Linux——线程(下)
文章目录
- 一、线程
- 二、线程操作
- 1. 创建线程
- 2. 获取线程ID
- 3. 线程等待
- 4. 线程终⽌
- 5. 线程分离
- 三、线程库的理解
- 1. 线程id
- 2. 线程TCB的存放和内容
- TCB的存储
- TCB中的内容
- 3. 线程的栈
- 4. 线程局部存储
一、线程
线程共享进程地址空间中的所有数据
全局区,代码区,堆区,共享区,栈区都是共享的
没错栈区也是共享的
只要线程a能拿到线程b函数中的栈区变量的地址,就可以对它进行修改和访问
而且修改之后,线程b看到的也是改变了之后的【但是强烈不建议这么做】
线程会瓜分进程的时间片
即:
一个进程的时间片是10ns
它一共有5个线程,那么每个线程的时间片就是2ns
为什么呢?
操作系统进行调度时,是以线程为单位的
而且承担资源分配的基本实体是进程,进程是资源的容器,线程瓜分进程资源,而时间片也是资源!!!
所以,必须给每个线程分时间片,这样操作系统调度线程时,才知道线程什么时候时间片耗尽
而且:
如果线程的时间片和它所属的进程一样长,那么一个进程就可以通过创建更多线程,来延长自己占用CPU的时间,这显然对其他进程不公平
这和分时操作系统的公平调度理念不符
二、线程操作
下面关于线程操作全是库函数
为什么Linux线程相关的函数是库函数,而不是系统调用?
因为在Linux中没有给线程先描述再组织
Linux内核中的线程是使用LWP模拟实现的
所以Linux内核就只给我们提供了创建LWP的系统调用接口(即系统调用clone)操作线程的各种系统调用通通没有
用户不愿意直接去使用创建LWP的系统调用,因为使用这个系统调用还得去了解Linux的LWP等相关知识,成本太高了
所以Linux就让库封装了LWP相关的系统调用得到了给用户提供了包括线程的各种操作的的库[库的名字就叫pthread]
封装成库之后,用户就只需要知道线程的相关概念就可以轻松使用库函数了
所以
Linux中,如果使用了线程相关的函数,那么编译时都要链接pthread动态库,pthread是Linux实现的自带的库,是原生线程库
所以:
其他任何语言想要在Linux平台上支持线程,就必须封装Linux的pthread库
1. 创建线程
pthread_create
作用:创建一个线程
#include <pthread.h>int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
-
参数thead:输出型参数,需要传入一个pthread_t类型的变量的地址,可以得到线程的tid。
-
参数attr:这个参数跟属性相关的设定,几乎用不到,这里也就不再进,设为nullptr就行。
-
参数start_routine:传入一个返回类型为void*,参数为void*的自定义函数,线程创建后会执行这个函数。
-
参数arg:传入一个void*类型的参数,最后会被作为start_routine的参数。
-
返回值:
非0:创建失败。
0:创建成功
为什么是void * 类型?
就是为了支持接收任意类型的参数,变量,数组,对象都可以传递过去
这样就可以一次传递多个信息,也可以更好地支持C和C++混合编写
我们可以定义一个任务类,里面存储一些基本信息和分配给这个新线程的任务函数
即设计一个任务类,里面的成员变量就是任务函数,以及任务函数对应的参数
#include <iostream>
#include <pthread.h>
#include <unistd.h>using namespace std;void* Route(void* args)
{char* k = (char*)args;cout << k;while(true){sleep(1);}return nullptr;
}int main()
{pthread_t p;char buf[] = "hello mihayou\n";int n = pthread_create(&p, nullptr, Route, buf);if(n != 0)exit(1);while(true){cout << "12345678\n";sleep(1);}return 0;
}
2. 获取线程ID
pthread_self
作用:获取线程的ID
#include <pthread.h>pthread_t pthread_self(void);
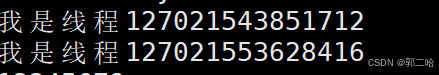
打印出来的tid是通过pthread库中有函数 pthread_self 得到的,它返回⼀个pthread_t类型的变量,指代的是调⽤pthread_self函数的线程的“ID”。
怎么理解这个“ID”呢?这个“ID”是pthread库给每个线程定义的进程内唯⼀标识,是pthread库
维持的。
由于每个进程有⾃⼰独⽴的内存空间,故此“ID”的作⽤域是进程级⽽⾮系统级(内核不认识)。
其实pthread库也是通过内核提供的系统调⽤(例如clone)来创建线程的,⽽内核会为每个线程创建
系统全局唯⼀的“ID”来唯⼀标识这个线程。
使⽤ps -aL命令查看线程信息
运⾏代码后:
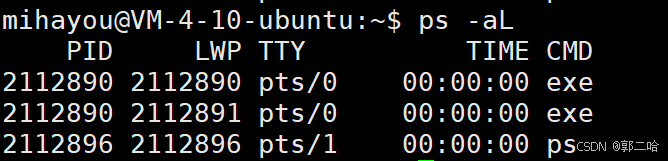
LWP是什么呢?
LWP得到的是真正的线程ID。
之前使⽤ pthread_self 得到的这个数实际上是⼀个地址,在虚拟地址空间上的⼀个地址,通过这个地址,可以找到关于这个线程的基本信息,包括线程ID,线程栈,寄存器等属性。
在 ps -aL 得到的线程ID,有⼀个线程ID和进程ID相同,这个线程就是主线程,主线程的栈在虚拟
地址空间的栈上,⽽其他线程的栈在是在共享区(堆栈之间),因为pthread系列函数都是pthread库
提供给我们的。⽽pthread库是在共享区的。所以除了主线程之外的其他线程的栈都在共享区。
3. 线程等待
从线程需要被主线程等待和回收(使用pthread_join)
- 线程的退出信息,在线程库中它自己的TCB中维护着,而TCB关联内核的LWP的生命周期
- 主线程也要知道其他线程把任务执行地怎么样 所以如果不等待,即使线程退出了,操作系统也不敢释放它的LWP,就会出现与进程类似的僵尸问题
pthread_join
作用: 等待线程结束
int pthread_join(pthread_t thread, void **retval);
- 参数thread:传入需要等待的线程tid。
- 参数retval:输出型参数,传入void类型的地址,得到线程的任务完成情况,这个retval得到的也就是在我们传入自定义函数中返回的void类型。因为分配给新线程的函数的返回值为void*类型的,所以以输出型参数的方式获取这个返回值就得是void**类型的。
- 返回值
非0:失败。
0:成功。
注意: pthread_join是阻塞等待的从线程的
一般是主线程等待从线程
4. 线程终⽌
如果需要只终⽌某个线程⽽不终⽌整个进程,可以有三种⽅法:
- 从线程函数return。这种⽅法对主线程不适⽤,从main函数return相当于调⽤exit。
- 线程可以调⽤pthread_exit终⽌⾃⼰。
- ⼀个线程可以调⽤pthread_cancel终⽌同⼀进程中的另⼀个线程。
pthread_exit
作用: 线程终⽌
#include <pthread.h>void pthread_exit(void *retval);
- void*retval:线程的退出信息
需要注意,pthread_exit或者return返回的指针所指向的内存单元必须是全局的或者是⽤malloc分配的,
不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了。
pthread_cancel
作用:取消⼀个执⾏中的线程
#include <pthread.h>int pthread_cancel(pthread_t thread);
- 参数thread:传入需要取消的线程tid。
- 返回值:int
成功,0
失败,就返回错误码
注意:
- 一个线程能被取消的前提是,这个线程已经启动了
- 被取消的线程也必须被回收(不然会内存泄露),而且退出码必定是-1
5. 线程分离
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进⾏pthread_join操作,否则⽆法释放资源,从⽽造成系统泄漏。
如果不关⼼线程的返回值,join是⼀种负担,这个时候,我们可以告诉系统,当线程退出时,⾃动释放线程资源。
pthread_detach
作用: 把指定线程的被等待状态设置成detach
int pthread_detach(pthread_t thread);
- 参数pthread_t thread:参入需要分离的线程tid。
- 返回值
成功:返回 0。
失败:返回错误码
三、线程库的理解
1. 线程id
我们使用的pthread库里面的接口的时候,使用的是线程id来操纵线程
但是线程id并不是Linux内核中的LWP,而是线程库pthread自己维护的
线程id的本质是地址,是线程库维护的这个线程对应的结构体(tcb)变量的起始地址
创建线程的时候,不仅Linux内核中会创建一个LWP描述线程的内核级属性,线程库pthread中也会创建一个TCB结构体变量来维护线程的用户级属性
即线程库中,会对线程进行先描述,再组织
为什么?
-
LWP是描述轻量级进程的,但是用户使用的是线程,所以用户需要的是线程的属性,而不是轻量级进程的属性
即LWP并不能非常好地描述用户所需的线程的属性(比如:LWP中没有维护这个线程的栈大小,而线程库TCB中维护了) -
为了解藕
因为用户使用的是线程库,线程库创建出来的线程是用户级线程
用户级线程不宜和内核级线程共用结构体和数据结构,这样耦合度太高,而且还要使用系统调用陷入内核
线程库哪里来的空间对线程先描述再组织?
线程库维护进程的线程使用的空间是进程自己申请的物理内存(即使用进程的共享区内存来存储)
因为这样描述线程属性的结构体变量才有虚拟地址,执行流执行线程的库函数的时候,才能找到并访问到对应的数据
所以就可以做到:
不同的进程,使用同一个线程库,但线程库中维护的线程是不一样的
但是线程库的代码区的代码是一样的
2. 线程TCB的存放和内容
TCB的存储
线程库中TCB的存储是在共享区中开辟一块内存,把所有TCB以及对应的连续存储在一起的
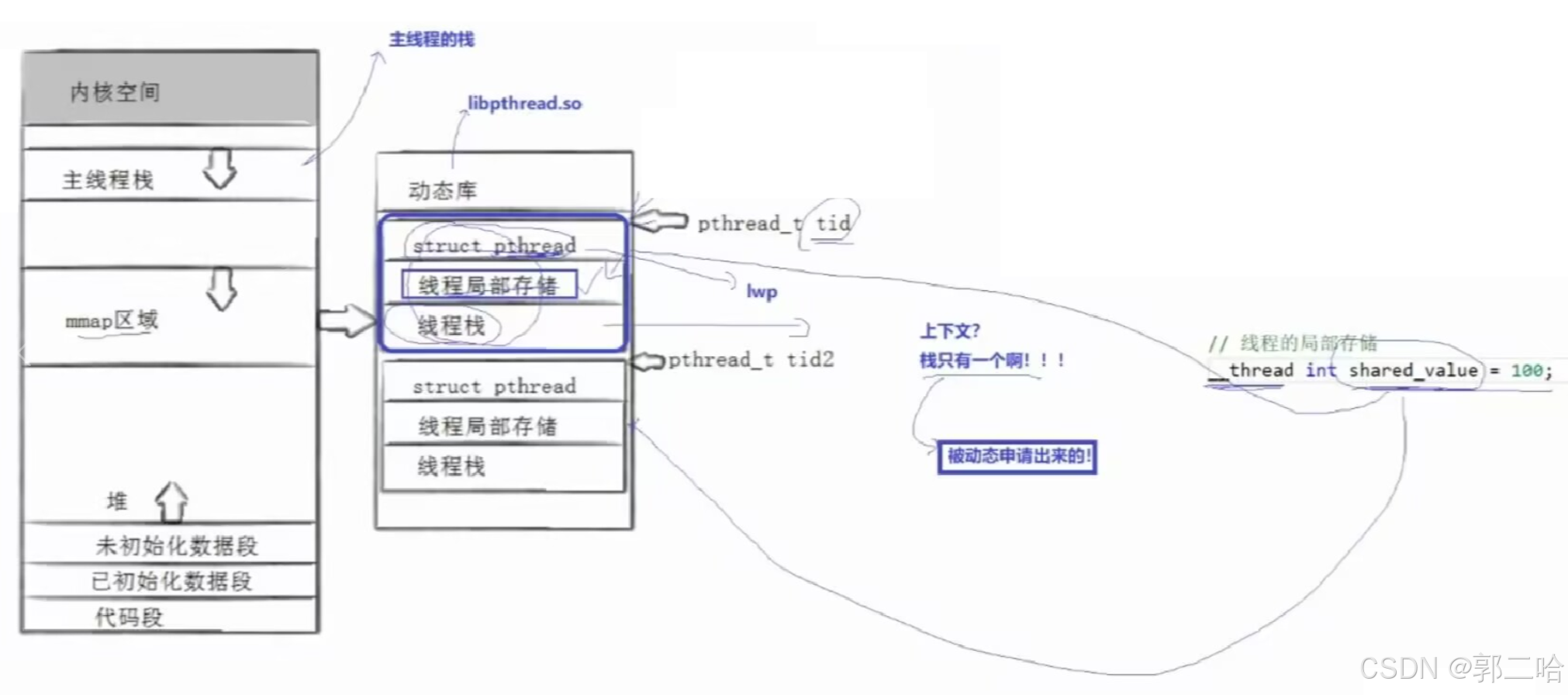
TCB中的内容
-
对应的轻量级进程的LWP
-
对应进程的pid
-
void*result:分配给自己这个线程的函数的返回值
-
用户分配给自己这个线程的入口函数的地址,以及它对应的参数
-
自己这个线程对应的栈的起始虚拟地址,以及栈的大小
-
线程对应的线程局部存储的起始地址,及其大小
-
标记线程是否分离的bool类型的变量
3. 线程的栈
线程的栈是独立的,分两种
- 进程地址空间中所谓的栈区,其实是专门给主线程用的栈区,大小是不固定的,可以扩容(当然也受到mm_struct的区域划分限制)
- 新线程的栈区是在创建新线程的同时,使用mmap在共享区开辟的一块的大小固定(一般默认是8MB,如果用满了8MB还用就会栈溢出)的内存
所以才说线程的栈是独立的
4. 线程局部存储
一个全局变量b本来是被所有线程共享的,所有线程访问这个的全局变量b时,访问的虚拟地址是同一个
如果定义时,给全局变量b前面加一个__thread那么这个全局变量b就不是被所有线程共享的了,不同线程访问这个变量b时,访问的虚拟地址不同
这是怎么做到的?
如果一个变量a定义时加了__thread,编译器编译的时候,如果创建了新线程,就会在这个线程的线程局部存储中开辟空间存储一份这个变量a
以后这个线程访问这个变量a的时候,就只访问自己线程局部存储中的变量a
注意:
__thread只能修饰内置类型的变量
线程局部存储的作用:
-
不同线程对应一个独立的错误码,比如C标准库提供的errno
-
缓存线程属性等访问频繁的数据,提高访问速度
比如:
可以加__thread定义一个全局的线程id,在对应线程里面初始化之后
这样以后使用线程id,就不需要在调用pthread_self,直接用它,不同的线程看到的也是自己的id