DGMR压缩技术:让大规模视觉Transformer模型体积减半而性能不减
Transformer架构展现出卓越的扩展特性,其性能随模型容量增长而持续提升。大规模模型在获得优异性能的同时,也带来了显著的计算和存储开销。深入分析主流Transformer架构发现,多层感知器(MLP)模块占据了模型参数的主要部分,这为模型压缩提供了重要切入点。
针对这一问题,研究者提出了多样性引导MLP缩减(Diversity-Guided MLP Reduction, DGMR)方法,该方法能够在保持性能近乎无损的前提下显著缩减大型视觉Transformer模型。DGMR采用基于Gram-Schmidt的剪枝策略,系统性地移除MLP层中的冗余神经元,同时通过精心设计的策略确保剩余权重的多样性,从而在知识蒸馏过程中实现高效的性能恢复。
实验结果表明,经过剪枝的模型仅需使用LAION-2B数据集的0.06%(无标签数据)即可恢复至原始精度水平。在多个最先进的视觉Transformer模型上的广泛实验验证了DGMR的有效性,该方法能够减少超过57%的参数量和浮点运算次数(FLOPs),同时保持性能几乎无损。值得注意的是,在EVA-CLIP-E(4.4B参数)模型上,DGMR实现了71.5%的参数缩减率,且未出现性能下降。
Transformer架构在计算机视觉和自然语言处理领域展现出强大的能力,其性能与模型规模呈现正相关关系。然而,大规模Transformer模型虽然能够达到极高的准确率,但其带来的计算复杂度和内存需求也呈指数级增长,严重限制了模型的实际部署和广泛应用。
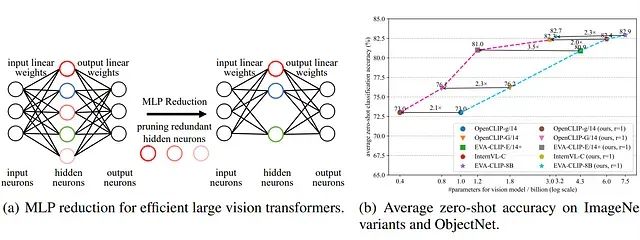
(a)视觉Transformer模型中较大的MLP扩展比导致存在大量冗余参数,为模型压缩提供了机会。(b)本方法在现有最先进大型Transformer模型的压缩任务中实现了近似无损的优异性能
为应对这一挑战,研究界主要探索了模型剪枝和知识蒸馏两大技术路径来实现大型视觉Transformer(ViTs)的高效化。传统剪枝方法通常基于重要性评分机制移除相对不重要的权重或注意力头,但这类方法往往忽视了权重多样性的维护需求,而权重多样性对于模型原始性能的恢复具有关键作用。此外,基于梯度的剪枝策略需要进行大量的计算开销和多轮微调过程,对于大规模模型而言成本尤为高昂。知识蒸馏方法则通过训练小规模学生模型来学习大规模教师模型的行为模式,但由于学生模型与教师模型在架构上的差异,通常需要从零开始进行训练,这同样需要消耗大量的时间和数据资源,特别是在处理大型ViTs时计算成本极其昂贵。
深入分析Transformer架构可以发现,MLP模块由于采用了较高的扩展比例而包含了大量参数。以EVA-CLIP-E模型为例,MLP模块占据了全部模型参数的约81.1%。如上图所示,输入层通过扩展机制转换为更大的隐藏层,其扩展比例通常在2.67(DINOv2-g)到8.57(EVA-CLIP-E)之间变化。虽然这种大规模扩展有助于模型的训练收敛和性能提升,但也不可避免地引入了大量冗余参数。因此,针对MLP模块隐藏层规模的优化成为提升大型视觉Transformer效率的有效途径。
研究专注于大型视觉Transformer MLP模块中冗余神经元的识别与移除。核心思想在于,经过适当的微调过程,大量神经元可以通过少数关键"主导"神经元的线性组合进行有效替代。这一过程面临两个关键技术挑战:如何科学地选择这些主导神经元,以及如何在剪枝操作后有效恢复模型的原始性能。
为解决上述挑战,研究提出了多样性引导MLP缩减(DGMR)方法。DGMR通过量化神经元与输入神经元之间的连接强度(基于权重幅度)来识别最重要的神经元。为确保所选神经元的多样性并避免信息冗余,算法在每次选择后对剩余权重进行更新。这一迭代过程持续进行直至达到预设的神经元数量目标,确保每个新选择的神经元都能提供已选神经元未能捕获的独特信息。
与传统方法相比,DGMR的显著优势在于无需额外的梯度计算或迭代式剪枝-微调流程,从而大幅提升了算法效率。在剪枝完成后,方法采用知识蒸馏技术协助缩减后的模型恢复原始性能,其中原始模型作为教师模型,剪枝模型作为学生模型进行学习。
主要贡献包括:提出了一种适用于大型视觉Transformer的高效压缩方法,避免了昂贵的迭代剪枝开销;设计了多样性引导的神经元选择策略,确保剪枝模型的有效性和可恢复性;通过仅在ImageNet-1K数据集(无标签)上进行知识蒸馏,在EVA-CLIP-8B等模型上实现了超过57%的参数和FLOPs缩减,在EVA-CLIP-E上达到71.5%的缩减率,且性能损失微乎其微。
研究在多个大规模模型上验证了方法的有效性,包括EVA-CLIP-E、EVA-CLIP-8B和DINOv2-g,均展现出强大的压缩能力和近似无损的性能表现。
视觉Transformer模型剪枝技术
为提升视觉Transformer(ViTs)的推理效率并降低内存占用,现有研究主要通过压缩多头自注意力模块或多层感知器(MLP)模块来实现模型优化。这些方法的核心在于评估模型权重的重要性并移除相对不重要的组件。
基于权重幅度的剪枝方法通过分析权重数值的大小来判断其重要性,保留具有较大数值的权重。ViT-Slim方法引入了可学习的稀疏性约束机制来发现高效的模型结构,而DIMAP方法则通过分析权重移除对信息传递的影响程度来避免误删重要权重。
基于注意力机制的剪枝方法利用注意力分数来确定模型组件的重要性。SNP方法移除具有低注意力分数的查询和键层,同时维持模型整体注意力分布的稳定性,以确保最终预测结果不受显著影响。
基于泰勒展开的剪枝方法采用数学近似技术来估计权重剪枝对损失函数的影响,从而在最小化性能损失的前提下进行权重移除。SAViT方法利用该思想评估模型不同组件的综合重要性以实现均衡剪枝,VTC-LFC方法采用基于泰勒展开估计的低频敏感性度量来指导权重选择,而NViT方法则引入了与泰勒展开相关的Hessian矩阵方法来评估Transformer块中参数组的重要性。
现有方法主要关注于减少剪枝操作对模型输出的负面影响。相比之下,本研究方法的创新之处在于强调保持剪枝模型中权重的多样性,这一特性显著有助于模型在知识蒸馏过程中的性能恢复。此外,与需要进行耗时的迭代剪枝-微调过程或额外梯度计算的传统方法不同,本方法在压缩大型视觉Transformer方面展现出更高的实用性和效率。
视觉Transformer的令牌缩减策略
除参数缩减外,另一种提升视觉Transformer推理速度的有效途径是减少模型处理的令牌数量。这一目标可通过令牌剪枝和令牌合并两种主要技术实现。
令牌剪枝技术通过从序列中移除相对不重要的令牌来加速推理过程。A-ViT方法在每个层级仅保留信息量最丰富的令牌,AdaViT方法根据输入图像特征自适应选择使用的补丁、注意力头或层级。DynamicViT方法采用注意力掩码技术阻断特定令牌间的交互,LRP方法通过计算"语义密度"分数评估各补丁的重要程度以指导令牌筛选,Zero-TPrune方法则从预训练Transformer的注意力图中构建重要性分布来指导令牌剪枝策略。
令牌合并技术将相似令牌组合以减少处理的令牌总数。ToMe方法采用快速匹配算法合并最相似的令牌,BAT方法将令牌分为高注意力和低注意力两类,合并相似的低注意力令牌同时保持高注意力令牌的独特性以维护多样性。TPS方法识别令牌间的最近邻关系并进行合并以保留重要信息,STViT方法引入语义令牌来全局或局部总结整个令牌集合,TokenLearner方法识别图像或视频中的关键区域并集中处理,Vid-TLDR方法检测视频中的关键区域以合并背景令牌同时增强对主要对象的关注。
本研究方法专注于通过剪枝MLP模块中的冗余神经元来减少大型视觉Transformer的参数数量。值得注意的是,该方法与现有的令牌缩减技术具有良好的兼容性。通过结合参数缩减和令牌缩减策略,可以进一步提升视觉Transformer的推理速度并降低内存使用量。
DGMR方法论
整体框架
模型压缩的核心目标是在最小化性能损失的前提下显著减少模型规模。针对大型视觉Transformer,本研究重点关注MLP模块的参数缩减,因为这些模块包含了模型的主要参数量。同时,方法致力于在剪枝过程中保持剩余权重的多样性,使压缩后的模型能够最大程度地保留原始模型的有效信息。
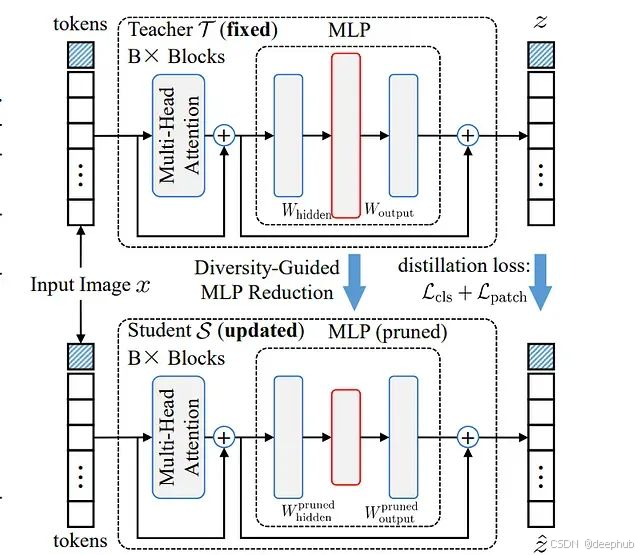
方法整体框架概述。第一阶段采用多样性保持策略对包含Transformer模型主要参数的MLP模块隐藏神经元进行剪枝。第二阶段利用原始Transformer模型作为教师模型指导剪枝模型的训练以实现性能恢复。
如上图所示,本方法采用两阶段压缩策略来实现高效的模型缩减和最小的性能损失。在第一阶段,方法对大型MLP模块的隐藏层进行神经元剪枝,同时精心维护权重连接的多样性。这一剪枝操作的关键优势在于不改变令牌的特征维度,从而避免对模型其他组件产生影响。
第二阶段采用知识蒸馏技术,原始大型模型充当教师角色,剪枝后的小型模型作为学生进行学习。学生模型通过模仿教师模型的行为模式来恢复性能。由于剪枝操作保持了输出维度的一致性,学生模型能够直接与教师模型的输出进行对齐,整个过程无需额外的模块设计或复杂的架构调整。
多样性引导的MLP缩减算法
本节详细阐述参数密集型MLP模块的缩减方法,旨在压缩大型视觉Transformer模型。算法的主要目标是减少冗余信息的同时在剪枝后维持权重或神经元的多样性,从而提升剪枝模型的可恢复性。
根据图2所示的架构,MLP隐藏层的权重表示为W(hidden)= [w₁, w₂, …, wₘ]ᵀ ∈ ℝᴹ×ᴺ,其中M表示隐藏神经元数量,N表示输入神经元数量。每个wᵢ ∈ ℝᴺ代表连接至第i个隐藏神经元的权重向量。隐藏层包含偏置项b(hidden)∈ ℝᴹ,MLP输出层权重表示为W(output)∈ ℝᴺ×ᴹ。
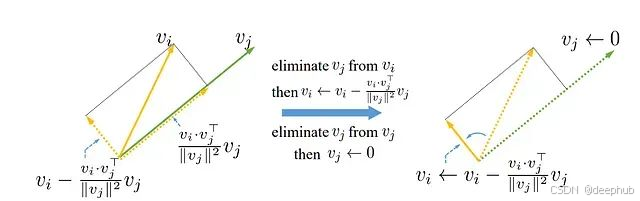
算法从集合{vi}i中移除神经元j对应的vj。通过Gram-Schmidt算法获得的具有最大ℓ2范数的神经元{vi}i在下一轮迭代中被选择。因此,下一个选择的神经元包含了前序神经元未能捕获的最大信息量。


基于知识蒸馏的性能恢复机制
多样性引导的MLP缩减技术在不显著改变模型整体架构的前提下实现对Transformer中大型MLP模块的有效剪枝。通过精心设计的神经元选择策略,剪枝后的模型保持了与原始完整模型相似的架构特征和权重分布模式。
基于这种结构和权重的相似性特征(即权重和结构亲和性),剪枝后的模型能够通过以原始模型为教师的学习过程有效恢复其损失的性能。这一被称为知识蒸馏的过程使得参数量显著减少的小型模型仍能恢复原始精度的绝大部分。
输入图像x同时输入教师模型T和学生模型S,获得最终Transformer块的输出表示:
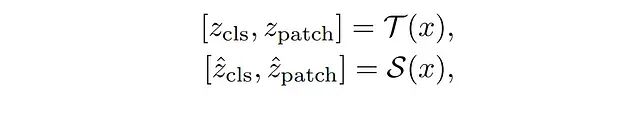
其中,z_cls ∈ ℝᶜ和z_patch ∈ ℝᴸ×ᶜ分别表示模型生成的特征向量。z_cls是类别令牌的表示,具有维度C;z_patch是所有补丁令牌的表示,组织为长度L的序列,每个元素具有维度C。
剪枝或蒸馏后的新表示ẑ_cls和ẑ_patch与原始表示保持相同的维度结构:ẑ_cls ∈ ℝᶜ,ẑ_patch ∈ ℝᴸ×ᶜ。这一设计确保了即使在剪枝操作后,特征尺寸与原始模型保持完全一致,从而保证了与网络其余部分的兼容性。
实验评估
实验配置
为协助剪枝模型恢复原始性能,研究在ImageNet-1K数据集上对模型进行知识蒸馏训练。该数据集不包含标签信息,仅占用于训练原始大型模型的LAION-2B数据集的约0.06%。所有用于蒸馏和评估的图像均被统一调整至224×224像素分辨率。
为全面验证方法有效性,研究在多个主流基准数据集上进行了测试。对于CLIP风格模型,在零样本图像分类任务上评估蒸馏后的视觉模型,采用的数据集包括ImageNet-1K验证集、ImageNet-V2、ImageNet-Adv、ImageNet-R、ImageNet-Sketch和ObjectNet,严格遵循CLIP基准测试协议。此外,在Flickr30K和COCO数据集上进行了零样本图像-文本检索任务的评估。
对于DINOv2-g等纯视觉模型,采用k近邻(kNN)评估协议在ImageNet-1K上测量性能。同时使用kNN协议对CLIP风格模型进行更全面的比较分析。为验证方法的通用适用性,将其应用于另一种Transformer架构Swin Transformer的监督图像分类任务(详细信息见附录)。
在剪枝阶段,将所有视觉Transformer模型的MLP模块压缩至目标扩展比r=1和r=2。当r=1时,MLP隐藏层尺寸与令牌维度尺寸相等;当r=2时,隐藏层尺寸为令牌维度的两倍。对于CLIP风格模型,仅对视觉Transformer部分进行压缩,文本编码器保持不变。
蒸馏训练在配备8×A6000 GPU的服务器上进行,训练周期为10个epoch,首个epoch用于学习率预热。采用AdamW优化器配合bfloat16精度,应用余弦学习率调度策略,学习率从lr = base_lr × batch_size / 256开始逐渐衰减至零。不同模型的具体基础学习率和批量大小参数详见补充材料。
OpenCLIP-g、OpenCLIP-G、EVA-CLIP-E和DINOv2-g等大型模型采用分布式数据并行(DDP)策略进行训练。对于超过60亿参数的模型(如InternVL-C和EVA-CLIP-8B),采用完全分片数据并行(FSDP)策略。所有模型均使用14的补丁尺寸进行嵌入处理。更详细的实现信息见附录部分。
零样本图像分类性能分析
为验证方法的有效性,研究通过设置MLP扩展比为r = 1和r = 2对最先进的CLIP风格模型进行压缩,并在多种ImageNet变体和ObjectNet数据集上评估其零样本图像分类性能。实验结果表明,压缩后的模型在平均零样本分类精度上始终与对应的原始模型保持可比性能,同时将参数数量和FLOPs均减少至原始模型的50%以下。此外,剪枝模型的图像处理吞吐量获得显著提升。
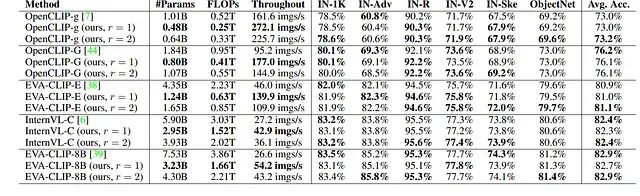
多种ImageNet变体和ObjectNet数据集上零样本图像分类任务的性能对比分析。
以EVA-CLIP-E模型为例,参数数量从43.5亿减少至12.4亿,实现71.5%的压缩率。相应地,FLOPs同样减少71.5%,EVA-CLIP-E(r = 1)的图像处理吞吐量相比原始模型实现3倍加速。当扩展比设置为r = 2时,剪枝后的EVA-CLIP-E在平均零样本分类精度上甚至超越原始模型0.2%。这些结果充分证明了本方法能够在零样本分类任务上实现大型视觉Transformer模型的近似无损压缩。
进一步的对比分析显示,剪枝后的OpenCLIP-G(r = 1)模型拥有8.0亿参数,在平均零样本精度上显著优于拥有10.1亿参数的OpenCLIP-g模型3.1%。剪枝后的EVA-CLIP-E(r = 1)模型拥有12.4亿参数,相比拥有18.4亿参数的OpenCLIP-G模型在性能上实现4.9%的大幅提升。总体而言,剪枝模型相比同等规模甚至更大规模的对比模型展现出更优越的性能表现,进一步验证了所提方法的有效性。
k近邻评估结果
为进行更全面的性能比较,研究进一步在ImageNet-1K纯视觉任务上评估剪枝后的视觉Transformer模型,采用kNN评估协议且不涉及文本编码器。实验结果显示,采用r = 1剪枝的模型实现了与对应原始模型相似的kNN精度。例如,剪枝后的OpenCLIP-g(r = 1)达到81.9%的kNN精度,较原始OpenCLIP-g模型提升0.2%。尽管参数量和FLOPs显著减少,r = 2设置下的剪枝模型始终优于原始模型。特别地,剪枝后的OpenCLIP-g(r = 1)相比原始模型展现出0.4%的kNN精度提升。
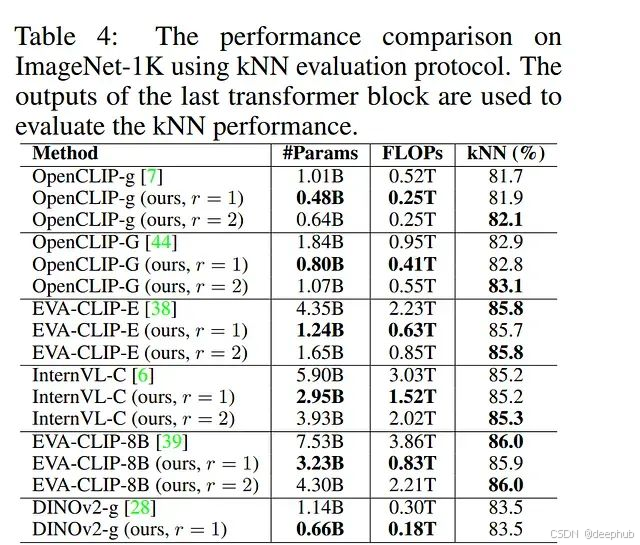
与参数规模相近的模型对比显示,本研究的剪枝模型展现出明显的性能优势。尽管参数量较少,拥有8.0亿参数的OpenCLIP-G(r = 1)在kNN精度上显著优于拥有10.1亿参数的OpenCLIP-g模型1.1%。同样,拥有12.4亿参数的EVA-CLIP-E(r = 1)在kNN精度上超越拥有18.4亿参数的OpenCLIP-G模型2.8%。为进一步验证方法的泛化能力,研究将其应用于纯视觉Transformer模型DINOv2-g。实验结果证实了本方法能够有效压缩大型视觉Transformer模型同时保持近似无损的性能水平。
MLP扩展比例影响分析
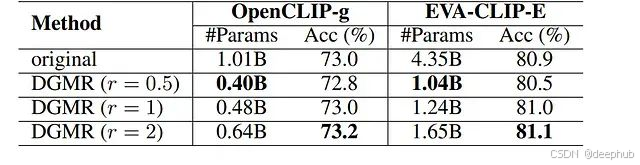
表5:MLP缩减比例对平均零样本分类精度的影响分析。"original"表示未经压缩的原始模型。
研究系统探索了不同MLP扩展比例对大型视觉Transformer压缩效果的影响。实验结果展示在表5中。采用DGMR方法以扩展比r = 1进行剪枝的OpenCLIP-g模型在五个ImageNet变体和ObjectNet数据集上实现了与原始OpenCLIP-g模型几乎相同的平均零样本分类精度,同时仅使用原始模型48.0%的参数量。当扩展比r增加至2时,剪枝模型在平均零样本精度上甚至超越原始OpenCLIP-g模型0.2%,参数使用量仍仅为64.0%。
研究还探索了r = 0.5的更小扩展比以实现更高的压缩率。实验结果显示,r = 0.5设置下的剪枝模型将参数数量减少60.0%,零样本分类精度仅从73.0%轻微下降至72.8%。相比r = 1的剪枝模型,该设置以0.2%精度下降为代价实现了额外8.0%的参数缩减。基于综合考虑,研究选择r = 1作为默认配置,以在显著压缩和良好性能恢复之间取得最佳平衡。
总结
本研究提出的方法主要针对参数密集型MLP模块的缩减优化,而注意力模块的压缩技术仍有待深入探索。在未来的研究工作中,计划将当前方法扩展至注意力模块的缩减,并适配于自然语言、音频和视频等其他模态的大规模Transformer模型。期望这一研究方向能够为实现跨领域大规模Transformer模型加速的更广泛目标做出重要贡献。
论文和源代码:
https://avoid.overfit.cn/post/a14cb35858d44dfa994c52fdb2c008c6
Devang Vashistha