动态规划Day1学习心得
今天开始学习动态规划的内容。
什么是动态规划
动态规划,英文:Dynamic Programming,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。
所以动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推导,而是从局部直接选最优的,
例如:有N件物品和一个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
动态规划中dp[j]是由dp[j-weight[i]]推导出来的,然后取max(dp[j], dp[j - weight[i]] + value[i])。
但如果是贪心呢,每次拿物品选一个最大的或者最小的就完事了,和上一个状态没有关系。
所以贪心解决不了动态规划的问题。
动规是由前一个状态推导出来的,而贪心是局部直接选最优的。
动态规划的解题步骤
状态转移公式(递推公式)是很重要,但动规不仅仅只有递推公式。
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
第一道:509. 斐波那契数 - 力扣(LeetCode)
class Solution {
public:int fib(int N) {if (N <= 1) return N;vector<int> dp(N + 1);dp[0] = 0;dp[1] = 1;for (int i = 2; i <= N; i++) {dp[i] = dp[i - 1] + dp[i - 2];}return dp[N];}
};前面的题目都比较简单,大家看一看代码应该就能明白。
第二道:70. 爬楼梯 - 力扣(LeetCode)
dp[i] = dp[i - 1] + dp[i - 2]
class Solution {
public:int climbStairs(int n) {if (n <= 1) return n; // 因为下面直接对dp[2]操作了,防止空指针vector<int> dp(n + 1);dp[1] = 1;dp[2] = 2;for (int i = 3; i <= n; i++) { // 注意i是从3开始的dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];}
};第三道:746. 使用最小花费爬楼梯 - 力扣(LeetCode)
这道题目需要注意每一次爬楼梯都有一个花费的问题,需要修改一下转移方程。
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2])
class Solution {
public:int minCostClimbingStairs(vector<int>& cost) {vector<int> dp(cost.size() + 1);dp[0] = 0; // 默认第一步都是不花费体力的dp[1] = 0;for (int i = 2; i <= cost.size(); i++) {dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);}return dp[cost.size()];}
};第四道:62. 不同路径 - 力扣(LeetCode)
这道题目也很简单,有点小学奥数的感觉。
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
class Solution {
public:int uniquePaths(int m, int n) {vector<vector<int>> dp(m, vector<int>(n, 0));for (int i = 0; i < m; i++) dp[i][0] = 1;for (int j = 0; j < n; j++) dp[0][j] = 1;for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}}return dp[m - 1][n - 1];}
};然后是变题:63. 不同路径 II - 力扣(LeetCode)
这道题目的思路与上一道相似,但是要针对障碍修改初始化条件,同时需要注意第一排和第一列,一旦遇到障碍,后面的或者是下面的地方都再也无法到达。
class Solution {
public:int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {int m = obstacleGrid.size();int n = obstacleGrid[0].size();if (obstacleGrid[m - 1][n - 1] == 1 || obstacleGrid[0][0] == 1) //如果在起点或终点出现了障碍,直接返回0return 0;vector<vector<int>> dp(m, vector<int>(n, 0));for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) dp[i][0] = 1;for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) dp[0][j] = 1;for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {if (obstacleGrid[i][j] == 1) continue;dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}}return dp[m - 1][n - 1];}然后是第六道:343. 整数拆分 - 力扣(LeetCode)
这道题有点反直觉,看一下动态规划的分析。
动规五部曲,分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i]:分拆数字i,可以得到的最大乘积为dp[i]。
dp[i]的定义将贯彻整个解题过程,下面哪一步想不懂了,就想想dp[i]究竟表示的是啥!
- 确定递推公式
可以想 dp[i]最大乘积是怎么得到的呢?
其实可以从1遍历j,然后有两种渠道得到dp[i].
一个是j * (i - j) 直接相乘。
一个是j * dp[i - j],相当于是拆分(i - j),对这个拆分不理解的话,可以回想dp数组的定义。
j是从1开始遍历,拆分j的情况,在遍历j的过程中其实都计算过了。那么从1遍历j,比较(i - j) * j和dp[i - j] * j 取最大的。递推公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
也可以这么理解,j * (i - j) 是单纯的把整数拆分为两个数相乘,而j * dp[i - j]是拆分成两个以及两个以上的个数相乘。
如果定义dp[i - j] * dp[j] 也是默认将一个数强制拆成4份以及4份以上了。
所以递推公式:dp[i] = max({dp[i], (i - j) * j, dp[i - j] * j});
那么在取最大值的时候,为什么还要比较dp[i]呢?
因为在递推公式推导的过程中,每次计算dp[i],取最大的而已。
- dp的初始化
dp[0] dp[1]应该初始化多少呢?
有的题解里会给出dp[0] = 1,dp[1] = 1的初始化,但解释比较牵强,主要还是因为这么初始化可以把题目过了。
严格从dp[i]的定义来说,dp[0] dp[1] 就不应该初始化,也就是没有意义的数值。
拆分0和拆分1的最大乘积是多少?
这是无解的。
这里只初始化dp[2] = 1,从dp[i]的定义来说,拆分数字2,得到的最大乘积是1,这个没有任何异议!
- 确定遍历顺序
确定遍历顺序,先来看看递归公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
dp[i] 是依靠 dp[i - j]的状态,所以遍历i一定是从前向后遍历,先有dp[i - j]再有dp[i]。
所以遍历顺序为:
for (int i = 3; i <= n ; i++) {for (int j = 1; j < i - 1; j++) {dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));}
}
注意 枚举j的时候,是从1开始的。从0开始的话,那么让拆分一个数拆个0,求最大乘积就没有意义了。
j的结束条件是 j < i - 1 ,其实 j < i 也是可以的,不过可以节省一步,例如让j = i - 1,的话,其实在 j = 1的时候,这一步就已经拆出来了,重复计算,所以 j < i - 1
至于 i是从3开始,这样dp[i - j]就是dp[2]正好可以通过我们初始化的数值求出来。
更优化一步,可以这样:
for (int i = 3; i <= n ; i++) {for (int j = 1; j <= i / 2; j++) {dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));}
}
因为拆分一个数n 使之乘积最大,那么一定是拆分成m个近似相同的子数相乘才是最大的。
例如 6 拆成 3 * 3, 10 拆成 3 * 3 * 4。 100的话 也是拆成m个近似数组的子数 相乘才是最大的。
只不过我们不知道m究竟是多少而已,但可以明确的是m一定大于等于2,既然m大于等于2,也就是 最差也应该是拆成两个相同的 可能是最大值。
那么 j 遍历,只需要遍历到 n/2 就可以,后面就没有必要遍历了,一定不是最大值。
至于 “拆分一个数n 使之乘积最大,那么一定是拆分成m个近似相同的子数相乘才是最大的” 这个我就不去做数学证明了,感兴趣的同学,可以自己证明。
- 举例推导dp数组
举例当n为10 的时候,dp数组里的数值,如下:
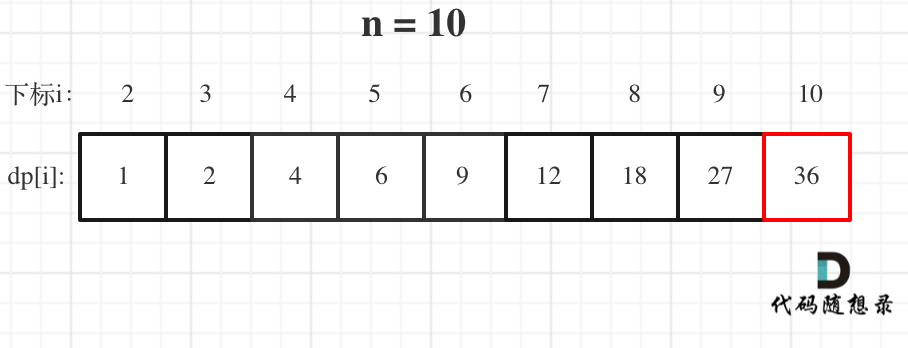
以上动规五部曲分析完毕,C++代码如下:
class Solution {
public:int integerBreak(int n) {vector<int> dp(n + 1);dp[2] = 1;for (int i = 3; i <= n ; i++) {for (int j = 1; j <= i / 2; j++) {dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));}}return dp[n];}
};然后看最后一道:96. 不同的二叉搜索树 - 力扣(LeetCode)
- 确定dp数组(dp table)以及下标的含义
dp[i] : 1到i为节点组成的二叉搜索树的个数为dp[i]。
也可以理解是i个不同元素节点组成的二叉搜索树的个数为dp[i] ,都是一样的。
以下分析如果想不清楚,就来回想一下dp[i]的定义
- 确定递推公式
在上面的分析中,其实已经看出其递推关系, dp[i] += dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量]
j相当于是头结点的元素,从1遍历到i为止。
所以递推公式:dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量
- dp数组如何初始化
初始化,只需要初始化dp[0]就可以了,推导的基础,都是dp[0]。
那么dp[0]应该是多少呢?
从定义上来讲,空节点也是一棵二叉树,也是一棵二叉搜索树,这是可以说得通的。
从递归公式上来讲,dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量] 中以j为头结点左子树节点数量为0,也需要dp[以j为头结点左子树节点数量] = 1, 否则乘法的结果就都变成0了。
所以初始化dp[0] = 1
- 确定遍历顺序
首先一定是遍历节点数,从递归公式:dp[i] += dp[j - 1] * dp[i - j]可以看出,节点数为i的状态是依靠 i之前节点数的状态。
那么遍历i里面每一个数作为头结点的状态,用j来遍历。
代码如下:
for (int i = 1; i <= n; i++) {for (int j = 1; j <= i; j++) {dp[i] += dp[j - 1] * dp[i - j];}
}
- 举例推导dp数组
n为5时候的dp数组状态如图:
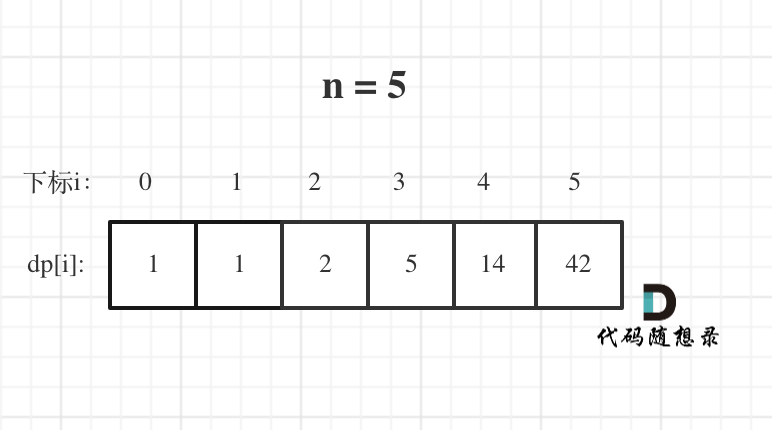
当然如果自己画图举例的话,基本举例到n为3就可以了,n为4的时候,画图已经比较麻烦了。
我这里列到了n为5的情况,是为了方便大家 debug代码的时候,把dp数组打出来,看看哪里有问题。
综上分析完毕,C++代码如下:
class Solution {
public:int numTrees(int n) {vector<int> dp(n + 1);dp[0] = 1;for (int i = 1; i <= n; i++) {for (int j = 1; j <= i; j++) {dp[i] += dp[j - 1] * dp[i - j];}}return dp[n];}
};