算法思维进阶 力扣 62.不同路径 暴力搜索 记忆化搜索 DFS 动态规划 C++详细算法解析 每日一题
目录
- 零、题目描述
- 一、为什么这道题值得你深入理解?
- 二、题目拆解:提取核心关键点
- 三、明确思路:从暴力递归到动态规划的进化
- 四、算法实现:从暴力到优化的完整流程
- 五、从记忆化搜索到动态规划:算法思想的同源与演进
- 动态规划与递归的关键转换:为什么 `dfs(x+1,y)` 变成了 `dp[x-1][y]`?
- 六、记忆化搜索与动态规划
- 七、实现过程中的坑点总结
- 八、举一反三
- 总结
零、题目描述
题目链接:不同路径

示例 1:
输入:m = 3, n = 7
输出:28
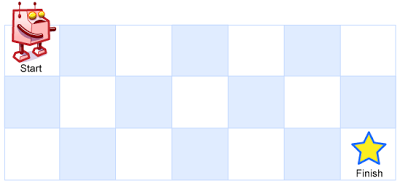
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
1.向右 -> 向下 -> 向下
2.向下 -> 向下 -> 向右
3.向下 -> 向右 -> 向下
提示:
1 <= m, n <= 100
代码框架:
class Solution {
public:int uniquePaths(int m, int n) {}
};
一、为什么这道题值得你深入理解?
“不同路径”作为一道经典的网格类动态规划问题,其价值远不止于“路径计数”的表层需求。它是动态规划与记忆化搜索思想的绝佳实践场,核心逻辑比上一篇博客中讲解的斐波那契数更贴近实际应用场景,能帮你建立“状态定义”与“子问题拆解”的直观认知。
如果还没看过我上一篇详细讲解记忆化搜索的博客,建议先回顾一下。其中对“递归优化”“子问题重复计算”“记忆化搜索”等核心概念的过度与解析,能帮你更快理解本题的优化逻辑——毕竟网格类问题的递归拆解思路,正是斐波那契数中“状态依赖”思想的延伸与具象化。
具体而言,这道题的价值体现在三个方面:
- 清晰展示**“暴力递归→记忆化搜索→动态规划”**的完整优化链条,让你亲眼见证算法效率从指数级到线性级的飞跃,感受“空间换时间”的优化魅力;
- 完美诠释“自顶向下”(递归)与“自底向上”(迭代)两种思维模式的关联与转换——从网格起点到终点的路径拆解,比斐波那契数的线性依赖更能体现“子问题网络”的结构,帮你打通递归与DP之间的逻辑壁垒;
- 为后续解决更复杂的路径规划、网格类动态规划问题(如带障碍的路径、最小路径和、机器人运动范围)奠定扎实基础。这些问题的核心逻辑与“不同路径”一脉相承,只是在状态转移中增加了约束条件。
哪怕你已经写出过解法,重新梳理这道题的思路,仍能让你对“重叠子问题”和“最优子结构”的理解更上一层楼——因为真正的算法能力,不在于“会做”,而在于“看透本质”,并能将本质逻辑迁移到新问题中。
二、题目拆解:提取核心关键点
“不同路径”的问题本质是计数类动态规划,核心要素可拆解为:
- 问题场景:在
m x n的网格中,机器人从左上角(0,0)出发,每次只能向右或向下移动,求到达右下角(m-1,n-1)的路径总数。 - 递推关系:到达格子
(x,y)的路径数 = 到达上方格子(x-1,y)的路径数 + 到达左方格子(x,y-1)的路径数(因为只能从这两个方向过来)。 - 边界条件:
第一行的所有格子(0,y)只有 1 条路径(只能一直向右走);
第一列的所有格子(x,0)只有 1 条路径(只能一直向下走)。
核心矛盾:暴力递归会重复计算大量子问题(如中间格子的路径数被多次求解),需要通过 “存储子问题结果” 来优化,进行剪枝减少递归次数。
三、明确思路:从暴力递归到动态规划的进化
1. 最直观的想法:暴力递归
拿到问题的第一反应:用递归直接拆解问题。
定义 dfs(x,y) 表示“从格子 (x,y) 走到终点 (m-1,n-1) 的路径数,那么:
- 若
x == m-1或y == n-1(到达最后一行或最后一列),则只有 1 条路径(只能一直向右或向下),即dfs(x,y) = 1; - 否则,
dfs(x,y) = dfs(x+1,y) + dfs(x,y+1)(向下走的路径数 + 向右走的路径数)。
以 m=3, n=3 为例,递归过程如下:
dfs(0,0) = dfs(1,0) + dfs(0,1)
dfs(1,0) = dfs(2,0) + dfs(1,1) → dfs(2,0)=1(最后一行)
dfs(0,1) = dfs(1,1) + dfs(0,2) → dfs(0,2)=1(最后一列)
dfs(1,1) = dfs(2,1) + dfs(1,2) → dfs(2,1)=1,dfs(1,2)=1
最终 dfs(0,0) = (1 + (1+1)) + ((1+1) + 1) = 6,结果正确。
但暴力递归的问题在于大量重复计算:例如 dfs(1,1) 在 dfs(1,0) 和 dfs(0,1) 中被计算了两次。当 m 和 n 增大时(如 m=100, n=100),重复计算量会呈指数级增长,导致超时。
2. 优化思路:记忆化搜索(带备忘录的递归)
既然重复计算是核心问题,我们可以用一个“备忘录”存储已计算过的 dfs(x,y) 结果。每次计算前先查备忘录:若已存在,则直接返回;否则计算后存入备忘录。
仍以 m=3, n=3 为例:
- 计算
dfs(0,0)时,需计算dfs(1,0)和dfs(0,1); - 计算
dfs(1,0)时,需计算dfs(2,0)(结果 1,存入备忘录)和dfs(1,1); - 计算
dfs(1,1)时,需计算dfs(2,1)(结果 1)和dfs(1,2)(结果 1),得到dfs(1,1)=2并存入备忘录; - 计算
dfs(0,1)时,需计算dfs(1,1)(直接从备忘录取 2)和dfs(0,2)(结果 1),得到dfs(0,1)=3; - 最终
dfs(0,0) = (1 + 2) + 3 = 6,且所有子问题仅计算一次。
3. 进一步优化:动态规划(自底向上递推)
记忆化搜索采用“自顶向下”的递归策略(从目标状态回溯至边界条件),而动态规划则可通过“自底向上”的递推方式(从边界条件逐层构建至目标状态),利用二维数组系统地存储子问题的解,彻底消除递归调用带来的栈空间开销。
状态定义的智慧
在动态规划中,我们定义 dp[x][y] 表示“从起点 (0,0) 出发,到达格子 (x,y) 的所有可能路径数目”。这与记忆化搜索中 dfs(x,y) 表示的“从 (x,y) 出发到达终点 (m-1,n-1) 的路径数”形成巧妙对偶。两种定义虽方向相反,但本质都是对路径依赖关系的建模。选择正向递推(起点→当前点)而非逆向递推(当前点→终点),是为了让状态转移与代码实现更符合人类直觉,避免逆向循环带来的理解障碍。
状态转移的逻辑链
- 边界条件的物理意义:
- 首行
dp[0][y] ≡ 1:机器人只能从左侧水平移动到达,路径唯一; - 首列
dp[x][0] ≡ 1:机器人只能从上方垂直移动到达,路径唯一。
- 首行
- 递推公式的数学表达:
dp[x][y] = dp[x-1][y] + dp[x][y-1]
(当前格子的路径数 = 上方格子路径数 + 左方格子路径数) - 目标状态的定位:
dp[m-1][n-1]即为所求的终点路径总数。
动态规划的美学价值
这种解法通过迭代而非递归,将路径计算转化为表格填充过程,既避免了栈溢出风险,又实现了时间与空间复杂度的最优解(均为 O(mn))。更重要的是,它揭示了动态规划的本质:用确定性的状态转移替代盲目递归,用空间换时间的策略换取指数级的性能提升。这种思想在网格路径、背包问题、序列比对等经典问题中一以贯之,是算法设计的基石。
逆向递推的可行性与局限
值得注意的是,动态规划也可以采用与递归相同的逆向思维,定义 dp[x][y] 为“从 (x,y) 到终点的路径数”。此时状态转移需从终点开始倒推:
- 边界条件:
dp[m-1][n-1] = 1(终点路径数为1); - 递推公式:
dp[x][y] = dp[x+1][y] + dp[x][y+1](需检查右侧和下方格子); - 遍历顺序:需按行/列从后向前遍历(如
for i in [m-1..0])。
这种实现虽与递归逻辑完全等价,但需处理复杂的边界检查(如 x+1 < m)和逆序循环,代码可读性显著降低。因此,正向递推仍是更优选择,尤其在多维状态转移问题中,方向的选择直接影响代码的简洁性与可维护性。
四、算法实现:从暴力到优化的完整流程
1. 暴力递归:直观但低效
核心逻辑:直接按递推关系递归,不做优化。
class Solution {
public:int m, n;int uniquePaths(int _m, int _n) {m = _m;n = _n;return dfs(0, 0);}int dfs(int x, int y) {// 边界条件:到达最后一行或最后一列,只有1条路径if (x == m - 1 || y == n - 1) {return 1;}// 递归计算:向下走 + 向右走return dfs(x + 1, y) + dfs(x, y + 1);}
};
时间复杂度:O(2^(m+n))(指数级,因为每个格子会分解为两个子问题,大量重复计算)。
空间复杂度:O(m+n)(递归栈深度,最坏为网格对角线长度)。
2. 记忆化搜索:优化重复计算
核心逻辑:添加备忘录存储已计算的 dfs(x,y) 结果,避免重复递归。
class Solution {
public:int mark[100][100]; // 备忘录:存储dfs(x,y)的结果int m, n;int uniquePaths(int _m, int _n) {m = _m;n = _n;memset(mark, -1, sizeof(mark)); // 初始化:-1表示未计算return dfs(0, 0);}int dfs(int x, int y) {// 1. 若已计算,直接返回备忘录中的结果if (mark[x][y] != -1) {return mark[x][y];}// 2. 边界条件:最后一行或最后一列,路径数为1if (x == m - 1 || y == n - 1) {mark[x][y] = 1;return 1;}// 3. 递归计算:向下 + 向右,并将结果存入备忘录mark[x][y] = dfs(x + 1, y) + dfs(x, y + 1);return mark[x][y];}
};
代码详解:
- 备忘录设计:
mark[x][y]存储从(x,y)到终点的路径数,大小为100x100(题目限制m,n≤100)。 - 初始化:
memset(mark, -1, ...)将所有元素设为-1,明确标识“未计算”状态。 - 递归逻辑:
- 先检查
mark[x][y],若已计算则直接返回,避免重复递归; - 处理边界情况(最后一行/列),路径数为 1;
- 计算当前格子的路径数(向下 + 向右),存入备忘录后返回。
- 先检查
时间复杂度:O(mn)(每个格子仅计算一次)。
空间复杂度:O(mn)(备忘录数组 + 递归栈)。
3. 动态规划:自底向上递推
核心逻辑:用二维数组 dp 存储路径数,从边界开始逐步计算到终点。
class Solution {
public:int uniquePaths(int m, int n) {// dp[x][y] 表示从(0,0)到(x,y)的路径数vector<vector<int>> dp(m, vector<int>(n, 1)); // 初始化所有为1// 填充dp数组(从第二行第二列开始)for (int x = 1; x < m; x++) {for (int y = 1; y < n; y++) {dp[x][y] = dp[x - 1][y] + dp[x][y - 1];}}return dp[m - 1][n - 1];}
};
代码详解:
- 状态定义:
dp[x][y]表示从起点(0,0)到(x,y)的路径数。 - 初始化:第一行
dp[0][y]和第一列dp[x][0]均为 1(只有一种走法),因此直接初始化数组为 1。 - 递推计算:对于非边界格子
(x,y),路径数 = 上方格子路径数 + 左方格子路径数。
空间优化:由于 dp[x][y] 只依赖上方 dp[x-1][y] 和左方 dp[x][y-1],可简化为一维数组:
class Solution {
public:int uniquePaths(int m, int n) {vector<int> dp(n, 1); // 一维数组,初始化为1(第一行)for (int x = 1; x < m; x++) {for (int y = 1; y < n; y++) {dp[y] += dp[y - 1]; // 等价于 dp[y] = 上一行的dp[y] + 当前行的dp[y-1]}}return dp[n - 1];}
};
优化后空间复杂度降至 O(n)(或 O(m),取决于保留行还是列)。
五、从记忆化搜索到动态规划:算法思想的同源与演进
当我们动手写记忆化搜索时,其实已经站在了动态规划(DP)的门口。这两种算法看似形式迥异(一个是递归,一个是迭代),但底层逻辑却同出一源——都是对"重复子问题"和"最优子结构"的回应。从记忆化搜索的思考流程中,我们能清晰看到动态规划的影子,而理解这种联系,正是算法思维从"技巧"到"本质"的关键一跃。
记忆化搜索的思考流程:递归视角的"问题拆解"
写记忆化搜索时,我们的思维路径通常是这样的:
- 定义"原子问题":先明确
dfs(x,y)的含义——“从格子(x,y)走到终点(m-1,n-1)的路径数”。这一步对应动态规划中的"状态表示"(dp[x][y]的含义),是整个算法的起点。 - 拆解问题:根据定义,
dfs(x,y)可以拆分为dfs(x+1,y) + dfs(x,y+1)。这正是动态规划中的"状态转移方程",核心是找到子问题之间的依赖关系。 - 处理边界:当
x == m-1或y == n-1时,直接返回已知结果(1)。这对应动态规划中的"初始化",是递归终止(或DP递推起点)的依据。 - 添加备忘录:用
mark数组存储已计算的dfs(x,y)结果,避免重复计算。这与动态规划中"用dp数组存储子问题结果"的核心思想完全一致,只是实现形式不同。 - 递归求解:从
dfs(0,0)出发,通过递归逐步拆解到边界条件,再反向汇总结果。这是"自顶向下"的求解顺序。
动态规划的思考流程:迭代视角的"问题堆砌"
再看动态规划的思考流程,会发现惊人的相似性:
- 定义状态:
dp[x][y]表示"从起点(0,0)走到格子(x,y)的路径数",与dfs(x,y)的含义完全对称(只是方向相反)。 - 推导转移方程:
dp[x][y] = dp[x-1][y] + dp[x][y-1],与记忆化搜索的递归关系完全对应,但方向相反。 - 初始化:
dp[0][y] = 1(第一行)和dp[x][0] = 1(第一列),对应记忆化搜索的边界条件。 - 存储子问题结果:
dp数组本身就是备忘录,记录所有已计算的子问题答案。 - 递推求解:从
dp[1][1]开始,按顺序计算到dp[m-1][n-1],是"自底向上"的求解顺序。
动态规划与递归的关键转换:为什么 dfs(x+1,y) 变成了 dp[x-1][y]?
这个问题是理解两种解法转换的核心。让我们通过一个具体例子来解释:
假设我们要计算dp[2][3](即从起点到(2,3)的路径数)。根据动态规划的状态转移方程:
dp[2][3] = dp[1][3] + dp[2][2]
这里的dp[1][3]和dp[2][2]分别表示从起点到(1,3)和(2,2)的路径数。
现在,让我们从记忆化搜索的角度思考:
如果要计算从(2,3)出发到终点的路径数dfs(2,3),根据递归公式:
dfs(2,3) = dfs(3,3) + dfs(2,4)
这里的dfs(3,3)和dfs(2,4)分别表示从(3,3)和(2,4)出发到终点的路径数。
关键观察:
- 在动态规划中,
dp[x][y]依赖于更小的x和y值(即左方和上方的格子) - 在记忆化搜索中,
dfs(x,y)依赖于更大的x和y值(即右方和下方的格子)
这是因为两种方法的方向是相反的:
- 动态规划是"自底向上",从起点逐步计算到终点
- 记忆化搜索是"自顶向下",从终点递归回起点
因此,递归中的dfs(x+1,y)(向右一步)对应DP中的dp[x-1][y](向左一步的结果),而递归中的dfs(x,y+1)(向下一步)对应DP中的dp[x][y-1](向上一步的结果)。
代码实现的镜像对应
让我们通过代码对比,更直观地看到这种对应关系:
记忆化搜索(递归):
int dfs(int x, int y) {if (mark[x][y] != -1) return mark[x][y];if (x == m-1 || y == n-1) return mark[x][y] = 1;return mark[x][y] = dfs(x+1, y) + dfs(x, y+1);
}
动态规划(迭代):
vector<vector<int>> dp(m, vector<int>(n, 1));
for (int x = 1; x < m; x++) {for (int y = 1; y < n; y++) {dp[x][y] = dp[x-1][y] + dp[x][y-1];}
}
对应关系总结:
| 记忆化搜索(递归) | 动态规划(迭代) | 解释 |
|---|---|---|
dfs(x,y) 的含义 | dp[x][y] 的含义 | 方向相反:从(x,y)到终点 vs 从起点到(x,y) |
边界条件:x == m-1 或 y == n-1 | 初始化:dp[0][y]=1 和 dp[x][0]=1 | 起点的路径数为1 |
递归关系:dfs(x+1,y) + dfs(x,y+1) | 递推关系:dp[x-1][y] + dp[x][y-1] | 方向相反:向下/右 vs 向上/左 |
| 计算顺序:递归调用(按需计算) | 计算顺序:双重循环(按顺序填充) | 自顶向下 vs 自底向上 |
同源与差异
记忆化搜索与动态规划的本质,都是**“存储子问题结果以避免重复计算”**。它们的核心要素完全一一对应:
| 记忆化搜索(递归) | 动态规划(迭代) | 本质作用 |
|---|---|---|
dfs(x,y) 的定义 | dp[x][y] 的定义 | 明确“子问题是什么” |
递归关系 dfs(x,y) = ... | 转移方程 dp[x][y] = ... | 明确“子问题如何依赖” |
| 递归终止条件 | dp数组初始化 | 明确“最小子问题的解” |
mark 备忘录 | dp 数组 | 存储子问题结果,避免重复计算 |
| 自顶向下(从n到0) | 自底向上(从0到n) | 遍历子问题的顺序不同 |
这种对应关系并非偶然。从数学上看,记忆化搜索是动态规划的“递归实现”,动态规划是记忆化搜索的“迭代实现”。它们就像一枚硬币的两面:一个从目标出发拆解问题,一个从基础出发堆砌答案,但最终都指向同一个结果。
六、记忆化搜索与动态规划
| 维度 | 记忆化搜索(递归) | 动态规划(递推) |
|---|---|---|
| 核心思路 | 自顶向下:从目标 n 分解到已知边界 0/1 | 自底向上:从已知边界 0/1 推到目标 n |
| 状态表示 | dfs(k):第 k 个斐波那契数 | dp[k]:第 k 个斐波那契数 |
| 状态转移方程 | dfs(k) = dfs(k-1) + dfs(k-2) | dp[k] = dp[k-1] + dp[k-2] |
| 初始化(边界条件) | dfs(0)=0,dfs(1)=1 | dp[0]=0,dp[1]=1 |
| 计算顺序 | 依赖递归调用,按需计算(需要哪个 k 才计算) | 按顺序计算,从 2 到 n 依次填充 |
| 存储方式 | 备忘录(数组 mark)存储已计算结果 | dp 数组存储所有结果(优化后可省数组) |
| 空间开销 | 递归栈 + 备忘录(O(n)) | 数组(优化后 O(1)) |
| 适用场景 | 子问题不密集(不是所有子问题都需要计算) | 子问题密集(大部分子问题都需要计算) |
本质联系:两者都是对暴力递归的优化,核心是存储已计算的子问题结果,避免重复计算。记忆化搜索更像“按需计算”,动态规划更像“批量计算”,最终时间复杂度相同,但实现方式和适用场景不同。
七、实现过程中的坑点总结
-
递归栈溢出
暴力递归在n较大时(比如n=30)虽然能算出结果,但递归深度过深可能导致栈溢出(不过本题n≤30影响不大,更大的n就必须优化)。
解决:用记忆化搜索或动态规划替代。 -
备忘录初始化错误
记忆化搜索中,若忘记初始化备忘录(比如mark未设为-1),可能导致误读未计算的内存值(比如随机值),结果错误。
解决:初始化时明确标记“未计算”状态(如-1)。 -
动态规划的边界处理
当n=0或n=1时,若直接进入循环计算,会导致逻辑错误(比如n=0时dp数组越界)。
解决:先单独处理边界情况,再进入循环。 -
矩阵快速幂的矩阵乘法错误
矩阵乘法的顺序、维度计算容易出错(比如 2x2 矩阵相乘的元素对应关系)。
解决:手动推导一次矩阵乘法过程,确保公式正确。
八、举一反三
“不同路径”的核心是“当前状态依赖前序状态”,掌握这一逻辑可解决以下问题:
- LeetCode 63. 不同路径 II(带障碍物的网格):在递推时判断当前格子是否为障碍物,若为障碍物则路径数为 0。
- LeetCode 64. 最小路径和:将路径数改为路径和,递推关系变为“取上方和左方的最小值 + 当前格子值”。
- 机器人移动范围:类似的网格递归问题,可通过记忆化搜索标记已访问格子,避免重复计算。
总结
“不同路径”看似简单,却完整展现了“暴力递归→记忆化搜索→动态规划”的算法优化链条。理解 dfs(x,y) 与 dp[x][y] 的状态定义,以及它们背后的递推关系,是掌握动态规划的关键。
记忆化搜索让我们直观感受到“空间换时间”的优化思想,动态规划则让我们学会“自底向上”的高效计算。这两种思路的灵活转换,将是解决复杂动态规划问题的重要基础。
下一篇,我们就来讨论力扣 300.最长递增子序列啦。感兴趣的朋友,不妨提前去原题页面逛逛,熟悉下题目背景,这样后面听讲解时或许会更有收获哦~
最后欢迎大家在评论区分享你的代码或思路,咱们一起交流探讨~ 🌟 要是有大佬有更精妙的思路或想法,恳请在评论区多多指点批评,我一定会虚心学习,并且第一时间回复交流哒!

这是封面原图~ 喜欢的话先点个赞鼓励一下呗~ 再顺手关注一波,后续更新不迷路,保证让你看得过瘾!😉
