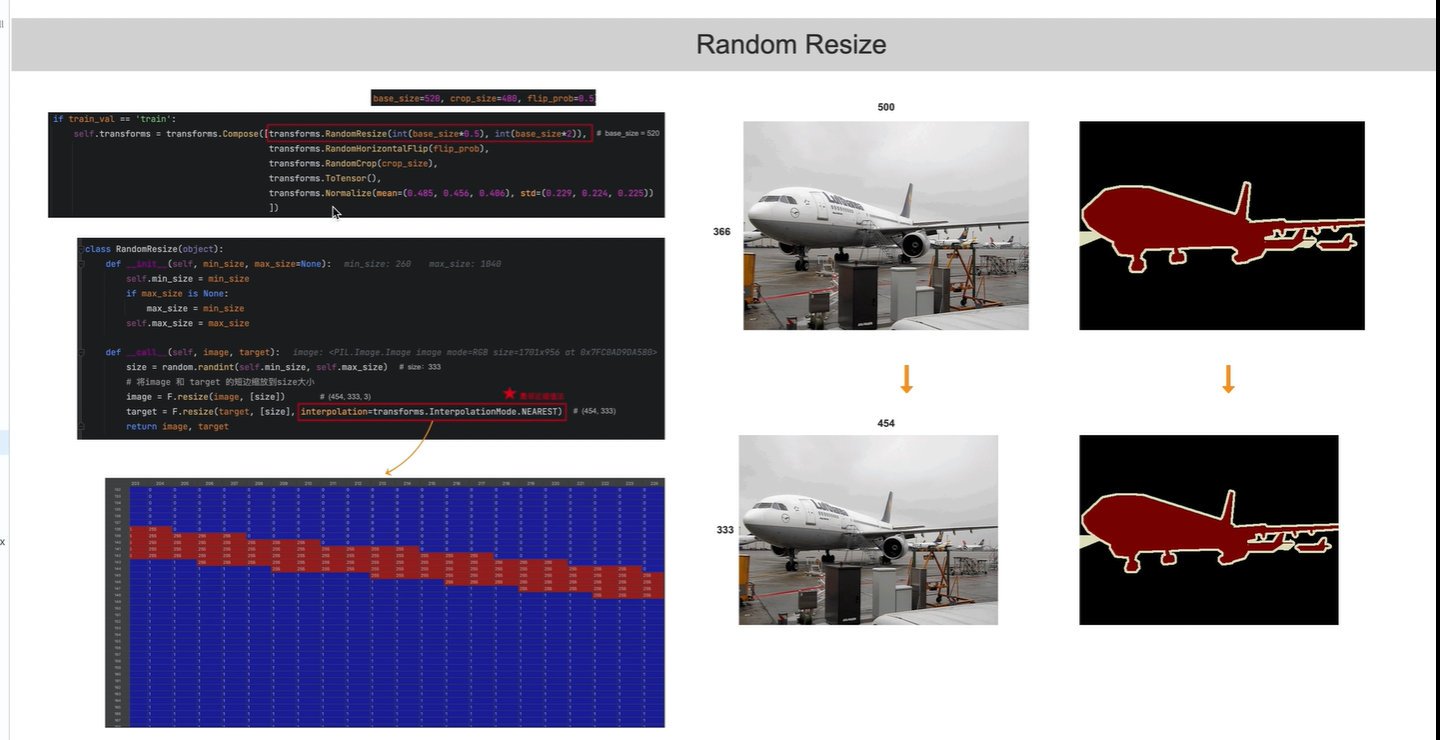
第一个预处理
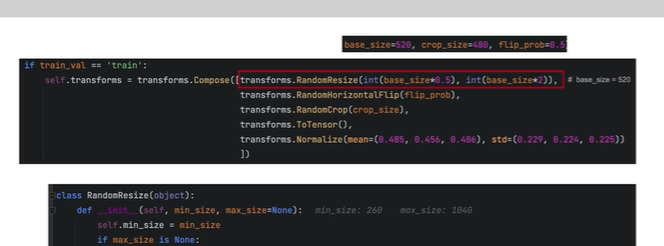
将图像随机缩放至base_size=520 的一半 或者 一倍之间
(260,1040)
注意在上采样时:
原始RGB图可以使用双线性插值, 标签图像仅使用最近邻插值( 原因看个人之前博客)
原因:标签原本像素值:0,1,255, 如果使用双线性插值,则会出现 100,123等没有意义的数字,
使用最近邻插值后,图像像素值依旧是0,1,255 均有意义
随机翻转
RGB原始图像与标签图像均要做相同翻转

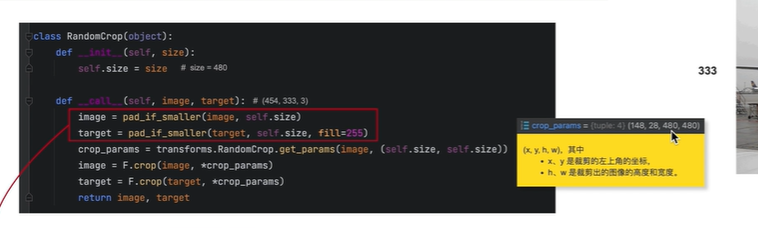
图像裁剪
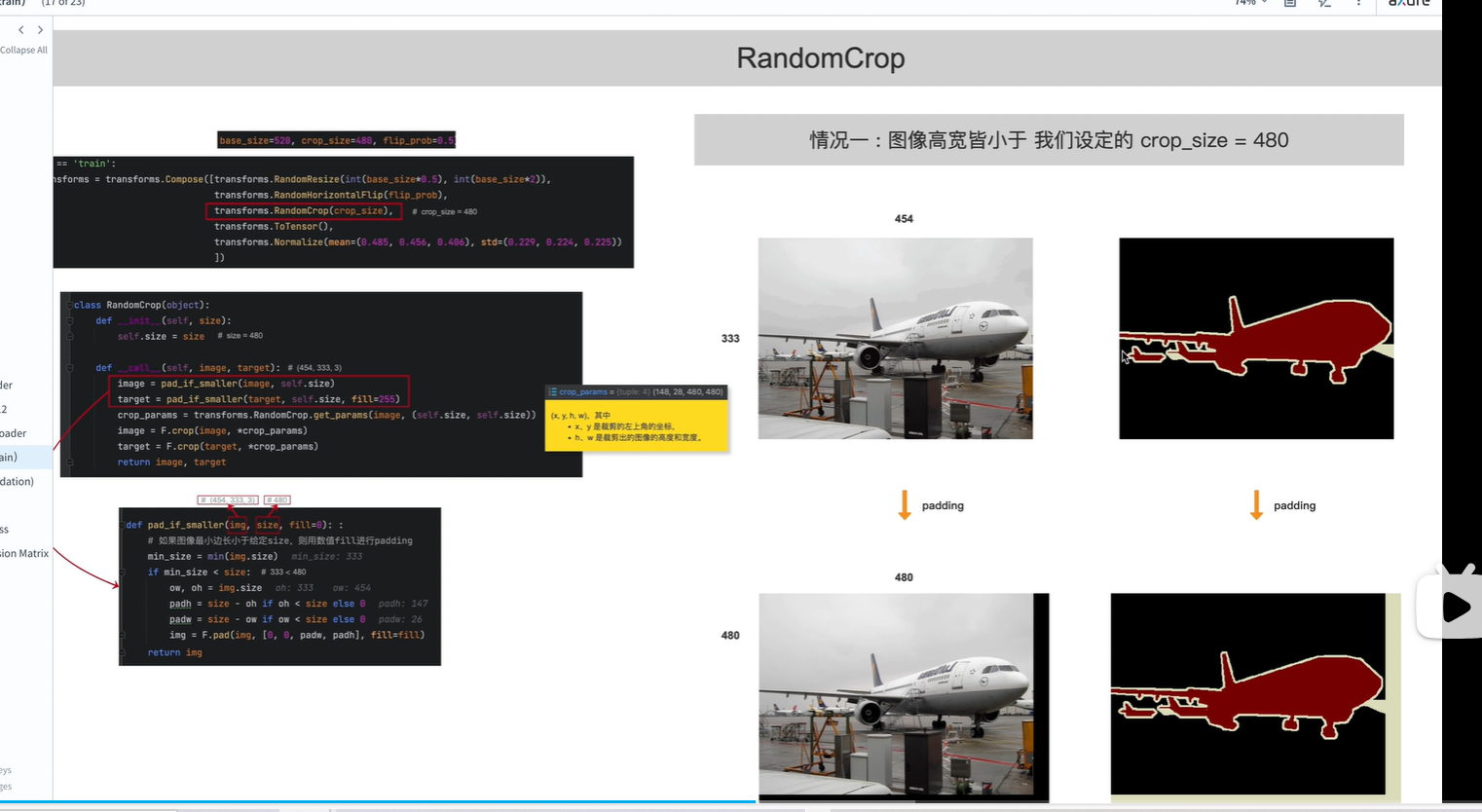
情况一:
如果原图宽高均小于480,则在裁剪之前需要给原始图像和标签 做padding
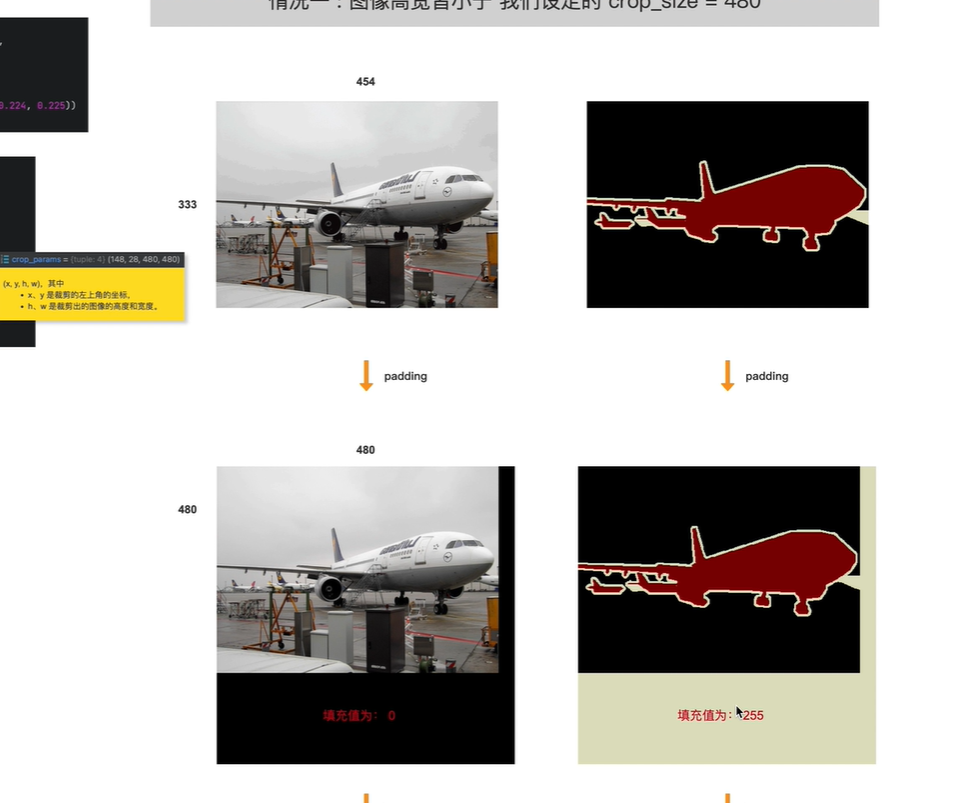
注意:
填充的时候,原图像使用0填充, 标签图像使用255填充(表示边界,不参与训练,在计算loss值的时候不会考虑在内;背景和内容需要参与训练)
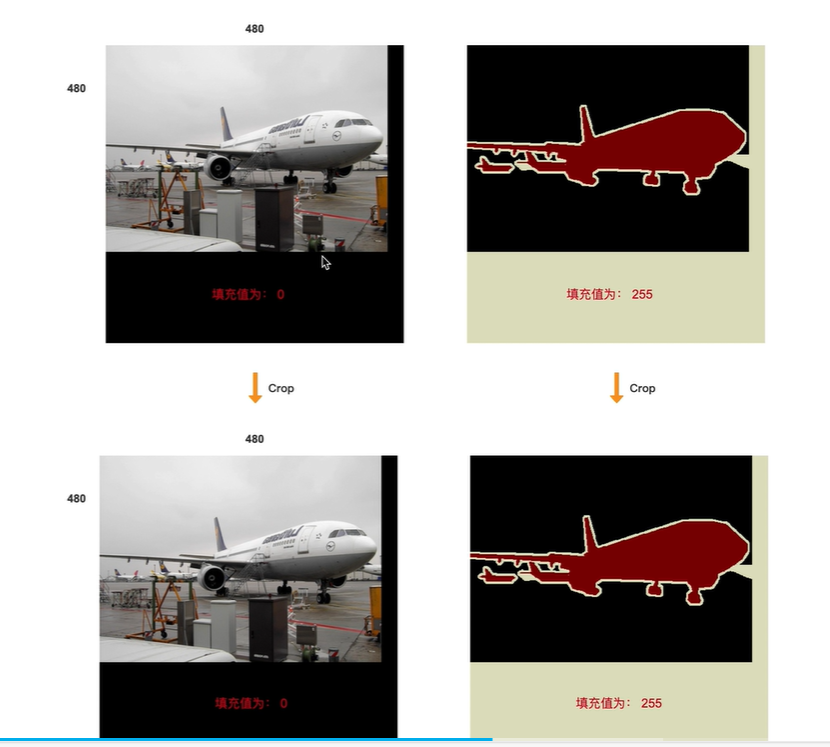
然后对padding后的图像进行裁剪,裁剪为480x480,由于在padding时已经填充为480x480,所以相当于没有裁剪
情况二

长宽中只有一个边小于 480
此时只对短边进行padding,然后进行裁剪

(x,y)随机值, 裁剪尺寸480x480
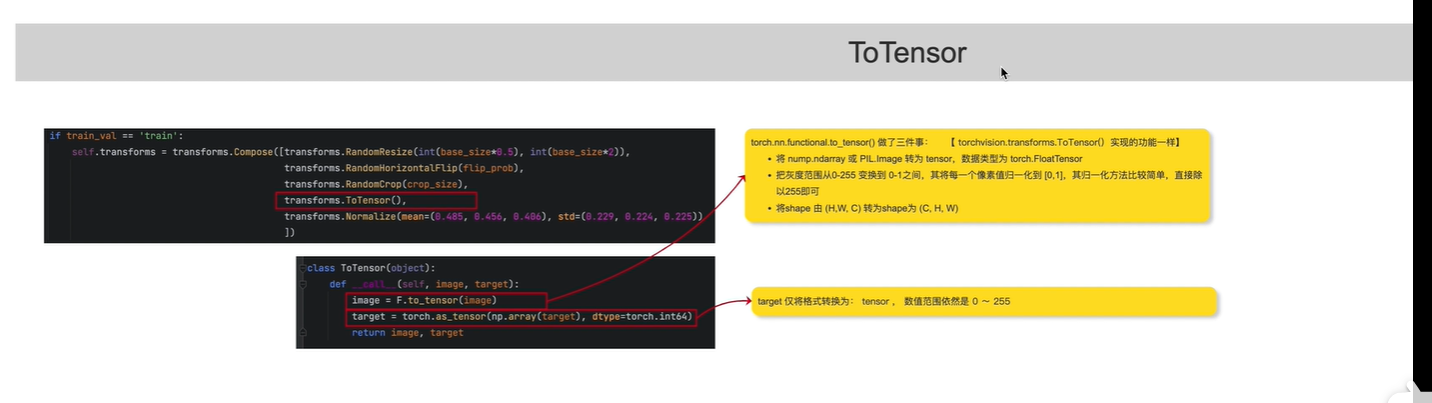
对原始RGB图像,像素值归一化到(0,1)
对标签图像,像素值不变,在[0,255]之间

验证阶段的图像处理
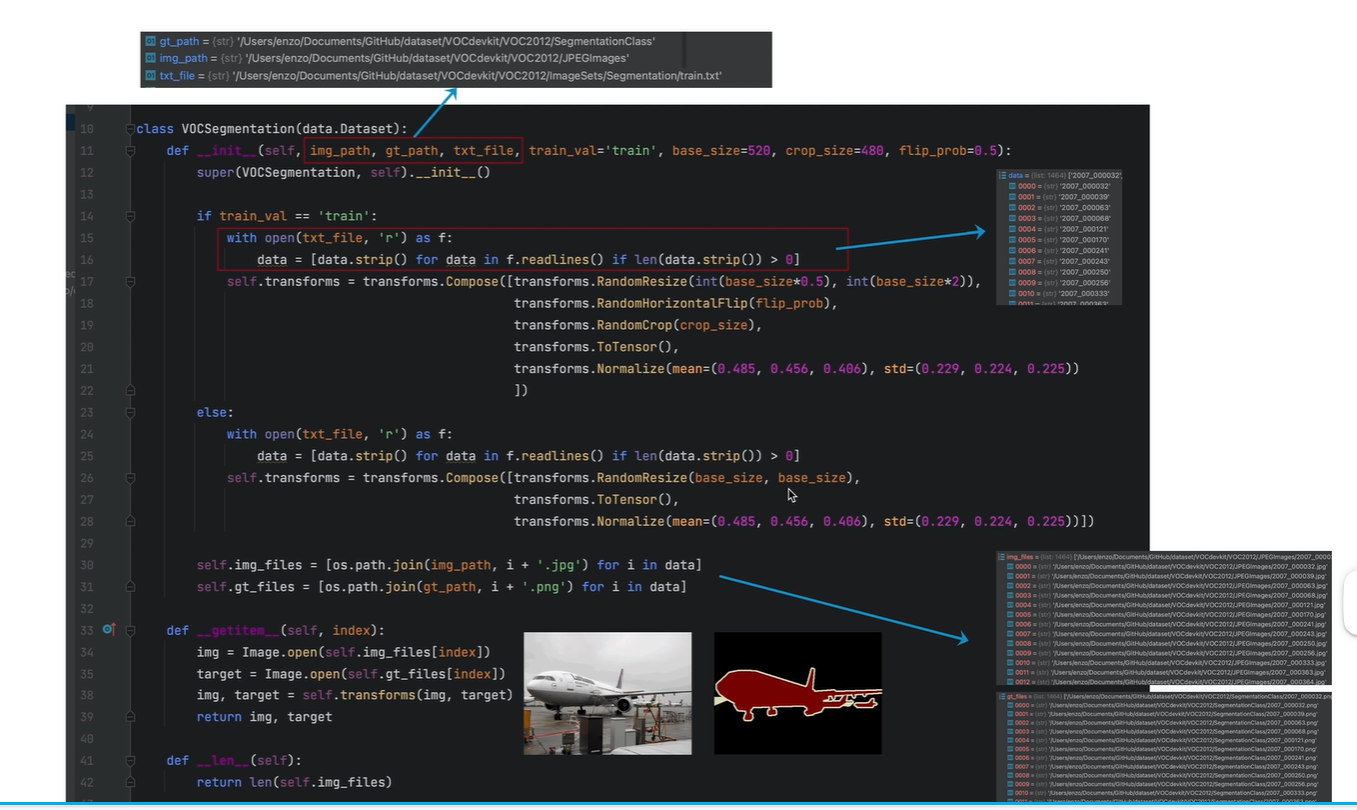
调整图像尺寸 为520x520
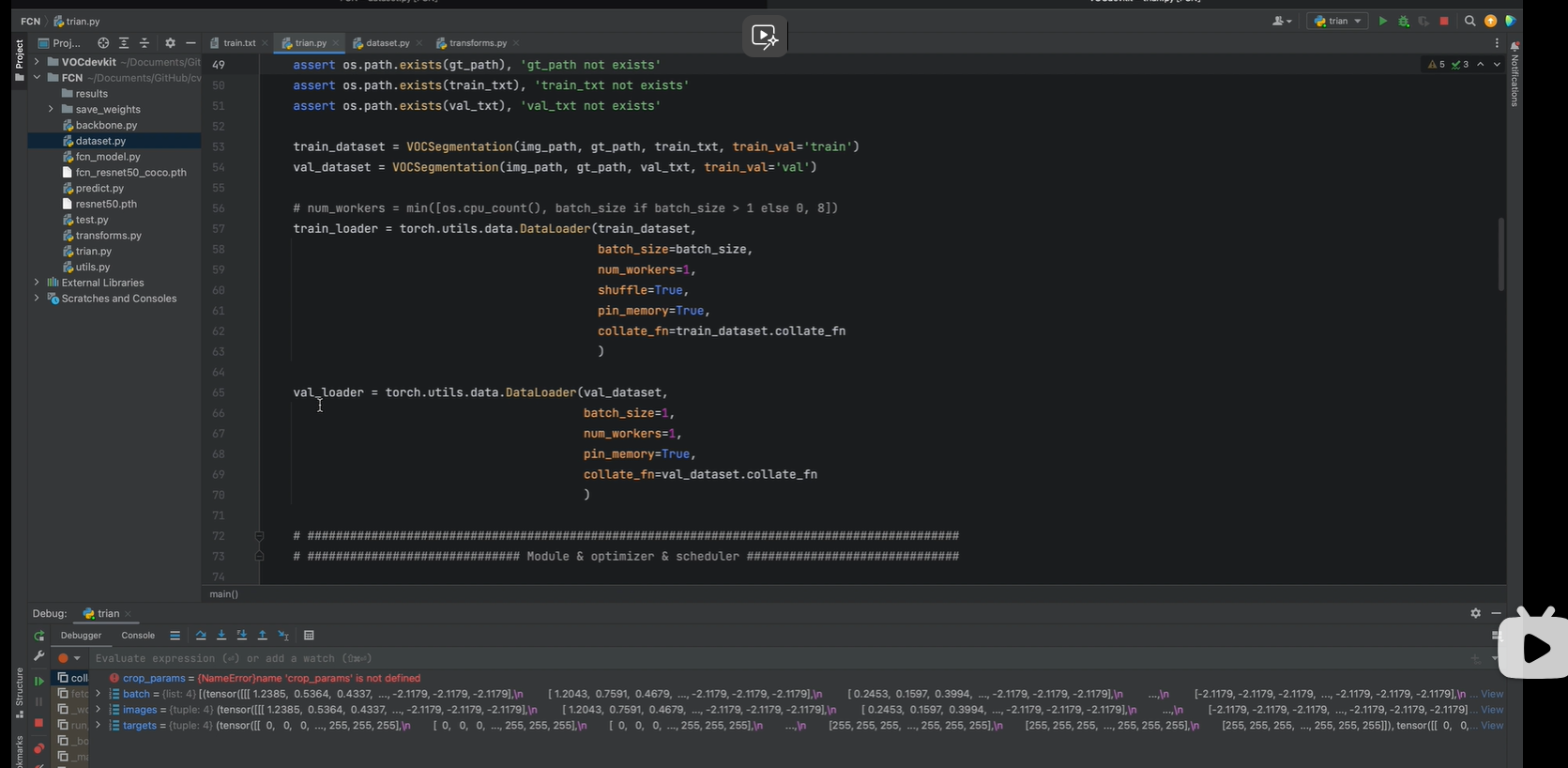
Dataloader
8.视频课8:损失函数
损失函数_哔哩哔哩_bilibili
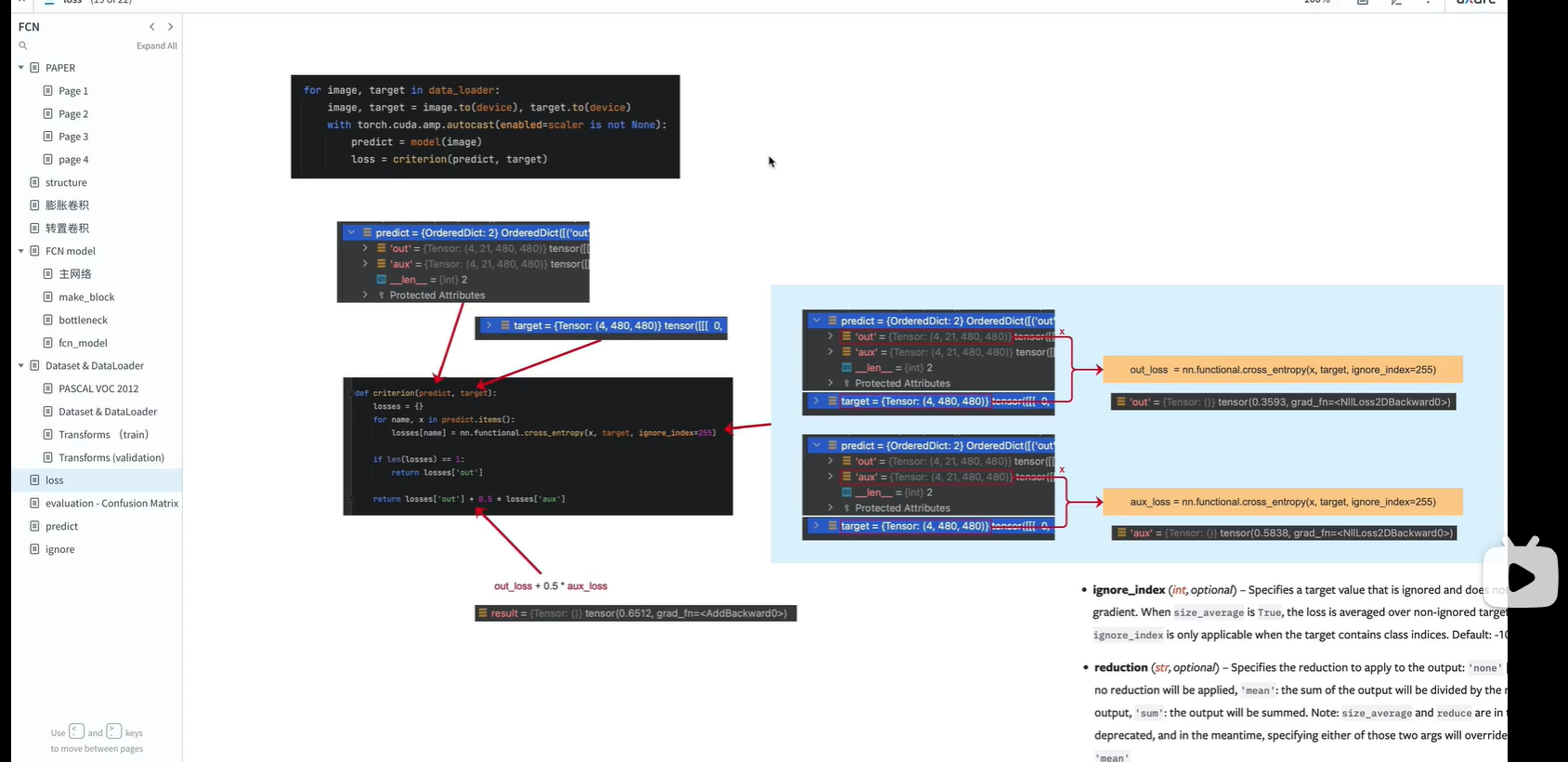
损失函数使用交叉熵损失函数
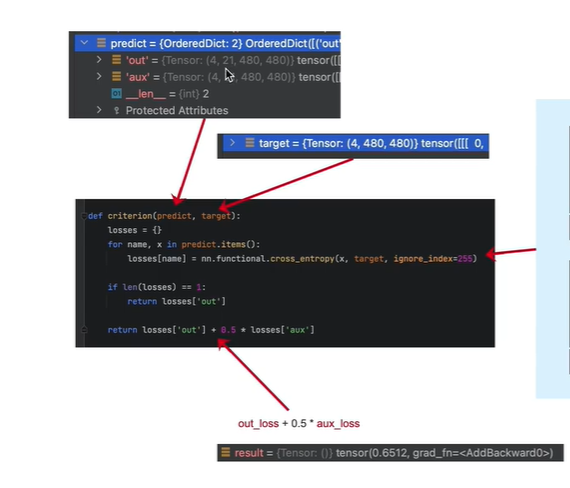
模型输出“”
out:
4表示batch_size = 4
21:PASCAL_VOC数据的类别, 20个类+1背景
480x480: 模型输出尺寸
aux:(辅佐网络输出)
target 处理好的标注图像的结果
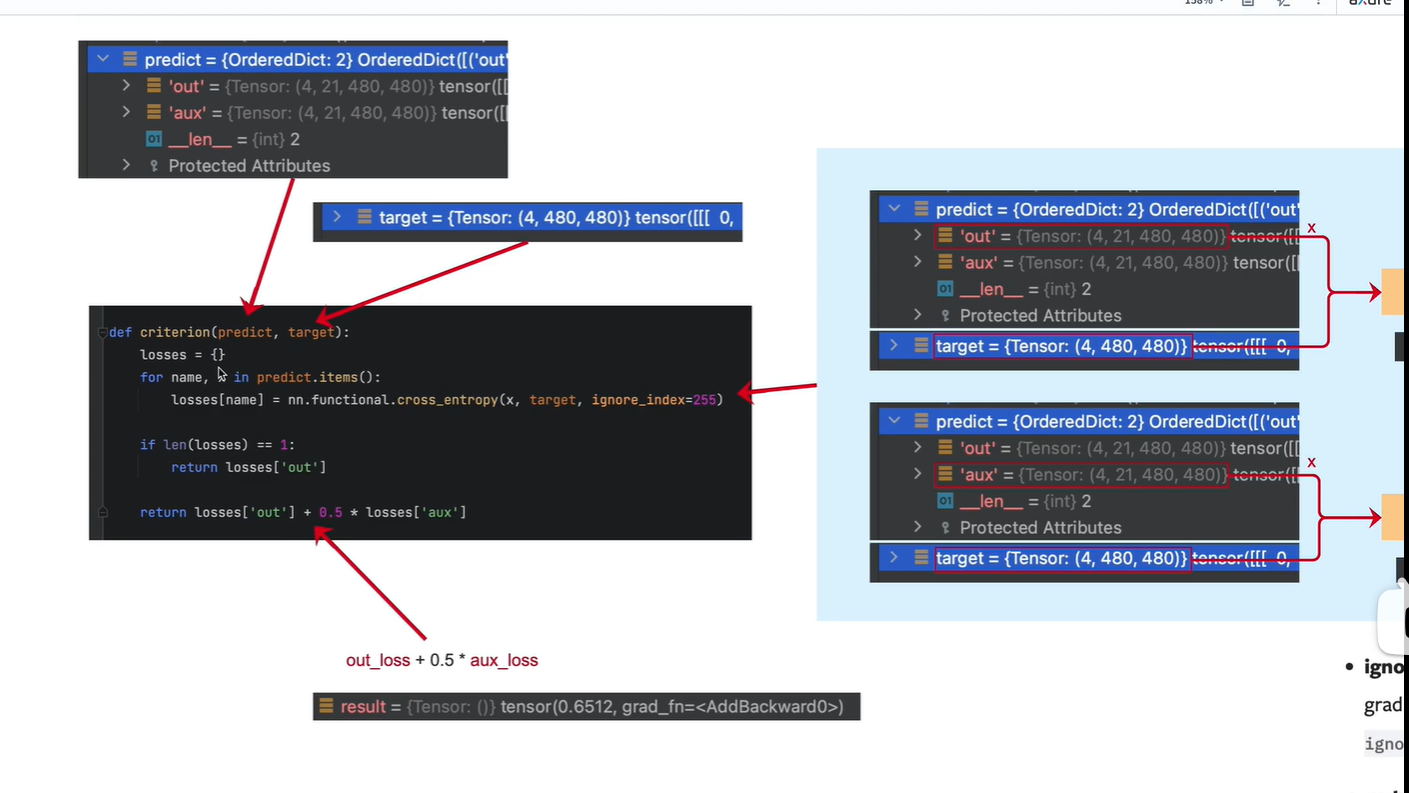
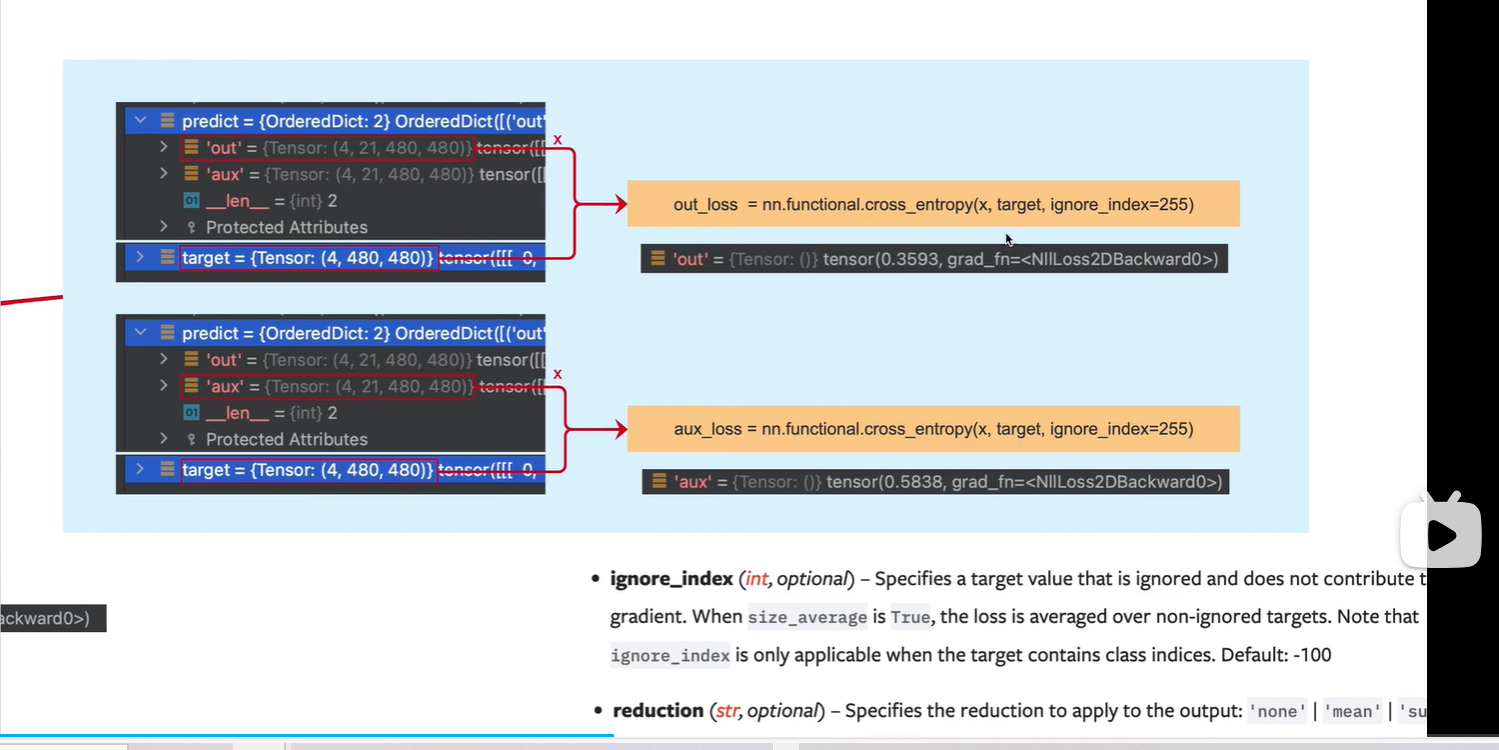
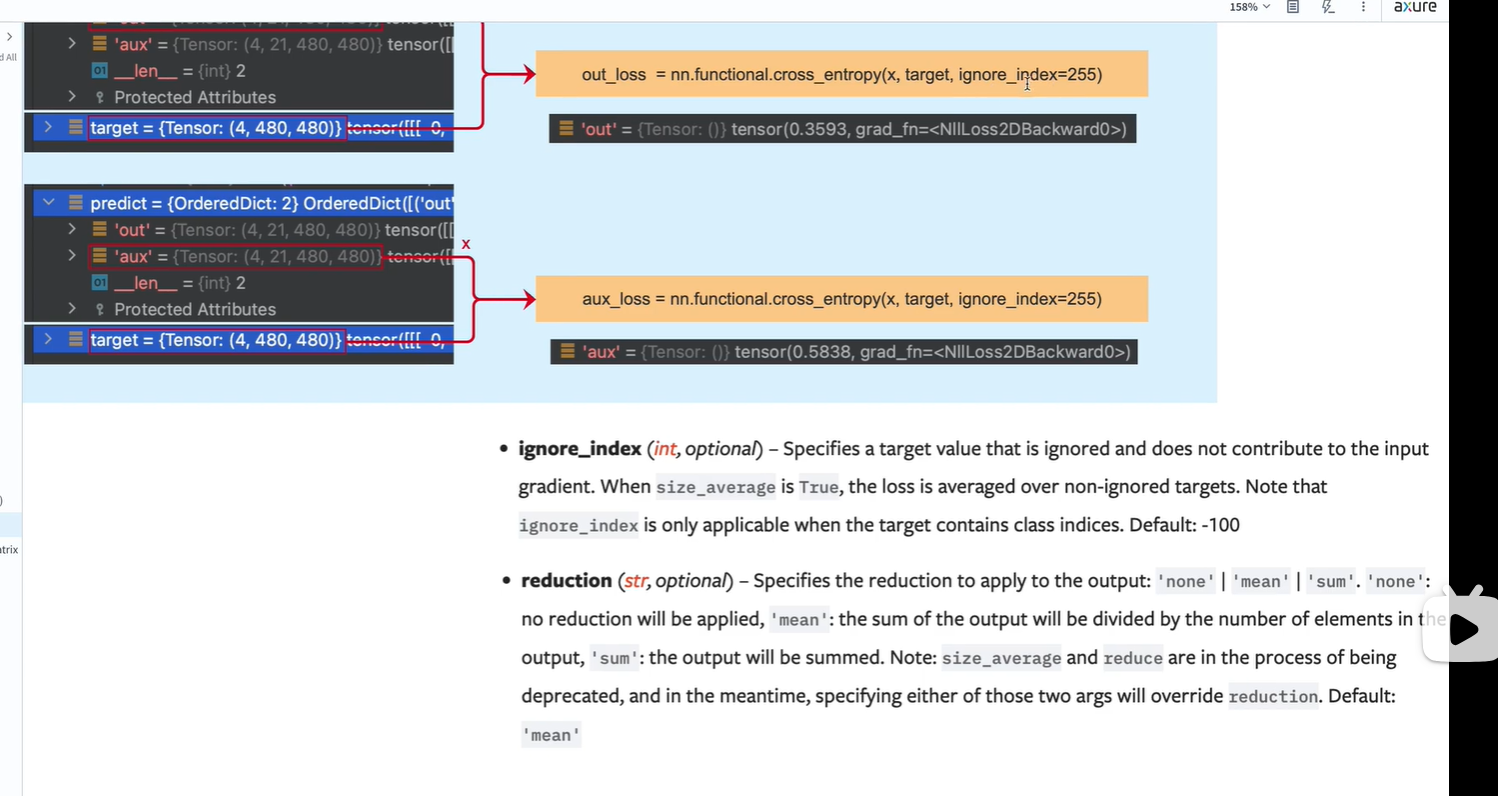
分别计算 主网络 out输出与 标签target的 损失; (辅佐网络)aux输出与target的损失
ignore_index 表示不计算 像素值为255的 像素点的 损失
reduction: 默认值为mean, 表示对所有像素的损失计算一个平均值
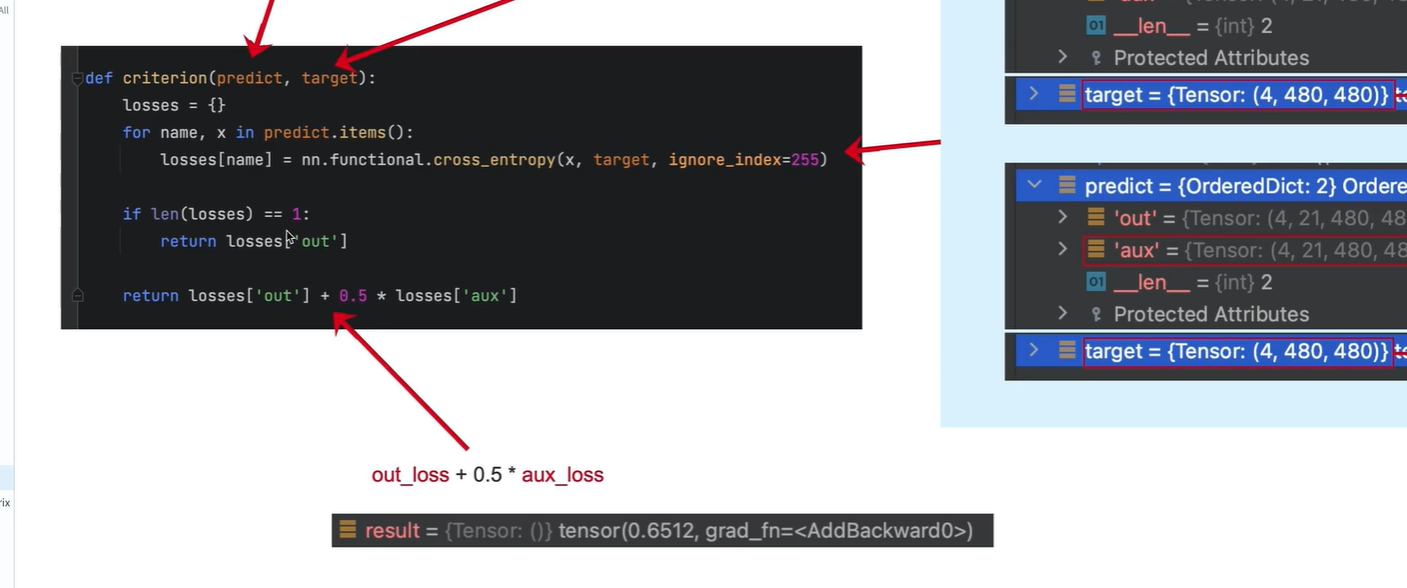
如果只有主网络(没有开启辅佐网络),losses=1,那就只输出主网络的损失

交叉熵损失函数视频,可参考
9.视频课9:学习率 / 学习率调度器 设置
学习率 / 学习率调度器 设置_哔哩哔哩_bilibili
可参考视频:
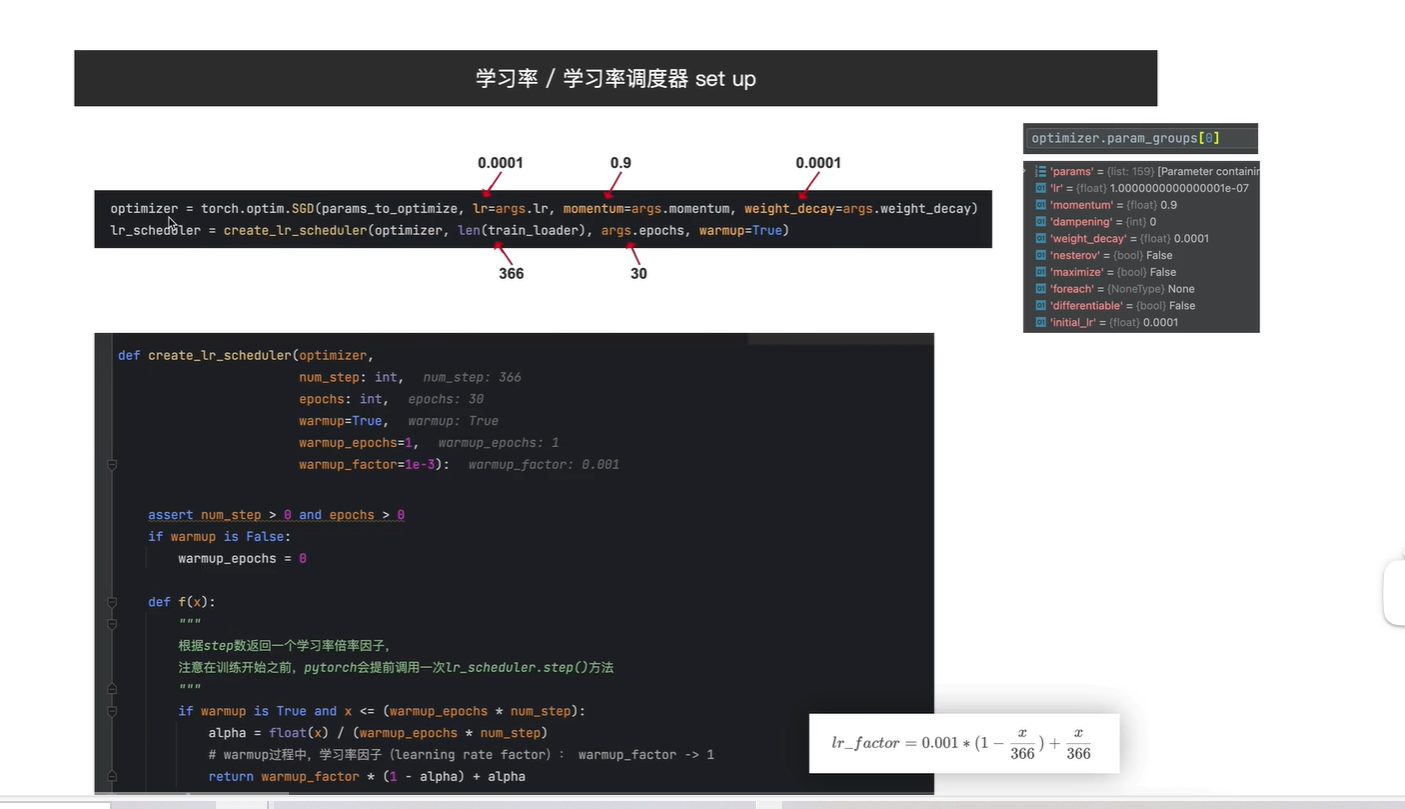

train_loader 图片一个1464张,batch_size=4, 因此1464/4=366, 一个epoch一共可以迭代366次

warmup_epoch 表示在第一个epoch,将学习率逐步调整到初始设定值
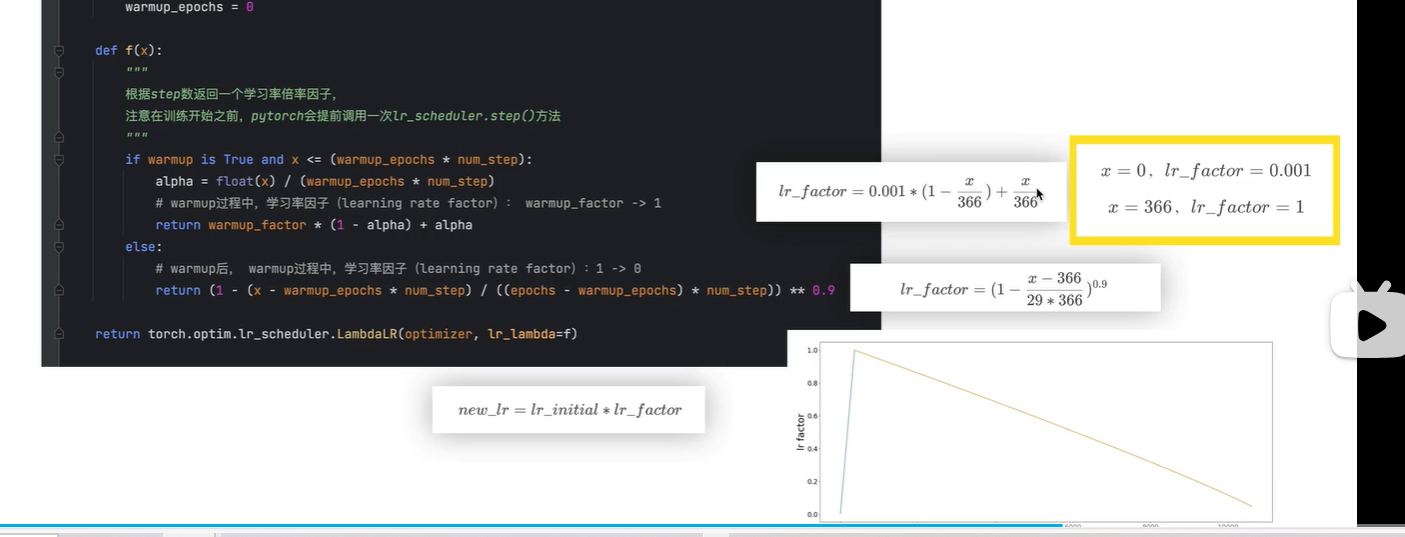
f(x) 中表示 调用f 的次数, 每个batch_size 调用一次
在第一个epoch过去后,学习率公式为右边第二个, x的范围[377, 29*366]
右边折线:学习率变化曲线
蓝色 第一个epoch
橙色:后续29个epoch中lr的变化
10.视频课10:评价指标
评价指标_哔哩哔哩_bilibili

target 标签 ,255表示边界像素,在计算损失时忽略这些值为255的像素点
predict 预测每个像素点对应的标签值: 分别有0,1,2
构造混淆矩阵
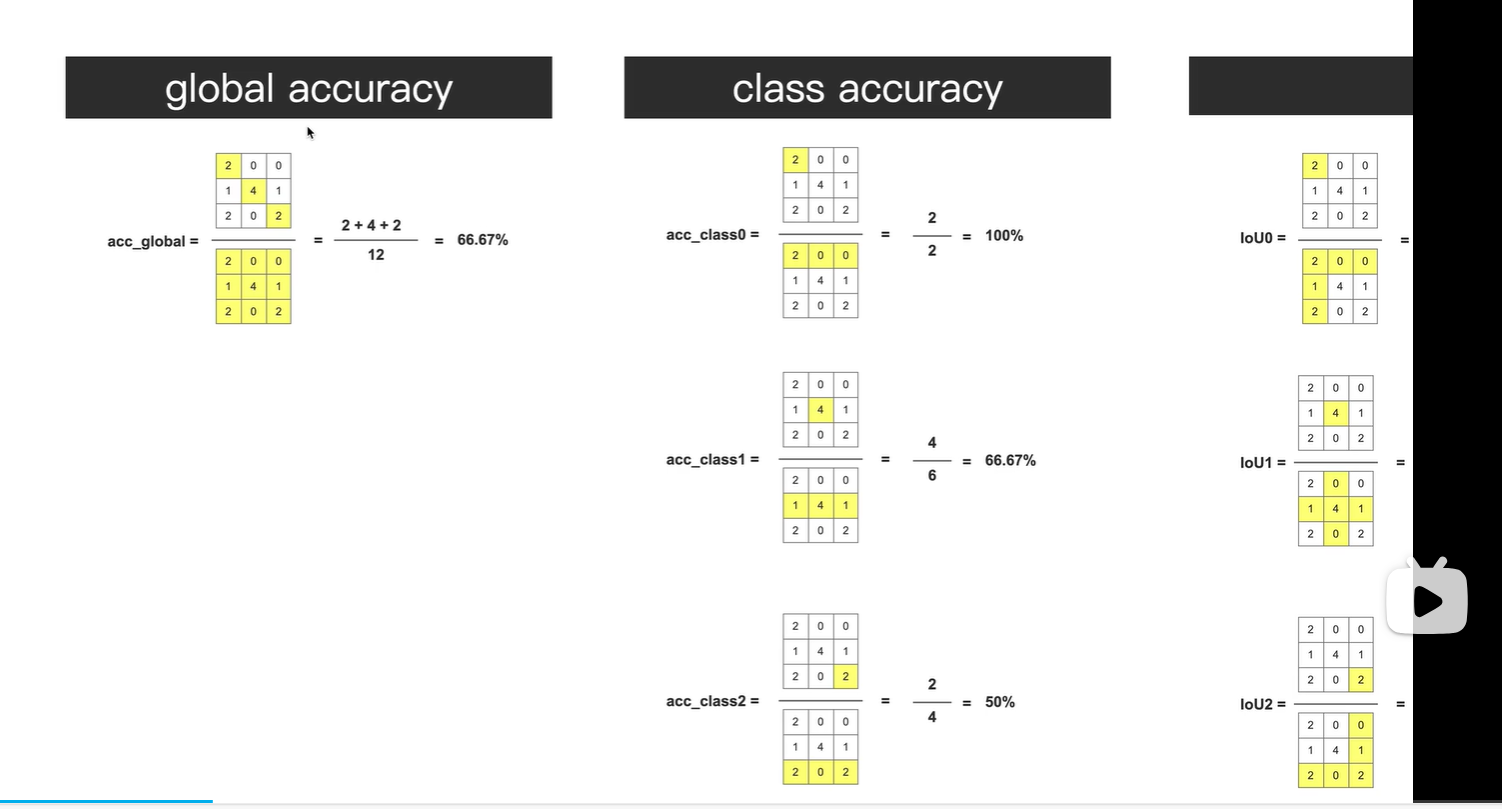
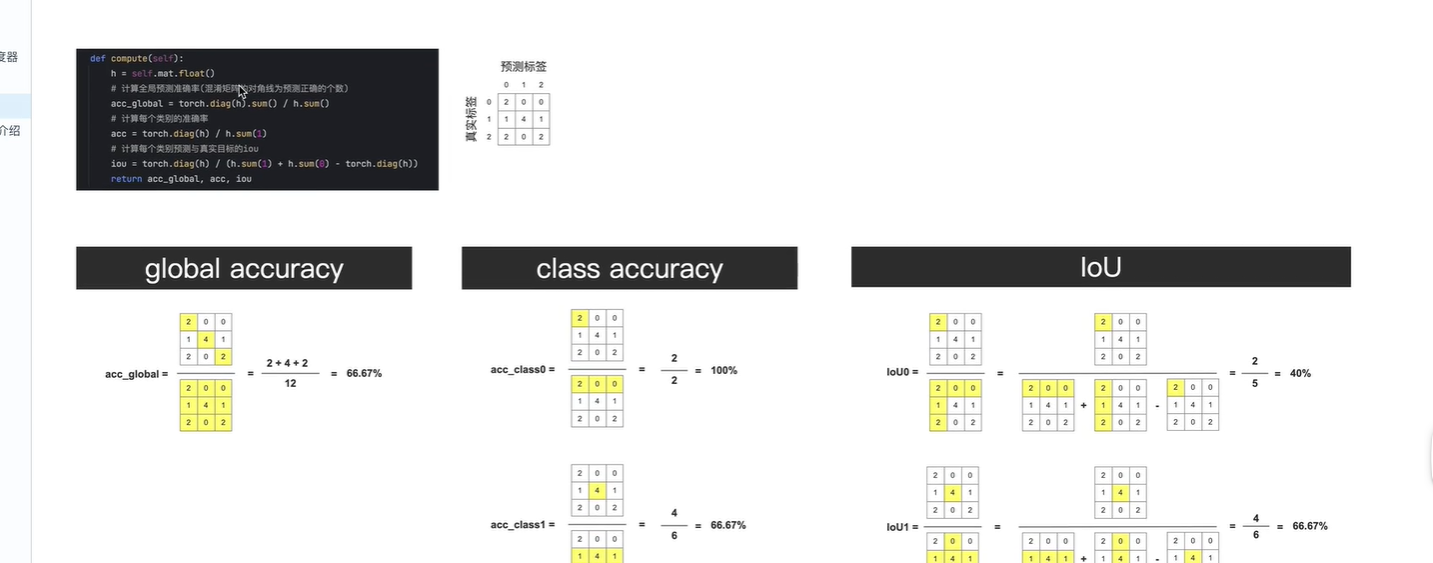
global accuracy 表示所有像素中 预测正确的像素的 占比(所有像素是指排除了像素值等于255的像素)
混淆矩阵的斜对角线, 表示预测正确的像素个数
class accuracy 表示 单个类别 像素预测正确的 占比
共三个类别 class0,class1,class2
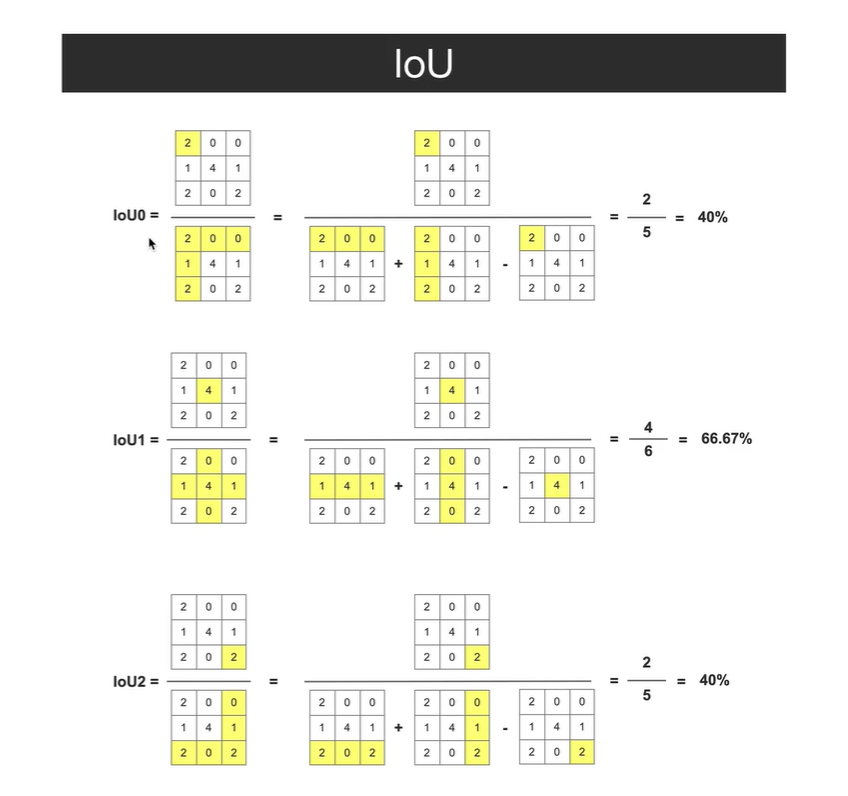
IOU表示:
真实类别为该类别的像素 与 预测类别为该类别的像素的 数量的交并比
如第一行:
真实类别为 行 2 0 0, 预测类别为列 2 1 2
两者交集2, 两者并集 (2+0+0)+(2+1+2)-2=5 减2表示减去重复数
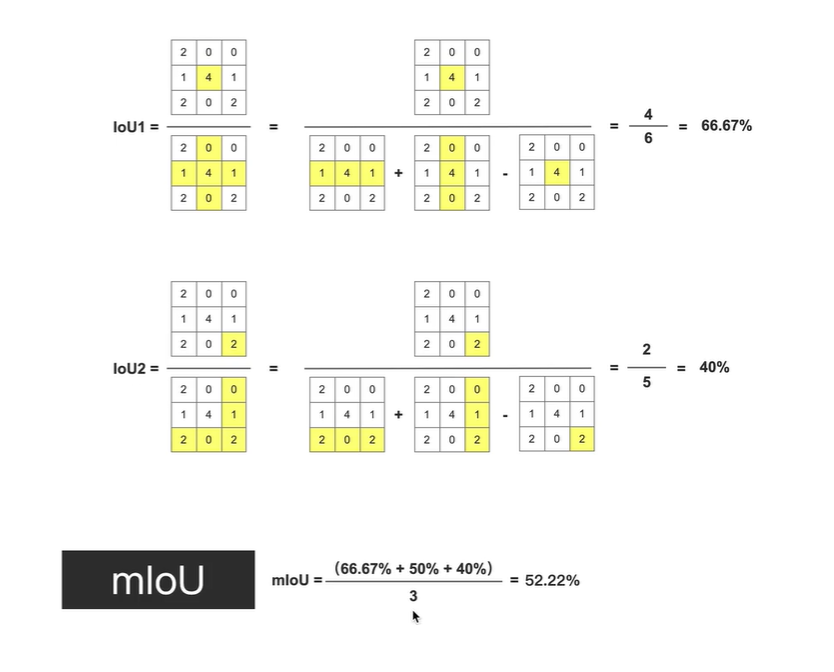
mIoU: 所有类别IoU的均值
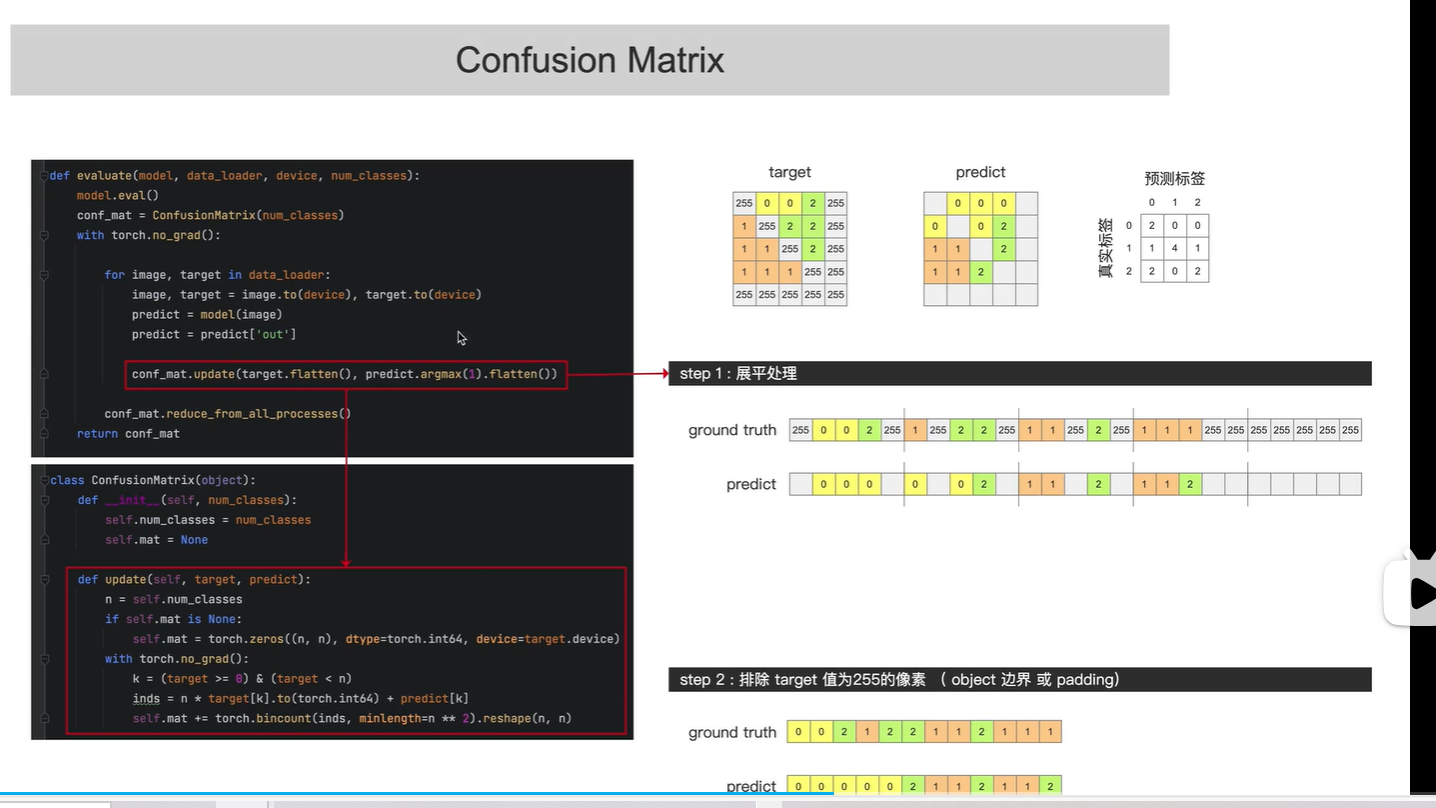
创建混淆矩阵
输入参数:
target.flatten, predict.argmax 展平后target, predict
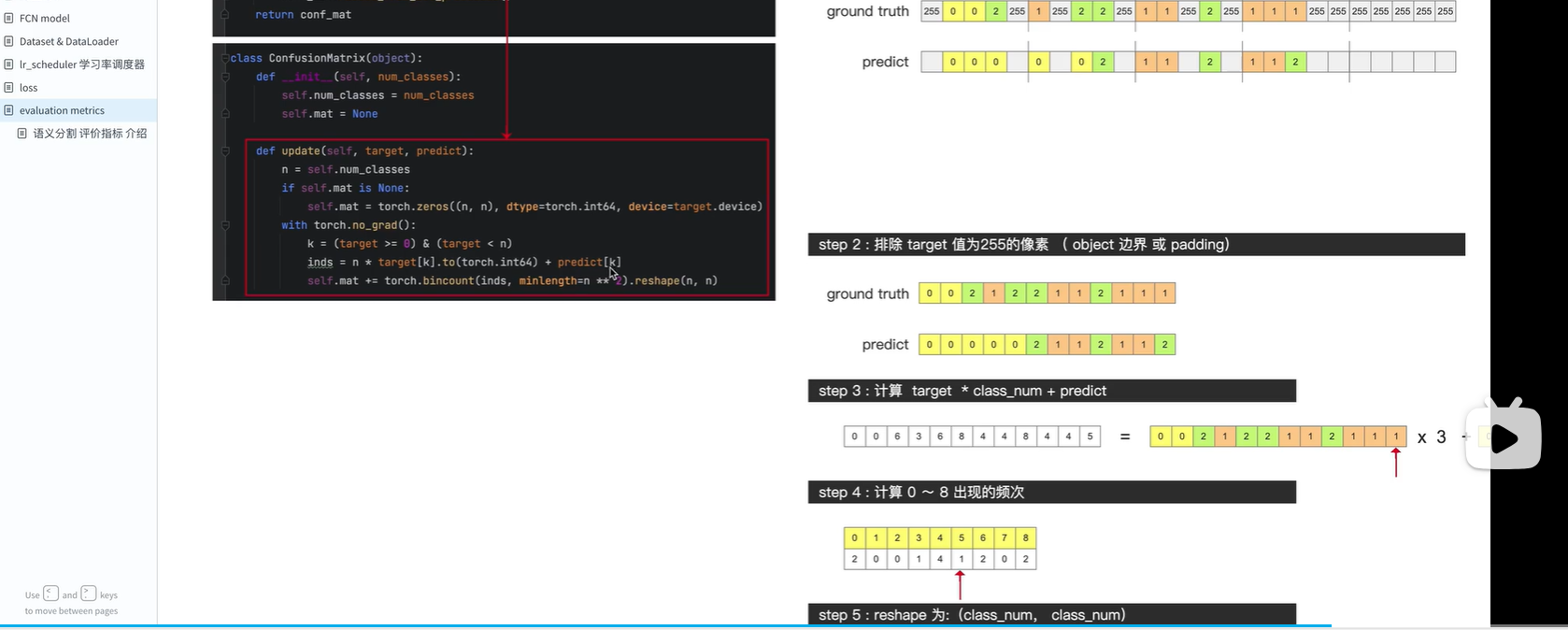
排除target值为255的像素
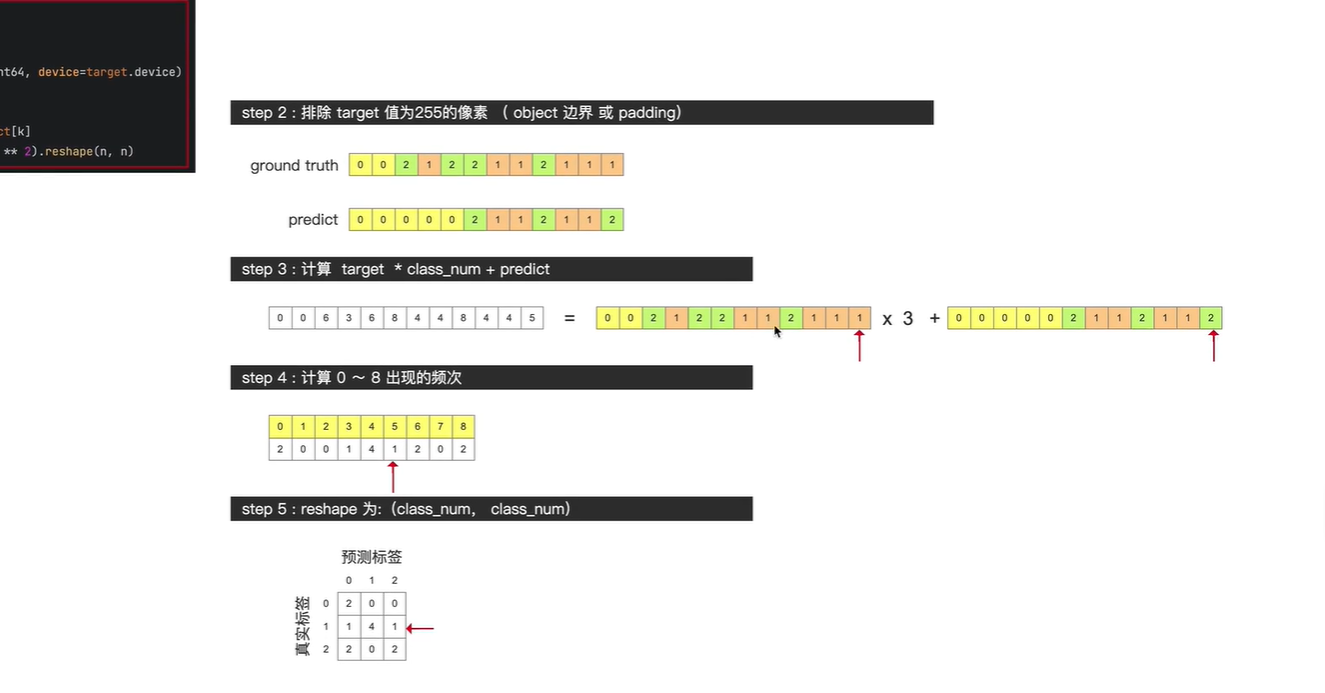
得到混淆矩阵,即可计算 三个评价指标
11.视频课11:predict 预测阶段
predict_哔哩哔哩_bilibili
使用训练好的模型去 分割一张图片
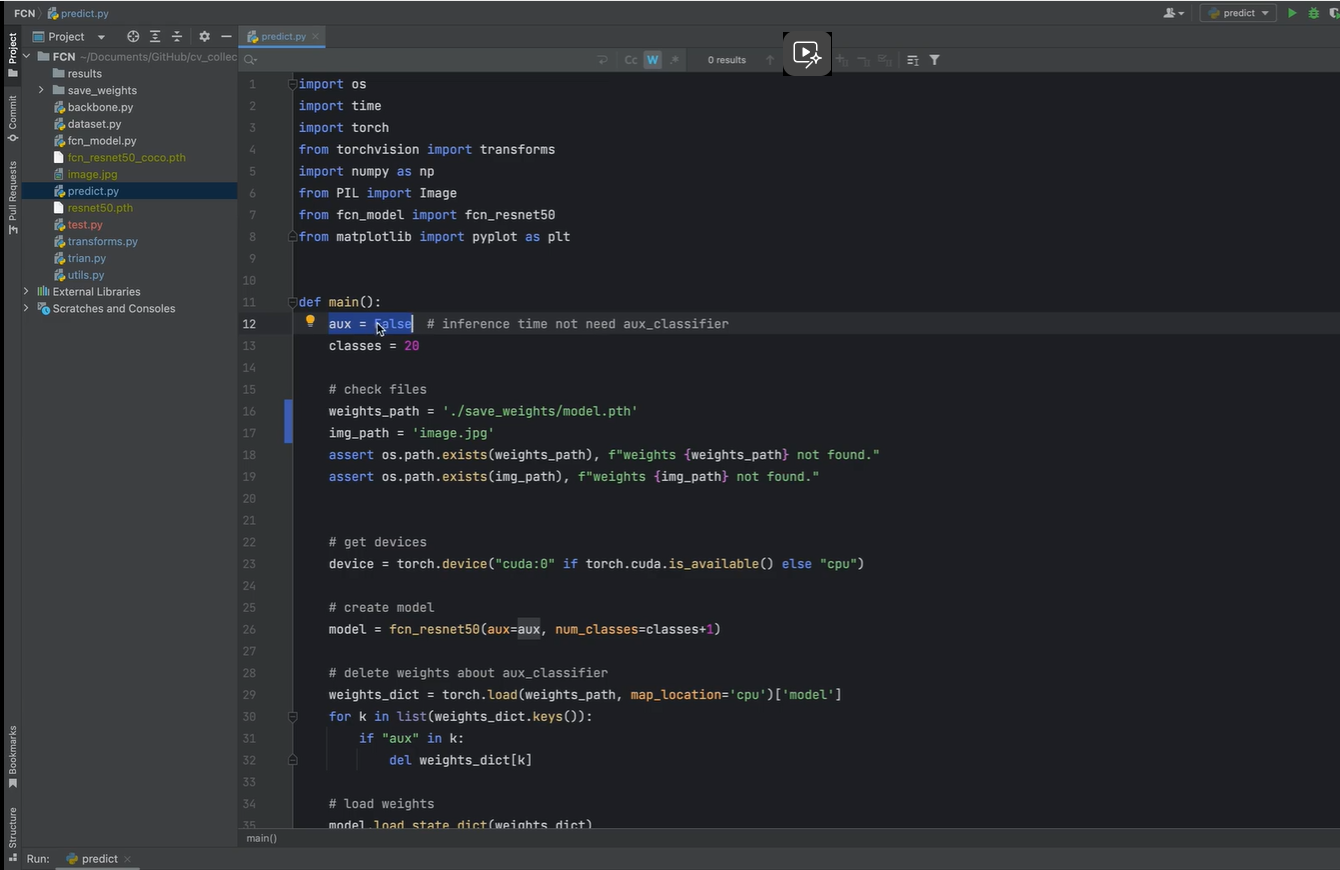
由于不是在训练阶段, 因此 aux(辅佐网络 关闭,设为False)

model.pth 包含:
模型参数信息,优化器信息,学习率调度器信息,以及训练到了第几个epoch等信息
这里只加载模型参数信息 model
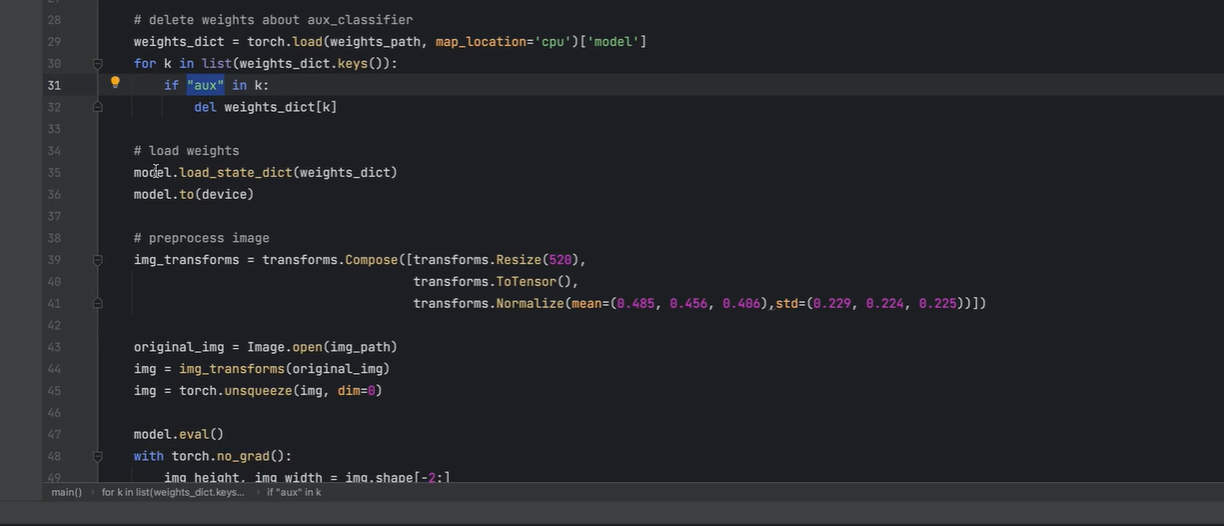
在模型参数里面 把辅佐网络aux删除 ,
把删掉后的参数加载至模型中
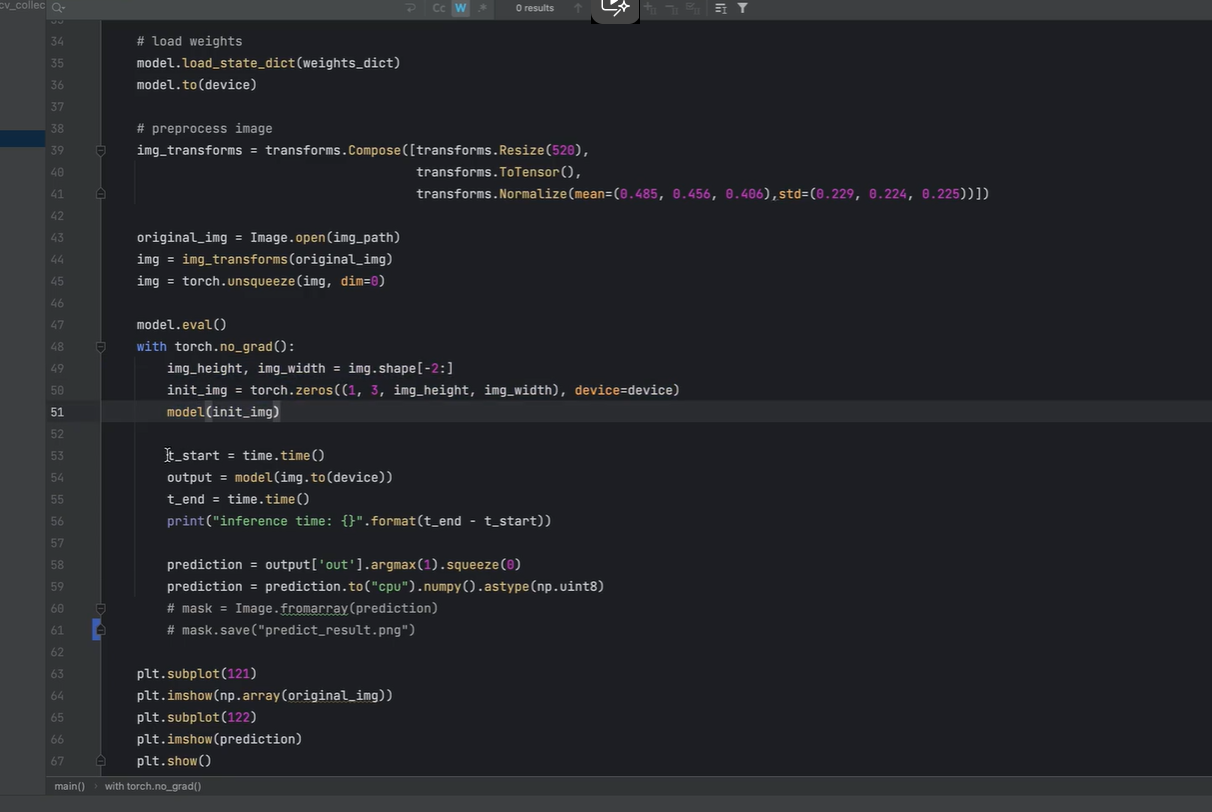

创建一个像素值全为0的图像 ,该图像大小与待检测图像大小相同
因为后续需要测试网络的推理速度,
在第一次预测时,网络需要加载并编译模型,此时计算推理速度不准确,会更长
因此第一次先给网络一张无目标图像
第二次检测图片才计算模型的推理时间

拿到主网络输出,并取出21个类别预测概率最大的 类别 (argmax(1))
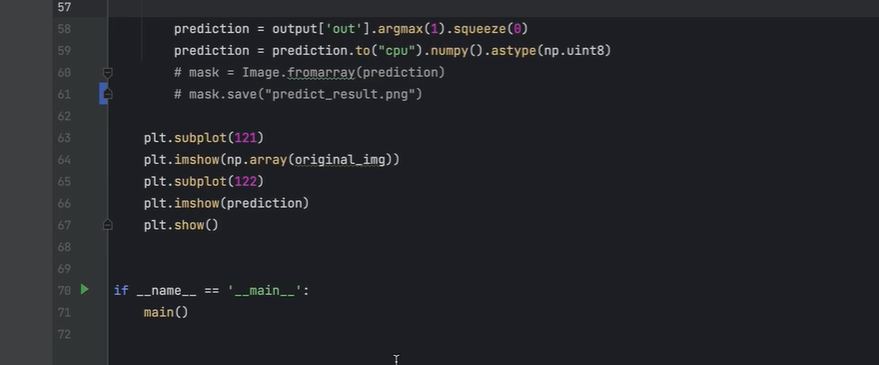
不保存预测结果,直接打印显示
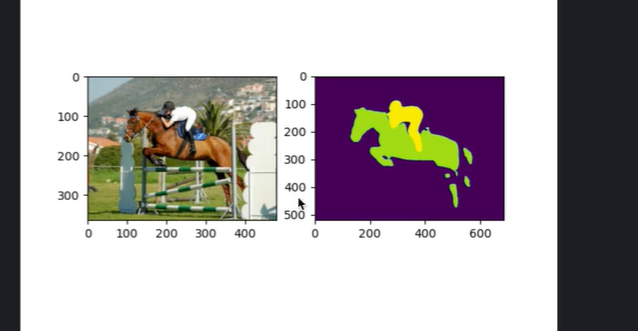

个人小结:
看完视频后,对FCN大概有了些了解
1.先网络模型搭建
2.定义损失函数
3.加载数据集
4.进行模型训练
5.保存训练结果
6.加载模型训练参数预测图片
(可以看看刘二大人)
对于徒手搭建这样一个平台感觉还是比较困难, 许多函数需要写
因此可以使用pytorch框架 搭建, 但是对于其中一些数据 实现、计算的细节 还是不太了解
在加载数据集时,计算损失函数时,预测时
如 背景、目标、边界的 像素的处理:
数据集处理
个人理解:
之前看 mooc 北京理工大学 《python语言程言设计》 嵩天老师所讲,
函数与代码复用,数据驱动, 函数就像一个模块,只要规定好数据格式,模块接收数据模式,然后就可以重复使用,随意输入符合格式的数据,经过模块处理,就能得到想要的处理结果。
2025.7.25记录
听了一天,还是有些收获,
如对代码框架理解,数据的处理流程,
但是如何写出这些程序,尤其是那些细节,还是困惑,只能说多看多练习
参考资料:
up:Enzo_mi
1.语义分割 之 FCN_哔哩哔哩_bilibili
2.膨胀卷积_哔哩哔哩_bilibili
3.转置卷积_哔哩哔哩_bilibili
4.模型搭建 - 网络讲解_哔哩哔哩_bilibili
5.模型搭建 - 代码解读_哔哩哔哩_bilibili
6.数据文件结构与标注图像详解_哔哩哔哩_bilibili
7.图像预处理 (Dataset & DataLoader)_哔哩哔哩_bilibili
8.损失函数_哔哩哔哩_bilibili
9.学习率 / 学习率调度器 设置_哔哩哔哩_bilibili
10.评价指标_哔哩哔哩_bilibili
11.predict_哔哩哔哩_bilibili