大型微服务项目:听书——11 Redisson分布式布隆过滤器+Redisson分布式锁改造专辑详情接口
11 Redisson分布式布隆过滤器+Redisson分布式锁改造专辑详情接口
11.1 缓存穿透解决方案&布隆过滤器
-
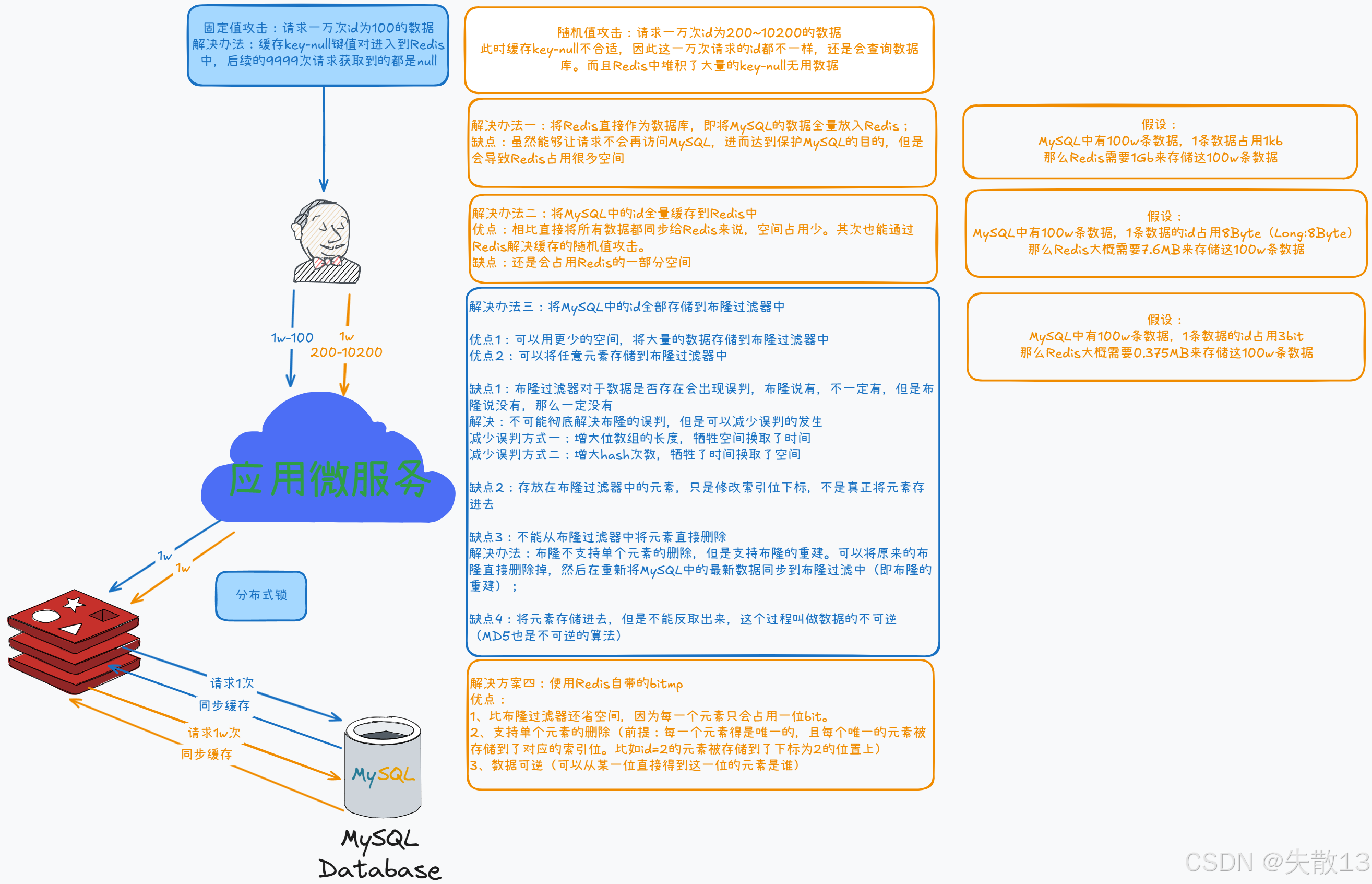
缓存穿透解决方案:
-
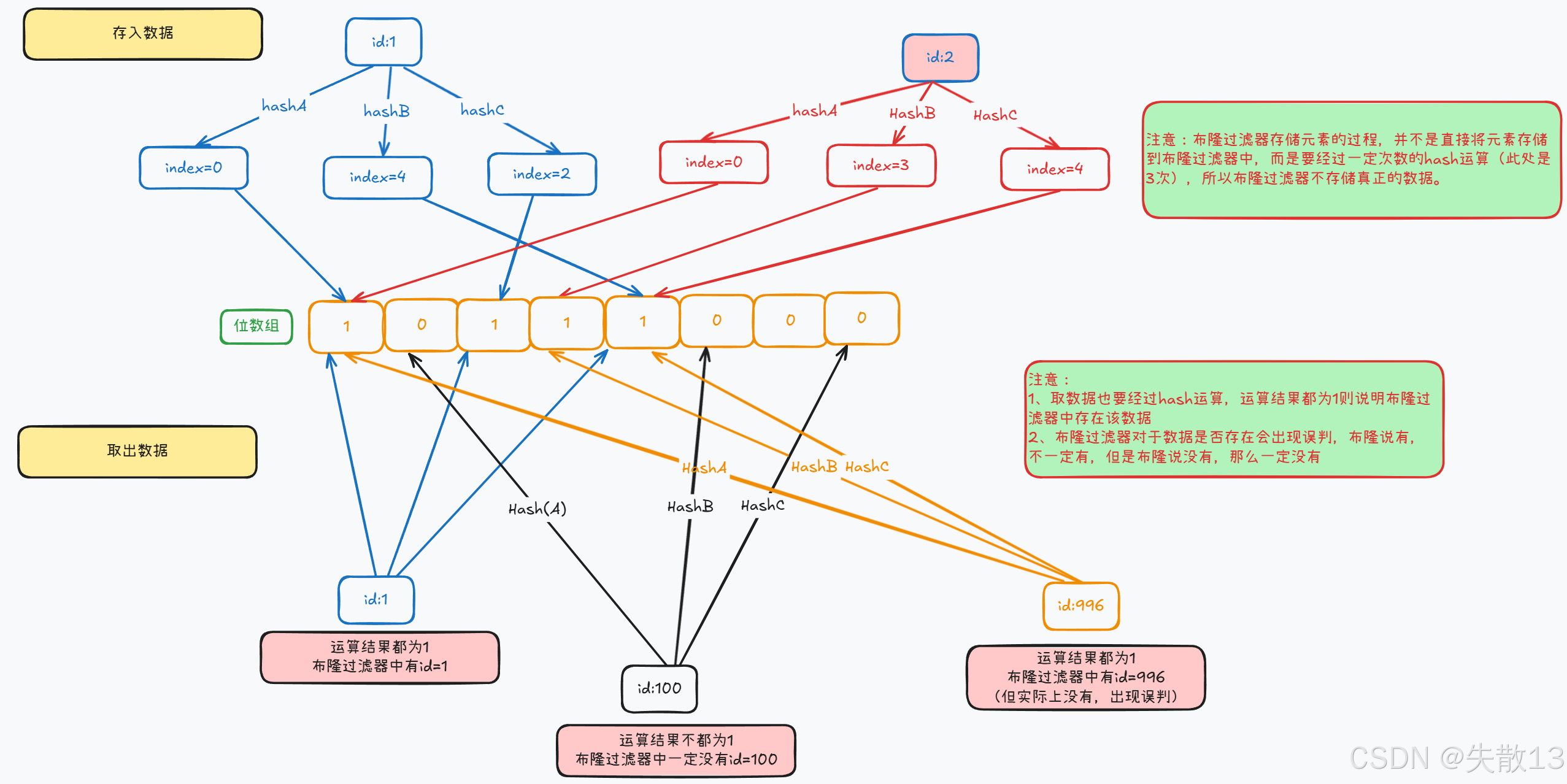
布隆过滤器:
-
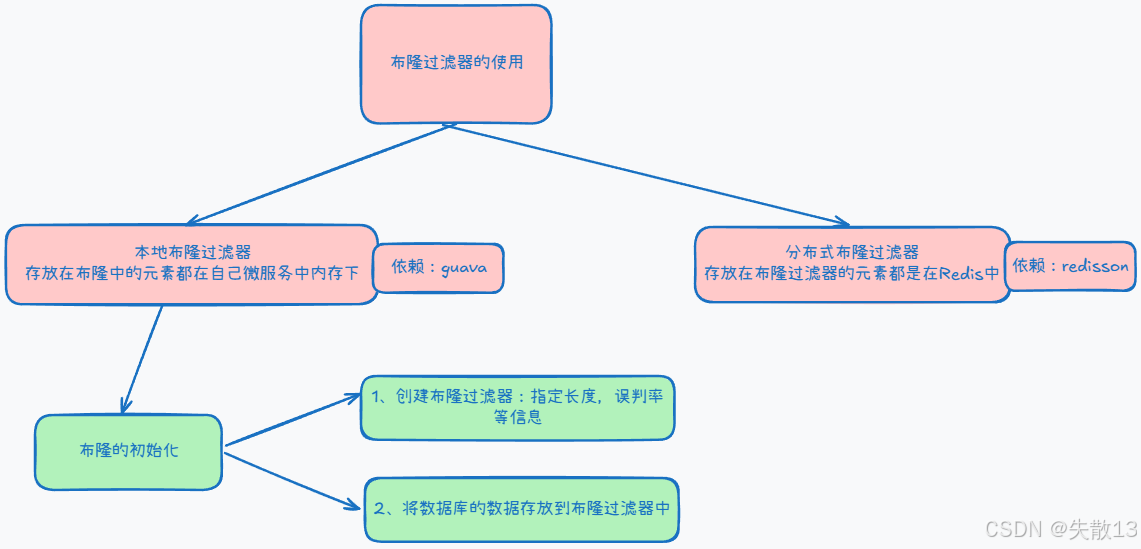
布隆过滤器的使用:
11.2 远程调用查询所有的专辑id集合
-
修改:
/*** 查询所有的专辑id集合* @return*/ @GetMapping("/getAlbumInfoIdList") Result<List<Long>> getAlbumInfoIdList(); -
修改:
@Override public Result<List<Long>> getAlbumInfoIdList() {return Result.fail(); } -
修改:
/*** 查询所有的专辑id集合* @return*/ @GetMapping("/getAlbumInfoIdList") Result<List<Long>> getAlbumInfoIdList() {List<Long> albumIdList = albumInfoService.getAlbumInfoIdList();return Result.ok(albumIdList); } -
修改:
/*** 查询所有的专辑id集合* @return*/ Result<List<Long>> getAlbumInfoIdList() {List<Long> albumIdList = albumInfoService.getAlbumInfoIdList();return Result.ok(albumIdList); } -
修改:
/*** 查询所有的专辑id集合* @return*/ @Transactional public void saveAlbumStat(Long albumId) {ArrayList<String> albumStatus = new ArrayList<>();albumStatus.add(SystemConstant.ALBUM_STAT_PLAY);albumStatus.add(SystemConstant.ALBUM_STAT_SUBSCRIBE);albumStatus.add(SystemConstant.ALBUM_STAT_BROWSE);albumStatus.add(SystemConstant.ALBUM_STAT_COMMENT);for (String status : albumStatus) {AlbumStat albumStat = new AlbumStat();albumStat.setAlbumId(albumId);albumStat.setStatType(status);albumStat.setStatNum(0);albumStatMapper.insert(albumStat);} } -
修改:在
ItemService中调用
/*** 查询所有专辑的id集合* @return*/ List<Long> getAlbumInfoIdList(); -
修改:
/*** 查询所有的专辑id集合* @return*/ @Override public List<Long> getAlbumInfoIdList() {Result<List<Long>> albumIds = albumInfoFeignClient.getAlbumInfoIdList();List<Long> albumIdsData = albumIds.getData();if (CollectionUtils.isEmpty(albumIdsData)) {throw new ShisanException(201, "应用中不存在专辑id集合");}return albumIdsData; }
11.3 本地布隆过滤器的使用
-
依赖:
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>23.0</version> </dependency> -
修改:
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnel; import com.google.common.hash.Funnels;@Slf4j @Service @SuppressWarnings({"unchecked", "rawtypes"}) public class ItemServiceImpl implements ItemService {// ……其它逻辑BloomFilter<Long> longBloomFilter = null;/*** 初始化本地布隆过滤器*/@PostConstruct // Spring在创建ItemServiceImpl Bean对象的时候,在其生命周期走到初始化前,会调用该方法public void initLocalBloomFilter() {// 创建化布隆过滤器// 创建漏斗(Funnel)// 漏斗(Funnel):是 Guava 库中用于将对象转换为字节流的接口,布隆过滤器通过它将元素哈希为位数组的位置// Funnels.longFunnel():是 Guava 提供的内置漏斗实现,专门用于处理 Long 类型,将长整型数值转换为字节流Funnel<Long> longFunnel = Funnels.longFunnel();// BloomFilter.create():静态工厂方法,用于创建布隆过滤器实例// longFunnel:指定元素类型(Long)的漏斗,用于元素的哈希转换// 1000000:预期插入的元素数量(容量)。布隆过滤器会根据此值和误判率计算所需的位数组大小// 0.01:期望的误判率(假阳性概率),即当元素实际不存在时,布隆过滤器误判为存在的概率。这里设置为 1%longBloomFilter = BloomFilter.create(longFunnel, 1000000, 0.01);// 将元素放入布隆过滤器器List<Long> albumInfoIdList = getAlbumInfoIdList();albumInfoIdList.stream().forEach(albumId -> {longBloomFilter.put(albumId);});log.info("本地布隆初始化完毕,布隆中的元素个数:{}", longBloomFilter.approximateElementCount());}/*** 根据专辑id查询专辑详情* @param albumId* @return*/@Overridepublic Map<String, Object> getAlbumInfo(Long albumId) {return getDistroCacheAndLockAndBloomFilter(albumId);}// ……其它逻辑/*** 最终版本+布隆过滤器* @param albumId* @return*/private Map getDistroCacheAndLockAndBloomFilter(Long albumId) {// ……其它逻辑// 查询布隆过滤器(本地)。解决缓存穿透的随机值攻击boolean b = longBloomFilter.mightContain(albumId);if (!b) {log.info("本地布隆过滤器中不存在访问的数据:{}", albumId);return null;}// ……其它逻辑if (acquireLockFlag) { // 若抢得到锁(即加锁成功)// ……其它逻辑try {long ttl = 0l; // 数据的过期时间// 回源查询数据库albumInfoFromDb = getAlbumInfoFromDb(albumId);// 设置数据的过期时间if (albumInfoFromDb != null && albumInfoFromDb.size() > 0) { // 如果数据库查询的数据不为空,则设置一个较长的过期时间ttl = 60 * 60 * 24 * 7l;} else { // 如果数据库查询的数据为空,则设置一个较短的过期时间ttl = 60 * 60 * 2;}// 将数据库查询的数据同步到Redis缓存,同时设置过期时间redisTemplate.opsForValue().set(cacheKey, JSONObject.toJSONString(albumInfoFromDb), ttl, TimeUnit.SECONDS);} finally {// ……其它逻辑}// 返回数据给前端return albumInfoFromDb;} else { // 若未抢到锁(即加锁失败)// ……其它逻辑}}// ……其它逻辑 } -
测试:以 Debug 模型启动
service-search微服务,打断点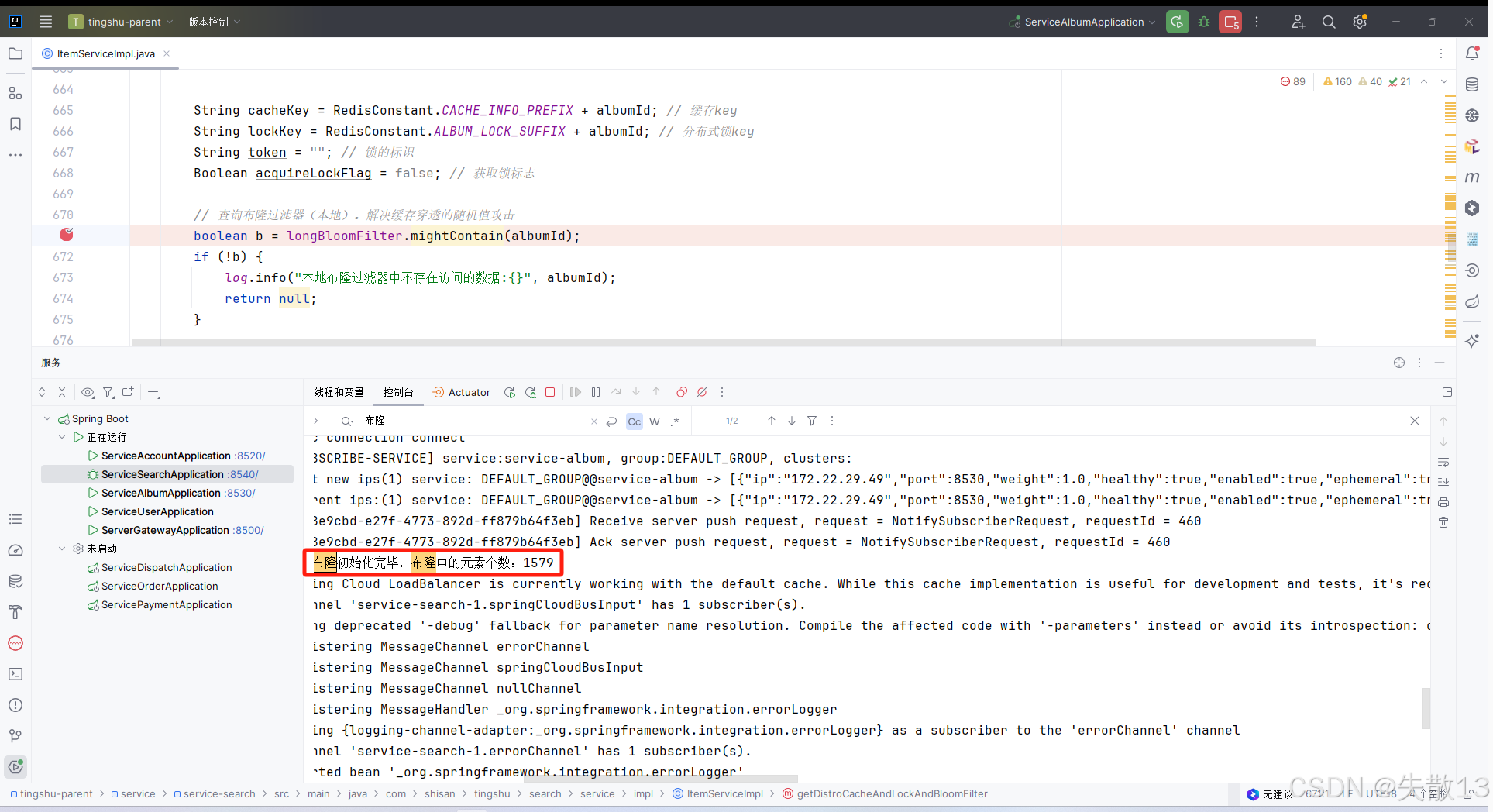
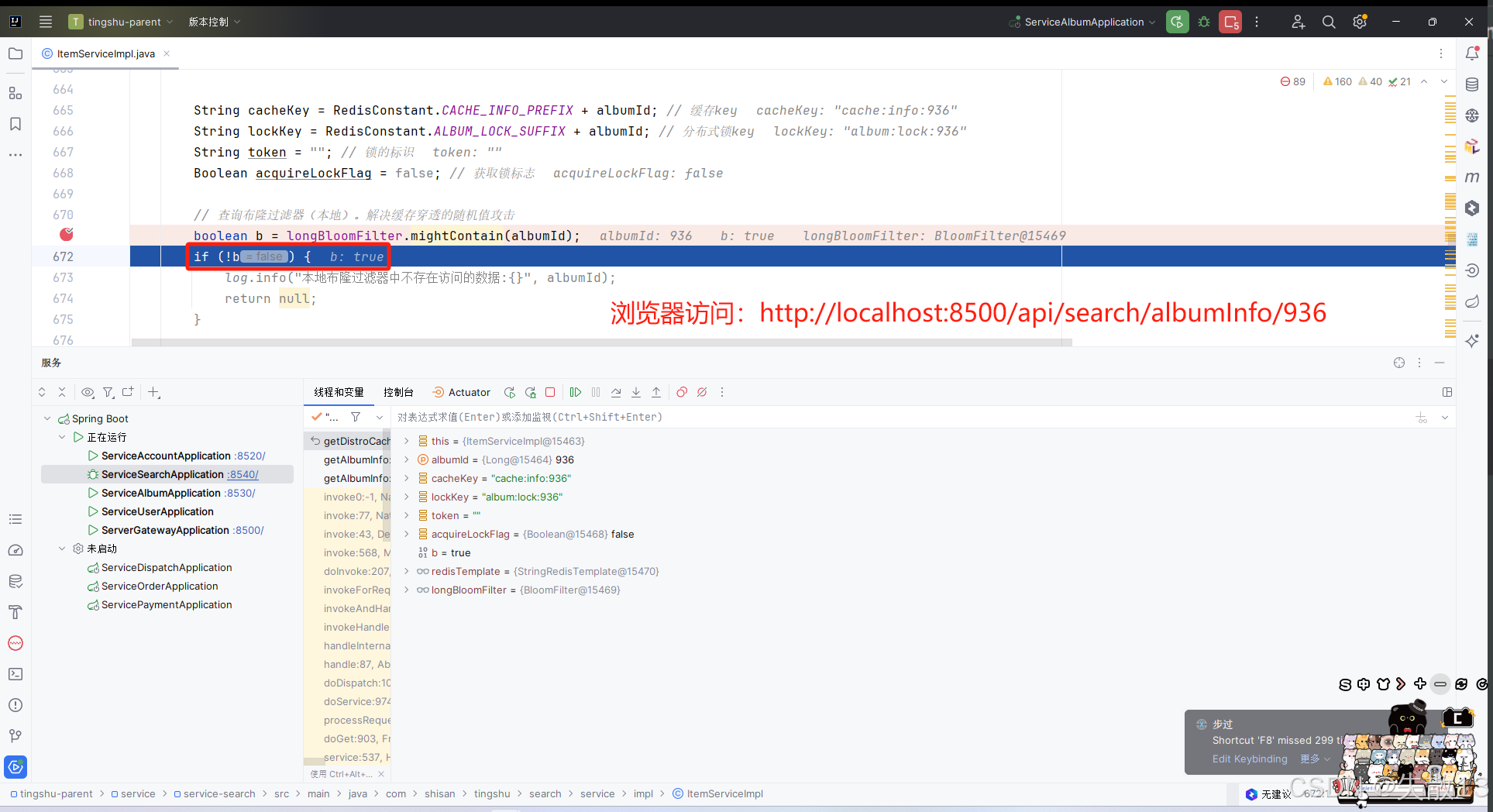

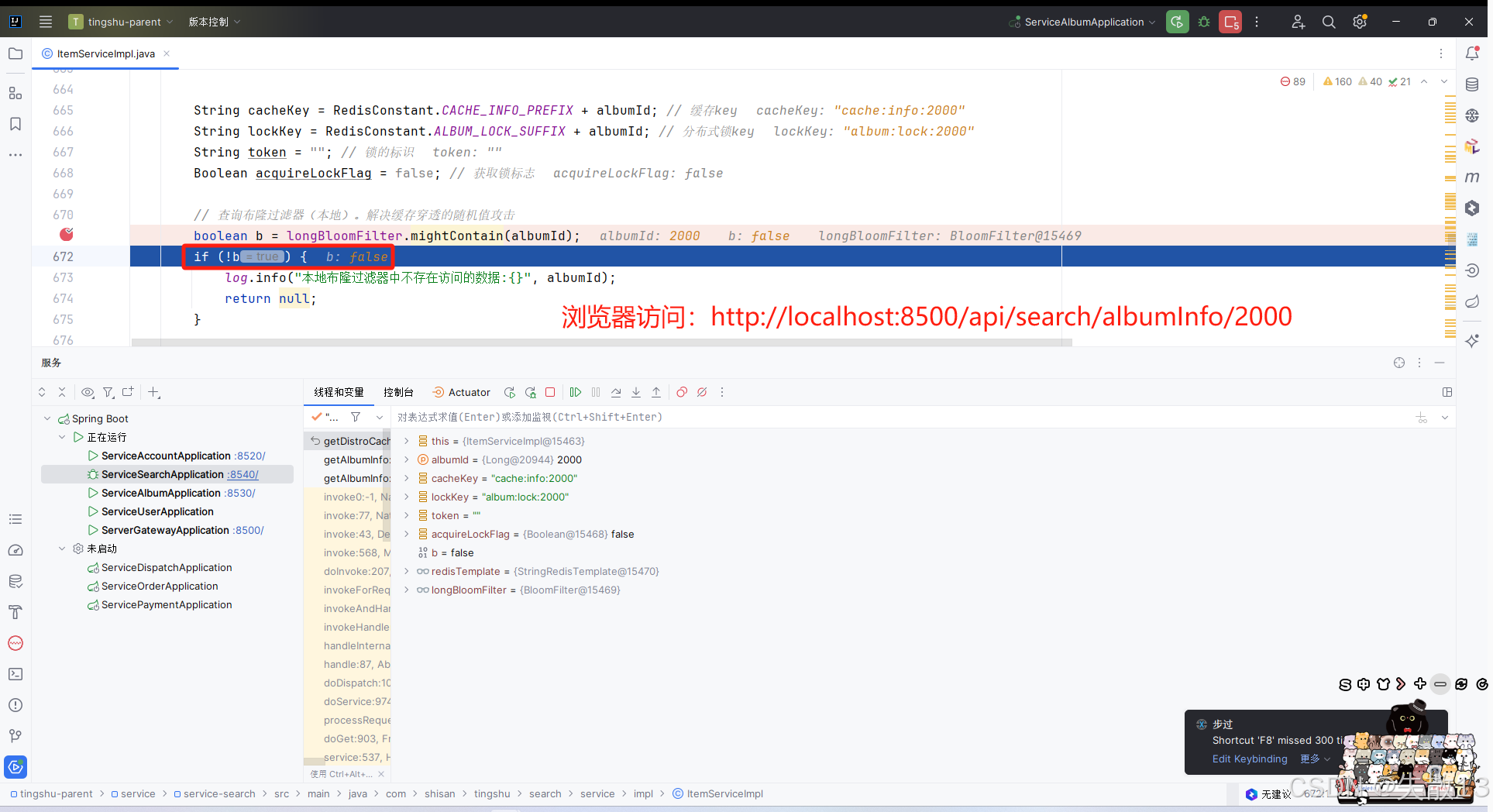
-
测试完,
initLocalBloomFilter()方法就可以注释掉了。
11.4 Redisson分布式布隆过滤器初始化
-
分布式布隆过滤器依赖于 Redisson;
- GitHub:GitHub - redisson/redisson: Redisson - Valkey & Redis Java client. Real-Time Data Platform. Sync/Async/RxJava/Reactive API. Over 50 Valkey and Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Bloom filter, Spring, Tomcat, Scheduler, JCache API, Hibernate, RPC, local cache…;
- 文档:Objects - Redisson Reference Guide;
-
引入依赖:
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.25.0</version> </dependency> -
新建:
package com.shisan.tingshu.search.config;import org.redisson.Redisson; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.autoconfigure.data.redis.RedisProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.core.StringRedisTemplate;@Configuration public class RedissonAutoConfiguration {Logger logger = LoggerFactory.getLogger(this.getClass());@Autowiredprivate RedisProperties redisProperties;@Autowiredprivate StringRedisTemplate redisTemplate;/*** 定义Redisson客户端的Bean对象*/@Beanpublic RedissonClient redissonClient() {// 给Redisson设置配置信息Config config = new Config();config.useSingleServer() // 使用单机模式.setPassword(redisProperties.getPassword()).setAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort());// 创建Redisson客户端RedissonClient redissonClient = Redisson.create(config);return redissonClient;}/*** 定义一个BloomFilter的Bean对象*/@Beanpublic RBloomFilter rBloomFilter(RedissonClient redissonClient) {// 如果在Redis中没有这个key,那么会自动创建,并返回这个key对应的布隆过滤器对象。反之 直接返回已经创建好的布隆过滤器// tryInit()方法返回true表示初始化成功(即之前不存在,现在新创建了),返回false表示已经存在(即之前已经初始化过)RBloomFilter<Object> albumIdBloomFilter = redissonClient.getBloomFilter("albumIdBloomFilter");// 初始化布隆过滤器boolean b = albumIdBloomFilter.tryInit(1000000l, 0.001);if (b) {logger.info("成功创建新的布隆过滤器,等待数据填充");} else {logger.info("布隆过滤器已存在,直接使用");}return albumIdBloomFilter;} }
11.5 让Spring容器在启动时就执行一些必要操作的四种实现方法
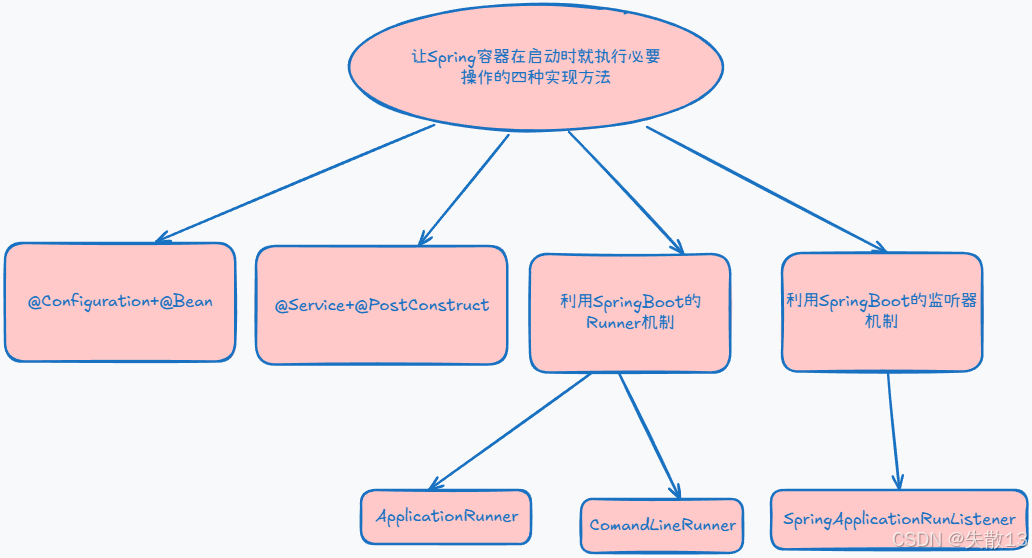
@Configuration + @Bean:- 在 Spring 中,
@Configuration注解用于标记一个类作为配置类,而@Bean注解用于在配置类中声明一个 Bean; - 当 Spring 容器启动时,会加载这些配置类,并初始化被
@Bean注解标记的方法所返回的对象,从而实现一些初始化操作; - 这种方式是 Spring 中比较基础的配置方式,通过 Java 代码的方式来替代传统的 XML 配置,使得配置更加类型安全和灵活;
- 在 Spring 中,
@Service + @PostConstruct:@Service注解用于标记一个类作为服务层组件,当 Spring 容器启动时,会扫描并初始化被@Service注解标记的类;- 而
@PostConstruct注解用于标记一个方法,该方法会在 Bean 初始化完成后被调用,通常用于在 Bean 初始化后执行一些初始化逻辑; - 这是 Spring 中常用的一种初始化 Bean 的方式,特别是在服务层组件中,经常需要在 Bean 初始化后进行一些资源初始化或数据加载等操作;
- 利用 SpringBoot 的 Runner 机制。SpringBoot 提供了两种 Runner 接口来实现在容器启动后执行特定的逻辑:
ApplicationRunner- 实现
ApplicationRunner接口的类会在 SpringBoot 应用启动后被调用,run方法会接收一个ApplicationArguments对象,可以用来获取应用启动时的命令行参数等信息; - 这种方式通常用于在应用启动后执行一些需要访问应用参数的初始化操作;
- 实现
CommandLineRunner- 与
ApplicationRunner类似,实现CommandLineRunner接口的类也会在应用启动后被调用,run方法接收的是原始的命令行参数数组; - 如果只需要简单地处理命令行参数,而不需要
ApplicationArguments提供的高级功能,那么可以使用CommandLineRunner;
- 与
- 利用 SpringBoot 的监听器机制(
SpringApplicationRunListener)SpringApplicationRunListener是 SpringBoot 提供的一个监听器接口,用于监听 SpringBoot 应用的启动过程。通过实现这个接口,可以在应用启动的不同阶段执行自定义的逻辑,例如在应用上下文准备好后、应用启动前等阶段。- 这种方式提供了对 Spring Boot 应用启动过程的更细粒度的控制,可以用于在应用启动的不同阶段执行一些自定义的初始化或监控操作。
11.6 利用SpringBoot的Runnner机制完成对分布式布隆过滤器的元素同步
-
接下来要将专辑id列表放入到分布式布隆过滤器中,此处采用
11.5 让Spring容器在启动时就执行一些必要操作的四种实现方法的方法三; -
新建:
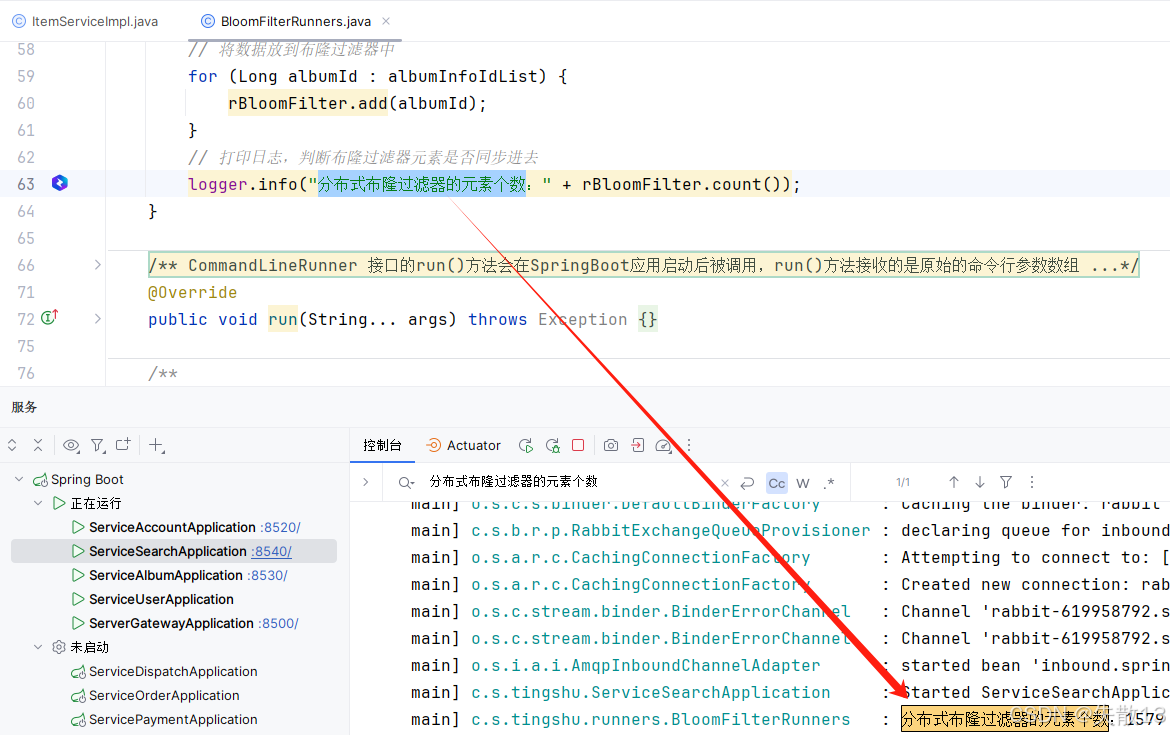
package com.shisan.tingshu.runners;import com.shisan.tingshu.search.service.impl.ItemServiceImpl; import org.redisson.api.RBloomFilter; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.BeansException; import org.springframework.boot.ApplicationArguments; import org.springframework.boot.ApplicationRunner; import org.springframework.boot.CommandLineRunner; import org.springframework.context.ApplicationContext; import org.springframework.context.ApplicationContextAware; import org.springframework.stereotype.Component;import java.util.List;/*** 利用SpringBoot的Runnner机制完成对分布式布隆过滤器的元素同步* ApplicationRunner:* 实现ApplicationRunner接口的类会在SpringBoot应用启动后被调用,run()方法会接收一个ApplicationArguments对象,可以用来获取应用启动时的命令行参数等信息;* 这种方式通常用于在应用启动后执行一些需要访问应用参数的初始化操作;* CommandLineRunner:* 与ApplicationRunner类似,实现CommandLineRunner接口的类也会在应用启动后被调用,run()方法接收的是原始的命令行参数数组;* 如果只需要简单地处理命令行参数,而不需要ApplicationArguments提供的高级功能,那么可以使用CommandLineRunner;*/ @Component public class BloomFilterRunners implements ApplicationRunner, CommandLineRunner, ApplicationContextAware {// 定义一个ApplicationContextAware接口的实现类,用于获取spring容器中的Bean对象private ApplicationContext applicationContext;Logger logger = LoggerFactory.getLogger(this.getClass());/*** ApplicationRunner 接口的run()方法会在SpringBoot应用启动后被调用,run()方法接收一个ApplicationArguments对象,可以用来获取应用启动时的命令行参数等信息* 这些参数中:--表示可选参数,没有--的表示必选参数。比如:--spring.profiles.active=dev表示可选参数,spring.profiles.active=dev表示必选参数* 在该方法中,可以获取到布隆过滤器的Bean对象,然后将数据同步到布隆过滤器中* @param args* @throws Exception*/@Overridepublic void run(ApplicationArguments args) throws Exception {// Set<String> optionNames = args.getOptionNames(); // for (String optionName : optionNames) { // 获取可选参数 // System.out.println("命令行中输入的可选参数名:" + optionName + "值:" + args.getOptionValues(optionName)); // } // for (String nonOptionArg : args.getNonOptionArgs()) { // 获取必选参数 // System.out.println("命令行中输入的必选参数名:" + nonOptionArg + "值:" + args.getOptionValues(nonOptionArg)); // }// 从Spring容器中获取到布隆过滤器的Bean对象RBloomFilter rBloomFilter = applicationContext.getBean("rBloomFilter", RBloomFilter.class);// 从Spring容器中获取应用的Bean对象ItemServiceImpl itemServiceImpl = applicationContext.getBean("itemServiceImpl", ItemServiceImpl.class);// 获取数据List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();// 将数据放到布隆过滤器中for (Long albumId : albumInfoIdList) {rBloomFilter.add(albumId);}// 打印日志,判断布隆过滤器元素是否同步进去logger.info("分布式布隆过滤器的元素个数:" + rBloomFilter.count());}/*** CommandLineRunner 接口的run()方法会在SpringBoot应用启动后被调用,run()方法接收的是原始的命令行参数数组* @param args* @throws Exception*/@Overridepublic void run(String... args) throws Exception {}/*** 实现ApplicationContextAware接口,用于获取spring容器中的Bean对象* @param applicationContext* @throws BeansException*/@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;} } -
测试:
11.7 利用SpringBoot的Listener机制完成对分布式布隆过滤器的元素同步
-
接下来要将专辑id列表放入到分布式布隆过滤器中,此处采用
11.5 让Spring容器在启动时就执行一些必要操作的四种实现方法的方法四;- 先将上一节讲的
BloomFilterRunners的类上的@Component注解注释掉;
- 先将上一节讲的
-
新建:
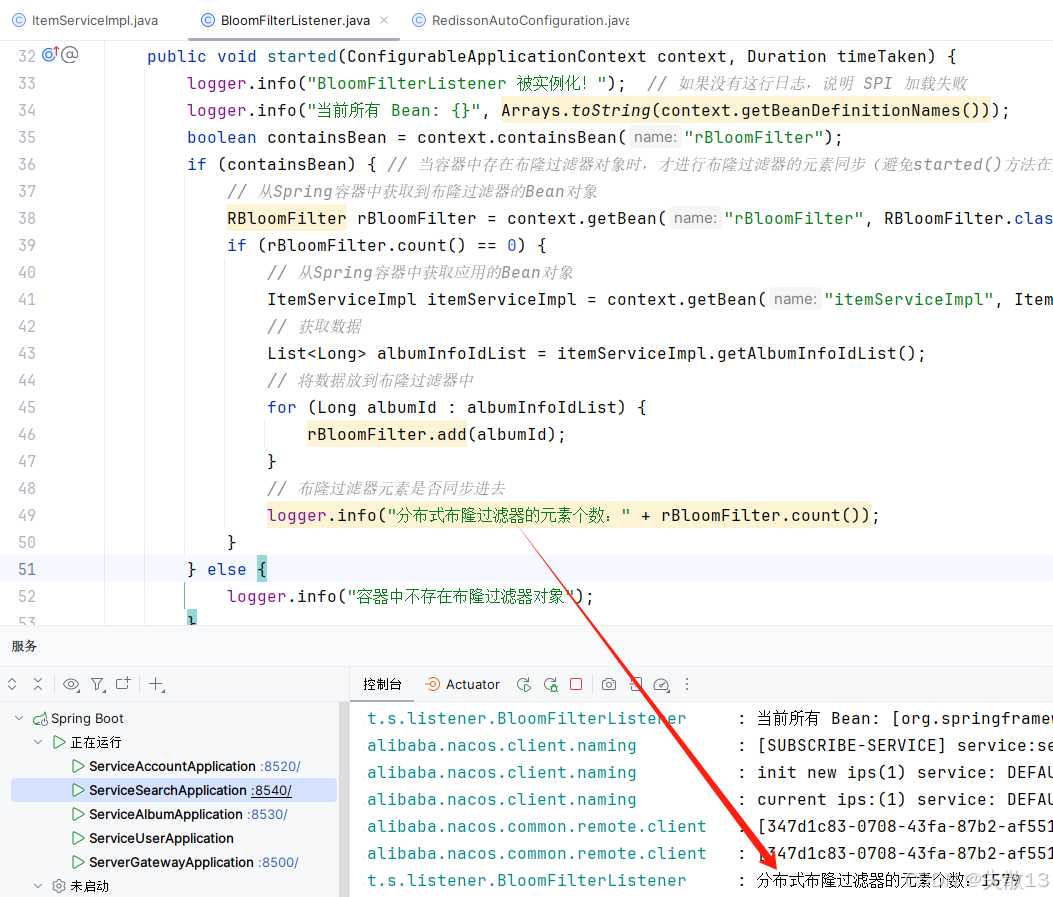
package com.shisan.tingshu.search.listener;import com.shisan.tingshu.search.service.impl.ItemServiceImpl; import org.redisson.api.RBloomFilter; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.SpringApplicationRunListener; import org.springframework.context.ConfigurableApplicationContext; import org.springframework.stereotype.Component;import java.time.Duration; import java.util.Arrays; import java.util.List;//@Component 即使加了这个注解,SpringBoot也不会自动扫描到这个Listener类。只能通过 SPI 机制来加载这个Listener类 // SpringApplicationRunListener是SpringBoot提供的一个监听器接口,用于监听SpringBoot应用的启动过程 // 通过实现这个接口,可以在应用启动的不同阶段执行自定义的逻辑,例如在应用上下文准备好后、应用启动前等阶段 public class BloomFilterListener implements SpringApplicationRunListener {Logger logger = LoggerFactory.getLogger(this.getClass());/*** started()方法在SpringBoot应用启动的过程中被调用,用于监听SpringBoot应用的启动过程* 注意:started()方法在SpringBoot应用启动的过程中会被调用两次* 第一次是SpringCloud的组件调用的。方法参数ConfigurableApplicationContext,即Spring容器中是没有应用中定义好的Bean对象* 第二次是SpringBoot组件调用的。方法参数ConfigurableApplicationContext,即Spring容器中才有应用中定义好的Bean对象* @param context Spring 容器* @param timeTaken 启动时间*/@Overridepublic void started(ConfigurableApplicationContext context, Duration timeTaken) {logger.info("BloomFilterListener 被实例化!"); // 如果没有这行日志,说明 SPI 加载失败logger.info("当前所有 Bean: {}", Arrays.toString(context.getBeanDefinitionNames()));boolean containsBean = context.containsBean("rBloomFilter");if (containsBean) { // 当容器中存在布隆过滤器对象时,才进行布隆过滤器的元素同步(避免started()方法在第一次被调用的时候容器中没有布隆过滤器对象而报错)// 从Spring容器中获取到布隆过滤器的Bean对象RBloomFilter rBloomFilter = context.getBean("rBloomFilter", RBloomFilter.class);// 从Spring容器中获取应用的Bean对象ItemServiceImpl itemServiceImpl = context.getBean("itemServiceImpl", ItemServiceImpl.class);// 获取数据List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();// 将数据放到布隆过滤器中for (Long albumId : albumInfoIdList) {rBloomFilter.add(albumId);}// 布隆过滤器元素是否同步进去logger.info("分布式布隆过滤器的元素个数:" + rBloomFilter.count());} else {logger.info("容器中不存在布隆过滤器对象");}} } -
新建:手动通过 SPI 机制将 Listener 注入容器
org.springframework.boot.SpringApplicationRunListener=com.shisan.tingshu.search.listener.BloomFilterListener -
测试:
-
最好先将Redis中关于
albumIdBloomFilter的数据删掉 -
在日志中也可以看到下面两行代码执行了两次
logger.info("BloomFilterListener 被实例化!"); // 如果没有这行日志,说明 SPI 加载失败 logger.info("当前所有 Bean: {}", Arrays.toString(context.getBeanDefinitionNames()));
-
-
修改
ItemServiceImpl:@Slf4j @Service @SuppressWarnings({"unchecked", "rawtypes"}) public class ItemServiceImpl implements ItemService {@Autowiredprivate RBloomFilter rBloomFilter;// ……其它逻辑/*** 最终版本+布隆过滤器* @param albumId* @return*/private Map getDistroCacheAndLockAndBloomFilter(Long albumId) {// ……其它逻辑// 查询布隆过滤器(本地)。解决缓存穿透的随机值攻击 // boolean b = longBloomFilter.mightContain(albumId); // if (!b) { // log.info("本地布隆过滤器中不存在访问的数据:{}", albumId); // return null; // }// 查询布隆过滤器(分布式)boolean bloomContains = rBloomFilter.contains(albumId);if (!bloomContains) {return null;}// ……其它逻辑}// ……其它逻辑 } -
测试:同
11.3 本地布隆过滤器的使用。
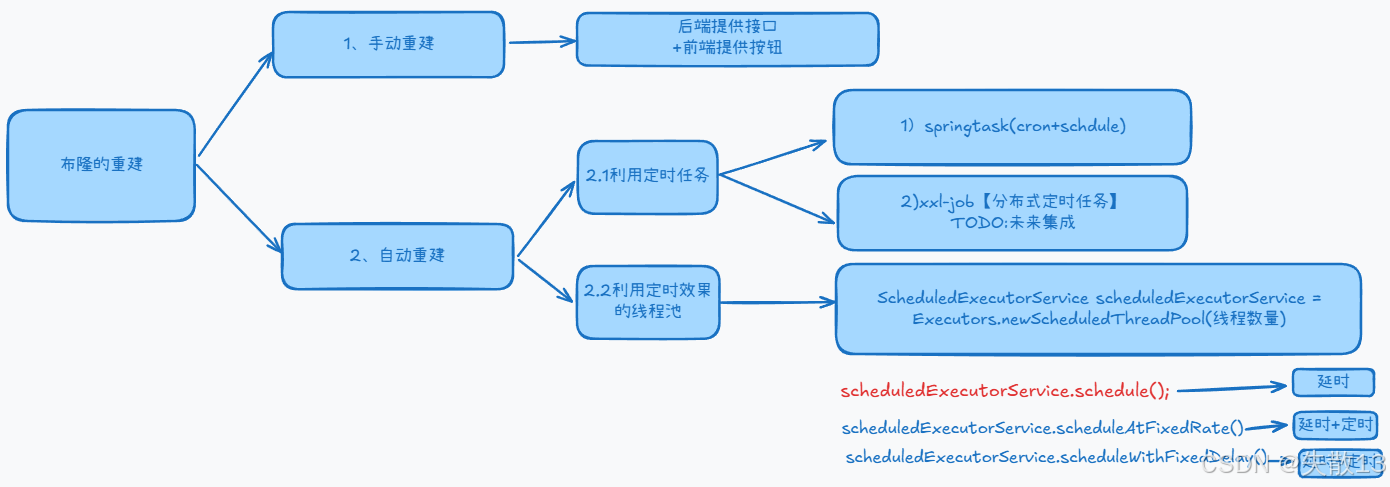
11.8 布隆重建的两种方案(手动和自动)
11.9 分布式布隆重建方案之手动重建
-
新建:
@GetMapping("/rebuildBloomFilter") @Operation(summary = "手动重建布隆") public Result rebuildBloomFilter() {Boolean isFlag = itemService.rebuildBloomFilter();return Result.ok(isFlag); } -
修改:
/*** 手动布隆重建* @return*/ Boolean rebuildBloomFilter(); -
修改:
@Autowired private RedissonClient redissonClient;/*** 手动布隆重建* @return*/ @Override public Boolean rebuildBloomFilter() {// 步骤:删除老布隆的数据 >> 删除老布隆的配置 >> 创建新布隆 >> 初始化新布隆 >> 将数据放到新布隆// 但在高并发场景下,第一个线程删除了老布隆的配置但是新布隆还没有创建时,第二个线程进来仍然使用的是老布隆,此时就会报错// 优化做法:创建新布隆 >> 初始化新布隆 >> 将数据放到新布隆 >> 删除老布隆的数据 >> 删除老布隆的配置 >> 将新布隆的名字重命名为老布隆的名字(第4、5、6步要做成一个原子操作)// 1、创建新布隆RBloomFilter<Object> albumIdBloomFilterNew = redissonClient.getBloomFilter("albumIdBloomFilterNew");// 2、初始化新布隆albumIdBloomFilterNew.tryInit(1000000l, 0.001);// 3、将数据放到新布隆List<Long> albumInfoIdList = getAlbumInfoIdList();for (Long albumId : albumInfoIdList) {albumIdBloomFilterNew.add(albumId);}albumIdBloomFilterNew.add(2000L); // 给新布隆添加一个老布隆不存在的数据,用于测试// 用lua脚本保证这三个步骤的原子性:4、删除老布隆的数据;5、删除老布隆的配置;6、将新布隆的名字重命名为老布隆的名字String script = " redis.call(\"del\",KEYS[1])" +" redis.call(\"del\",KEYS[2])" +// KEYS[1]对应的是下面asList的第一个元素,KEYS[2]对应的是下面asList的第二个元素,以此类推" redis.call(\"rename\",KEYS[3],KEYS[1])" + // 用后者替换前者" redis.call(\"rename\",KEYS[4],KEYS[2]) return 0";List<String> asList = Arrays.asList("albumIdBloomFilter", "{albumIdBloomFilter}:config", "albumIdBloomFilterNew", "{albumIdBloomFilterNew}:config");Long execute = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), asList);if (execute == 0) {log.info("老布隆被删除,新布隆上线");}return execute == 0; } -
测试:
11.10 优化:分布式布隆过滤器只初始化一次&同步数据只做一次
-
每一次服务已启动,就会初始化分布式布隆过滤器并同步数据,但是实际上 Redis 中已经存在布隆过滤器和同步数据了。所以此处就优化一下,让分布式布隆过滤只初始化一次且同步数据只做一次;
-
修改:加个锁,让分布式布隆过滤器只初始化一次且同步数据只做一次
/*** 定义一个BloomFilter的Bean对象*/ @Bean public RBloomFilter rBloomFilter(RedissonClient redissonClient) {// 如果在Redis中没有这个key,那么会自动创建,并返回这个key对应的布隆过滤器对象。反之 直接返回已经创建好的布隆过滤器// tryInit()方法返回true表示初始化成功(即之前不存在,现在新创建了),返回false表示已经存在(即之前已经初始化过)RBloomFilter<Object> albumIdBloomFilter = redissonClient.getBloomFilter("albumIdBloomFilter");// 加个锁,让分布式布隆过滤器只初始化一次且同步数据只做一次// 当锁存在的时候,表示布隆过滤器已经初始化过了,直接返回布隆过滤器对象String bloomFilterLockKey = "albumIdBloomFilter:lock";Boolean aBoolean = redisTemplate.opsForValue().setIfAbsent(bloomFilterLockKey, "1");if (aBoolean) {// 初始化布隆过滤器boolean b = albumIdBloomFilter.tryInit(1000000l, 0.001); // 利用分布式锁保证分布式布隆的初始化只做一次if (b) {logger.info("成功创建新的布隆过滤器,等待数据填充");} else {logger.info("布隆过滤器已存在,直接使用");}}return albumIdBloomFilter; } -
修改:如果布隆过滤器元素个数为0,说明布隆过滤器元素还没有同步,需要同步布隆过滤器元素
@Override public void started(ConfigurableApplicationContext context, Duration timeTaken) {logger.info("BloomFilterListener 被实例化!"); // 如果没有这行日志,说明 SPI 加载失败logger.info("当前所有 Bean: {}", Arrays.toString(context.getBeanDefinitionNames()));boolean containsBean = context.containsBean("rBloomFilter");if (containsBean) { // 当容器中存在布隆过滤器对象时,才进行布隆过滤器的元素同步(避免started()方法在第一次被调用的时候容器中没有布隆过滤器对象而报错)// 从Spring容器中获取到布隆过滤器的Bean对象RBloomFilter rBloomFilter = context.getBean("rBloomFilter", RBloomFilter.class);if (rBloomFilter.count() == 0) { // 如果布隆过滤器元素个数为0,说明布隆过滤器元素还没有同步,需要同步布隆过滤器元素// 从Spring容器中获取应用的Bean对象ItemServiceImpl itemServiceImpl = context.getBean("itemServiceImpl", ItemServiceImpl.class);// 获取数据List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();// 将数据放到布隆过滤器中for (Long albumId : albumInfoIdList) {rBloomFilter.add(albumId);}// 布隆过滤器元素是否同步进去logger.info("分布式布隆过滤器的元素个数:" + rBloomFilter.count());} else {logger.info("布隆过滤器元素已经同步!");}} else {logger.info("容器中不存在布隆过滤器对象");} }
11.11 使用SpringTask的Schdule机制实现布隆定时重建
-
新建:
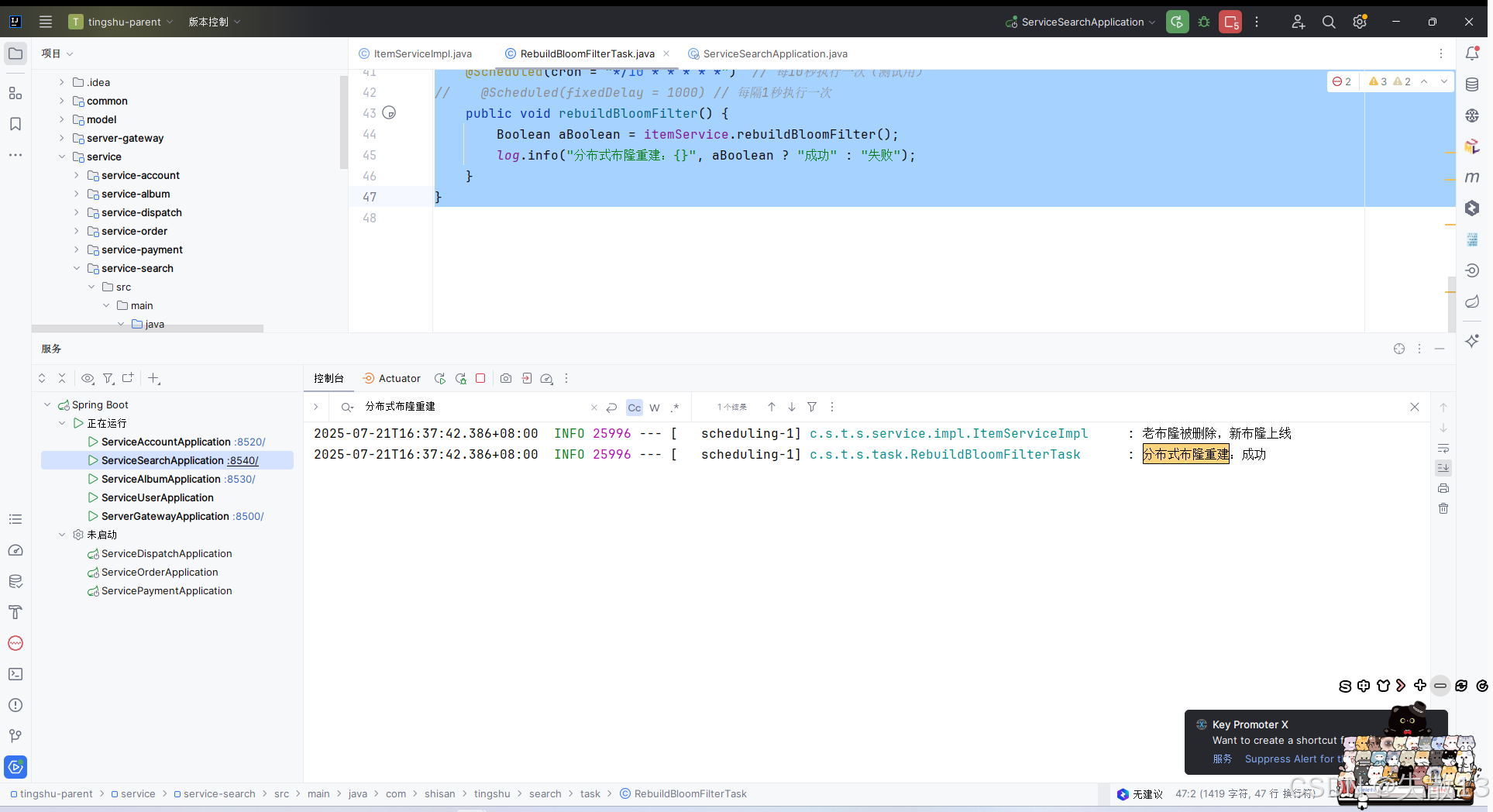
package com.shisan.tingshu.search.task;import com.shisan.tingshu.search.service.ItemService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component;@Component @Slf4j public class RebuildBloomFilterTask {@Autowiredprivate ItemService itemService;/*** cron表达式有7位,但实际使用的只有6位,即:秒 分 时 日 月 周 (年)* 注意:日和周不能同时出现,所以如果写日,就不要写周,用一个?占位即可** 书写格式如下:* 字段 允许值 特殊字符* 秒 0-59 , - * /* 分 0-59 , - * /* 时 0-23 , - * /* 日 1-31 , - * / ?* 月 1-12 或 JAN-DEC , - * /* 周 0-7 或 SUN-SAT , - * / ?* 注意:0 和 7 均表示周日** 特殊字符说明:* 字符 含义 示例* * 所有值(任意时刻) 0 * * * * *:表示每分钟执行* ? 忽略该字段(仅用于日或周) 0 0 0 ? * MON:表示每周一执行* - 范围 0 0 9-17 * * *:表示9点到17点每小时执行* , 多个值 0 0 8,12,18 * * *:表示每天8点、12点、18点执行* / 步长 0 0/5 * * * *:表示每5分钟执行一次*/// @Scheduled(cron = "0 0 2 */7 * ?") // 每周日凌晨2点执行@Scheduled(cron = "*/10 * * * * *") // 每10秒执行一次(测试用) // @Scheduled(fixedDelay = 1000) // 每隔1秒执行一次public void rebuildBloomFilter() {Boolean aBoolean = itemService.rebuildBloomFilter();log.info("分布式布隆重建:{}", aBoolean ? "成功" : "失败");} } -
同时在
ServiceSearchApplication启动类上加上@EnableScheduling注解; -
测试:
11.12 工厂类创建饿汉式单例定时任务线程池+一次性延迟任务+嵌套任务本身实现定时布隆重建
-
修改:开启允许循环依赖
spring:main:allow-circular-references: true -
修改:
@Autowired private RedissonClient redissonClient;@Autowired private ItemServiceImpl itemServiceImpl; // 自己注入自己,记得在application.yaml中开启允许循环依赖/*** ScheduleTaskThreadPoolFactory工厂类+一次性延迟任务+嵌套任务本身实现定时布隆重建*/ @PostConstruct public void initRebuildBloomFilter() {// // 创建一个定时任务线程池,核心线程数为2,用于执行定时或周期性任务 // ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2); // // 安排一个周期性任务:RebuildBloomFilterRunnable,每隔7天执行一次 // scheduledExecutorService.scheduleWithFixedDelay( // new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl), // 要执行的周期性任务 // 0, // 首次立即执行 // 7, TimeUnit.DAYS // 在上一次任务执行完成后,固定间隔7天再次执行(FixedDelay策略) // ); // // 安排一个一次性延迟任务:RebuildBloomFilterRunnable,在10秒后执行。与上面的周期性任务不同,这个任务只执行一次 // // 那么怎么实现每10秒执行一次呢?在RebuildBloomFilterRunnable的run方法中,再调用一次scheduledExecutorService.schedule()方法,实现每10秒执行一次 // scheduledExecutorService.schedule( // new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl), // 10, TimeUnit.SECONDS // );// 从服务启动开始,每隔7天的凌晨两点执行一次// 使用ScheduleTaskThreadPoolFactory工厂类,实现定时任务的线程池对象创建ScheduleTaskThreadPoolFactory instance = ScheduleTaskThreadPoolFactory.getINSTANCE();Long taskFirstTime = instance.diffTime(System.currentTimeMillis()); // 传入当前时间,计算出距离下次执行任务的时间差instance.execute(new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl),taskFirstTime,TimeUnit.MILLISECONDS); // instance.execute(new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl), 20L, TimeUnit.SECONDS); // 测试用 } -
新建:专门用于定时重建布隆过滤器的线程任务类
package com.shisan.tingshu.search.runnable;import com.shisan.tingshu.search.factory.ScheduleTaskThreadPoolFactory; import com.shisan.tingshu.search.service.impl.ItemServiceImpl; import lombok.extern.slf4j.Slf4j; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.data.redis.core.script.DefaultRedisScript;import java.util.Arrays; import java.util.List; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;/*** 专门用于定时重建布隆过滤器的线程任务类*/ @Slf4j public class RebuildBloomFilterRunnable implements Runnable {Logger logger = LoggerFactory.getLogger(this.getClass());private RedissonClient redissonClient;private StringRedisTemplate redisTemplate;private ItemServiceImpl itemServiceImpl;public RebuildBloomFilterRunnable(RedissonClient redissonClient, StringRedisTemplate redisTemplate, ItemServiceImpl itemServiceImpl) {this.redissonClient = redissonClient;this.redisTemplate = redisTemplate;this.itemServiceImpl = itemServiceImpl;}@Overridepublic void run() {// 步骤:删除老布隆的数据 >> 删除老布隆的配置 >> 创建新布隆 >> 初始化新布隆 >> 将数据放到新布隆// 但在高并发场景下,第一个线程删除了老布隆的配置但是新布隆还没有创建时,第二个线程进来仍然使用的是老布隆,此时就会报错// 优化做法:创建新布隆 >> 初始化新布隆 >> 将数据放到新布隆 >> 删除老布隆的数据 >> 删除老布隆的配置 >> 将新布隆的名字重命名为老布隆的名字(第4、5、6步要做成一个原子操作)// 1、创建新布隆RBloomFilter<Object> albumIdBloomFilterNew = redissonClient.getBloomFilter("albumIdBloomFilterNew");// 2、初始化新布隆albumIdBloomFilterNew.tryInit(1000000l, 0.001);// 3、将数据放到新布隆List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();for (Long albumId : albumInfoIdList) {albumIdBloomFilterNew.add(albumId);}albumIdBloomFilterNew.add(2000L); // 给新布隆添加一个老布隆不存在的数据,用于测试// 用lua脚本保证这三个步骤的原子性:4、删除老布隆的数据;5、删除老布隆的配置;6、将新布隆的名字重命名为老布隆的名字String script = " redis.call(\"del\",KEYS[1])" +" redis.call(\"del\",KEYS[2])" +// KEYS[1]对应的是下面asList的第一个元素,KEYS[2]对应的是下面asList的第二个元素,以此类推" redis.call(\"rename\",KEYS[3],KEYS[1])" + // 用后者替换前者" redis.call(\"rename\",KEYS[4],KEYS[2]) return 0";List<String> asList = Arrays.asList("albumIdBloomFilter", "{albumIdBloomFilter}:config", "albumIdBloomFilterNew", "{albumIdBloomFilterNew}:config");Long execute = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), asList);if (execute == 0) {log.info("老布隆被删除,新布隆上线");}// 一次性延迟任务+嵌套任务本身,进而实现定时的效果(Nacos源码就是这么做的) // ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2); // scheduledExecutorService.schedule(this,10, TimeUnit.SECONDS);//但是定时任务线程池被创建了两次(ItemServiceImpl的initRebuildBloomFilter()中一次,上面一次),所以可以使用工厂模式ScheduleTaskThreadPoolFactory instance = ScheduleTaskThreadPoolFactory.getINSTANCE();instance.execute(this, 7l, TimeUnit.DAYS); // instance.execute(this, 20l, TimeUnit.SECONDS); // 测试用} } -
新建:定时任务线程池工厂类
package com.shisan.tingshu.search.factory;import java.time.LocalDate; import java.time.LocalDateTime; import java.time.LocalTime; import java.time.ZoneId; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;public class ScheduleTaskThreadPoolFactory {static ScheduledExecutorService scheduledExecutorService = null;// 在加载ScheduleTaskThreadPoolFactory类的时候,提前将定时任务的线程池对象创建出来static {scheduledExecutorService = Executors.newScheduledThreadPool(2);}/*** 使用单例设计模式定义一个工厂类的实例对象(饿汉式。在并发情况下,比懒汉式安全一点)* 饿汉式:类加载时就立即初始化单例实例,线程安全但可能造成资源浪费* 懒汉式:首次使用时才初始化单例实例,节省资源但需额外处理线程安全问题*/private static ScheduleTaskThreadPoolFactory INSTANCE = new ScheduleTaskThreadPoolFactory();/*** 获取上面定义的实例对象*/public static ScheduleTaskThreadPoolFactory getINSTANCE() {return INSTANCE;}/*** 私有化构造器。让外面无法通过new的方式创建该工厂类的实例对象*/private ScheduleTaskThreadPoolFactory() {}/*** 该方法使得工厂可以接收外部提交过来的任务* runnable:外部提交过来的任务* ttl:延迟时间* timeUnit:时间单位*/public void execute(Runnable runnable, Long ttl, TimeUnit timeUnit) {// 一次性延迟任务+嵌套任务本身,进而实现定时的效果(Nacos源码就是这么做的)scheduledExecutorService.schedule(runnable, ttl, timeUnit);}/*** 计算时间差*/public Long diffTime(Long currentTime) {// 获取当前时间的下一周的凌晨2点的时间戳LocalDate localDate = LocalDate.now().plusDays(7);LocalDateTime localDateTime = LocalDateTime.of(localDate, LocalTime.of(2, 0, 0));// 将LocalDateTime转换为毫秒值。ZoneId.systemDefault()是获取系统默认时区long time = localDateTime.atZone(ZoneId.systemDefault()).toInstant().toEpochMilli();// 当前时间减去下一周的凌晨2点的时间戳,得到时间差(小减大、大减小都行)Long diffTime = currentTime - time; // Long diffTime =time - currentTime;long absDiffTime = Math.abs(diffTime);return absDiffTime;} } -
测试:可能有延迟,正常现象
11.13 Redisson的lock锁和tryLock锁
-
Redisson 是一个基于 Redis 的 Java 客户端,提供了分布式锁的实现;
-
lock锁,即
lock()方法,是阻塞式的获取锁方式-
特点:
- 如果锁可用,则立即获取锁并返回
- 如果锁不可用,则当前线程会被阻塞,直到锁被释放
- 支持可重入(同一个线程可以多次获取同一把锁)
- 默认情况下,锁的租期是30秒,但会通过看门狗机制自动续期
-
例:
RLock lock = redisson.getLock("myLock"); try {lock.lock();// 执行业务逻辑 } finally {lock.unlock(); } -
注意:必须手动释放锁(在 finally 块中调用
unlock())
-
-
tryLock锁,即
tryLock()是非阻塞或带超时的获取锁方式-
特点:
- 非阻塞版本:
tryLock()立即返回获取结果 - 超时版本:
tryLock(long waitTime, TimeUnit unit)在指定时间内尝试获取锁 - 同样支持可重入
- 非阻塞版本:
-
方法重载:
boolean tryLock():尝试获取锁,成功返回true,失败立即返回falseboolean tryLock(long waitTime, long leaseTime, TimeUnit unit):在waitTime时间内尝试获取锁,获取成功后锁的持有时间为leaseTimeboolean tryLock(long waitTime, TimeUnit unit):在waitTime时间内尝试获取锁,获取成功后锁会通过看门狗自动续期
-
例:
RLock lock = redisson.getLock("myLock"); try {if (lock.tryLock(10, 30, TimeUnit.SECONDS)) {// 在10秒内获取到锁,且锁的租期是30秒// 执行业务逻辑} else {// 获取锁失败} } finally {if (lock.isHeldByCurrentThread()) {lock.unlock();} }
-
-
二者对比:
特性 lock() tryLock() 阻塞性 阻塞直到获取锁 非阻塞或带超时的阻塞 返回值 无返回值 返回boolean表示是否获取成功 适用场景 必须获取锁的场景 可以容忍获取锁失败的场景 自动续期 默认支持(看门狗机制) 取决于参数设置
11.14 最最终版本:Redisson分布式布隆过滤器+Redisson分布式锁
-
修改:
/*** 最最终版本:Redisson分布式布隆过滤器+Redisson分布式锁* @param albumId* @return*/ @SneakyThrows private Map getDistroCacheAndLockFinallyRedissonVersion(Long albumId) {// 1.定义缓存keyString cacheKey = RedisConstant.CACHE_INFO_PREFIX + albumId; // 缓存keyString lockKey = RedisConstant.ALBUM_LOCK_SUFFIX + albumId; // 分布式锁keylong ttl = 0l; // 数据的过期时间// 2.查询分布式布隆过滤器boolean contains = rBloomFilter.contains(albumId);if (!contains) {return null;}// 3.查询缓存String jsonStrFromRedis = redisTemplate.opsForValue().get(cacheKey);// 3.1 缓存命中if (!StringUtils.isEmpty(jsonStrFromRedis)) {return JSONObject.parseObject(jsonStrFromRedis, Map.class);}// 3.2 缓存未命中 查询数据库// 3.2.1 添加分布式锁RLock lock = redissonClient.getLock(lockKey);boolean accquireLockFlag = lock.tryLock(); // tryLock:非阻塞、自动续期if (accquireLockFlag) { // 抢到锁try {// 3.2.2 回源查询数据Map<String, Object> albumInfoFromDb = getAlbumInfoFromDb(albumId);if (albumInfoFromDb != null) { // 如果根据albumId查询到的数据不为空,则设置一个较长的过期时间ttl = 60 * 60 * 24 * 7l;} else { // 如果根据albumId查询到的数据为空,则设置一个较短的过期时间ttl = 60 * 60 * 24l;}// 3.2.3 同步数据到缓存中去redisTemplate.opsForValue().set(cacheKey, JSONObject.toJSONString(albumInfoFromDb), ttl, TimeUnit.SECONDS); // 防止缓存穿透的固定值攻击return albumInfoFromDb;} finally {lock.unlock();// 释放锁}} else { // 没抢到锁。等同步时间之后,查询缓存即可Thread.sleep(200);String result = redisTemplate.opsForValue().get(cacheKey);if (!StringUtils.isEmpty(result)) {return JSONObject.parseObject(result, Map.class);}return getAlbumInfoFromDb(albumId);} } -
记得修改接口:
/*** 根据专辑id查询专辑详情* @param albumId* @return*/ @Override public Map<String, Object> getAlbumInfo(Long albumId) {return getDistroCacheAndLockFinallyRedissonVersion(albumId); } -
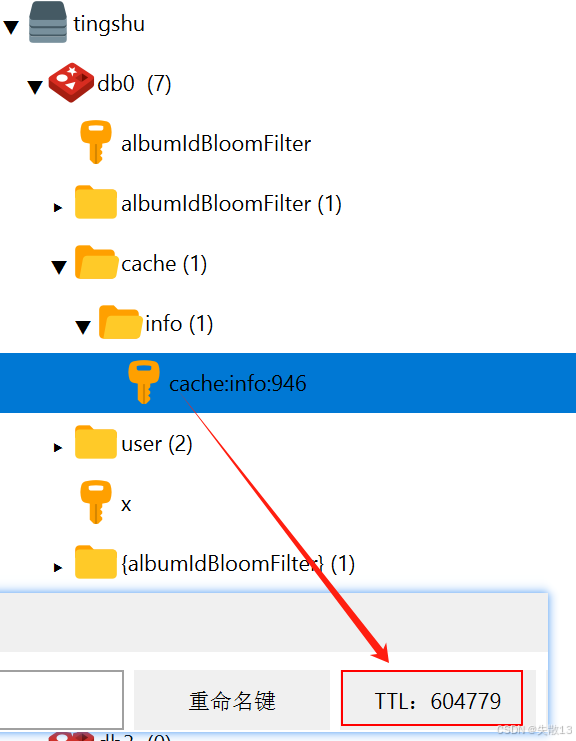
启用前端测试Redis:
- 因为根据 albumId 从数据库中查到是有数据的,所以 TTL 时间较长;
- 布隆过滤器则看后台有没有打印相关日志即可