图片查重从设计到实现(4)图片向量化存储-Milvus 单机版部署
Milvus 单机版部署
在 Docker 环境下安装、应用和配置 Milvus 向量数据库可以按照以下步骤进行,涵盖从安装到基础应用的完整流程:
1. 部署前准备
- 服务器:建议测试环境配置 2 核 CPU、8GB 内存;处理 100 万组向量数据,推荐 4 核 CPU、16GB 内存及 50GB 存储;500 万组向量数据则需 8 核 CPU、32GB 内存及 200GB 存储 。
- 软件层面,服务器需安装 Docker
1.1 Milvus 单机版镜像
# 拉取最新版 Milvus 单机版镜像
docker pull milvusdb/milvus:latest# 或指定具体版本(推荐,版本更稳定)
docker pull milvusdb/milvus:v2.4.5
1.2 MinIO 镜像(对象存储)
docker pull minio/minio:RELEASE.2023-03-20T20-16-18Z参考图片存储MinIO 应用介绍及 Docker 环境下的安装部署
1.3拉取 etcd 镜像(元数据存储)
# Milvus 推荐的 etcd 版本
docker pull quay.io/coreos/etcd:v3.5.5
Milvus安装准备etcd介绍、应用场景及Docker安装配置
2. 启动 Milvus 单机服务
2.1配置文件 milvus-config
文件挂载的目录下

进入milvus-config,在线拉去配置文件
wget https://raw.githubusercontent.com/milvus-io/milvus/v2.4.5/configs/milvus.yaml2.2 etcd的配置
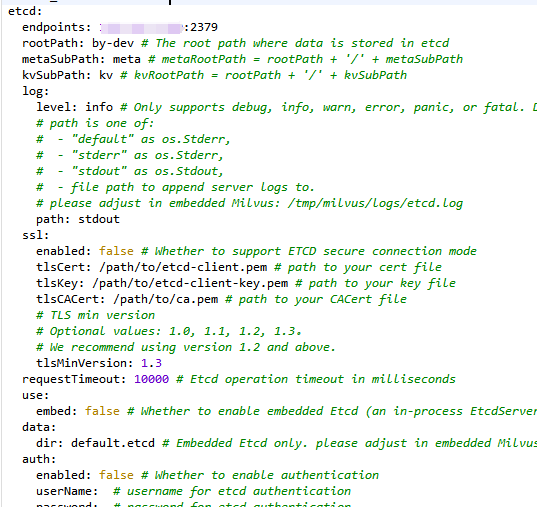
2.3 mino的配置
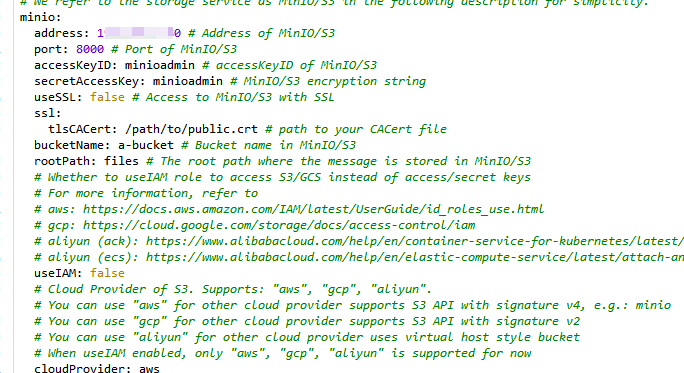
3. 启动服务
docker run -d \--name milvus245 \ # 容器名称,方便后续管理-p 19530:19530 \ # 端口映射:宿主机19530 -> 容器19530(客户端连接端口)-p 9091:9091 \ # 端口映射:宿主机9091 -> 容器9091(监控/健康检查端口)--privileged \ # 授予容器特权模式(避免部分文件系统权限问题)-v /data/milvus/milvus-config/milvus.yaml:/milvus/configs/milvus.yaml \ # 挂载自定义配置文件-v /data/milvus/milvus-data:/milvus/data \ # 挂载数据目录(持久化向量数据)-v /data/milvus/milvus-var:/var/lib/milvus \ # 挂载var目录(内部状态文件)-v /data/milvus/milvus-logs:/milvus/logs \ # 挂载日志目录(持久化日志)milvusdb/milvus:v2.4.5 \ # 使用的镜像:Milvus 2.4.5版本milvus run standalone # 容器启动命令:以单机模式运行Milvus
关键参数说明
- –name milvus245
为容器指定一个唯一名称(milvus245),后续可通过该名称操作容器(如 docker stop milvus245),避免使用自动生成的随机名称。
端口映射(-p)
19530:Milvus 客户端 SDK 连接的端口(如 Python 的 pymilvus、Java SDK 等)。
9091:Milvus 监控和健康检查端口,可通过 http://localhost:9091/healthz 检查服务状态。 - –privileged
授予容器特权模式,解决部分环境下因文件系统权限不足导致的启动失败(如宿主机目录权限严格时),非必需但建议添加以避免权限问题。 - 数据持久化(-v 挂载)
通过 volume 挂载将容器内的关键目录映射到宿主机,确保容器删除后数据不丢失:
配置文件:/data/milvus/milvus-config/milvus.yaml(宿主机)→ /milvus/configs/milvus.yaml(容器),用于加载自定义配置。
数据目录:/milvus/data 存储向量数据和索引文件,映射到宿主机 /data/milvus/milvus-data。 - 日志目录:/milvus/logs 存储运行日志,映射到宿主机 /data/milvus/milvus-logs,方便问题排查。
- 启动命令(milvus run standalone)
明确指定 Milvus 以单机模式(standalone)运行,这是 v2.4.x 版本的标准启动方式,确保 tini 初始化进程能正确启动 Milvus 主服务。
4. 检查服务状态
# 检查健康状态
curl http://localhost:9091/healthz# 查看版本信息
curl http://localhost:9091/v1/version

5、基础操作示例
使用 Python 客户端连接并操作 Milvus:
# 安装客户端
# pip install pymilvusfrom pymilvus import (connections,utility,FieldSchema,CollectionSchema,DataType,Collection,
)
import random# 1. 连接到 Milvus
connections.connect(alias="default",host="localhost", # 若在远程服务器,替换为实际IPport="19530"
)# 2. 定义集合名称
collection_name = "demo_vectors"# 3. 若集合已存在则删除
if utility.has_collection(collection_name):utility.drop_collection(collection_name)# 4. 定义集合结构
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384), # 384维向量FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50) # 分类信息
]schema = CollectionSchema(fields=fields,description="演示用向量集合"
)# 5. 创建集合
collection = Collection(name=collection_name, schema=schema)# 6. 创建索引
index_params = {"index_type": "IVF_FLAT","metric_type": "COSINE", # 使用余弦相似度"params": {"nlist": 128}
}collection.create_index(field_name="embedding",index_params=index_params
)# 7. 插入示例数据
num_entities = 1000
data = [[i for i in range(num_entities)], # id[[random.random() for _ in range(384)] for _ in range(num_entities)], # 向量[f"category_{random.randint(1, 10)}" for _ in range(num_entities)] # 分类
]insert_result = collection.insert(data)
print(f"成功插入 {len(insert_result.primary_keys)} 条数据")# 8. 加载集合到内存
collection.load()# 9. 执行向量搜索
query_vector = [[random.random() for _ in range(384)]] # 生成查询向量search_params = {"metric_type": "COSINE","params": {"nprobe": 10}
}results = collection.search(data=query_vector,anns_field="embedding",param=search_params,limit=5, # 返回前5个最相似结果output_fields=["category"]
)# 10. 输出搜索结果
print("\n搜索结果(按相似度排序):")
for hit in results[0]:print(f"ID: {hit.id}, 分类: {hit.entity.get('category')}, 相似度: {1 - hit.distance:.4f}")# 11. 释放集合
collection.release()# 12. 断开连接
connections.disconnect("default")总结
通过以上步骤,即可完成 Milvus 单机版在 Docker 环境下的部署、配置及基础应用。这种部署方式适合中小规模向量数据的管理与检索场景,如实验环境测试、小型 AI 应用开发等。==