脑电分析——EEGLAB的使用与代码的解读
脑电分析——EEGLAB的使用与代码的解读
- 一、eeglab在MATLAB中安装教程
- 1. 下载软件
- 2. 添加路径
- 二、eeglab中数据的预处理
- 1. 加载 .edf 文件
- 2. 通道定位
- 3. 删除错误、不用、坏的通道
- 4. 高通、低通滤波
- 5. 重参考
- 6. 降采样
- 7. 手动去伪迹
- 8. ICA
- 9. 手动去伪迹和自动去伪迹
- 10. 绘制频谱图
- 11. 导入自定义marker
- 12. 分段与基线校准
- 13. 添加插件
- 三、运行代码
- 1. 预处理
- 2. 特征提取
- 3. 分类
- 四、学习感受
一、eeglab在MATLAB中安装教程
1. 下载软件
由于群里发的eeglab的版本和以前下载的matlab版本好像不大匹配,所有去官网下载了另外的版本。
- 下载网址:
https://sccn.ucsd.edu/eeglab/download.php
- 填写信息,提交Submit
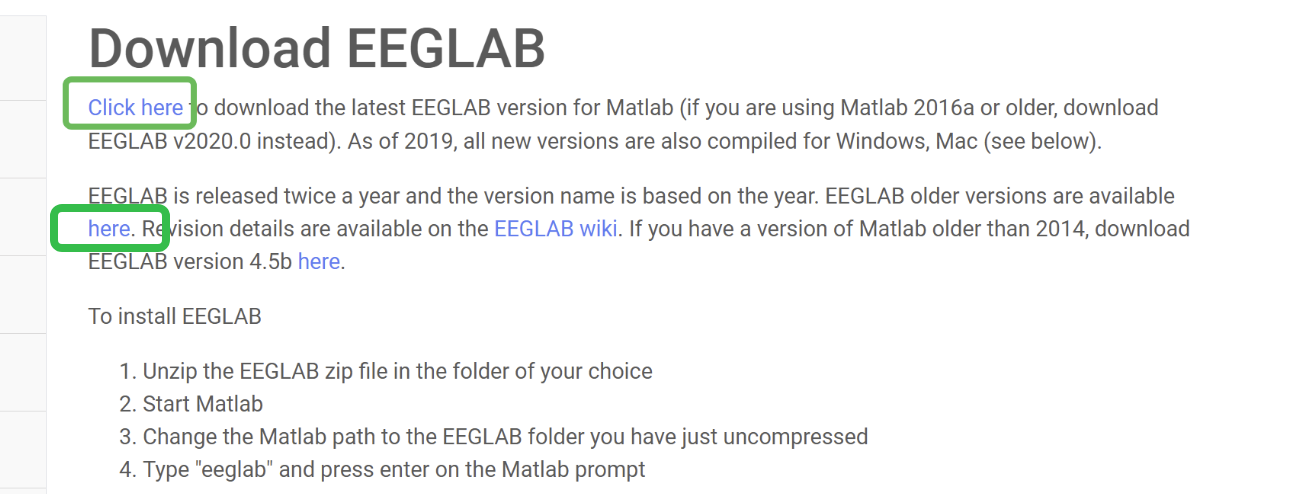
- 点击click here下载最新版本的EEGLAB,但我们一般不下载最新版本,旧版本可以通过here进行下载
- 下载好安装包后进行解压
2. 添加路径
下载好了EEGLAB,还需要记住其所在的路径,让Matlab知道EEGLAB工具包在哪里,从而方便开展后期工作。
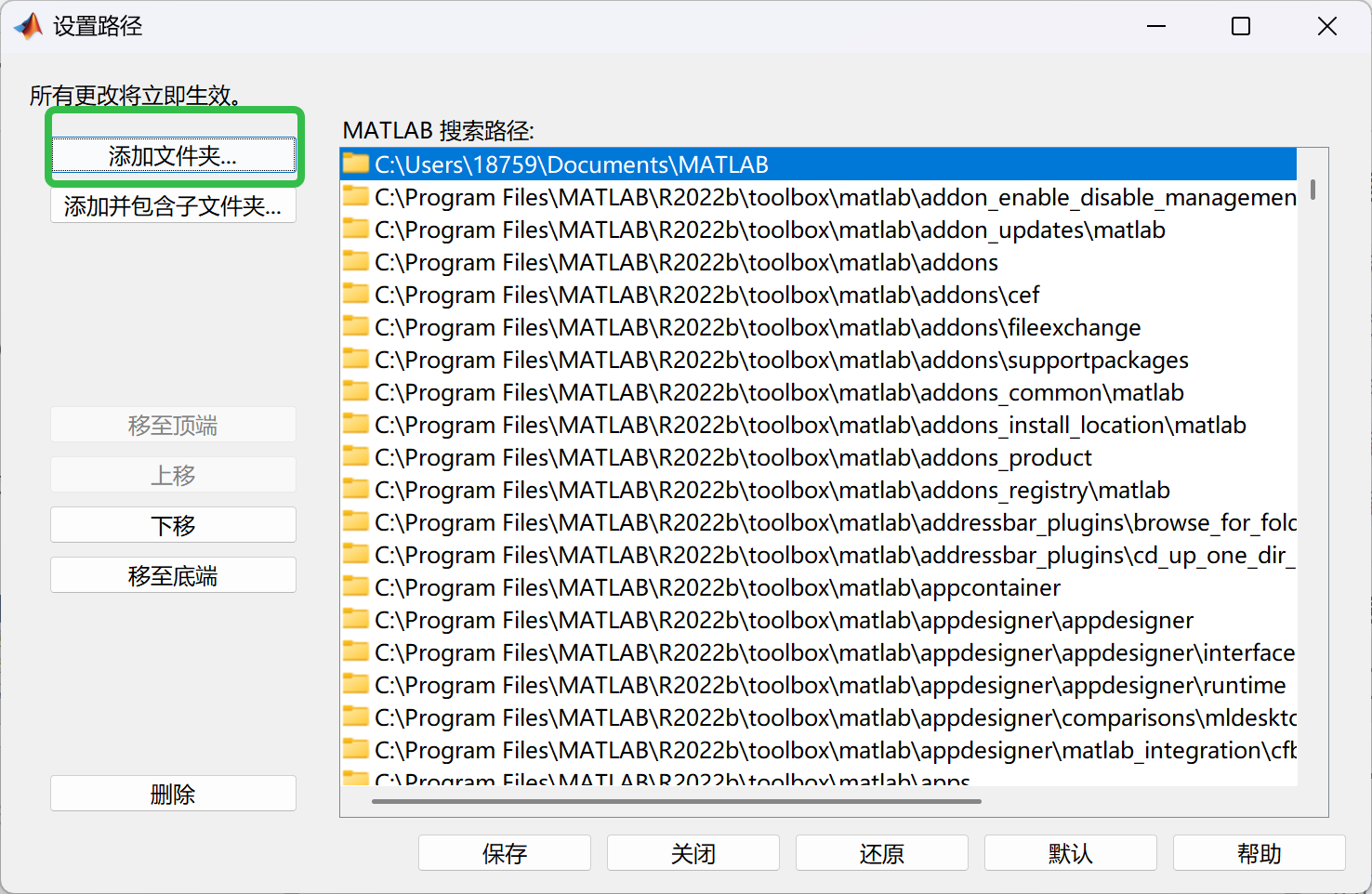
- 添加路径,选择Matlab菜单栏上面的Set Path(设置路径)

- 点击Add Folder(添加文件夹),不要点击Add with Subfolder(添加并保存子文件夹)
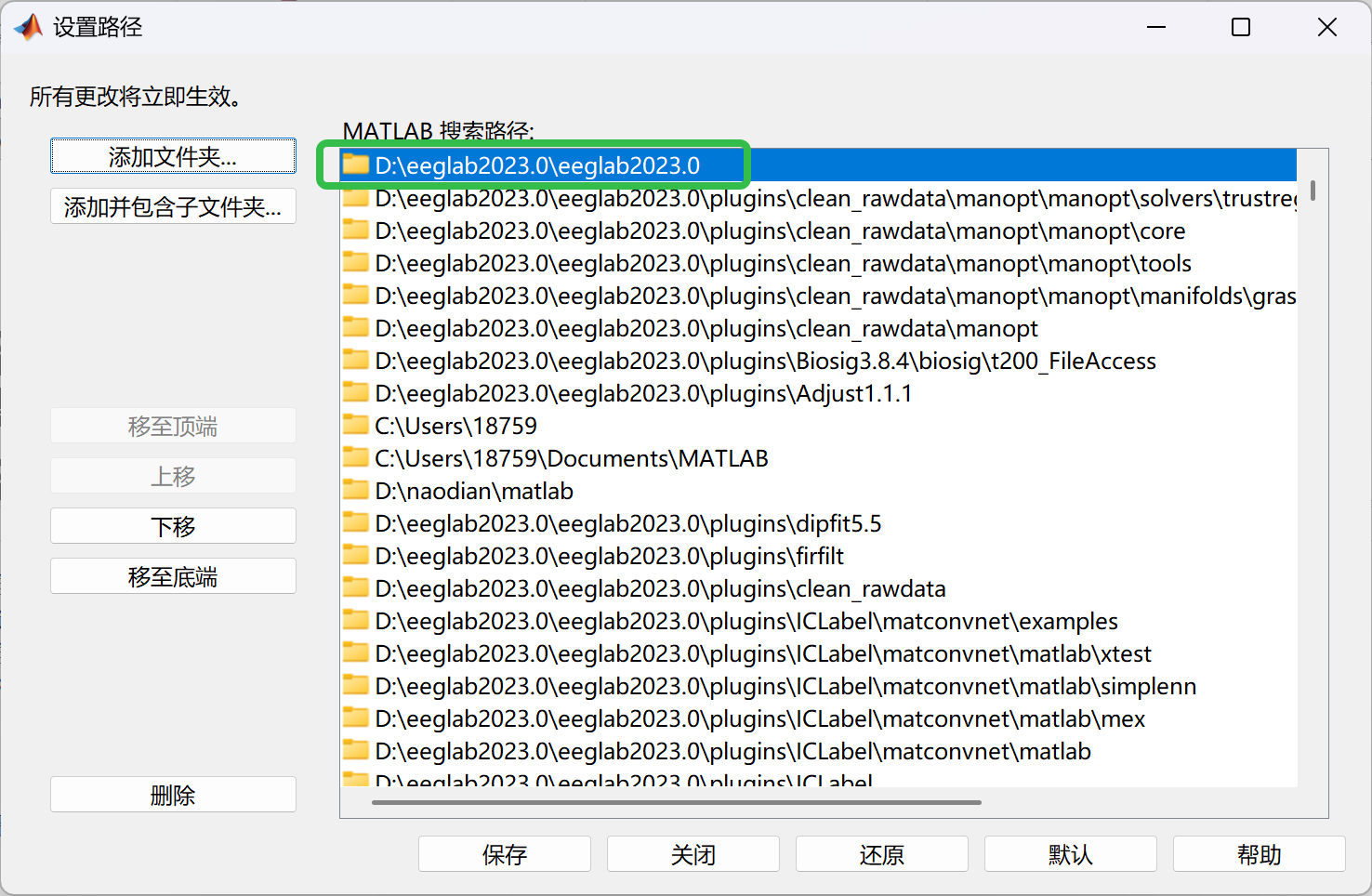
- 找到我们刚刚下载好并解压好的eeglab_current,选中eeglab2023.0,然后点下面的选择文件夹,并点击 save(保存)
- 点击 close(关闭)
- 在 Matlab 的 Command Window 输入 eeglab
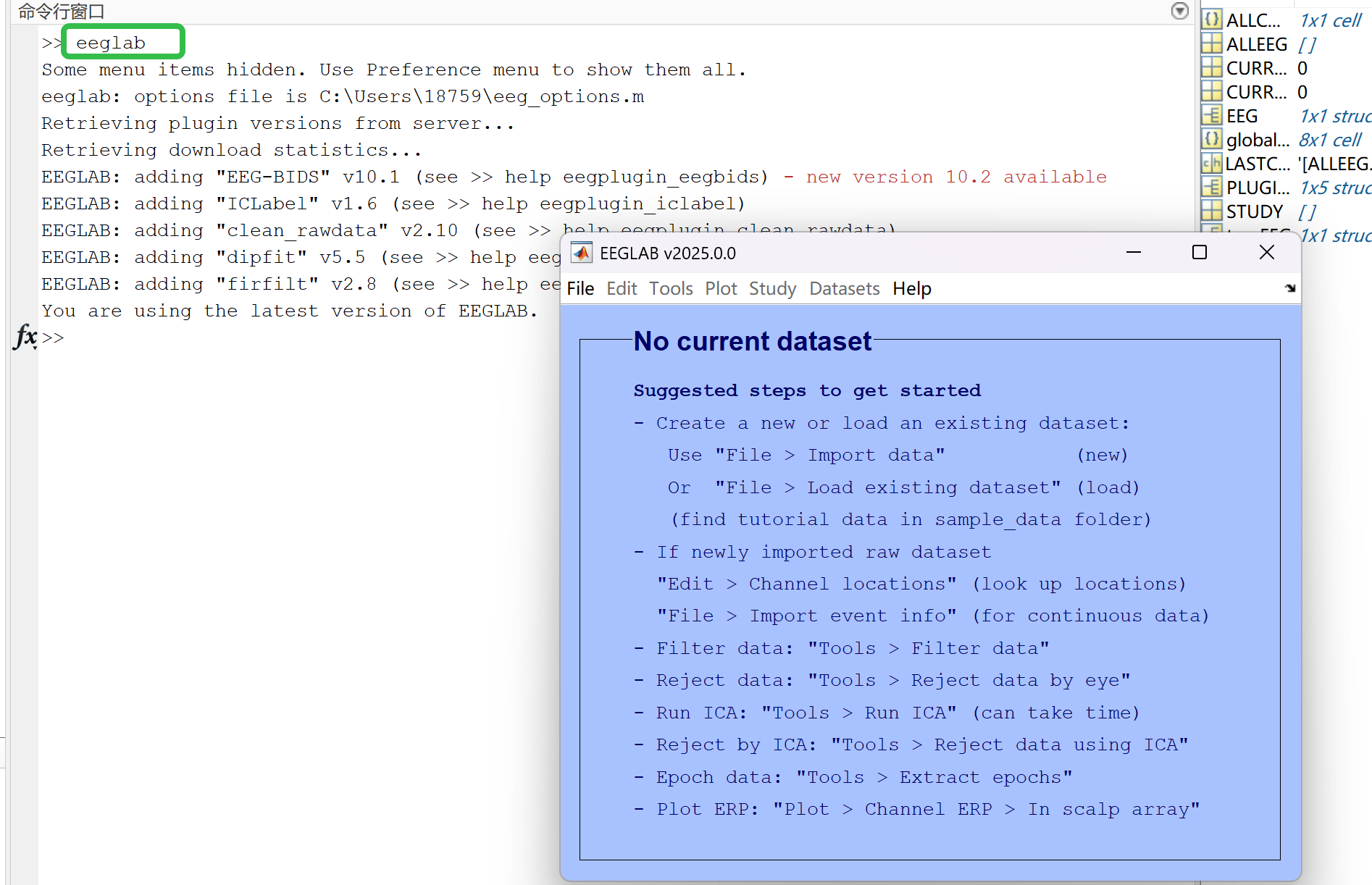
- 软件准备工作完成
以上是通过官网进行下载的方式。
注意:尽量不要下载高版本的 eeglab
二、eeglab中数据的预处理
以下是根据毕明川学姐的使用eeglab工具箱步骤进行的操作,选择其中一个edf文件进行处理。同时也参考博客链接: https://blog.csdn.net/2401_83174937/article/details/148266298
1. 加载 .edf 文件
- 常用脑电文件是 edf或者edf+ 比较常见
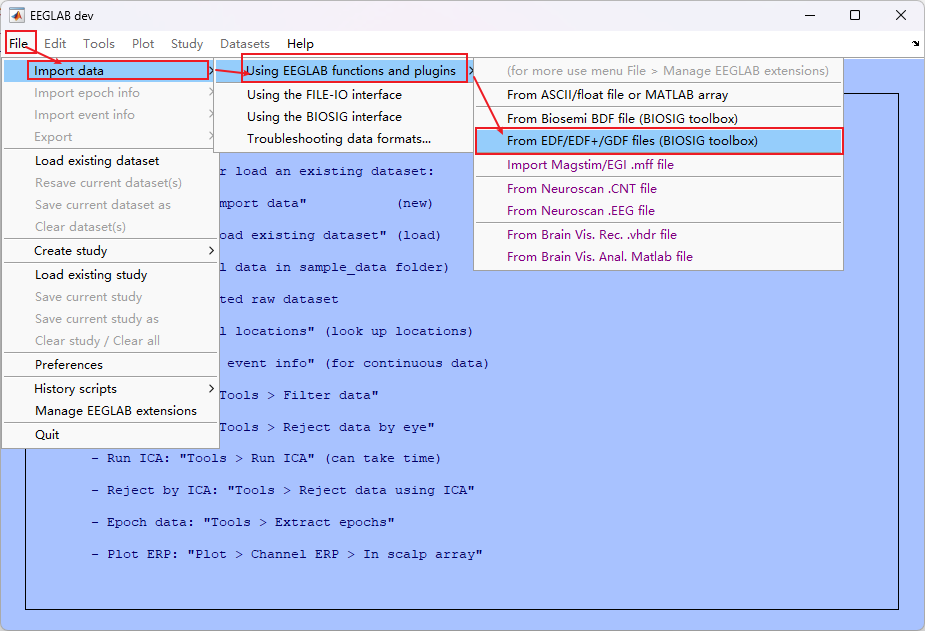
- 点击OK 就行
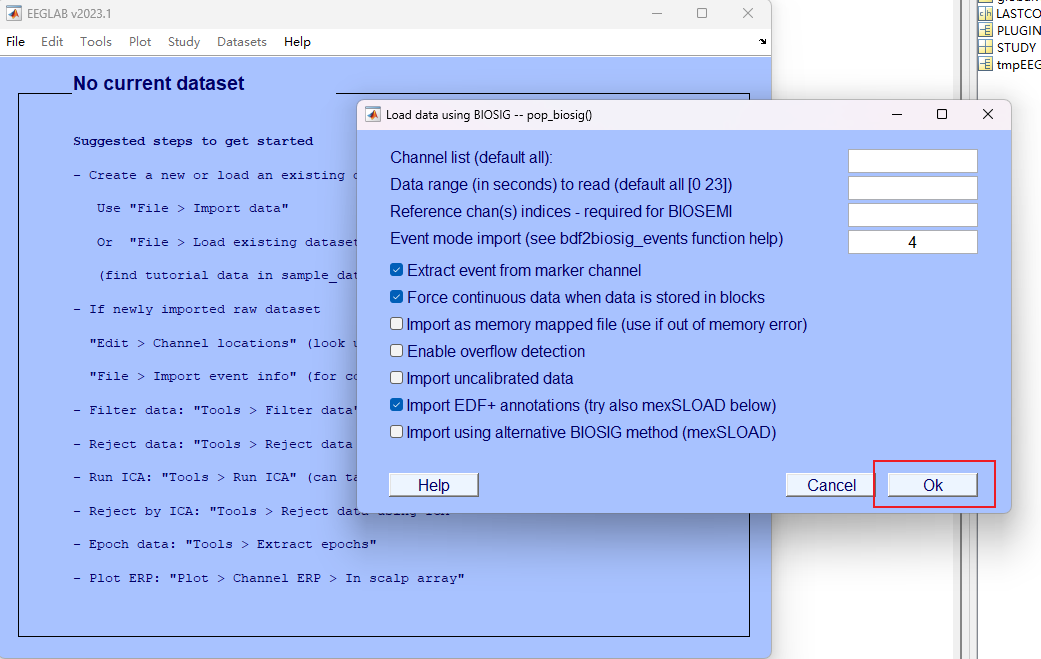
- 给文件取个昵称
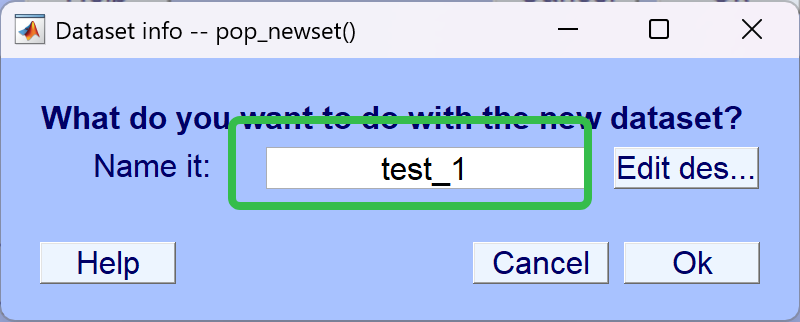
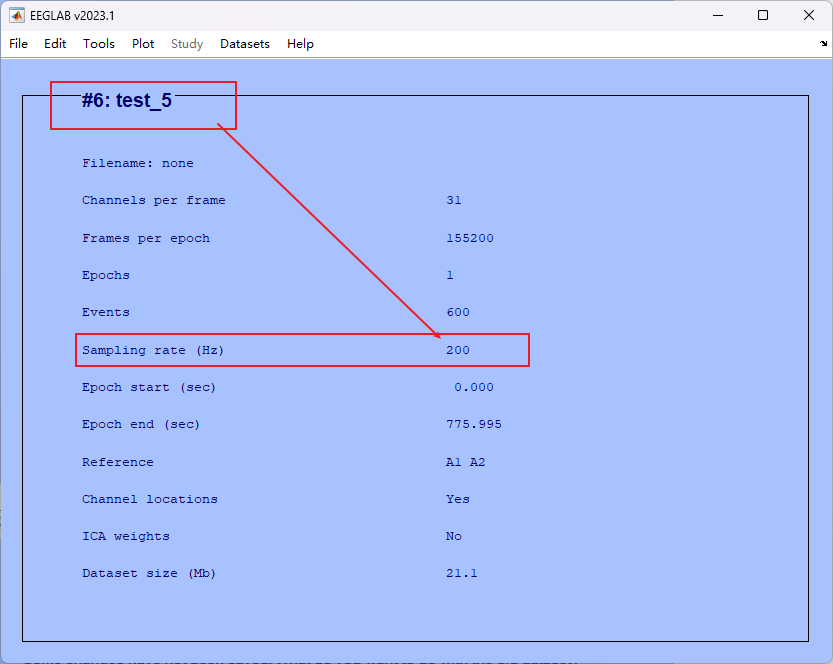
- 最终结果如图
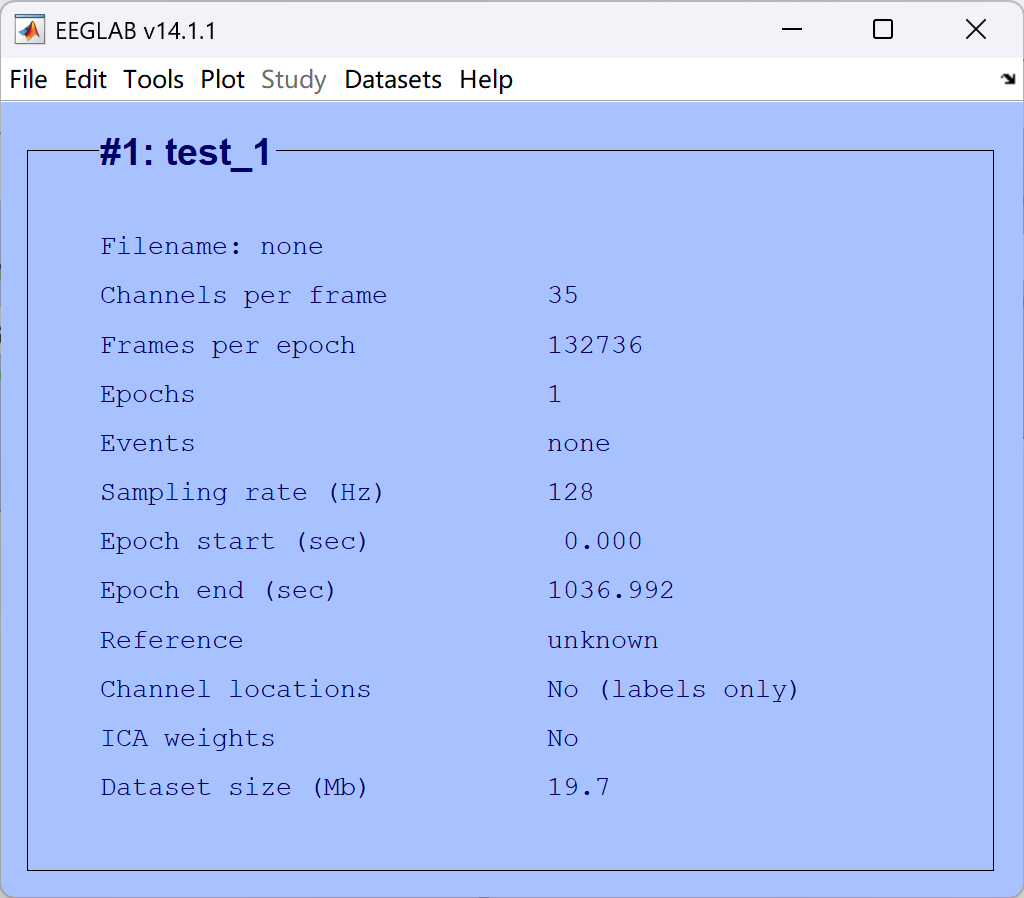
解释:
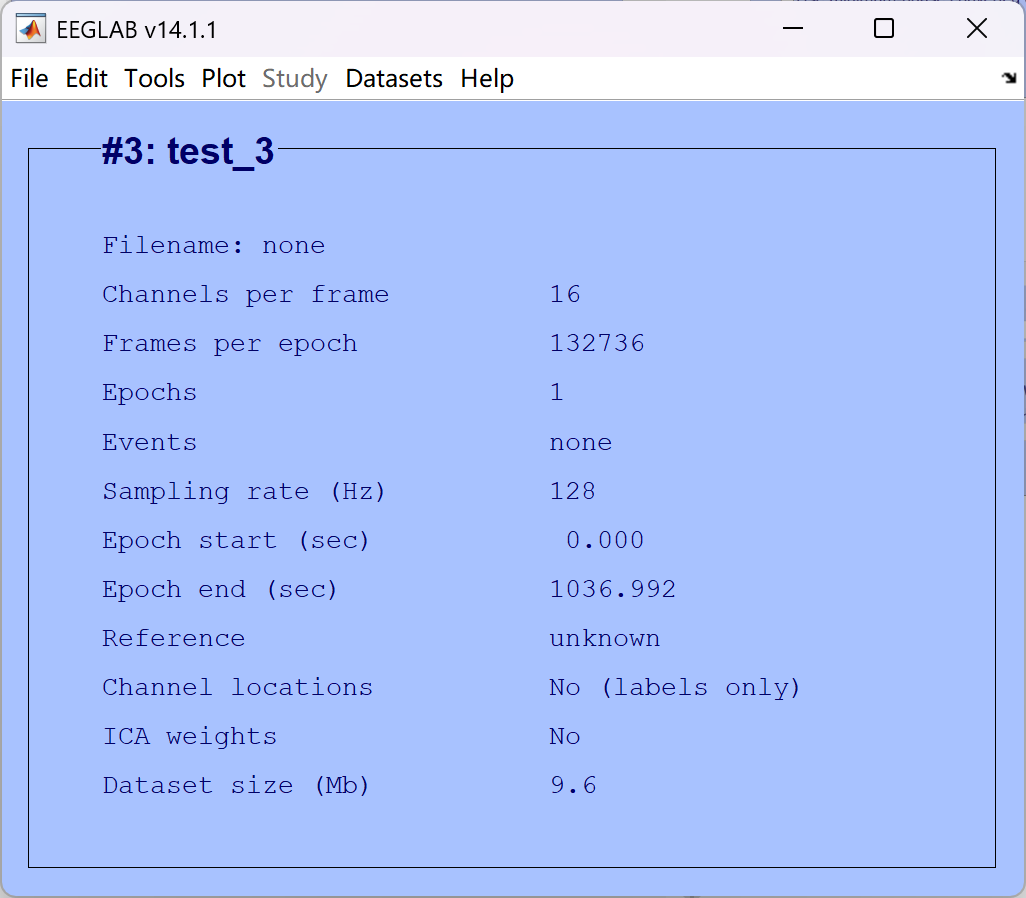
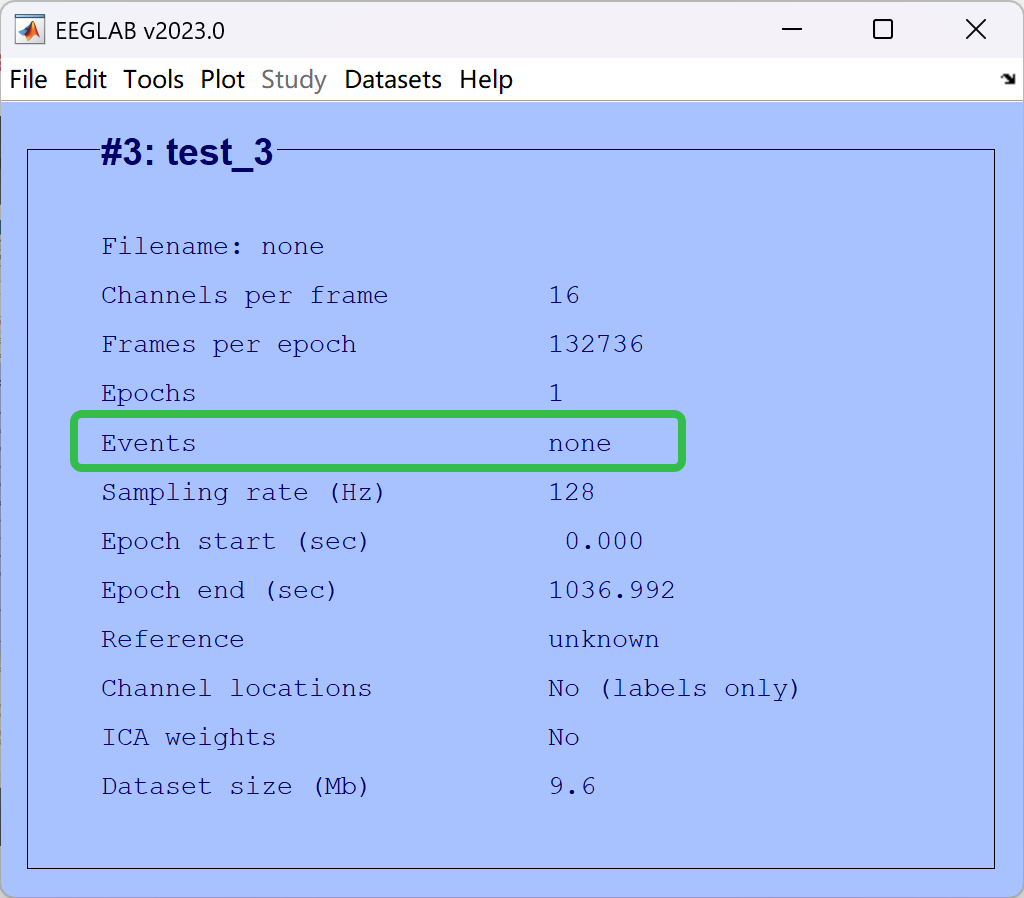
- test_1 所命名的名称
- Channels per frame 通道数量,反映脑电采集的电极通道数
- Epochs 分段数量(当前没分段所以为1段)
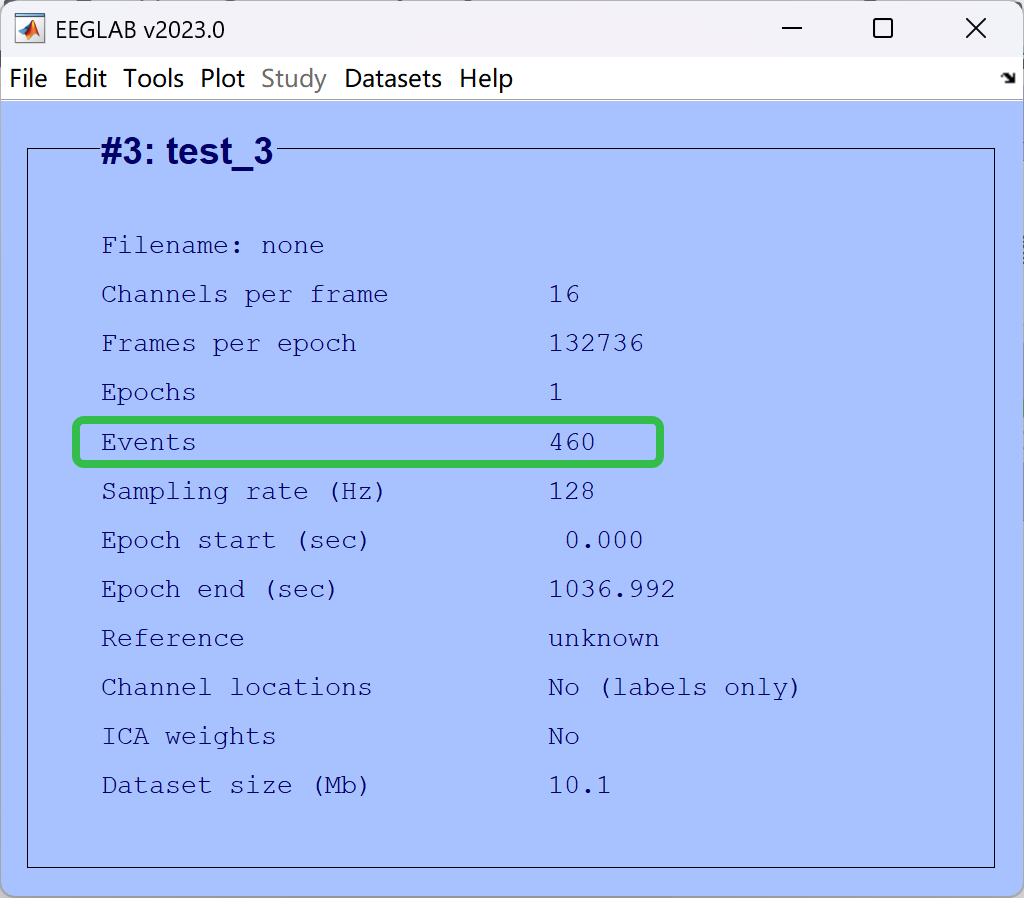
- Events mark数量(有时候无法识别到,需要手动导入)
- Sampling rate (HZ) 当前频率,即每秒采集 128 个数据点
- Reference 当前参考点
- Channel locations 通道定位(当前没定位)
- ICA weights ICA(当前没有执行ICA)
- Dataset size(Mb) 当前数据集的大小
- 查看图像
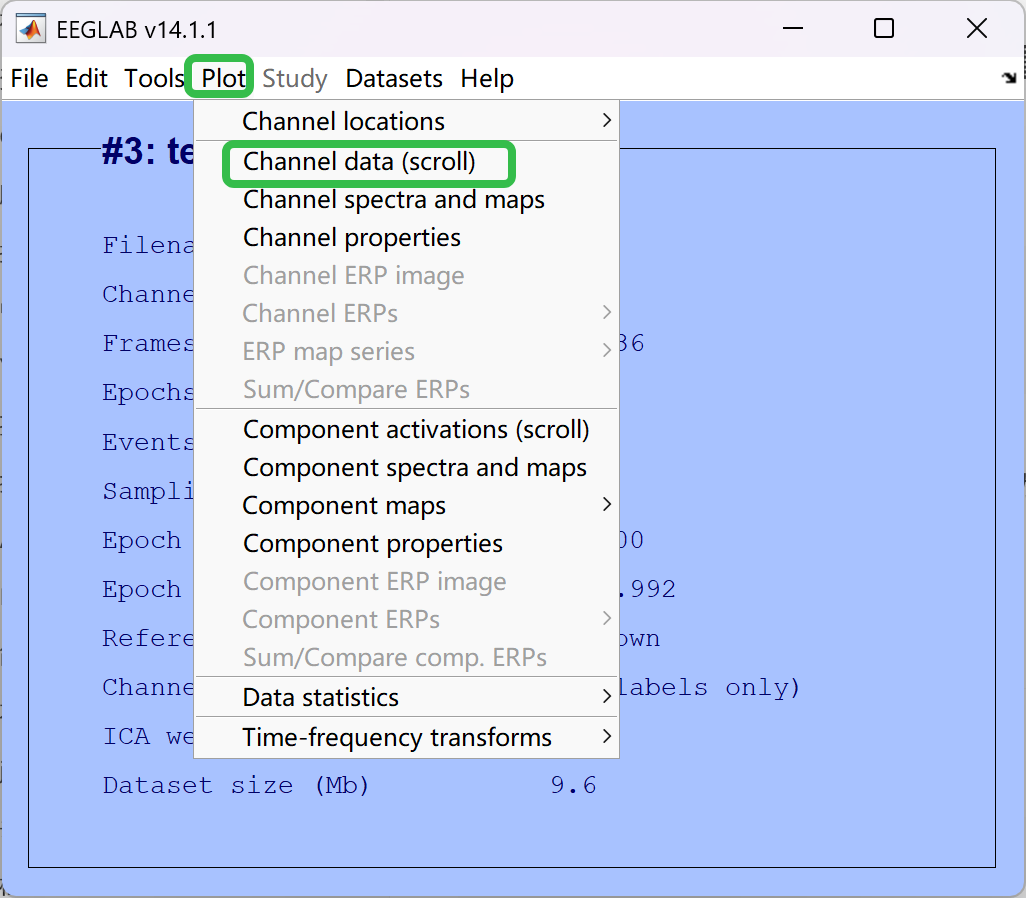
2. 通道定位
- 定位通道
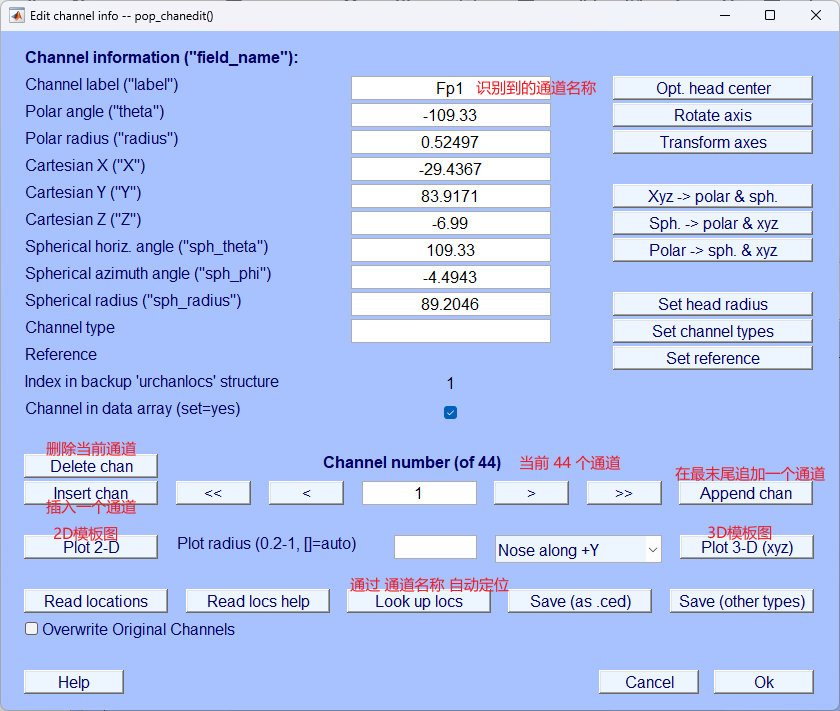
通过该页面我们要查看 错误、不用、坏 通道,注意是查看不是删除
- 点击 Plot 2-D 即可查看 2D 图像
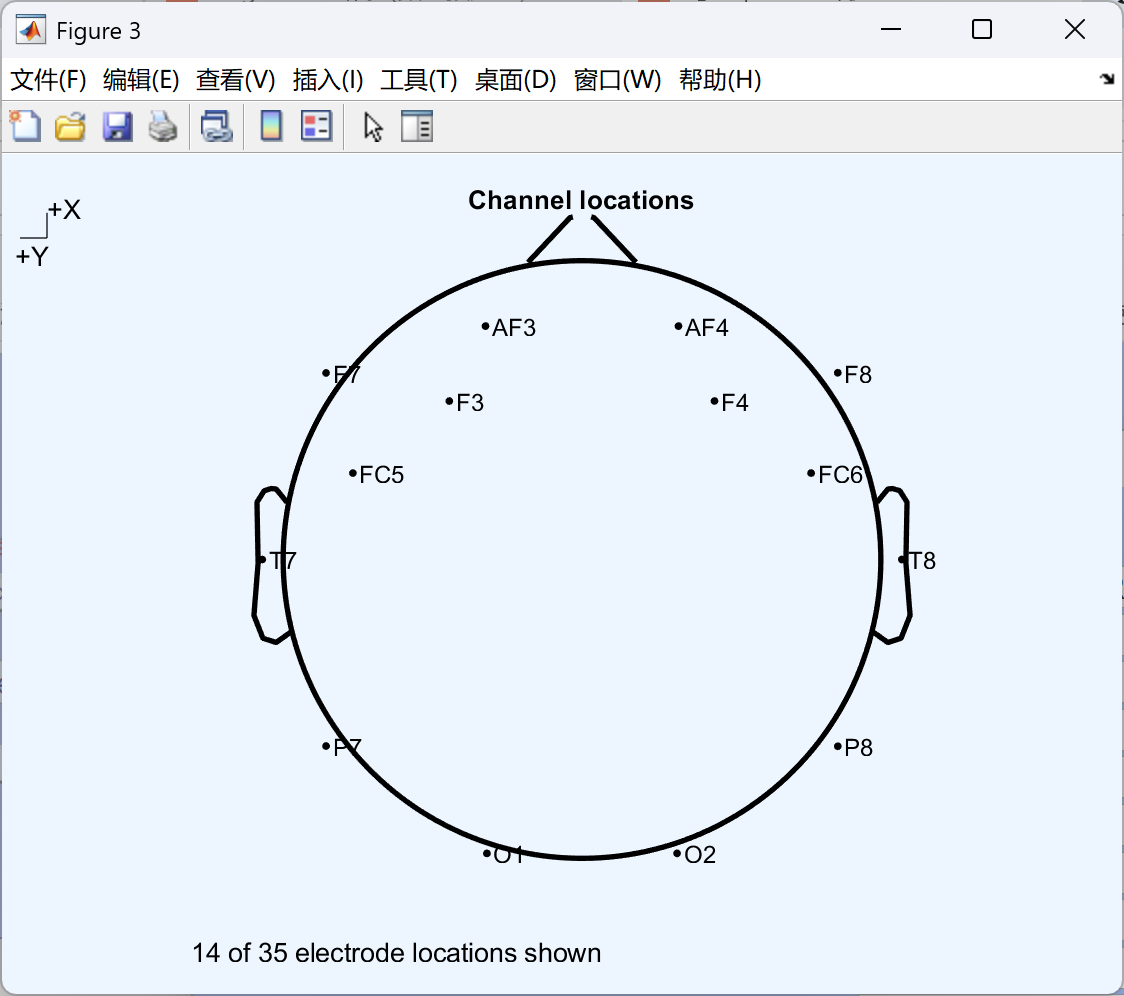
3. 删除错误、不用、坏的通道
- 选择我们要删除的通道名称,并点击OK
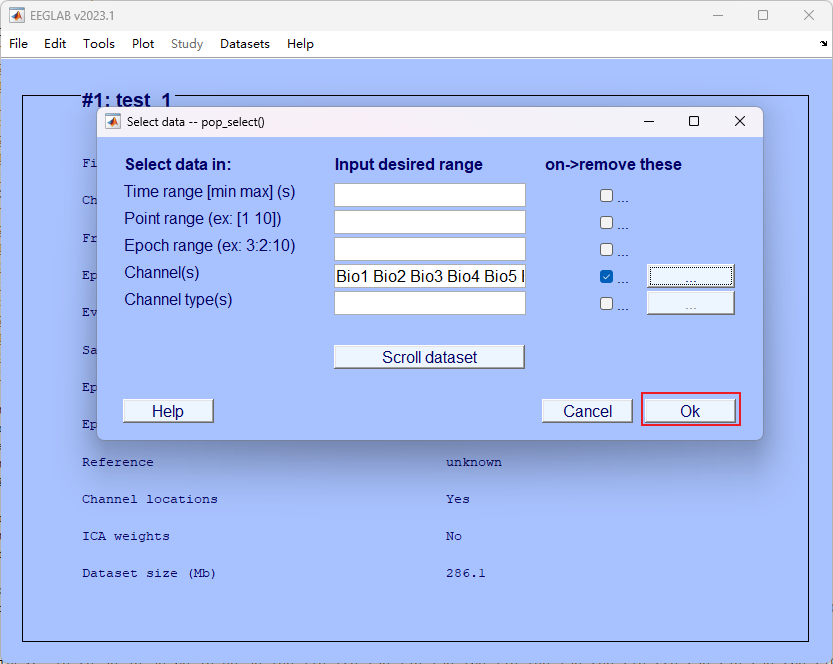
- 将这步结果从命名为即可
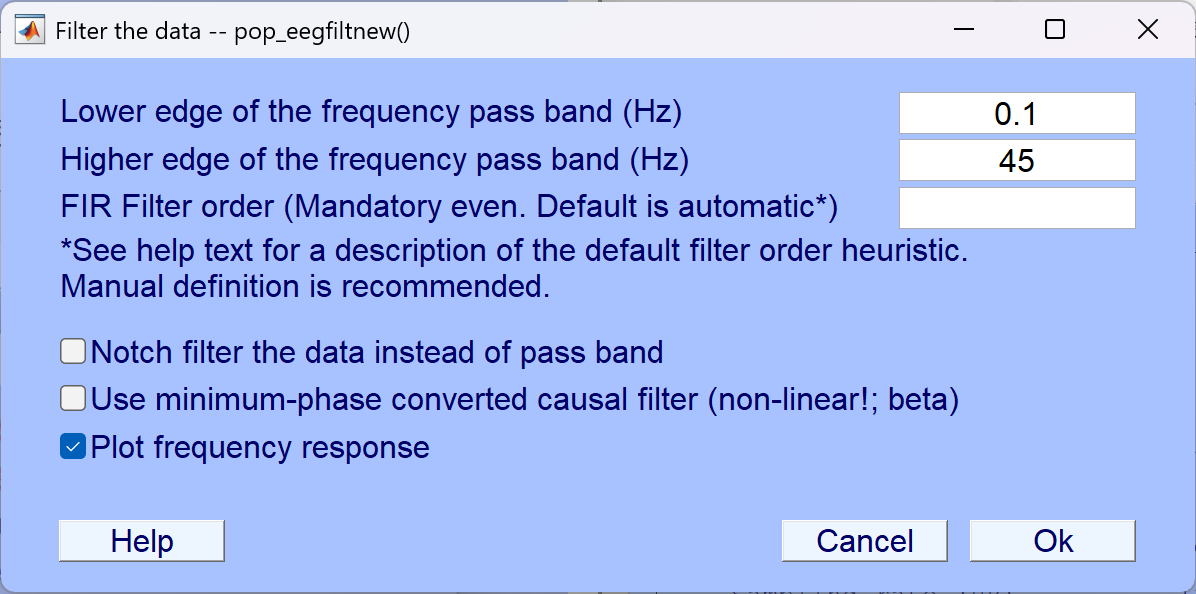
4. 高通、低通滤波
高通滤波
作用:去除低频滤波(包括头动伪迹、漂移、皮肤色反应)、电极松动引起的慢波干扰等。
常用的截至频率:
| 截至频率 | 场景 |
|---|---|
| 0.1HZ | 保留更多慢波成分(如delta) |
| 0.5HZ | 通常推荐,兼顾去噪与信息保留 |
| 1HZ | 对 ICA 非常有效,常用于 ICA 前预处理(但会丢失慢波) |
低通滤波
作用:取除高频噪声(如肌电干扰、电源干扰、头皮肌肉抖动);保留脑电中低频波段(如Alpha、Theta等)
常见截至频率
| 截至频率 | 场景 |
|---|---|
| 30HZ | 常见的认知 ERP 分析(如N400,P300) |
| 45-50HZ | 留下一些高频但过滤肌电 |
| 100HZ | 保留高频段(如gamma)分析时使用 |
注意:低通滤波太低会去掉gamma波段(30+HZ以上)
- 按如下步骤点击
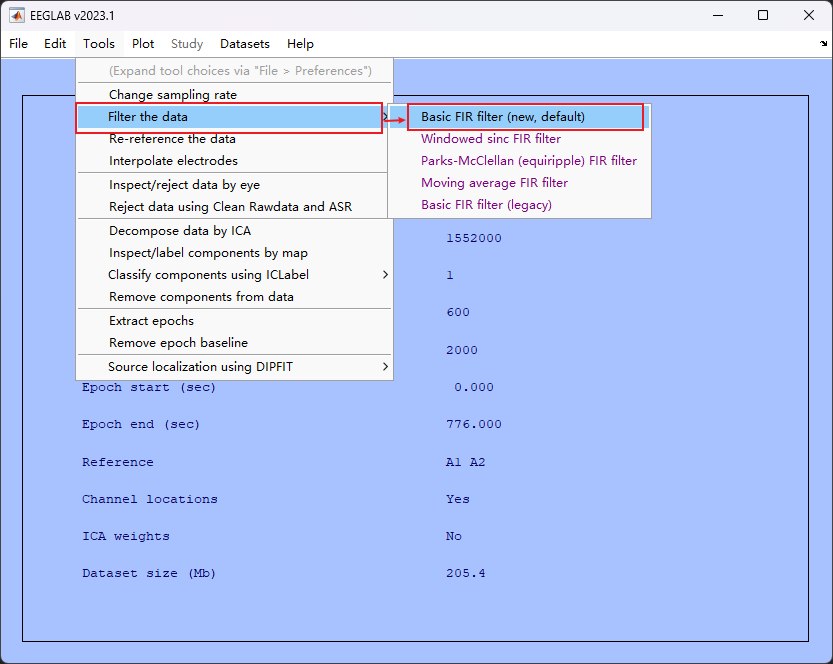
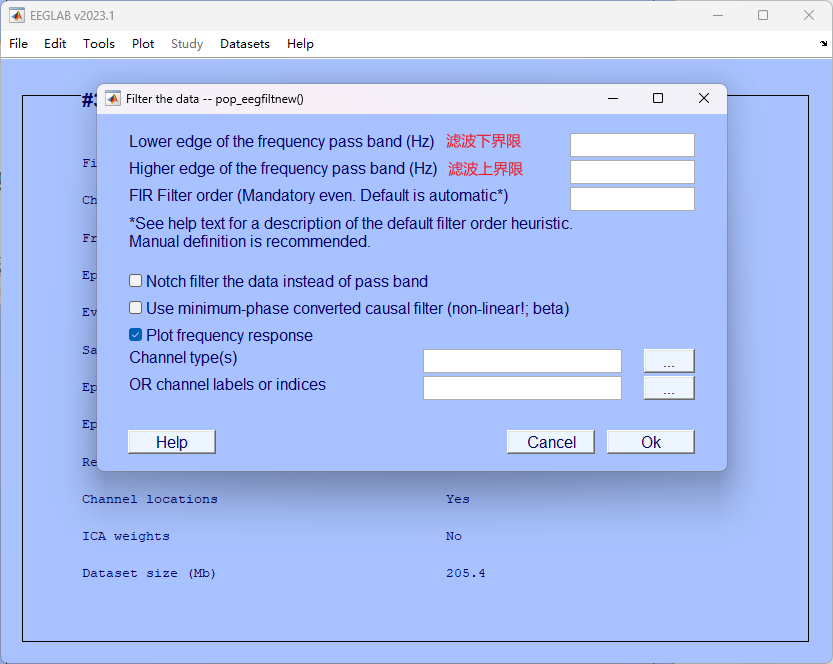
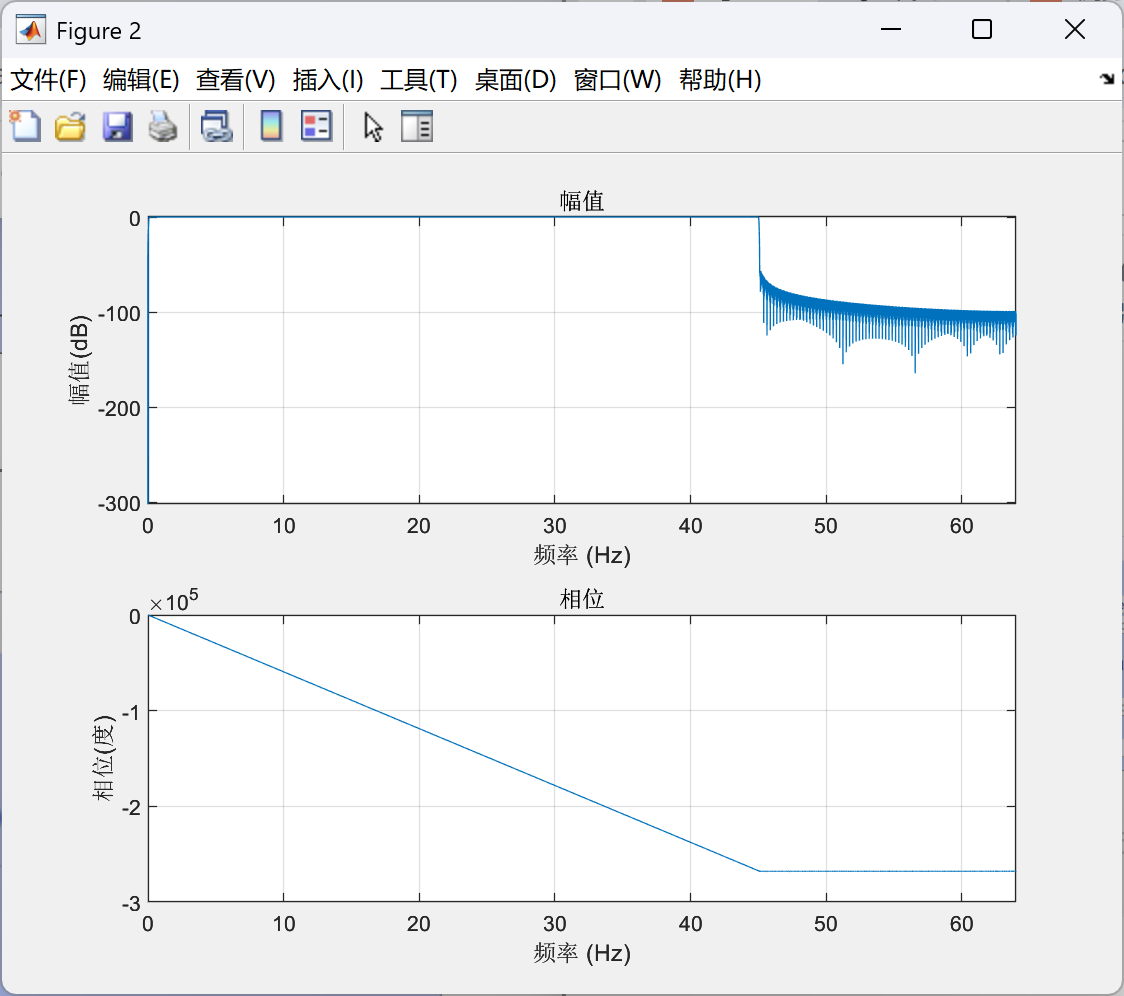
- 另取一个名字(如test_3即可)
5. 重参考
重参考的目的
选择一个更合适的参考电极或参考方式,使得EEG信号更加稳定、真实、易于解读。
什么是参考电极
EEG记录的是电压差,而不是绝对电压。
每一个电极的值 = 当前电极电压 − 参考电极电压
所以选择哪个参考,就决定了看到的 EEG 波形的 “基准线”
常见的参考有:
- 单一参考(如耳垂 A1、鼻尖 N)
- 平均参考(平均所有电极)
- 特定区域参考(如 mastoid、Cz)
- REST参考(参考电极标准化技术)
为什么要在 EEGLAB 中进行重参考
EEG 数据导入时,参考电极可能不是最理想的,因此需要重新设置参考以优化信号质量。
主要目的:
| 目的 | 解释 |
|---|---|
| 减少参考电极噪声 | 原始参考电极可能受肌电、运动等干扰,影响所有通道 |
| 平衡空间信息 | 平均参考可以让所有通道更平衡地表示大脑活动 |
| 提高 ICA 分离效果 | ICA 假设信号为“均值为零”,重参考(如平均参考)有助于符合这个假设 |
| 提高特定成分可见性 | 比如用 mastoid 参考更容易观察 P300,鼻尖参考更适合看前额成分 |
常见的参考方式
| 类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 单电极参考 | 如 A1、Cz、鼻尖 | 实现简单,部分 ERP 传统 | 可能受该点噪声影响 |
| 平均参考 | 所有电机平均 | 公认的“中性”参考 | 对电极数量少不稳定(<32) |
| Linked Mastoid | A1和A2平均 | 用于 ERP,较安静区域 | 偶尔不稳定 |
| REST | 模拟理论零参考 | 最科学(数学上) | 实现复杂,需插件 |
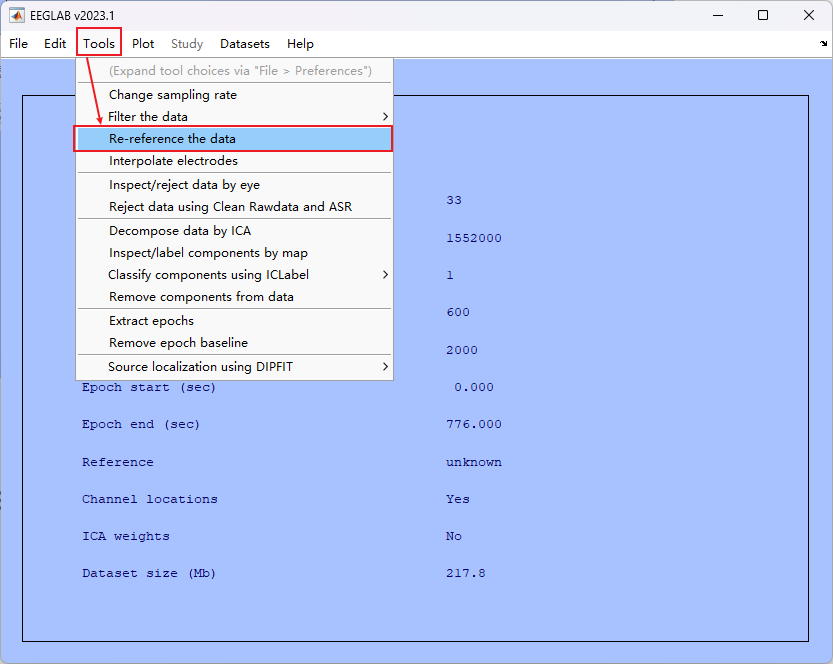
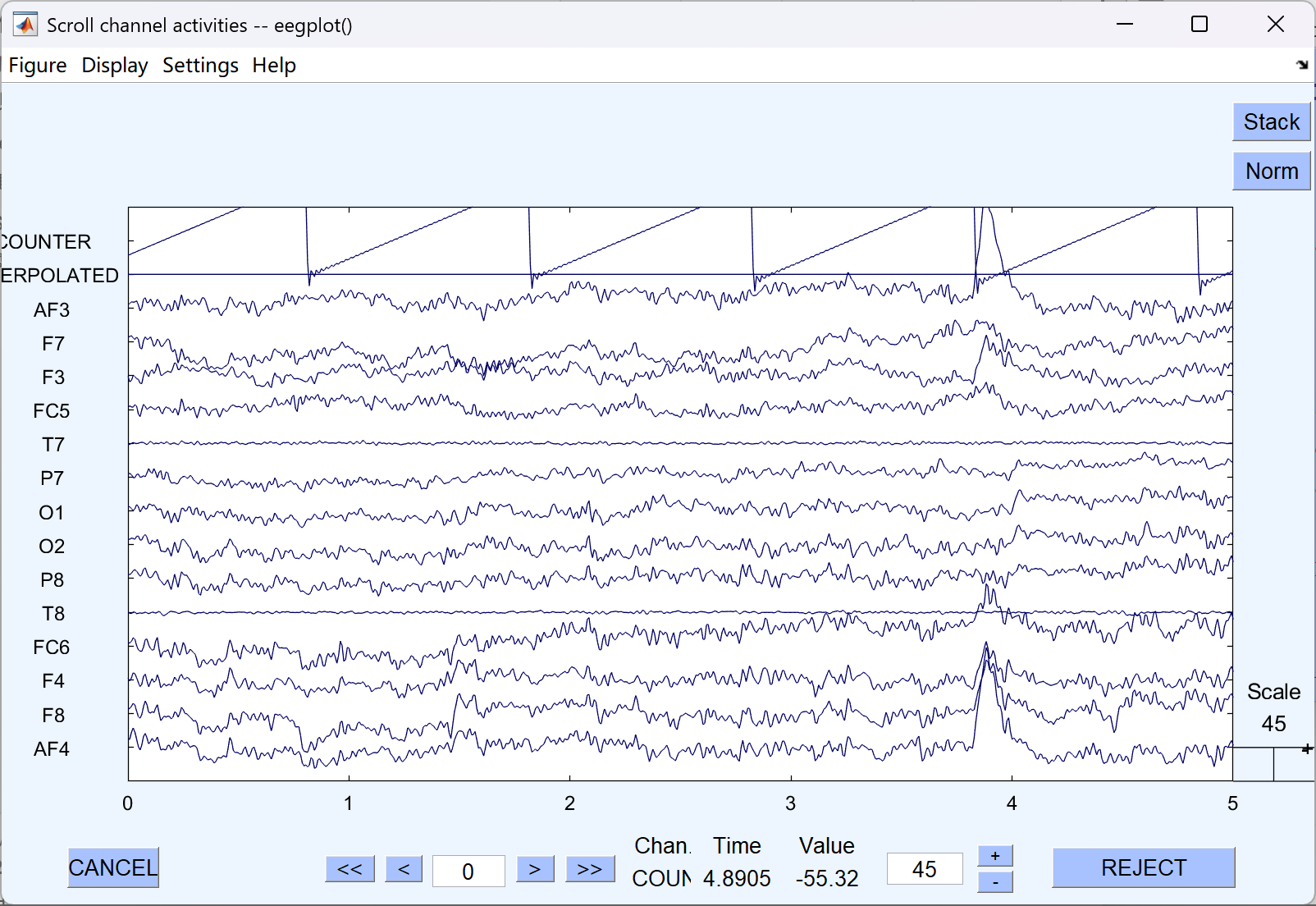
- 我们选择参考特定通道中的 T7 与 T8
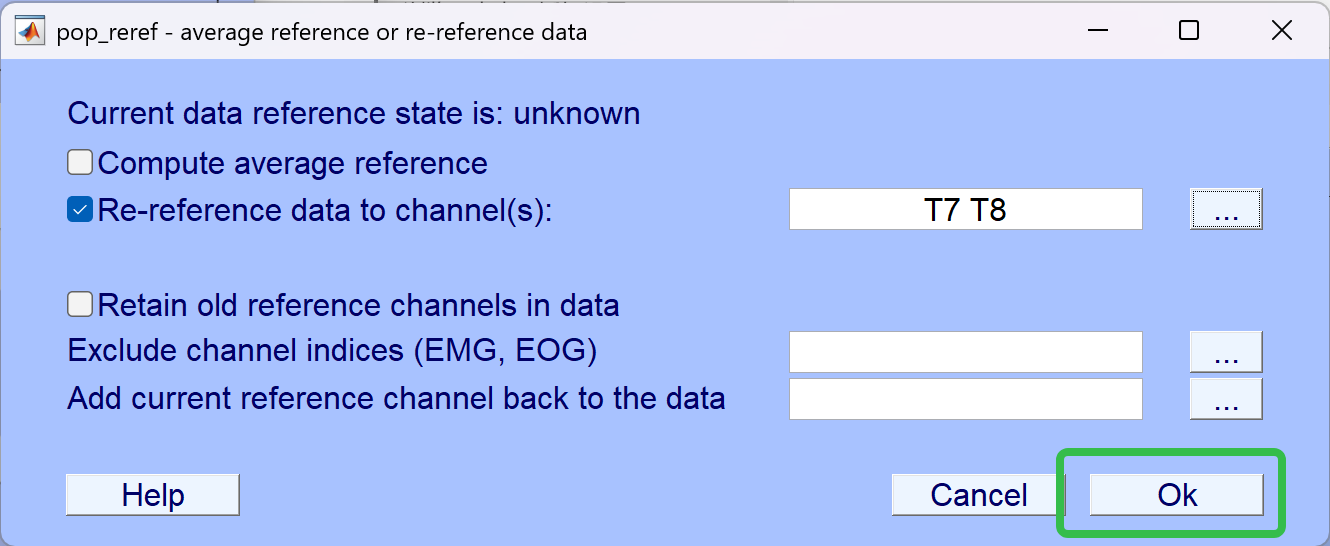
- 重命名(如命名为test_4)
- 重参考前
- 重参考后
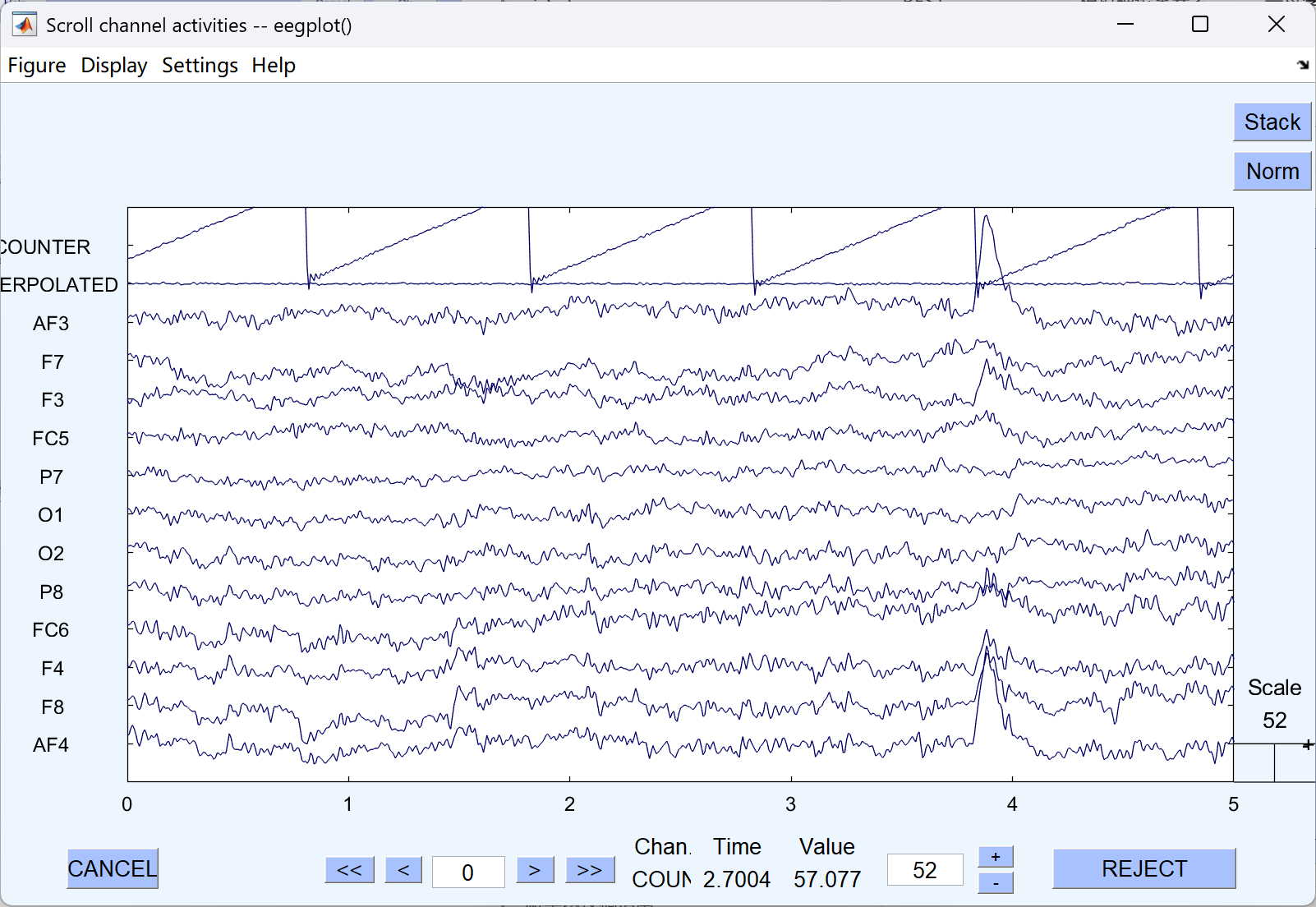
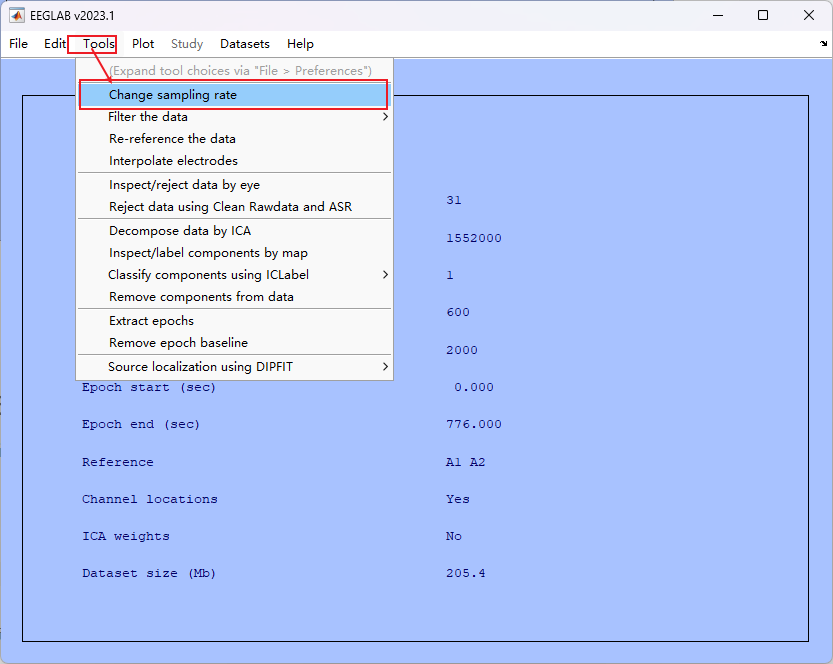
6. 降采样
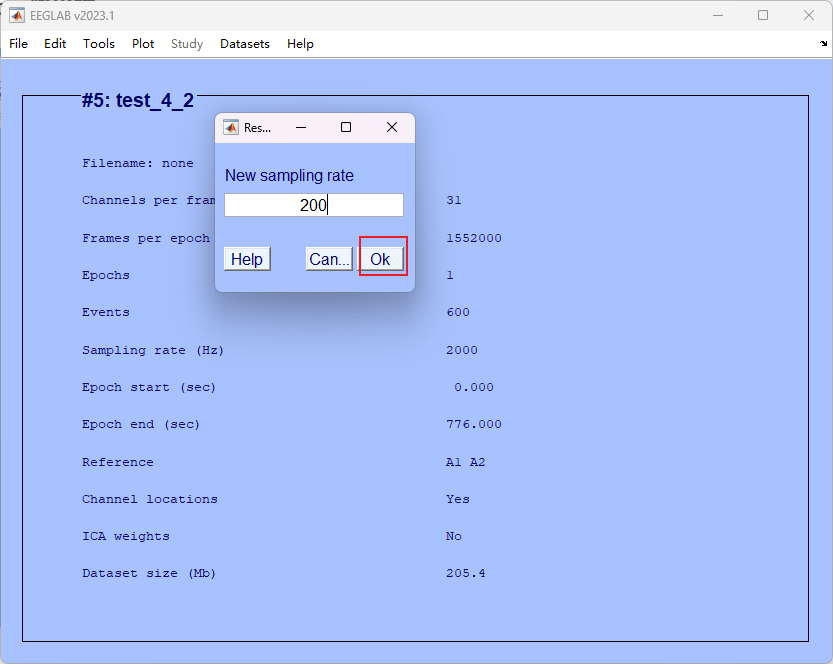
- 如果采样率过大,可通过一下方法降低采样点(通常选择 200-250 个采样点)
- 选用200Hz,取名点击OK即可完成
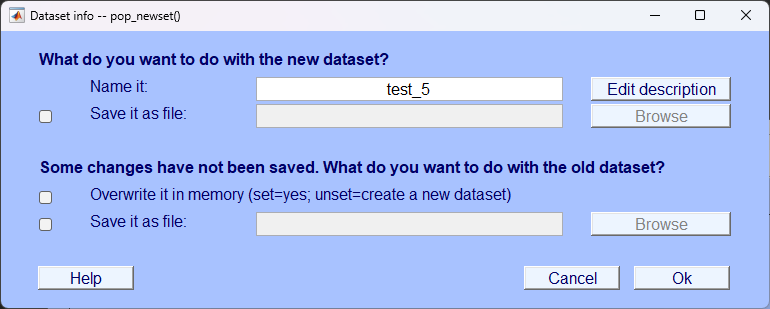
7. 手动去伪迹
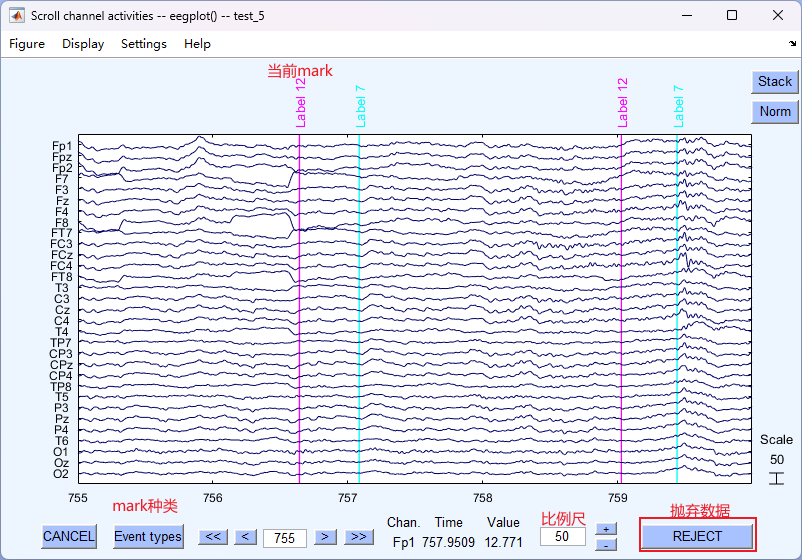
- 鼠标左键点击拖动,选张要删除的数据,点击 REJECT 即可
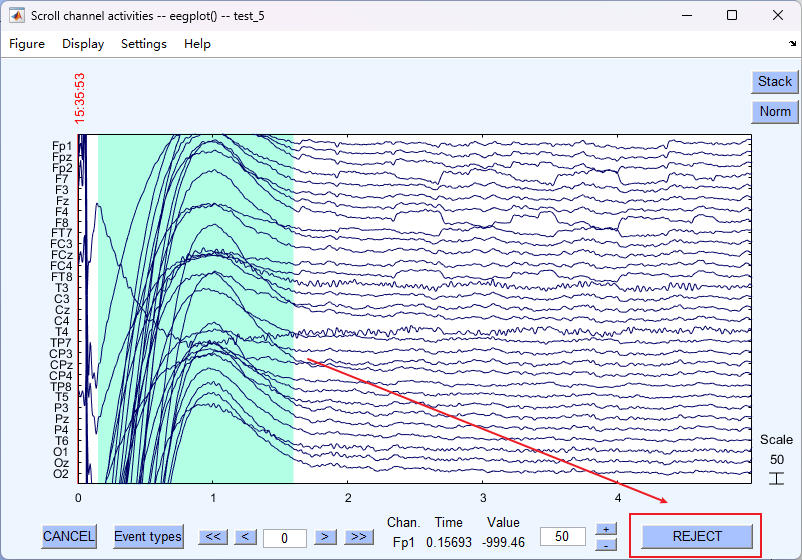
- 重新取名即可
8. ICA
什么是PCA
概念:PCA 是一种线性降维技术,它通过寻找数据中方差最大的方向来将高维数据映射到低维空间。这些方向被称为 “主成分” ,每个主成分彼此正交(不相关)。
目的:找出最能表示数据变异性的方向,用较少的维度来表示原始数据。
关键特征:
- 主成分之间是不相关的
- 是一种基于协方差矩阵的二阶统计方法
- 常用于数据压缩、噪声过滤和可视化
- 并不强调信号的独立性或物理含义
什么是ICA
概念:ICA 是一种将混合信号分离为统计独立的源信号的算法。在EEG中,观测到的电极信号通常是多个信号源(大脑活动、眼电、肌电等)的混合,ICA 能够从中提取出具有独立统计特性的成分。
目的:通过最大化成分之间的统计独立性,实现盲源分离(BSS)。
关键特征:
- 成分之间是统计独立的
- 使用的是高阶统计量(如峰度、偏度)
- 常用于伪迹取除,如眼动(EOG)、肌肉(EMG)、心电(ECG)等
- 得到的独立成分可以有明确的生理意义
PCA与ICA的区别
举例:
假设有一个 EEG 信号数据,是多个源信号的混合,比如:
EEG观测信号 = 大脑活动 + 眼动伪迹 + 肌电伪迹
- PCA:能提取主方向,但不能区分这些来源。主成分可能仍然混合了大脑和眼动。
- ICA:可以尝试将这些来源分离开来,你可以单独拿掉 “眼动” 成分。
- 点击OK即可
- 开始ICA,这时候不能点击Interrupt,需要静静等待 ICA 结束
- ICA 跑完自己结束
- 保存ICA之后的结果,结果为一个 .set 文件
9. 手动去伪迹和自动去伪迹
基于跑完的ICA我们要开始去伪迹。eeglab 给我们提供了自动去除伪迹与手动去除伪迹两种方法。
方法一:手动去伪迹
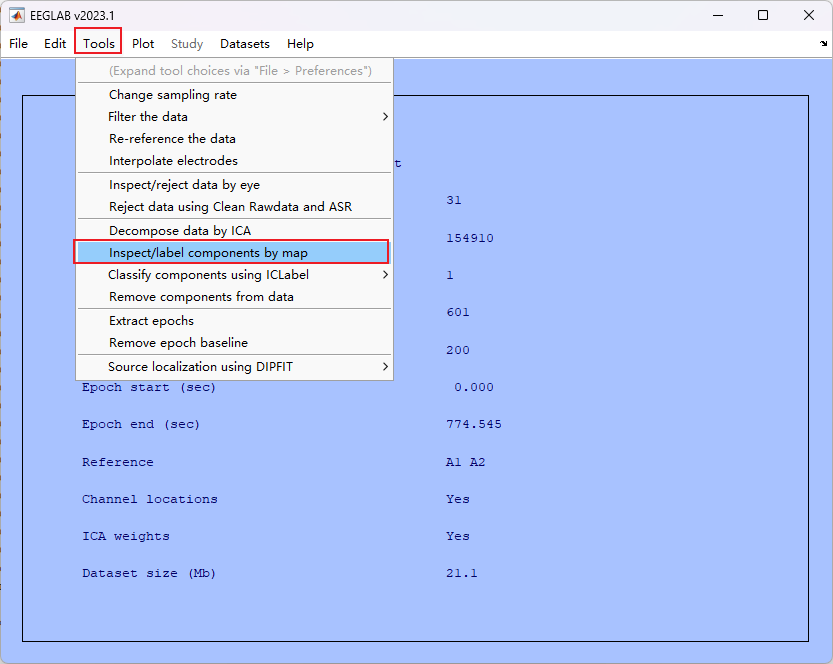
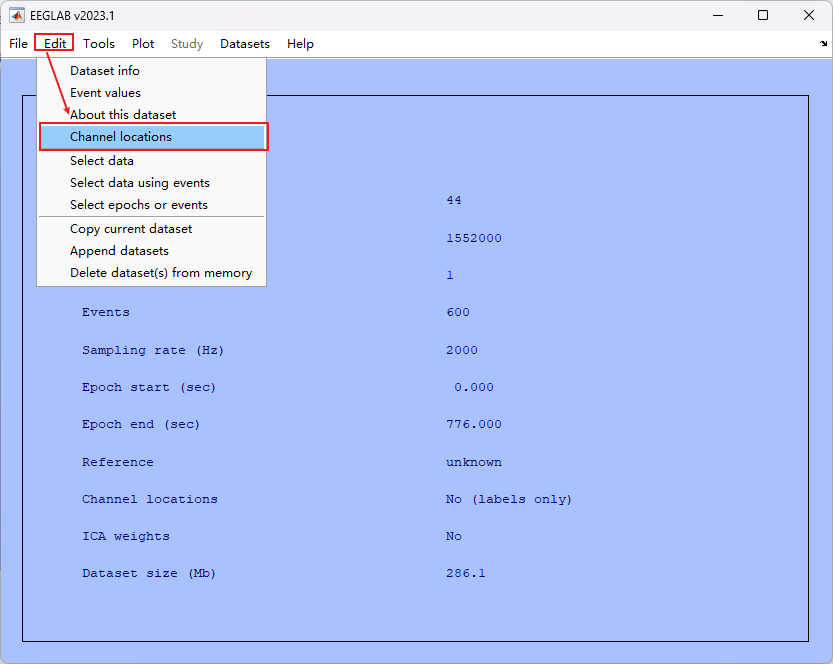
- 在这一步骤中出现了加载的 EEG 数据没有附带通道空间位置信息的问题
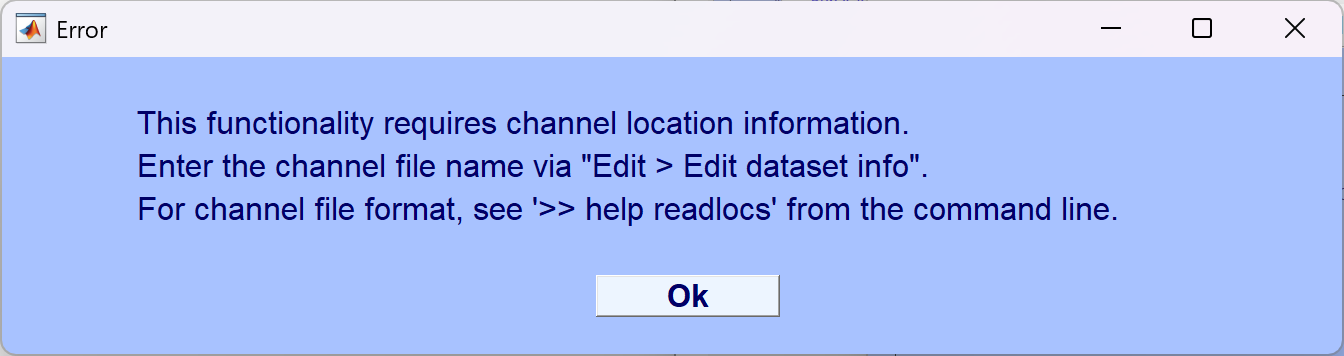
- 解决方法:增加通道位置信息
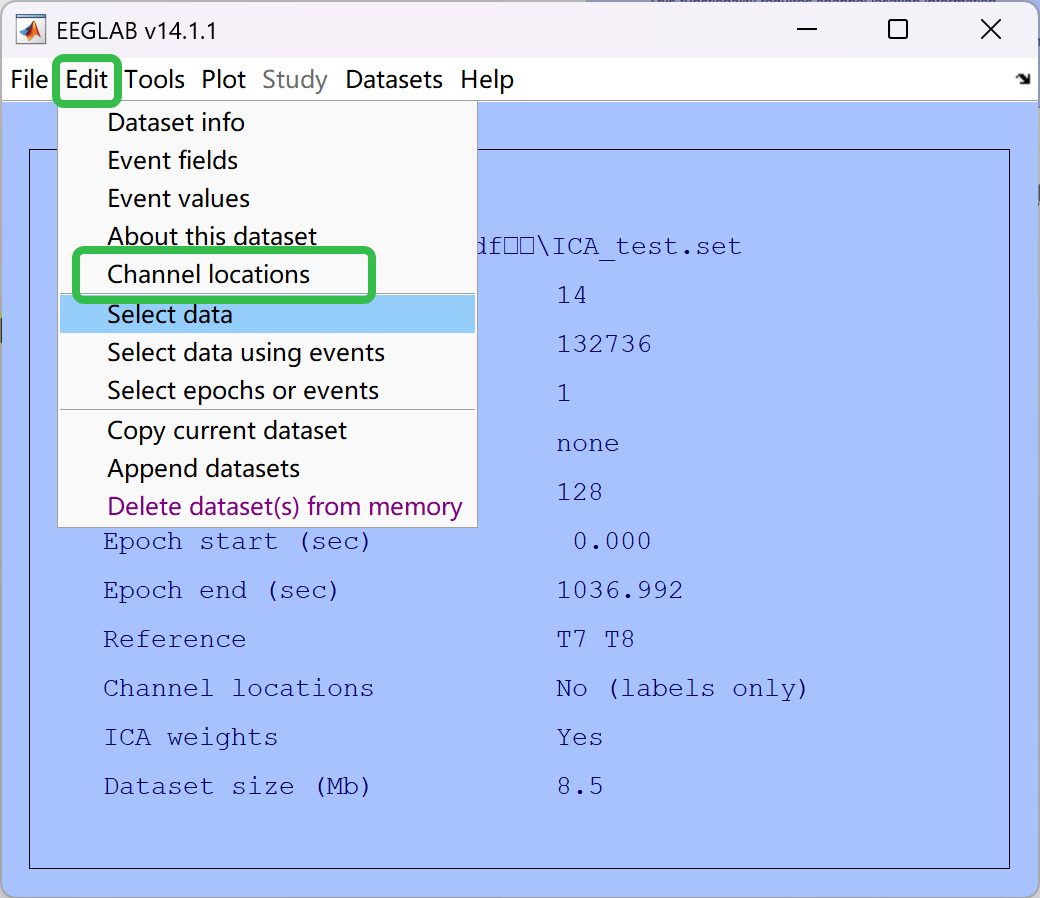
- 点击 OK 即可,Channel locations 变为了 Yes
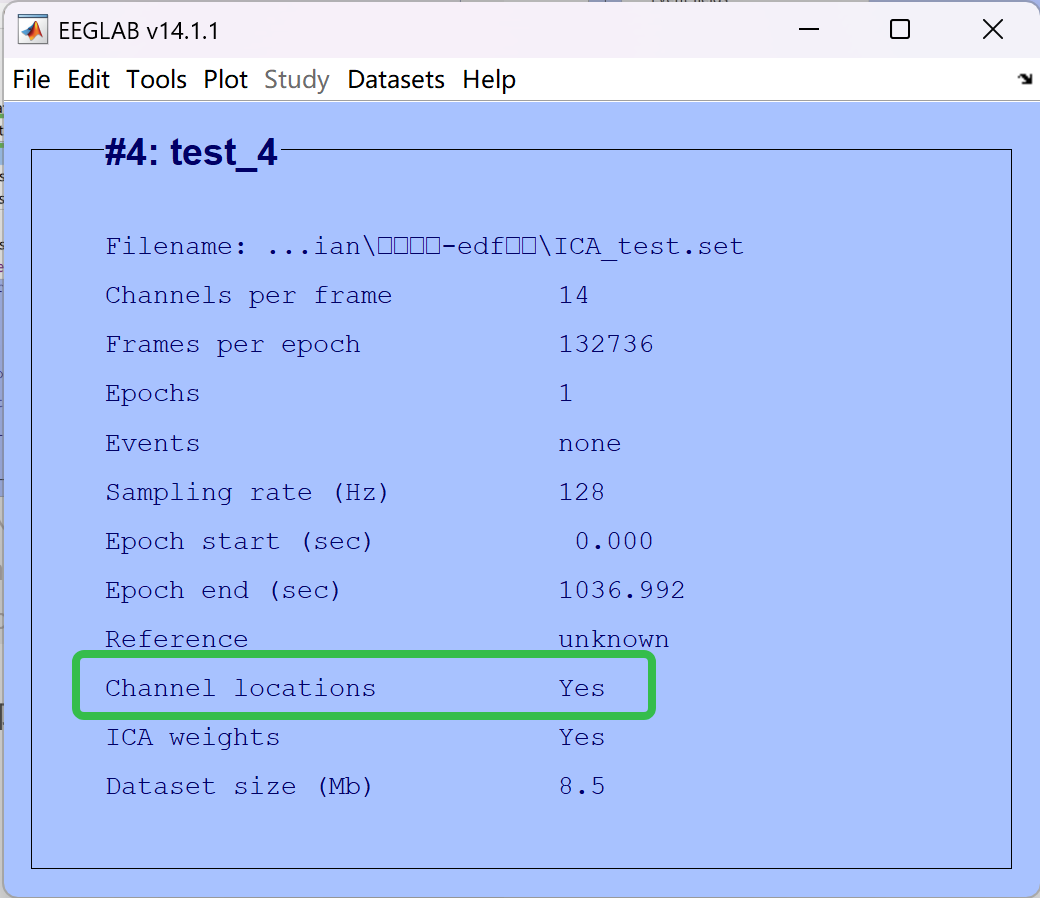
- 解决好问题后,按照上面的步骤继续完成即可,点击 OK
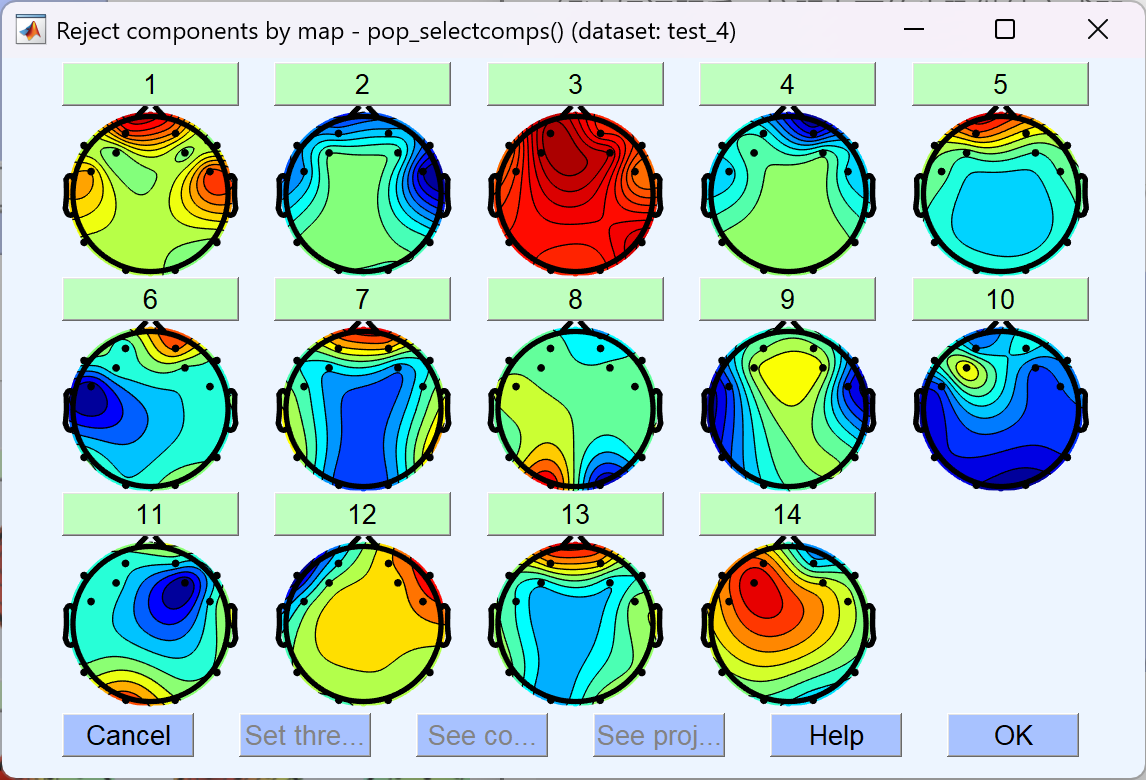
- 这时会画出对应的脑图,点击序号可以查看详情,其中 ACCEPT 表示标记其为 非伪迹
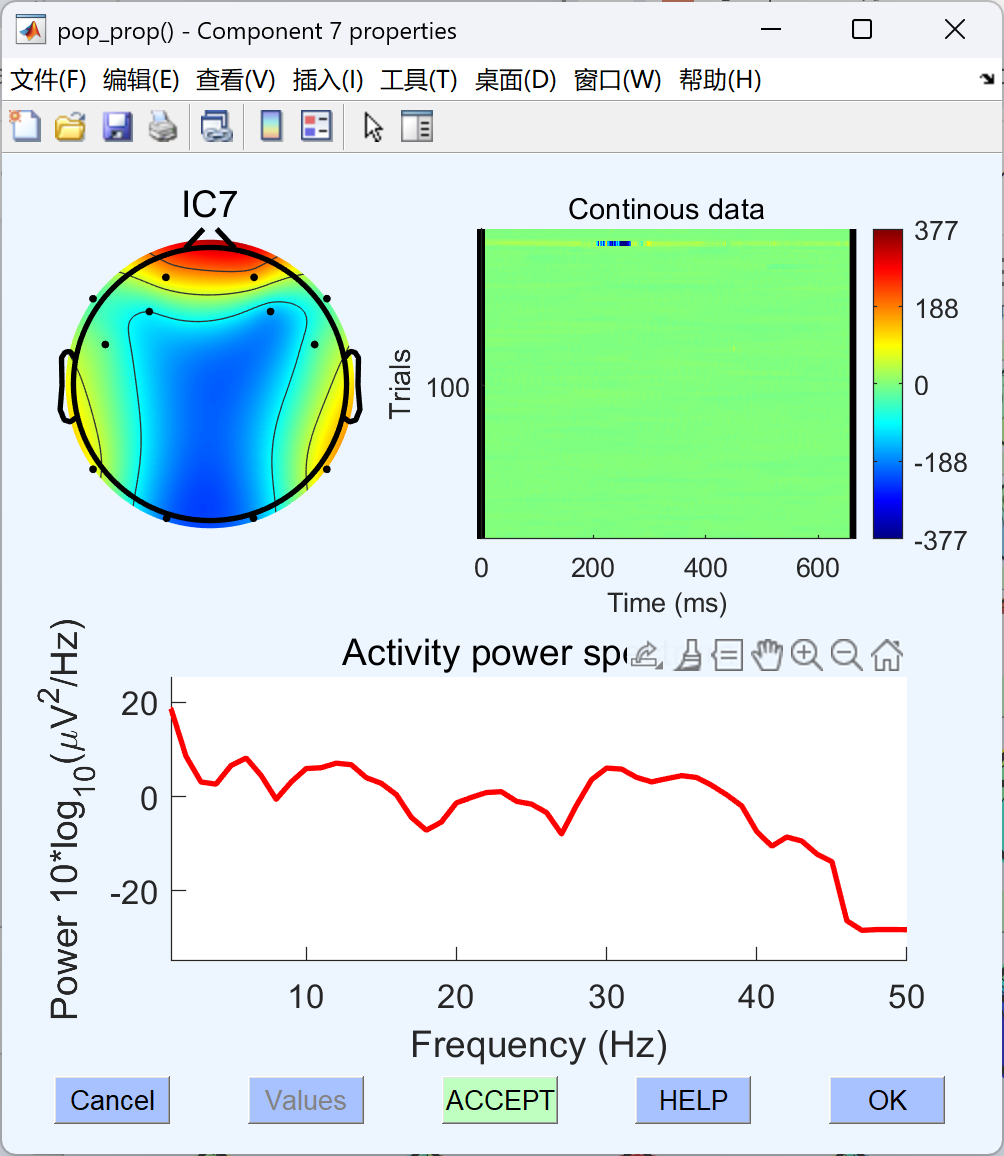
- 若点击 ACCEPT 使其变为 REJECT 。表示当前标记其为 伪迹。 点击OK。(伪迹在图中就会呈现红色)
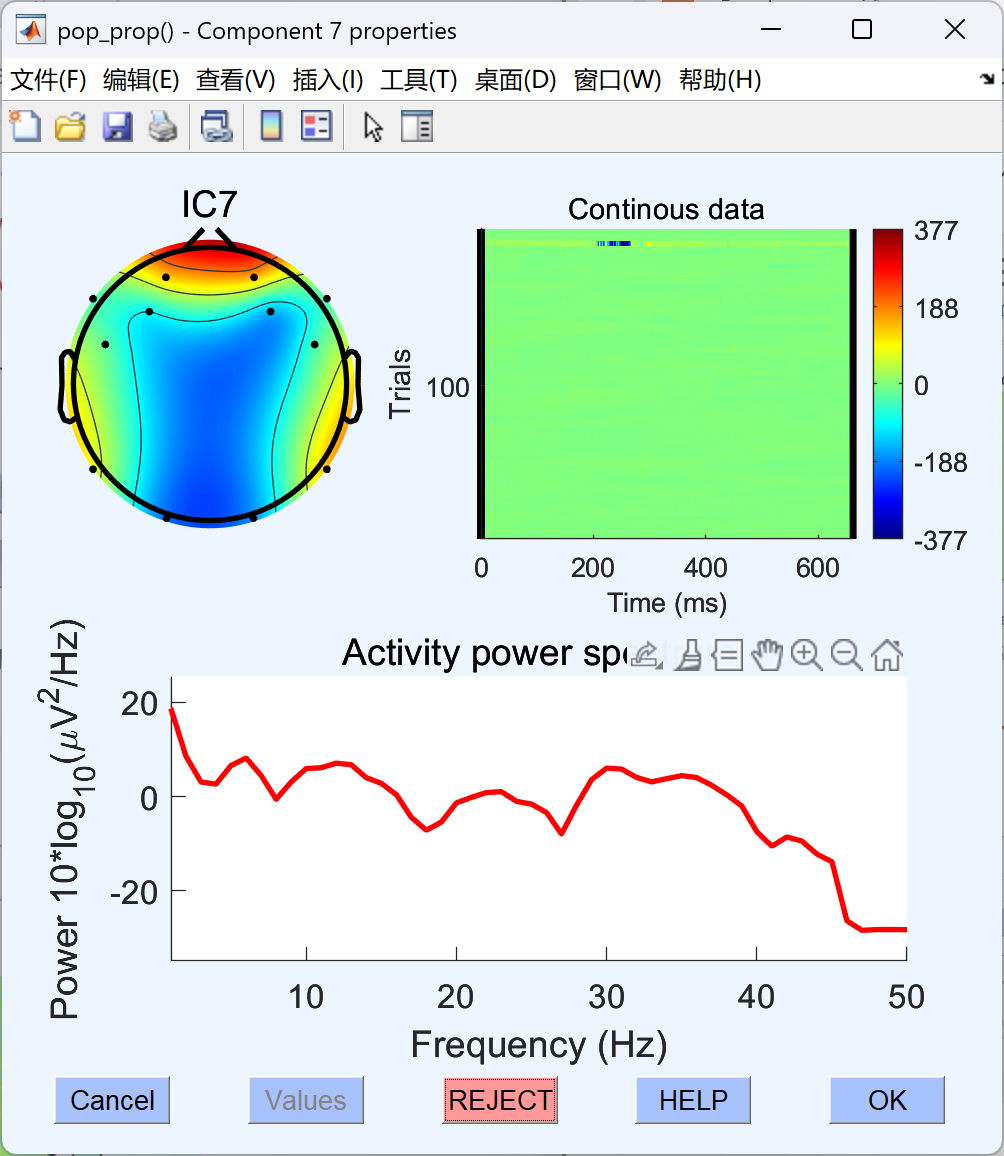
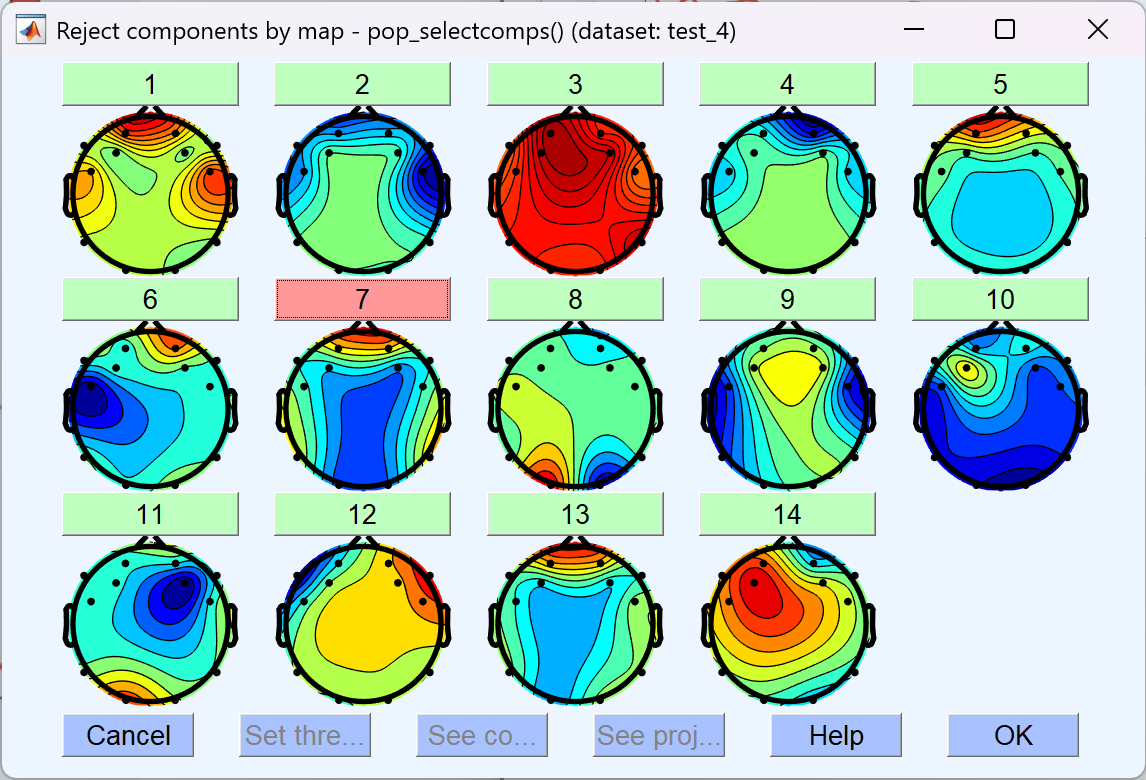
- 这里标记了7作为伪迹,最后点击OK。
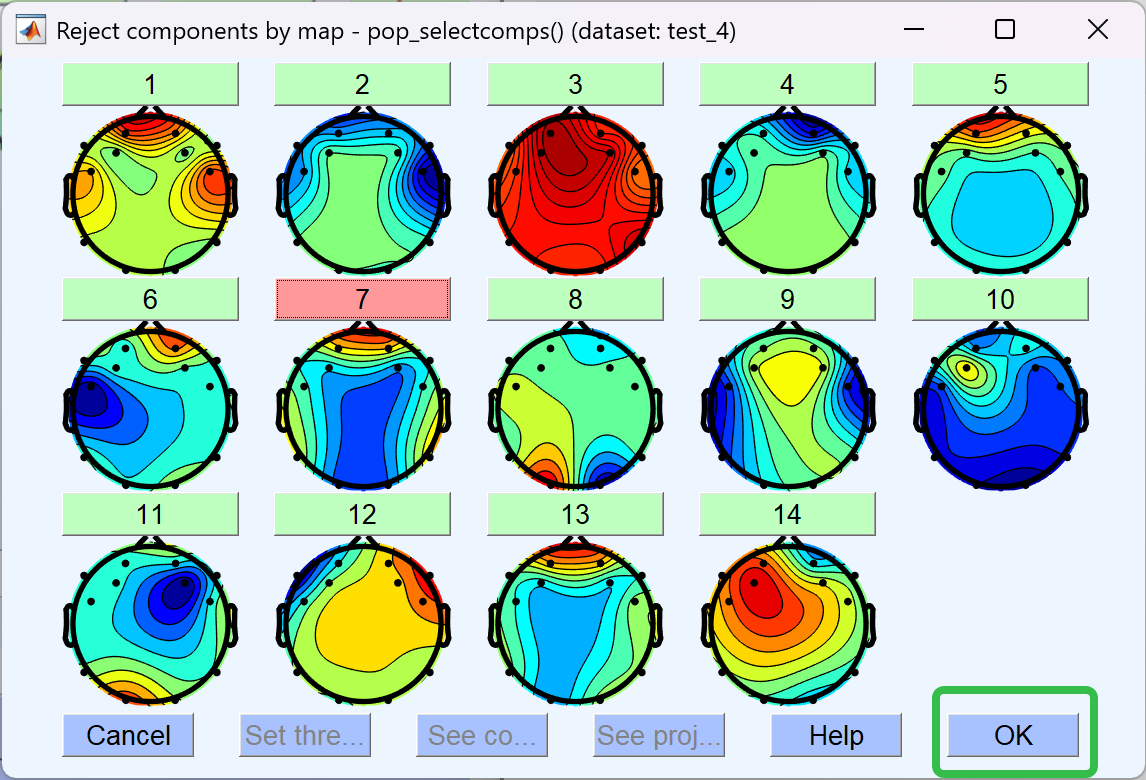
- 然后进行移除伪迹
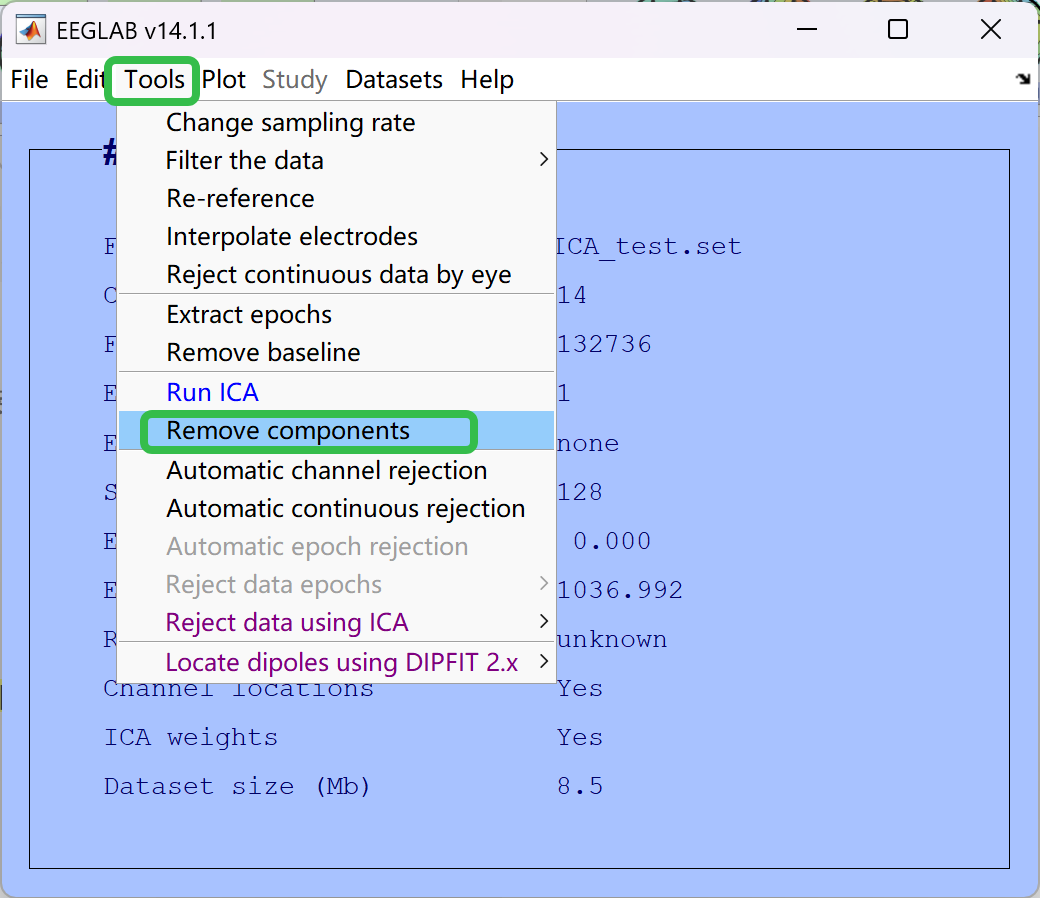
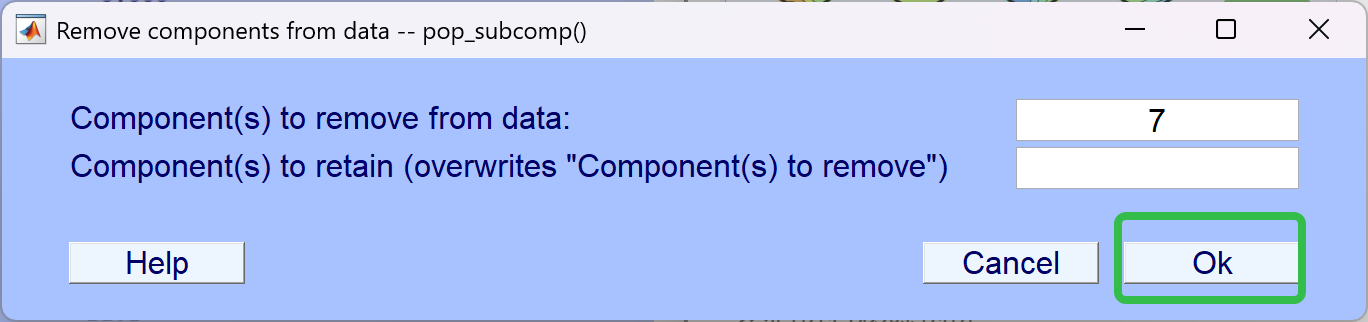

- 取名为test_5,表示手动去伪迹成功
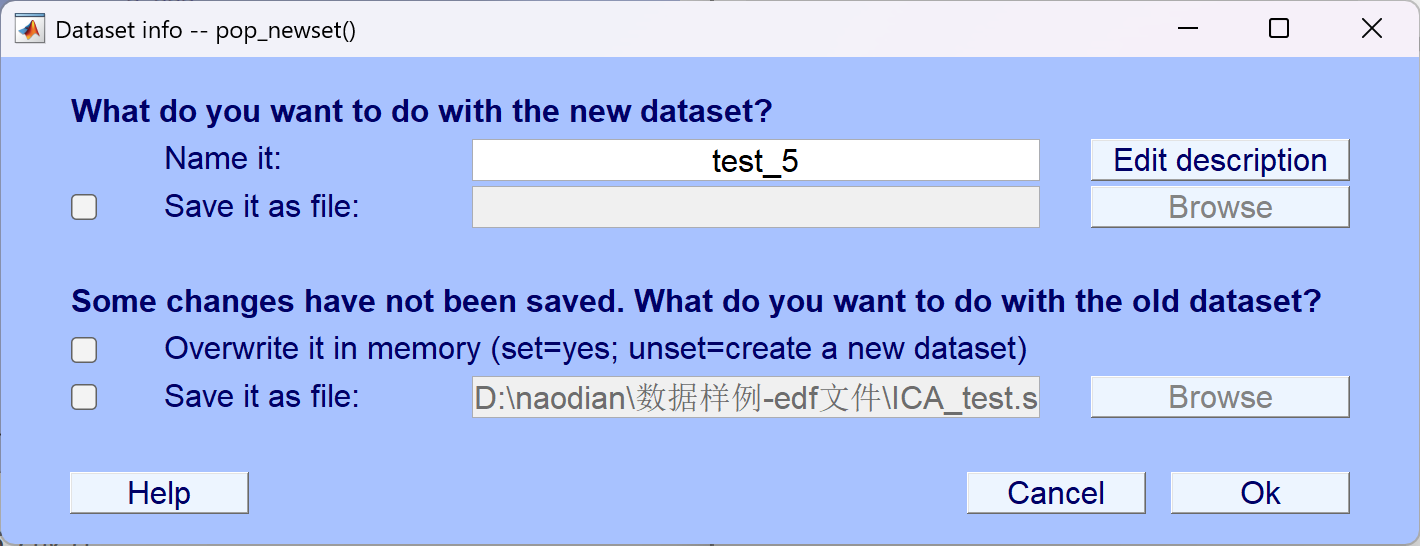
方法二:自动去伪迹
首先先选回原来还未手动去伪迹的test_4。
- 进行自动去伪迹
- 之后一直按 OK 即可,eeglab 最后会画出对应的所有成分。然后自动对其进行打标。
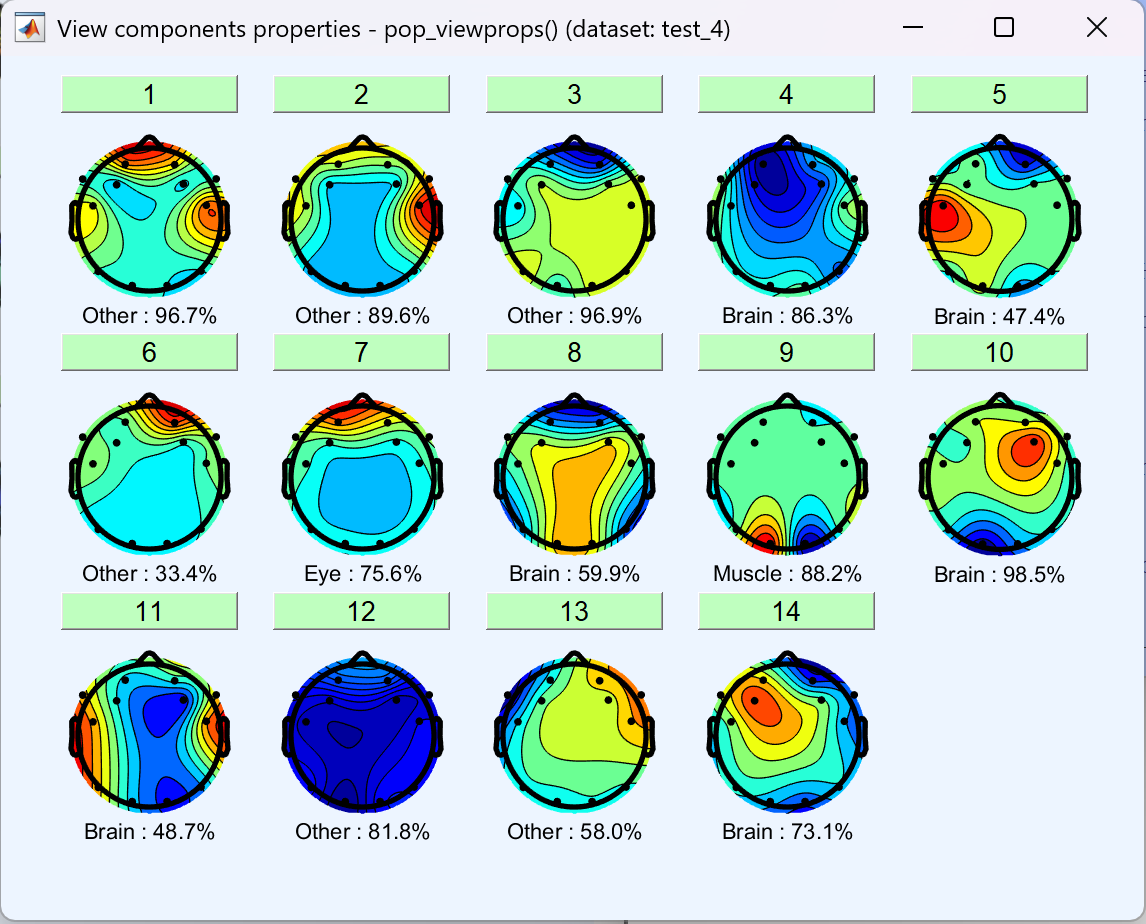
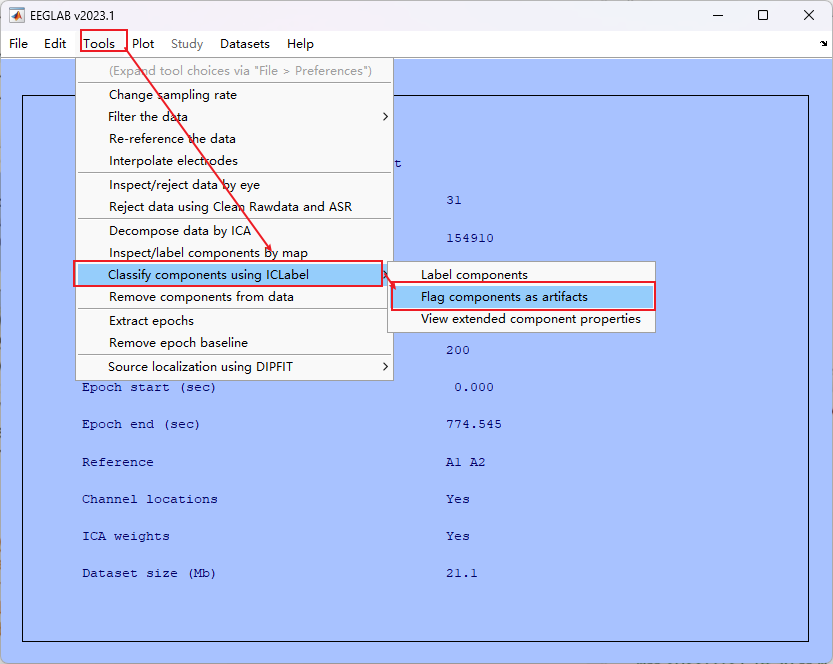
- 这里eeglab会自动选择90%-100%的Eye和Muscle的成分,默认点击OK即可
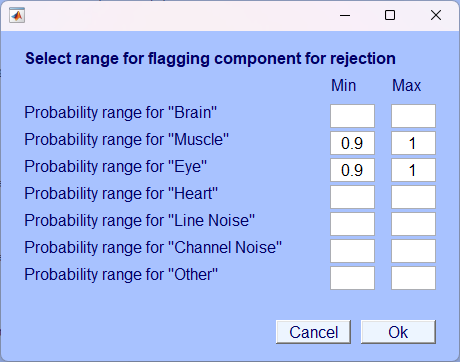
- 一直点击OK ,点击Accept,最后重命名即可
10. 绘制频谱图
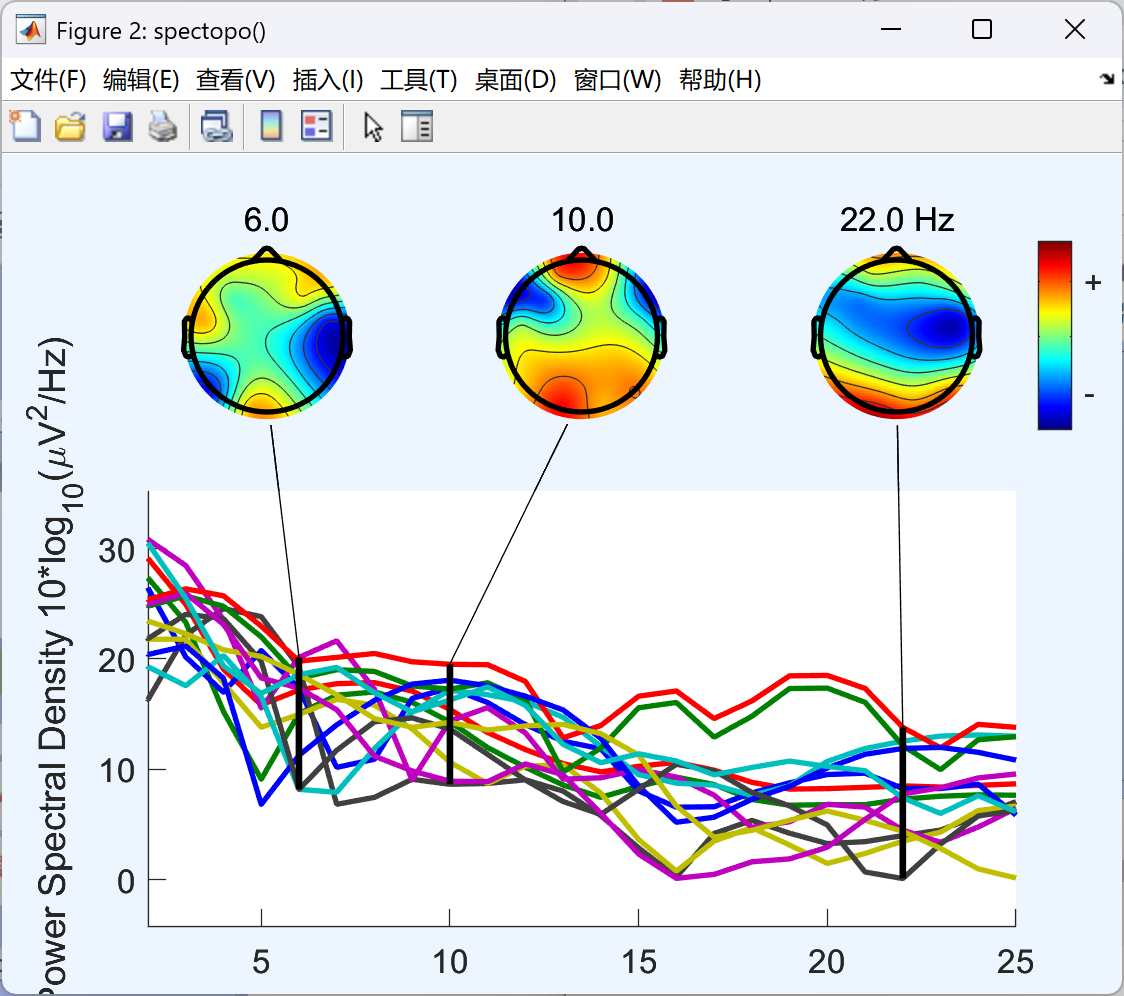
- 默认选择15%的数据进行分析,我们每次得到的结果将有所不同,而取值为100时,是无误的结果。以下是取值为100的结果
11. 导入自定义marker
什么是marker
Marker (标记) 在EEG数据采集过程中,用来记录特定事件发生时刻的标签或信号,代表着事件发生的事件或标志,用来辅助你理解和分析脑电信号。
marker的用途
| 应用 | 说明 |
|---|---|
| 刺激呈现 | 比如视觉、听觉刺激开始时,系统会插入一个mark(如"S1")表示刺激1的开始 |
| 行为事件记录 | 比如受试者按下按钮、作为选择 |
| 后续分析依据 | 用于进行时间锁定分析(如 ERP ),从 mark 开始提取某段数据 |
| 任务分段 | 比如 “试验开始” “休息” “试验结束” 都可以打mark |
| 数据筛选 | 只分析某种 mark 对应的试验(如只看案件正确的情况) |
- 在未定义marker之前 Event 为空
为什么要手动插入Marker
在我们处理EEG数据时,有时需要在数据中手动标记marker。特别是对于静息态EEG数据,数据记录时往往并没有打marker,而在静息态数据处理中需要把数据分割成比如说长度为2的epoch,此时可能需要离线手动标记相应的marker,以便于方便提取epoch。
以下是一个手动插入marker的例子
- ① 在eeglab中导入静息态EEG数据,该例子的EEG数长度为1036.992
- 建立一个带有marker信息的txt文件,在Matla命令中输入以下指令
cc=120:2:1036;% 创建一个从2到1036的向量,步长为2
ent=ones(length(cc),2);% 创建一个大小为(length(cc), 2)的全1矩阵
ent(:,1)=cc';% 将cc的值赋给ent的第一列
save marker.txt -ascii ent% 将ent矩阵以ASCII格式保存到.txt文件
- 得到一个带有marker信号的txt文件,命名为marker.txt。
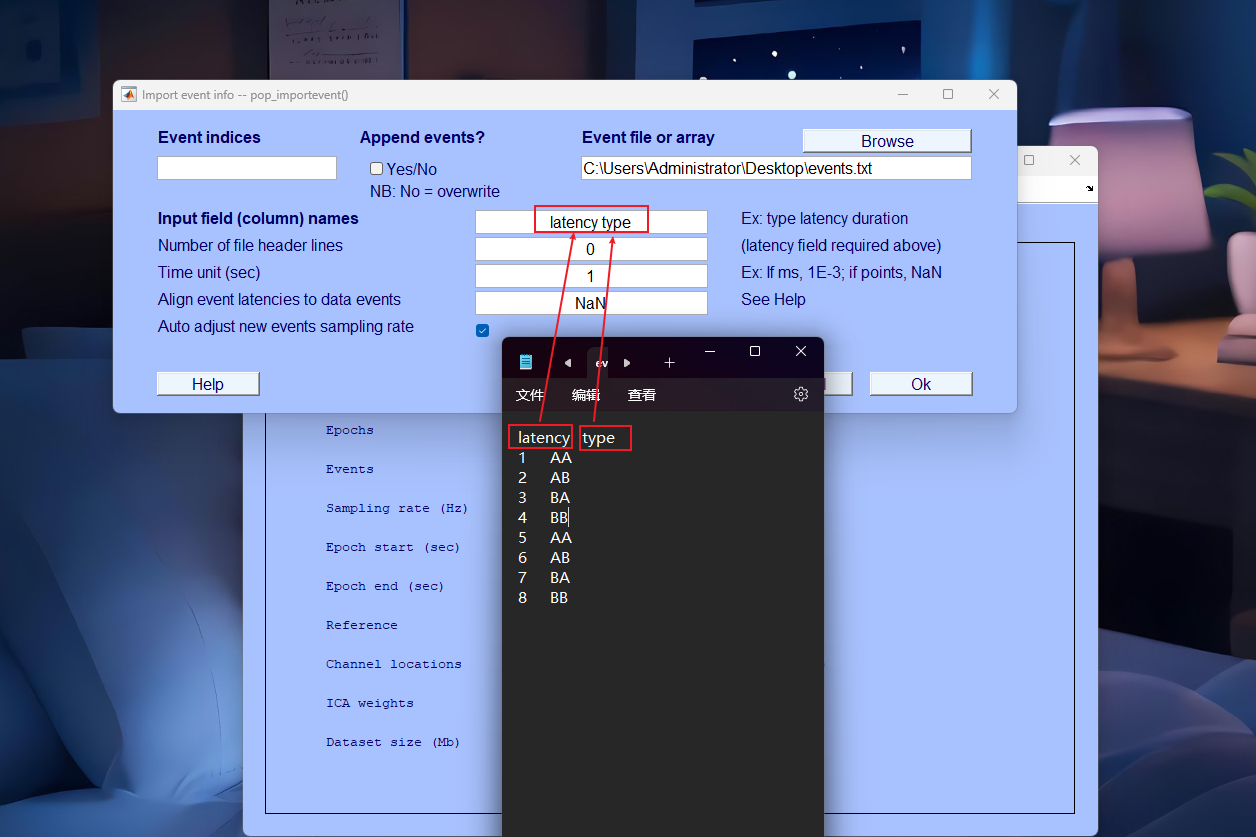
- 打开txt文档,在第一行加入latency和type。txt文档中第一列表示marker所处的时间点位置,以秒为单位;第二列表示marker类型,该例子中我们假设marker的类型都一样,即都为类型1.
- 第一行固定格式 latency + “TAB键” + type
- 第二行开始,第一列写时间,第二列写该时间点对应的标签类型

- 导入marker信息
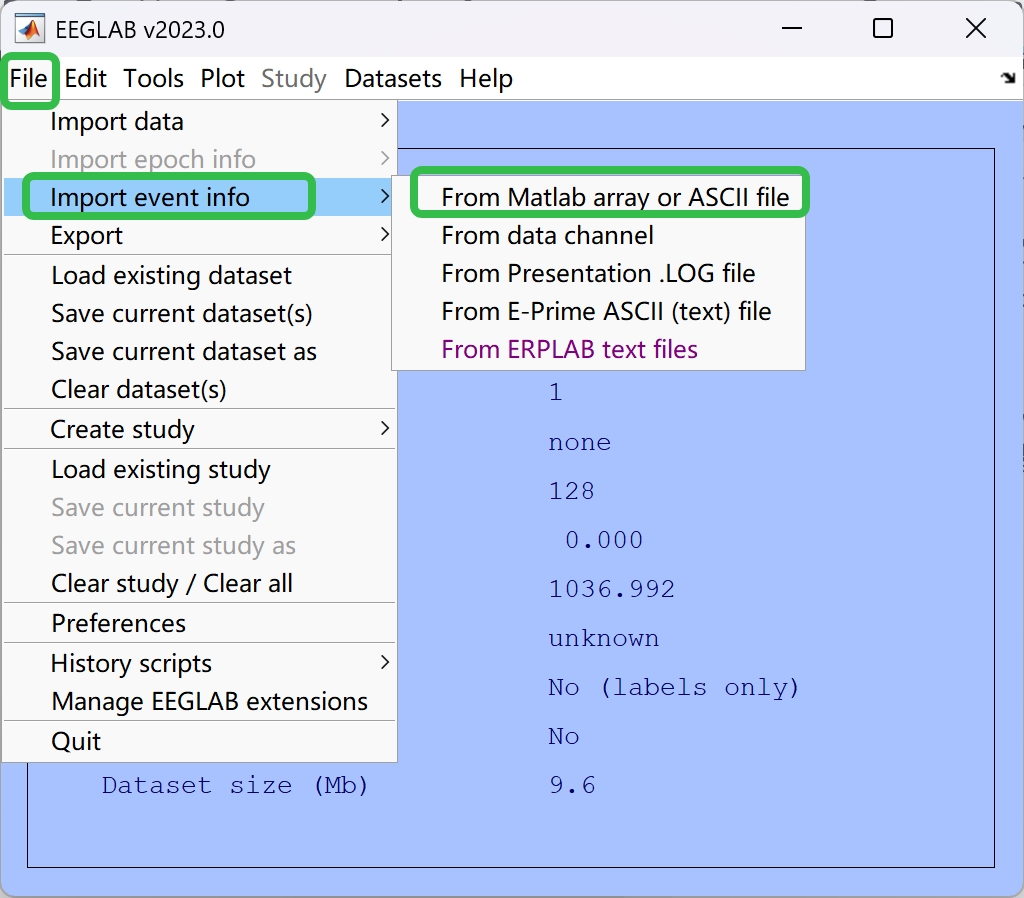
- 设置框框内的参数,最后点击OK即可
- 这里的选择很重要
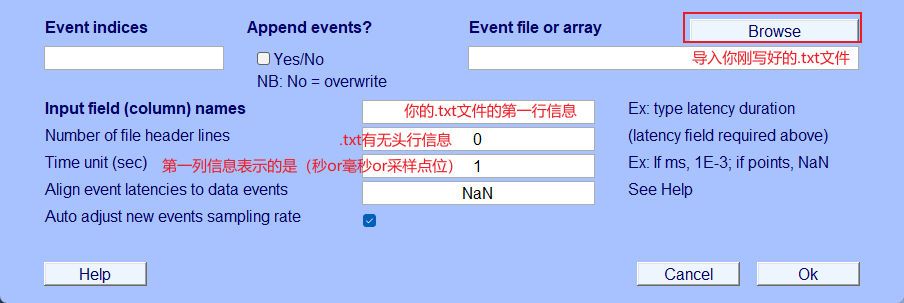
- 导入txt
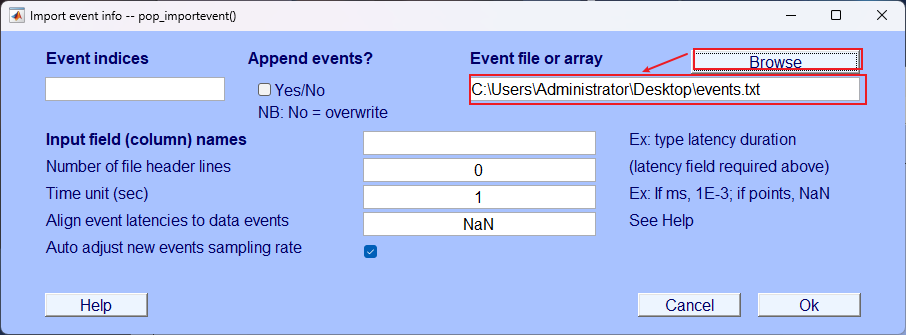
- 一一对应填写表头。 .txt中Tab键位在填写时只需要空格键即可
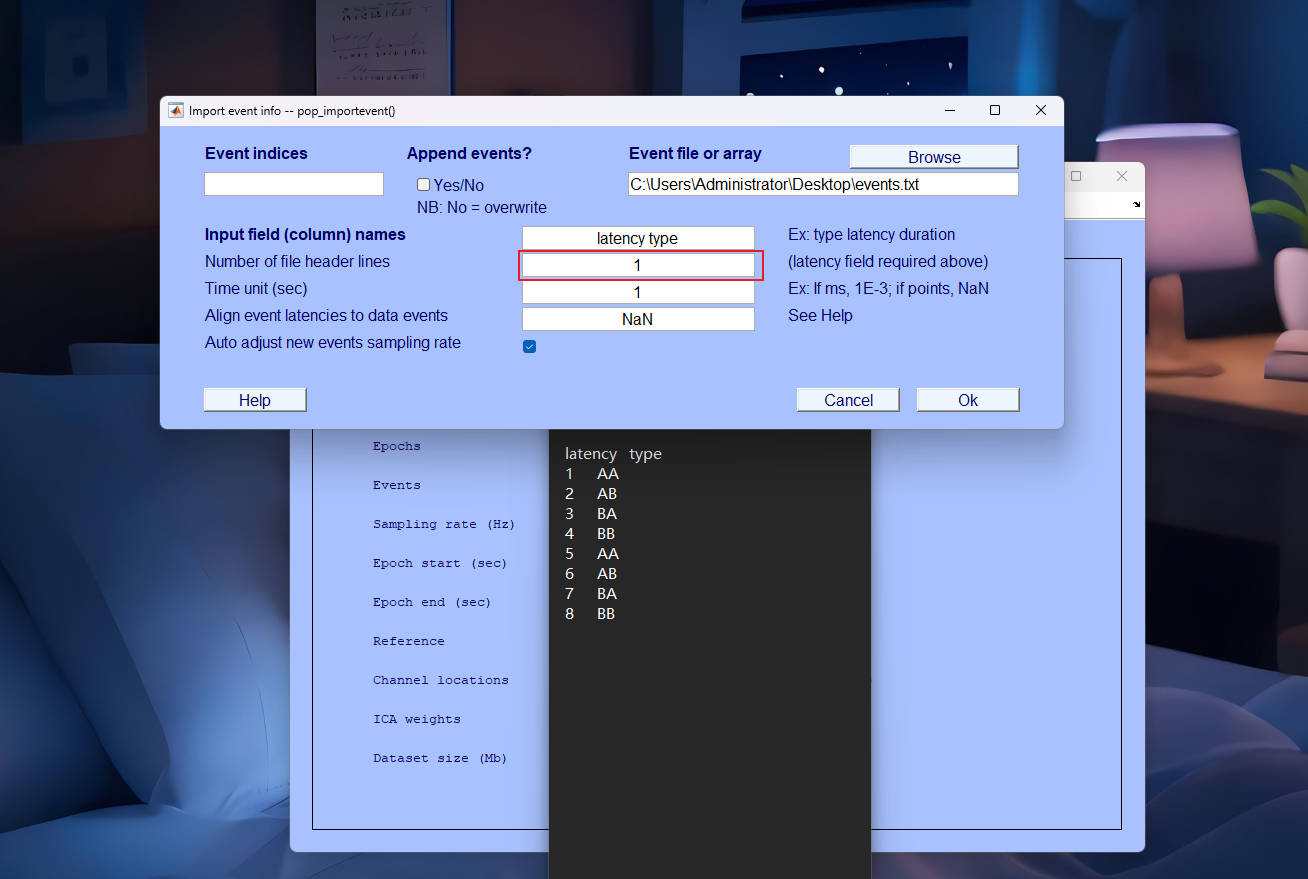
- 这里必须填1,因为我们要用.txt的表头内容
- 最后的结果
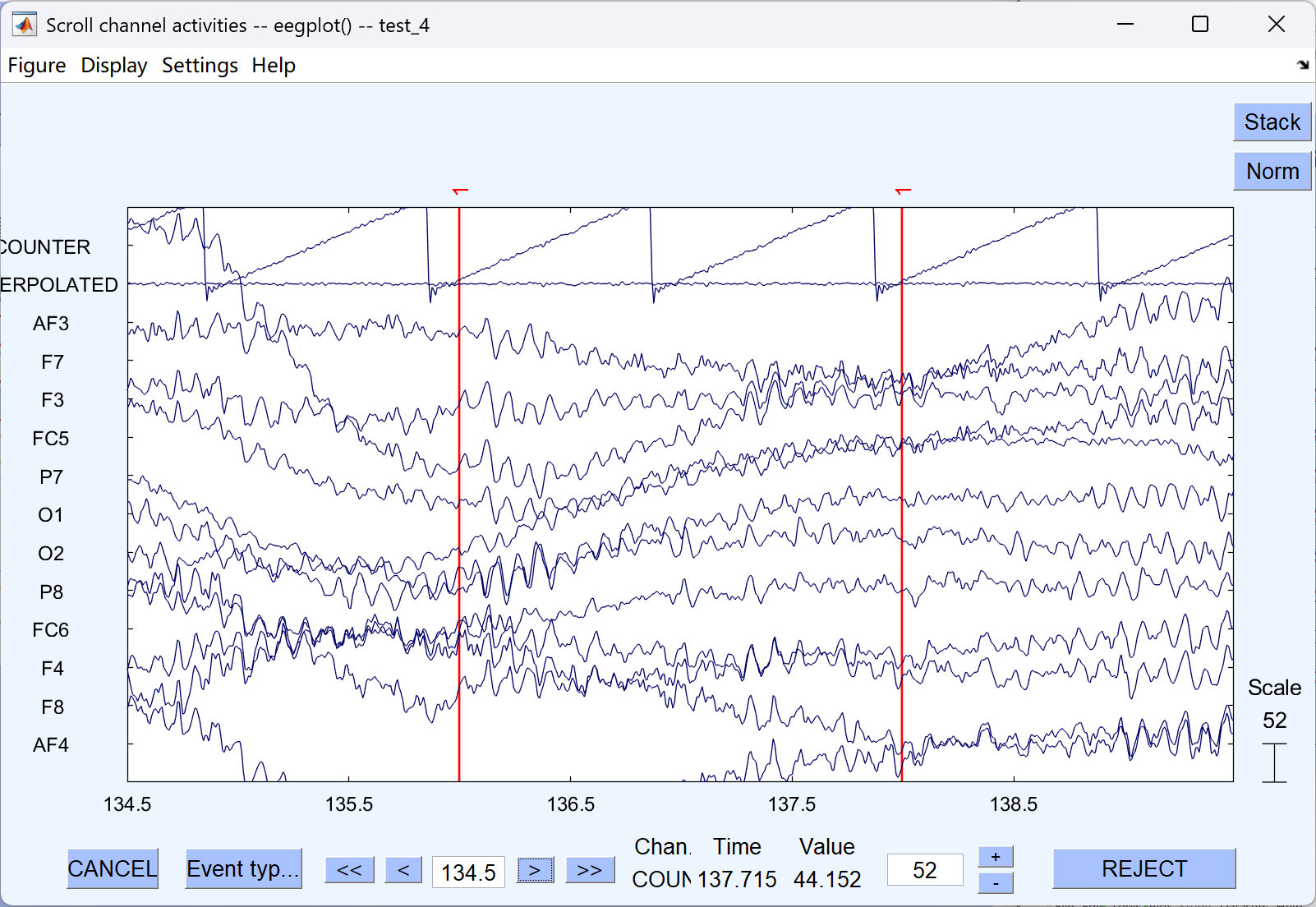
12. 分段与基线校准
什么是分段
定义:分段是根据某个是事件(marker)把连续的 EEG 信号截取成一个个小片段(epoch),每个片段围绕一个事件发生点展开。
例子:假设你有一个marker(事件)出现在第500个采样点,你想提取从这个点钱200ms到后800ms的脑电数据。
如果你的采样率是1000HZ,那么这个epoch就是:
- 从第500 - 200 = 300个采样点
- 从第500 + 800 = 1300个采样点
- 总长度:1100个采样点,对应1000ms的时间窗(-200ms ~ +800ms)
结果:原本是一条很长的EEG事件序列,现在变成了很多个 短片段(epoch),每个片段都围绕着一个刺激或行为事件。
什么是基线校准
定义:把每个epoch的某一个时间段(通常是事件前)作为准线,减去这个基准线的平均值,从而让信号以该基线为 “零点” 。
例子:假设你有一个epoch,从-200ms到+800ms
你设定准线区间为:-200ms到0ms。你要做的事就是:
- 对这个区间求品均值(比如是3μV)
- 然后把整个epoch的所有值减去这个3μV
- 最终的信号就相对于这个刺激时刻对齐了
二者的关系
| 操作 | 目的 | 时机 |
|---|---|---|
| 分段 | 将数据围绕事件裁剪为一个个epoch | 先做 |
| 基线校准 | 去除刺激前点位偏移,使数据 “归零” | 后做 |
- 操作步骤
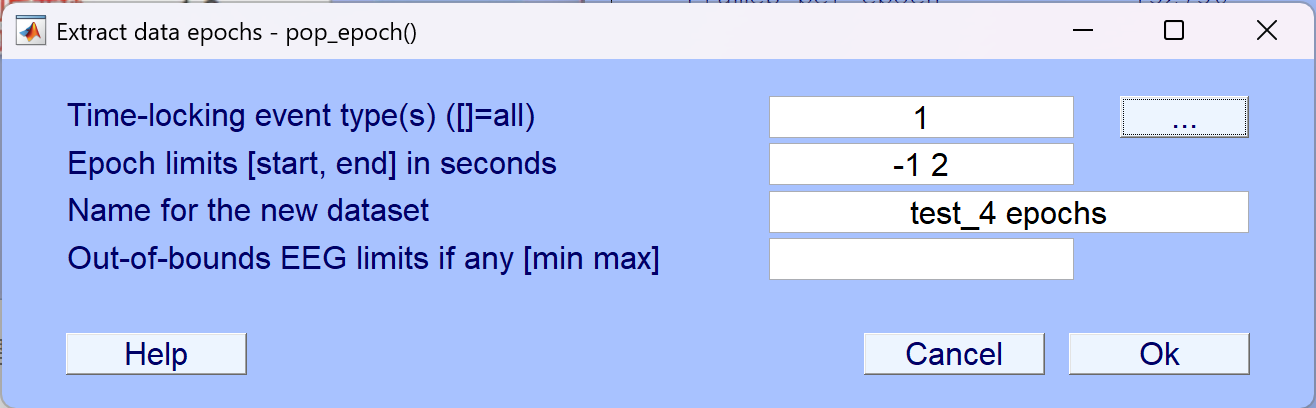
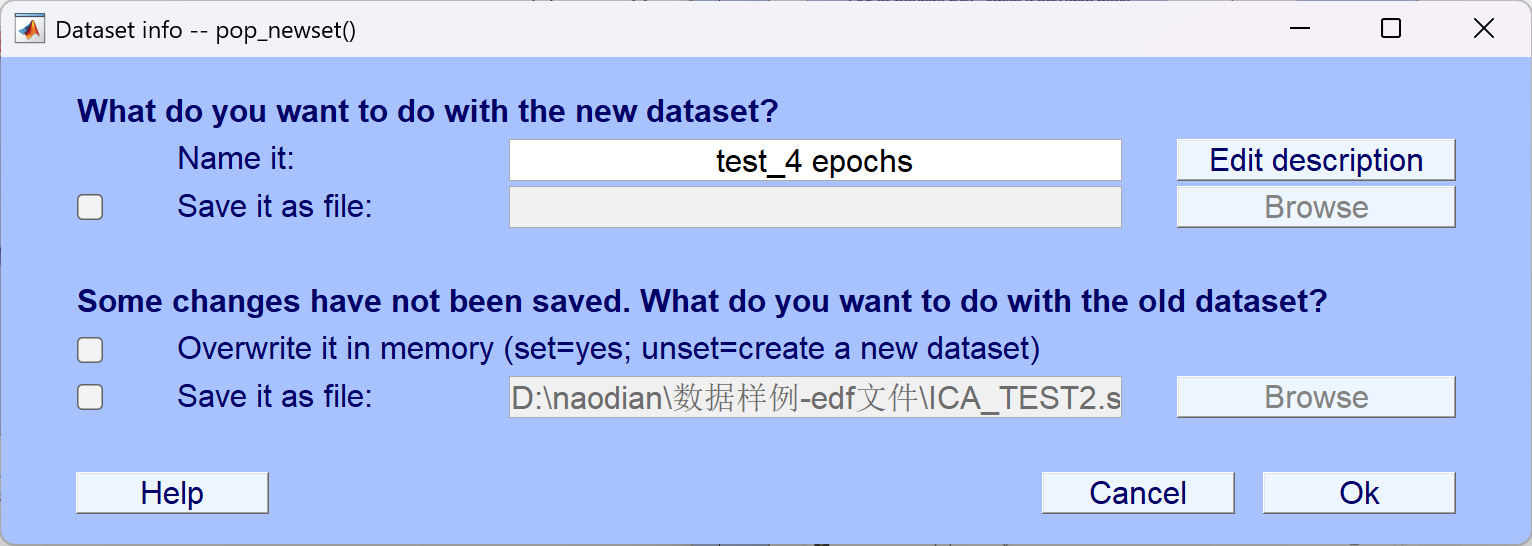
- 点击OK后会弹出下一个要求基线校准的对话框,默认使event前的数据作为基线来进行校正,点击OK即可
- 结果如下
13. 添加插件
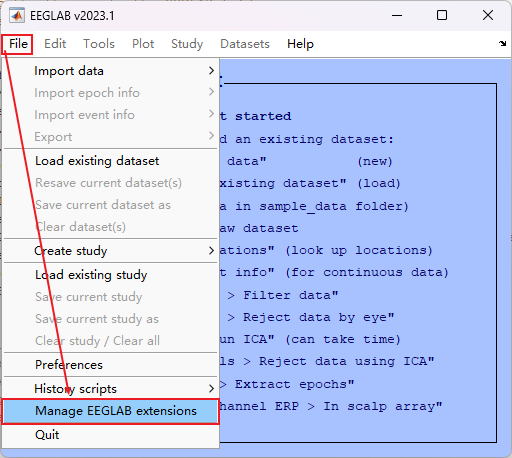
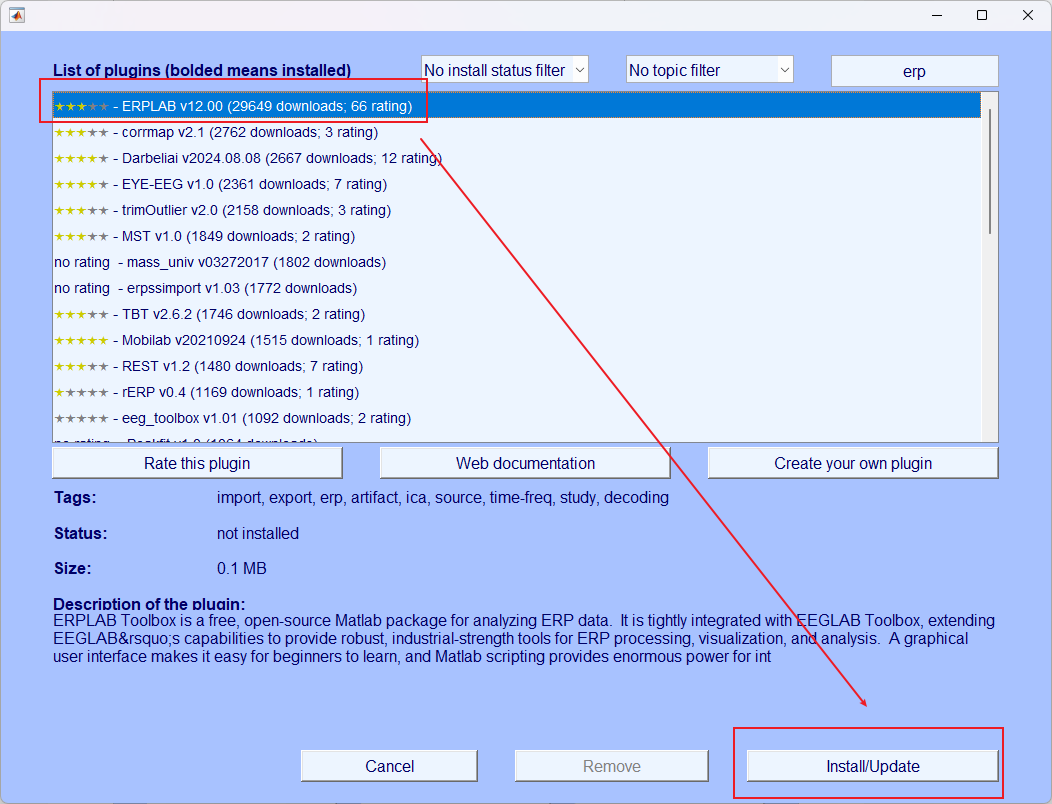
- 对于想要安装的插件直接在上面搜索即可
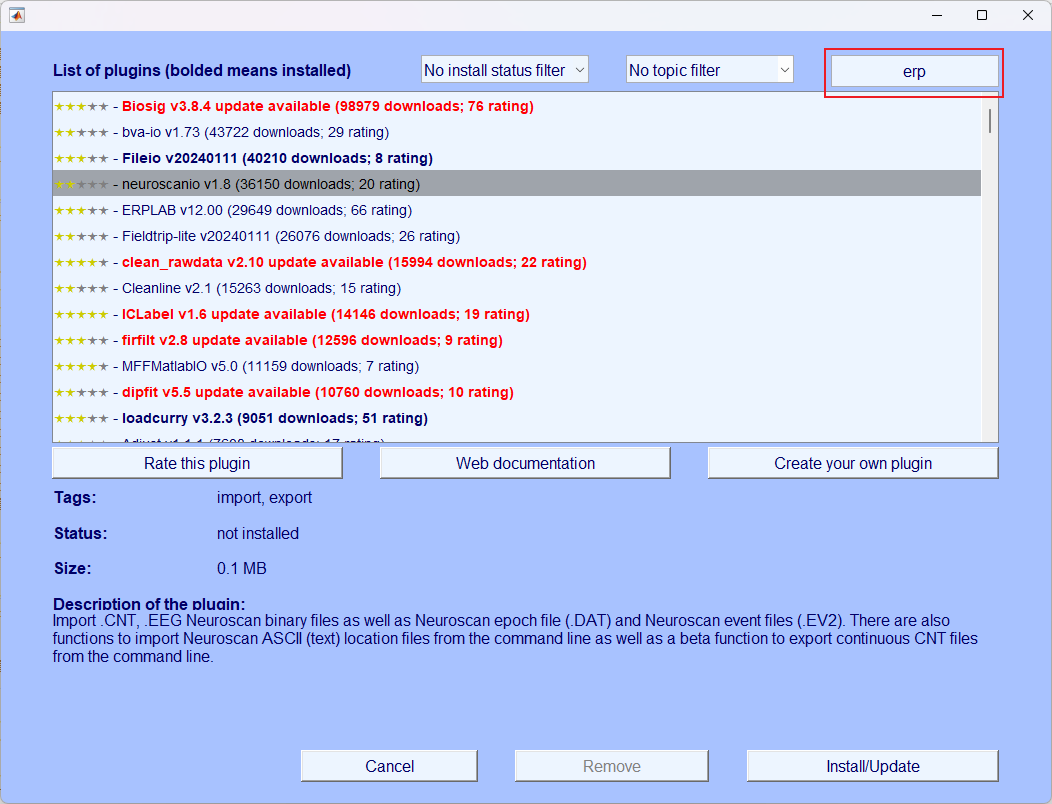
- 点击安装即可
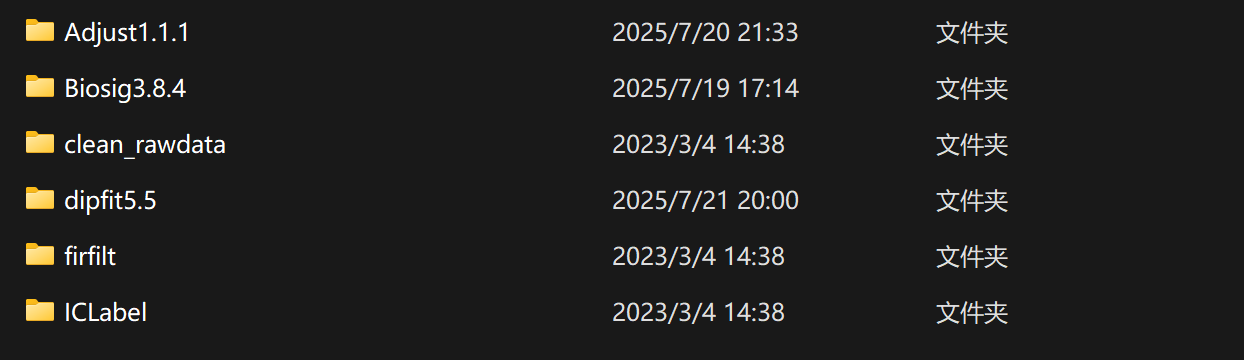
- 安装的结果一般存放在 eeglab/plugins 中
三、运行代码
1. 预处理
- 处理流程
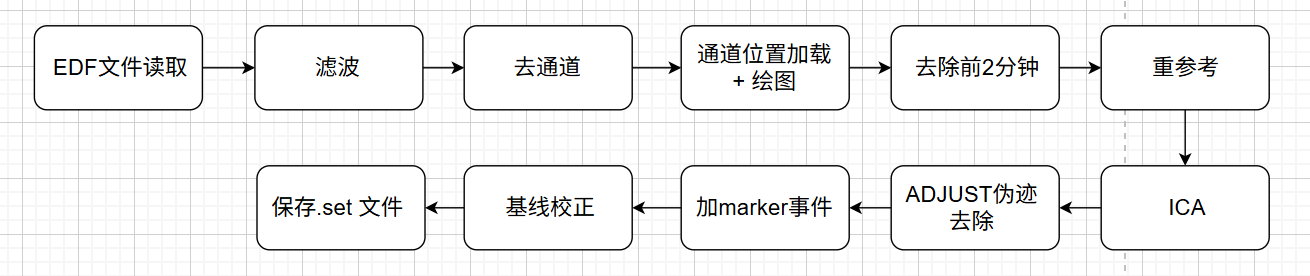
- 关键代码分析
数据加载与文件遍历
- 使用dir()读取指定路径下的所有.edf文件
- 对每个文件执行完整的预处理流程
数据导入
- 首选用pop_biosig()读取EDF文件
- 如果失败,则尝试使用edfread()+pop_importdata()兜底导入数据
滤波
- 使用pop_eegfiltnew()对数据进行 0.1–45 Hz 的带通滤波,去除高频噪声和低频漂移。
通道剔除与通道位置信息
- 剔除无用通道(如陀螺仪、参考电极、质量控制等)。
- 使用 pop_chanedit() 添加标准通道位置信息,用于后续可视化和 ICA。
初步可视化与截断前段
- 绘制初始电极布局图。
- 剪去前 2 分钟数据,排除刚开始不稳定部分。
重参考
- 使用 T7 和 T8 电极作为参考,进行重新参考(pop_reref())。
独立成分分析(ICA)
- 使用 runica 算法提取独立成分。
- 若存在 ADJUST 插件,则使用其自动识别伪迹成分并剔除。
伪迹成分剔除
- 从 report.txt 中读取自动标记的坏成分编号。
- 调用 pop_subcomp() 删除这些成分。
事件插入
- 每隔 2 秒插入一个虚拟事件 marker。
- 创建并写入带有头信息的 marker_with_header.txt,再读取并构造 EEG 事件结构。
去基线
- 对每个 epoch 的前 0–100ms 区间执行去基线处理(pop_rmbase())。
保存数据
- 将处理后的 EEG 数据保存为 .set 文件,保存在指定输出路径中。
2. 特征提取
- 处理流程

- 关键代码分析
数据加载与遍历
- 使用 dir() 获取指定路径下的所有 .set EEG 数据文件;
- 遍历每个 .set 文件,逐一加载并进行特征提取。
创建 CSV 文件用于保存特征
- 构建输出路径 features.csv;
- 用 fopen() 打开写入通道;
- 写入列标题:File, Label, Event, Channel, Mean, Std, PeakToPeak, Skewness, Kurtosis;
- 若文件打开失败则报错终止。
初始化 EEGLAB 环境
- 使用 [ALLEEG, EEG, CURRENTSET] = eeglab; 初始化 EEGLAB 工具箱。
事件合法性检查
- 遍历 EEG.event,将每个事件的 latency 调整到合法范围 [1, EEG.pnts];
- 防止索引超出 EEG 数据边界。
提取标签(label)
- 通过 file_list(i).name(6) 获取文件名第6个字符;
- 作为该文件对应的分类标签(Label)写入 CSV。
按事件分割 EEG 数据段
- 遍历每个事件,获取当前事件和下一个事件的 latency,以两个事件之间的数据段作为分析窗口,如果是最后一个事件,则以 EEG.pnts 作为结束。、
提取每个通道的时域特征
- 对每个通道的该事件段数据提取以下特征:均值(mean)、标准差(std)、最大值 - 最小值(Peak-to-Peak)、偏度(skewness)、峰度(kurtosis)
写入特征到 CSV 文件
- 每条数据格式为一行:文件名, 标签, 事件编号, 通道编号, 特征1~5;
- 使用 fprintf() 将所有通道所有事件的特征写入文件。
3. 分类
- 处理流程

- 关键代码分析
读取特征数据
- 使用readtable()从CSV文件中读取特征数据(包含多个通道、事件、文本样本)
数据筛选(仅保留特定通道)
- 只选择 Channel == 1 的行(一个通道用于分类);排除其他通道以简化分析。
提取特征和标签
- features = filtered_data{:, 3:8} 提取第3~8列作为模型输入特征(如 Mean、Std、PeakToPeak、Skewness、Kurtosis);
- labels = filtered_data{:, 2} 第2列作为分类标签(表示 EEG 的类别,如正常/癫痫等)。
特征标准化
- 使用 normalize(features) 对特征进行归一化处理;消除不同特征量纲差异,提高模型训练稳定性。
划分训练集和测试集(HoldOut法)
- 使用 cvpartition() 按照 70% 训练 、30% 测试 划分数据;
- rng(‘default’) 固定随机种子确保结果可重复;
- 得到训练索引 trainIdx 和测试索引 testIdx。
构建训练集与测试集
- x_train, y_train:用于训练模型;x_test, y_test:用于模型测试和评估。
模型训练(支持三类模型)
- 使用SVM、随机森林、KNN进行训练
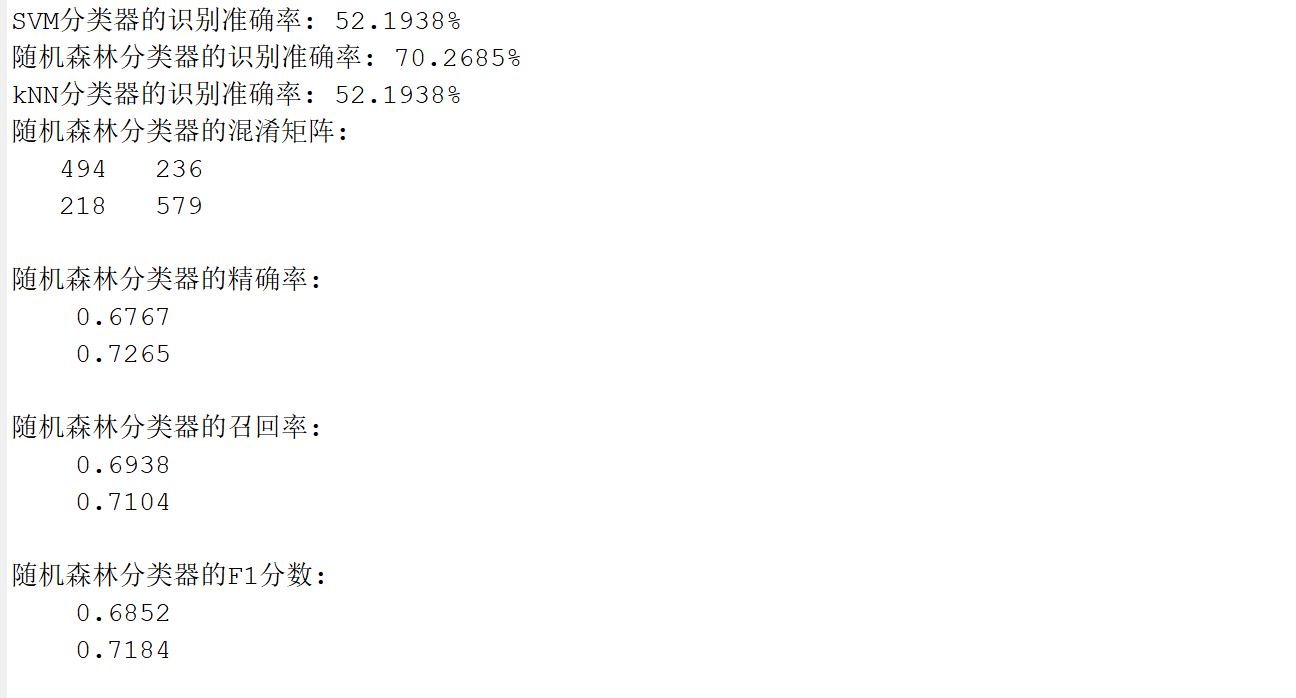
模型预测与准确率评估
- 依次使用 SVM、随机森林、kNN 对测试集预测;
- 计算准确率(预测正确数 ÷ 总样本数):accuracy = sum(pred == y_test) / length(y_test)
- 使用 disp() 显示每种模型的识别准确率。
混淆矩阵与性能指标分析(以随机森林为例)
计算混淆矩阵:confusionmat(y_test, rf_predictions);
进一步计算:
- 精确率(Precision):每类预测中有多少是对的;
- 召回率(Recall):每类实际样本中识别对了多少;
- F1 分数(F1 Score):精确率与召回率的调和平均值。
交叉验证评估泛化性能(随机森林)
- 使用 crossval() 对随机森林模型做 10 折交叉验证;
- 使用 kfoldLoss() 计算平均验证误差;
- 显示随机森林在验证集上的错误率(越低越好)。
- 运行结果
四、学习感受
通过本次对EEGLAB的使用以及对代码的解读,我学习了脑电信号从导入、预处理到特征提取和分类建模的完整流程,进一步加深了对每一步背后原理的理解,比如重参考对信号稳定性的影响、ICA在去除伪迹中的作用等。刚开始接触时会觉得流程繁琐,一步步操作下来之后,发现每个环节都具有必要性。