虚拟地址-物理地址
虚拟地址和页表的由来
如果在没有虚拟内存和分⻚机制的情况下,每⼀个⽤⼾程序在物理内存上所对应的空间必须是连续的,如下图:
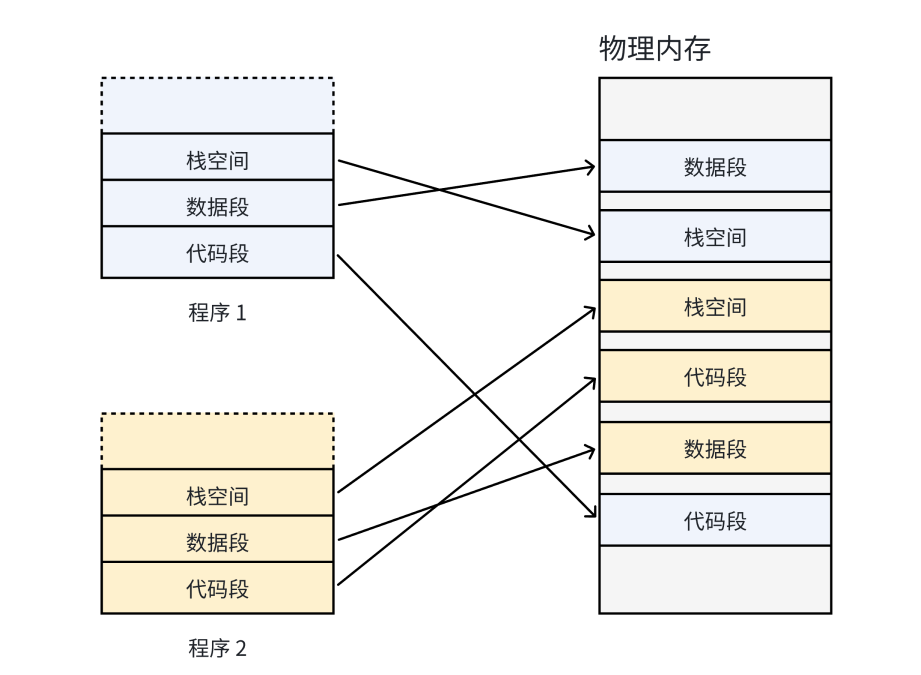
因为每⼀个程序的代码、数据⻓度都是不⼀样的,按照这样的映射⽅式,物理内存将会被分割成各种离散的、⼤⼩不同的块。经过⼀段运⾏时间之后,有些程序会退出,那么它们占据的物理内存空间不可以被回收,导致这些物理内存都是以很多碎⽚的形式存在。怎么办呢?我们希望操作系统提供给用户的空间必须是连续的,但是物理内存最好不要连续。此时虚拟内存和分⻚便出现了,如下图所示:
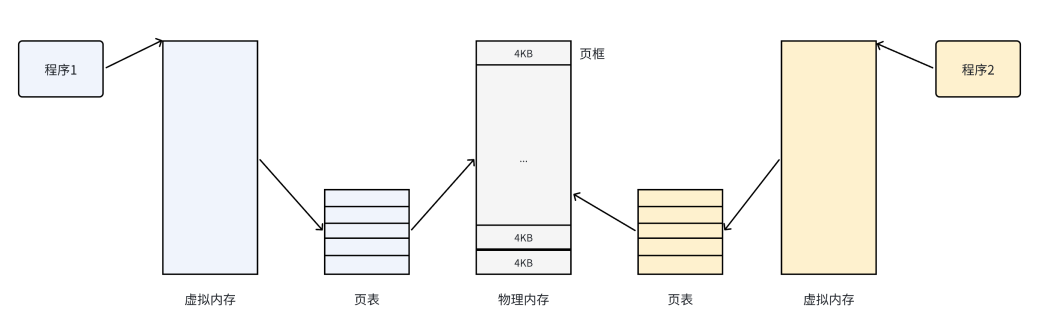
有了这种机制,CPU 便并⾮是直接访问物理内存地址,⽽是通过虚拟地址空间来间接的访问物理内存地址。所谓的虚拟地址空间,是操作系统为每⼀个正在执⾏的进程分配的⼀个逻辑地址,在32位机上,其范围从0 ~ 4G-1。
操作系统通过将虚拟地址空间和物理内存地址之间建⽴映射关系,也就是⻚表,这张表上记录了每⼀对⻚和⻚框的映射关系,能让CPU间接的访问物理内存地址。
把物理内存按照⼀个固定的⻓度的⻚框进⾏分割,有时叫做物理⻚。每个⻚框包含⼀个物理⻚(page)。⼀个⻚的⼤⼩等于⻚框的⼤⼩。⼤多数 32位 体系结构⽀持 4KB 的⻚,⽽ 64位 体系结构⼀般会⽀持 8KB 的⻚。
总结⼀下,其思想是将虚拟内存下的逻辑地址空间分为若⼲⻚,将物理内存空间分为若⼲⻚框,通过⻚表便能把连续的虚拟内存,映射到若⼲个不连续的物理内存⻚。(注意虚拟和物理的对应是虚拟页与物理页框的对应)
物理内存的管理
假设⼀个可⽤的物理内存有 4GB 的空间。按照⼀个⻚框的⼤⼩ 4KB 进⾏划分, 4GB 的空间就是4GB/4KB = 1048576 个⻚框。内核⽤ struct page 结构表⽰系统中的每个物理⻚,出于节省内存的考虑, struct page 中使⽤了⼤量的联合体union。
/** Each physical page in the system has a struct page associated with* it to keep track of whatever it is we are using the page for at the* moment. Note that we have no way to track which tasks are using* a page, though if it is a pagecache page, rmap structures can tell us* who is mapping it.*/
struct page {unsigned long flags; /* Atomic flags, some possibly* updated asynchronously */atomic_t _count; /* Usage count, see below. */union {atomic_t _mapcount; /* Count of ptes mapped in mms,* to show when page is mapped* & limit reverse map searches.*/struct { /* SLUB */u16 inuse;u16 objects;};};union {struct {unsigned long private; /* Mapping-private opaque data:* usually used for buffer_heads* if PagePrivate set; used for* swp_entry_t if PageSwapCache;* indicates order in the buddy* system if PG_buddy is set.*/struct address_space *mapping; /* If low bit clear, points to* inode address_space, or NULL.* If page mapped as anonymous* memory, low bit is set, and* it points to anon_vma object:* see PAGE_MAPPING_ANON below.*/};
#if USE_SPLIT_PTLOCKSspinlock_t ptl;
#endifstruct kmem_cache *slab; /* SLUB: Pointer to slab */struct page *first_page; /* Compound tail pages */};union {pgoff_t index; /* Our offset within mapping. */void *freelist; /* SLUB: freelist req. slab lock */};struct list_head lru; /* Pageout list, eg. active_list* protected by zone->lru_lock !*//** On machines where all RAM is mapped into kernel address space,* we can simply calculate the virtual address. On machines with* highmem some memory is mapped into kernel virtual memory* dynamically, so we need a place to store that address.* Note that this field could be 16 bits on x86 ... ;)** Architectures with slow multiplication can define* WANT_PAGE_VIRTUAL in asm/page.h*/
#if defined(WANT_PAGE_VIRTUAL)void *virtual; /* Kernel virtual address (NULL ifnot kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGSunsigned long debug_flags; /* Use atomic bitops on this */
#endif#ifdef CONFIG_KMEMCHECK/** kmemcheck wants to track the status of each byte in a page; this* is a pointer to such a status block. NULL if not tracked.*/void *shadow;
#endif
};操作系统中使用一个数组按地址高低顺序存储所有的page的地址,那么我们只需要知道一个page的数组下标就可以找到这个数组对应的物理地址,所以在page中没有存储起始地址的指针。在page结构体中有这样几个重要的参数:
1.flags :⽤来存放⻚的状态。这些状态包括⻚是不是脏的,是不是被锁定在内存中等。flag的每⼀位单独表⽰⼀种状态,所以它⾄少可以同时表⽰出32种不同的状态。
2. _mapcount :表⽰在⻚表中有多少项指向该⻚,也就是这⼀⻚被引⽤了多少次。当计数值变
为-1时,就说明当前内核并没有引⽤这⼀⻚,于是在新的分配中就可以使⽤它。
3. virtual :是⻚的虚拟地址。通常情况下,它就是⻚在虚拟内存中的地址。
页表
页表中的每⼀个表项,指向⼀个物理⻚的开始地址。在 32 位系统中,虚拟内存的最⼤空间是 4GB ,这是每⼀个⽤⼾程序都拥有的虚拟内存空间。既然需要让 4GB 的虚拟内存全部可⽤,那么⻚表中就需要能够表⽰这所有的 4GB 空间,那么就⼀共需要 4GB/4KB = 1048576 个表项。
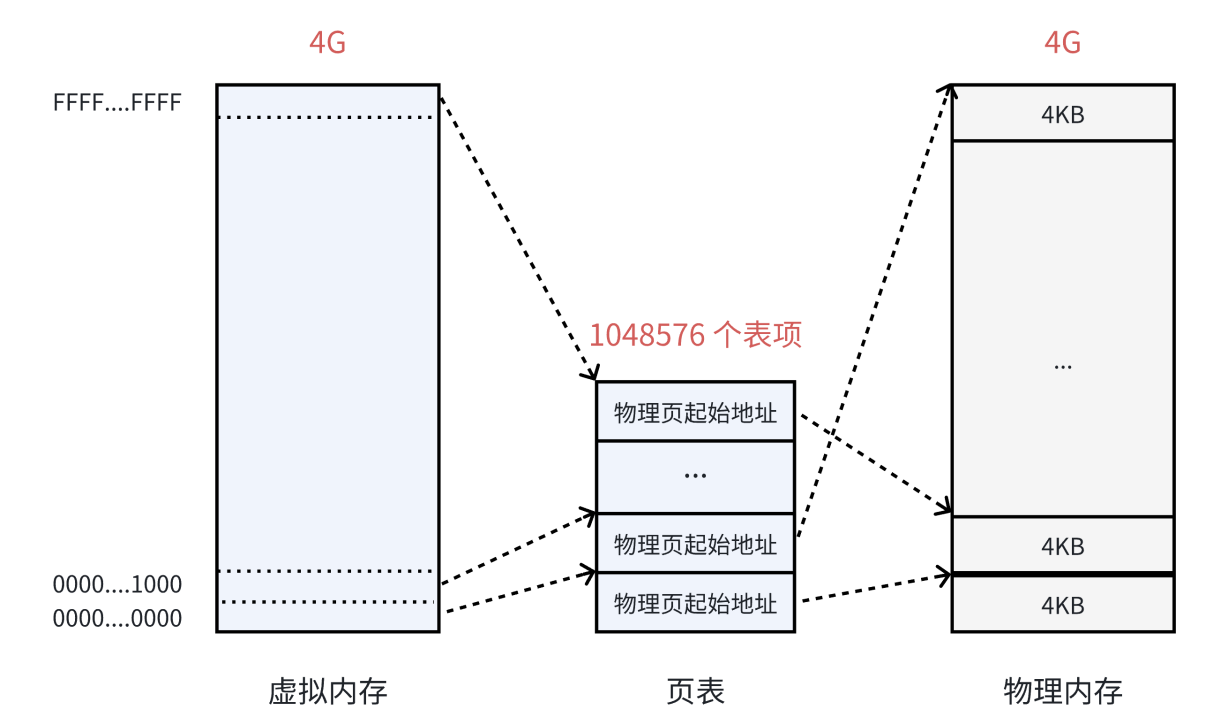
可以看到虚拟地址是一直连续的,被分成一页一页的,每一页都对应4KB大小的空间,每一个页都通过页表对应一个物理内存的页框。可以看到物理地址的映射是随机的,但是虚拟地址的开辟却是连续的。
但是有一个问题:在 32 位系统中,地址的⻓度是 4 个字节,那么⻚表中的每⼀个表项就是占⽤ 4 个字节。所以⻚表占据的总空间⼤⼩就是: 1048576*4 = 4MB 的⼤⼩。也就是说映射表⾃⼰本⾝,就要占⽤ 4MB / 4KB = 1024 个物理页。
• 回想⼀下,当初为什么使⽤⻚表,就是要将进程划分为⼀个个⻚可以不⽤连续的存放在物理内存
中,但是此时⻚表就需要1024个连续的⻚框,似乎和当时的⽬标有点背道⽽驰了......
• 此外,根据局部性原理可知,很多时候进程在⼀段时间内只需要访问某⼏个⻚就可以正常运⾏
了。因此也没有必要⼀次让所有的物理⻚都常驻内存。
为了解决这个问题,可以把这个单⼀⻚表拆分成 1024 个体积更⼩的映射表。如下图所⽰。这样⼀来,1024(每个表中的表项个数) * 1024(表的个数),仍然可以覆盖 4GB 的物理内存空间。
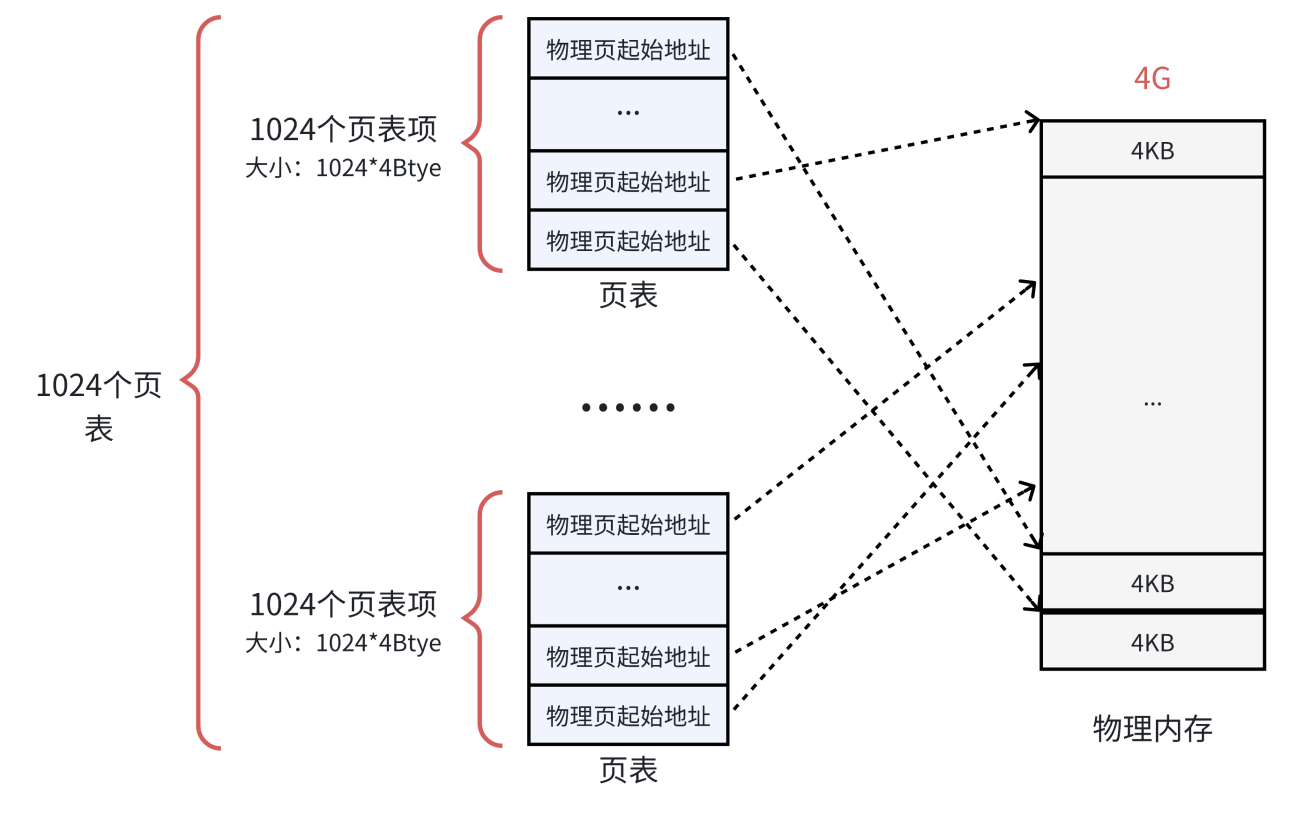
聪明的伙伴已经发现,⼀共有 1024 个⻚表。⼀个⻚表⾃⾝占⽤ 4KB ,那么1024 个⻚表⼀共就占⽤了 4MB 的物理内存空间,和之前没差别啊?从总数上看是这样,但是⼀个应⽤程序是不可能完全使⽤全部的 4GB 空间的,也许只要⼏⼗个⻚表就可以了。例如:⼀个⽤⼾程序的代码段、数据段、栈段,⼀共就需要 10 MB 的空间,那么使⽤ 3 个⻚表就⾜够了。
页目录结构
到⽬前为⽌,每⼀个⻚框都被⼀个⻚表中的⼀个表项来指向了,那么这 1024 个⻚表也需要被管理起来。管理⻚表的表称之为⻚⽬录表,形成⼆级⻚表。(事实上更大的内存会使用更多级的页表进行管理,但是思想都是一致的,我们这里拿2级表举例)
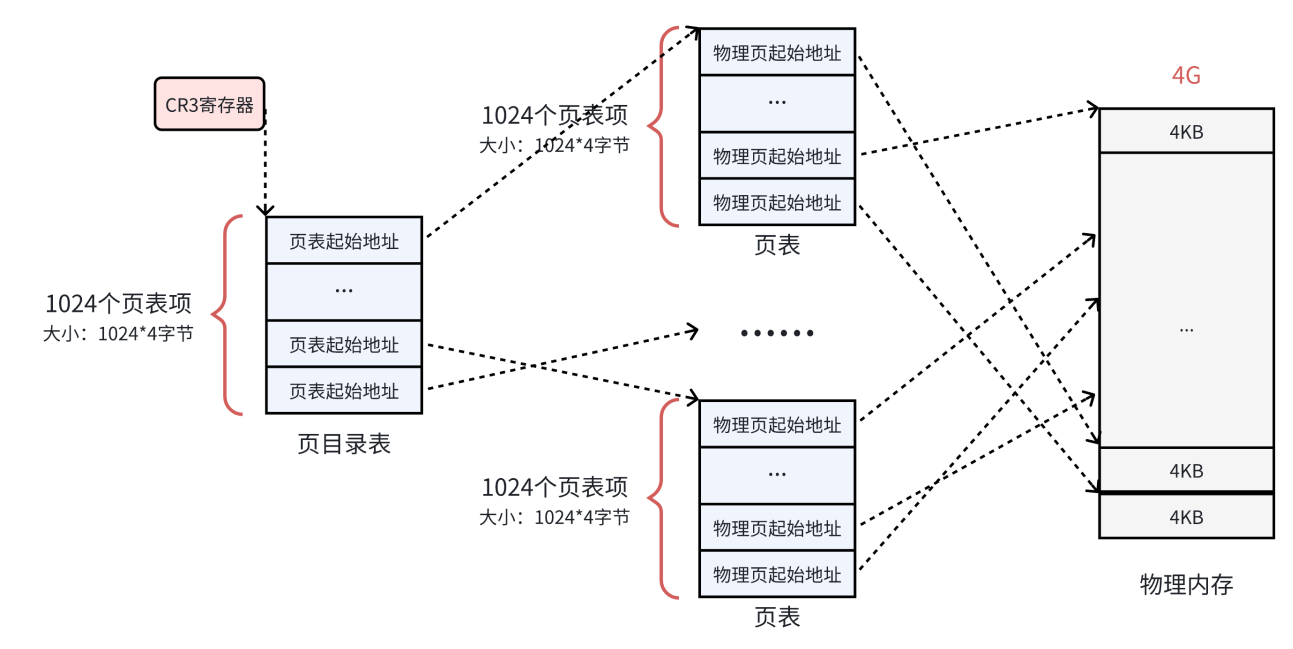
• 所有⻚表的物理地址被页目录表项指向
• ⻚⽬录的物理地址被 CR3 寄存器 指向,这个寄存器中,保存了当前正在执⾏任务的⻚⽬录地址。
所以操作系统在加载⽤户程序的时候,不仅仅需要为程序内容来分配物理内存,还需要为⽤来保存程序的⻚⽬录和⻚表分配物理内存。
两级页表的虚拟地址到物理地址的转换
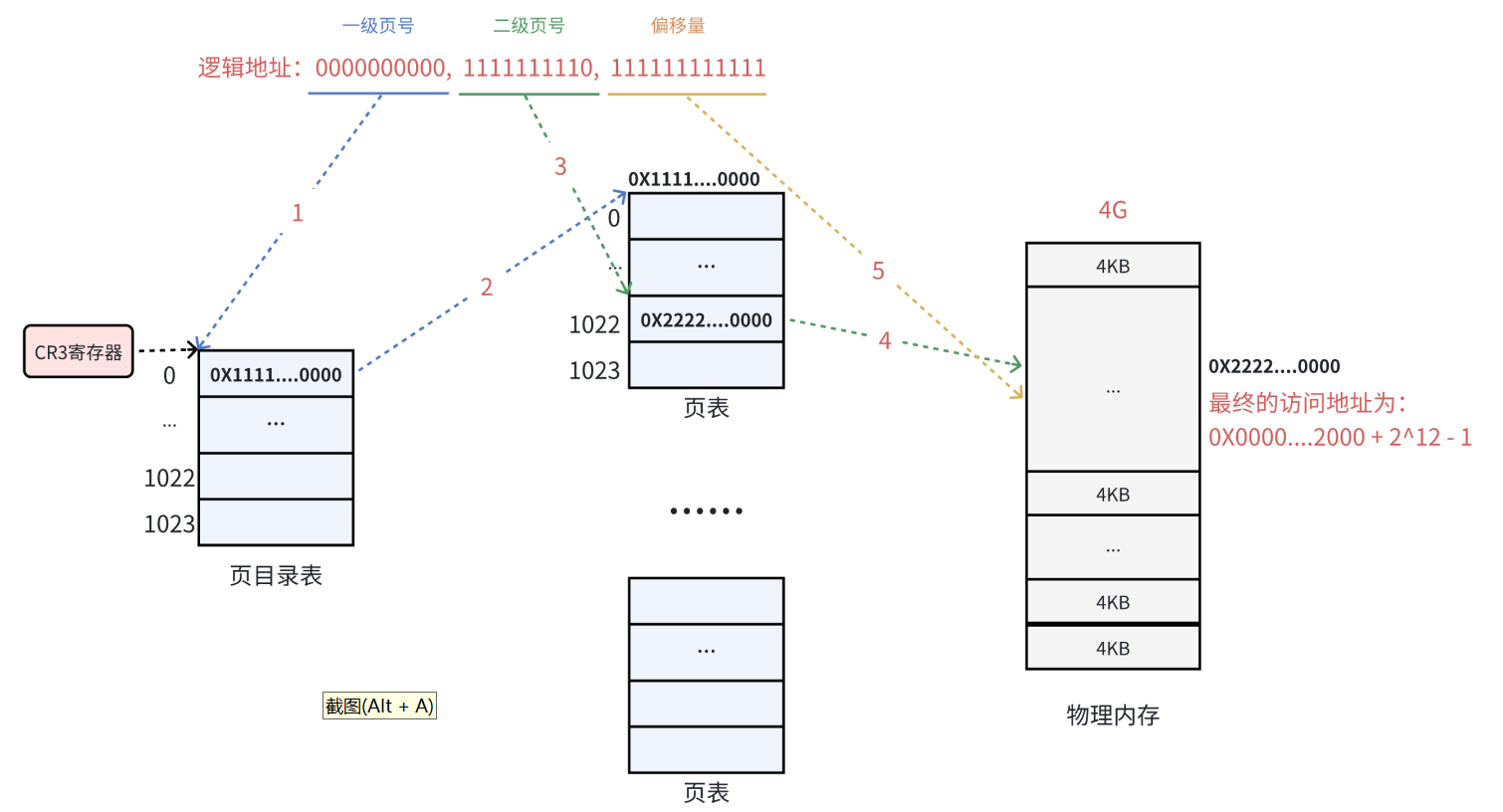
下⾯以⼀个逻辑地址为例。将逻辑地址( 0000000000,0000000001,11111111111 )转换为物
理地址的过程:
1.在32位处理器中,采⽤4KB的页大小,则虚拟地址中低12位为页偏移(页偏移就是使用虚拟地址的高20位知道到该虚拟地址对应的页了,那么该虚拟地址的低12位就直接可以作为页内偏移地址),剩下⾼20位给⻚表,分成两级,每个级别占10个bit(10+10)。
2.CR3 寄存器读取页目录起始地址,再根据⼀页号查页目录表,找到下⼀级页表在物理内存中
存放位置。
3. 根据虚拟地址的高20位和二级页号查表,找到最终想要访问的page。
4. 结合页内偏移量(虚拟地址的低12位)得到物理地址。
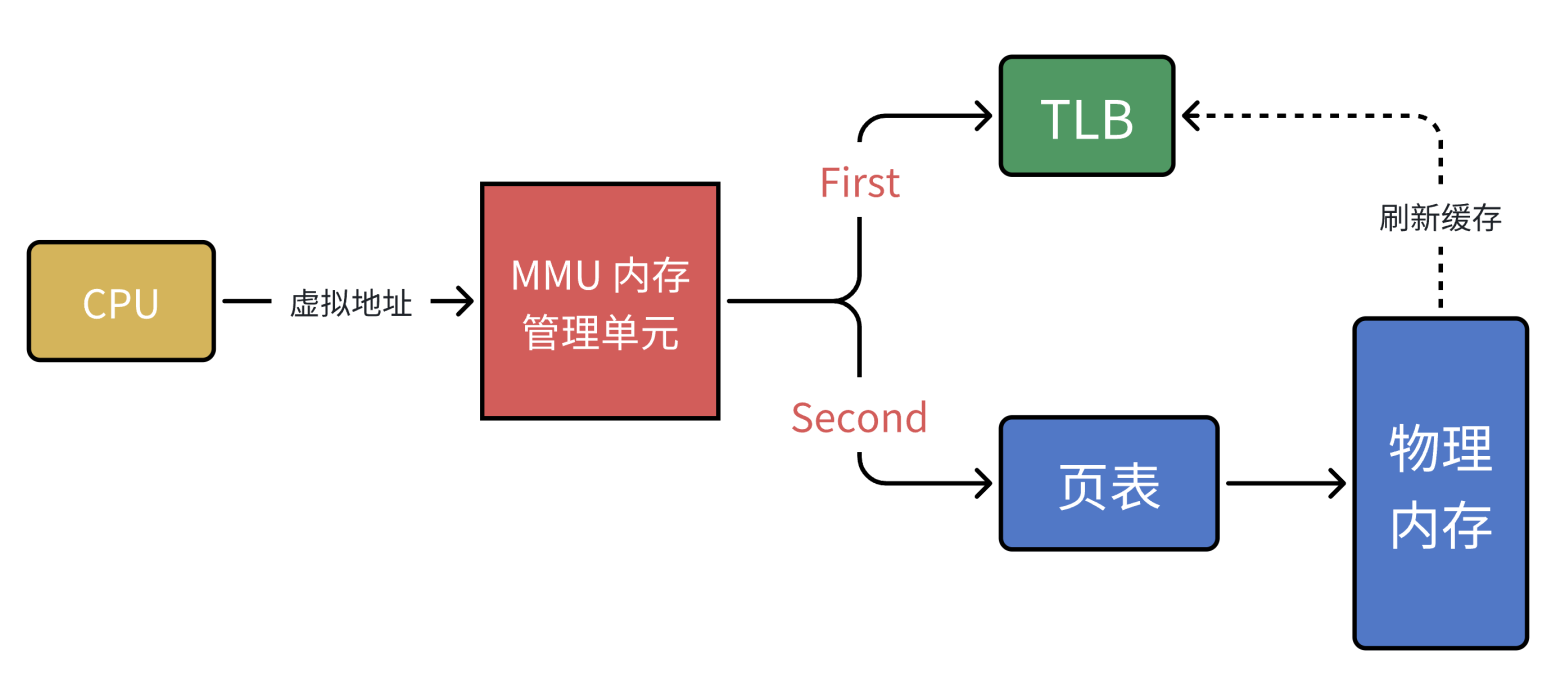
以上其实就是 MMU 的⼯作流程。MMU(Memory Manage Unit)是⼀种硬件电路,其速度很快,主要⼯作是进⾏内存管理,地址转换只是它承接的业务之⼀。单级页表对连续内存要求⾼,于是引⼊了多级页表,但是多级页表也是⼀把双刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。有没有提升效率的办法呢?计算机科学中的所有问题,都可以通过添加⼀个中间层来解决。 MMU 引⼊了新武器:快表的 TLB (其实,就是缓存)。
当 CPU 给 MMU 传新虚拟地址之后, MMU 先去问 TLB 那边有没有,如果有就直接拿到物理地址发到总线给内存,⻬活。但 TLB 容量⽐较⼩,难免发⽣ Cache Miss ,这时候 MMU 还有保底的⽼武器 ⻚表,在⻚表中找到之后 MMU 除了把地址发到总线传给内存,还把这条映射关系给到TLB,让它记录⼀下刷新缓存。